一种基于LSM树的键值存储系统性能优化方法
2019-07-30王海涛李战怀赵晓南
王海涛 李战怀 张 晓 赵晓南
(西北工业大学计算机学院 西安 710129) (大数据存储与管理工业和信息化部重点实验室(西北工业大学) 西安 710129)
随着Web 2.0和云计算的快速发展,现代社会已经步入大数据时代,数据体量和访问量呈爆发式增长,传统的关系型数据库管理系统逐渐难以适应大量高并发的数据存储和访问需求[1-2].在此场景下,键值(key-value, KV)存储架构应运而生.简而言之,KV存储将一组键(key)映射到关联的值(value),用户通过GET,PUT以及DELETE等简单的接口进行操作,相对于传统的关系型数据库管理系统具有更好的性能、可伸缩性和可用性[3-4],成为了众多大数据应用系统的关键组件,广泛应用在各种数据密集型的服务系统中,例如Web索引、电子商务和云存储等.
目前流行的KV存储系统大都基于日志结构合并(log-structured merge, LSM)树[5]而不是传统的B树索引结构,如BigTable[6],Cassandra[7],HBase[8],LevelDB[9]以及RocksDB[10]等.主要原因是在众多的大数据系统中,KV存储的写入性能非常关键,而LSM树对数据的写入操作进行了优化.其基本思路是首先在内存中对写请求进行缓存和合并,然后再批量写入到存储设备中,从而将随机写操作转换为顺序写操作,提升用户写入性能.但是这种KV存储在处理频繁的小块数据更新负载时,写性能开销依旧很大.
LSM树的写性能开销主要由2部分构成:
1) 由数据压缩(compaction)操作引入的开销.数据压缩是LSM树必需的操作,其目的是保证KV数据的有序性以及进行垃圾回收,使得用户在进行查询操作的时候能够迅速定位到所需的KV数据,提高用户的读性能.数据压缩操作需要读取多个key范围有重合的数据文件,对数据进行合并排序后再写入到新的文件中,然后删除旧的数据文件.这个过程中涉及大量数据的重复写入,造成了数据的写放大,增加了性能开销.
2) 由KV存储系统的日志机制引入的性能开销.首先,KV存储通常利用预写日志(write-ahead log, WAL)来保证KV数据的可靠性,以确保在系统崩溃时能够恢复正常数据.因此,每次写入操作的数据需要首先写入WAL,然后才能写入目标文件.其次,基于LSM树的KV存储系统一般使用通用的文件系统(如Ext4)来存储数据,文件系统本身也通过自带的日志机制来保证数据一致性,因此造成了多重日志的问题,进一步增加了性能开销.此外,通用文件系统中复杂的功能和软件栈也会增加性能开销.本文中将这些性能开销统称为日志开销.对于插入密集型的小块KV负载,WAL文件的更新将非常频繁,从而导致严重的日志开销,造成KV存储系统写入性能的剧烈下降.
本文针对上述性能问题,提出了一个称为RocksFS的优化文件系统,避免了通用文件系统中复杂的功能和软件栈引入的额外负载,同时通过优化日志存储结构以及更新流程来减小日志更新引入的元数据负载,从而提升KV存储系统写性能.最终在业界广泛应用的KV存储系统RocksDB上进行了验证,结果表明相对于通用文件系统,RocksFS能够有效提高KV存储的写入和更新性能,特别是对于插入密集型的小块KV负载.
1 相关工作
基于LSM树的KV存储系统在大数据系统中应用广泛,受到了工业界和学术界的持续关注.针对这类KV存储系统的写性能问题,国内外的研究人员从不同的角度提出了一些优化方案.
WiscKey[11]基于LevelDB实现了一种新的存储机制,其核心思路是将key和value解耦并分开存储,只对key进行排序,而value则追加到独立的日志中.该机制可避免数据排序时value的移动,减小数据压缩过程中的读写放大.但是由于没有对value进行排序,因此KV数据范围检索的性能降低,且需要有垃圾回收操作来处理日志中的旧数据,引入了额外的负载.
PebblesDB[12]实现了一种基于片段的日志结构合并(fragmented log-structured merge, FLSM)树,只维持片段之间的有序性,而片段内部的不同文件之间无序,避免了KV数据压缩过程中引入的同一层数据的重写操作,从而减小了压缩操作引入的数据写放大.但是由于无法保证每一层数据完全有序,读性能以及范围检索性能有所降低.
SkipStore[13]在LSM树结构基础上实现了一个针对压缩操作优化的KV存储系统,在KV数据压缩的过程中跳过一些中间层,将相关的数据直接压缩到不相邻的组件中,从而加速数据压缩流程,减少压缩操作造成的写放大,提高KV存储系统写入性能.但是由于增加了读流程的复杂性,读取性能有所下降.
这些研究工作能够减小KV数据压缩过程中引入的写放大,从而提高写入性能.然而读性能以及范围检索性能有所损失,且忽略了本地文件系统以及多重日志引入的负载.FlashKV[14-15]在LevelDB的基础上,利用Open-Channel SSD[16-17]实现了一个由用户层直接管理闪存存储空间的KV存储系统,去除了文件系统层以及SSD内部的闪存转换层(flash translation layer, FTL)等功能有重合的层级,从而解决了多重日志的问题,但是依赖于特定的硬件设备.
总之,现有研究工作主要关注KV存储系统中的压缩负载,忽略了多重日志以及文件系统引入的负载,或者是需要特定的硬件支持来降低多重日志开销.本文主要关注在通用硬件基础上,如何减小文件系统以及多重日志的开销以提升KV存储系统的写入和更新性能.
2 研究背景和动机
本节以流行的KV存储系统RocksDB为例,简要介绍基于LSM树的KV存储系统的架构以及基本操作,分析WAL文件引入的日志开销问题.
2.1 LSM树的基本架构和操作
LSM树[3]是一种支持高效索引的数据持久性存储结构,其基本思路是通过聚合内存中的多个更新操作并将其批量刷新到存储中,从而将随机写转换为顺序写以提升写性能.图1以RocksDB为例,展示了典型的LSM树架构.RocksDB是由Facebook开源的一个典型的基于LSM树的KV存储系统,目前广泛用于Facebook等众多大数据系统中.RocksDB包含6个基本组件:memtable,immutable memtable,sstfile,WAL,Manifest和Current.其中memtable和immutable memtable常驻内存,而其他文件位于硬盘上.

Fig. 1 Typical architecture of LSM-tree[3]图1 LSM树的典型架构[3]
插入KV数据时,首先将数据追加到WAL文件中,然后将其刷新到磁盘以保证数据的持久性和安全性,之后将数据插入memtable以方便KV数据的查找与合并.memtable中的KV数据按照key的顺序进行排序,方便对最近插入的KV进行高效查找和扫描.当memtable填满时,将其转化为只读的immutable memtable,然后将其顺序写入到存储设备上的有序字符串表文件(sorted string table file, sstfile)中.Manifest和Current是辅助文件,前者存储sstfile的元数据;后者记录当前Manifest文件的名称,方便数据的检索.
RocksDB为每个Li层配置了数据量阈值,当达到阈值时将启动压缩(compaction)操作,选择该层中的部分sstfile与Li+1中key范围与之有重合的sstfile进行合并排序,然后将排序好的数据顺序写入Li+1中新的sstfile中,再删除相关的旧文件.因此memtable中包含最新的数据,然后依次是L0,L1,…层中的文件.由于L0层的数据是由内存中的memtable直接刷新到磁盘生成的,因此L0层的不同sstfile中的key可能会有重合,而L0层以外的各层是通过压缩操作生成的,具有相同key的数据已经进行了合并,因此没有重合数据.
LSM树中数据的删除操作通过插入删除标记的形式来处理,以利用插入操作的性能优势.具体而言,当需要删除某个KV数据时,LSM树首先在memtable中搜索key并为其设置删除标记以表示该KV数据已被删除.如果memtable中找不到该key,则LSM树只为该key创建索引并插入删除标记.在后续的压缩操作中,所有包含删除标记的KV数据都不会合并到新的sstfile中.通过这种方法,随机删除操作转换为顺序插入从而提高了操作性能.
LSM树的数据查找基本流程是,从内存中的memtable开始,由上到下逐层搜索,直到找到所需的key或者确定其不在系统中.与B树相比,LSM树的点查询操作可能需要多次的磁盘读操作,从而导致读取性能不高.因此,在实际中,LSM树一般应用于写密集型的场景,并利用布隆过滤器(Bloom filter)[18]等方法加速查询操作.
2.2 LSM树的日志负载
LSM树在进行写入操作时,数据首先持久化到WAL文件中,然后才可以写入指定的文件,目的是保证数据的可靠性.虽然用户可以选择在RocksDB的配置中关闭WAL,或者设置WAL为非同步,即不及时将WAL中的数据刷新入磁盘.但是,对于许多云存储系统或Web应用的数据管理系统,确保数据的可靠性通常至关重要,这意味着必须尽快将WAL同步到磁盘.因此,本文关注于WAL同步的场景.
图2展示了RocksDB中WAL的写I/O路径.一次WAL的写入会触发多个磁盘操作,因为除了WAL中新加的数据需要及时写入磁盘之外,WAL文件的元数据(主要是有效数据的大小)在每次数据更新之后都会发生变化,也必须同步到磁盘以保持文件系统的数据一致性.具体来说,当WAL写请求到达时,将执行5个步骤:①将新数据写入WAL文件;②将新数据刷新到磁盘;③将WAL文件的元数据写入到元数据文件中;④将元数据文件刷新到磁盘;⑤向用户返回WAL写入成功的消息.因此,小块KV数据的频繁更新会引入大量的WAL写操作,造成严重的性能开销.本文将这些由于WAL写入造成的性能开销称为日志开销.
具体来说,日志开销包括WAL数据写入开销及其引入的元数据更新开销.WAL是保证数据可靠性所必需的,因此无法减小其数据写入开销.但是可以通过减少元数据更新来降低日志开销.图3展示了元数据更新引入的日志开销的严重性.具体测试方法是调用RocksDB的PUT接口将具有不同value大小的KV数据(总量为256 MB)写入RocksDB,并收集WAL文件的元数据更新数据量与实际写入磁盘的数据量进行对比.
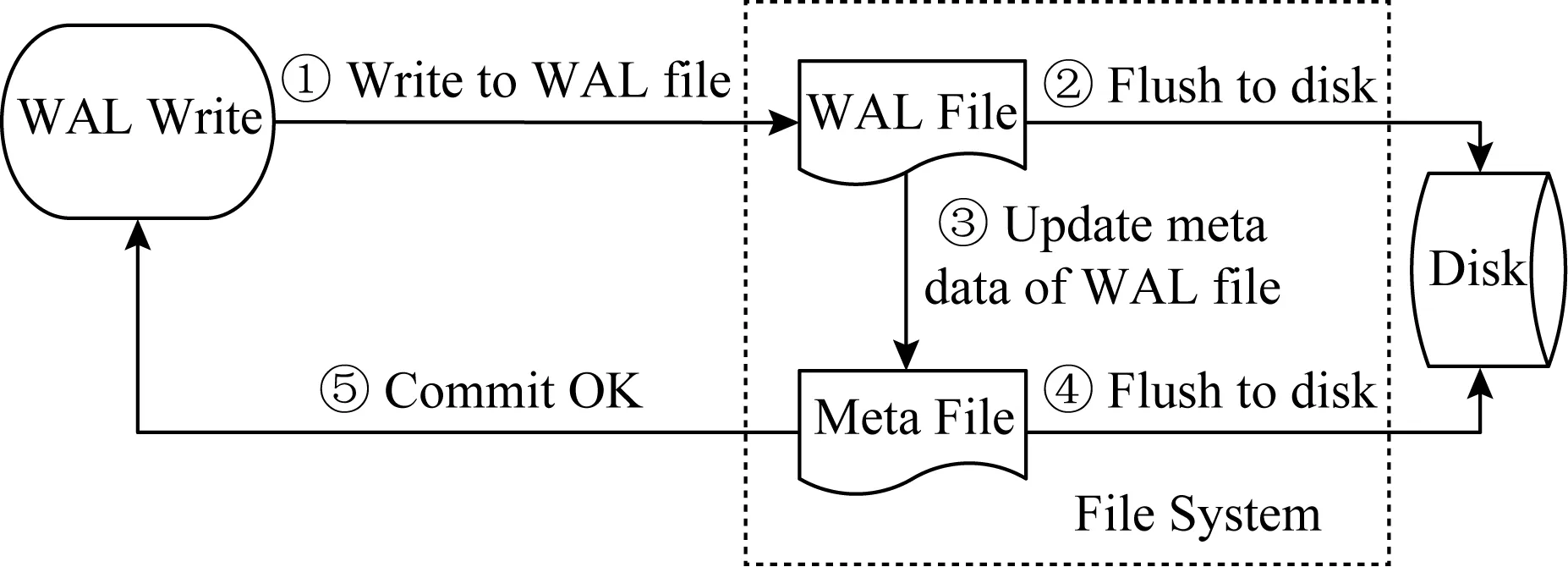
Fig. 2 Write path of WAL in RocksDB图2 RocksDB中WAL的写I/O路径
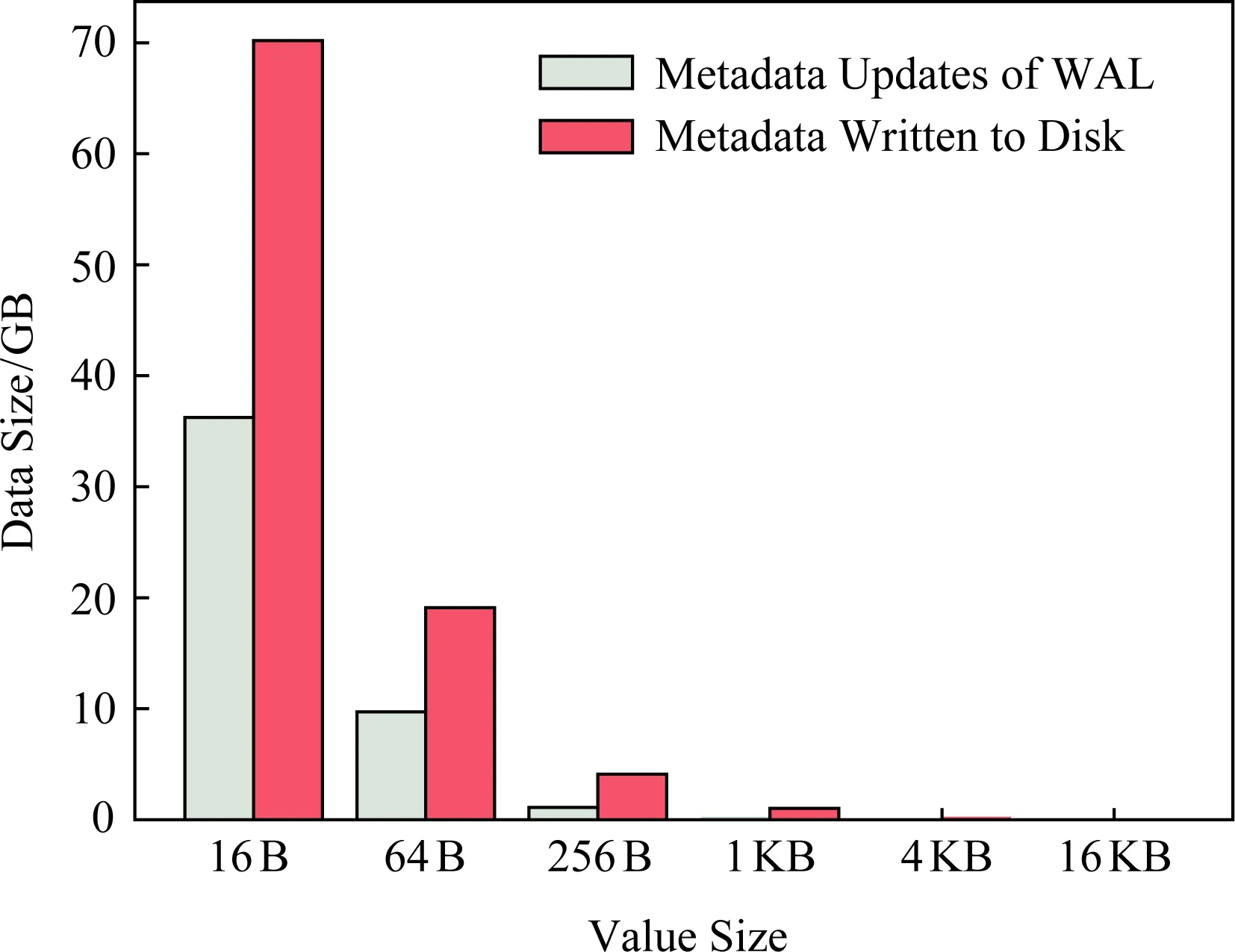
Fig. 3 Metadata overhead of WAL file图3 WAL文件元数据负载
由图3可以看到,写入磁盘的元数据量远超原始的WAL写入数据量.例如,当value大小为16 B时,数据更新造成的元数据写入量达到了35 GB,而实际写入磁盘的元数据量超过了70 GB,超过了原始的WAL写入量(256 MB)的200倍.主要原因是为了保证WAL文件的元数据及时更新到磁盘,RocksDB使用直接I/O(即写入文件时设置O_DIRECT选项)来同步元数据,每次写入都必须与块大小一致(在RocksDB中默认为4 KB),因此不足4 KB的元数据写入请求需要进行补零操作进行块对齐才能写入磁盘.因此,在小块数据频繁更新的场景下,WAL的频繁写入会造成严重的写放大,大幅降低写性能.
在通用文件系统中,上层应用无法细粒度地控制元数据更新,因而难以根据负载模式进行元数据更新流程的优化.同时,通用文件系统中的日志功能与KV存储系统中的WAL机制在功能上有重叠,造成了多重日志的问题.虽然通用文件系统中可能有一些配置选项可以关闭日志,但这样会增大当前系统中其他应用的数据安全性风险.
基于上述背景,本文提出了一个名为RocksFS的优化文件系统,针对LSM树的KV存储系统的负载模式进行优化,只保留KV负载所需的功能和接口,并重新设计WAL的存储结构和更新流程以减小元数据负载,大幅提升了小块KV数据的写入和更新性能.
3 设计与实现
本节分析RocksFS的系统架构以及WAL写入流程的优化方法.
3.1 RocksFS系统架构
如图4所示,RocksFS是一个用户库,RocksDB可通过RocksFS管理块设备,绕过复杂的通用文件系统,从而去除不必要的文件系统开销.RocksFS只有2种不同的磁盘结构(即块和文件),存储设备的第1个块是版本块(Version),用于记录此文件系统的版本信息;第2个块是超级块(Super Block),用于记录文件系统的元数据,例如设备路径和元数据文件的位置等.元数据文件(metadata file)位于超级块之后,用于记录文件系统中的其他文件的元数据.每次文件更新时,必须将相应的元数据更新写入元数据文件,并且同步到磁盘以确保数据一致性.当RocksDB挂载RocksFS时,将会加载元数据文件到内存中并重放,从而恢复RocksFS的所有元数据.RocksFS中每个文件的元数据量很小(不超过128 B),因此对于RocksFS这样的轻量级文件系统,将所有元数据缓存在内存中以提高性能是合理的.

Fig. 4 Architecture of RocksFS图4 RocksFS架构
需要注意的是,元数据文件由一块连续空间加上元数据块索引信息组成,以支持元数据文件的动态变化.索引信息常驻内存,可迅速定位到分布在硬盘其他位置的各个元数据块以保证访问性能.由于元数据块分布在硬盘的不同位置,因此一般不会造成硬盘某一位置成为热点.此外,对于目前流行的SSD来说,设备内部的闪存转化层会将上层应用的写请求分散在不同的物理位置上,并且以异地更新的方式写入新数据,同时预留空间、垃圾回收以及磨损均衡等技术放置某一物理位置的频繁擦除.因此即使上层应用对某块元数据频繁更新,对SSD的整体寿命也影响不大.

Fig. 5 Main data structures in RocksFS图5 RocksFS主要数据结构
图5展示了RocksFS中的主要数据结构.RocksFS仅支持2层目录,即目录中只有文件但没有子目录.目录映射表(dirmap)将目录名称映射到目录结构(dir),目录结构中包含此目录下的文件映射表(filemap),而文件映射表将索引节点(inode)映射到具体文件结构(file).文件结构只包含5个成员,包括1个文件节点(fnode)、1个64 b文件引用计数(refs),3个bool变量指示这个文件是否脏(dirty)、锁定(locked)或删除(deleted).fnode结构封装了文件的关键元数据,包括inode编号(ino)、数据大小(size)、修改时间(mtime)以及表示此文件磁盘空间映射表(extents).通过这些结构,RocksFS能够支持RocksDB所需的文件操作.
3.2 优化WAL存储结构
图6展示了RocksDB中的WAL文件格式.WAL文件由一系列不同长度的记录组成(即r0,r1等),每条记录中包含了一次写请求对应的数据以及校验信息,并按kBlockSize(默认32 KB)的大小进行分组,不足的空间用空(null)数据填充(即P).读写操作都以kBlockSize为单位进行.

Fig. 6 Original WAL file format in RocksDB图6 RocksDB中原始的WAL文件格式

Fig. 8 WAL write path in RocksFS图8 RocksFS中的WAL写流程
每个数据块写入WAL之后,首先将其刷新到底层磁盘,然后将元数据的更新写入元数据文件,并及时将元数据文件写入磁盘中以保证数据和元数据的一致性.通用的文件系统(如Ext4)必须在将新数据写入WAL后及时将WAL的元数据(关键是有效数据量)写入元数据文件,否则RocksDB将难以确定需要从WAL文件读取的数据量,导致无法恢复正确的数据.然而正如2.2节所述,这些频繁的元数据更新操作造成了严重的日志负载.
为了解决这个问题,RocksFS重新设计了WAL存储结构,如图7所示.将来自RocksDB的记录(即r0,r1等)封装到事务中.每个事务都有一个头字段(Head)来指示其开始,一个长度字段(Len)记录其数据量,以及一个尾部字段(Tail)包含数据校验信息并标志事务的结束.由于事务中包含了记录的长度信息以及校验信息,因此不再需要频繁地向元数据文件中更新WAL的元数据,而只需顺序读取WAL并解码数据即可恢复有效事务.RocksFS接收到上层传来的写请求之后,首先将其包装为事务,然后将数据追加到WAL中,通过优化后的WAL写入流程(见3.3节)有条件地更新元数据,能够大幅降低元数据更新频率,提升存储性能.

Fig. 7 New WAL file format in RocksFS图7 RocksFS中新的WAL格式
RocksFS中的kBlockSize参数是根据RocksDB的对应参数设置的.RocksDB使用直接I/O读写WAL,因此I/O块大小必须与磁盘块(默认4 KB)大小对齐.设置较大粒度的I/O块(如32 KB)能够提升WAL读写带宽,但是也会造成数据可靠性的粒度增大,写入失败时可能丢失的数据会增多.因此根据实际应用场景的权衡,RocksDB将其默认值设置为32 KB.由于RocksFS文件系统是根据此参数格式化创建的,因此无法动态调整该参数.并且写入性能主要取决于元数据更新负载,而kBlockSize对元数据的更新频率影响不大,实现该参数的动态调整难以提升写入性能.
3.3 优化WAL写入流程
优化后的WAL写流程如图8所示.当一批来自RocksDB的WAL文件写操作到达RocksFS时,执行4个步骤:
1) 将写请求编码到事务中.
2) 检查WAL文件的大小,确定是否可以容纳当前事务.
3) 如果WAL中有足够的空闲空间,则只需将事务追加到WAL中并将数据同步到磁盘.
4) 如果WAL中没有足够的空闲空间,为此WAL分配一块新的空间(默认为4 MB),将事务写入其中并将数据同步到磁盘,然后更新WAL文件的元数据并将其同步到磁盘.
由于RocksDB中memtable的默认大小为4 MB,因此在将memtable写入磁盘之前,系统会创建4 MB大小的WAL文件.默认配置下,这种粒度的WAL足以承载memtable的所有更新,因此无须将其设置得更大.在RocksFS中,只要WAL文件有充足的可用空间,就不需要更新其元数据,从而消除了大量的元数据更新,尤其是对于写密集型的小块KV负载.
RocksFS利用直接I/O(direct I/O)实现文件读写.通用文件系统中,使用缓存I/O(buffered I/O)一般可以提升性能,但是会造成数据在多级缓存中重复拷贝,消耗大量内存的同时也引入了额外的数据拷贝开销以及缓存一致性开销.由于RocksDB中的WAL更新需要尽快同步到磁盘以保证数据可靠性,因此在这种情况下使用直接I/O更简单有效,并且能够减小系统内存消耗.
3.4 崩溃一致性保证
为了保证RocksFS的崩溃一致性(crash consist-ency),RocksFS中提供2类恢复机制:数据恢复机制和元数据恢复机制.数据的写入通过WAL文件来保证原子性和安全性,只有在WAL写入完成后,才将更新的数据写入实际的文件.如果在文件写入过程中发生崩溃,则使用WAL文件重做写入操作以替换损坏的数据,恢复正确的数据.为了保证元数据的可靠性,元数据的更新以事务的形式同步到元数据文件,并立即将元数据文件刷新到磁盘中.如果在更新元数据的过程中发生崩溃,则在重新挂载RocksFS时,将元数据文件加载到内存中并重放其中的有效事务以恢复元数据,保持数据与元数据之间的一致性.
RocksFS基于Ceph[19]的本地存储引擎文件系统BlueFS实现,通过Ceph中自带的文件系统功能测试工具(bluefs_test)进行了完备性检查,证明了其功能的完备性.BlueFS是分布式存储系统Ceph针对RocksDB开发的简化版文件系统,用于支持其本地存储引擎的小块数据以及元数据存储.与BlueFS类似,RocksFS仅支持RocksDB所必需的操作,从而降低文件系统开销.不同之处在于,RocksFS同时优化了WAL的存储结构以及事务写入流程,大幅降低了元数据更新负载.此外,RocksFS以共享库的方式实现,可脱离RocksDB独立使用,方便其他应用程序调用.
4 实验与分析
本节在RocksDB的场景下,对比了RocksFS以及其他4个典型通用文件系统的性能,证明了RocksFS能够大幅提升小块KV数据的写入和更新性能.
4.1 实验设置
实验设置如表1所示,通过RocksDB自带的db_bench基准测试工具进行性能测试,测试的负载模式包括fillseq,fillrandom,readseq,readrandom,overwrite以及updaterandom.在配置不同文件系统的前提下,使用16个线程进行压力测试,对比RocksDB的性能.由于在典型的KV存储应用场景中,绝大部分的key大小不超过16 B,而value大小不超过1 KB[20],因此实验中设置key的大小为16 B,value的大小分别设置为16 B,64 B,256 B,1 KB,4 KB以及16 KB,这可以代表大多数场景下的KV工作负载.实验中开启了RocksDB的WAL同步选项,以测试在高数据可靠性要求场景下的KV存储性能.

Table 1 Experiment Settings表1 实验设置
由于每轮测试中value大小都是常量,因此可以使用每次基准测试的IOPS(即每秒完成的I/O操作)中位数统计值来代表各个文件系统下RocksDB的性能.每项测试中进行100万次KV数据操作,每次测试之前首先清空系统缓存,然后按顺序执行6个基准测试:
1) fillseq.随机生成key和value,并按照key的顺序插入KV数据.
2) readseq.从已有KV数据库中按照key的顺序读取value.
3) readrandom.从已有KV数据库中以随机的key序列读取value.
4) overwrite.以异步的方式,通过随机的key序列重写已有KV数据库中的value.
5) updaterandom.以读改写的方式,通过随机的key序列修改已有KV数据库中的value.
6) fillrandom.以异步的方式,通过随机的key序列向已有KV数据库中写入KV数据.
需要注意的是,在进行SSD上的性能测试时,随着写入数据量的增加,可能会触发SSD内部的垃圾回收操作,导致性能突然下降.因此,在每轮文件系统测试之前,首先擦除整个SSD,以最大限度地减小前一轮测试的影响,从而获得公平的性能.测试结果通过Ext4上的性能数据进行标准化以方便对比.
4.2 HDD上的性能对比
本节对比了HDD上采用不同文件系统后端时RocksDB在典型负载下的性能,结果如图9所示:
如图9所示,对于KV数据的写入(即fillseq和fillrandom)或者更新(即updaterandom和overwrite)负载,RocksFS的性能远高于其他文件系统,特别是对于小块的KV数据.例如,当value大小为16 B时,RocksFS的写入和更新性能比Ext4高5倍以上,比BlueFS高约1倍.主要原因是RocksFS通过优化WAL存储结构以及写入流程,大幅减小了日志开销,从而提升了KV数据的写入和更新性能.相反,通用的文件系统无法减少WAL文件更新引入的日志开销以及其他不必要的文件系统开销.而BlueFS虽然通过去除不必要的文件系统功能,减少了额外的文件系统开销,同时提高了文件读写的顺序性,但是日志开销仍然很严重.因此,在BlueFS上,RocksDB的小块KV写入和更新性能比通用文件系统高,但是比RocksFS低.

Fig. 10 Performance comparison on SSD图10 SSD上的性能对比
至于读取性能,RocksFS和BlueFS通常略低于通用文件系统.具体来说,在顺序读取KV数据(即readseq)的负载下,RocksFS的性能基本与通用文件系统持平(差距小于10%),而BlueFS的性能最多比通用文件系统低20%.主要原因是在顺序读取KV数据时,RocksDB中的memtable缓存的效果较好,大部分的KV数据可以在缓存中命中.因此虽然RocksFS以及BlueFS没有文件系统缓存,但是顺序读取KV数据的性能与通用文件系统相比差距较小,特别是在value较小(如value小于1 KB时)的情况下.在随机读取KV数据(即readrandom)的负载下,RocksFS与BlueFS的小块KV(如value小于1 KB时)随机读取性能基本与通用文件系统持平,而大块KV随机读取性能则低于通用文件系统(不超过50%).主要是因为RocksDB中设置的memtable缓存有限,因此value越小,能够缓存到的数据项越多,读取操作的缓存命中率越高.当KV数据块较大(如value大于1 KB)时,内存中的memtable不足以容纳大量的KV数据项,降低了缓存命中率.但是通用文件系统依然可通过文件系统缓存来提升读取性能,而RocksFS以及BlueFS采用直接I/O操作块设备,在文件系统级别上没有缓存机制,因此随机读取性能有所降低.
总之,与传统文件系统相比,RocksFS能够大幅提高RocksDB在HDD上的写性能,并保持小块KV数据的读性能基本不受损失,但是大块KV数据的读性能有所降低.
4.3 SSD上的性能对比
本节对比了SSD上采用不同文件系统后端时RocksDB在典型负载下的性能,图10展示了性能对比结果.每轮测试之前将整个SSD擦除以避免垃圾回收操作对后一轮测试造成的干扰.性能对比的总体结果与HDD上的结果类似.
如图10所示,RocksFS的数据写入(即fillseq和fillrandom)和更新(即updaterandom和overwrite)性能远高于其他文件系统,尤其是在KV数据块较小的场景下.例如当执行随机更新KV数据的负载(即updaterandom)且value为16 B时,RocksFS的性能可达其他文件系统的8倍.而BlueFS在写性能方面几乎没有提升.这主要是因为SSD上的随机I/O操作的性能与顺序I/O操作的性能差异很小,因此写入和更新性能的高低主要取决于日志负载的大小,而BlueFS无法减小日志负载,因此难以有效提升写入和更新性能.
至于SSD上的读取(即readseq和readrandom)性能,在value比较小(例如小于1 KB)时,RocksFS和BlueFS的读取性能与通用文件系统基本持平;而当value比较大(达到1 KB以上)时,RocksFS和BlueFS的读取性能低于(最低约50%)通用文件系统.这主要因为传统文件系统的文件系统缓存机制有助于提高读取性能,而BlueFS和RocksFS利用直接I/O读写数据,因而没有文件系统缓存机制,且RocksDB的memtable缓存有限,无法缓存大量的大块KV数据项,因此memtable的缓存命中率较低,降低了读性能.
总之,在SSD上,RocksFS作为RocksDB的后端文件系统的写入和更新性能也远高于BlueFS以及Ext4等通用文件系统,读性能基本与通用文件系统持平,大块KV数据的读性能有所降低.因此,RocksFS非常适用于插入密集型的工作负载,特别是小块的KV数据操作.
5 结果与讨论
KV存储已经成为大数据系统中的关键组件,其中基于LSM树的KV存储系统获得了广泛的应用.针对这些KV存储系统中的文件系统开销以及日志开销引入的性能下降问题,本文提出了RocksFS,一个针对LSM树优化的文件系统,去除通用文件系统中不必要的开销,并优化日志存储结构和更新流程以减少日志开销,从而提高数据写入和更新性能.实验结果表明,与通用文件系统相比,RocksFS可以将RocksDB的小块KV写入和更新性能提高8倍左右,同时保证读性能基本不受损失.
对于基于LSM树的KV存储系统,数据压缩负载也是一个重要的问题,一些现有的研究试图通过提高压缩操作的性能加快存储系统的写操作.这些工作与本文是互补的,未来的研究工作可尝试将这2种方法结合起来以进一步提高KV存储系统的性能.
