逆概率加权多重插补法在中国居民收入影响因素中的应用研究
2019-07-27程豪
程 豪
(中国科协创新战略研究院,北京 100863)
一、引言
众所周知,线性回归理论广泛应用于统计学及其交叉领域。但是,该理论需要满足较为严苛的高斯假设条件,且仅体现平均数水平,无法全面刻画因变量在各分位点随自变量的变化趋势。相比之下,分位回归可以处理研究对象异质性问题,展示数据全貌,有较好的稳健性,不要求分布形式。而数据的缺失问题普遍存在,如果处理不当,则会得出错误的分析结果和研究结论,导致预测与决策的严重偏差。
通常,分位回归中的缺失问题包括因变量缺失和自变量缺失两类。由于分位回归不存在似然函数,目前很多基于似然的处理方法无法直接使用。因此,国内外以分位回归为模型基础,探索自变量缺失问题仍存在较大的研究空间。
综上,本文以分位回归中自变量缺失与因变量有关为选题,旨在通过逆概率加权(Inverse Probability Weighting, IPW)修正现有的多重插补法,提供追溯缺失数据、挖掘丢失信息的方法支持,探讨中国居民收入影响因素的实际问题。
二、文献综述
分位回归自1978年提出以来,成为一种理论探讨和方法应用领域颇具前景的分析工具[1]。数据缺失现象普遍存在,一直是备受关注的研究课题。
Hendricks和Koenker利用分位回归研究了家庭日常用电量与天气特征之间的关系[2]。Konenker和Machado关注分位数曲线的数据拟合程度评价问题[3]。Bassett和Chen讨论了金融市场中多时期的收益问题[4]。Wei等提出了半参数的分位数模型,并用它建立生长曲线图[5]。李育安对分位回归及应用进行简单介绍[6]。Terry等用分位回归研究肥胖问题[7]。Wei首次提出了对多元条件分位数的估计[8]。陈建宝等利用分位回归对中国居民收入和消费进行了实证分析,但未讨论缺失数据问题[9]。梅波和田茂再讨论了贝叶斯时空分位回归模型,并用其对北京市PM2.5浓度进行研究[10]。
截止目前,缺失插补方法领域中大多数情况是完全随机缺失机制下的完整资料分析法、条件均值插补和基于似然的插补方法[11]。完整资料分析法是一种最简单的缺失数据分析方法。但它功效较低,且导致有偏估计[12]。同样地,条件均值插补也会带来有偏估计,因此这些方法不再适用[13]。此时,考虑使用逆概率加权法,在满足一定分布假定下,基于逆概率加权的估计方程的半参数估计量是有效的、稳健的,因此广受好评[14]。Yi和He对Robins等提出的逆概率加权广义估计方程进行了拓展,用逆概率加权来修正估计偏差[15-16]。Lipsitz等用逆概率加权方法处理了纵向数据缺失问题[17]。但与完整资料分析法类似,逆概率加权法仅仅利用可观测的完整数据信息,造成有效信息的损失。此外,它还会影响估计量的有效性,带来较大的估计方差。
Wei等提出分位回归中的多重插补方法,并在此基础上通过构造压缩估计量调整估计偏差[18]。但是,分位回归中的多重插补法适用于自变量随机缺失与因变量无关的情况,当自变量随机缺失与因变量有关时,估计偏差较大。因此,多重插补法有待进一步讨论和修正。
三、方法依据及原理
(一)现有多重插补法的局限
对于分位回归,缺失插补方法需要解决两个问题:一是得到x的完整分布,即通过x的条件密度函数f(x|y,z)生成缺失数据的插补值;二是保证或改善估计量的统计性质,即在减少估计偏差的同时,有效控制估计方差。
Wei(2012)提出的自变量随机缺失机制下的多重插补方法,解决了分位回归的缺失问题,但该方法适用于自变量缺失与因变量无关的情形,当自变量缺失与因变量有关时,该多重插补方法与现有的完整资料分析法一样,都会带来较大的估计偏差。
为了解释多重插补法在自变量缺失与因变量有关时产生估计偏差的原因,令δi是缺失数据的示性变量。对于完整资料分析法,需要求解如下估计方程:
∑S[yi,xi,zi,β]*δi=0
(1)
为了得到有效的估计,估计方程的形式为:
E{S[yi,xi,zi,β0]*δi|xi,zi}=0
(2)
其中,β0是参数真值。
当自变量缺失与因变量无关时,即δi与yi无关时,
E{S[yi,xi,zi,β]*δi}
=E{S[yi,xi,zi,β]|xi,zi}*E{δi}
(3)
因此,E{S[yi,xi,zi,β0]}=0。
但是当自变量缺失与因变量有关时,即δi与yi有关时,
E{S[yi,xi,zi,β]*δi}
≠E{S[yi,xi,zi,β]|xi,zi}*E{δi}
(4)
因此,E{S[yi,xi,zi,β0]}≠0。此时,自变量缺失与因变量有关,多重插补法的参数估计结果不是无偏估计。
(二)选择逆概率加权的原因
当自变量缺失与因变量有关时,缺失的数据部分与可完整观测的数据部分之间会存在系统差异,如果直接利用可观测的数据信息,依次推断缺失数据,一定会产生推断结果与真实结果间的差异。换言之,现有的可完整观测的数据点并不能代表总体的分布特征。如果执意将现有的每条完整的数据记录以相同的概率纳入分析(通常默认为1),那么可观测的完整数据部分就是总体的一个有偏样本,估计结果当然也是有偏的。因此,需要对自变量缺失与因变量有关时的每一条可完整观测的数据记录赋予不同的概率,用以平衡现有可完整观测数据代表总体数据分布的偏差。
作为一种减少偏差的修正方法,逆概率加权法最早由Horvitz和Thompson提出,即对每个可观测的yi的概率取倒数,作为被观测的yi的权重,修正由缺失数据或有偏抽样带来的估计偏差。
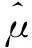
(5)
=E{y}>=μ
(6)
可见,利用逆概率加权,总体均值的估计方程一定为无偏估计方程。因此,当自变量缺失与因变量有关时,逆概率加权使得多重插补法的估计方程为无偏估计方程,从而估计出无偏差的估计结果。
(三)用逆概率加权修正多重插补法的原理
作为现有多重插补法的核心内容之一,求得x中缺失部分的插补值需要完成概率密度函数f(x|y,z)的估计,即通过f{y|x,z;β0(τ)}和f{x|z;η(τ)}两部分完成估计,其中,β0(τ)和η(τ)是两个真实的分位系数过程。这是因为,
f(x│y,z)=(f(x,y│z))/(f(y│z))
=f(x|z)f(y|x,z)/f(y│z)
(7)
为了完成逆概率加权对样本的修正,β0(τ)和η(τ)的估计值一定是逆概率加权以后的参数估计结果。此外,在完成缺失插补后,逆概率加权多重插补法的分位回归估计量也是逆概率加权的结果。
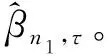



(8)

四、模拟研究
(一)基本设定
假定生成模拟数据的基础模型为:
yi=1+xi+zi+(0.5xi+0.5zi)ei
(9)
该模型服从如下假定:
1)自变量向量(xi,zi)服从均值为(4,4)T,方差为(1,1)T的联合正态分布。
2)自变量缺失比例控制在20%左右,缺失概率定义为:P(xi缺失|yi)=1/(1+exp(a+bzi+cyi))。其中,a,b,c为参数。
3)自变量缺失与因变量有关。通过定义缺失相关参数(上式中的c),分别设定c=0.3,0.6,0.9三种情况,表示自变量缺失与因变量有关的不同程度。
4)残差ei的分布包括两种假定:标准正态分布和卡方分布。
此外,模拟过程中包括逆概率加权法(IPW),多重插补法(MI),基于观测概率真值的多重插补法(MI0),逆概率加权多重插补方法(MI1)四种方法(令MI,MI1,MI0中的m=10)。模拟过程的Monte-Carlo次数为200,样本量为1 000。
根据上述假定,设置如下模拟情形:
情形1:缺失相关参数为0.3。
情形1-1:缺失相关参数为0.3,残差ei服从标准正态分布。
情形1-2:缺失相关参数为0.3,残差ei服从卡方分布。
情形2:缺失相关参数为0.6。
情形2-1:缺失相关参数为0.6,残差ei服从标准正态分布。
情形2-2:缺失相关参数为0.6,残差ei服从卡方分布。
情形3:缺失相关参数为0.9。
情形3-1:缺失相关参数为0.9,残差ei服从标准正态分布。
情形3-2:缺失相关参数为0.9,残差ei服从卡方分布。
(二)模拟结果
1.情形1:缺失相关参数为0.3
以逆概率加权法(IPW),多重插补法(MI),基于观测概率真值的多重插补法(MI0)三种方法为参照,运行200次Monte-Carlo模拟,实现对逆概率加权多重插补方法(MI1)估计结果的比较研究。表1为缺失相关参数为0.3时不同分位数下参数估计结果(截距相关估计结果已省略),即对200次Monte-Carlo模拟估计结果取均值、标准差和均方误差。
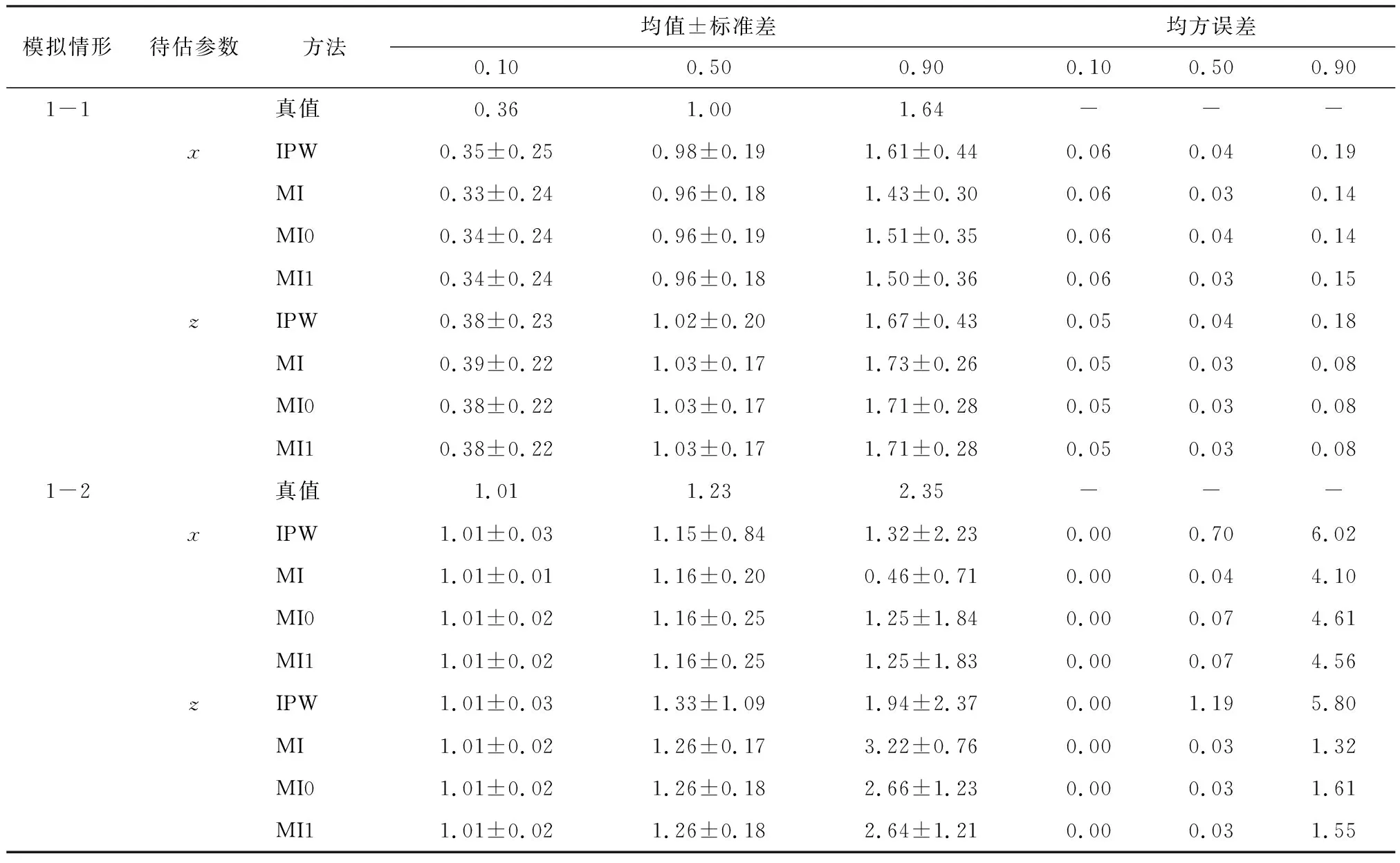
表1 缺失相关参数为0.3时不同分位数下参数估计结果(N=1 000)
由表1中关于x和z的估计结果可知,当残差服从正态分布时,有如下发现:1)MI在各分位水平下的估计均值与真值间的差距均为最大,IPW在各分位水平下的估计均值与真值间的差距均为最小。尽管在中分位水平下,MI、MI0和MI1的估计均值与真值间的差距相同,但在低分位水平和高分位水平下,MI0和MI1的估计均值与真值间的差距均小于同等条件下的MI,略大于或等于同等条件下的IPW。2)与其他方法相比,IPW在无偏性上具有明显的优势。但是,它在有效性和估计精度方面的表现最差。即无论在何种分位水平下,IPW的估计标准差和均方误差均达到最大值。在高分位水平时表现的尤为明显。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
当残差服从卡方分布时,关于x和z的估计结果所揭示的规律有所不同。1)四种方法在低分位水平下的估计均值与真值间的差距相同,IPW在中分位水平下的估计均值与真值间的差距均为最大,其余三种方法在中分位水平下的估计均值与真值间的差距均为相同。在高分位水平下,MI的估计均值与真值间的差距最大,x的系数估计结果中IPW的估计均值与真值间的差距最小,z的系数估计结果中MI1的估计均值与真值间的差距最小。2)与残差服从正态分布时一致的是,无论在何种分位水平下,IPW的估计标准差和估计精度均达到最大值。在中分位水平和高分位水平时表现的尤为明显。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
2.情形2:缺失相关参数为0.6
除缺失相关参数外,其余模拟背景相同。表2是缺失相关参数为0.6时不同分位数下参数估计结果(截距相关估计结果省略),即对200次Monte-Carlo模拟估计结果取均值、标准差和均方误差。由表2中关于x和z的估计结果可知,当残差服从正态分布时,有如下发现:1)MI在各分位水平下的估计均值与真值间的差距几乎均为最大,IPW在各分位水平下的估计均值与真值间的差距均为最小。尽管在低分位水平下,MI,MI0和MI1的估计均值与真值间的差距相同,但在高分位水平下,MI0和MI1的估计均值与真值间的差距均小于同等条件下的MI,略大于或等于同等条件下的IPW。2)与其他方法相比,IPW在无偏性上具有明显的优势。但是,它在有效性和估计精度方面的表现最差。即无论在何种分位水平下,IPW的估计标准差和均方误差均达到最大值。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
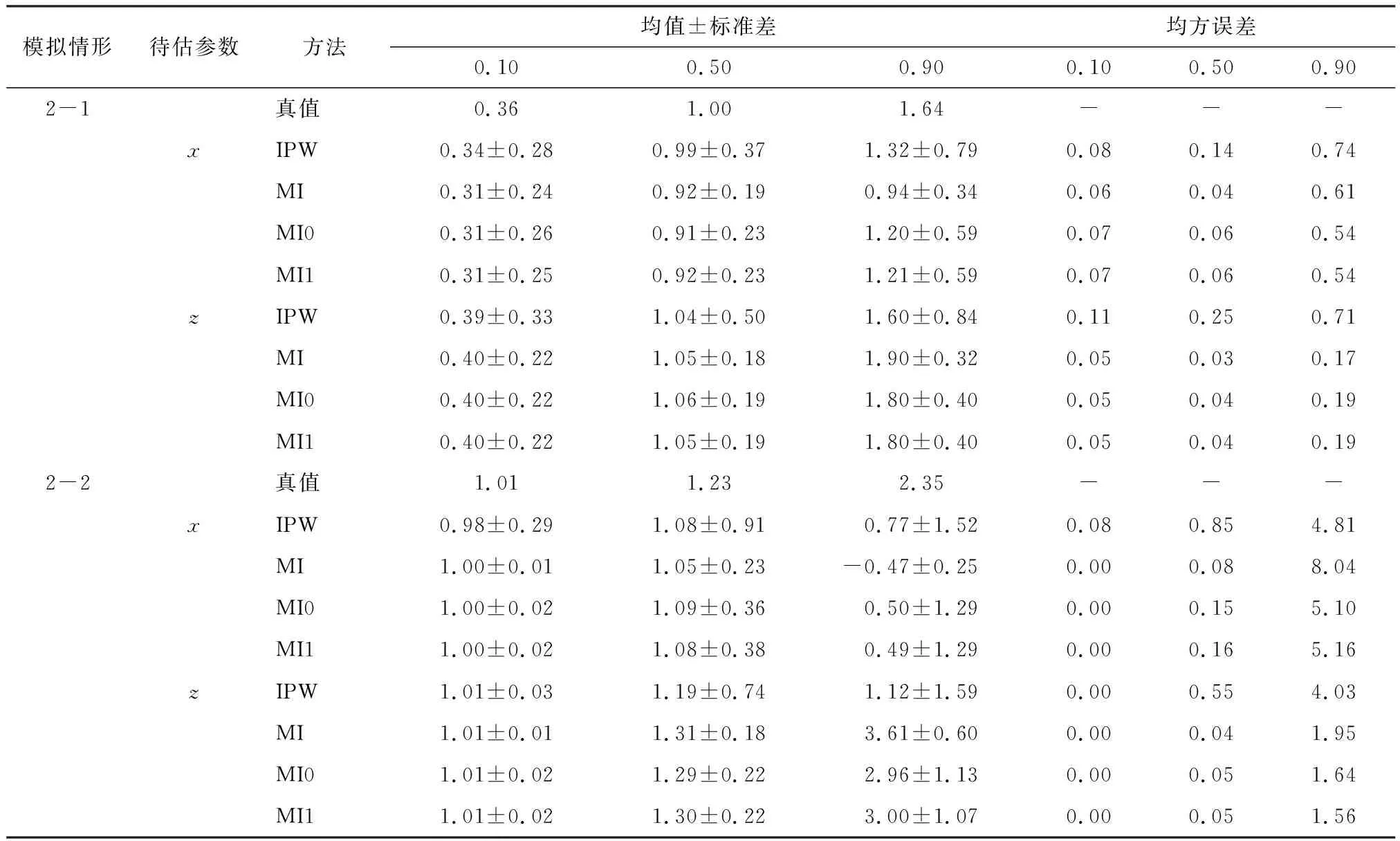
表2 缺失相关参数为0.6时不同分位数下参数估计结果(N=1 000)
当残差服从卡方分布时,关于x和z的估计结果所揭示的规律有所不同。1)MI,MI0和MI1三种方法在低分位水平下的估计均值与真值间的差距相同,MI在中分位水平和中分位水平下的估计均值与真值间的差距均为最大。在高分位水平下,四种方法的估计均值与真值间均存在较明显的差距,x的系数估计结果中IPW的估计均值与真值间的差距最小,z的系数估计结果中MI0的估计均值与真值间的差距最小。2)无论在何种分位水平下,IPW的估计标准差和估计精度几乎均达到最大值(除高分位水平下x系数的均方误差达到最大外)。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
3.情形2:缺失相关参数为0.9
表3是缺失相关参数为0.9时不同分位数下参数估计结果(截距相关估计结果已省略),即对200次Monte-Carlo模拟估计结果取均值、标准差和均方误差。
由表3中关于x和z的估计结果可知,当残差服从正态分布时,有如下发现:1)MI在各分位水平下的估计均值与真值间的差距几乎均为最大,IPW在各分位水平下x系数的估计均值与真值间的差距均为最小。在低分位水平和高分位水平下,MI0和MI1在x系数的估计均值与真值间的差距均小于同等条件下的MI,略大于或等于同等条件下的IPW。而MI0和MI1在z系数的估计均值与真值间的差距均最小。2)与其他方法相比,IPW在有效性和估计精度方面的表现最差。除高分位水平下x系数中MI均方误差达到最大值以外,IPW的估计标准差和均方误差均达到最大值。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
当残差服从卡方分布时,关于x和z的估计结果所揭示的规律有所不同。1)MI、MI0、MI1三种方法在低分位水平下的估计均值与真值间的差距相同,MI在中分位水平下的估计均值与真值间的差距均为最大。在高分位水平下,IPW和MI的估计均值与真值间的差距最大,x的系数估计结果中IPW的估计均值与真值间的差距最小,z的系数估计结果中MI1的估计均值与真值间的差距最小。2)除高分位水平下x系数中MI均方误差达到最大值以外,IPW的估计标准差和估计精度均达到最大值。3)MI0和MI1在无偏性、有效性和估计精度上的估计结果均颇为近似。
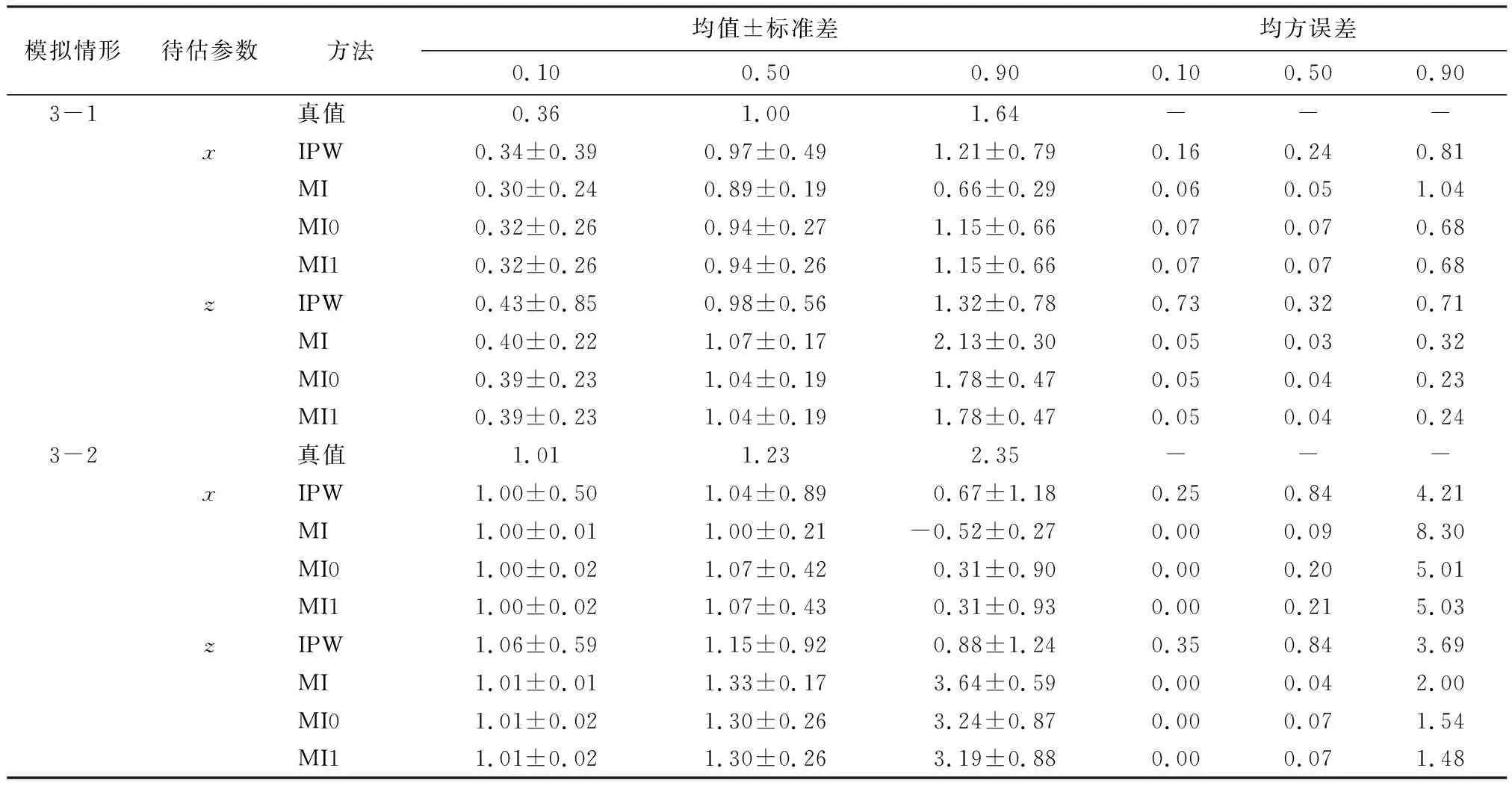
表3 缺失相关参数为0.9时不同分位数下参数估计结果(N=1 000)
(三)可视化研究
为了进一步直观展示上述模拟结果,进一步研究不同分位水平下四种方法在无偏性和有效性(尤其是无偏性)方面的表现,本文选择缺失相关系数为0.3的相关参数估计结果,绘制图1。
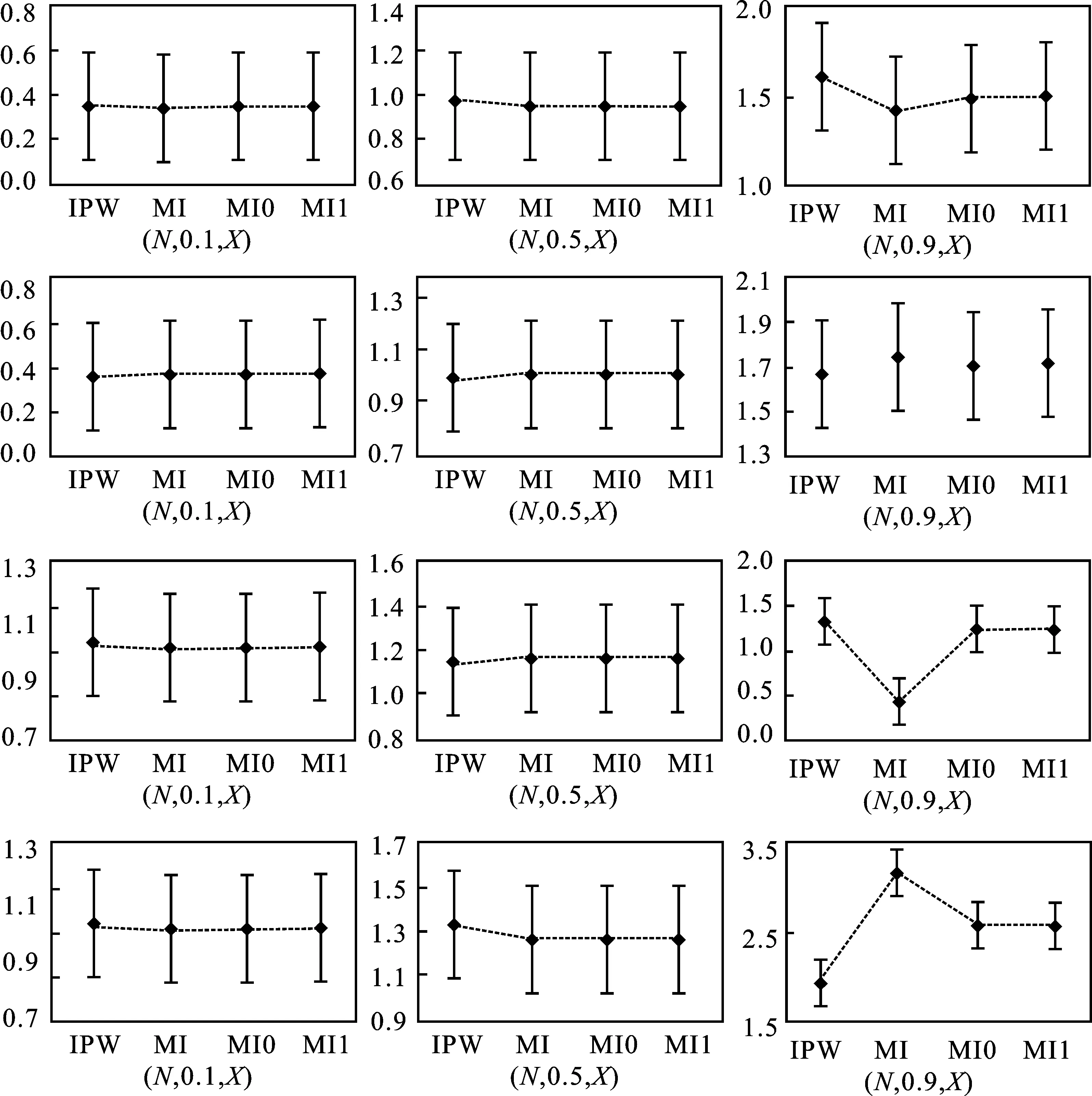
图1 参数估计均值和标准差图
图1中,(N,0.1,X)分别表示正态分布下分位水平为0.1的x系数估计结果;(N,0.1,Z)分别表示正态分布下分位水平为0.1的z系数估计结果;(C,0.1,X)分别表示卡方分布下分位水平为0.1的x系数估计结果;(C,0.1,Z)分别表示卡方分布下分位水平为0.1的z系数估计结果,其他同理。图1突出了不同分位数下,四种方法无偏性差异的不同规律。从图形上来看,随着分位水平的提高,它们间的差异逐渐变大,高分位水平时最为明显。为了进一步研究高分位水平下,四种方法的无偏性及变化规律,本文计算绝对偏差(均值减去真值的绝对值),并绘制了以不同方法为横轴、绝对偏差为纵轴的折线图,见图2。

图2 参数估计偏差图
图2中,(N,0.9)分别表示正态分布下分位水平为0.1的绝对偏差;(C,0.9)分别表示卡方分布下分位水平为0.9的绝对偏差;X.IPW表示IPW对x系数的估计,其他同理。由图2可知,无论残差服从正态分布还是卡方分布,四种方法按相同顺序排列后的绝对偏差整体上呈现相似的变化规律。相同的是,最大绝对偏差均出现在MI方法处(X.MI和Z.MI)。唯一明显的不同之处在于最小绝对偏差出现的位置。当残差服从正态分布时,x和z的最小绝对偏差均在IPW方法下取得,且优势较为明显;而当残差服从卡方分布时,x在IPW、MI0和MI1方法下的最小绝对偏差几乎处于同一水平,z的最小绝对偏差均在MI1方法下取得,且与MI0颇为接近。
五、应用研究
(一)问题介绍
本文的应用研究基于2010年中国综合社会调查(Chinese General Social Survey,CGSS)的部分数据,旨在研究年收入的影响因素。研究的对象为1 000名受访者。本文以年收入(y)为结局变量,周工作时间(x1,含缺失数据,缺失率为20%左右)、年龄(x2)、受教育年限(x3)为影响因素。考虑到这些变量的分布呈现偏态且均为连续数据,因此可以考虑构建分位回归模型。模型表达式如下:
Qτ(y)=β0,τ+β1,τx1+β2,τx2+β3,τx3
(10)
(二)研究方法
不难理解,存在缺失数据的周工作时间,完整观测的年龄以及完整观测的受教育年限都与年收入存在一定的相关关系,即这些自变量在一定程度上会影响或决定了年收入状况。因此,本文以完整资料分析法(CC)、逆概率加权法(IPW)和多重插补法(MI)为参照,比较逆概率加权多重插补法(MI1)在中国居民收入影响因素问题中的估计结果。其中,多重插补法(MI)和逆概率加权多重插补法(MI1)中m取值为10。
与模拟研究相同,分位回归中,分位数水平取值为从0到1、间距为0.02的50个分位数。整个参数估计过程包括200次Bootstrap,参数估计结果包括参数估计值、200次Bootstrap估计的标准差和参数显著性的检验P值。
(三)结果解释
在低分位水平(τ=0.10),中分位水平(τ=0.50)和高分位水平(τ=0.90)下,不同插补方法的参数估计结果如表4所示。
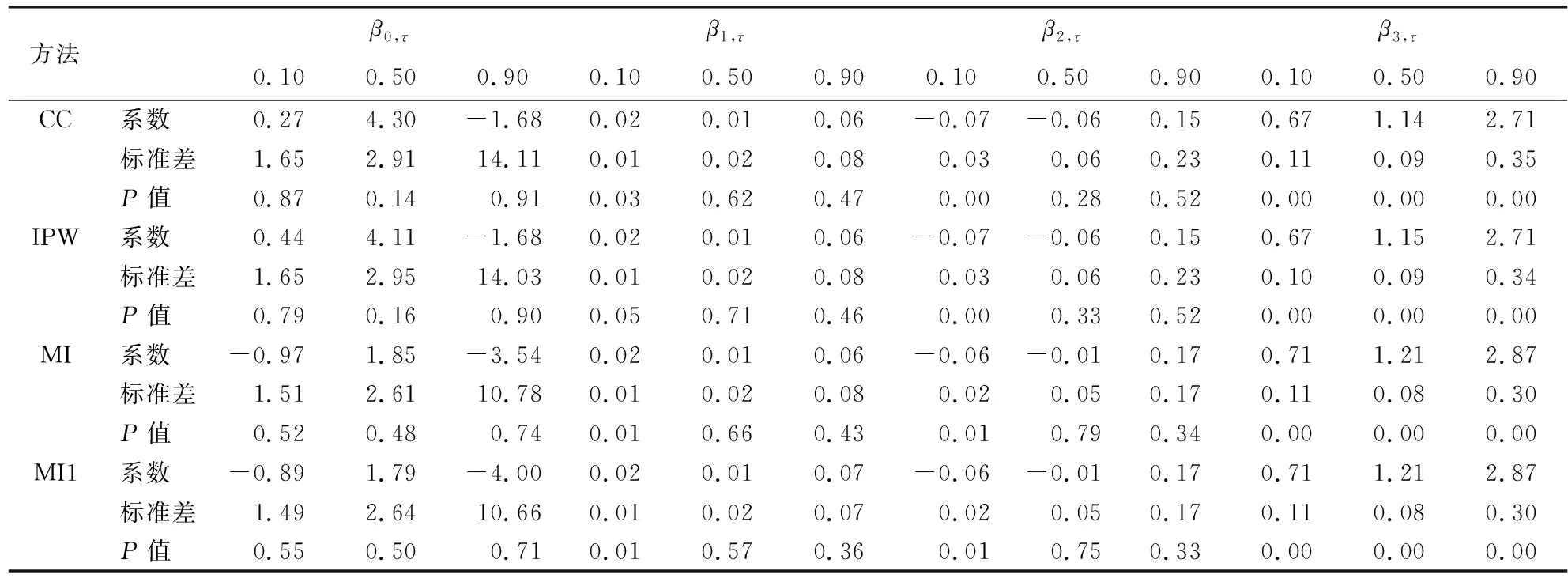
表4 不同分位数水平下的参数估计结果
由表4可得到一系列方程:
低分位水平:
CC:Qτ(y)=0.27+0.02x1-0.07x2+0.67x3
IPW:Qτ(y)=0.44+0.02x1-0.07x2+0.67x3
MI:Qτ(y)=-0.97+0.02x1-0.06x2+0.71x3
MI1:Qτ(y)=-0.89+0.02x1-0.06x2+0.71x3
中分位水平:
CC:Qτ(y)=4.30+0.01x1-0.06x2+1.14x3
IPW:Qτ(y)=4.11+0.01x1-0.06x2+1.15x3
MI:Qτ(y)=1.85+0.01x1-0.01x2+1.21x3
MI1:Qτ(y)=1.79+0.01x1-0.01x2+1.21x3
高分位水平:
CC:Qτ(y)=-1.68+0.06x1+0.15x2+2.71x3
IPW:Qτ(y)=-1.68+0.06x1+0.15x2+2.71x3
MI:Qτ(y)=-3.54+0.06x1+0.17x2+2.87x3
MI1:Qτ(y)=-4.00+0.07x1+0.17x2+2.87x3
研究表明:分位回归模型全面展示出,不同年收入水平下,不同人群具有不同的特征和规律。1)无论在哪种分位水平下,周工作时间(x1)对年收入的贡献最小、受教育年限(x3)对年收入的贡献最大,且始终为正向。说明当周工作时间或受教育年限变长时,年度收入会相应增加。其中,受教育年限的影响更为明显。2)随着分位水平的升高,受教育年限(x3)对年收入的绝对贡献(系数值)有所增加。说明年收入水平越高的人群,具有相对越高的受教育水平。3)年龄随分位水平的升高,呈现由负变正、不断增加的趋势。表明随着年龄的增加,年收入水平也会相应提高,在一定程度上反映出工龄与收入间存在的关系规律。综上所述,受教育年限(或文化程度)成为影响年收入水平的一个关键因素。
六、总结与讨论
一直以来,提高中国居民工资待遇水平,保障人民生活质量都是我们必须面对的重要课题。本文通过模拟研究和应用研究两部分,将逆概率加权修正后的多重插补法应用于中国居民收入影响因素分析中,尝试挖掘关键因素。
模拟研究表明,在本文涉及的自变量缺失与因变量的相关程度以及残差服从的分布类型范围内,可以得出如下结论:
第一、逆概率加权法(IPW)对现有多重插补法(MI)的估计偏差进行一定程度的修正,即逆概率加权多重插补法(MI1)比现有多重插补法(MI)在估计偏差上有所改进。
第二、逆概率加权多重插补法(MI1)与基于观测概率真值的多重插补法(MI0)在无偏性、有效性和估计精度上的估计结果均颇为近似。即在所有分位水平下,逆概率加权多重插补法(MI1)和基于观测概率真值的多重插补法(MI0)的估计量具有相对较好的无偏性和有效性。
第三、逆概率加权多重插补法(MI1)在不同分位水平下表现出较好的无偏性,有效性和估计精度,可以判定为统计性质较佳的估计量。
在模拟中,真实观测概率是已知的,基于观测概率真值的多重插补法(MI0)可以使用并作为参照,用于对比研究逆概率加权多重插补法(MI1)。但在实际应用中,真实观测概率是未知的,基于观测概率真值的多重插补法(MI0)的讨论无法开展,因此,基于观测概率真值的多重插补法(MI0)仅限于理论层面的探讨,逆概率加权多重插补法(MI1)确实对现有多重插补法(MI)有一定程度的改进,但就其程度而言,仍存在着较大的改进空间。将逆概率加权法(IPW)引入现有多重插补法(MI)的思想,有效缓解了当自变量缺失与因变量有关带来的估计偏差较大的问题,而且并未增加计算复杂度(应用研究中,MI和MI1的单次运行时间分别为11.93秒和11.95秒)。
将逆概率加权多重插补法及其它缺失处理方法应用于中国居民收入影响因素分析中,不难发现,年度收入会随着周工作时间、年龄和受教育年限的增长而增加。其中,受教育年限的影响更为明显。年收入水平较高的人群同时具有相对越高的受教育水平。因此,在中国居民收入的影响因素分析中,受教育程度成为影响收入水平的关键因素,相比之下,时间因素对收入水平的影响或贡献较弱。
综上所述,逆概率加权多重插补法(MI1)拓宽了现有多重插补法(MI)的适用范围,确保了估计量具有较好的统计性质,而从均方误差来看,该方法仍然具有可观的研究前景,使得估计量的性质得到更大程度的改善。此外,在中国居民收入影响因素分析中,我们发现,随着受教育水平的不断提高,工作时间因素已不再是制约或影响提高工资待遇的最重要因素,提高学历水平和文化程度成为改善工资待遇状况的重要途径。
