一种残差置乱上下文信息的场景图生成方法
2019-07-30徐云龙刘纯平
林 欣 田 鑫 季 怡 徐云龙 刘纯平,3
1(苏州大学计算机科学与技术学院 江苏苏州 215006)2(苏州大学应用技术学院 江苏苏州 215300)3(符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)
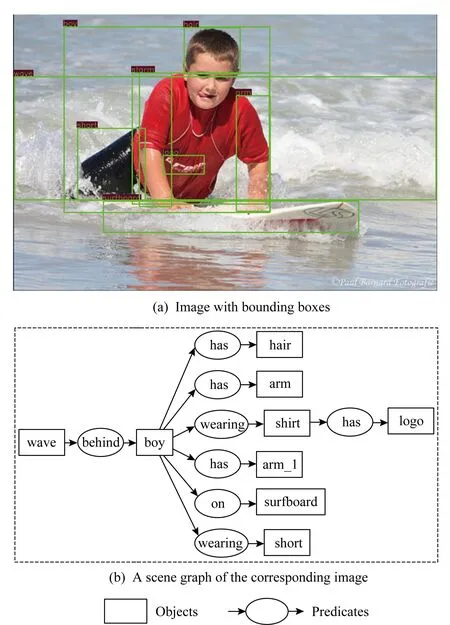
Fig. 1 A sample of a ground truth scene graph图1 场景图示意图
场景图[1]是真实图像中目标和目标间关系的精细化语义抽取,通过对预定义的目标实例、目标属性和目标对间关系进行预测来构建,常用三元组的结构化语言表示场景中目标间的交互.图1给出了一幅图像三元组关系表示的场景图实例,如boy-wearing-shirt.在场景图中,节点描述类别信息连同边界盒表示的目标实体,有向边则表示主、宾语间的关系类别.借助场景图对一幅图像可解释结构化表示的描述,图像被重构为连接图结构而不是孤立的目标实体,可以支持高层视觉智能任务,如图像检索[2]、目标检测[3-4]以及视觉问答[5-7]等视觉任务.由于手工标注海量图像的三元组关系描述格外昂贵,因此训练一个模型来自动生成高质量的场景图是近年来视觉理解的一种重要方向,再加上场景图表示需要推理复杂的依赖关系,高效准确地提取场景图也是一个极具挑战性的任务.
作为连接视觉与语言的桥梁,场景图生成任务是尽可能生成一个精确映射真实视觉场景的图表示.现有大多数基于目标的场景图方法,主要有基于目标检测和关系分类两阶段生成方法、基于目标和关系联合推理两大类.基于推理的场景图生成方法又可细分为基于消息传递[1,8-10]和全局上下文[11-12]2类.为得到更精准的目标标签,这类方法在候选场景图上进行消息传递与推理.
基于消息传递的方法中,首先提取目标区域的局部特征输入循环神经网络学习,其次使用相邻节点和边的表示来生成消息,并在图的拓扑结构中进行传递,最终获得主语、宾语和关系的最终表示结果.常见的消息传递策略包括迭代消息传递[1]、并行和串行消息传递[9]、空间加权消息传递[10]等.Xu等人[1]最早提出基于迭代消息传递的场景图生成方法IMP(iterative message passing).该方法首先通过ROI-pooling[13]从VGG-16卷积层[14]中提取目标和关系的特征,然后将视觉特征分别输入节点和边GRU(gated recurrent unit)[15]中,在之后的迭代过程中根据拓扑结构,利用相邻节点或边的隐藏状态生成消息,获取最终目标和关系表示.此外,还有一些改进的消息传递方法被提出,如并行和串行消息传递策略[9]可以更好地在目标和关系间传递信息;空间加权消息传递结构和空间敏感关系推理模块机制下的基于子图连接图[10]可有效加速推理过程和提高场景图生成效率.但是由于不完全的数据集标注,此类模型生成的消息受到局部上下文偏差的影响以及缺乏全局的视野.
基于视觉和语义特征候选场景图中节点间上下文传递下更新节点和关系表示能更加有效地学习到可靠边的位置,减少不可能边的影响.NM(neural motifs)模型[11]是最具代表性的全局上下文方法,此外还有注意力图卷积网络[12]的场景图生成方法.相对于局部上下文方法局限于关系三元组进行消息传递,全局上下文方法在全图范围内进行上下文更新,从而获取更加全面的特征表示.在NM模型中,目标候选框的特征以一个固定的顺序被输入到双向LSTM(long short-term memory)网络[16]中,从而获得图像的全局上下文,并通过连接主、宾语的全局上下文表示,实现对关系的分类.由于该类方法将原始图像中呈二维空间分布的目标排列成一个固定的从左至右的线性顺序,全局上下文信息受到破坏,使模型更倾向于学习到数据集的偏差,而不是真正的视觉关系表示,同时损失了空间信息,无法获得全面的全局上下文.
鉴于上述问题,本文以NM模型[11]为基础,提出了残差置乱上下文信息的场景图生成模型(residual shuffle sequence model, RSSQ),其主要贡献有3个方面:
1) 提出随机置乱策略,将固定顺序的隐藏状态迭代打乱重组.该策略就像纸牌游戏中的洗牌操作,可以加强目标节点和其他所有相邻节点的信息交换,提高模型的泛化能力,降低数据集偏差对场景图生成的影响.
2) 构建不同双向LSTM层之间的残差连接,获得不同层次的全局上下文信息,以形成更好的全局共享上下文表达,同时因残差的引入解决梯度消失问题.
3) 提出显式编码目标对间的位置信息嵌入,以增强场景图生成中的空间上下文,改善目标关系描述.
1 相关工作
场景图生成是近几年才发展起来的计算机视觉高级任务之一.与本文提出场景图生成方法密切相关联的工作主要有NM模型和残差连接.下面分别介绍这2个方面.
NM模型[11]是一种代表性的全局上下文方法.该模型将场景图生成分为候选目标边界盒、区域标签和关系预测3个阶段.在候选目标边界盒预测阶段,计算边界盒区域内的上下文信息并进行传递;然后将全局上下文用于预测边界盒的标签,并基于全局上下文进行边预测;最后在融合上下文边界盒区域信息的基础上给边分配标签.具体实现中首先提取候选目标的局部特征,并以候选区域中心点在原图上的位置从左至右的线性顺序将局部特征输入双向LSTM;然后用一个单向LSTM来解码目标类别,连同目标上下文输入到边上下文双向LSTM网络中;最后组合主、宾语特征,获取关系的最终表示.通过序列学习,NM模型能够学到视觉场景的强规则化信息,但是具有复杂空间分布和丰富语义信息的图像被抽象为一个固定次序线性序列的简单操作造成了重要信息损失,如场景中的空间位置信息丢失;再加上双向LSTM的强记忆能力使得NM模型更容易学习到数据集的偏差.
与本文提出场景图生成方法相关的另一个工作是残差连接.残差连接的关键思想是在网络层之间增加短路连接,提供额外的梯度路径[17].通过残差连接,非常深的卷积网络[17]被应用与图像分类和检测.残差连接在深层卷积神经网络中的应用,提高了模型的泛化能力,解决了模型的“退化”问题.最近,Kim等人[18]提出了在LSTM模型中增加残差连接的方法,并将该方法应用于远场语音识别,证明了残差连接可以提供短路,解决梯度消失问题.鉴于深度学习中,不同的网络层可以表示低/中/高不同层次的特征[19],因此,在不同层次的LSTM中建立残差连接能够更好地学习抽象视觉关系,减少梯度消失问题.NM模型在双向LSTM中使用高速连接的设计,在时间维度上解决了梯度消失问题,但是随着层数的增加,建立了高速连接的LSTM仍然存在退化问题[20],同时在空间维度上高速连接使得训练过程更加困难,残差连接解决了这个问题[18].
2 RSSQ方法
为了获取更优的关系表示以生成更精确的场景图,提出了RSSQ方法.该方法主要由目标解码模块、残差置乱模块以及位置嵌入模块3个部分组成,其整体框架如图2所示.为了简洁和方便,下文双向LSTM隐藏状态均表述为上下文信息.

Fig. 2 The framework of our Residual Shuffle Sequence Model (RSSQ)图2 残差置乱上下文信息场景图生成方法框架
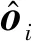
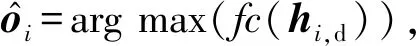
(1)
其中,fc(·)表示全连接,d表示目标解码模块.主语目标i和宾语目标j之间的谓词表示由置乱残差边上下文表示pri,j以及位置嵌入向量psi,j的最大全连接获得.谓词表示为
reli,j=arg max(fc(pri,j,psi,j)).
(2)
2.1 目标解码
目标解码阶段的主要目的是实现目标分类.该模块首先使用Faster RCNN[21]来进行目标的预分类以及目标边界盒的回归.由于Faster RCNN中,目标分类是不考虑上下文信息的.为了引入上下文信息,采用NM模型[11]中的目标上下文模块构建目标预测的上下文表示.
目标上下文信息hi,o提取是利用中心点偏移从左至右将其目标特征向量fi输入到高速双向LSTM[16]中获得,即:
hi,o=biLSTM(fi).
(3)
目标的分类向量由目标上下文信息hi,o输入目标解码LSTM获得,即:
hi,d=LSTM(hi,o).
(4)
2.2 残差置乱
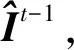

(5)

残差置乱模块的输入由目标上下文编码的隐藏状态和词向量编码2部分拼接而成:

(6)


(7)

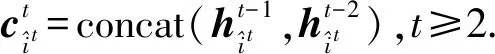
(8)
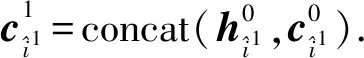

(9)
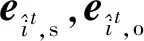
最终残差边上下文表示pri,j为
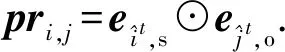
(10)
其中,⊙表示点乘运算.
2.3 位置嵌入
给定主语包围盒boxi=(xi,yi,wi,hi),宾语包围盒boxj=(xj,yj,wj,hj),主宾语间的相对几何特征PE和区域比特征Aup,位置嵌入特征psi,j则可通过一个全连接层的融合得到:
psi,j=fc(PE,Aup).
(11)
主、宾语间的相对几何特征PE是一个高维嵌入表示.为了获取平移和尺度不变的相对几何特征,对主宾语间的4维相对几何特征进行对数转换,转换后的相对几何特征为

(12)
在本文实验中,根据文献[22]的方法,通过正弦和余弦函数分别计算主、宾语间的相对几何特征PE的奇数(2m+1)和偶数(2m)维度的变换特征,将4维相对几何特征pos换为64维表示.变换公式分别为
PE(pos,2m)=sin(pos10002mdmod el),
(13)
PE(pos,2m+1)=cos(pos10002m+1dmod el).
(14)
除了相对几何位置关系,目标对间的空间关系通过目标对之间面积关系和重叠关系来进一步增强[23].文献[23]中,通过相对位置、面积、形状等描述空间分布.受到该文献启发,本文引入4维区域比特征Ai,j,并利用一个ReLu函数激活的全连接层将其转换至64维:
Aup=ReLu(fc(Ai,j)).
(15)
区域比特征Ai,j=(Vi,j,Vo,i,Vo,j,Vo.u)由1个面积比Vi,j和3个重叠比Vo,i,Vo,j,Vo.u构成:
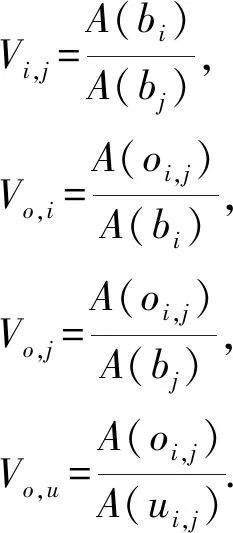
(16)
其中,A(bi)表示包围盒boxi的面积,A(oi,j)表示包围盒的重叠面积,A(ui,j)表示主宾语的外包围盒面积.
3 实验与结果分析
实验在公开数据集Visual Genome(VG)[24]上展开.为了验证提出RSSQ方法场景图生成性能,进行了模型本身的消融分析,同时进一步在关系分类、场景图分类和场景图生成3个不同层次子任务上进行方法性能的评价.
3.1 数据集及评价指标
Visual Genome数据集是一个人工标注的视觉关系数据集.根据不同的数据预处理方式和数据划分方法,存在多种不同的版本[8,11-12,25].在实验中,使用最普遍使用的数据预处理和数据集划分方法[1],其中训练集和测试集分别有75 651图像和32 422图像.保留了最常见的150类目标以及50类关系,每张图像平均有11.5个目标和6.2个关系.
场景图生成任务的目的是定位预定义的目标以及预测目标对间的关系.整个任务被分成3个子任务:
1) 关系分类任务(predicate classification, PredCls).给定真实目标框以及真实标签,需要预测目标对间关系;
2) 场景图分类任务(scene graph classification, SGCls).给定真实的目标边界盒,需要预测目标标签和目标对间关系;
3) 场景图生成任务(scene graph generation, SGGen).给定一张图像,需要检测其中的目标和关系.
实验评价指标采用Recall@K,缩写为R@K,是置信度最高的K个分类结果在关系真值中所占比例.本文根据在Visual Genome数据集中证明结论:随机生成一个三元组关系Recall@100约为0.000 089[24],在实验中将K取值为50和100.
3.2 RSSQ方法整体定量分析
实验中,以场景图中3个子任务为目标,将RSSQ方法与一些现存模型进行对比,包括Language Priors(LP)模型[26]、IMP模型[1]、Graph R-CNN(GR)模型[12]以及NM模型[11].实验结果如表1所示:
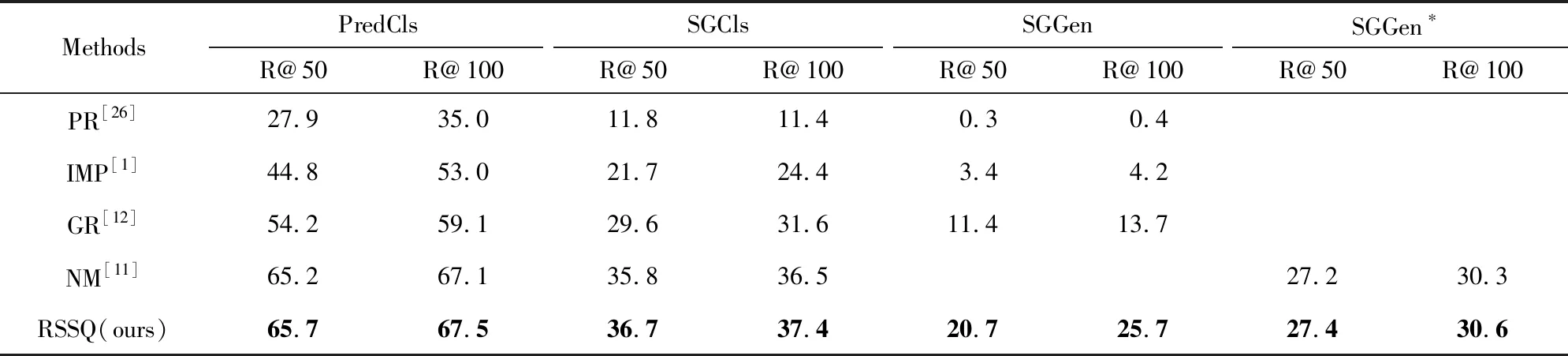
Table 1 Comparison with Some Existing Works表1 RSSQ方法与现有方法对比实验结果
IMP模型[1]主要针对局部关系上下文进行建模,丢失了全局上下文的视野.GR模型[12]使用特定线性变换方法根据相邻节点进行节点表示更新,但是更新的策略相对简单.NM模型[11]通过双向LSTM网络生成边上下文,丢失了结构化信息.从表1中可以看出,提出的RSSQ方法在3个子任务中都超过了现有方法.相对于2018年CVPR的NM模型,在子任务SGCls上超过0.9%,在PredCls子任务上超过0.5%.在SGGen子任务上,提出方法超过GR模型12%.这表明提出RSSQ方法可以更加有效地生成场景图.
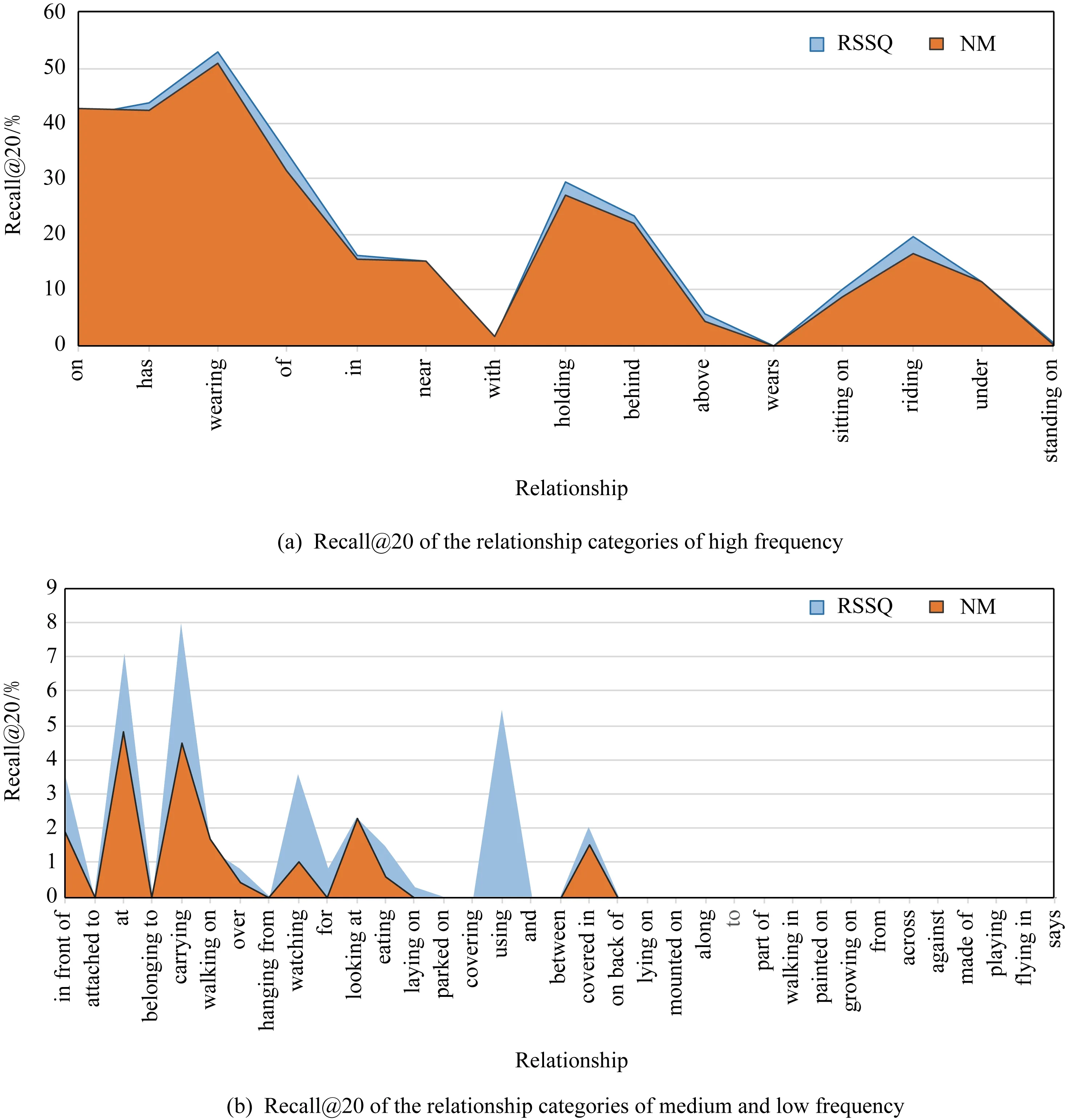
Fig. 3 The accuracy of each relationship categories of SGCls of R@20 setting图3 关系分类逐类分析
为了更进一步精确地对比提出地RSSQ方法和NM模型在分类性能上的改进.图3给出了在SGCls子任务中Recall@20设置上进行的关系分类准确率统计分析.横坐标上关系类别以出现频率的降序排列,只有在关系三元组全部被预测正确,包括主宾语和关系,才会被统计.图3给出了根据频率将关系分为高频(a)、中低频(b)2个部分区段的实验对比.在高频段(图3(a)),NM模型和RSSQ方法对关系频率高的分类均表现良好,在部分关系类别中,提出的RSSQ方法相对于NM模型有微弱提升.
在中频区域(如图3(b)所示),NM模型的分类准确率较低,这是因为NM模型学到更多的数据集偏差而并非真正理解关系.提出的RSSQ方法在这个区间的关系分类精度有相对大的提升,比如of,holding,behind,above,riding,at,carrying,using以及covered in关系类别.受益于更好的全局上下文特征,提出的RSSQ方法在抽象关系分类精度方面有较明显提升,如holding(+2.36%)、riding(+4.76%)、carrying(+9.75%)以及using(+6.79).基于位置嵌入对位置信息的增强,提出的RSSQ方法对位置关系分类精度也有较大提升,如of(+2.43%)、behind(+1.12%)、above(+1.55%)、at(+2.14%)以及covered in(+2.55%).在低频段的分类识别,2个模型均没什么表现,这就需要更多研究,比如少量学习[27].
总之,由于Visual Genome是一个严重不均衡的数据集,使大多模型更容易学习数据集偏差.提出的RSSQ方法在中等频率区间性能的明显提升,表明提出的RSSQ方法更少地受数据集偏差的影响,在一定程度上较好地改善了数据偏差对关系分类的影响.
3.3 残差置乱模块评价
基于NM模型[10]中4层LSTM层组成的边上下文模块(如图4(a)所示),本文通过置乱模块和残差连接基本架构单元来构成残差置乱模块.通过对图4(a)分别插入1,2,4次置乱层和残差连接构成3种残差置乱模块结构e1,e2和e4,如图4(b)~4(d)所示.

Fig. 4 The initial edge context module in NM[10] and structures of residual shuffle module insertion图4 残差置乱模块示意图
由于NM模型[10]没有给出未经微调的SGGen子任务的实验结果,残差置换模块的实验分析在PredCls和SGCls两个子任务上进行.此外,也进行了LSTM层之间的原始设置以及残差连接2种不同连接方式的实验.如表2所示,通过置乱操作,在SGCls任务中有0.3%相对提升;通过残差连接,在PredCls子任务和SGCls子任务分别有0.5%和0.7%的相对提升.在单纯加入置乱操作的设置中,PredCls子任务中有些许性能下降,这是由于PredCls使用目标标签真值,置乱破坏了关系的固定模式.从实验结果来看,置乱操作不断地打乱目标序列输入次序,在训练迭代过程中,即使是同一条训练数据也会有不同的输入次序,增加了模型的鲁棒性,提高了模型的泛化能力.残差连接融合了不同层次的边上下文,在不同LSTM层间建立短路,从而减少梯度消失问题,获取了更丰富语义的边上下文.

Table 2 Evaluation of the Residual Shuffle Module表2 残差置乱模块分析
Note: “raw” means regular connection of LSTM layers, and “res” means residual connection.
3.4 消融实验
为进一步分析提出的RSSQ方法中残差置乱和位置嵌入2个模块对场景图生成的性能影响,表3给出了在3个子任务上的消融学习结果.这部分实验以NM模型为基准模型,单纯用残差置乱模块替换NM模型中的边上下文提取模块,在PredCls子任务和SGCls子任务中分别有0.5%和0.7% 的提升.单纯将位置嵌入模块添加到NM模型的边上下文模块中,在PredCls子任务和SGCls子任务中有些许提升.在SGGen子任务的实验中,位置嵌入模块与NM模型的结合是残差置换与NM模型结合,是提出RSSQ方法中性能表现最好的组合.提出的RSSQ方法在2个子任务PredCls和SGCls是表现最好的.综上分析,残差置乱和位置嵌入2个模块部分缓解了数据集偏差和全局上下文共享问题,完整的RSSQ方法在3个子任务中的综合表现良好.

Table 3 Ablation Study表3 消融实验结果
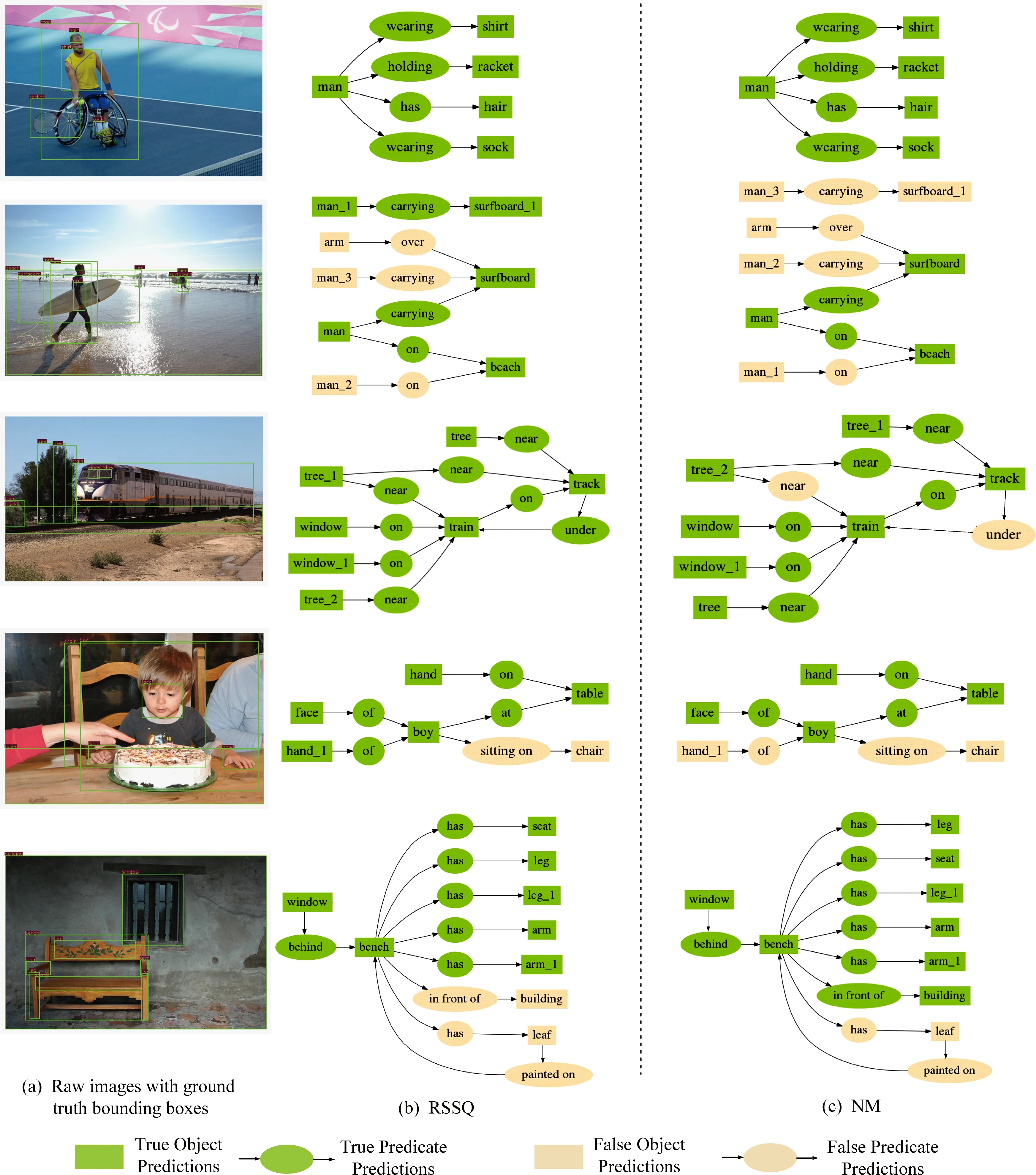
Fig. 5 Qualitative results of SGCls图5 场景图分类结果可视化结果
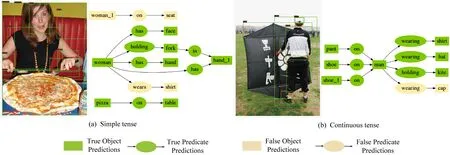
Fig. 6 Errors caused by tense disagreements图6 时态不一致引起的错误示例
3.5 部分场景图可视化结果
为了更直观展示提出的RSSQ方法在场景图生成的效果,图5、图6给出了场景图可视化结果.其中图像中给出的是真值标签的边界盒,场景图给出了SGCls子任务中生成场景图和真值场景图的对比,方框表示目标实体,有向箭头从主语指向宾语,椭圆形表示关系.每个给出的具体样例中的完整场景图是真值描述的场景图,其中深色底纹表示正确预测,浅色底纹表示错误预测.图5(a)是原始带有目标真值标签的原始图像,图5(b)给出的是RSSQ方法生成的场景图,图5(c)是NM模型[10]生成的场景图.
图6给出了由于谓词的时态不一致性带来的关系分类错误,如图6(a)中wears和图6(b)中的wearing.从图5第1行样例可以看出,RSSQ方法和NM模型[10]均能比较吻合地生成比较简单的场景图.从图5第3行与第5行样例可以看出,RSSQ方法相对于NM模型[10]改进了相对位置关系(near,under,in front of)的分类.从图5第2行与第5行样例可以看出,RSSQ方法在中频区间的关系类别(carrying,in front of)有一定改进,缓解了数据集偏差问题.图5第4行样例说明,RSSQ方法对于高频区间的关系分类(如of)也有改进.
4 总 结
鉴于场景图生成方法更多的学习数据集偏差,本文从残差置乱和位置嵌入角度改进NM模型,提出了一个新的基于残差置乱上下文信息的场景图生成方法(RSSQ).置乱策略有效地改善了数据集偏差对场景图生成的影响,尤其是在中频段的关系分类性能的提升比较明显;残差连接在不同LSTM层之间建立短路连接,完成不同层次的信息交换,较好解决了全局上下文信息共享,此外,残差连接还解决了梯度消失问题.位置嵌入从面积比和重叠比角度整合目标位置信息,也有效地提升了提出的RSSQ方法对位置关系分类的性能.在Visual Genome数据集的实验中验证了提出的RSSQ方法可行且高效,可以更少地受到数据集偏差的影响.
