一种基于集成学习的科研合作者潜力预测分类方法
2019-07-15马国帅杨凯凯钱宇华
艾 科 马国帅 杨凯凯 钱宇华
(山西大学大数据科学与产业研究院 太原 030006) (计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006) (山西大学计算机与信息技术学院 太原 030006)
科学学[1](science of science)旨在发掘学科的发展动力,构造模型反映学科演化过程,进而推动科学事业发展,科研合作就是其研究内容之一.合作和产出之间有强相关性[2],越来越多的高水平研究成果通过合作实现,这正凸显了合作者选择的重要性.优秀的合作关系能够充分发挥各合作者的潜力,最大化科研效益.通过科研合作模式指导,预先甄别合作者的潜力有助于学者平衡投入与产出,选择潜在收益最大的合作者,最大化科研效率.
合作关系所形成的合作数据反映了学者间的相互关系,是科研网络和学者行为的重要研究对象.基于合作数据的科研合作模式研究是当前的热点内容.科研合作模式对于研究学者行为有着非常重要的意义.以科研合作模式为载体的合作者推荐问题研究,多基于复杂网络理论[3];以点和边的拓扑分析为基础,把合作者推荐问题作为链路预测问题[4]处理,如基于随机游走的最有价值合作者MVCWalker(most valuable collaborator)[5]方法预测二者之间产生合作的可能性;Tang等人[6]则致力于解决交叉学科的合作者推荐和预测问题;一些其他方法也得到了较好的效果,如把共同参加同一会议作为影响合作产生的因素[7],以统计概率的形式描述新合作的产生;以及通过量化学者间的局部相关性和全局相似性[8]进行合作者推荐;模式识别方面,Xia等人[9]利用高维度多角度的学术大数据,结合数据特征构造Shifu模型,对导师-学生关系进行挖掘.
然而以上的工作多以合作产生的可能性为研究目的,并没有对合作的结果给出预判性指导.为了达到最好的合作效果,需要对学者的合作潜力进行研究.但是仅仅依靠传统的拓扑关系已经无法满足问题需求,需要质量更高、信息量更大的数据来支撑.然而学术大数据(big scholar data, BSD)[10]的“爆发”性质[11]使得合作者潜力预测问题成为挑战.首先,数据量巨大使模式挖掘更加困难;其次,数据形式多样,不局限于现有方法中使用的结构化数据,学术大数据包含许多异构信息,如作者、文章、机构、期刊会议等,以及合作者合著关系等复杂网络关系[12];同时,数据具有动态性,学者个人、文章的影响力以及学者之间的合作强度都是与时间相关的,时间不同效果也不同.来自问题和数据的多重挑战迫切需要提出更有效的解决方法.
集成学习算法[13]是机器学习的一种新学习思想,该学习算法把同一个问题分解到多个不同模块中,由多个学习器参与学习,共同解决目标问题,最终通过平均或投票选用分类器,从而提高分类器泛化能力.根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器间存在强依赖关系、必须串行生成的序列化方法(以Boosting[14]为代表),以及个体学习器间不存在强依赖关系、可同时生成的并行化方法(Bagging[15]和随机森林[16](random forest, RF)为代表).
因此,本文把集成学习分类方法应用于真实学者-文章大数据,构造面向合作者潜力预测问题的样本集.样本特征综合考虑学者的个人属性以及合作者之间的相关性,分别从文章标题、文章等级、文章数量、时间、署名序等多维度进行特征构造[17-18],进而提出了基于集成学习分类方法的科研合作者潜力预测模型.该模型旨在通过学者的属性集,对当前合作者的潜力进行预测.
本文的主要贡献有2个方面:
1) 构造了面向合作者潜力预测模型的样本集.将学术大数据中的文章、作者与文章等级进行对应,处理成含等级的文章和含等级的作者数据作为基准数据集.同时定义了一系列学术背景下的学者个人特征描述以及学者间相关性特征描述.
2) 提出合作者潜力预测的挖掘模型.将分类方法应用于以上特征集来解决合作者的潜力预测问题且实验效果显著.
1 合作者潜力预测模型设计思路
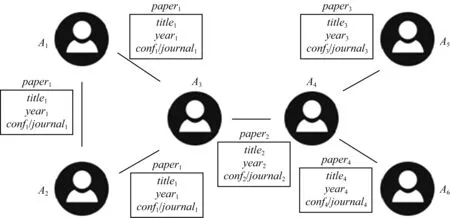
Fig. 2 Scientific coauthor network图2 科研合作网络
本文提出的合作者潜力预测模型基于假设:合作者潜力通过合作成果的等级高低表现,而成果等级高低与合作者各自的单一属性和合作者之间的相关属性密切相关——作为个体每个学者都有一系列学术属性和社会属性,一定存在某种潜在模式使合作者的属性合集达到特定的形式时会产出特定等级的合作成果,这正是模型构建的出发点.本文通过对真实学术大数据进行分析并构建样本,利用集成学习算法在样本集挖掘合作者潜力预测模型.模型整体流程如图1所示:
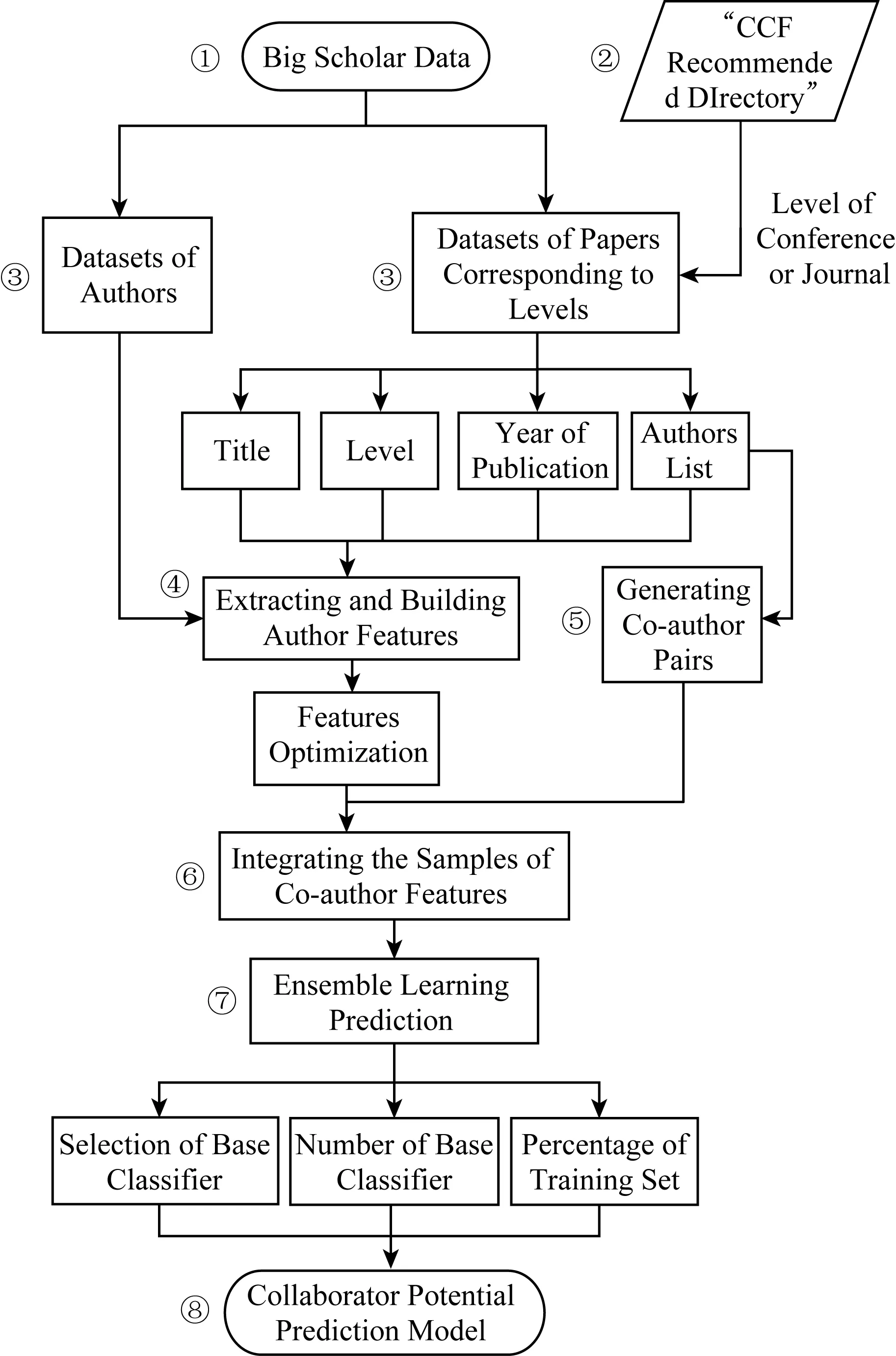
Fig. 1 Flow chart of the model图1 模型流程图
① 以ArnetMiner[19]提供的学术社会网络数据集为数据源提取特征,其中包括学者数据集和文章数据集.
② 以《中国计算机学会推荐国际学术会议和期刊目录》(简称《CCF推荐目录》)中的类别A,B,C(其中A代表高水平的期刊和会议)作为评价合作成果等级的标签.
③ 以作者为唯一标识符构建作者数据集,以文章为唯一标识符结合《CCF推荐目录》构建包含等级的文章数据集.
④ 基于格式化的作者和文章数据集抽取和构建作者包含等级的作者特征集.考虑文章标题、等级、发表年份、作者列表属性,从时间、数量、文本相似性等角度综合度量不同特征对结果产生的偏差.
作者属性如题目、研究兴趣等都是文本形式,为了分析这些文本特征之间的关系,本文利用了自然语言处理中的潜在语义索引(latent semantic indexing, LSI)模型[20].LSI基于奇异值分解(singular value decomposition, SVD)的方法得到文本主题,通过1次SVD过程得到文档和主题的相关度、词和词义的相关度以及词义和主题的相关度索引.
⑤ 科研合作是由合著关系表示的一种强社会关系.不同模式的合作关系隐藏在广泛的科研合作关系中.在共著关系基础上可以构建1个科研合作网络[21],如图2所示.在科研合作网络中,2位学者如果共同撰写文章就会被认为是相互联系的.基于科研合作网络的结构和社会规律对合作模式挖掘非常重要.
类似于网络图中对边的定义和研究,模型构建中只考虑合作成果作为1条边的情况,即只考虑2个人而非多个人之间产生合作的模型构建.
⑥ 构造基于当前合作双方的基准特征集,包含作者各自的特征以及二者之间相关性的特征.若合作样本(文章)的等级为A,则样本标签记为“1”,否则为“0”,进而将特征和样本整合为样本集.
⑦ 分别采用Boosting,Bagging,RF这3种基分类器对以上样本集进行集成学习.分别改变训练集比例以及基分类器个数以测试所构造样本集在当前研究中的有效性.
⑧ 得到学术大数据下的科研合作者潜力预测模型.
2 合作者潜力预测模型构建过程
本文构建合作者潜力预测模型的过程主要包含2部分:1)基于科研合作大数据的分析,提取可用特征;2)基于学者基本数据构造特征样本,采用集成学习算法构建模型,完成合作者潜力预测的任务.
2.1 特征分析
考虑与合作者潜力相关的因素,以统计图表形式分别对4个特征进行分析:1)文章标题;2)不同等级中的文章数量;3)文章发表年份;4)署名序.
首先,图3以发表篇数为横坐标、发表该篇数的人数为纵坐标初步刻画了数据内容,这里以S表示所有文章,即不考虑文章分级进行数量统计.图3中不论级别都基本服从长尾的幂率分布,这一表现与直观认知一致,少量学者占据了多数发文量,这个不平衡数据问题需要充分利用数据构建特征以反映内在模式.
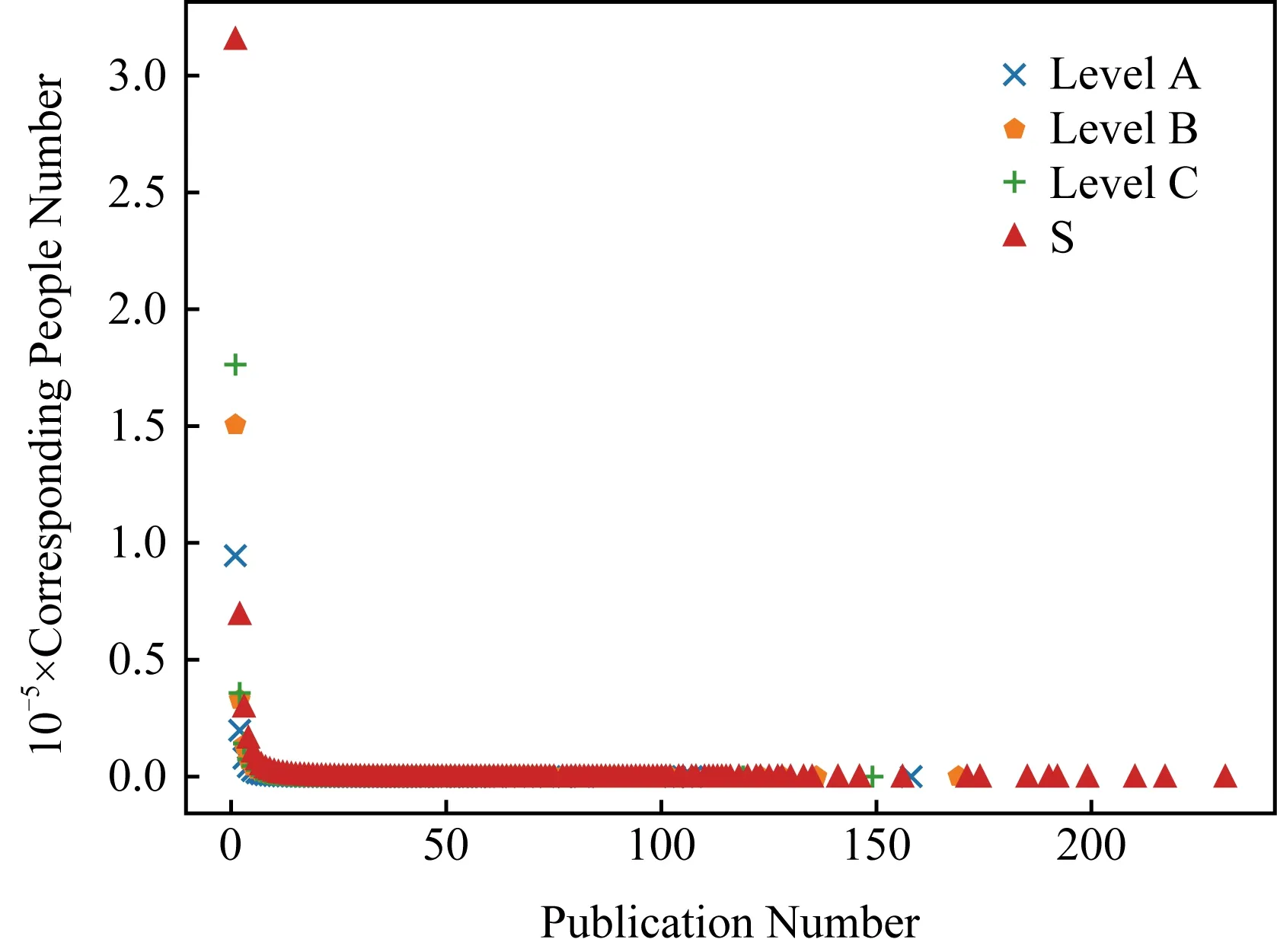
Fig. 3 Publication number and corresponding authors number图3 发表篇数与对应人数
将图3中发表篇数与对应人数分别取对数得到图4.
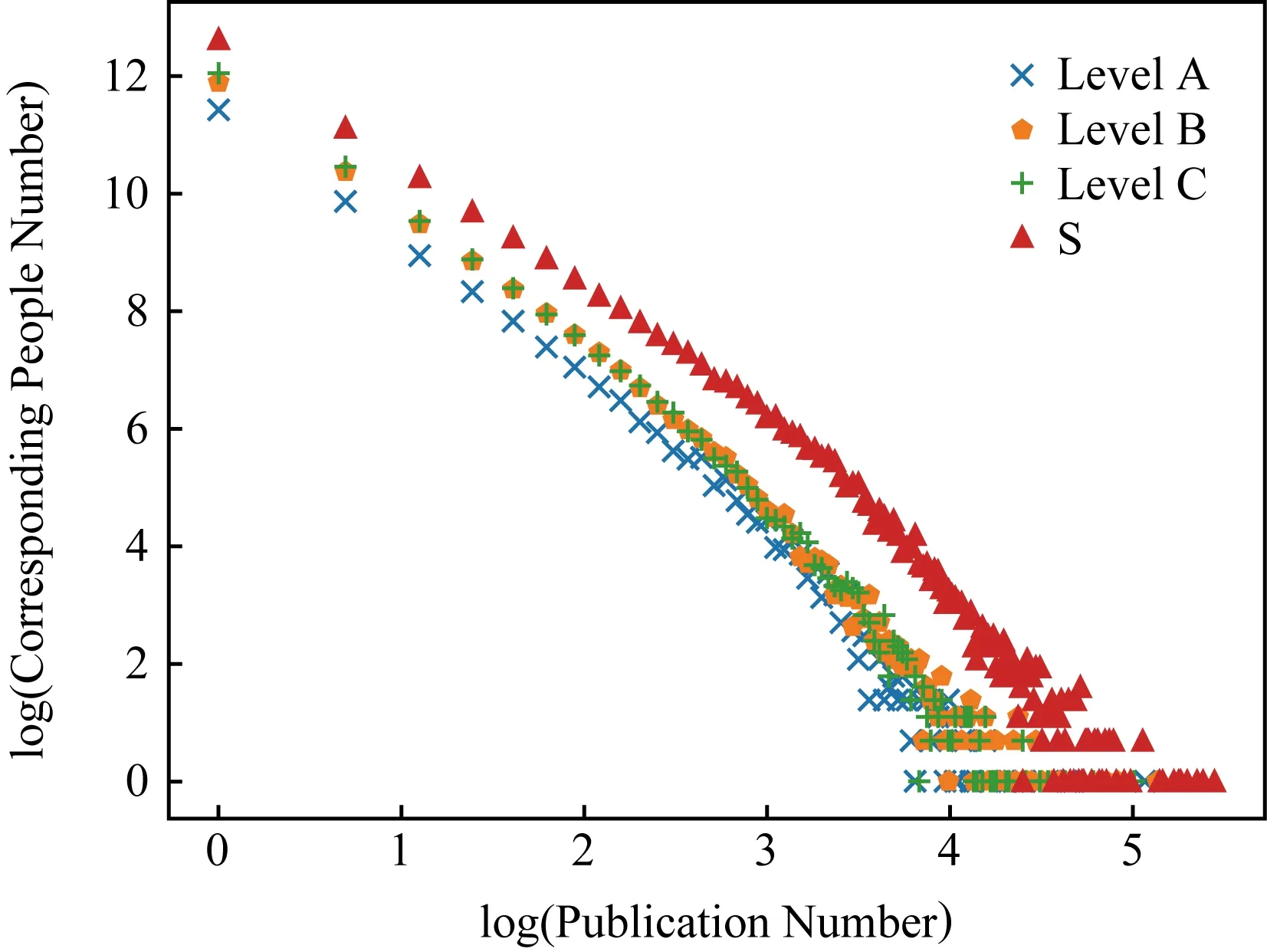
Fig. 4 Logarithms for publication number and corresponding authors number图4 发表篇数与对应人数取对数
1) 文章标题.利用文本数据挖掘方法提取各级别所有文章标题中的高频词根.以2000—2010年为例,图5表示每年前3位高频词根随时间变化情况.某些年份词频较为接近,会出现一定程度重叠.图5中点的纵坐标与轴对应,表示数值大小,而点右侧词的高低不具有坐标意义,只与相对高低的点对应表示此点的词根.图5中不论A,B,C类每年高频词根数量持续增长,数量变化趋势基本一致,内容虽大致相同但有少量变化,说明文章标题是一个较为敏感的因素.因此作者文章标题可以作为合作者潜力预测的基本特征.
2) 不同等级中的文章数量.图6展示了各等级中,以学者发表文章数量为排序依据,各学者发表不同级别文章数量的分布情况,为了便于表示这里选取排名前50位作图.如图6(a)表示以各学者发表A类文章数量为排序依据,前50位发表A,B,C类文章的分布情况.由图6可得,不同排序标准下的排序分布不同,不计级别意义下(图6(d))的文章数量并不能准确反映作者在各个等级下单独的能力,每个作者在不同等级中都有一定的能力体现,因此文章等级及文章数量可以作为合作者潜力预测的基本特征.
3) 文章发表年份.分别取不同等级中累积发表该类文章数量前3位的学者,分析他们发表文章数量的等级分布随时间变化,如图7所示.虽然各等级中学者发表文章以该类为主,但仍有其他类的文章发表.学者科研生涯发表文章数量和等级不断变化,考虑年份特征更能反映学者在当下的科研潜力,因此文章的发表年份可以作为合作者潜力预测的基本特征.
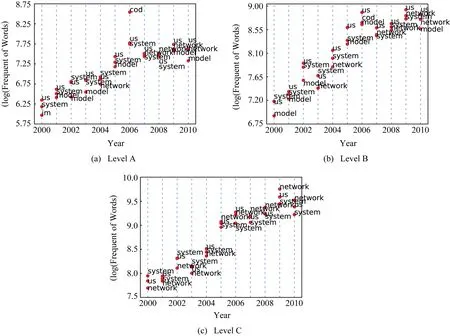
Fig. 5 Top 3 words in titles by year图5 文章题目前3词汇时间分布
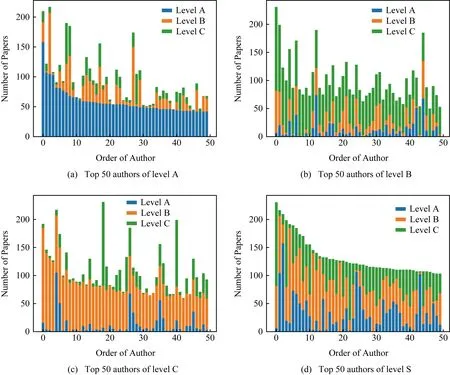
Fig. 6 Level distribution of top 50 authors in each level图6 各等级前50位发文等级分布
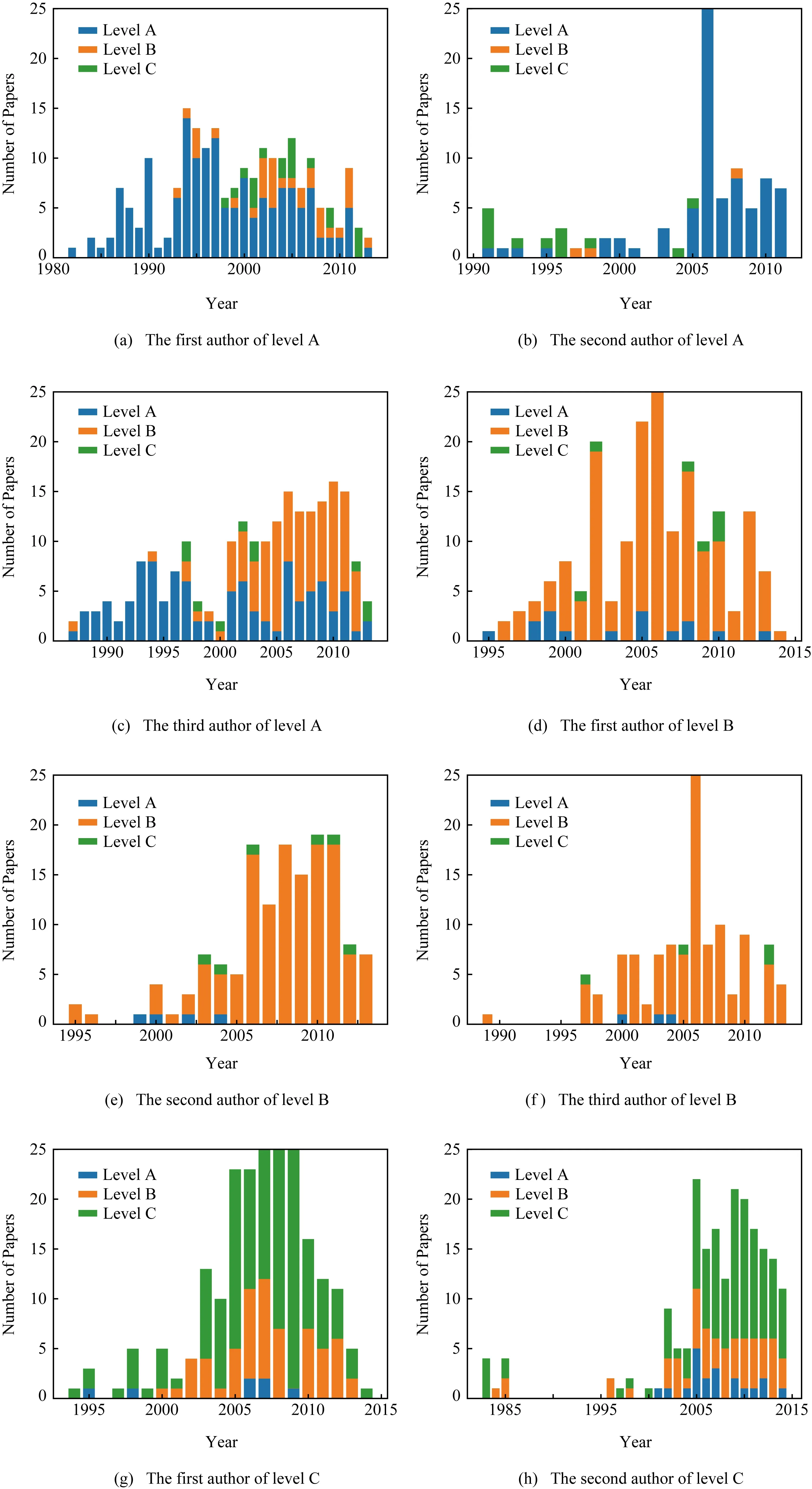
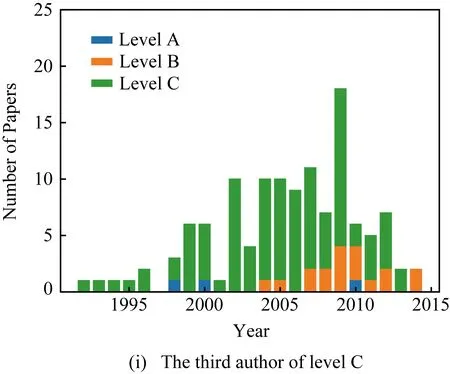
Fig. 7 Level distribution by year of top 3 authors in each level图7 各等级前3位发文等级年份分布
4) 署名序.每篇文章的作者常以合作者列表的形式呈现,每位作者对文章的贡献程度是不一样的,最直观的就是通过学者在作者列表中的位置来反映.例如1篇A类文章的第1作者和第2作者比第2作者之后的作者对文章的贡献更大,即前2位作者较之后的作者有更多A类潜力.因此署名序可以作为合作者潜力预测的基本特征.
2.2 样本特征构造
经2.1节对学术大数据的分析,提取可用特征:文章标题、文章等级、文章数量、文章发表年份以及署名序.
基于以上基本特征因素进行规范和优化.首先年份特征作为时间因素可以衍生出相关特征:文章发表时间为t,发表第1篇文章距今的时间间隔定义为其学术年龄AA(academic age)[9];第1篇文章的发表时间为t0;最近1篇文章的发表时间tl.对于署名序,由于1篇文章的作者列表可能包含多人,进行特征组合会产生大量冗余特征,因此这里只用署名第2作者之内的O0(包括第2作者)的和第2作者之外的O1加以区分.而文章级别分为A,B,C这3类,文章数目计数器记为N,则优化后的基本特征如图8所示:
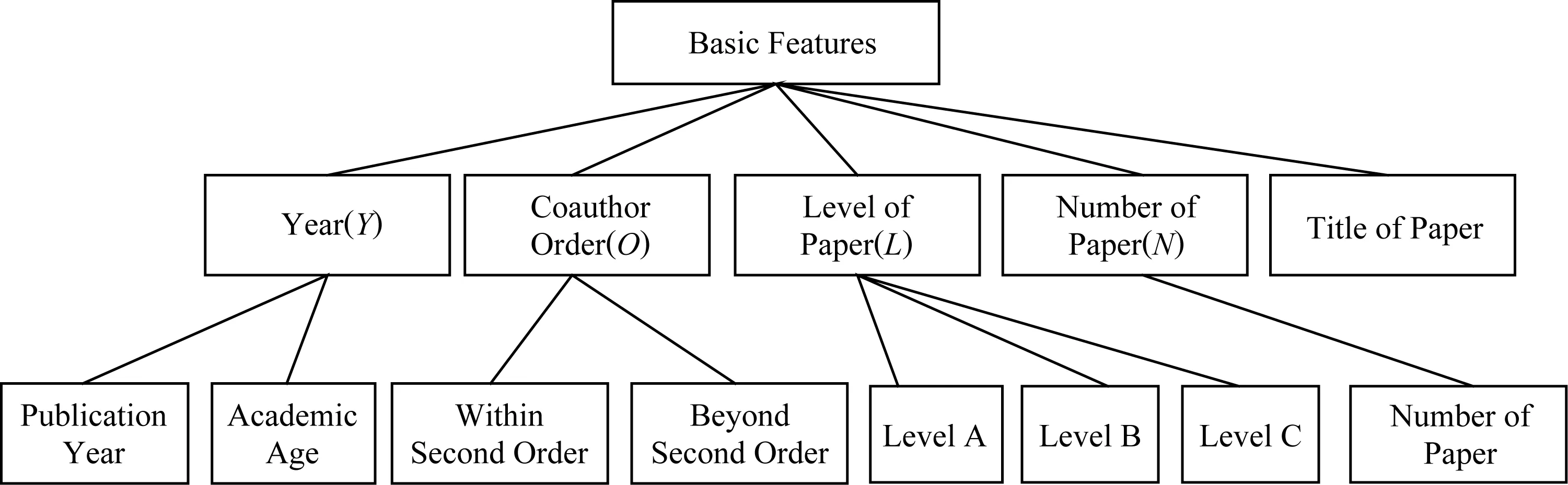
Fig. 8 Basic features after optimizing图8 优化后的基本特征
基本特征从简单维度反映了合作者的潜力表现,是预测模型最直接的量化和外在形式.但是仅依据直观意义下的单一统计量不足以适应多样化的合作模式,难以挖掘合作者潜力.因此,对于数字类数据和文本类数据,本文分别采用了不同的特征构造策略:1)以特征工程处理数字类数据,对基本特征进行1次组合及2次组合,得到较小粒度的可用特征;2)文本类数据特征利用语义信息计算语义相似度构造特征.
1) 数字类数据特征构造.以基本特征为基元扩展特征维度.首先对基本特征进行1次组合如表1所示,得到特征:NL特征、OL特征、YL特征、NO特征、NY特征、YO特征(所有特征都基于当前合作时间点tc得出).
①NL特征.不同等级li中文章的数量Nli(li表示文章等级:lA表示A级别、lB表示B级别、lC表示C级别):
NL={Nli|li∈{lA,lB,lC}}.
(1)
②OL特征.不同等级li中文章的署名序Oli:
OL={Oli|li∈{lA,lB,lC}}.
(2)
③YL特征.不同时序位置ti和不同等级li的文章发表时间yearti,li或学术年龄AAti,li(ti表示文章的时序位置:t0表示当前学者生涯第1篇,tl表示当前学者最近1篇):
YL={(year,AA)ti,li|ti∈{t0,tl},li∈{lA,lB,lC}}.
(3)
④NO特征.不同署名序oi时的文章数NOi(oi表示署名序:当作者在文章中署名前2位作者时oi=1,否则oi=0):
NO={NOi|oi∈{0,1}}.
(4)
⑤NY特征.不同时间区间Ti中的文章数量NTi(Ti表示文章时间区间的时序位置:[t0,t0+ΔT)表示学者学术生涯中第1个时间区间、[tl-ΔT,tl)表示最近1个时间区间,其中ΔT表示时间区间长度,如ΔT=5,则统计学术生涯前5年和最近5年中的文章数量):
NY={NTi|Ti∈{[t0,t0+ΔT), [tl-ΔT,tl)}}.
(5)
⑥YO特征.不同时序位置ti和不同署名序oi的文章发表时间yearti,oi或学术年龄AAti,oi:
YO={(year,AA)ti,oi|ti∈{t0,tl},oi∈{0,1}}.
(6)
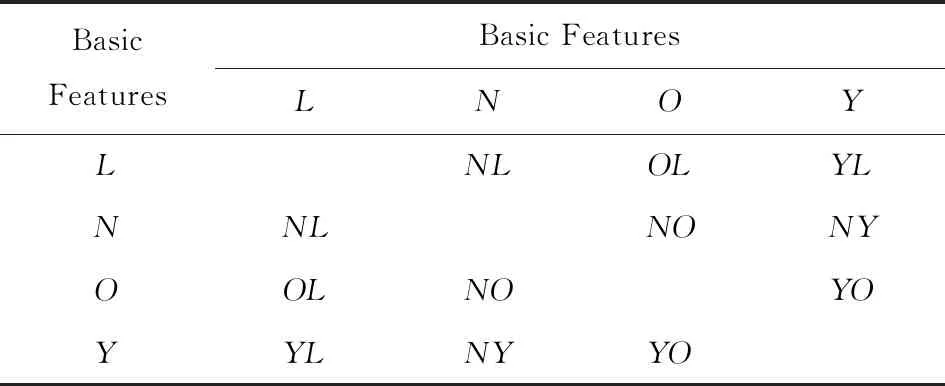
Table 1 Combining Basic Features of Papers表1 文章基本特征组合
细化特征粒度,排除意义重复特征,对以上特征二次组合得到YL&O特征和NO&YL特征.
⑦YL&O特征.不同时序位置ti、不同署名序oi、不同等级li的文章发表年份yearti,oi,li或学术年龄AAti,oi,li:
YL&O={(year,AA)ti,oi,li|ti∈{t0,tl},
oi∈{0,1},li∈{lA,lB,lC}}.
(7)
⑧NO&YL特征.不同时间区间Ti、不同署名序oi、不同等级li的文章数量NTi,oi,li:
NO&YL={NTi,oi,li|Ti∈{[t0,t0+ΔT), [tl-ΔT)},oi∈{0,1},li∈{lA,lB,lC}}.
(8)
2) 文本类数据特征构造.文本数据不同于数字类数据.每个文本在形式上由包括标点在内的字符组成,由词到句,由句到篇.不论是在文本的自底向上或自顶向下的层次解析中,形式相同的一段字符串在不同的语境下可得到不同的含义.文本的一致性和多义性决定了其独特的处理方式.因此本文利用潜在语义索引[20]方法,计算基于集成语料库子空间的标题特征值以及标题间相似度.
首先给出3个定义:
定义1.文章标题全集sumTitle(T*,L*).
sumTitle(T*,L*)= ∪{titlepi|yearpi∈T*,lpi=L*},
(9)
其中,T*表示发表年份区间,L*表示文章等级(标题titlepi、年yearpi、级别lpi对应于同一篇文章pi).
定义2.文本特征值计算函数Cal(x,X).其中,x为待计算的文本样本,X为对应的计算子空间.
定义3.文本相似度运算函数dis(yi,yj).其中yi,yj分别为文本合集.
基于文本定义可得2个文本特征:
1)TIT特征.分别以作者au第1篇t0、最近1篇tl及到当前时间tc为止累积发表文章标题合集作为计算样本x,以样本x中文章在当时年份tp、当时年份之前1个时间区间[tp-ΔT,tp)及到当时年份为止[0,tp)时间段的文章标题全集分别为计算子空间X(计算子空间X中所有文章等级与计算样本x的等级lp一致),将样本和子空间代入特征值函数得出标题特征:
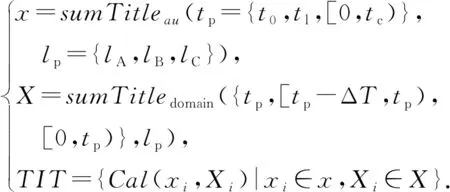
(10)
2)SIMtitle(aui,auj)相似度.合作者aui和auj到当时年份为止[0,tp)在各等级上文章标题全集之间的文本相似度:
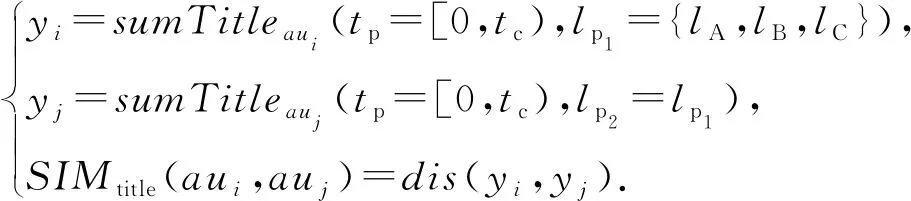
(11)
2.3 集成学习方法
集成分类器如图9所示,利用多个基学习器参与学习,通过投票或平均选择最适应当前任务的分类器,提高泛化性能.

Fig. 9 Ensemble estimators图9 集成分类器
所用集成学习方法简述:
1) AdaBoost[14].该方法先从初始训练集训练出1个基学习器,再根据基学习器的表现对训练样本进行调整,使得先前基学习器的错分样本能够在后续中得到更多的训练,基于调整后的样本分布进行下一个基学习器的训练.如此重复直到基学习器数量达到预先指定的值,最终将这些基学习器进行加权结合.
2) Bagging[15].该方法首先经过多次随机有放回采样,得到多个采样集.使得有的样本多次出现,有的样本则从未出现.进而个体学习器之间既有差异又能进行有效学习.之后从每个采样集中训练出1个基学习器,最终将这些基学习器进行结合.
3) 随机森林[16](random forest, RF).在以决策树为基学习器的Bagging集成的基础上,在训练过程中引入随机属性选择,不同于传统的决策树在当前的属性全集中选择1个最优属性,而是从属性集合中随机选择1个属性的子集,再从子集中选1个最优属性用于划分.
3 实验设计
3.1 数据描述与实验设置
ArnetMiner 数据集上有丰富的文章和作者信息,包含文章数据2 092 356条、作者数据1 712 433条、文章作者匹配数据5 192 998条.每条文章数据包括ID、题目、作者、年份、所发机构、期刊等;每条作者数据包括ID、姓名、机构、研究兴趣等;文章作者匹配数据通过各自的ID把文章和作者联系起来.ArnetMiner 数据的优势在于给每个作者赋予了唯一的ID,使重名消歧的问题从数据源头得以解决.《CCF推荐目录》中包含计算机10个领域的600多个各类期刊会议.本文将ArnetMiner 中《CCF推荐目录》的全部数据抽出,根据《CCF推荐目录》的论文分级从ArnetMiner 中抽取计算机领域整个数据集作为研究对象,以期刊和会议的等级高低作为文章的级别标签(其中A类文章100 324篇,B类文章162 634篇,C类文章208 422篇,总计471 380篇),得到计算机领域的全部数据进行实验.
从以上真实数据中抽取合作边,根据第2节所述合作者潜力预测模型中的式(1)~(11)构建样本特征,结果等级为A类文章样本标签记为“1”,否则样本标签记为“0”.依流程图1把每个合作边样本构造为特征,标签样本,得到样本数据集.为了兼顾模型的准确率和运行的时间开销,本文的实验以当前年份之前10年数据为训练集,当前年份之后3年数据为测试集进行验证.如当前年份为2010年时,训练集为2000—2010年的样本,测试集为2001—2003年的样本.
3.2 评价指标
本文选用机器学习分类常用的准确率、召回率、F1分数和模型学习时间作为评价模型的指标.假定某类标签的预测集合为PS.根据预测标签和真实标签可以将PS分为表2混淆矩阵中的4组.

Table 2 Confused Matrix表2 混淆矩阵
TP:真实标签为正例被正确判定为正例;
FN:真实标签为正例未被正确判定为正例;
FP:真实标签为负例的被错误判定为正例;
TN:真实标签为负例的未被判定为正例.
由混淆矩阵得到准确率(precision,P)、召回率(recall,R)、F1分数(F1-score,F)计算为
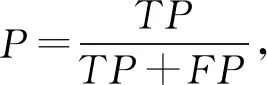
(12)
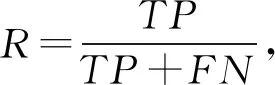
(13)
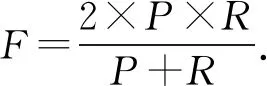
(14)
3.3 实验结果及分析
为了验证本文构造模型在合作者潜力预测问题中的适应性,设置实验对TP,FN,FP,TN四个指标进行测试比较.同时引入决策树(decision tree, DT)、K-近邻(K-nearest neighbor, KNN)、逻辑回归(logistic regression, LR)和支持向量机(support vector machine, SVM)多种传统学习算法作为基于集成学习的科研合作者潜力预测模型的对比方法,进一步验证其有效性.
图10以10年全部数据中不同百分比的样本作为训练集,集成学习方法基分类器个数为300时,Adaboost,Bagging,RF,DT,KNN,LR,SVM多种类型的算法在4个指标的实验性能(其中SVM时间开销巨大,因此图10(d)只展示了除SVM外的6种算法运行时间,同时DT和LR运行较快,曲线基本重叠).结果显示,集成学习算法虽然时间开销较高,但是准确率、召回率和F1分数都远高于对照算法.同时,本文基于集成学习算法的模型在较小的训练集时就已经能取得较好的效果,即以较少的数据量快速收敛于较高的性能.其中Bagging对模型的适应性最好,但是运行时间更长.运行时间、性能参数与数据量正相关,但是使用20%的训练集样本就基本接近性能最优值,此时的运算时间较低,因此时间开销并不大.
图11为以10年中全部数据作为训练集,增加集成学习中基分类器个数时Adaboost,Bagging,RF这3种算法在4个指标的实验性能.与增加训练集数据时类似,本文模型在较少的基训练器时基本接近大量基训练器的效果.而运行时间主要取决于集成学习方法自身的复杂度,基本呈线性分布.
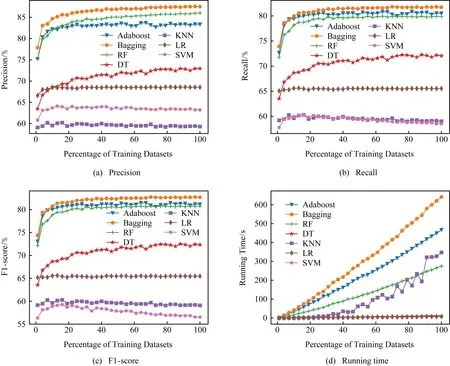
Fig. 10 Experimental results with training dataset increasing图10 训练集增加的实验效果
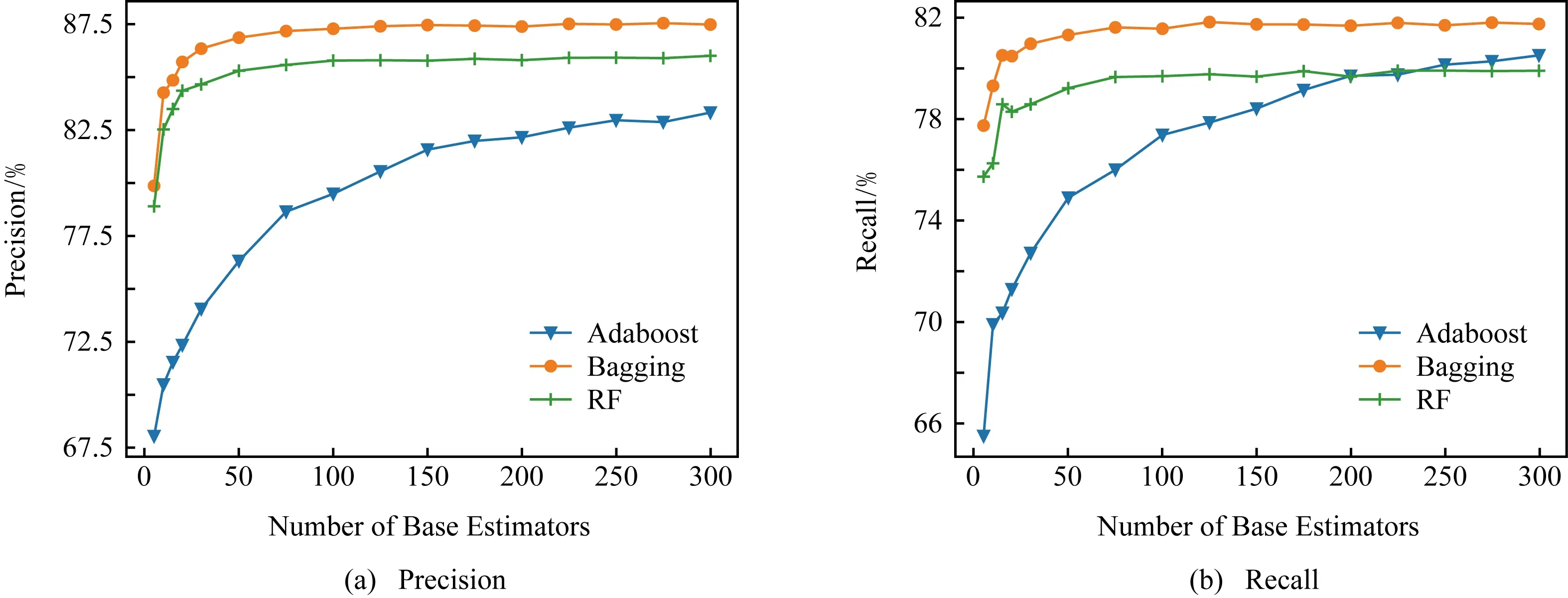
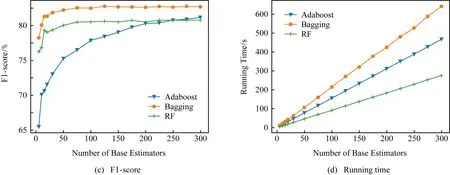
Fig. 11 Experimental results with estimator number increasing图11 基分类器增加的实验效果

Fig.12 Experimental results with training dataset and estimators number increasing图12 训练集和基分类器增加时RF的实验效果
3种集成学习算法的性能表现趋势大致相同,因此图12以RF为代表,用三维散点图的形式表示训练集和基分类器同时增加时的实验效果.更直观地说明了增加训练集和基分类器个数对实验性能的影响.
综合上述实验结果可得:1)3种经典集成学习方法的准确率、召回率和F1分数都超过了0.8,较好地完成了合作者的潜力预测问题.Bagging算法最能适应本文所提模型,准确率、召回率、F1分数分别达到87%,82%,82%.RF虽然性能略差,但是运行时间最快;2)模型的样本收敛较快,少量训练集时性能参数基本达到最优;3)基分类器数量较少时性能参数基本达到最优;4)以上2点保证了模型较低的时间开销.
4 结束语
基于文章等级与合作者属性相关这一假设,本文研究了大数据背景下的合作者潜力预测问题,从大量合作关系中挖掘不同等级的合作表现,指导学者进行合作者选择.为了训练和评估模型,本文从学术大数据中抽取并构造了一系列特征来描述合作者潜力,把ArnetMiner 的文章和学者信息与《CCF推荐目录》匹配构造包含等级的文章数据集和包含等级的学者数据集作为样本集.同时定义了一系列学术背景下的学者个人特征描述及学者间相关性特征描述,并将经典集成学习方法应用于所构造的样本.实验结果说明了本文所提模型的实用性和优越性,从而可以为学者选择有潜力合作者提供参考性意见,有助于个人科研效率最大化.
本文未来的工作将继续拓展特征的丰富性来更全面地刻画合作者潜力,以《CCF推荐目录》中的不同分级为标准,向多维数据扩展,如期刊、会议、作者主页,爬取完整数据,提升模型性能,进一步挖掘合作模式.
