融合全卷积和级联卷积神经网络的人脸检测方法
2019-07-31刘丽娴樊学宝
刘丽娴 樊学宝
【摘 要】为了解决小人脸漏检以及人脸定位偏差的问题,通过融合FCN深浅层特征和多尺寸人脸框生成技术,介绍了一种人脸快速标注和定位的方法。该方法研究了如何利用全卷积网络深浅层特征快速锁定人脸区域,然后采用金字塔生成不同尺寸的人脸候选框,最终实现由粗到细、逐级筛选的人脸检测和定位。实验证明,与传统方法相比,本文的方法无论在准确率还是速度上都具有一定的优势。
【关键词】全卷积神经网络;级联神经网络;图像金字塔;人脸检测
1 引言
在复杂环境下,人脸检测会受到很多外界因素的干扰,如人脸姿态、光照条件、遮挡以及小目标检测。随着近几年人脸检测技术的快速发展,特别是深度学习的飞速发展,大量的人脸识别检测技术如雨后春笋般涌现出来。卷积神经网络[1-2](Convolutional Neural Network,CNN)作为深度学习的典型,在人脸识别上取得了卓越的成就。但该方法使用范围较窄,特别是在光照比较复杂的环境下人脸检测的精度较低,而且通过遍历的方式来检测人脸框,导致人脸检测的复杂度很高,而且CNN需要固定输入图片的尺寸,大大限制了应用的范围。
随着研究的深入,研究者提出了Fast R-CNN的人脸检测方法[3-4],该方法将整张图片一次性放进卷积神经网络,然后将候选窗口映射到最后一层的特征图上,并采用ROI Pooling的方法使候选窗口输出的尺寸是固定的,最后采用全连接层进行人脸的检测和候选窗口的边框回归。该方法对输入图片的尺寸没有限制,但是由于采用选择性搜索的方法来生成候选框,速度上还是满足不了实际使用的要求。Faster R-CNN[5-6]采用RPN的方法来获得候选框的特征信息,然后使用分类器对候选框分类并对候选框的位置进行回归调整。除了上述的几种经典的算法,还有Mask R-CNN[7-8]、A-Fast-RCNN[9]、Light-Head R-CNN[10]等,但都是对传统R-CNN的改进而已,都能在一定程度上提升检测的准确度。
本文在梳理主流研究文献的基础上,针对小目标检测及通过将人脸框映射到深层特征图上产生定位偏差的问题,提出了融合全卷积和级联卷积神经网络的人脸检测方法,采用一种由粗到细、由浅到深的特征提取,实现人脸的快速检测和准确定位。
2 相关理论的介绍
2.1 全卷积神经网络
全卷积神经网络(Fully Convolutional Networks, FCN)可以实现从图像级理解到像素级理解的神经网络,可以接受任意尺寸的输入图像。采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到与输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时也保留了原始输入图像中的空间信息。最后在上采样的特征图上进行逐像素分类,这是一种端到端的图像语义分割和边缘检测的方法,使网络实现像素级的标签预测。
2.2 级联卷积神经网络
级联卷积神经网络是一种由浅到深特征提取的“神器”,能够通过截取原图中不同大小的区域进行特征提取,最后通过生成的特征图谱实现人脸的检测。通过综合不同级别的卷积神经网络对人脸的概率判定和人脸区域的锁定,最终实现人脸的有效检测。
经典的级联卷积神经网络由3组简单的卷积神经网络组成,通过每组卷积神经网络训练数据大小的不同对图像进行特征提取,实现由粗到精、逐层精细化定位人脸候选窗口,这在很大程度上提高了人脸检测的准确率。多个网络对人脸的识别以及多个预测结果进行加权平均,得出的人脸检测结果更有说服力。
2.3 全卷积与级联卷积神经网络的融合
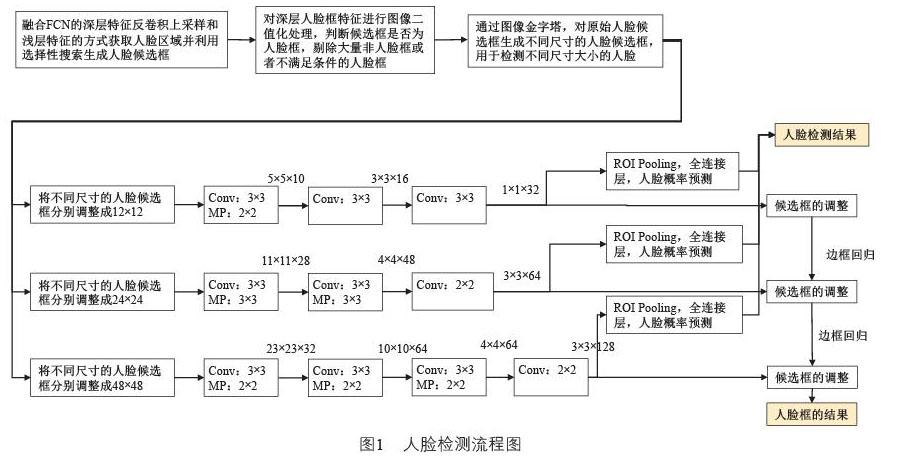
众所周知,深层特征信息具有更强的语义信息,识别问题更有效,但是会导致人脸区域定位的偏差。相反,浅层信息虽然能更有效地进行物体区域的定位,但在判断人脸时显得力不从心。因此,本文综合全卷积神经网络和级联卷积神经网络的特点,人脸检测的方法如图1所示。
人脸检测流程图的具体过程为:
(1)定位人脸的时候,融合FCN的深层特征和浅层特征的方式快速实现人脸区域检测并实现人脸区域的快速标注,然后通过选择性搜索方法快速生成各种尺寸的人脸候选框。
(2)选取人脸框的深层特征值并进行图像二值化处理,快速筛选大量不满足条件的人脸框。
(3)采用图像金字塔将人脸框调整成不同尺寸的人脸框,这样做可以避免小人脸的漏检现象发生。
(4)将不同尺寸的人脸框放进三组级联卷积神经网络中(三组级联卷积神经网络,其输入图像的尺寸分别为:12×12、24×24、48×48,因此需要将不同尺寸的人脸框调整为12×12、24×24、48×48),并对不同的人脸框进行独立预测,然后通过加权平均的方法对人脸框的预测结果进行综合判定。
(5)采用边框回归和非最大值抑制(NMS)算法实现人脸框的逐级调整,实现由粗到细的人脸框区域定位。
3 融合全卷积和级联神经网络的人脸检
测模型
(1)全卷积神经网络的人脸位置区域提取,并生成人脸框
通过全卷积神经网络对图片进行特征提取,在最后一层输出热力图,该热力图虽然能够有效地识别不同物体类别的边界,但是由于該热力图的尺寸过小,无法反映物体的边界。因此,本文采用多尺度融合的方法,将最后一层的热力图逐层进行上采样直至与原图的尺寸一致,并提取人脸位置区域。
在获取人脸区域后,采用选择性搜索方法,通过对人脸区域采用不同尺寸窗口进行滑窗,得到不同的人脸检测候选框。
(2)采用图像二值化的方法检测人脸框
考虑到人脸与周围像素对比度明显,本文采用图像二值化方法提取人脸区域的边缘特征,并基于该特征来剔除大量不满足条件的人脸框。传统非极大值抑制法需要计算边框的相似度和重合度才能剔除大量冗余人脸框,而图像二值化方法则利用边缘特征值便能快速、有效判别人脸框,其计算的复杂度比传统方法低。
(3)通过构建图像金字塔,实现不同尺寸大小的人脸检测
当计算机视觉感知要对一个未知的场景进行分析并识别时,并不能够提前预知要用什么样的尺度对图像的信息进行描述,唯一的方案就是将图片生成不同的尺度进行描述,以便获得未知尺度的变化。
本文对人脸框进行图像金字塔处理的目的就是对图片中小人脸框的检测。如果图片中有一个离前景较远的人脸,一般来说会在图片中显得比较小,直接采用传统的卷积方式处理很可能会忽略小人脸的检测,导致人脸检测的漏检。因此,本文采用图像金字塔的方法将上述人脸框生成不同的尺寸,使更小的人脸框都有可能被检测出来。
(4)采用级联神经网络实现人脸的识别与定位
级联神经网络主要实现人脸的分类和边框的回归,其中人脸框划分可以归结为二分类的问题,对每一个样本采用交叉熵函数来计算。边框回归是计算候选窗口与真实窗口之间的偏移量,对候选窗口进行校正。
人脸分类的公式如式(1)所示:
Li=-(yilgpi+(1-yi)(1-lgpi)) (1)
按照公式(1)将待检测的人脸与真实人脸进行相似度对比,从而确定待检测人脸是否为人脸。其中,Li表示待检测的人脸和真实人脸之间的相似度,通过衡量预测样本和真实样本的相似度来优化级联神经网络,yi表示人脸的取值标签,一般取值为0或者1。
边框回归的公式如式(2)所示:
Libox=|| y^ibox- y ibox||22 (2)
公式(2)表示将选择性搜索获取的窗口经过一定的映射关系,实现与真实窗口更接近的回归窗口。其中,Libox表示真实窗口与候选窗口的偏移量,y^ibox表示CNN网络的回归向量,yibox表示真实窗口的实际位置,一般采用四维向量表示(x1, x2, y1, y2)。
將由图像金字塔生成的不同尺寸的人脸框逐一调整成12×12的尺寸之后,输入到12-卷积神经网络中。此时采用边框回归的方法,将候选人脸框进行校正,使得预测的窗口更接近于真实窗口。与此同时,对候选窗口输出人脸预测结果。
将不同尺寸的人脸框逐一调整成24×24的尺寸之后,执行上一步的操作,进一步优化人脸框的位置,并对候选窗口输出人脸预测结果。
同理,将不同尺寸的人脸框逐一调整成48×48的尺寸之后,重复上一步的操作。对上述3种人脸预测结果,通过加权平均的方法可以获取最终的预测结果。与此同时,采用多数据对网络进行迭代训练,通过层层优化后的人脸框更加接近真实窗口,提升了人脸识别和定位的精确性。
4 实验结果与分析
4.1 数据预处理
训练融合全卷积和级联神经网络的数据在WIDER FACE公开数据上采集,本文采集其30 000张人脸进行训练,然后采集FDDB(Face Detection Data Set and Benchmark)公开数据集上的1 000张图片进行测试,其中选取了200张具有小脸的图片,以检测本文提出模型对小目标的检测能力。
训练级联神经网络时,由于不同的网络输入人脸框的尺寸不一致,因此需要对图像进行预处理。按照网络输入的要求,对图像金字塔处理后的人脸框分别调整成12×12、24×24、48×48。除此之外,还要将正样本和负样本的比例设为1:1。
4.2 与传统算法的比较
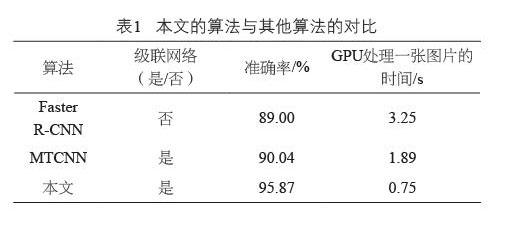
为了更直观体现本文方法的优势,本文对比了传统的Faster R-CNN和MTCNN两种人脸检测方法,本文所提出的方法在上述测试集上的准确率为95.87%,远高于Faster R-CNN和MTCNN两种方法,本文的模型具有一定的优势。与此同时,本文提出的方法的处理速度也有一定的提升。本文的算法与其他算法的对比如表1所示。
从表1的结果可以看出:本文提出的方法由于考虑到数据集中有可能存在小人脸的现象,采用了图像金字塔来实现小人脸检测,在很大程度上提升了人脸检测的准确率。虽然MTCNN也采用图像金字塔来降低小人脸漏检的问题,但是本文所提的方法将特征图进行多尺度的融合,这在一定程度上解决了定位偏差的问题,提升了模型的准确率。
表1的结果还说明本文采用的图像二值化处理方法剔除大量候选人脸框的方法能够在一定程度上提升模型的准确率。而Faster R-CNN和MTCNN则采用非极大值抑制的方法来剔除大量的冗余框,这种方法需要计算人脸框的重叠度和相似度,因此需要花费大量的计算资源,而本文采用图像二值化处理方法大大简化了大量候选框计算的复杂度,因此速度相对于传统的方法有所提升。
5 结束语
本文提出了一种融合全卷积和级联神经网络的人脸检测方法,该方法在WIDER FACE和FDDB公开数据集上均取得了良好的检测结果和运行效率。本文采用全卷积神经网络获取人脸位置区域后,采用图像二值化的方法删除大量不满足目标的人脸框,在一定程度上提升了人脸检测的速度。然后,采用图像金字塔生成不同尺寸的候选人脸框,并将其放在级联神经网络中进行训练,提升了小目标检测的准确性。采用由粗到细级联的方式不断对候选人脸框进行优化,提升了人脸框定位的精度。从本文的实验效果可知,本文提出的模型融合全卷积神经网络和级联神经网络的优点,能够快速、准确定位人脸框,在一定程度上能解决小人脸漏检的问题,具有一定的扩展性。
参考文献:
[1] 陈奎,邢雪妍,田欣沅,等. 基于CNN的人脸识别门禁系统设计[J]. 徐州工程学院学报:自然科学版, 2018,33(4): 89-92.
[2] 洪刚,秦川. 基于MT-CNN的人脸识别算法研究[J]. 工业控制计算机, 2018,31(11): 123-124.
[3] 路海. Fast R-CNN人脸检测技术浅析[J]. 信息技术与信息化, 2018(4): 17-19.
[4] 车凯,向郑涛,陈宇峰,等. 基于改进Fast R-CNN的红外图像行人检测研究[J]. 红外技术, 2018,40(6): 70-76.
[5] 董兰芳,张军挺. 基于Faster R-CNN的人脸检测方法[J]. 计算机系统应用, 2017,26(12): 262-267.
[6] 尉冰. 基于Faster R-CNN的人脸检测与识别算法研究与实现[D]. 西安: 西安电子科技大学, 2017.
[7] Kaiming H, Georgia G, Piotr D, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018: 1.
[8] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision (ICCV), 2017.
[9] Wang X, Shrivastava A, Gupta A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 3039- 3048.
[10] Jourabloo A, Liu X. Pose-Invariant Face Alignment via CNN-Based Dense 3D Model Fitting[J]. International Journal of Computer Vision, 2017,124(2): 187-203.
