融合三维骨架和深度图像特征的人体行为识别
2019-07-23宋相法
宋相法,吕 明
(河南大学 计算机与信息工程学院,河南 开封 475004)
0 引 言
人体行为识别具有很高的应用价值,可应用于游戏娱乐[1]、视频监控[2]、老年人护理等领域[3],因此计算机视觉与模式识别等领域的研究人员对其进行了深入研究[4-5]。早期的研究人员主要利用可见光摄像机获取的图像进行人体行为识别的研究,取得了诸多研究成果。但是基于可见光摄像机获取的图像进行人体行为识别的效果对光照和颜色等因素比较敏感,当上述因素发生变化时,识别精度会大幅度降低。因此,人体行为识别仍然极具挑战性。
近年来,随着微软Kinect体感设备的出现,研究人员利用该设备可以实时获得人体的深度图像信息。与传统的可见光摄像机获得的图像相比,深度图像不受光照和颜色等因素影响;同时,也可以从深度图像中提取出人体三维骨架信息。所以,基于深度图像的人体行为识别和基于三维骨架的人体行为识别引起了研究人员的广泛关注。例如,文献[6]提出了基于深度运动图的梯度方向直方图特征的识别方法,文献[7]提出了基于四维法向量特征的识别方法,文献[8]提出了基于深度运动图的局部二值模式特征的识别方法,文献[9]提出了基于法向量编码的识别方法。此外,文献[10-16]也提出了几种识别方法。
在上述研究的基础上,文中提出了一种融合三维骨架和深度图像特征的人体行为识别方法。该方法首先从三维骨架中提取出基于运动姿态描述子的稀疏编码特征,同时从深度图像中提取出基于深度运动图的梯度方向直方图特征(histograms of oriented gradients,HOG)[17],然后将得到的这两种特征分别使用liblinear工具包(http://www.csie.ntu.edu.tw/~cjlin/ liblinear/)进行线性分类,最后利用对数意见汇集规则[18]对分类结果进行融合,从而得到最终的人体行为识别结果。
1 文中方法
文中从三维骨架中提取基于运动姿态描述子的稀疏编码特征,同时从深度图像中提取基于深度运动图的梯度方向直方图特征,这两种特征可以增强信息互补性,提高人体行为识别率。
1.1 三维骨架特征提取
文献[11]在研究三维骨架人体行为识别时提出了运动姿态描述子。运动姿态描述子由三维骨架的关节点位置、运动速度和加速度组成,具体实现详述如下。
在三维骨架序列中,每一帧数据由关节点的位置pi(t)=(px,py,pz)组成,其中i∈{1,2,…,n},n为关节点总数。对于每一帧,其关节点位置特征向量表示为:
P=[p1(t),p2(t),…,pn(t)]
(1)
把每一帧三维骨架表示为人体关节点坐标随时间变化的连续函数P(t),则当前帧P(t0)的一阶导数可表示为:
δP(t0)≈P(t1)-P(t-1)
(2)
当前帧P(t0)的二阶导数可表示为:
δ2P(t0)≈P(t2)+P(t-2)-2P(t0)
(3)
其中,P(t-1)表示当前帧的前一帧;P(t1)表示当前帧的后一帧,依次类推。
综上所述,t0时刻的运动姿态描述子表示为:
Pt0=[P(t0),δP(t0),δ2P(t0)]
(4)
在提取每一帧三维骨架的运动姿态描述子的基础上,为提高特征表达的鲁棒性,文中采用稀疏编码的方法对运动姿态描述子进行编码。
为表述方便,使用X=[x1,x2,…,xm]∈d×m表示输入运动姿态描述子集合,其中xi∈d表示第i个输入运动姿态描述子,d是输入运动姿态描述子的维数。相应地,用B=[b1,b2,…,bl]∈d×l表示视觉字典,其中bk∈d表示第k个视觉单词,l表示字典大小。
近年来,稀疏编码在计算机视觉和机器学习等领域得到了广泛关注[19-20],它在最小二乘的基础上加入1-约束从而实现在一个过完备视觉字典上响应的稀疏性,得到稀疏表示,如下式所示:
(5)
其中,S=[s1,s2,…,sm]∈l×m中的每一列sj表示xj在字典B上的稀疏表示系数;表示矩阵Frobenius范数;λ>0为正则化参数。
式5中被优化的变量是B和系数矩阵S。通常的求解方法是通过固定B或者S采用多次交替求解的方法。当B固定不变时,式5可以转化为一个关于S的基于1-约束的凸优化问题,可分别通过求解每一个xj的系数sj进行优化:
(6)
当S固定时,式5是一个关于B的带二次约束的最小平方凸优化问题,即
(7)
文中采用SPAMS工具包(http://spams-devel.gforge.inria.fr/)来求解式6和式7。
一旦得到字典B,就可以根据式6求解每个三维骨架的运动姿态描述子在B上的稀疏系数,然后采用最大值池化方法得到三维骨架特征MPSC(moving pose sparse coding,MPSC)。
1.2 深度图像特征提取
文献[6]在研究深度图像人体行为识别时提出了基于深度运动图的梯度方向直方图特征的方法。该方法首先把深度图像序列的每一帧深度图像Ii投影到由前视图f,侧视图s和俯视图t构成的正交笛卡尔平面上,然后提取梯度方向直方图特征。对于包含N帧的深度图像序列,根据式8计算出它的深度运动图DMMv(v(f,s,t)):
(8)
其中,i表示帧索引。
通过式8分别在3个平面上得到深度运动图DMMf,DMMs和DMMt,然后去除深度运动图中处于边缘的全零行和全零列,得到人体行为的有效区域,如图1所示。
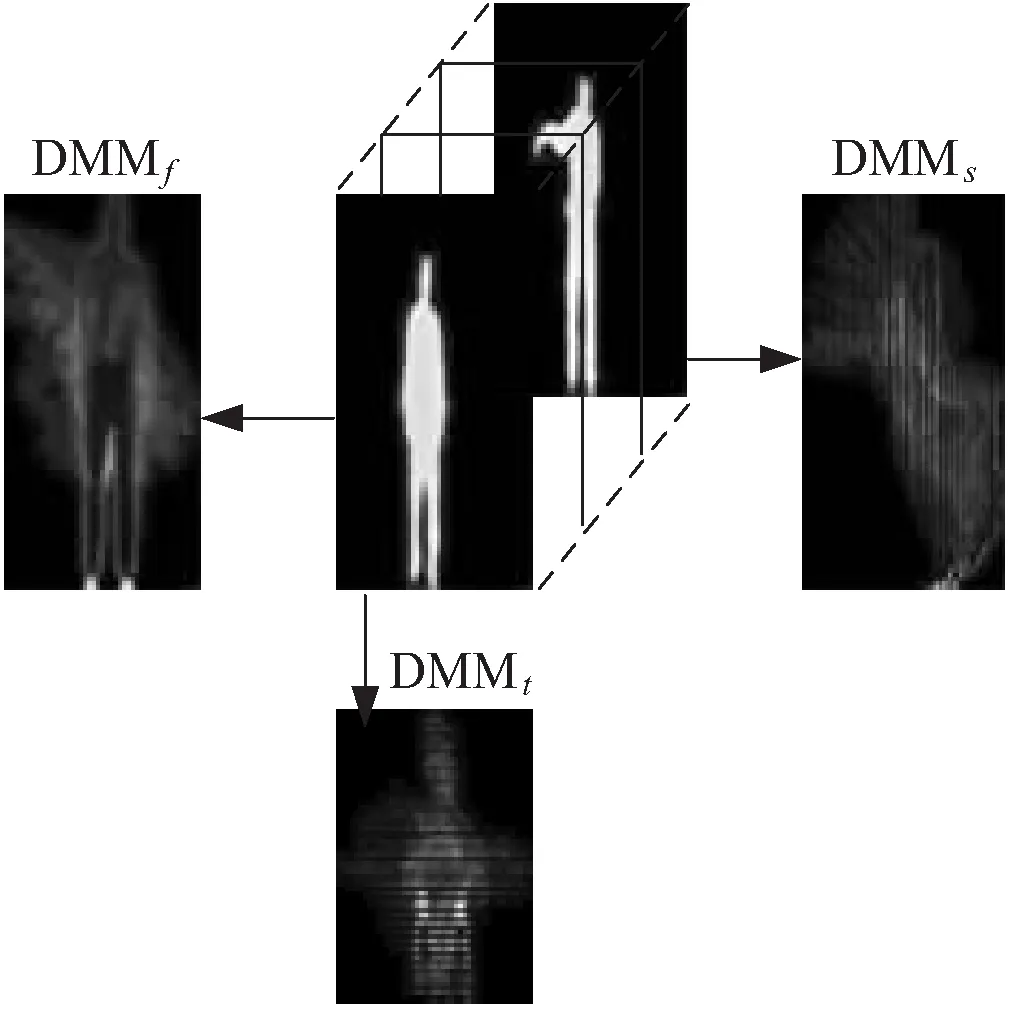
图1 DMM框架
为了减少不同深度图像序列的类内差别,文中分别把DMMf,DMMs和DMMt规范化为96×48,96×72和72×48的深度运动图DMMv(v(f,s,t))。
为了进一步降低特征维数和提高识别性能,在深度运动图DMMv(v(f,s,t))的基础上提取它的梯度方向直方图特征HOGv(v(f,s,t))。提取HOGv时,把深度运动图DMMv划分成若干个互不重叠的8×8的单元,每个单元生成9维HOG特征,每相邻2×2个单元组成一个块,将每个块内所有单元生成的HOG串联而成一个36维向量。用块对DMMv进行扫描,步长为一个单元,最后将所有块的特征串联起来得到HOGv(v(f,s,t))。
文中将提取的HOGf,HOGs和HOGtt串联起来得到深度图像特征DMM-HOG。
1.3 分类融合
把从三维骨架中提取的基于运动姿态描述子的稀疏编码特征MPSC和从深度图像中提取的基于深度运动图的梯度方向直方图特征DMM-HOG分别作为线性分类器的输入,然后根据线性分类器对这两类特征的输出结果利用对数意见汇集规则进行融合,从而实现人体行为的识别。根据文献[21]用Sigmoid函数作为连接函数将线性分类器的输出f(x)映射到[0,1],从而实现其后验概率输出,其后验概率输出形式表示为:
(9)
其中,参数a和b为Sigmoid函数的参数,文中a=-1,b=0。
在对数意见汇集规则中,估计隶属度函数的后验概率pq(yc|x)表示为:
(10)
或者
(11)
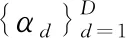
样本x所属类别标号y*如下式所示:
(12)
文中方法的具体实现框架如图2所示。
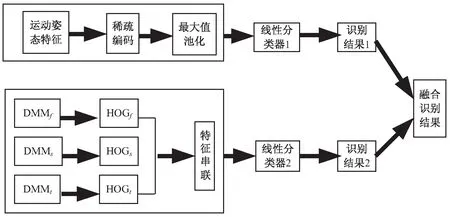
图2 文中方法的具体实现框架
2 实验结果和分析
2.1 实验数据集
文中使用MSR Action 3D数据集[21]进行实验,该数据集包含10个人分别完成的20种行为,例如水平挥臂、敲打、手抓等行为,总共包括557个240×320的深度图像和557个三维骨架数据。
2.2 实验设置
在提取三维骨架特征时,式5中字典B的大小l的取值为1 024,正则参数λ的取值为0.1。为了保证比较的公平性,实验中采用文献[6-16]给出的设置,表演者1,3,5,7,9的数据当作训练样本,表演者2,4,6,8,10的数据当作测试样本。实验的硬件配置为3.6 GHz的四核CPU,32 G内存,系统为64位Windows 8,软件平台为Matlab2014a。
2.3 实验结果与分析
文中方法和对比方法在MSR Action3D数据集上的实验结果如表1所示。
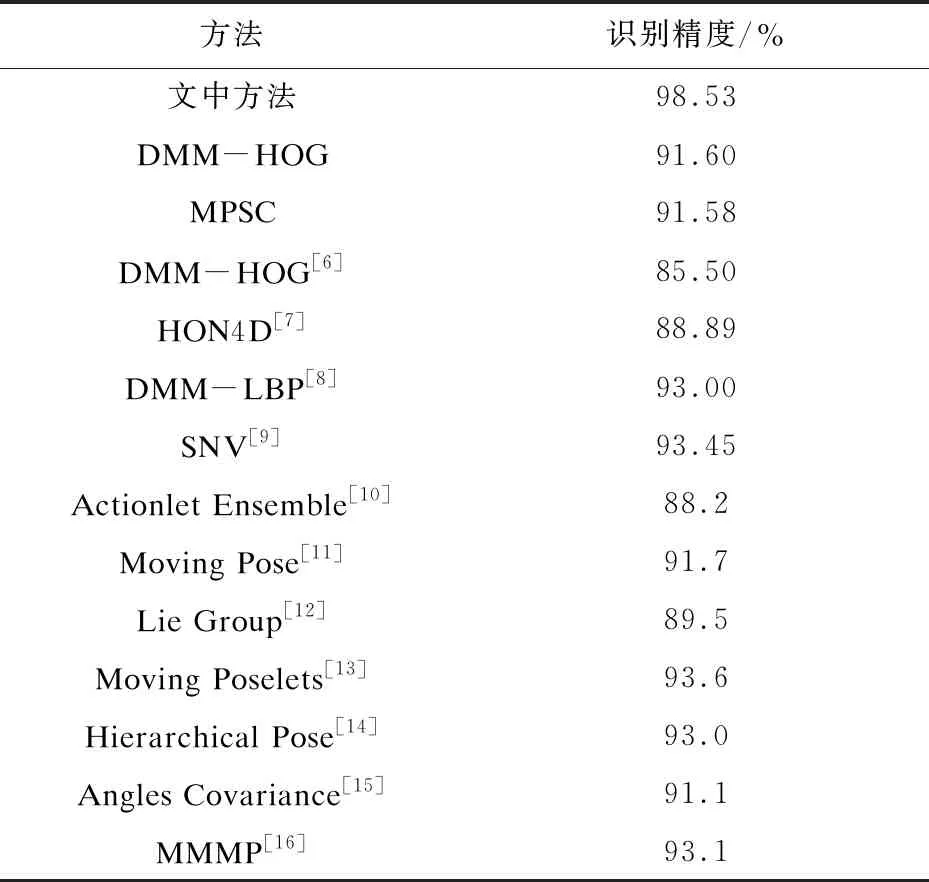
表1 在MSR Action 3D数据集上的实验结果
由表1可知:文中方法的识别精度为98.53%,相比于基于单一的深度图像特征DMM-HOG方法,识别精度提高了6.93%,相比于基于单一的三维骨架特征MPSC方法,识别精度提高了6.95%;相比于其他方法提高了4.93%~13.03%,进一步证明了提出的融合三维骨架和深度图像特征的人体行为识别方法的有效性。
图3以混淆矩阵的形式给出了文中方法在MSR Action3D数据集上的识别结果。
从图3中可以看出,在20种行为中,有17种行为的识别精度为100%,平均识别率为98.53%。
但是hand catch行为的识别率较低,仅为75%,是因为hand catch行为与high throw行为和draw x行为比较相似造成的。
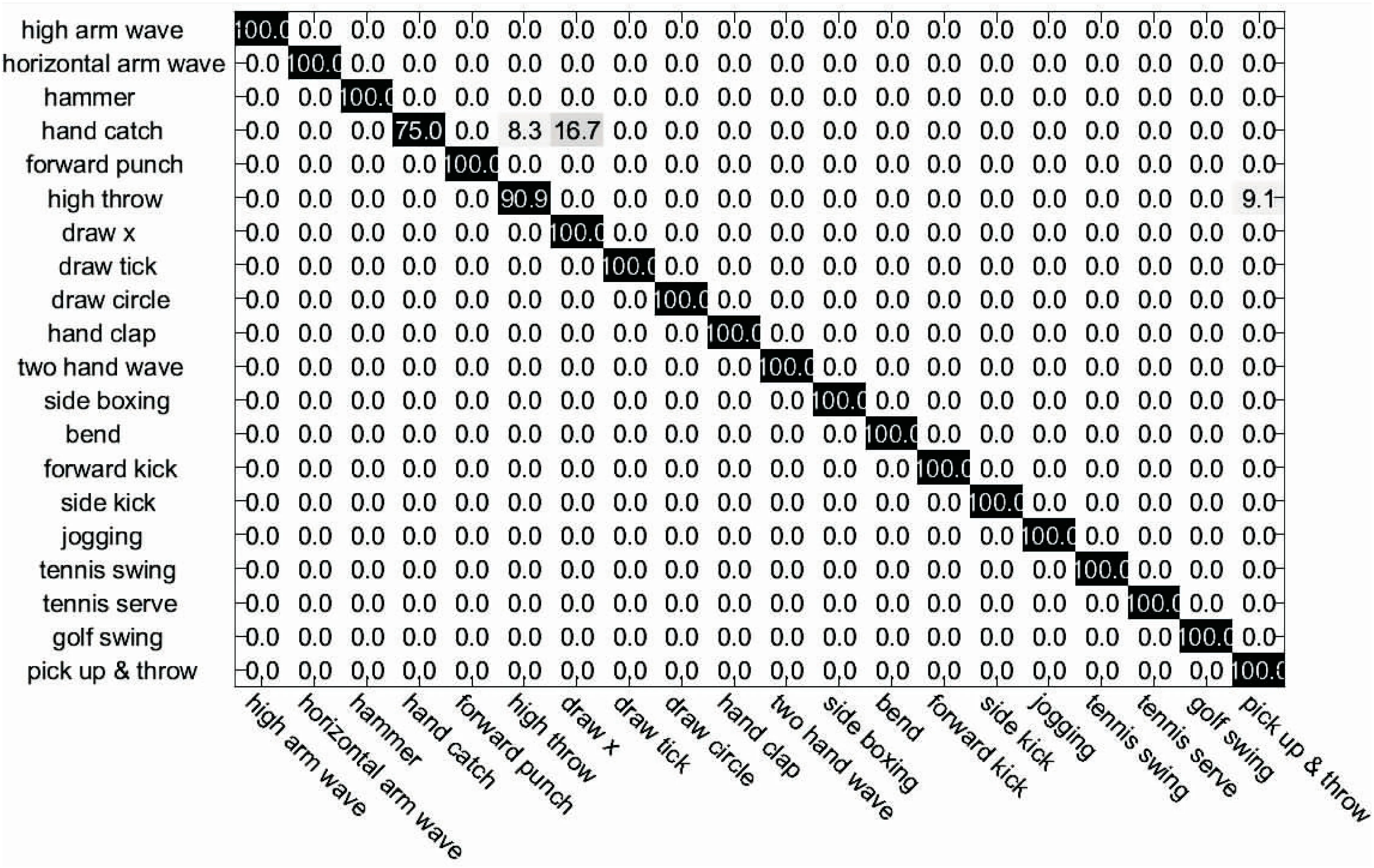
图3 文中方法在MSR Action3D数据集上的混淆矩阵
3 结束语
为了提高人体行为识别率,提出了一种融合三维骨架和深度图像特征的人体行为识别方法。该方法在MSR Action 3D数据集上的识别精度为98.53%,不但超过了基于单一的三维骨架特征MPSC的方法和基于单一的深度图像特征DMM-HOG的方法,而且也高于其他方法,从而证明了该方法的有效性。
