基于推荐系统的大学生就业的研究
2019-07-21尚衍亮
尚衍亮

摘 要:随着中国经济的腾飞,互联网行业进入发展的快车道,招聘网站如雨后春笋般出现,一时间互联网上充斥着大量的招聘信息。为解决当前环境下招聘信息数量庞大,数据分散,学生无法及时获取到适合的招聘岗位的问题,提出了基于语义分析的就业推荐系统。利用python网络爬虫抓取各大网站的招聘信息,将招聘信息汇总,避免了招聘信息的分散。使用分词技术,将爬取到岗位信息进行分词,结构化处理,计算招聘岗位之间的相似度,提高岗位推荐的准确率。通过对现抓取的所有数据进行评测,实验结果表明,该方法可以准确的找出相近的岗位。
关键词:推荐系统数据挖掘高校就业
一、研究背景
近年来我国招聘行业发展迅速,然而,如何使求职者全面充分了解真实的用人单位需求,如何让用人单位能更加便捷高效的匹配到所需的人才,一直都是社会多方人士所考虑的问题。与此同时,大学生在求职过程中始终存在着技能与岗位不匹配的问题,双方信息的不对称,也大大增加了招聘的成本。招聘行业的转型,已经成为了一个亟待解决的问题。
国家统计局数据显示,全国目前共有在校大学生2695.8万,用户规模大,这使得技能共享的市场十分广阔,同时,据央视报道,到2020年,高端技术人才缺口将会达到2200万,这表明社会对于技能型人才的需求也在日益增长。那么,构建一个完备的,针对大学生技能共享提升、智能求职的平台,是尤为重要的。
就业推荐,是指根据用户的信息和企业的信息,借助相关技术,给用户推荐合适的企业,给企业推荐合适的员工。用户在浏览就业信息网站的时候,面临的企业如此之多,如何在众多的企业中找到自己合适的岗位,要花很长的时间去寻找,同样,企业也面临同样的问题,如何在众多的应聘者中找到自己合适的人选,要花很长的时间去寻找。网站提供了数千万个企业,用户却只能使用分类浏览、分类导航、搜索等此类通用的网站工具来搜索信息。这就要求用户对所要搜索的企业有相当清楚的了解和把握。然而面对如此众多的企业,绝大多数的用户基本不会有效整合网站信息资源的,这就很容易出现所谓的“信息迷航”。诸如此类现象:网站存在有用户需要的企业,然而用户却没有找到,或找到的企业不是最适合自己的。
二、主要技术
1.推荐系统
推荐系统产生推荐列表的方式通常有两种:协同过滤以及基于内容推荐,或者基于个性化推荐。协同过滤方法根据用户历史行为(例如其购买的、选择的、评价过的物品等)结合其他用户的相似决策建立模型。这种模型可用于预测用户对哪些物品可能感兴趣(或用户对物品的感兴趣程度)。基于内容推荐利用一些列有关物品的离散特征,推荐出具有类似性质的相似物品。
2.结巴分词
结巴分词开源的中文分词工具,主要使用三种算法进行分词:1.基于前缀词典实现高效的词图扫描,生成句子中汉子所有可能成词情况所构成的有限无环图(DAG);2.采用了动态规划查找最大概率路径找出基于词频的最大切分组合;3.对于为登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
三、语义文本的获取
1.目前主流的招聘网站有十多家,每天的招聘岗数量有几十万条,如果采用手工抓取的话,既耗时又耗力。于是采用了python爬虫技术,利用自建的爬虫框架,构建自动岗位信息抓取工具,这样既省时又省力,并且将抓取到的数据存放于数据库中,方便随时使用。同时在抓取的时候,按照职位种类抓取,这样可以以保证抓取的数据已经存在于一个较大的聚类中了。
2.主要抓取的數据包括 :岗位名称,公司,工作地点,学历要求,工作经验,性别,最低薪资,最高薪资,职位种类,岗位职责等。
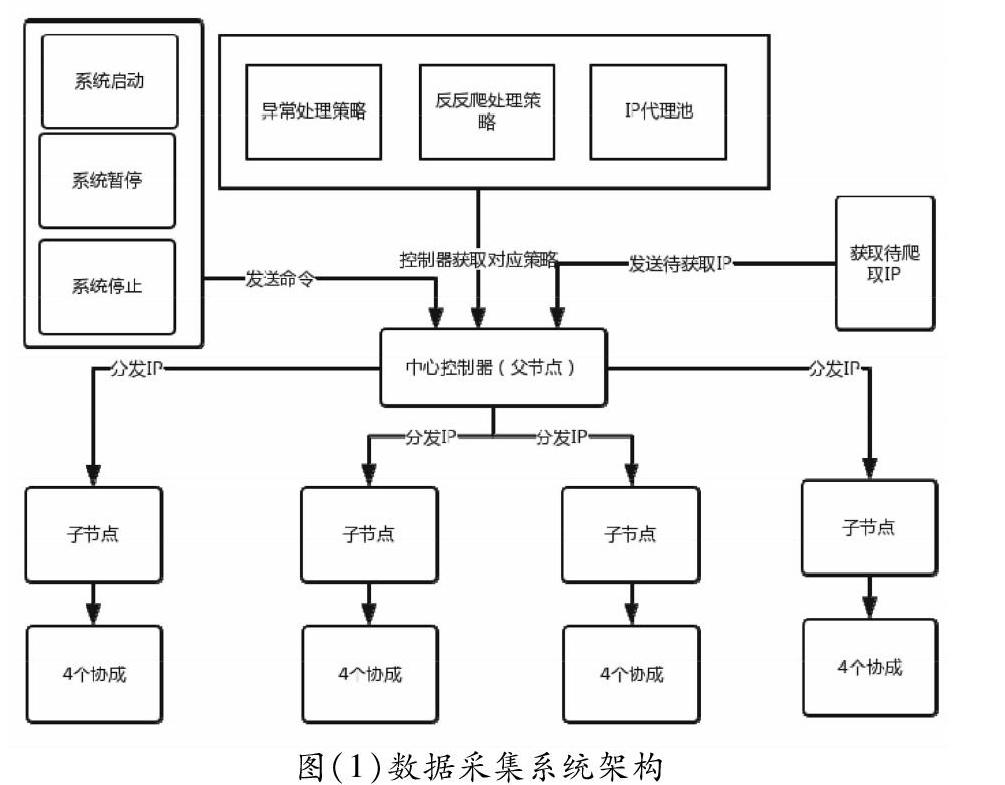
3.系统架构
四、语义文本的建立
根据已经抓取到的招聘信息,我们可以发现,抓取回来的信息主要可以分为两类,一种是具体的属性,比如学历要求,工作经验等信息,另一种是岗位职责。由此我们在建立语义文本的时候分为两类建立。
1.一级语义文本的建立及处理
1.1建立
在进行一级语义文本建立时,我们采用了自顶而下的构建方式,并将部分信息剔除。我们将岗位名称,工作地点,学历要求,工作经验,性别,薪资定义为顶级属性,而后在进行二级定义,而例如学历就拥有二级属性:专科,本科,硕士,博士。最终建立所需的的语义文本如下图(4.1)
1.2 处理处理过程将按照表格中的数据选择性的列举:
1.2.1 岗位名:例如初级java工程师;中级java工程师;高级java工程师,这三个岗位虽然属于java类岗位,但是对于java的水平要求却不一样。因此需要对岗位名称进行分词。提取出关键的信息,这样在进行岗位相似度比较的时候,更准确。下表是结巴分词的效果:
1.2.2 经验要求:公司对于求职者的经验要求一般以年计算,其中应届生的经验看为0,最后将其映射为整形数据:0,1,2,3,4……
1.2.3学历要求:公司对于求职者的学历要求大致分为:大专,本科,研究生,博士生,将其映射为整形数据:大专=0;本科=1;研究生=2;博士生=3。
1.2.4最低薪资和最高薪资:本身就是具体的整型数据。
1.2.5性别:性别只有男,女两种类型,将其映射为整形为:男-0;女-1。
2.二级语义文本的建立二级语义文本的建立主要依赖于岗位职责,而对于岗位职位,一般是文本的形式,如下示例:
任职要求
1、熟练掌握Java及面向对象设计开发,对部分Java技术有深入研究,研究过优秀开源软件的源码并有心得者优先;
2、了解SOA架构理念、实现技术;熟悉常见设计模式,熟练掌握Spring、myBatis等框架;
3、熟练掌握MySQL应用开发、数据库原理和常用性能优化和扩展技术,以及NoSQL,Queue的原理、使用场景以及限制;
4、研究过http协议、搜索引擎、缓存、jvm调优、序列化、nio、RPC调用框架等,有相应实践经验者优先;
5、参与过大型复杂分布式互联网(特别是电商)用户端WEB/API系统的设计开发者优先。在建立二级语义文本的时候需要提取其中的专业技能要求,在这里利用的是结巴分词。具体细节如下:
Step1: 将所有岗位的岗位职责从数据库中提取出来
Step2: 利用结巴分词从所有的所属相同职位种类的岗位职责中尽可能提取多的专业技能要求,并形成部分限定词库,又因为分词效果不能完全的找出所有的专业技能要求,需要手工添加和剔除。
Step3: 利用限定词库,找出每个岗位的岗位职责中的专业技能要求。并保存到数据库中。
Step4:以java这个岗位为例,最终找出的语技能要求如图所示
五、相似度计算
1.这里根据一级语义文本计算岗位间的相似度使用欧式距离相似度。
又名欧几里得度量是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。可以看出,当n=2时,欧几里得距离是平面上的两点的距离。
2.计算步骤
2.1.设定目标找出10个不同分类的岗位,来找出这10个岗位的10个相似度最高的岗位。示例如下:
2.2.根据一级语义文本计算物品间的相似度从数据库中找出与之对应分类的所有岗位,这样保证了同属于同一个聚类中,然后计算岗位名称的文本相似度,然后计算其余属性的欧几里得距离
2.3.根据二级语义文本计算物品间的相似度从数据库中找出与之对应分类的所有岗位的岗位职责,计算出文本相似度,这里仍然采用欧几里得距离。
2.4.根据两次计算出的欧几里得距离,计算平均值,并选出top10.
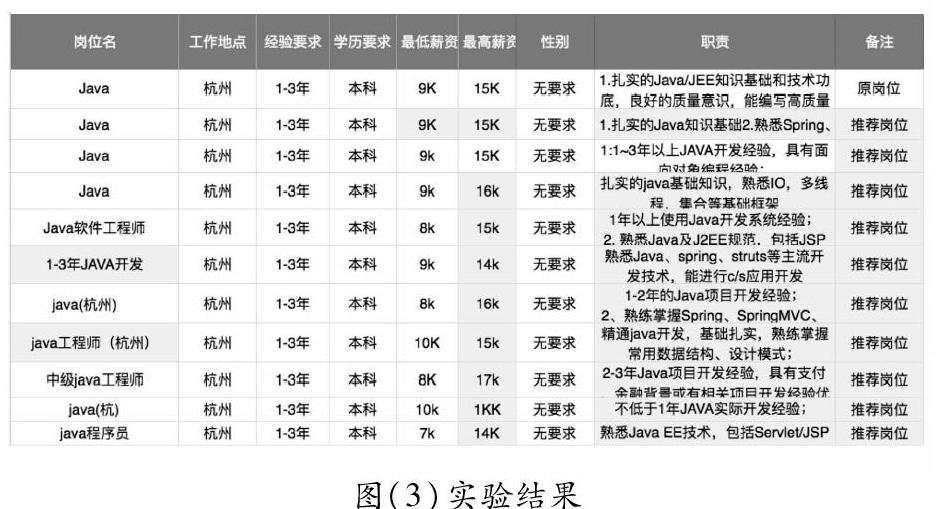
六、实验结果
从实验结果中可以看出,该系统推荐精度较为满意。两个岗位间的相似度较高,由此可以得出,该推荐结果符合推荐预期。
[参考文献]
[1]隋占丽, 李文, 李影, et al. 面向大学生就业的协同过滤推荐算法与推荐系统研究[J]. 山东农业工程学院学报, 2017, 34(4):3-4.
[2]张骏. 推荐系统多样性研究及其在就业推荐中的应用[D].山东师范大学,2017.
[3]陈朝冲. 基于高校毕业生与招聘企业双选的推荐系统[D].西南科技大学,2017.
[4]黄贵斌,孙柳,黄佳玲,余发明,贾礼平.基于爬虫技市的就业推荐系统设计与实现[J].内江科技,2018,39(01):59-61.
[5]揭正梅. 基于协同过滤的高校个性化就业推荐系统研究[D].昆明理工大学,2015.
[6]刘玉华,陈建国,张春燕.基于数据挖掘的国内大学生就业信息双向推荐系统[J].沈阳大学学报(自然科学版),2015,27(03):226-232.
[7]吴琼. 基于改进K-Means聚类方法的高校就业推荐系统研究[D].大连海事大学,2015.
(作者單位:江苏师范大学智慧教育学院,江苏 徐州 221000)
