基于用户信息画像的专业馆员服务研究∗
2019-07-27吴紫山
吴紫山 陈 哲
(广州番禺职业技术学院图书馆,广东 广州 511483)
教育部于2015年颁布了《普通高等学校图书馆规程》,把图书馆的馆员分为“专业馆员和辅助馆员”,同时指出“专业馆员的数量不低于馆员总数的50%”,并将专业馆员的培养纳入高校人才培养计划[1]。据此规程,专业馆员服务工作作为高校教辅工作的重要组成部分,对图书馆的发展和转型也起到重要的战略意义。图书馆如何开展专业馆员服务工作,《规程》中表述比较模糊,这就需要图书馆馆员在实践中进行探索和研究。笔者利用大数据的分析方法——用户画像,以广州番禺职业技术学院图书馆(以下简称番职图书馆)开展专业馆员服务工作产生的数据为基础,对高校馆专业馆员如何开展专业服务进行研究,总结出一套更科学、更高效的专业馆员服务方法,为图书馆服务创新和转型提供参考和借鉴。
1 用户画像的相关研究和运用情况
1.1 相关研究
由AlanCooper 提出的建立在一系列真实数据(MarketingData)之上的目标用户模型即用户画像(UserPersona)[2]。图情领域用户画像相关研究主要有:刘海鸥等提出国内外用户画像研究综述对图情领域的用户画像概念起到定义作用[3];陈慧香等归纳了图书馆应用用户画像的经验,指出用户画像为精准个性化服务提供了基础[4];刘速以天津图书馆为例,从数据来源、数据采集、信息识别、模型搭建等方面就用户画像的构建进行了阐述,提出可视化统计描述、多维度交叉分析、用户关系图谱等用户画像分析方法[5];胡媛等对数字图书馆用户画像建模分析,并对构建综合服务能力评价指标体系进行研究。[6]
1.2 运用情况
基于“用户画像”的信息智能推送服务已经广泛应用于各行各业,如阿里巴巴、京东、苏宁易购、携程等电商。以在某APP 上搜索浏览需求商品、旅游目的、住宿酒店等信息为例,再次打开该APP时就会自动在首页推荐相关商品信息、旅游线路、住宿优惠等广告内容,甚至会根据用户注册的手机号发来推荐信息。这些推荐信息是怎么得来的呢?为什么APP 知道你想购买什么,要去哪里呢?这就是电商根据用户行为大数据分析了用户的需求,再根据这些需求进行广告推送。国内利用用户画像研究运用到现实场景的有:刘岩等的《浅析大数据在京东商城精准营销中的应用》[7],单晓红等的《基于在线评论的用户画像研究——以携程酒店为例》[8]。图情领域利用用户画像运用到现实场景有:杨帆的《画像分析为基础的图书馆大数据实践——以国家图书馆大数据项目为例》[9],其文以国家图书馆数据管理与分析平台项目为背景,根据数据计算结算加载到读者模型以及资源数据模型中,逐步实现构建读者以及资源画像。裘惠麟、邵波的《基于用户画像的高校图书馆精准服务设计》[10]搭建了高校图书馆精准服务系统逻辑平台,从数据库层、中间层和客户层方面利用用户画像工具对图书馆的精准服务加以技术实现。据此研究与现状,图书馆专业馆员服务可以借鉴该领域的成功模式,将用户画像及智能推荐技术融合引入专业馆员个性化服务应用领域。
2 基于用户信息画像的专业馆员服务的优势
2.1 针对用户结构,优化行为数据
图书馆的信息数据量比较庞大,一般包括读者用户使用图书馆各项资源情况,如各库室使用情况、馆藏书目借阅情况和数字资源阅读、下载信息,另外还有内部产生的馆员的工作日志、图书编目数据、视频监控数据、各库室环境监控等。这些数据受存储能力限制没能及时保存和利用,但随着智慧图书馆的建设,机房的数据存储计算能力不断提高,这些结构和非结构化,表面上看似关联度不大的数据经过分析挖掘,可以找出很多隐性的、未知的但却非常有价值的信息。例如,通过对数字资源检索、阅读、下载情况的分析,可以得到包括读者的信息需求分类、数字资源使用习惯、馆内参考咨询效率等信息。通过用户画像处理这些大量涌现的信息数据可以更加高效地服务读者。
2.2 精准对接用户,提升服务效率
专业馆员是知识服务中必不可少的角色。通过用户画像工具可以在学科服务方面分析师生学术画像,根据师生的科研方向开展定题服务、参考咨询等,实现专业馆员和对口院系的精准对接,提升服务效率。对图书馆系统已形成的用户数据则需对咨询的读者进行识别和判断,进而推测其爱好及需求,并据此提供相关的搜索建议及帮助,使读者可以又快又准获取信息。专业馆员也可以根据用户画像对用户行为进行分析,根据其收藏以及订阅的内容进行定期文献更新及消息推送,减少用户搜索文献的时间成本,为数字图书馆知识社区中的读者用户提供方便的服务。
2.3 建立精准、科学的采编机制
在采编工作方面,分析师生阅读画像,可以帮助采编部门了解师生的借阅需求,从而建立精准、科学的采编机制。专业馆员在开展服务工作时可以联动采编部,整理读者借阅和偏好的数据,通过用户画像工具进行分析、推荐购买相关的图书和期刊,经采购编目并完成上架后,及时推送给所属学院的师生和相关读者,从而建立精准、科学、及时的采编机制。
3 用户画像应用场景
3.1 资源利用场景
图书馆藏书由大量的实体图书、期刊、数字资源等文献信息资源组成,如何开发利用好这些资源并推荐给读者用户就成为了专业馆员工作的重点和难点。通过计算机系统开发利用文献信息资源是主要的技术手段,但目前大部分专业馆员对信息加工仍以手工为主,尚未建立科学系统的分析模型,资源的开发利用在很大程度上受到局限。以番职图书馆为例,该馆的专业馆员每月会统计各书库畅销书籍的借阅量、借阅频率,通过宣传海报、微信公众号等媒介向读者有针对性地推送好书。而如何精准选择用户群、推送适合的书籍就成了该馆专业馆员服务面临的难题,利用用户画像原理设计系统模型就可以解决这方面的问题。首先由专业馆员建立数据后台,利用用户画像原理,对读者群体、专业分类、内容兴趣,阅读行为等数据粘贴用户标签,最后计算分析出新一期图书和期刊投放的媒介、时间、位置等信息,通过这样系统的处理就可以实现精准地推荐好书。
3.2 资源检索场景
图书馆OPAC 馆藏图书查询系统是读者用户最熟悉、最常用的平台检索系统。目前OPAC系统不仅可以检索馆藏图书资源,还整合了各种类型的数字资源和服务。如何利用该系统的用户信息流,深入挖掘分析用户行为,提高图书馆的资源检索效率也成为专业馆员的工作重点。将用户画像原理加入到OPAC 检索系统可以设计出精准检索查询系统,增加用户体验好感,方便读者快捷地检索到所需内容。以一位读者在OPAC 系统中输入“微信小程序”为关键字搜索阅读资料为例,精准的画像推荐系统就会发起请求命令并记录下来,下一次该读者再次登记OPAC系统时,与之相关的同类书目将出现在该用户界面的显著位置上,从而完善图书馆智慧化检索查询系统。
3.3 资源推广场景
以番职图书馆进行阅读推广为例,有些主题活动并未了解大学生的真实需求,使得提供的服务适应性不足,某些情况下造成资源浪费[11]。利用用户画像工具则可在前期策划时深度挖掘相关用户的阅读时间、个性需求、阅读特征等数据,分析读者的阅读偏好,筛选出比较受读者用户喜爱的项目主题,进而提供差异化的主题服务,使阅读与用户需求有机结合[12],以便有的放矢地有开展阅读推广活动。
4 基于用户信息画像的专业馆员服务构建
4.1 用户画像的数据源获取
要获得图书馆用户画像首先要获取用户的行为数据。高校图书馆用户行为按用户使用群体划分可分为教职工和学生两种,按使用资源类型又可以分为实体资源和数字资源两种。
以数字资源为例,用户先注册一个账号,基本上是名字、手机、性别、所属学校、专业等,但这只是基础数据。更重要的是用户的使用记录,如搜索内容、浏览内容、访问数量、关注方向等一系列用户行为轨迹,通过这些行为最后会变成几千个事实标签,成为分析用户行为数据的一部分。目前数字资源用户的行为数据多来源于资源商提供的日志和统计,得到行为数据后使用大数据分析函数进行分析。笔者对番职图书馆2018年1月至12月超星读秀资源的使用数据进行简单加工后生成的饼状分析图,如图1所示。通过该分析图得出,电子图书(23187 次)的浏览量排第一位;期刊(10347 次)浏览排第三位(第二位首页浏览排除)进行分析,提取的主要行为信息包括用户的浏览内容、访问数量,利用这些相关的信息进行归属,构成用户的静态信息库,对收集得到的静态信息库数据进行分析,利用数据挖掘算法模型,抽取出用户画像标签,构建用户画像标签体系。
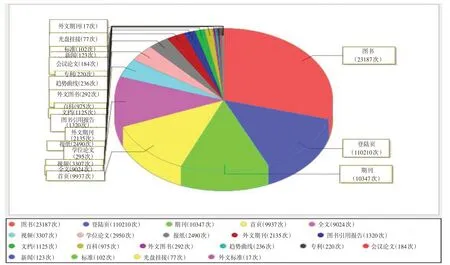
图1
4.2 构建用户画像标签
通过简单的数据获取分类后,图书馆专业馆员可以按类型将这些数据打标签,使计算机能够程序化处理这部分信息,如用户的姓名、性别、年龄、专业、研究方向、职称等级和该用户的搜索内容、浏览内容、访问数量等关键信息,然后根据数据的关联程度和用户所需求的专业服务进行偏好分析,也可以通过网络爬虫技术,跟踪用户在图书馆数字资源中的行为数据,如设置“摄影”或“会计”等这样的关键字,对浏览借阅过的用户的次数、频率进行统计。通过以上数据挖掘的方式获取到更加精准的信息数据,从而进行精准的信息推送和定题服务。
4.3 用户画像权重计算
设置以下样例进行用户画像行为数据分析:(1)某读者用户;(2)某个时间段;(3)借阅了一本《大众摄影》书籍。
对该样例简单分析可以得出,这个借阅行为标签不能判断目标用户是专业摄影的师生,有可能是随手翻阅的师生,也有可能是非摄影专业的师生,这个时候就需要通过更多的行为标签来判断用户群体的属性。
设定一个比较简单的标签权重算法:
兴趣标签(摄影)权重=行为权重*访问时长*衰减因子
行为权重:什么都不干+1,参与书评+0.5,续借+1,再借阅同类书籍+2
时长权重:3天以内权重为0.5,3-10天为1,10天以上为2
衰减因子:0-3 天内权重为 0.5,3-7 天权重为1,7-15 天权重为0.8,15-30 天权重为0.5,30 天以上权重为0.1
兴趣标签权重=行为权重*访问时长*衰减因子
行为权重数值是指参与书评、续借、再借同类书籍等行为操作后产生的不同的数值,对其累加构成行为权重。
时长权重数值指借阅停留时长。借阅时长一般代表对该书的兴趣程度,停留的时间越长,时间权重也越高。但借阅时间并不能代表最佳的阅读兴趣,需加入衰减因子进行控制。
衰减因子数值指最佳阅读时长。一般认为,正常的一本书3~7 天的借阅时间长是最有兴趣爱好的阅读时间,短期借阅行为和逾期行为均无法代表正常的阅读习惯,所以衰减因子权重呈波浪型曲线。
根据以上标签权重算法,图书馆用户每次的借阅行为都会生成一个加了权重的兴趣标签,这个标签会将该用户一段时间内所有的借阅类目进行兴趣权重累加计算,再用S 形函数标准化,就可以得到一个介于0至10的区间兴趣标签值。标签值越高,用户对该类目(如摄影)的偏好程度就会越高。接下来这些偏好会被转换为特征向量。假设摄影标签值是8,阅读时间段是5,阅读时长段是2,就可以用向量表示为r(8,5,2)。这样就可以把特征向量理解成三维空间上的一个坐标,通过把每一个用户的向量坐标代入余弦公式或距离公式(见图2)中,就能计算出相似的用户,进而把用户分类画像,专业馆员就可以按用户画像分类提供针对性服务。
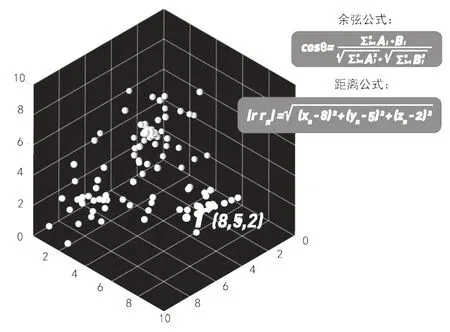
图2 用户特征三维图
4.4 用户画像建模分析
根据以上方法计算出用户特征三维图后,用户画像系统就能获得基本计算方法,将搜索内容、浏览内容、访问数量等信息组成模型,通过模型使计算机程序化、系统化处理这部分信息,进而从杂乱的标签中找到用户真正的兴趣点,勾勒出读者用户基本面貌和需求,实现构建用户画像,指导专业馆员进行精准服务。
4.5 用户画像难点及建议
目前通过以上这些行为数据只能计算出偏好,无法判断出用户的性别、学术研究程度等更加具体的个人属性。这就需要把已知性别和学历的用户作为样本,一部分用来训练模型,一部分用来测试准确度。测试最后专业馆员就能得到一个相似程度达80%以上的用户画像模型,专业馆员可以通过这个模型图归纳并定位到对应服务群体,完善精准度。
5 结语
笔者提出一种以用户画像为工具的高校图书馆专业馆员学科服务方法,阐述了从采集数据到形成标签、计算权重、建立模型等利用读者用户画像数据进行专业服务的思路,使专业馆员开展工作时能够更加精确地服务到有需求的人群。利用图书馆用户画像还可以使用户在利用图书馆的实体资源和数字资源的过程中得到更加人性化的体验。
