结合蝙蝠算法改进的密度峰值聚类算法
2019-07-22吴辰文刘晓光魏立鑫
吴辰文,刘晓光,魏立鑫
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
在科技迅猛发展的今天,计算机,信息,互联网技术已经不仅仅是某一门学科或某一类职业的专属,更是广泛的融入到医学[1],商业[2],工农业[3-4]等各个领域之中。这些领域伴随着计算机技术的应用,每天都会产生海量的数据。由于计算机硬件技术的不断升级,这些数据产生的速度也不断加快,这也就是平时我们所说的大数据时代的数据爆炸增长。
如何在大规模的数据之中提取到有用的知识成为了研究的重点,数据挖掘技术便应运而生。数据挖掘技术通过一系列算法来搜索那些隐藏于大数据之中的信息。而聚类分析作为数据挖掘最重要的研究内容之一,旨在将数据集分为多组组内具有相同特性、组间具有不同特性的簇。聚类分析的算法可以分为划分法[5](partitioning methods)、层次法[6](hierarchical methods)、基于密度的方法[7](density-based methods)、基于网格的方法[8](grid-based methods)、基于模型的方法[9](model-based methods)。
Alex Rodriguez和Alessandro Laio在2014年提出了一种基于密度的聚类方法[10],该算法相比于其他同类算法的优势在于对于任意形状的数据集,其均可以快速、高效地发现数据集的类簇中心,并进行非类簇中心样本点的分配,在大规模数据集上表现良好。该算法的主要思想是寻找被低密度区域分离的高密度区域。目前,已有许多专家学者针对密度峰值聚类算法进行改进:WANG Shuliang等人将密度峰值聚类算法结合信息熵理论,使其可以自动从数据集中提取截断距离参数[11]。薛小娜等人提出了一种基于K近邻和多类合并的密度峰值聚类算法,以提高算法聚类精度[12]。高诗莹等人将DPC算法和密度比的概念相结合,从而解决了DPC算法在密度分布不均衡的数据集上表现不佳的问题[13]。董晓君等人利用无参核密度估计来分析数据并自适应地选取截断距离[14]。尽管这些算法在一定程度上解决了DPC算法的部分缺陷,但依旧存在诸如模型复杂、真实数据集上表现不佳等问题。本文要解决的DPC算法的主要问题在于:算法的结果依赖于截断距离的选取,但目前选取截断距离的方法主要还是人工选取,主观性太强。而将DPC算法与启发式优化算法相结合,配合适应度函数,对截断距离参数进行寻优,可以有效解决此类问题。
蝙蝠算法(bat algorithm,BA)是由YANG Xinshe于2010年提出的一种高效生物启发式算法[15],该算法假设每个虚拟蝙蝠在位置xi均有随机的飞行速度vi,同时每只蝙蝠具有不同的频率f或波长λ、响度Ai和脉冲发射速率r。蝙蝠发现自己的猎物时,通过改变脉冲发射速率、响度以及频率来对猎物定位,进行最优解(位置xi)的选择,直到目标停止或条件得到满足。本质上就是使用调谐技术来控制蝙蝠群的动态行为,平衡调整算法的相关参数,以取得蝙蝠算法的最优解。BA在工程设计、分类等方面得到了广泛的应用[16-17]。BA同遗传算法和粒子群算法等传统的寻优算法进行比较,也具有较大的优势,但BA依旧存在缺陷,在收敛的过程中,算法后期的收敛速度会逐渐变慢,同时容易陷入局部最优。许多专家学者对蝙蝠算法进行了改进研究:王海军等人将蝙蝠算法和BP神经网络相结合对图像进行去噪处理[18];刘振等人提出了一种自适应进化的蝙蝠算法对原算法的收敛性进行改进[19];王馨等人基于负梯度理论,通过调整蝙蝠算法的速度更新策略来改进蝙蝠算法的全局寻优能力[20]。
针对以上两种算法的优点和缺陷,本文提出了结合蝙蝠算法改进的密度峰值聚类算法(weighted bat algorithm denisity peaks clustering,WBADPC)。首先,对蝙蝠算法的蝙蝠速度和位置公式进行改进;然后,运用改进后的蝙蝠算法对密度峰值聚类的截断参数进行优化,使用聚类评判准则函数作为适应度函数,利用蝙蝠算法较强的全局寻优能力在截断距离取值范围内选取使得适应度函数取值尽可能大地截断距离参数,再运用密度峰值聚类算法进行聚类;最后,通过评判准则函数与传统的密度峰值聚类算法以及其他传统的聚类算法进行比较,并在多种数据集上进行验证。实验结果表明,使用蝙蝠算法优化的密度峰值聚类算法与其他聚类算法相比,具有较好的聚类效果。
1 相关算法介绍
1.1 DPC算法
DPC算法基于如下假设[21]:①类簇中心点的密度大于周围邻居点的密度;②类簇中心点与更高密度点之间的距离相对较大。为了寻找满足上述假设的类簇中心点,DPC算法需要引入两个参数:数据点i的局部密度ρi;局部密度大于数据点i的点集之中距离点i最近的点与点i之间的距离δi。数据点i的局部密度ρi的计算有两种方式,当数据集规模较大时:
ρi=∑χ(dij-dc)。
(1)
其中,dij为点i与点j之间的距离,dc为密度峰值聚类算法的截断距离参数。函数χ为
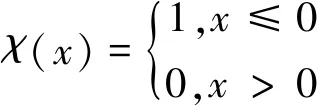
(2)
面对较小规模数据集时,局部密度ρi可以利用指数核函数来进行计算,
(3)
点i与较高密度点的最小距离为
δi=minj:ρi>ρj(dij),
(4)
当点i为局部密度最高的点时,
δi=maxj(dij)。
(5)
在选取聚类中心时,由DPC算法的前提假设可以知道,当点i的局部密度ρi以及与较高密度点的最小距离δi均较大时,点i才可能被选为聚类中心点。在文献[10]中使用决策图的方法来选取聚类中心,即将每点的ρ值和δ值于坐标平面内绘出,然后,将ρ和δ值都较大的点作为聚类中心。但是,当数据点分布较为稀疏时,就很难只通过ρ和δ值来确定聚类中心,此时需要引入另一个参数γ,
γ=ρ×δ,
(6)
将γ值较高的k个点选为聚类中心。
DPC算法的具体步骤如下:
1)计算数据点之间的距离,并求得距离矩阵;
2)人工选取截断距离,计算每个数据点的局部密度ρ,以及与较高数据点之间的最小距离δ;
3)通过得出的ρ和δ的值来计算每个点的γ值并排序,选取前k个作为聚类中心点;
4)对剩余非聚类中心点依照距离最近原则进行归类。
1.2 蝙蝠算法
蝙蝠算法是一种模拟蝙蝠在飞行过程中通过发射超声波以及反射的回声来定位搜索猎物的元启发式算法。此算法基于如下假设:
1)蝙蝠以速度vi飞行在位置xi(解)附近,并且可以根据与目标的距离自动调整脉冲频率;
2)蝙蝠发出的超声波的响度A从大到小变化。
在该算法的实际应用中,通过频率f控制波长λ的变化来调整蝙蝠飞行的距离。当蝙蝠越靠近猎物时,波长取值越小,飞行距离越短。
在一个N维的搜索空间中,在第t次迭代时,第i个蝙蝠的速度和位置公式分别为
fi=fmin+(fmax-fmin)β,
(7)
(8)
(9)
其中,β的取值范围在0到1之间,是一个随机向量,x*是当前全局最优解。在求解问题前,在[fmin,fmax]的范围内为蝙蝠的脉冲发射频率初始化赋值。求解问题时,在保证波长不变的同时,在取值范围内改变蝙蝠的脉冲发射频率。开始搜索之后,每只蝙蝠的位置为
xnew=xold+εAt。
(10)
其中,ε为在-1到1范围之间的随机数,At为在第t次迭代时,所有蝙蝠的平均响度。在迭代过程中,蝙蝠的脉冲发射响度A和速率r的更新公式为
(11)
(12)
其中α和γ是响度和速率更新的比率,通常α取值在0到1之间,γ取值不小于0。蝙蝠脉冲发射响度和速率会在不断地趋近于最优解的过程中更新。基于以上公式和分析,蝙蝠算法的步骤描述如下:
1)对算法参数进行初始化:蝙蝠初始位置和速度、目标函数、脉冲发射频率范围、蝙蝠种群数量以及响度和速率;
2)通过调整蝙蝠的脉冲发射频率进而改变波长,产生新的解,并根据新解的值改变蝙蝠位置和速度;
3)产生一个随机数,如果随机数大于速率r,就从最佳解集中选取一个解在其附近形成局部解;
4)通过随机飞行产生一个新解;
5)产生随机数,如果随机数小于此时的响度,并且新解对应的适应度的值要优于之前的解对应的适应度的值,用新解替换之前的解,并更新响度和速率;
6)将蝙蝠当前的位置进行排列并选取当前的最优解,若满足结束条件,跳出并输出当前最优解,否则转回步骤2)。
2 结合蝙蝠算法改进的密度峰值聚类算法
本文通过改进后的蝙蝠算法对密度峰值聚类需要人工选取截断距离的缺陷进行改进,主要思想是通过蝙蝠算法较强的全局最优解的寻优能力,将一个评价聚类指标的函数作为适应度函数,在解的空间中进行寻优,从而避免DPC算法中由于需要手动给出截断距离而产生的不确定性。
2.1 蝙蝠算法的改进
在基本的蝙蝠算法之中,蝙蝠的速度是根据前一代的速度和位置进行更新的,但随着迭代次数的增加,蝙蝠的速度会逐渐减缓,甚至蝙蝠种群可能会出现进化停滞。受到文献[16]的启发,为了解决这一问题,本文对蝙蝠的速度更新公式(8)加入自适应惯性权重,将式(8)修改为
(13)
其中,
(14)
ωmax和ωmin分别代表最大最小自适应惯性权重,t代表当前迭代次数,N代表最大迭代次数。加入权重后,在迭代之初,ω较大,算法的全局搜索能力较强,有利于跳出局部最优,在算法迭代的后期,ω会逐渐减小,有利于在最优解的邻域内进行局部寻优,并加速算法的收敛。将蝙蝠种群设置为10,迭代次数设置为1 000,利用两种算法对同一适应度函数进行迭代实验。实验结果显示,虽然改进前后的算法都能在一定循环次数内找到最优解,但改进后的算法收敛到最优解所需要的迭代次数大大减少,算法的收敛性增强,较好地克服了基本蝙蝠算法易过早陷入局部最优的缺陷。
2.2 结合加权蝙蝠算法优化截断距离参数
在传统的DPC算法中,由式(3)和式(4)可知,密度峰值聚类的两个重要参数,局部密度和与高密度点之间的最小距离均与截断距离有关。但截断距离dc往往由人工给出,dc取值过大,会导致聚类个数多于真实簇类数;相反,dc取值过小,导致聚类个数少于真实簇类数。本文提出的WBADPC算法将聚类算法的Silhouette指标[22]作为适应度函数。Silhouette指标最早由Peter J. Rousseeuw在1986年提出。它结合内聚度和分离度两种因素,可以用来在相同原始数据的基础上评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。对于单个样本,设α是与它同类别中其他样本的平均距离,b是与它距离最近不同类别中样本的平均距离,Silhouette指标为
(15)
Silhouette指标的取值范围在[-1,1]之间,其值越接近1,说明聚类的结果就越合理。Silhouette指标结合了聚类结果的类间距离和类内距离,对于聚类结果能产生准确的评判,并且不需要先验知识,所以,本文采用Silhouette指标作为适应度函数。
本文所提出算法通过蝙蝠算法较强的寻优能力,通过多次迭代,找出能使DPC算法的Silhouette指标最大的截断距离作为对于当前数据集最合适的截断距离dc,算法的具体步骤如下。
输入:数据集Data,蝙蝠数量,最大迭代次数,响度,速率,频率的变化范围,自适应惯性权重的最大和最小值。
输出:聚类结果C。
1)数据预处理;
2)计算样本间的欧氏距离矩阵,根据距离矩阵确定截断距离的搜索空间,并生成初始解;
3)执行DPC算法,根据聚类结果生成Silhouette指标的值;
4)调整改进后的蝙蝠算法参数生成新的解,计算每个解所对应的Silhouette指标;
5)产生随机数,如果新解对应的适应度的值要优于之前的解对应的适应度的值,用新解替换之前的解,并更新响度和速率。否则保持原来的解不变;
6)若满足迭代终止条件,跳出循环并得到最优截断距离,否则转回3);
7)用所得到的最优截断距离进行密度峰值聚类,输出聚类结果。
算法的流程图如图1所示。

图1 WBADPC算法流程图Fig.1 A schematic diagram of WBADPC
3 实验结果与分析
为了验证算法的有效性,本文采用6个数据集对WBADPC算法进行测试和评价。实验环境如表1所示,所采用的数据集属性如表2所示。
3.1 评价指标
由于本文所提算法的评价指标采用Silhouette指标,为了避免重复计算Silhouette指标带来的影响,本次实验的评价指标主要采用调整互信息(adjusted mutual information,AMI)指标和调整兰德指数(adjusted Rand index,ARI)对聚类结果进行评价。
3.1.1 AMI指标 互信息MI(mutual information based scores)是一个基于信息论的概念,可以用作聚类结果的评价指标,主要用来对一些有先验知识的数据集的聚类结果进行评判。互信息可以用来衡量两个数据分布的吻合情况,如果A和B分别是M个样本的同一个数据集用两种不同聚类方法所得到的类别标签,则这两个类别标签的熵分别为

(16)
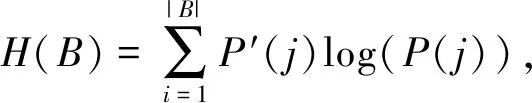
(17)
(18)
(19)
Ai和Bj分别代表,在A和B的标签之中第i类和第j类的标签,A与B之间的互信息可以定义为
(20)
而调整互信息AMI就可以表示为
(21)
MI的取值范围为[0,1],E(MI)是对MI的数学期望。AMI同样基于信息论,是对MI的一种改进,它的取值范围为[-1,1]。相比于MI来说,AMI具有更高的区分度,它的取值越接近1,说明聚类效果越好。
3.1.2 ARI指标 兰德系数(Rand index,RI)和调整兰德系数经常被用来做聚类的模型评估,在RI中,假设U是样本真实标签,而V代表聚类结果,则a为在U中属于同一类且在V中也属于同一类的数据点对数,b代表在U中属于同一类但在V中不属于同一类的数据点对数,c表示在U中不为同一类但在V中属于同一类的数据点对数,d即为在U和V中均不属于同一类的数据点对数。兰德系数RI可表示为
(22)
兰德系数的取值范围在[0,1]之间。为了使RI具有更高的区分度,引入ARI作为RI的改进,ARI可表示为
(23)
ARI的取值范围在[-1,1]之间,其结果越接近1,说明聚类结果越接近数据集的原始标签。
3.2 实验仿真与结果分析
本文选用了D31,R15和Aggregation 3个人工数据集以及Iris和Wine两个UCI数据集,和文献[23]所提供的白血病数据集Leukemia,数据集的属性如表2所示。R15,Aggregation和D31数据集均为2维数据集,D31的样本数量较多,Iris和Wine数据集为多维数据集,Leukemia数据集为基因表达数据的高维数据集,可分为3个类簇。文献[24]提出了一种基于 K 近邻的快速密度峰值搜索并高效分配样本的聚类算法(KNN-DPC)。该算法利用样本点的K近邻信息定义样本局部密度, 搜索和发现样本的密度峰值, 以峰值点样本作为初始类簇中心。将本文提出的WBADPC算法与KNN-DPC算法、标准DPC算法和DBSCAN算法进行比较。WBADPC和DPC算法在聚类中心点选取时,将所有数据点的γ值从大到小排列,选取前k个,直到满足条件
(24)

表1 实验环境Tab.1 Simulation environment
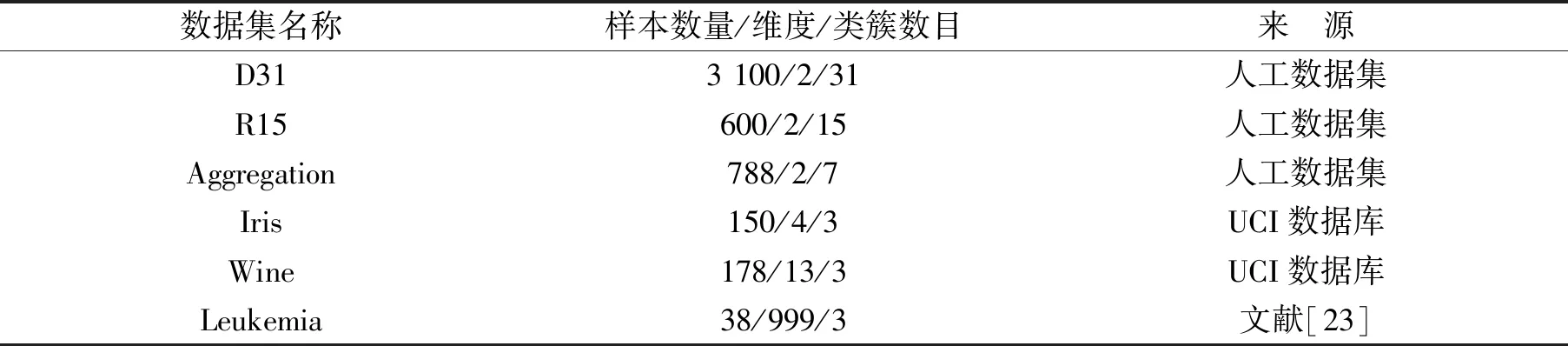
表2 所用数据集属性Tab.2 Data set attribute
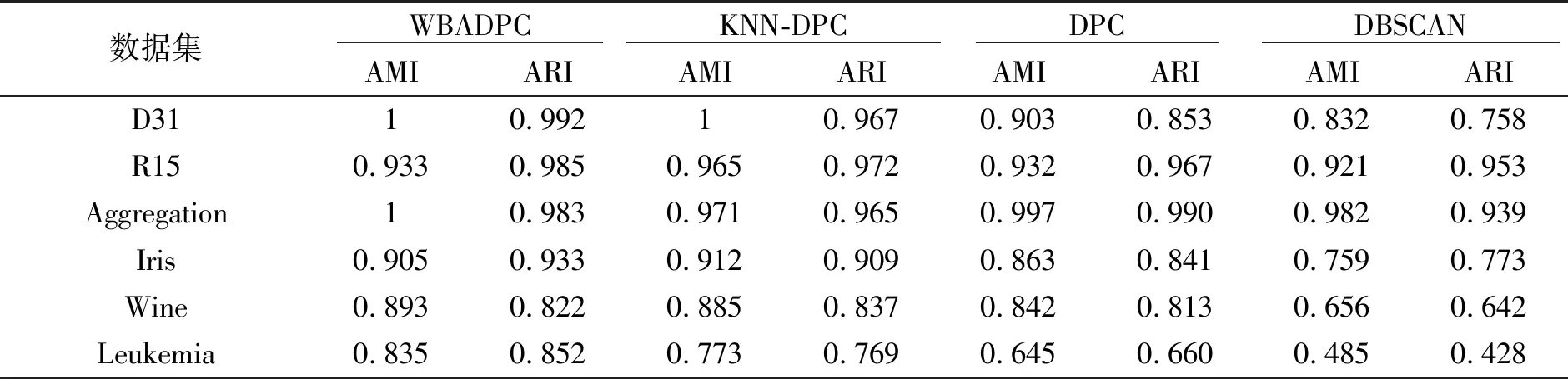
表3 4种算法在6个数据集上的实验结果Tab.3 Simulation results of four algorithms on six data sets
对于Aggregation和R15两个二维数据集来说,数据集的类簇间隔较大,样本数量较少,有利于聚类,从而会使4种算法在这两个数据集上的表现相近。而D31数据集样本数量较多,数据集整体分布复杂。从图2中可以看出,在D31数据集上前3种算法的聚类结果较好,但DBSCAN算法出现部分数据点错误聚类的情况。在Wine和Leukemia数据集上,利用主成分分析法提取主成分进行可视化,在图2中可以看出,WBADPC算法的效果略优于KNN-DPC,并且明显好于其余两种算法。4种算法在全部6个数据集上的实验结果如表3所示。图3和图4分别表示了AMI和ARI指标的对比情况,可以看出,在Iris和Wine两个多维数据集上,本文提出的WBADPC算法表现最优,KNN-DPC算法略低,DPC算法在Iris数据集上性能要差于DBSCAN。综合来看,在两个UCI的多维数据集上,WBADPC算法聚类结果准确率最高,其次是KNN-DPC,第3是DPC算法,最后是DBSCAN算法。而在高维数据集Leukemia上,WBADPC算法依旧保持良好的聚类性能,而其余3种算法的性能明显下降。
本文提出的算法在复杂度方面不仅和问题规模有关,还与蝙蝠算法的迭代次数以及适应度函数有关,所以,在提升算法准确率的基础上,在时间复杂度上略高于其余3种算法,而KNN-DPC算法则略高于DPC算法和DBSCAN算法,DPC算法和DBSCAN算法在时间复杂度上最优。4种算法空间复杂度的主要来源均为存储距离矩阵,对于样本规模为n的数据集,空间复杂度均为O(n2),量级相同。所以,本文算法在算法复杂度方面略高于其他算法,但是在准确率方面有明显的提升。

图2 4种算法在3个数据集上的聚类结果Fig.2 The clustering results of the four algorithms on the three data sets

图3 4种算法在6个数据集上的AMI对比图Fig.3 AMI comparison chart of four algorithms on 6 data sets
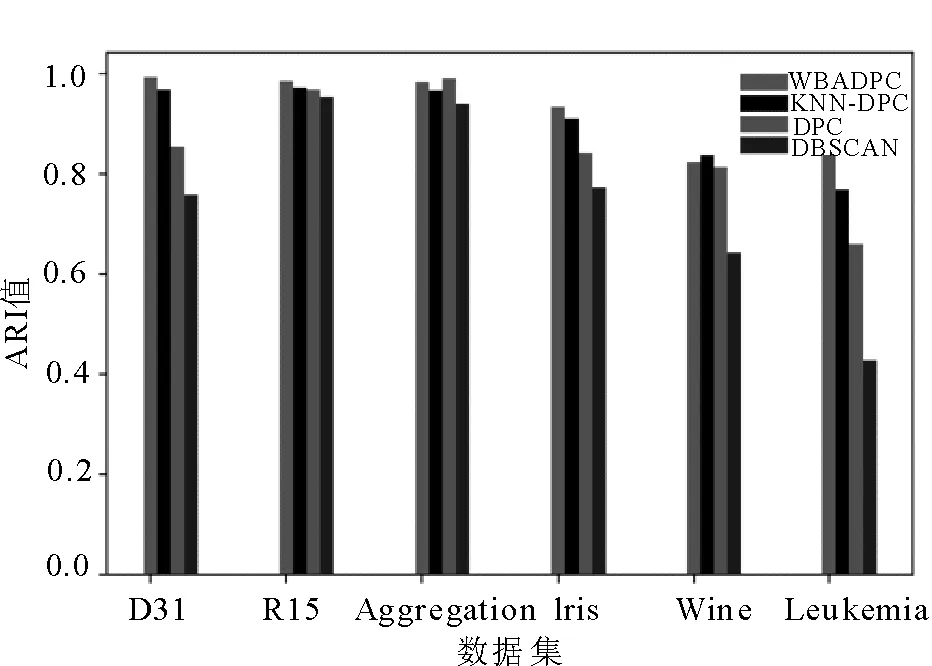
图4 4种算法在6个数据集上的ARI对比图Fig.4 ARI comparison chart of four algorithms on 6 data sets
4 结 语
为了改进密度峰值聚类算法无法自动确定截断距离的问题,本文提出一种结合蝙蝠算法改进的密度峰值聚类算法,该算法利用蝙蝠算法较强的全局寻优能力,将Silhouette指标作为适应度函数,在一定的范围内,对截断距离进行寻优。通过在人工数据集、UCI数据集以及基因表达数据集上的实验验证,可以得出结论:本文所提出的结合蝙蝠算法改进的密度峰值聚类算法能更准确地发现聚类中心点,并将非聚类中心点样本分配到合适的类簇,是一种有效的自适应聚类算法,能发现任意形状的类簇。可用于聚类任意维度、任意规模的数据。下一步研究的目标是通过优化算法有效降低算法的时间复杂度。
