基于移动计算平台的语音情感识别系统设计*
2019-07-26黄佳杰朱浩威金瑜成孙凯悦戚国亮张石清
苏 岑,黄佳杰,朱浩威,金瑜成,孙凯悦,戚国亮,张石清
(台州学院 电子与信息工程学院,浙江 台州 318000)
随着移动互联网的快速发展,人们常与手机、平板电脑等移动终端设备为伴,从而导致“人机互动”不断增加。在此情况下,人们对人机交互活动提出了更高的要求,即情感交互需求,因为人类之间的沟通与交流是自然而富有感情的,因此人们也期望与之交互的移动终端设备也应该具有类似于人一样的观察、理解与生成情感特征的能力。近年来,随着情感计算(Affective Computing)技术的不断发展,情感交互也成为当前信息时代下智能人机交互技术的主要发展趋势。
语音情感识别,是实现情感交互的核心技术之一,旨在利用计算机自动分析说话人的语音信号,确定说话人的情感状态,以便达到人机交互之间更轻松、更智能化的交流。目前,在语音情感识别领域,大多数研究工作[1-4]都是以离线方式预先采集好数据进行情感识别,没有在线实现情感识别的实时性。为此,本文考虑到智能手机的便利性和普及性,以HTC G1(搭载Android 1.6 OS)为硬件实现平台,设计一种基于安卓(Android)操作系统的实时性语音情感识别系统。该系统将语音情感识别中的关键步骤,如语音采集、特征提取、情感识别等,与Android系统有机结合在一起。实验测试表明,该系统具有实时性、识别性能较高的特点。
1 语音情感识别系统的设计
一个基本的语音情感识别系统包括语料库的建设(训练样本、测试样本)、语音预处理、情感特征提取以及情感判别器,如图1所示。该系统的每一个步骤介绍如下:

图1 语音情感识别系统结构图
1.1 语料库的建设
情感语料库的建设是进行语音情感识别研究的先决条件,而且语料库的好坏直接影响到最后的情感识别效果的可靠性。目前,国内外研究者已经建立了各种语言的情感语料库,比较典型的有德语EMODB[5]、英语 eNTERFACE05[6]、汉语普通话 CHEAVD[7]等。本文利用已有的情感语料库 EMO-DB 和CHEAVD分别作为训练样本进行训练,而测试样本来源于现场测试时采集到的说话人语句。其中,EMODB[5]数据库包含 535 个语音样本,共七种情感:生气(Anger)、高兴(Happiness)、悲伤(Sadness)、害怕(Fear)、讨厌(Disgust),无聊(Boredom)和中性(Neutral)。而 CHEAVD[7]数据库包含 2852 个语音样本,共八种情感:生气、高兴、悲伤、讨厌、中性、担心(Worried)、焦虑(Anxiety)和惊奇(Surprise)。由于现场采集的情感语句类型比较有限,这里测试时仅考虑基本的五种情感类型:生气、高兴、悲伤、害怕和中性。
1.2 语音预处理
语音预处理主要包括语音信号的预加重和加窗分帧处理。预加重是为了实现对语音信号的高频分量的补偿,消除口唇辐射的影响,从而提高语音信号的高频分辨率。本文通过一个传递函数为H(z)=1-az-1的一阶有限长单位冲激响应(Finite Impulse Response,FIR)高通滤波器来实现预加重,其中预加重系数a取a=0.98。考虑到语音信号短时间内(10 ms-30 ms)具有平稳特性的特点,就可以对语音信号进行加窗分帧处理,即采用可移动的有限长度的窗函数进行加权的方法来实现。本文采用布莱克曼窗(Blackman)函数对语音信号加窗分帧,以便减小吉布斯现象的影响。布莱克曼窗函数是二阶升余弦窗,具有主瓣宽、旁瓣比较低的特点,其时域表达式为
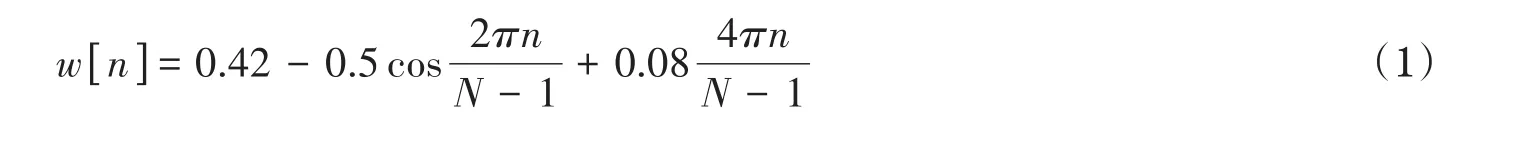
其中,N是帧长。
1.3 情感特征提取
情感特征提取旨在从语音信号中提取能够反映说话人情感的语音特征参数。目前,在语音情感识别领域研究者发现与说话人发音时紧密相关的情感特征参数,主要包括与发音语调和轻重有关的基音频率和振幅,以及与发声方式有关的频谱能量分布参数[1-4,8,9]。因此,本文对每一句语音样本,都提取基音频率、振幅、频谱能量分布三个方面的特征参数,共计9个特征。其中,对基音频率和振幅两个特征分别计算出平均值、标准差和短时抖动三个统计学参数,而对频谱能量分布特征取50 Hz-1000 Hz、1000 Hz-4000 Hz和4000 Hz-5000 Hz三个不同频带范围的能量参数。
1.4 情感判别器
情感判别器用于实现语音情感类型的判别任务,输出最终的语音情感识别结果。本文采用模板匹配(Template Matching)方法[10]实现情感的分类。模板匹配方法的基本思想是从待测试样本中提取相应的特征向量,与训练样本上提取的作为模板的对应特征向量进行比较,然后计算测试样本的特征向量与模板特征向量之间的距离大小,最后采用最小距离法判定该测试样本所属的情感类别。

通过不断重复计算该测试样本和训练样本模板之间的距离,并比较所有的距离大小,然后找到一个与测试样本距离最小的训练样本所对应的样本类别号作为测试样本X所属的情感类型。
2 语音情感识别系统的测试
2.1 Android平台开发
Android作为一个巨大的开放式移动体系,从作用上划分Android开发,大概有三类:(1)移植开拓移动电话系统;(2)Android应用软件开发;(3)Android系统开发。相对于语音情感识别系统而言,本文采用Android应用软件开发的方式进行系统设计。为了给Java层次的应用软件提供调用的接口,应该要从底层到顶层整体开发。有以下几个步骤:
(1)扩张 C 或者 C++现有库;(2)定义 Java 需要的类;(3)将需要的源代码封装成 JNI;(4)把 Java 类和JNI结合起来;(5)应用软件调用Java类。
2.2 系统测试
2.2.1 软件、硬件测试环境
系统测试的软件、硬件环境如表1、表2所示。

表1 软件测试环境

表2 硬件测试环境
2.2.2 功能测试
图2给出了该系统测试的APP启动界面,以及输出五种基本情感类型,如生气、高兴、悲伤、害怕和中性的识别结果。APP启动之后,说话人就可以对着手机麦克风进行现场采集语音,并实时性地进行情感判别,即APP界面会实时性输出每一种情感类别的判别分数,得分最高的那种情感类型就是最终识别的情感类别号,如图2(b)所示。
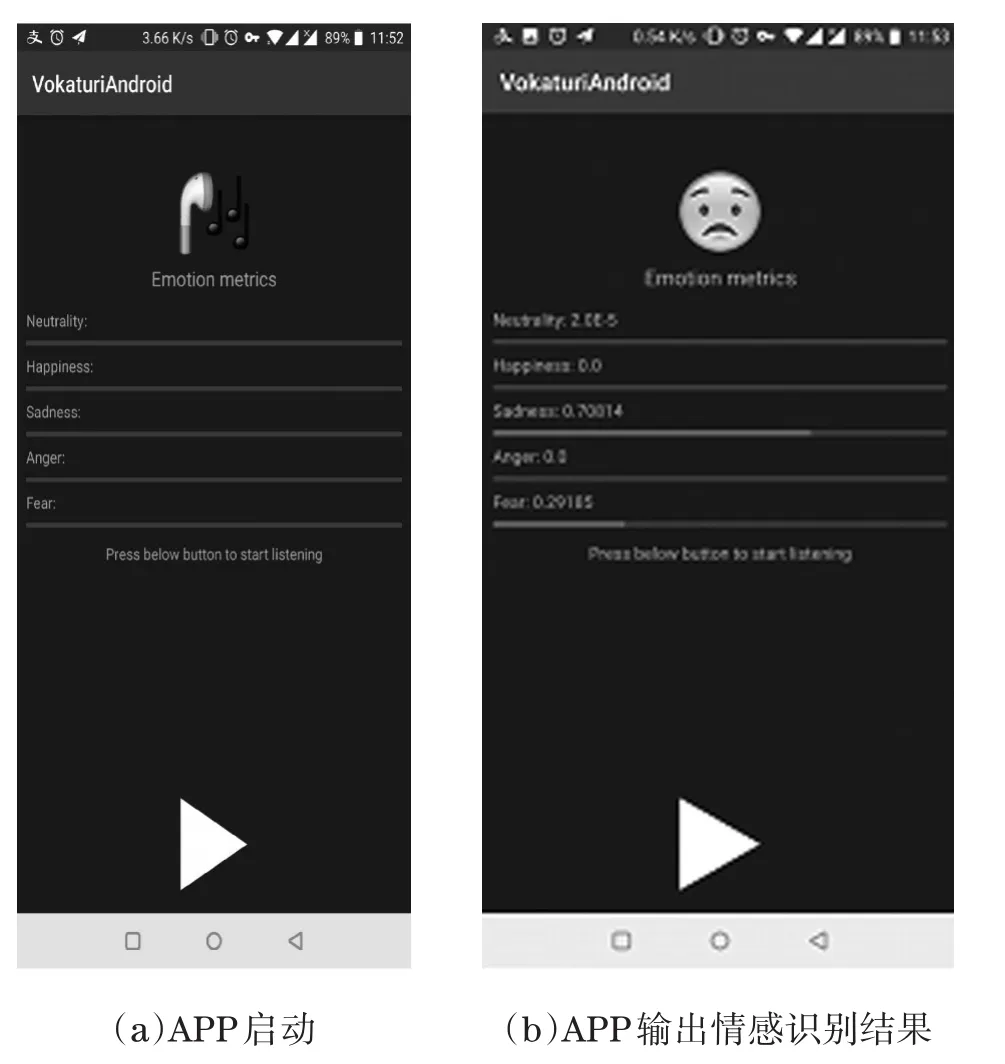
图2 语音情感识别系统APP测试
2.2.3 情感识别结果测试
情感识别结果测试分为同语言和跨语言两种情况。对于同语言测试,采用汉语普通话CHEAVD[7]语料库的语音样本作为训练样本,而测试时说话人的汉语普通话语音样本作为测试样本。对于跨语言测试,采用德语EMO-DB[5]语料库的语音样本作为训练样本,而测试时说话人的汉语普通话语音样本作为测试样本。所有测试的情感类型为五种基本情感类型,即生气、高兴、悲伤、害怕和中性。测试时,说话人现场模拟每一种基本的情感类型进行录音,从而采集10个测试样本用于测试。
表3和表4分别给出了同语言和跨语言的情感识别结果。从表3和表4的实验结果可以看出,同语言的情感正确识别率的平均值为74 %,说明该系统的同语言的识别性能较好。然而,跨语言的情感正确识别率的平均值只有56 %。实验结果表明,同语言的情感识别性能明显高于跨语言的识别结果。这说明,跨语言的情感识别难度比较打,因为不同语言上的差异会明显影响情感识别的性能。

表3 同语言(汉语作为训练,汉语作为测试)的情感识别结果

表4 跨语言(德语作为训练,汉语作为测试)的情感识别结果
3 结论
本文设计了一种基于安卓(Android)移动平台的实时性语音情感识别系统。该系统在Android上集成了语音采集、情感特征提取、情感判别模型等语音情感识别系统的关键环节。实验测试结果表明,该系统具有实时性和识别性能较高的特点。
