基于强化学习的Lustre文件系统的性能调优
2019-07-15张文韬程耀东
张文韬 汪 璐 程耀东
1(中国科学院高能物理研究所计算中心 北京 100049)2(中国科学院大学 北京 100049)
高能物理计算是一种数据密集型计算,存储系统是其性能决定因素之一.未来10年内,各大物理实验如江门中微子实验、高海拔宇宙线实验、北京谱仪实验等将累积近100 PB的物理数据.大规模的数据处理给存储系统提出了“百GBs的聚合带宽、数万个客户端并发访问、数据可靠性和可用性、跨域站点数据共享以及数据长期保存”等需求和挑战[1].
高能物理数据处理主要包括模拟计算、重建计算以及物理分析3种类型,每种计算类型各有其特点.高能物理计算中数据是1次写入、多次读取.通过监控计算节点上的用户作业,可以得到文件系统的访问模式:大部分文件的连续读请求大小分布在256 KB~4 MB之间,每2个连续读请求之间都有offset,65%的offset绝对值分布在1~4 MB之间,这说明文件的读访问方式为大记录块的跳读.
存储系统管理员往往会根据系统的历史情况以及系统的实时状态,调节相应的参数值以提高系统的访问性能[2].参数调节和系统的反馈之间是有延时的,如果采取了连续多个调节动作,很难确定究竟是哪个动作起了作用,或者每个动作对结果的影响是多少.因此,人工调节不免存在偏差,况且庞大的参数搜索空间、负载的连续性、负载和设备的多样性等因素也决定了传统方法是非常低效的.传统的参数配置算法包括基于模型的控制反馈算法和无模型的参数搜索2大类.前者需要系统管理员具备丰富的先验知识且不支持动态负载变化;后者在参数搜索空间很大时优化效率很低.
强化学习由于其优秀的决策能力在人工智能领域得到了广泛应用.然而,早期的强化学习主要依赖于人工提取特征,难以处理复杂高维状态空间下的问题.随着深度学习的发展,算法可以直接从原始的高维数据中提取出特征.深度学习具有较强的感知能力,但是缺乏一定的决策能力;而强化学习具有较强的决策能力,但对感知问题束手无策.因此,将两者结合起来,优势互补,能够为复杂状态下的感知决策问题提供解决思路.
把调节引擎看作是智能体,把存储系统看作是环境,存储系统的参数调节问题是典型的顺序决策问题.因此,我们很自然地将强化学习引入到存储系统的参数调节中.本文基于高能物理计算的数据访问特点,设计并实现了基于强化学习的参数调节系统,实验表明,该系统可使Lustre文件系统的吞吐率提升30%左右.
1 相关工作
1.1 强化学习基础
Markov决策过程(Markov decision process, MDP)是强化学习的最基本的理论模型[3].在MDP中,Agent和环境之间的交互过程可如图1所示:
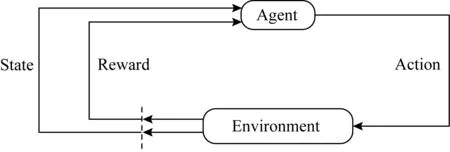
Fig. 1 Interactive process of reinforcement learning图1 强化学习交互过程
Agent的目标是找到1个最优策略π*,使得它在任意状态s和任意时间步骤t下,都能够获得最大的长期累积奖赏,即:
(1)
强化学习的目标是寻找最优状态值函数(optimal state value function):
(2)
基于此推导出贝尔曼方程:
Vπ(s)=Eπ[rt+1+γVπ(s′)].
(3)
强化学习的方法分为基于模型的方法和无模型的方法,而现实世界中大部分问题模型是未知的,所以解决无模型的方法是强化学习的精髓.无模型即意味着状态转移概率是未知的,这样计算值函数时期望是无法计算的,如何计算期望呢?强化学习在此处引入了蒙特卡罗方法.
蒙特卡罗法,即经验平均法.所谓经验,是指利用该策略做很多次实验,产生很多幕数据,这里1幕是1次实验的意思,平均就是求均值.利用蒙特卡罗方法求状态s处的值函数时,又可以分为第1次访问蒙特卡罗方法和每次访问蒙特卡罗方法.计算为
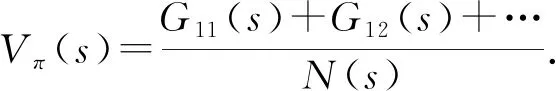
(4)
蒙特卡罗的方法需要等到每次实验结束,所以学习效率不高,于是人们又提出了时间差分法(temporal difference, TD),其是蒙特卡罗法与动态规划法的结合,不用等到实验结束,而是在每步都更新.TD方法更新值函数的公式为
V(St)←V(St)+α[rt+1+γV(St+1)-V(St)].
(5)
根据行动策略和评估策略是否是1个策略,时间差分法又分同策略法与异策略法.时间差分法的同策略法即Sarsa方法,异策略法即Q-learning方法.
1.2 强化学习算法
本节介绍调节系统用到的3种强化学习算法:DQN(deep q network)算法、A2C(synchronous advantage actor critic)算法、PPO(proximal policy optimization)算法.
1.2.1 DQN算法
DQN是基于Q-learning的算法,其对Q-learning的修改主要体现在3个方面[4]:
1) DQN利用深度卷积神经网络逼近值函数.利用神经网络逼近值函数的做法在强化学习领域早就存在了,可以追溯到20世纪90年代.当时人们发现用深度神经网络去逼近值函数常常出现不稳定不收敛的情况,所以这个方向一直没有突破,那DQN做了什么其他的事情呢?
2) DQN利用了经验回放对强化学习的学习过程进行训练.人在睡觉的时候,海马体会把1天的记忆重放给大脑皮层.利用这个启发机制,DQN构造了一种新的神经网络训练方法:经验回放.训练的前提是训练数据是独立同分布的,而通过强化学习采集到的数据之间存在着关联性,利用这些数据进行顺序训练,神经网络当然不稳定.经验回放可以打破数据间的关联,从而使网络得以收敛.
3) DQN独立设置了目标网络来单独处理时间差分算法中的TD偏差.我们称计算TD目标时所用的网络为TD网络.以往的神经网络逼近值函数时,计算TD目标的动作值函数所用的网络参数为θ,与梯度计算中要逼近的值函数所用的网络参数相同,这样就容易使得数据间存在关联性,训练不稳定.为了解决这个问题,DQN中计算TD目标的网络表示为θ-,计算值函数逼近的网络表示为θ,用于动作值函数逼近的网络每一步都更新,而用于计算TD目标的网络每个固定的步数更新1次.因此值函数的更新变为

(6)
1.2.2 从AC(actor critic)算法到A2C算法的演化
当要解决的问题动作空间很大或者动作为连续集时,值函数方法无法有效求解.策略梯度法是将策略进行参数化,利用线性或非线性函数对策略进行表示,此时强化学习的目标回报函数可表示为

(7)
τ表示智能体的行动轨迹.我们的训练方法则可以表示为
θt+1←θt+αθU(θ),
(8)
此时问题的关键是如何计算策略梯度:
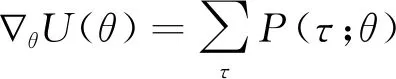
(9)
利用经验平均来估算梯度:
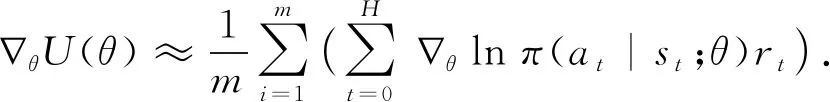
(10)
式(10)的意义在于,回报越高的动作越努力提高它出现的概率.但是某些情形下,每个动作的总回报rt都不为负,那么所有的梯度值都≥0,此时每个动作出现的概率都会提高,这在很大程度下减缓了学习的速度,而且也会使梯度的方差很大.因此需要对rt使用某种标准化操作来降低梯度的方差.具体地,可以让rt减去1个基线b(baseline),b通常设为rt的1个期望估计,通过求梯度更新θ,总回报超过基线的动作的概率会提高,反之则降低,同时还可以降低梯度方差(证明略).这种方式被叫作行动者-评论家体系结构.
A3C(asynchronous advantage actor critic)算法为了提升训练速度采用异步训练的思想,利用多个线程[5].每个线程相当于1个智能体在随机探索,多个智能体共同探索,并行计算策略梯度,对参数进行更新.相比DQN算法,A3C算法不需要使用经验池来存储历史样本并随机抽取训练来打乱数据相关性,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度.与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练.
在A3C的基础上,OpenAI又提出了A2C.如图2所示,2个算法的不同点在于,在A3C中,每个智能体并行独立地更新全局网络,因此,在特定时间,智能体使用的网络权重与其他智能体是不同的,这样导致每个智能体使用不同的策略在探索更多的环境.而在A2C中,所有并行智能体的更新先被统一收集起来,然后去更新全局网络,全局网络更新完后再将权重分发到各个智能体.为了鼓励探索,每个智能体最后执行的动作会被加入随机噪声.
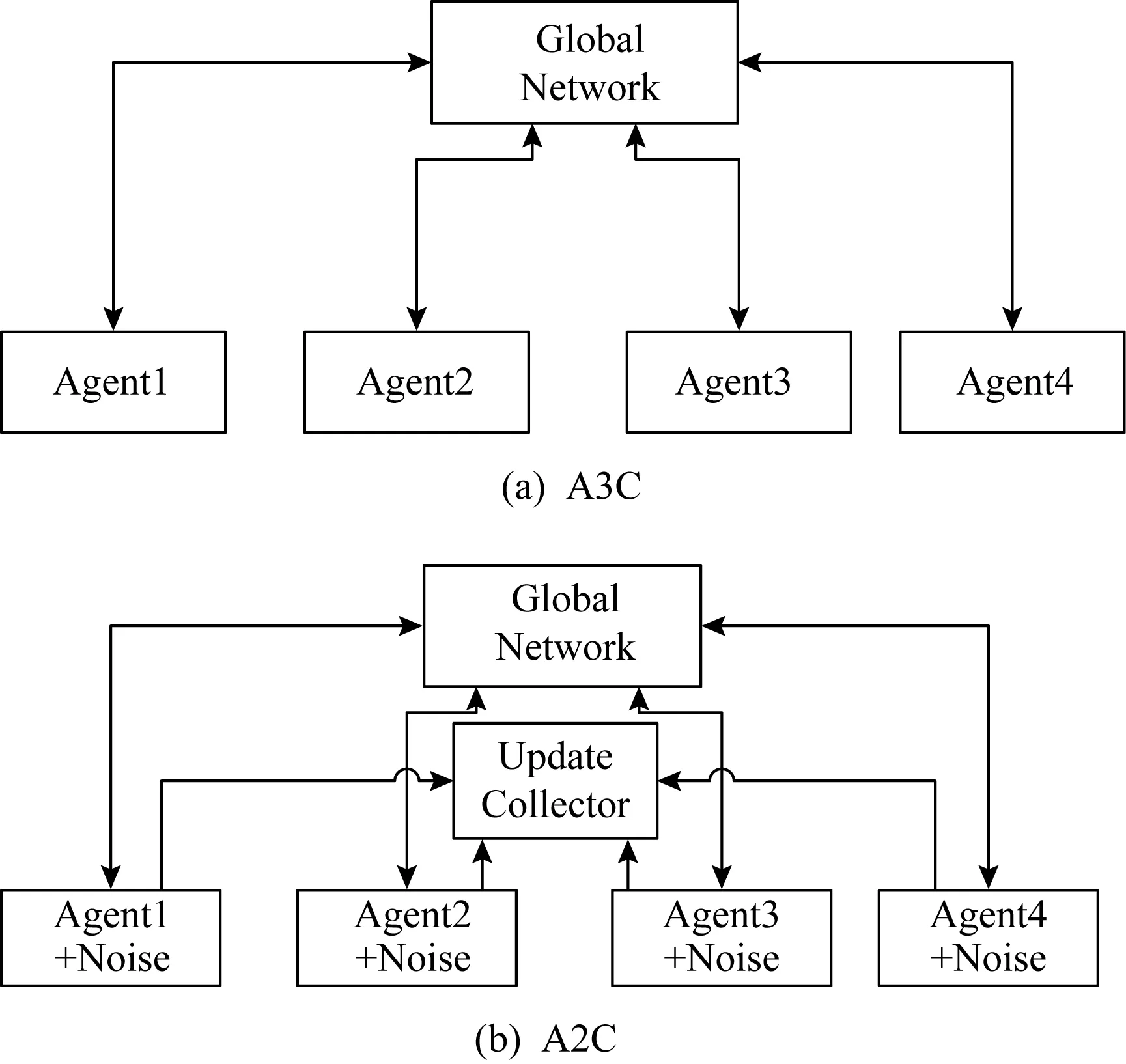
Fig. 2 Comparison of parameter updating methodsbetween A3C and A2C图2 A3C与A2C参数更新方式的对比
1.2.3 从TRPO算法到PPO算法的演化
对于普通的策略梯度方法,如果更新步长太大,则容易发散;如果更新步长太小,即使收敛,收敛速度也很慢,因而实际情况下训练常处于振荡不稳定的状态.文献[6]为了解决普通的策略梯度算法无法保证性能单调非递减而提出了TRPO(trust region policy optimization)算法,TRPO的主要改进是,它可以设置较大的步长,加快学习速度,同时对目标函数进行优化时有一定的约束条件,满足该约束条件后,优化是安全的,并能从数学上证明优化单调递增.约束表示新旧策略差异的KL散度期望小于一定值情形下最大化下面目标表达式,通过KL散度来表示新旧策略差异,它小于一定值表示1个置信域,在这个置信域内进行优化.其目标函数:
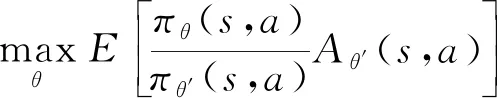
(11)
TRPO的标准解法是将目标函数进行一阶近似,约束条件利用泰勒进行二阶展开,然后利用共轭梯度的方法求解最优的更新参数.然而当策略选用深层神经网络表示时,TRPO的标准解法计算量会非常大.因为共轭梯度法需要将约束条件进行二阶展开,二阶矩阵的计算量非常大.PPO是TRPO的一阶近似[7],把TRPO中的约束放到目标函数中,减少了计算量,可以应用到大规模的策略更新中,其目标函数为
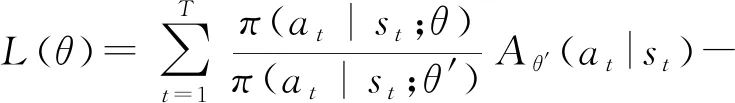
(12)
1.3 参数调优
参数调优是一个充满挑战的研究领域.
传统的方法有控制反馈算法与参数搜索算法.控制反馈算法是基于模型的方法,当已知负载运行情况且该负载情况非常简单时效果良好,但是此方法往往需要管理员设置关键参数的取值[8].参数搜索算法往往是针对特定系统的特定负载进行一次搜索的过程[9],当负载变化时其不适用.
文献[10]提出了运用神经网络来加速传统的搜索方法.文献[11]最先尝试了运用深度强化学习算法来进行参数调优,但是只是针对1台单独的服务器.文献[12]开发了一种系统来对更大规模的集群进行调参,但是其存在5个缺点:
1) 调节参数的范围较小,其只调节了2个参数.
2) Reward的设置过于简单,不能适应复杂且动态变化的负载.
3) 状态State的设置有误,其将每个客户端的状态信息作为智能体的输入,但是智能体针对每个客户端的决策应是相互独立的,即智能体的输入应是每个单独客户端的状态,返回的动作信息应由接口负责将其正确分发.
4) 训练过程未做批标准化,这样会导致训练不稳定,模型难以收敛.
5) 强化学习算法发展迅速,最初的DQN算法无论是在训练速度以及模型效果上,已经与前沿算法有了显著差距.
2 参数调节系统的设计与实现
如图3所示,系统由策略节点和目标集群组成.策略节点包含强化学习智能体以及信息接口,目标集群上的每个节点都包括1个用来收集节点信息的Monitor和1个用来执行参数调节动作的Actor.系统运行时,每个节点的Monitor每隔固定的时间会收集系统状态信息,并将信息发送给接口,接口把状态信息发送给智能体,智能体根据状态信息返回动作信息,并将其发回给接口,由接口将该动作发送给对应的节点,该节点的Actor负责执行调节动作.然后不断迭代执行上述过程,直至满足终止条件.在这整个的交互过程中,强化学习智能体是在不断训练提升的.
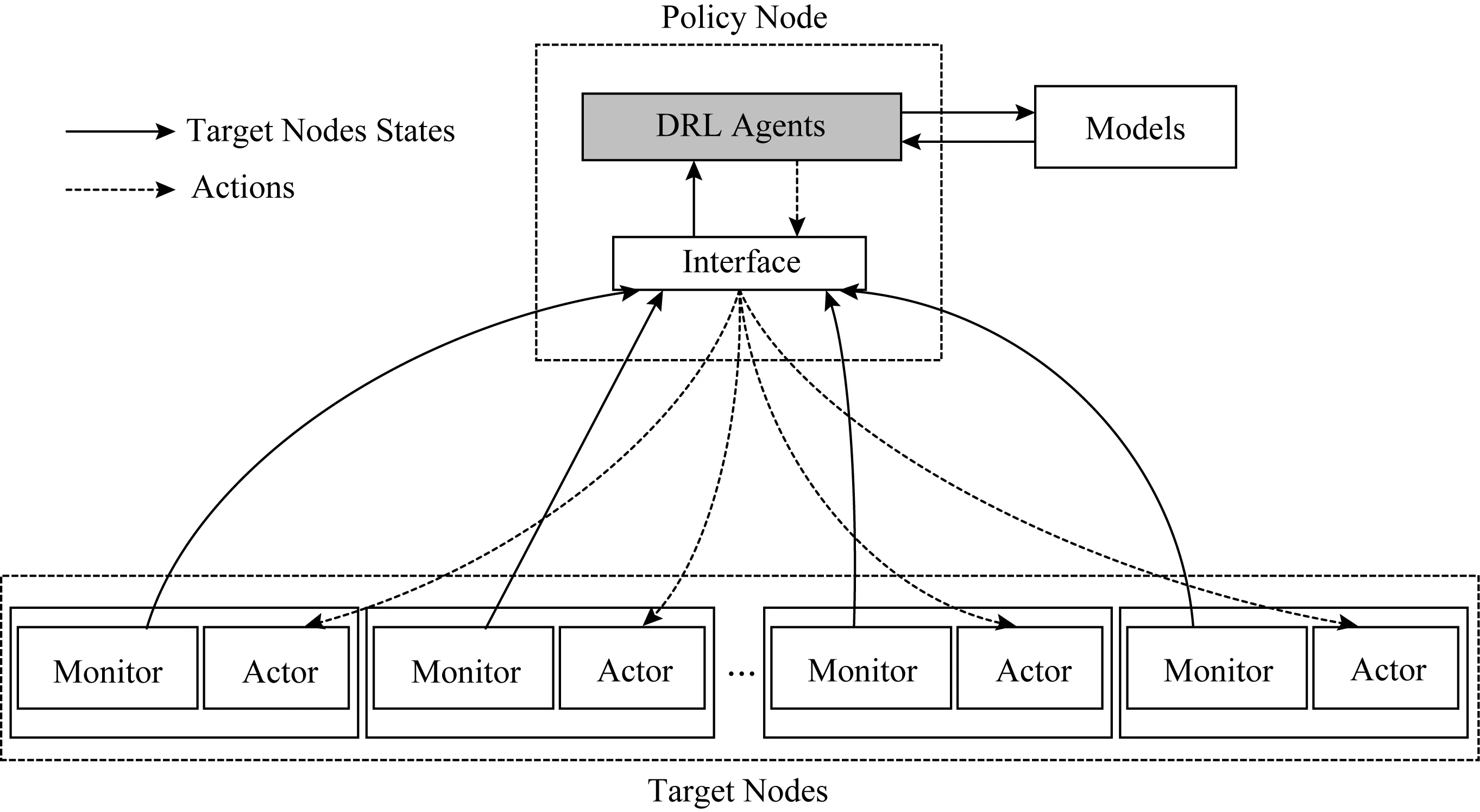
Fig. 3 Framework of parameter tuning system图3 参数调节系统框架
在实际的部署过程中,策略节点应部署在目标集群外,以尽量降低系统运行过程中对目标集群的影响.并且,策略节点应尽可能地部署在含有GPU的节点上,以加快训练速度.
2.1 参数调节系统的状态信息
类似于人类需要对环境信息了若指掌后才能做出好的决策一样,强化学习中的状态信息是十分重要的,算法会分析这些信息并做出决策.传统的机器学习方法需要大量的特征工程,近年来深度学习的飞速发展,已经证明其拥有强大的感知能力,所以深度强化学习算法只需要把状态信息输入深度神经网络,神经网络会自动抽取重要特征进行训练.
在做状态信息选取时,应尽可能地把跟系统性能相关的因素都包含进来.本文选取的部分状态信息如表1所示:

Table 1 Status Information表1 状态信息
2.2 参数调节系统的动作信息
动作决定了参数应如何调节,按离散动作空间来处理,为每个参数指定1个步长,则每个参数对应2个动作:调高和调低,调高即当前参数加步长,调低即当前参数减步长.此外,系统如果根据状态信息判断当前没有需要调节的参数,那么也应可以选择什么都不做.这样,动作空间即为:2×参数个数+1.
从安全的角度考虑,还应为每个参数设置范围,当调节后的值大于或小于该范围时,相应地设置值为最大值或最小值,以保证系统的正常运行.
当性能优化目标确定时,系统应针对该优化目标进行参数选取.这需要存储领域一定的先验知识,即需要知道所关注的性能变化是与哪些参数相关的.如果将存储系统的全部参数都纳入进来,动作空间会很大,模型不好收敛.本文的目标性能是吞吐率,选择的参数有7个:
1) 最大脏数据量(max dirty space, MD),对象存储客户端(object storage client, OSC)中可以写入并排队等候的脏数据量.
3) RPC最大并发处理数(max RPCs in flight, MRF),从OSC到其OST的最大可处理的并发RPC数.
4) 文件预读的最大数据量(max read ahead space, MRA).
5) 客户端缓存的最大非活动数据量(max cached space, MC).
6) 完整读取文件的最大大小(max read ahead whole space, MRAW).
7) 线程预取的最大文件属性数(statahead max, STM).
参数相关信息如表2所示:
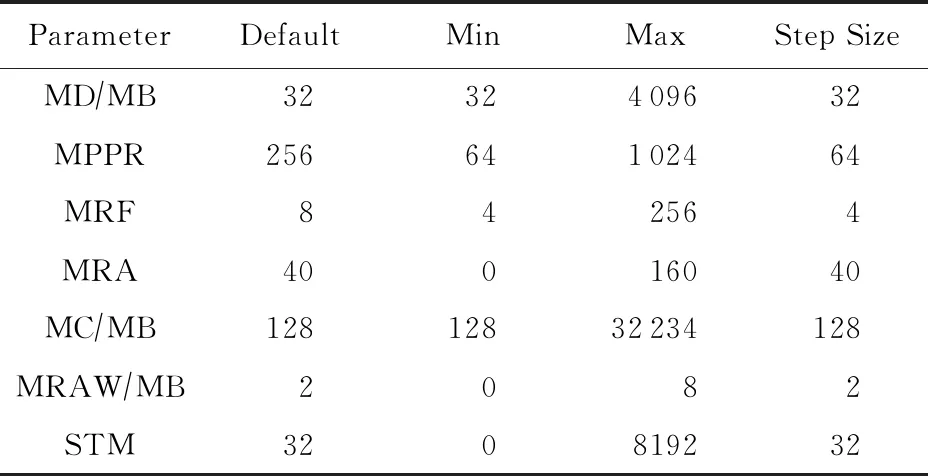
Table 2 The Parameters Selected in This Paper andTheir Related Attributes表2 选取的参数及其相关属性
2.3 参数调节系统的奖励信息
奖励信息的设计是强化学习最关键之处,因为模型的训练是依赖奖励信息进行的,奖励信息设计的好坏往往决定了1个强化学习算法最后能不能成功应用.
分布式存储系统的负载是不断变化的,如果只是简单定义奖励信息为当前吞吐率与上一时刻吞吐率之差,当负载剧烈变化时,奖励信息会相应有很大变化,那么此时的奖励信息系统无法分辨是因为负载变化导致,还是因为参数调节导致模型无法收敛.
如果不只是考虑当前时间点的吞吐率跟上时间点的吞吐率差,而是考虑动作执行后某一时间段内的吞吐率变化情况作为奖励信息,比如最近一定步数N的吞吐率差,此处用e表示,即:
(13)
这样当步数选取合适的值时,可以克服某个时间点(或某个时间段)负载剧烈变化导致奖励信息受影响的问题.γ值的选取代表了是更关心当下的奖励还是长期奖励.
可能会出现这个时间窗口内,负载都一直在不断加大,从而导致奖励信息因为负载的原因一直在变大,这样的情况可以接受的,并且奖励信息也理应给高,因为这代表系统利用率高(除了吞吐率外也考虑系统的利用率).
2.4 参数调节系统的接口模块
接口模块介于强化学习算法模块与目标集群之间,负责2个模块之间的消息通信,使得2个模块可以独立开发而互相不影响,践行了强内聚、松耦合的设计模式.
本文的消息通信模块选用了ZeroMQ,它是一种基于消息队列的多线程网络库,其对套接字类型、连接处理、帧、甚至路由的底层细节进行抽象,提供跨越多种传输协议的套接字,可并行运行,分散在分布式系统间.ZeroMQ将消息通信分成4种模型,分别是1对1结对模型、请求回应模型、发布订阅模型、推拉模型.基于系统的架构,本文采用了请求回应模型.
2.5 参数调节系统的神经网络模型
1个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从1个有限维空间到另一个有限维空间的Borel可测函数,此即万能近似定理[13].万能近似定理意味着无论我们试图学习什么函数,我们知道1个大的多层感知器一定能够表示这个函数.具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化.在很多情况下,使用更深的模型能够减少表示期望函数所需单元的数量,并且可以减少泛化误差.
深度学习与强化学习的结合,即用深度神经网络去逼近强化学习的值函数或策略函数.本文我们采用Pytorch 0.4实现了含3个隐藏层的全连接神经网络,每个隐藏层的单元数量是状态空间的2倍,激活函数为ReLU函数,优化算法为Adam算法.
3 验证系统调节效果的实验
3.1 实验环境
整个存储系统有2个服务器节点和2个客户端节点.2个服务器节点中1个为元数据服务器(meta data server, MDS)节点,1个为对象存储服务器(object storage server, OSS)节点,对象存储服务器管理着22个对象存储目标(object storage target, OST).这些服务器节点在测试期间均为闲置节点,以避免其他负载对测试结果的影响.2个客户端节点采用相同的配置:8个Intel®Xeon®CPU E5620@2.40 GHz,32 GB RAM,网络带宽为10 GBs.
策略节点配置有24个Intel®Xeon®CPU E5-2650 v4 @ 2.20 GHz,64 GB RAM,以及2个NVIDIA Tesla K80 GPU.
本文的分布式文件系统选用了Lustre(2.5.3).强化学习算法使用了Pytorch(0.4)实现.
3.2 测试工具
本文选用了Iozone(3.479)来进行测试.Iozone是1个文件系统的 Benchmark 工具,可以测试不同的操作系统中文件系统的读写性能.
3.3 测试项
本文选取7个测试项及其定义为:
1) Write.测试向1个新文件写入的性能.
2) Re -Write.测试向1个已存在的文件写入的性能.
3) Read.测试读1个已存在的文件的性能.
4) Re-Read.测试读1个最近读过的文件的性能.
5) Strided Read.测试跳跃读1个文件的性能.
6) Random Read.测试读1个文件中的随机偏移量的性能.
7) Random Write.测试写1个文件中的随机偏移量的性能.
测试以吞吐量模式运行,指定每个客户端节点启动16个进程来并行读写.测试文件大小8 GB,文件块大小1 MB,跳读跨度为2 MB.测试时会在测试目录里生成各个节点的数据包,测试完成后在日志文件里会看到各个节点的读写速度、最大速度、最小速度、平均速度、总的吞吐量.
3.4 实验流程
1) 采用Lustre默认参数配置测试3次,取其测试结果均值作为 baseline.
2) 启动Iozone测试,独立地对每个算法训练一定的时间,将训练好的模型储存以备调用.
3) 将系统参数重置为默认值.
4) 启动Iozone测试,同时启动调节系统,每个算法测试3次后,取其测试结果均值得到最终结果.
3.5 实验结果
搭建好测试环境后,我们对各强化学习算法进行了测试.测试前,对每个算法模型预先训练24 h,后对每个算法测3次(每次测试花费时长约10 h),取其均值作为测试结果,如表3所示,测试数据为32个并发读写进程的平均吞吐率.为了更加直观地体现测试结果,我们采用柱状图对测试数据进行可视化,但由于各测试项数据差异较大,致使数据值较小的测试项展示效果不太明显,故又对测试数据进行了标准化(范围100~200),如图4所示.
Table 3 Performance Test Data表3 各算法性能测试数据 KBs
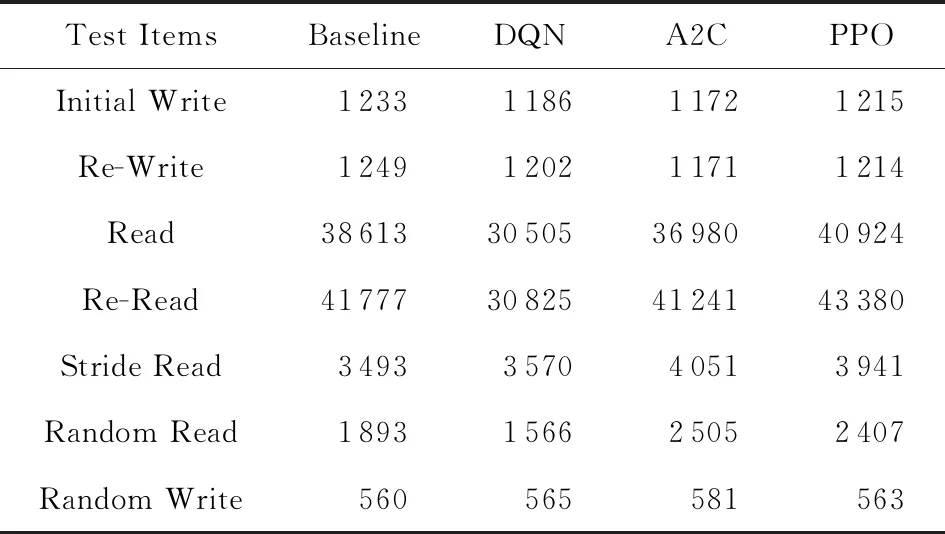
Table 3 Performance Test Data表3 各算法性能测试数据 KBs
Test ItemsBaselineDQNA2CPPOInitial Write1233118611721215Re-Write1249120211711214Read38613305053698040924Re-Read41777308254124143380Stride Read3493357040513941Random Read1893156625052407Random Write560565581563
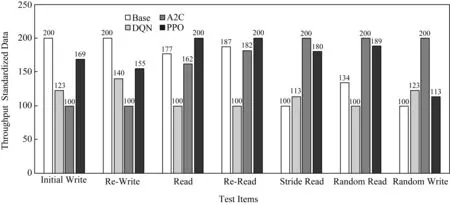
Fig. 4 Performance test results图4 各算法性能测试结果
可以看到,在跳读和随机读测试项上,A2C和PPO强化学习算法都有明显的提升效果.而DQN算法在这种负载多变的测试环境上表现较差,这在文献[12]中也有所体现,其测试结果指出DQN算法在测试读写比例为1∶1时性能几乎没有提升,本文的测试读写比例即为1∶1.因此,针对存储系统参数调优任务来说,策略梯度方法是明显优于值函数方法的.具体来说,虽然PPO算法对5个测试项都有性能提升,而就高能物理计算环境所关注的跳读和随机读来说,A2C 算法表现更好,是最贴近实际应用的算法.
经过对测试结果的分析,我们发现使用强化学习的方法来对存储系统的参数进行调节,确实对存储系统性能有了较为显著的提升,而当负载发生变化时,其可进行动态适应性的调整,并且对生产系统的影响很小.可以预见:将其部署在生产系统后,在提升系统性能的同时,可大大减少人力成本及时间成本.
4 总结与展望
本文介绍了一种基于强化学习的参数调节方法,实验表明该方法使我们所关注的性能得到了显著提升.事实上该方法不只是针对分布式存储领域,通过自定义环境和奖励,它可以泛化到更多的领域中.
总的来说,我们将强化学习应用到分布式存储领域中只是1次初步的尝试,有很多方面需要进一步探索:
1) 本文只是对Lustre客户端的参数进行了调节,未来我们会增加Lustre服务器端以及其他分布式文件系统(如eos,ceph)的参数调节.
2) 状态的表示.本文我们将当前时间点跟系统性能相关的因素作为状态来训练,事实这可能存在一定的局限,只了解到当前的状态,而对系统的历史信息以及变化趋势没有涉及.因此,未来的工作会对系统的状态表示加以改进.
3) 算法.强化学习发展迅速,不断有新的方法被提出,如逆向强化学习、分层强化学习、世界模型等,新的算法的性能往往会有较大提升,我们会在未来的工作中加深对算法的研究以及应用,并在前人的基础上尝试提出自己的强化学习算法.
