基于深度卷积生成对抗网络和拓展近邻重排序的行人重识别
2019-07-30戴臣超王洪元倪彤光陈首兵
戴臣超 王洪元 倪彤光 陈首兵
(常州大学信息科学与工程学院 江苏常州 213164)
行人重识别[1]旨在自动匹配同一个行人在不同摄像机视图下的行人图片,该任务在公共安全方面具有很大的应用潜力.因为光照、遮挡、姿势改变、背景混乱等因素,不同摄像机视图下同一个行人的图片往往有很大不同,如图1所示(同一列的图片属于同一个行人),所以该任务具有很大的挑战性,是目前计算机视觉领域的研究热点.近几年在行人重识别领域的进步主要归功于高性能的深度学习算法[2].和传统方法相比[3-6],这类算法往往需要大量标注好的行人图片.尽管目前已经发布了一些规模较大的行人重识别数据集,但是在这些数据集中每个行人的图片仍然是有限的.据统计,在Market1501数据集[7]之中平均每个行人只有17.2张图片,在CUHK03数据集[8]之中平均每个行人只有9.6张图片,在DukeMTMC-reID数据集[9]之中平均每个行人只有23.5张图片.为解决这个问题,有部分研究者试图使用其他场景下标注好的行人图片,例如Ni等人[10]提出一个迁移学习模型试图学习不同场景下行人图片的公共特征.另外一些研究者试图利用无标签行人图片,例如Xin等人[11]提出多视图聚类的方法来为无标签图片分配一个伪标签,然后在训练期间使用具有真实标签和伪标签的数据参与训练,进而提高模型的泛化性能.然而这些方法往往只在特定场合下有用,有时候甚至会导致模型性能下降.本文从另外一个角度出发,使用改进的生成对抗网络,从现有训练集中生成类似行人图片参与训练,从而引入更多的颜色、光照以及姿势变化等信息来正则化模型,提升模型的鲁棒性.

Fig. 1 Pedestrian image pairs of public datasets图1 公共数据集行人图像对
另一方面,行人重识别在本质上就是一个图片检索任务,给定一张查询图片,在对应的图库之中检索出与这张查询图片身份相同的行人图片.在这个过程之中经常会出现匹配不吻合的现象,导致行人重识别第一匹配率下降.为缓解这个问题,越来越多的研究者在行人重识别任务中加入重排序[12-15].简单来说,重排序就是重新计算查询图片与图库图片之间的距离,从而使得更多与查询图片身份一致的图库图片排在排序列表更靠前的位置.然而,目前流行的重排序方法往往需要根据每一组图片对的k近邻或者k互邻重新计算新的排序列表,这使得重排序操作复杂度极高.为了解决这个问题,本文通过引入拓展近邻距离[16]的概念,提出了一种新的重排序方法,它不需要为每组图像对重新计算新的排序列表.经实验发现,本文方法可以达到的最高Rank-1和mAP在Market-1501数据集上是89.70% 和82.86%,在CUHK03数据集上是87.60% 和87.46%,在DukeMTMC-reID数据集上是76.44%,67.59%,并成功用于2018全球(南京)人工智能应用大赛多目标跨摄像头跟踪赛题.
1 相关工作
1.1 生成对抗网络
生成对抗网络由2个子网络组成:生成网络和判别网络.在训练过程中二者相互博弈直到进入一个均衡和谐的状态.针对普通的生成对抗网络经常会面临训练不稳定、网络难以收敛以及生成图片质量太差等问题,本文采用的深度卷积生成对抗网络[17](deep convolutional generative adversarial network, DCGAN)在3个方面作出改进:1)去除掉网络中卷积层后面的全连接层,此时网络变成了全卷积网络,实验发现去掉该全连接层,网络可以收敛的更快;2)在生成网络的输入层之后作批归一化操作,使得训练过程变得更加稳定;3)使用步幅卷积来替换网络中的所有池化层,使得网络可以学习自身的空间下采样,进而生成质量更高的行人图片.
1.2 重排序
最近几年,重排序在行人重识别领域受到了越来越多的关注,Shen等人[12]使用k近邻生成新的排序列表,并且基于这些排序列表重新计算图片对之间的距离.Ye等人[13]将k近邻的全局特征与局部特征组合为一个新的查询特征,并且根据这些信息修正初始排名列表.不同于普通的k近邻,Zhong等人[14]利用k互邻来计算杰卡德距离,融合杰卡德距离与原始的欧氏距离获得更有效的排序距离.与基于k近邻和k互邻的重排序方法不同,本文引入了拓展近邻距离的概念,通过聚合每一对图片的拓展近邻距离来进行重排序(本文称之为拓展近邻重排序).
由此,本文结合DCGAN与拓展近邻重排序进行行人重识别.通过DCGAN从原始训练集中生成类似的行人图片参与训练,提高模型的泛化能力,再对初始排序表进行拓展近邻重排序操作,缓解行人匹配错误的现象,提升行人重识别的性能.
2 基于DCGAN和拓展近邻重排序的行人重识别
本文提出基于DCGAN和拓展近邻重排序的行人重识别方法,整体框架如图2所示.首先使用训练好的卷积神经网络分别提取图库图片和查询图片的特征向量,然后基于欧氏度量计算每一张图库图片和查询图片之间的距离生成初始排序表,最后利用拓展近邻重排序对初始排序表进行重排序,生成最终的排序表.本节将介绍卷积神经网络如何在训练期间引入DCGAN生成的行人图片,以及拓展近邻重排序的定义与描述.

Fig. 2 The whole framework of the method图2 本文方法的整体框架
2.1 卷积神经网络
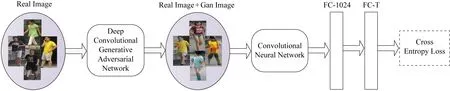
Fig. 3 Network training framework with generated image图3 结合生成图片的网络训练框架
本文采用ResNet50[1]作为基础网络结构,并且采用文献[1]中的训练策略.不同于文献[1],本文去掉了最后1 000维的分类层,并且增加了2层全连接层:第1个全连接层的输出为1024维(称为FC-1024);第2个全连接层的输出是T维(称为FC-T,其中T代表训练集中的类别数).经实验证明,添加这2层全连接层可以很有效地提升行人重识别的准确率,并且不会影响模型的收敛速度.与文献[1]采取的策略不同,本文并没有为生成图片赋予一个伪标签,而是分配了一个对现有类别都统一的标签分布.在2.2节将对生成图片标签分布的分配进行讨论.结合生成图片的网络训练框架如图3所示.首先使用DCGAN从现有训练集中生成类似的行人图片,然后将生成图片与真实图片混合在一起作为卷积神经网络的输入,最后通过最小化交叉熵损失来对网络进行调参使模型更鲁棒.
2.2 标签平滑正则化
标签平滑正则化[18](label smoothing regulari-zation, LSR)的思想就是给非真实类别赋予一个较小的值而不是0.这种策略相当于加入一些噪音数据,以防网络过于倾向真实类别.在每一个批次中都有一定数量的真实图片和生成图片,所以本文的损失函数为
LLoss=LR+LG,
(1)
其中,LR为真实图片的交叉熵损失;LG为生成图片的交叉熵损失.交叉熵损失定义为
(2)
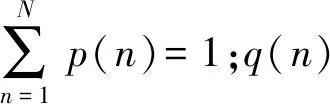
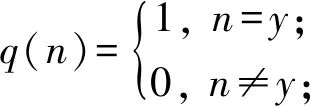
(3)
其中,y代表图片的真实标签.
在文献[18]中,通过标签平滑正则化把非真实类别的分布考虑在内,鼓励网络不要太倾向于真实类别.因此,运用标签平滑正则化策略后,图片的标签分布为
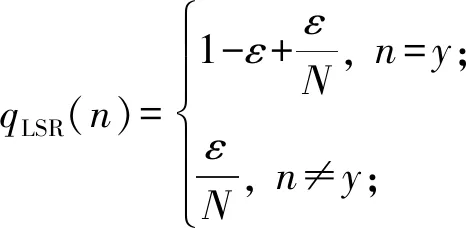
(4)
其中,ε∈[0,1].
然而,生成的行人图片不属于任意已知类别,无法为之分配一个准确的标签.不同于以往文献处理无标签图片的策略,本文提出为无标签图片分配一个虚拟的标签分布,设置其标签分布在所有已知类别上都是统一的.因此,对于生成图片,本文改进后的标签分布被定义为

(5)
此时,生成图片的标签分布为均匀分布,即默认任意一张生成图片属于任意已知类别的概率是相同的.所以,生成图片的交叉熵损失为
(6)
考虑到训练集中行人图片的内容和标签是正确匹配的,本文并没有对训练集中的真实图片进行标签平滑正则化处理,因此真实图片的交叉熵损失为
LR=-log(p(y)).
(7)
结合式(6)与式(7),本文的损失函数为

(8)
其中,β的取值为0或者1,β=0时,是真实图片的损失;当β=1时,则是生成图片的损失.虽然本文使用的生成图片质量并不高,无法为之分配一个与图片内容相符的标签,但是本文使用改进后的标签平滑正则化方法可以直接处理在样本空间中位于真实图片附近的生成图片.通过这种方式可以引入更多的颜色、光照、背景、姿势变化等信息来正则化网络模型,进而引导网络去寻找更具有判别力的特征.
2.3 拓展近邻重排序
给定一个行人图库G={gi|i=1,2,…,S}以及一张查询图片,那么查询图片与图库图片之间的距离可以用欧氏距离来计算:
d(p,gi)=(xp-xgi)T×(xp-xgi),
(9)
其中,p指的是查询图片;gi指的是图库中的第i张图片;xp指的是查询图片p的特征向量;xgi指的是图库图片gi的特征向量.
重排序就是要重新计算查询图片与图库图片之间的距离,进而生成新的排序表.给定一组图片(包括一张查询图片与一张图库图片).首先寻找2张图片对应的拓展近邻集合,然后聚合这2个集合中每一对图片之间的距离,并用聚合之后的距离(本文称之为拓展近邻距离)来代替该组图片原本的距离.查询图片的拓展近邻集合R(p,K)为
{R(p,M),R(M,N)}→R(p,K),
(10)
其中,R(p,M)是与查询图片p最相似的M张近邻图片;R(M,N)指的是与R(p,M)中每个元素最相似的N张近邻图片.同理,图库图片的拓展近邻集合计算方式也是如此.拓展近邻距离可以被定义为
从表2得知,学生的学习计划方面已经有了明显提高。但是,学生中的大部分没有及时监控学习过程、调节学习方法,在英语学习中不能熟练使用监控策略和调节策略。

(11)
其中,pj指的是查询图片的拓展近邻集合R(p,K)中的第j个近邻;gij指的是图库图片gi的扩展近邻集合R(gi,K)中的第j个近邻;d(·)是图片对之间的距离.
本文采用基于排序列表的方式来计算d(·),即根据2个排序列表前k个近邻的位置来计算2个排序列表之间的距离.虽然该方法是由Jarvis等人[16]提出的并且已经成功地运用到人脸识别任务[19]中,但是据我们所了解,该方法是首次运用到行人重识别任务中.基于排序列表的距离计算:

(12)
其中,Sp(n)表示图片n在排序列表Lp中的位置;Sgi(n)表示图片n在排序列表Lgi中的位置;×表示矩阵乘法;Lp与Lgi分别表示p与gi所对应的排序列表.[·]+=max(·,0).因为只考虑排序列表中前k张行人图片的情况,所以使用max函数将排序列表中前k张以外的图片排除在外.minmax(·)是指对(·)进行归一化处理.
3 实 验
本文在Market-1501,DukeMTMC-reID和CUHK03数据集[7-9]上进行实验,并采用累积匹配特征曲线以及平均查准率(mean average precision, mAP)来评价实验性能.累积匹配特征曲线表示查询图片出现在排序后图库列表中的概率.因为在实际应用中往往只会考虑Rank-1,即第一次就成功匹配的概率,所以本文主要关注Rank-1.
3.1 数据集
Market-1501中的行人图片收集自6个摄像机,其中包括来自于1 501个行人的32 668张标记好的行人图片.该数据集分为训练集,图库集和查询集.训练集由来自751个行人的12 936张行人图片组成,图库集则是由来自750个行人的19 732张行人图片组成.查询集合中拥有来自750个行人的3 368张查询图片.
DukeMTMC-reID是最新发布的大规模行人重识别数据集,其中有1 812个行人,一共1 404个行人出现在至少2个摄像头下,剩余408个行人仅出现在一个摄像头之下.它的训练集和测试集各包含702个人,训练集包括16 522张图片,图库集由17 661张图片组成,查询集包括2 228张图片.
3.2 实验设置
本文在Market-1501数据集上采用了Single Query和Multiple Query设置.Single Query指查询集中每个行人只有一张图片,Multiple Query指查询集中每个行人有多张图片.在CUHK03数据集上使用了single-shot和multi-shot设置.single-shot是指在图库中每个行人只有一张图片,multi-shot是指在图库中每个行人有多张图片.和本文方法进行比较的有DNS[20], Verif.-Identif.[21], SOMAnet[22], XQDA[23]等方法.DNS方法通过匹配训练数据判别零空间中的行人来克服行人重识别度量学习中的小样本问题.Verif.-Identif.方法基于验证模型和识别模型可以同时计算验证损失和识别损失,进而可以得到一个更具有判别力的卷积神经网络和相似性度量.SOMAnet则是基于深度卷积神经网络的框架,它试图通过对人体结构信息建模来缓解行人重识别的类内差异.XQDA方法首先提取特征,并提出一种度量学习方法来使类内距离变小类间距离变大.
3.3 参数分析
本文在Market1501数据集上采用控制变量法对重排序方法中的参数M与N进行测试,以期望获得最优值.首先固定住一个参数,然后通过调整另一个参数来查看Rank-1和mAP的变化.从图4中可以看出在Single Query设置下当N=8时,Rank-1和mAP达到最优值.从图5中可以看出在Single Query设置下当M=3时,Rank-1和mAP达到最优值.经实验测试,在数据集CUHK03和DukeMTMC-reID上,M=3与N=8时Rank-1和mAP也可以达到最优.因此,本文取M=3和N=8为实验参数.

Fig. 4 Influence of parameter N on Re-ID performance on Market1501 dataset图4 在Market1501数据集上参数N对行人重识别性能的影响
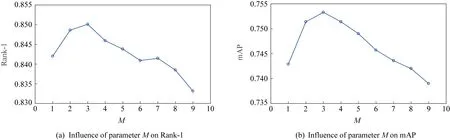
Fig. 5 Influence of parameter M on Re-ID performance on Market1501 dataset图5 在Market1501数据集上参数M对行人重识别性能的影响

Fig. 6 Generated images of CUHK03图6 CUHK03数据集的生成图片
3.4 生成图片的数量对Re-ID性能的影响

Fig. 7 Generated images of Market-1501图7 Market-1501数据集的生成图片
图6~8分别展示了以CUHK03,Market-1501和DukeMTMC-reID为训练集的生成对抗网络生成的行人图片.随着生成图片数量的增加,行人重识别的表现是否可以获得一个持续性的改进?表1展示了不同数量的生成图片参与Market-1501数据集训练的实验结果.在Market-1501数据集中训练集一共有12 936张图片.从表1中可以看出:太少的生成图片参与训练时,标签平滑正则化的正则化能力并不充分;太多的生成图片参与训练时,则会引入过多的干扰项.本文采取一个折中处理,即设置参与训练的生成图片与真实图片的比例为1∶1.

Fig. 8 Generated images of DukeMTMC-reID图8 DukeMTMC-reID数据集的生成图片

Table 1 Impact of the Number of Generated Images on Person Re-identification表1 生成图片的数量对Re-ID性能的影响
3.5 标签平滑正则化对Re-ID性能的改进
表2~5展示了本文方法在Market-1501,CUHK03和DukeMTMC-reID数据集上的实验结果.在所有表中,LSR代表在训练期间加入了生成图片,rerank代表在测试期间使用了拓展近邻重排序操作.从中可以看出:当使用生成图片参与训练时,实验效果明显超过了本文的基准方法Resnet50:在Market-1501数据上Single Query与Multiple Query情况下,Rank-1分别提升了1.22%和0.66%,mAP分别提升了0.61%和1.48%(如表2所示);在CUHK03数据集Single-shot与multi-shot情况下,Rank-1分别提升了2.97%和0.51%,mAP分别提升了2.32%和0.70%(如表3、表4所示);在DukeMTMC-reID数据上,Rank-1和mAP上分别提升了1.22%和0.64%(如表5所示).这使我们有兴趣探索使用现实生活中真实的行人图片参与训练是否也有好的效果.为了验证这一点,本文随机挑选DukeMTMC-reID数据集中12 000张真实的图片来代替Market-1501训练集中的生成图片.
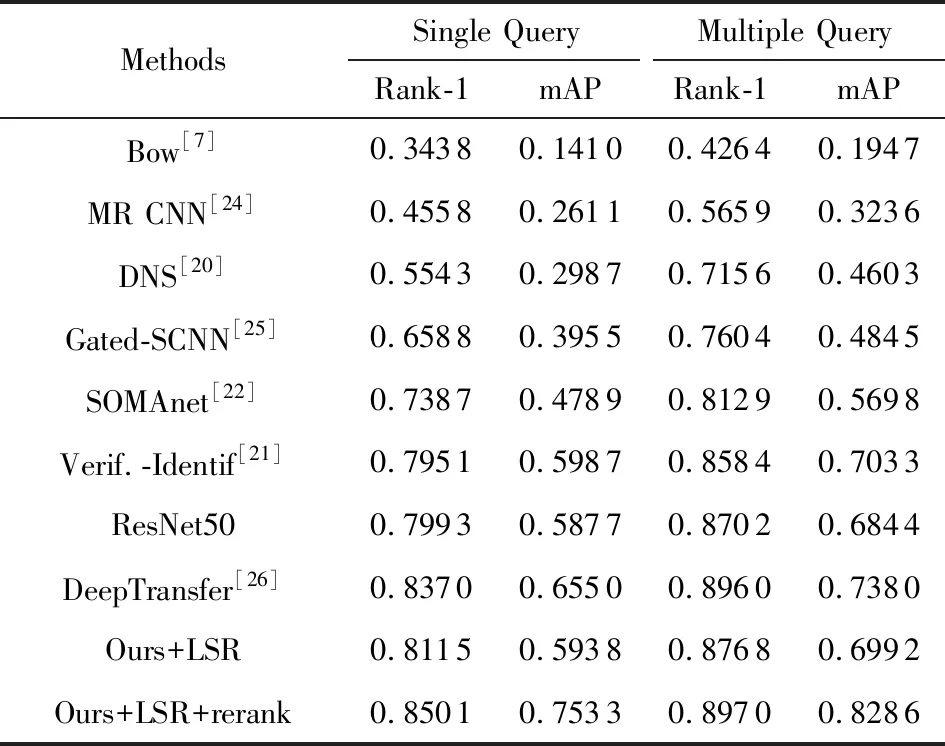
Table 2 Performance Comparison on the Market-1501 Dataset表2 在Market-1501数据集上的性能比较
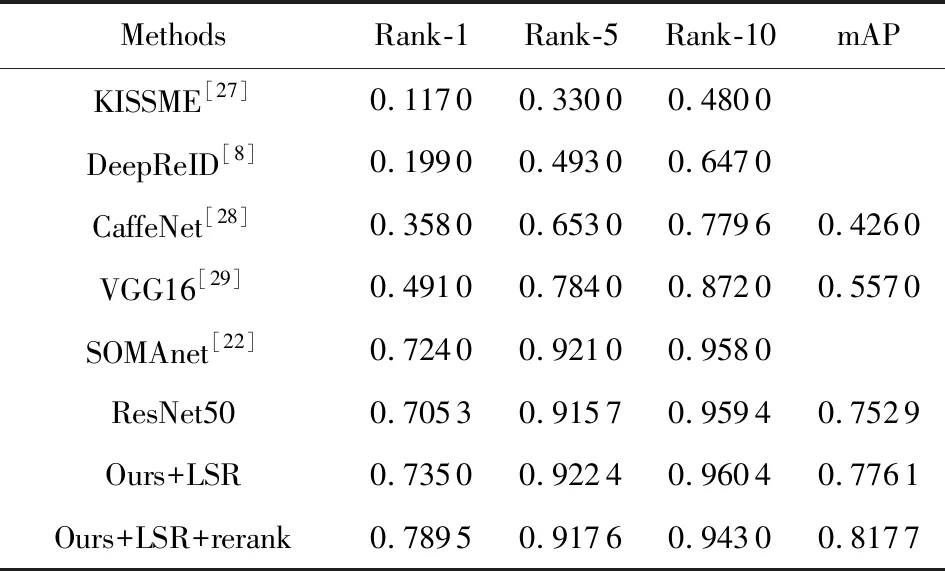
Table 3 Performance Comparison on the CUHK03 Dataset Under single-shot Setting表3 single-shot情况下多种方法在CUHK03数据集上的比较

Table 4 Performance Comparison on the CUHK03 Dataset Under multi-shot Setting表4 multi-short情况下CUHK03数据集上的性能比较
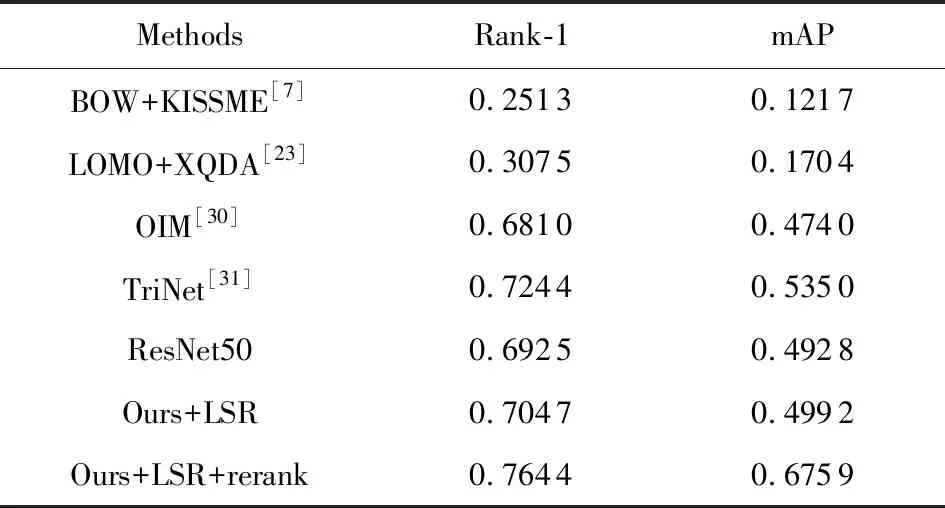
Table 5 Performance Comparison on the DukeMTMC-reID Dataset表5 DukeMTMC-reID数据集上的性能比较
从表6可以看出,加入12 000张DukeMTMC-reID数据集中的真实图片参与训练也有助于模型的正则化,改善了行人重识别的准确度,但是加入DCGAN生成的图片参与训练取得的效果更好.

Table 6 Impact of Generated Images and Real Images onPerson Re-identification表6 生成图片与真实图片对行人重识别性能的影响
3.6 拓展近邻重排序对Re-ID性能的改进
从表2~5中可以看出,拓展近邻重排序可以有效地改善行人重识别的性能:在Market-1501数据集Single Query情况下,Rank-1和mAP分别提升了3.86%和16%,Multiple Query情况下,Rank-1和mAP分别提升了2.02%和12.94%;在CUHK03数据集single-short情况下Rank-1和mAP分别提升了5.45%和4.16%,multi-short情况下Rank-1和mAP分别提升了7.52%和12.61%;在DukeMTMC-reID数据集上Rank-1和mAP分别提升了5.97%和17.67%.
本文还将拓展近邻重排序方法和目前2种流行的重排序方法相比较,这2种重排序方法分别为稀疏上下文激活重排序[15](sparse contextual activa-tion, SCA),k互邻重排序[14](k-reciprocal, k-r).SCA通过考虑上下文空间中的原始成对距离,设计一个稀疏上下文激活的特征向量来对图像进行编码.k-r则是通过k互近邻方法降低图像错误匹配情况,最后将欧氏距离和杰卡德距离加权来对排序表进行重排序.表7展示了在Market-1501,CUHK03和DukeMTMC-reID这3个数据集上拓展近邻重排序方法和其他2种先进重排序方法的实验比较结果.从表7中可以看出,本文提出的拓展近邻重排序方法无论是Rank-1指标还是mAP指标都要比上述2种重排序方法效果要好.

Table 7 Comparison of Various Reranking Methods 表7 不同重排序方法的比较
4 总 结
基于深度学习算法的行人重识别方法往往需要大量标记好的训练数据,然而标记大量的行人图片极其耗时.针对这个问题,本文使用改进的生成对抗网络DCGAN从现有训练集中生成类似行人图片参与训练,并采用标签平滑正则化方法来同时训练生成图片与真实图片.通过这种方式在训练过程中引入更多的颜色、光照、背景、姿势变化等信息,提升模型的鲁棒性.大量实验表明该方法能有效提升行人重识别性能.在此基础上,本文进一步提出了用于行人重识别的新的重排序方法——拓展近邻重排序方法.该方法根据2个排序列表前k个近邻的位置来计算2个排序列表之间的距离,无需重新计算每一对图片的排序列表,通过有说服力的实验,证明该方法比其他重排序方法有更好的性能表现,能更好地提升行人重识别性能.本文所报道的上述方法也在2018全球(南京)人工智能应用大赛多目标跨摄像头跟踪赛中得到了成功应用(荣获第2名).
