基于出行方式及语义轨迹的位置预测模型
2019-07-15章静蕾石海龙
章静蕾 石海龙 崔 莉
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)
近年来,随着GPS数据、LBS地理位置信息方便被获得后,基于地理位置的服务也深受用户的喜爱,这些服务程序通常都是利用用户行径的历史地理位置信息来为用户提供更方便、有效的服务.有效的LBS服务不仅能够提前告知用户下一个位置的具体位置点,同时还能表示此位置的语义信息,如学校、超市、公寓等.这对用户的行为活动计划有所帮助,也提前给用户的兴趣偏好产生一定的影响.
位置预测技术就是通过获取GPS轨迹数据,并对用户日常行为活动和其日常的出行规律进行分析,根据此分析结果结合用户的历史轨迹信息对下一个位置进行预测.而只根据用户当前位置的地理信息并不能达到优质的效果,如图1所示,给出了用户的3条GPS轨迹的例子.
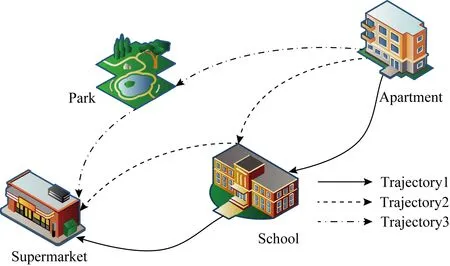
Fig. 1 An example of user’s location trajectory图1 用户位置轨迹示例
图1中,按照地理位置轨迹分析,轨迹2和轨迹3离得更近.因此,在对轨迹2进行位置预测时,基于地理位置轨迹的相似度,得到的结果会偏向于轨迹3.因此,只考虑地理位置信息进行预测用户的轨迹位置可能并不会达到令人满意的结果.因此需要结合基于语义轨迹的挖掘来进行辅助.这3条轨迹由位置所对应的语义信息所组成,如公寓、公园、便利店、学校等.由图1所知,轨迹1和轨迹2均为公寓,学校,便利店,隐含着轨迹1和轨迹2从语义上才是相似的.因此将用户有相似行为活动规律通过语义轨迹表示出来,不仅能将没有访问过的位置加入考虑之中,同时也结合用户行为活动对位置进行预测.
另外尽管目前在对位置预测的问题中,不少研究也结合多方面因素进行考虑,比如对轨迹中的2个兴趣点之间的路径进行预测,并结合路径对位置预测结果进行提升,或者结合用户之前没有访问过的地理位置信息对用户的位置进行预测等,然而目前研究没有加入用户的出行方式的因素.众所周知,当用户进行户外行为活动时,根据其自身的行为偏好在兴趣点之间进行转移时,不可避免需要进行出行方式的选择,因此出行方式同样也反映出用户外出的行为规律,这对位置的选择和偏好也产生重要的影响.因此在对用户轨迹数据进行挖掘信息时,我们不仅要考虑位置轨迹所蕴含的语义信息,同时也要结合用户的出行方式来挖掘用户行为活动有助于提高位置预测技术.
因此,本文提出一种结合轨迹信息数据及出行方式的未来位置预测模型,该模型分为2部分:1)在轨迹信息数据挖掘方面,本文首先通过对轨迹数据进行分析,设计实现一种同时结合语义轨迹和位置轨迹模式的组合模型,即通过对语义轨迹和位置轨迹的频繁模式挖掘得到相应的频繁轨迹集合,并对目标轨迹分别进行匹配得到预测结果的位置候选集.2)通过对轨迹数据和用户的出行方式进行分析,设计实现一种结合用户出行方式和轨迹频繁模式的模型,即根据用户历史轨迹序列和历史出行方式序列建立模型预测得到未来位置结果候选集.最后根据2部分的结果候选集得到用户最终的未来位置.
本文的主要贡献有2个方面:
1) 提出一种同时结合语义轨迹和位置轨迹的位置预测算法,该算法根据语义轨迹进行相似用户的挖掘,并结合个人的语义轨迹和相似用户的位置轨迹对未来位置结果进行预测.
2) 提出一种结合用户出行方式的位置预测算法,根据用户轨迹和历史出行方式建立Markov模型,对用户的未来出行方式进行预测.
最后结合这2个部分的结果得到最后预测的位置结果.
1 相关工作
近年来,随着基于地理位置信息的服务技术的发展,与此相关的服务也在迅速发展,如导航路径服务、交通流量拥塞管理、城市计算服务或者基于位置的广告投放服务等.而在这些服务当中,都是普遍基于未来位置预测技术之上产生的.
关于位置预测技术的研究,目前也有大批研究者对此进行深入的探索并取得一定的成绩.Chen等人[1]提出一种基于Markov模型的位置预测算法,对用户的轨迹位置进行挖掘,并考虑当前时刻位置对未来位置的影响,由此对用户的未来位置进行预测.Yang等人[2]提出一种层次聚类的挖掘算法并使用一阶Markov模型对位置进行预测.然而该方法具有一定的限制性,即数据源是个人的历史位置数据,因此模型也只适用于个人的行为活动挖掘,而不具有较强的泛化能力,不具有普适性.Monreale等人[3]提出一种新的方法对位置预测技术进一步研究,该方法同时考虑位置的访问顺序、用户访问某个兴趣点位置的访问度和逗留该位置的时长3个因素,对位置进行较高精确度的预测.
除了在使用用户的历史轨迹数据进行挖掘来对未来位置进行预测之外,部分研究者认为只靠用户的轨迹数据并不能对提高位置预测的精确度进行更高的提升,因此需要引入额外的外源数据来辅助预测结果的精度,如社交网络关系、历史轨迹的路径长度、不同地区的分布状态、路径道路的拥塞程度、事故报道和司机的驾驶习惯[4-7]等.类似地,研究者还会引入文本信息作为外源数据,如具有周期性阶段的时间段和相应的位置信息可以作为重要因素列入模型训练过程中[8].因此在对位置预测方面,我们不仅可以从大量的轨迹数据中提取有用的信息,同时也可以结合用户行为活动中产生的外源数据作为辅助来提高位置预测结果的精确度.
2 TransPredict算法概述
本文分别引入语义轨迹模式挖掘和出行方式序列2个部分对未来位置进行预测,总体描述流程如图2所示.该框架主要包括结合语义轨迹和位置轨迹进行频繁模式挖掘、结合出行方式和位置轨迹进行未来位置预测这2个模块组成.
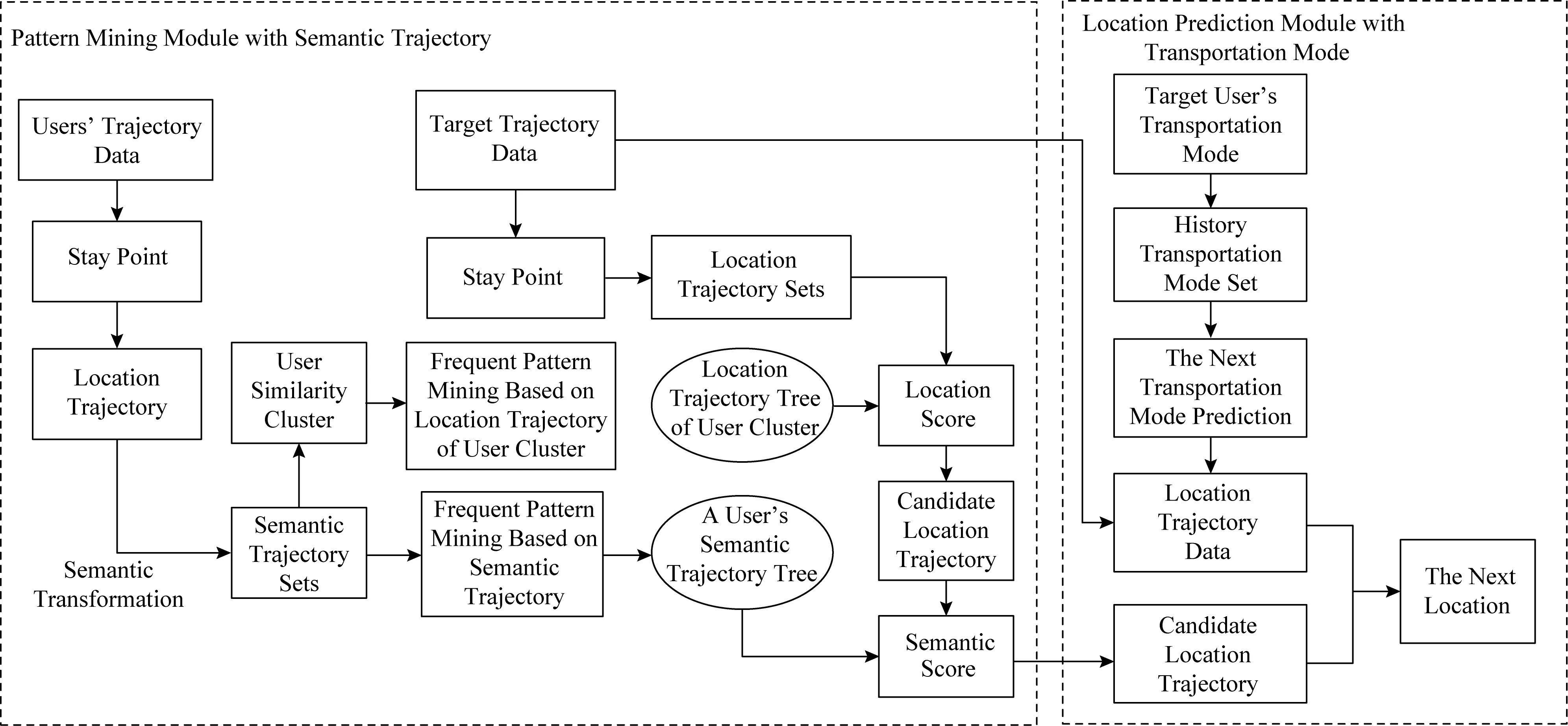
Fig. 2 The flow diagram for location prediction图2 位置预测总框架图
在语义轨迹模式挖掘模块中,我们首先对所有用户的历史轨迹数据进行处理,对由GPS点组成的轨迹挖掘出停留点(stay point)进行轨迹分段;再对停留点进行聚类得到兴趣点位置轨迹,得到位置轨迹序列.通过对位置轨迹进行语义化,将位置信息标识成语义信息并得到语义轨迹,根据个人用户的语义轨迹进行频繁模式挖掘,得到语义频繁轨迹集合并建立相应的语义模式树.根据之前得到的语义轨迹,进行聚类挖掘具有相似行为活动的用户.由于只根据语义轨迹并不能得到具体预测未来位置的地理信息,因此需要结合位置轨迹数据来处理.由此,对相同簇内所有用户的位置轨迹集合挖掘频繁模式集合,并建立相应的位置轨迹树.最后当对用户的目标轨迹进行预测时,将其与位置模式树的路径匹配得到候选轨迹集合及其位置得分,接着将候选轨迹路径语义化后与语义模式树进行匹配,得到相应的语义得分,根据两者的得分加权获得依据得分高低排序相应的候选轨迹集合,候选轨迹下一个位置就是未来位置预测的结果.由此,结合语义轨迹和位置轨迹进行预测时,不仅考虑其用户自身历史轨迹信息,同时考虑与其有相似行为活动用户的轨迹信息对未来位置进行预测.
在结合出行方式位置预测模块中,给定用户的历史出行方式集合,将其转化成出行方式序列,并结合目标轨迹数据提取特征建立模型对未来出行方式进行识别,然后结合目标轨迹序列及其对应的出行方式序列,建立Markov模型对未来位置进行预测,得到由位置候选集及其相应的概率值,最后结合其候选集和由语义轨迹模式挖掘模块中得到的位置候选集选择具有高得分高概率的位置作为最终的预测结果.
3 TransPredict算法设计与实现
3.1 基于语义及位置的频繁模式挖掘
本节研究内容是得到用户的轨迹后,对多用户的频繁轨迹路径进行挖掘,同时结合常去位置的兴趣度得到兴趣点挖掘,结合两者挖掘获得用户群体的日常行为规律.因此本节需要对不同用户轨迹路径进行频繁模式挖掘,并对目标用户轨迹进行未来位置的预测.因此我们将先对轨迹语义化得到语义轨迹,并进行相似用户挖掘得到相应的语义轨迹树;然后对相似用户的位置轨迹进行频繁模式挖掘得到位置轨迹集合,建立相应的位置轨迹树;最后对目标轨迹结合语义模式集合和位置模式集合进行相应的路径匹配,得到未来位置预测结果.
3.1.1 语义轨迹的频繁模式挖掘
在得到每个用户的位置轨迹点后,首先对位置轨迹进行语义映射并得到语义轨迹,具体算法过程见图3所示:
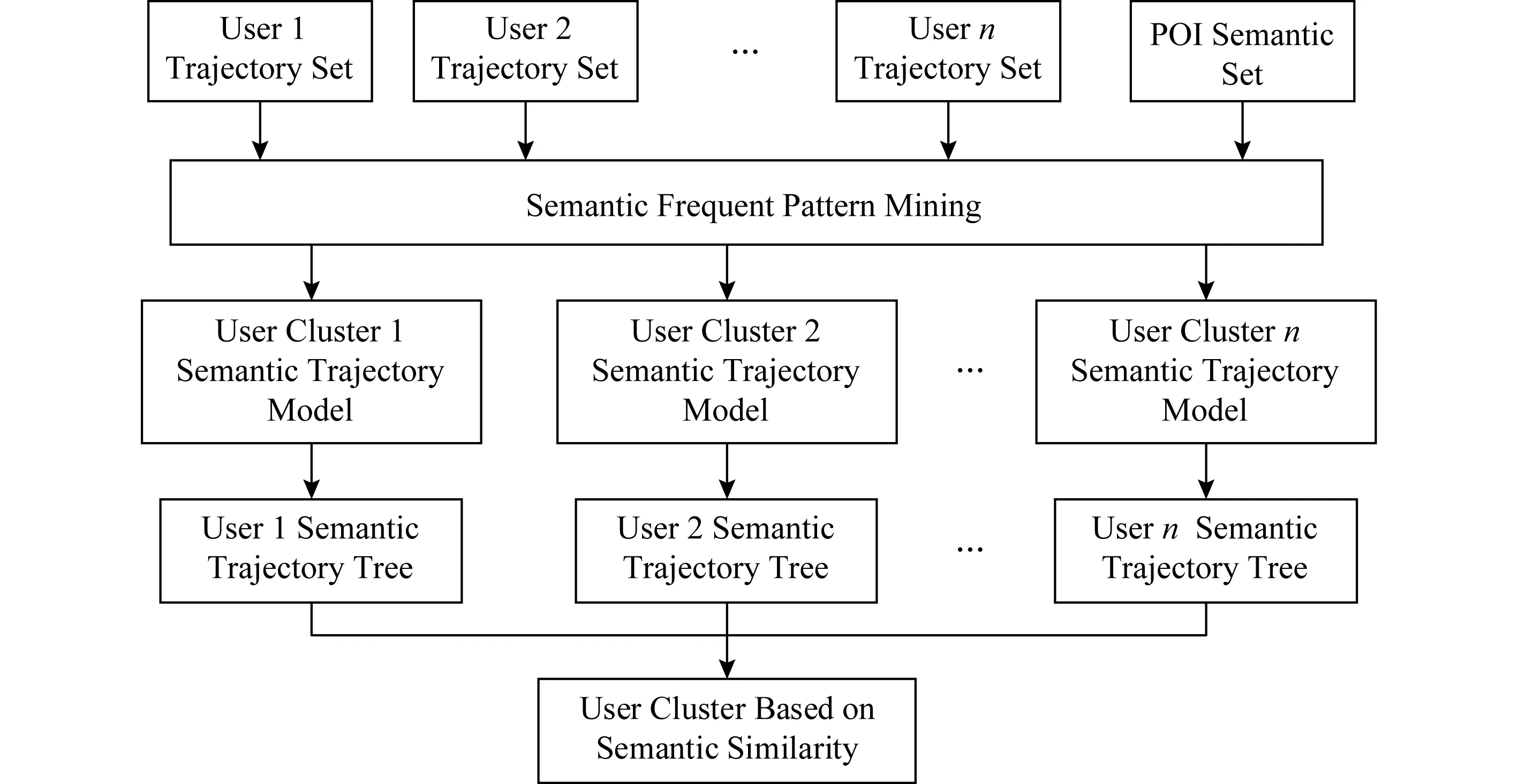
Fig. 3 Frequent pattern mining based on semantic trajectory图3 基于语义轨迹的频繁模式挖掘
基于语义轨迹的频繁模式挖掘算法的整体流程步骤:
1) 在获得每个用户的轨迹数据后,首先对每个点进行停留点(stay point)的挖掘,即根据半径和时间范围进行挖掘.在获得stay point后,使用基于密度的聚类算法K-means进行位置点的聚类,得到兴趣点的挖掘.由此位置轨迹由这些兴趣点位置所表示.
2) 对于得到由兴趣点表示的轨迹后,将这些兴趣点进行语义化,即调用Openstreet API对位置点进行语义标识.由此不仅得到语义轨迹,同时得到位置的POI语义信息集合.
3) 对各个用户的轨迹集使用PrefixSpan算法进行序列频繁模式的挖掘,即将语义轨迹挖掘出频繁模式,得到频繁语义轨迹集合.
4) 对挖掘的频繁语义轨迹集合建立前缀树,由此得到每个用户的语义模式树,用于对目标轨迹进行路径匹配.
5) 对于每个用户,使用MSTP轨迹相似度算法进行两两比较,根据此来进行用户的层次聚类,最后得到基于相似语义路径的用户.
因此该算法可由以上5个部分所得.接下来将对算法的具体过程进行展开介绍:
1) 语义轨迹的表示
根据GPS所表示的经纬度和时间戳代表的位置点组成的轨迹,我们采用文献[9]中的方法进行停留点的挖掘,然后选择基于K-means的聚类方法进行兴趣点的挖掘,由于该算法聚类得到的范围一般都是以圆圈为主,因此符合一个真实位置范围.由此GPS点组成的轨迹可表示成兴趣点位置轨迹.
对于得到的用户轨迹数据,我们对其进行语义标识的映射.对于兴趣点位置,将其语义化标识成语义轨迹,并将语义组成语义集合.如图4中的3条轨迹,可以进行语义化得到轨迹位置的语义标识,并得到相应的语义轨迹,如表1所示.
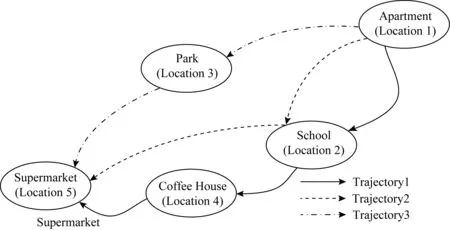
Fig. 4 An example of semantic trajectory图4 语义轨迹示图

Trajectory Location TrajectorySemantic TrajectoryTrajectory1Location1,Location2,Location4,Location5Apartment,School,Coffee House,SupermarketTrajectory2Location1,Location2,Location5Apartment,School,SupermarketTrajectory3Location1,Location3,Location4Apartment,Park,Supermarket
在将每个轨迹由位置轨迹转换成语义轨迹后,每个用户就有自己的语义轨迹集合.虽然每个用户由于自身的兴趣偏好不同,导致轨迹位置不一样,但是不可否认存在相似偏好的用户,他们的主要行为是相同的.比如如果用户是学生群体,那么他们白天的轨迹基本都是从家里到学校之间的轨迹路径;如果是上班族,那么他们的轨迹基本是从家里到公司,可能也会途径超市等地方.因此具有相似偏好的用户群体能够根据他们的语义轨迹被挖掘出来.
2) 语义频繁模式挖掘
为了获得用户的频繁行为活动,首先需要对用户的语义轨迹进行挖掘,除掉偶尔经过兴趣点,从语义上来挖掘其频繁路径.这里将采用PrefixSpan[10]算法来对用户的每条语义轨迹进行挖掘找到频繁语义轨迹.由于该算法是对序列模式进行挖掘,而轨迹在经过每个语义位置的前后顺序也非常重要,这也符合对具有序列形式的轨迹挖掘,因此将采用该方法来执行.
对于语义轨迹模式,可以提供不同的规则来定义预测的方式.比如对于公寓,学校,便利店这个频繁语义轨迹,我们可以得到当用户经过公寓并到达学校后,可以预测他的下一个语义位置是便利店.然而越长的频繁语义轨迹,它包含的频繁子序列也越多.因此当一个频繁序列是以上语义序列时,则对应的频繁子序列分别为公寓,学校,便利店,公寓,学校,公寓,便利店,学校,便利店.
3) 语义轨迹模式树的建立
当对用户的当前位置和其语义轨迹逐个进行匹配是非常耗时的,所以这边为了能够更有效且快速地进行位置预测,将采用前缀树的匹配算法实现,即建立语义轨迹树 (semantic trajectory tree, STraj-Tree)来代表语义轨迹的集合.语义轨迹模式树的建立过程参考文献[11]所示.对于表1中由位置轨迹语义化后得到的语义轨迹集合可以挖掘相应的语义轨迹频繁模式.假设设置PrefixSpan的最小支持度为0.5,则满足其支持度的所有频繁模式如表2所示:
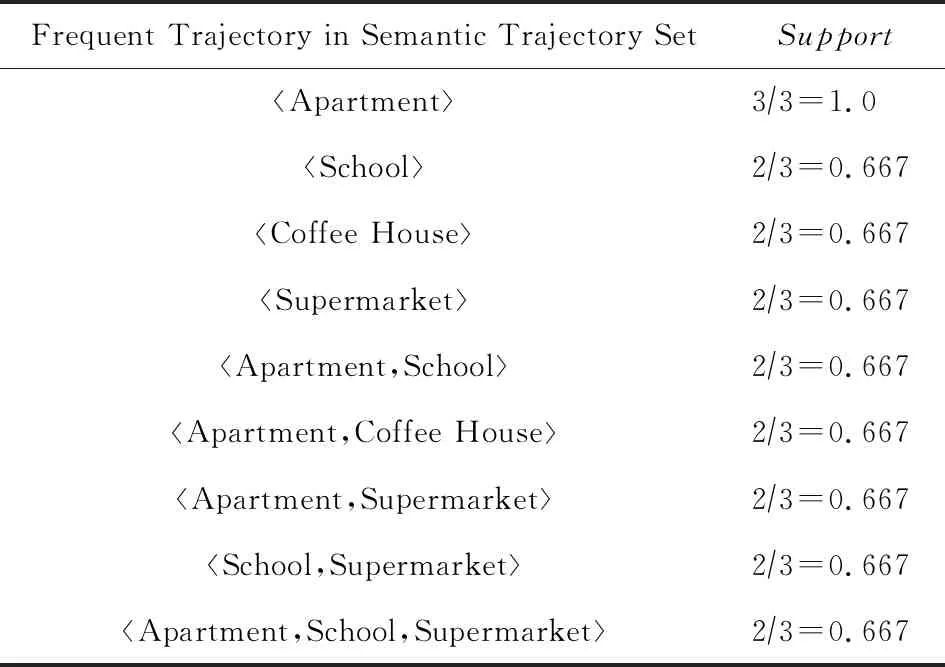
Table 2 The Frequent Trajectory in Semantic Trajectory Set表2 频繁语义轨迹集合
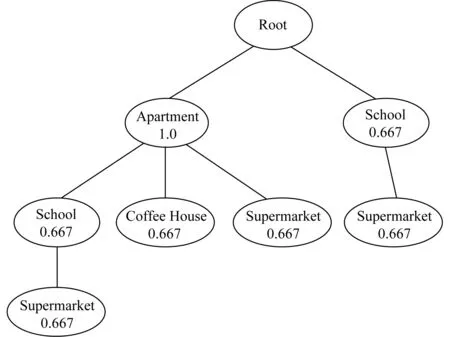
Fig. 5 Semantic trajectory tree with support of its node图5 语义轨迹树及其节点支持度
图5表示频繁语义轨迹集合对应的语义轨迹树STraj-Tree.可以注意到树的每个枝代表的就是一条频繁的语义路径,而该枝也同时包含许多频繁路径.如其中的路径(公寓,1.0)→(学校,0.667)→(便利店,0.667)同时包含很多语义轨迹模式路径,即公寓,学校,便利店,公寓,学校,公寓,便利店和学校,便利店.因此可以说轨迹模式树是对语义轨迹模式集合的一种压缩式集合形式.如果前缀树中一条枝包含多个频繁路径,则该枝条路径的支持度选择所有频繁路径支持度中的最大值.另外,对于只有一个位置点的频繁路径,则从轨迹模式数中剔除,因为它对于预测位置没有任何帮助.
4) 基于语义的相似用户挖掘
在对轨迹进行分析时,我们发现即使2条轨迹在位置上相似,但是若位置语义不同,预测的结果精确度不高,说明语义所带的指示性含义要比实际位置轨迹所代表的含义更深刻.基于语义轨迹分析,我们发现相似语义轨迹的用户,其也具有相似的兴趣偏好.因为当用户的频繁行为活动在语义上更具有相似性时,他们的下一个位置的预测结果不仅关联该用户自身的行为模式,同时也关联具有相似语义行为的其他用户,因此我们可以根据相似语义轨迹对相似行为偏好的用户进行聚类.
在对相似用户进行聚类时,我们需要对用户的语义轨迹进行相似度的衡量.首先采用最长公共子序列算法对不同轨迹得到公共相似序列,并用最大语义轨迹模式相似 (maximal semantic trajectory pattern similarity, MSTP-Similarity) 算法[12]来将公共序列和轨迹进行相似度的计算,那么对于计算2个用户的相似度,就是将2个用户分别对轨迹进行笛卡儿积式匹配计算,两两轨迹分别进行计算,那么用户的相似度就是其所有语义轨迹的相似度的平均值.由此可以来衡量2个用户的相似性的程度.根据此相似度计算标准,最后用层次聚类算法对相似用户进行聚类,得到具有相似语义轨迹的用户集合.
3.1.2 位置轨迹的频繁模式挖掘
将语义轨迹模型建立后,由于预测得到的只能是位置语义信息,而不能得到具体位置坐标,因此我们需要进行地理位置信息的挖掘并建立频繁位置轨迹模型.该算法具体过程如图6所示.
由图6看出,对位置轨迹进行频繁模式挖掘且模型建立的过程有4个步骤:
① 对于根据语义信息聚类后的用户,对同簇中的相似用户的位置轨迹合并;
② 对同簇中的位置轨迹,使用PrefixSpan算法进行序列频繁模式挖掘,得到频繁位置轨迹集合;
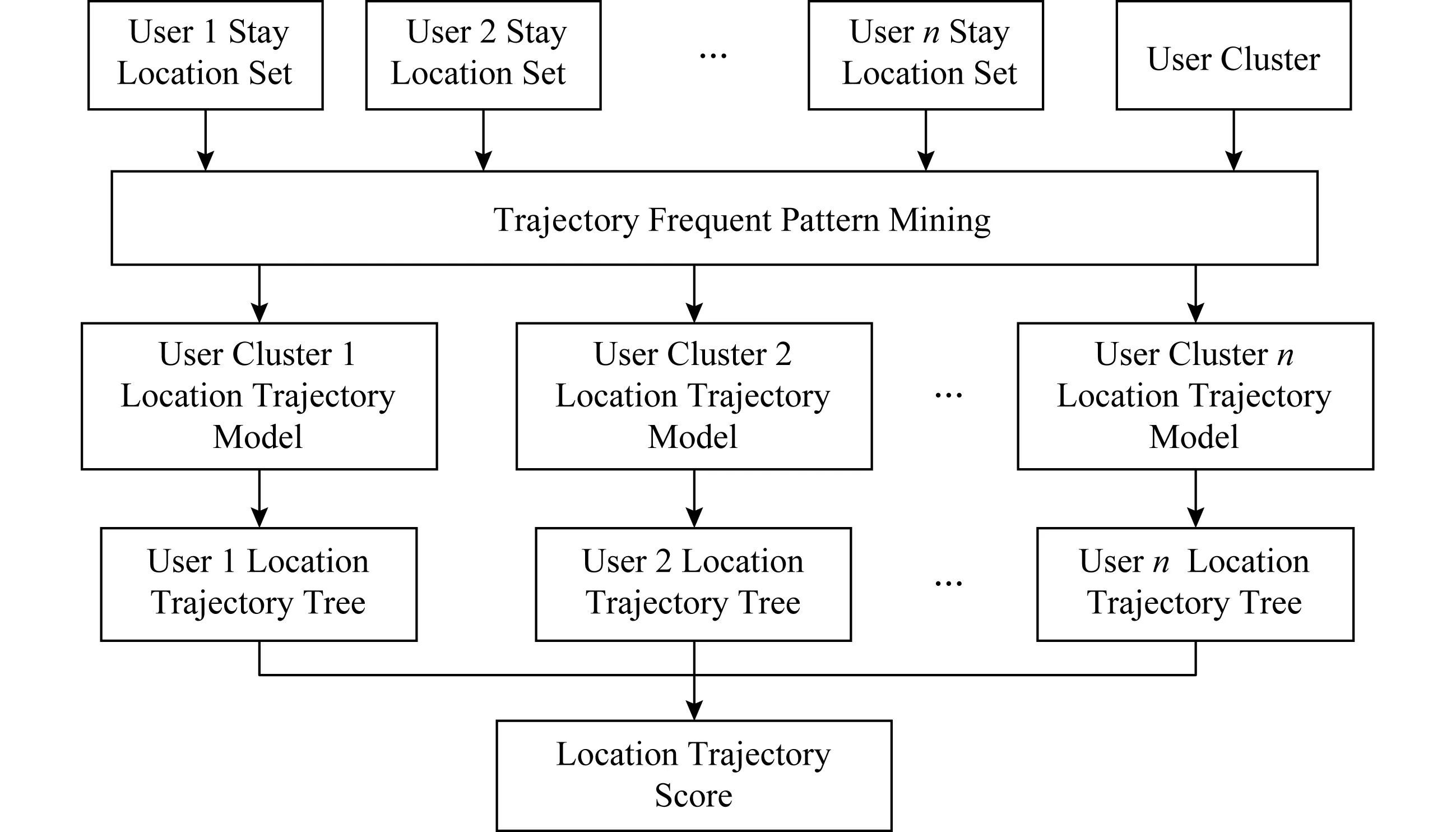
Fig. 6 Frequent pattern mining based on location trajectory图6 基于位置轨迹的频繁模式挖掘
③ 对挖掘的频繁位置轨迹模式建立Prefix-Tree前缀树,同样形成了位置轨迹树;
④ 根据目标轨迹对位置轨迹树进行路径匹配并计算位置轨迹得分.
1) 位置轨迹频繁模式挖掘
根据语义轨迹进行相似用户聚类之后,得到具有相似行为活动的用户簇.在通过对用户簇中所有轨迹的兴趣点进行聚类统一后,我们需要对频繁的位置轨迹模式挖掘,挖掘出这些相似用户实际位置的相似程度.同样,采用PrefixSpan算法对位置轨迹进行频繁模式挖掘.比如,假设对表1中的3条位置轨迹进行挖掘,设最小支持度为0.5,则可以得到相应的频繁位置轨迹有位置1,位置2,位置5,位置1,位置4.对于这些频繁位置轨迹,可以得到相应的支持度,具体如表3所示:

Table 3 The Frequent Trajectory in Location Trajectory Set表3 频繁位置轨迹集合
2) 位置轨迹模式树的建立
在对位置轨迹集合进行频繁模式挖掘后,得到频繁的位置轨迹集合.同样建立相应的位置轨迹树 (location trajectory tree, LTraj-Tree)来代表位置轨迹的集合.如图7所示,轨迹树的每条路径就是频繁子序列轨迹,路径上的每一个节点代表兴趣点位置序号和支持度.
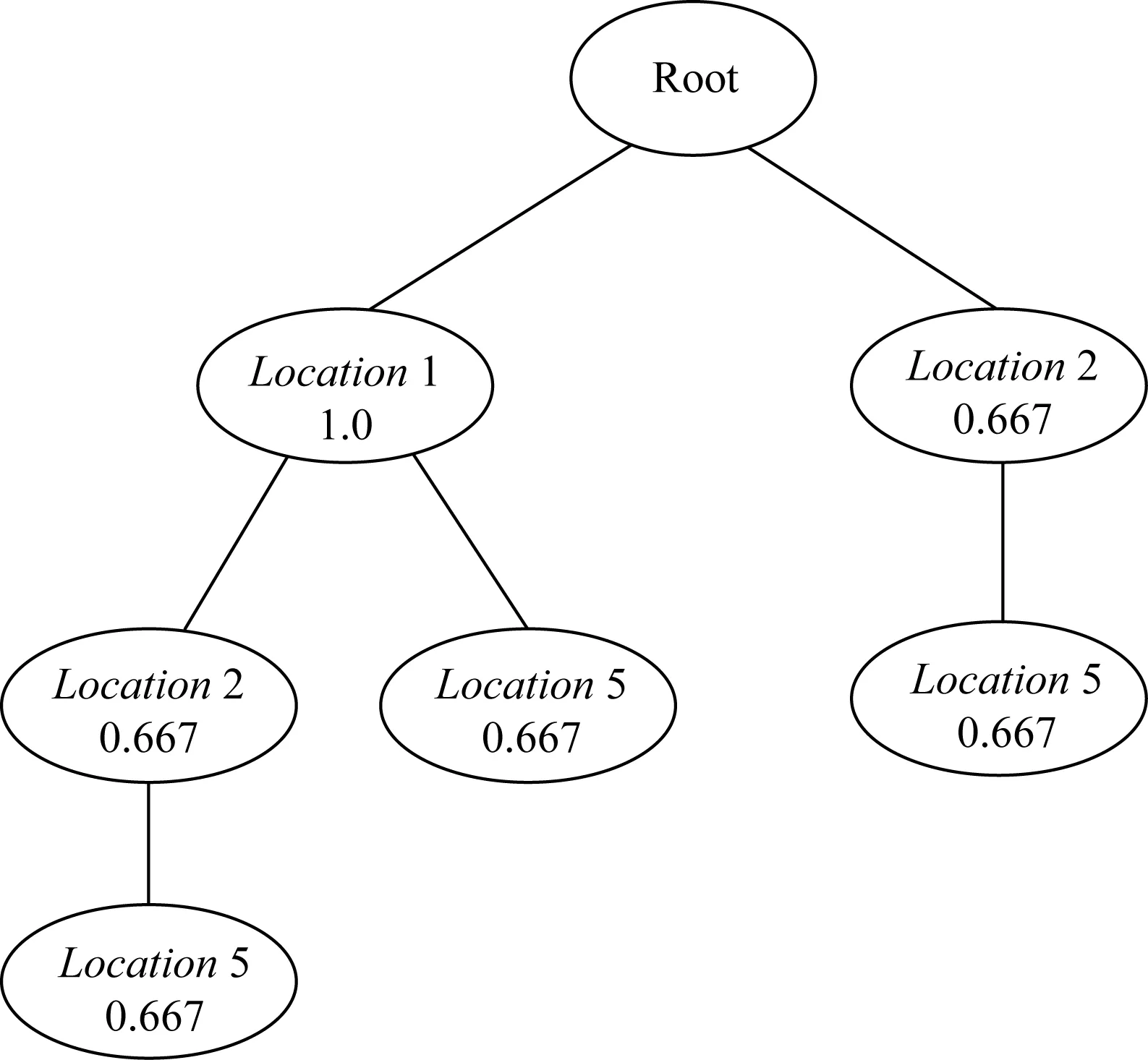
Fig. 7 Location trajectory tree with support ofits node图7 位置轨迹树及其节点支持度
图7所示为根据表3中的频繁位置轨迹集合建立的位置轨迹树.对于一条路径上包含的多个位置轨迹,将进行重叠处理,如果经过某个节点上的路径有多条,则选择支持度最大的路径作为该位置的支持度.同样,由于只有一个节点的路径并不能对位置预测提供帮助,因此将取消其路径.
3.1.3 位置预测
当给定用户的轨迹数据后,我们不仅从轨迹语义上分析并得到用户频繁的行为路径,同样也从轨迹位置上分析得到相似用户在实际位置行径中的频繁行为活动.由此得到基于个人轨迹建立的语义轨迹树和基于相似行为用户建立的位置轨迹树.当对目标位置轨迹进行位置预测时,我们将其对2棵轨迹树进行相应的得分计算,最后对得分进行加权得到相应的匹配路径集合,即:
Result_Score=α×Semantic_Score+ (1-α)×Location_Score,
(1)
其中,权值为ɑ,且满足0<ɑ<1.这里Location_Score表示当前的路径与位置轨迹树的位置得分,Semantic_Score表示与语义轨迹树进行匹配得到的语义得分.我们首先进行位置轨迹树的得分计算,若大于0,则说明此路径可作为候选路径.由此对其转换成相应的语义路径,并将此语义路径与该用户的语义轨迹树进行匹配得分,最后将两者进行加权得到相应路径的最后得分.另外,由于本模型是对具有语义轨迹聚类后的相同簇内的用户们的位置轨迹进行建树,因此若用户为了隐私保护而关闭设备未获取到位置信息,模型会挖掘该用户其他时间段的轨迹信息的语义找到对应的簇,当对该用户进行预测时也会将其他用户经过的位置作为预测结果.因此若用户出于隐私保护未上传部分位置轨迹对模型不会造成重大影响.下面将对具体位置轨迹树和语义轨迹树得分的计算进行介绍.
1) 位置轨迹树得分
在得到当前用户的目标轨迹位置点后,将其转换成位置轨迹序列.另外由于该轨迹序列可能较长,因此在与位置轨迹模式树进行匹配时会耗时,我们采用半匹配算法[11]进行匹配.
在对目标轨迹T与位置轨迹树路径P的匹配进行计算得分时,采用文献[11]中的计算得分:
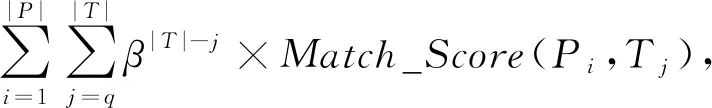
(2)
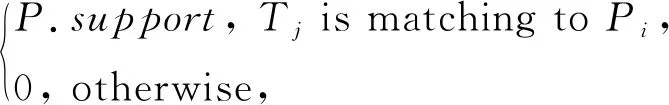
(3)
式(2)(3)表示在对目标轨迹T和轨迹树P进行匹配时,首先从目标轨迹T当前位置开始(q=1)选取位置序列.其中β|T|-j表示离匹配位置越远的位置,其重要性越低.当匹配Tj与Pi时,若相等,则将Pi的支持度作为匹配的得分Match_Score,最后根据目标位置序列及轨技树进行匹配得到最后的得分.如图8为匹配过程,假设路径权值β=0.8,当q=1时,用户的位置轨迹序列为位置5,位置1,位置2,此时没有与之匹配的路径,因此得分为0.当q=2时,位置轨迹序列为位置1,位置2,与模式树的路径(位置1,1.0)→(位置2,0.667)相匹配,因此相应的得分为0.8×1.0+0.667.当q=3时,位置轨迹序列与路径(位置2,0.667)相匹配,因此得分为0.667.候选轨迹及相应的得分计算如表4所示.由此就可以得到每条候选轨迹及相应的地理位置得分,若该轨迹的得分为0,则去除该候选轨迹.
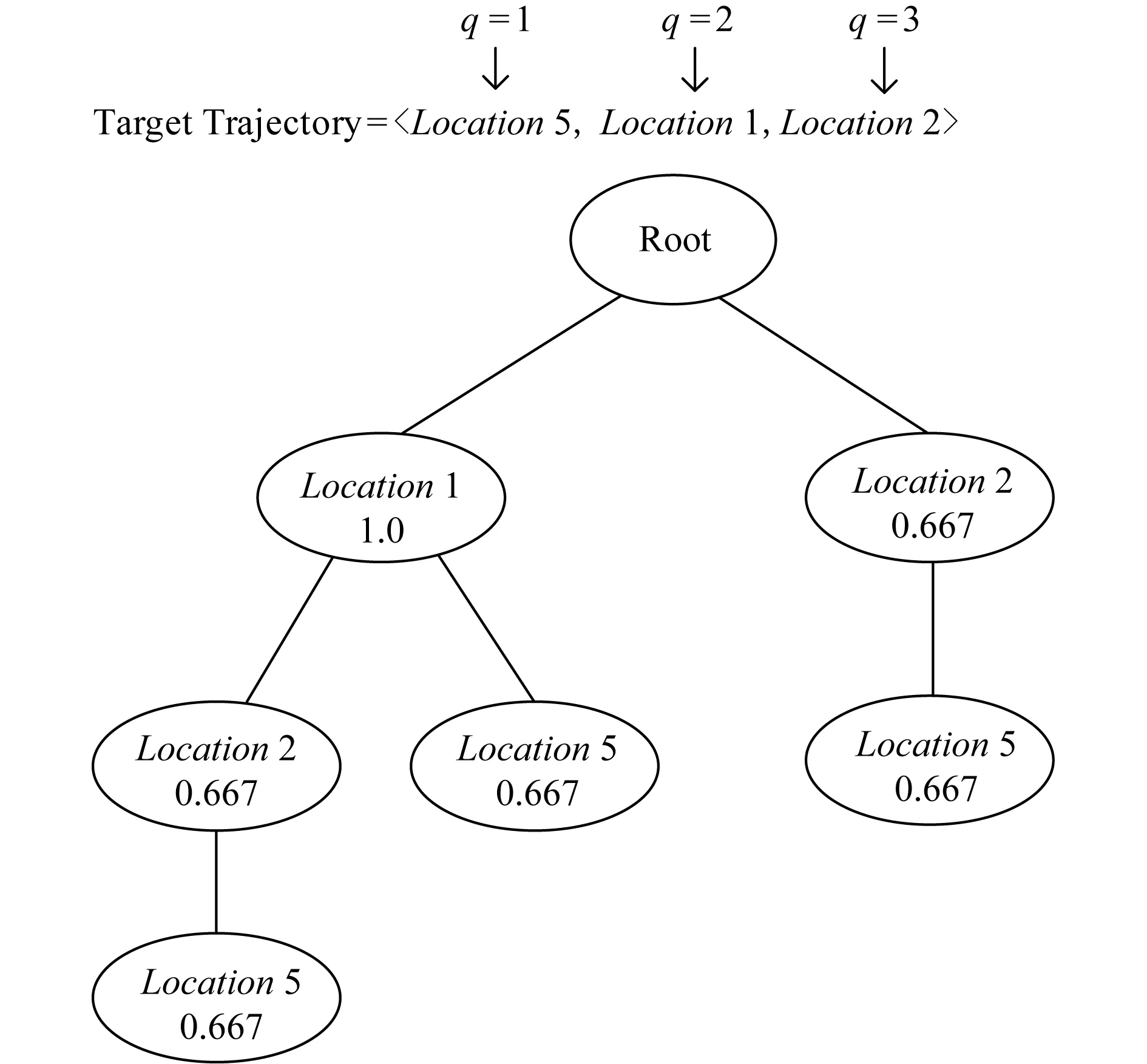
Fig. 8 The matching process of target path and LTraj-Tree图8 目标路径与位置轨迹树匹配过程

Candidate Location TrajectoryLocation ScoreLocation5,Location1,Location20Location1,Location20.8×1.0+0.667=1.467Location20.667
2) 语义轨迹树得分
由于只根据地理位置的轨迹来进行用户的位置预测并不准确,因此需要结合语义轨迹来进行挖掘,因此在对目标轨迹进行分析时,也需要将其与语义轨迹树进行匹配得到相应的语义得分.我们仍然采用半匹配算法进行匹配得分.如图9为例子,假设路径权值β=0.8,则候选语义路径为公寓,学校.当q=1时,语义路径公寓,学校与语义轨迹树的路径(公寓,1.0)→(学校,0.667)相匹配,因此相应的语义得分为0.8×1.0+0.667.当q=2时,语义轨迹与路径(学校,0.667)相匹配,因此其相应的得分为0.667.其计算语义得分的过程如表5所示.
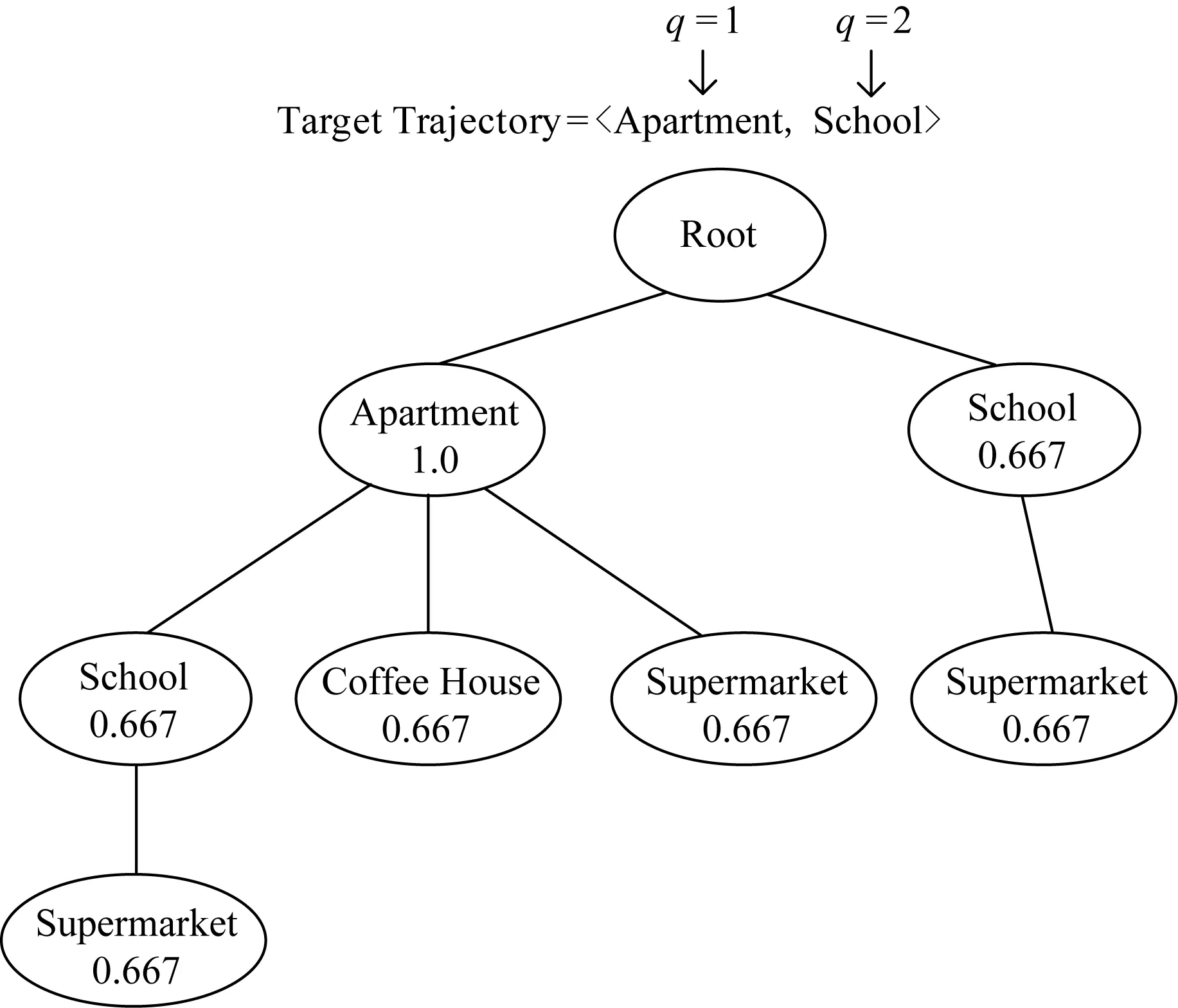
Fig. 9 The matching process of target path and STraj-tree图9 候选路径与语义轨迹树匹配过程

Candidate Semantic TrajectorySemantic ScoreSupermarket,Apartment,School0Apartment,School0.8×1.0+0.667=1.467School0.667

Fig. 10 The location prediction model with transportation mode图10 结合出行方式的位置预测模型
最后,我们使用式(1)来对每条候选路径进行计算总的得分.根据表4和表5中的每条路径的位置得分Location_Score和语义得分Semantic_Score,进行加权并得到最后的得分结果.假设权值ɑ=0.7,则对应候选路径位置1,位置2的最后得分为0.7×1.467+0.3×1.467=1.467.而对于另一条候选路径位置2的最后得分为0.7×0.667+0.3×0.667=0.667.因此我们可以得到得分最高的候选路径为位置1,位置2.因此对于目标路径位置5,位置1,位置2,其要预测的位置结果即为候选路径的子节点的位置值.而如果当最高的候选路径没有下一个节点的话,就选得分排第2的候选路径的子节点作为预测结果,以此类推.由此我们结合语义轨迹和位置轨迹来对目标轨迹匹配并依据相应得分得到位置预测的候选集.
3.2 基于出行方式及语义轨迹的位置预测
本研究内容是在对轨迹位置进行预测时,只考虑轨迹数据并不能对位置预测结果精确度的提高产生更高的有效性,因此需要结合多源数据进行考虑.本文将结合用户的历史出行方式以及根据用户历史轨迹数据来对用户的未来位置进行预测.
对于根据用户得到的轨迹数据,结合兴趣点位置间的距离、用时时长、出行方式等因素,并根据历史出行方式,对其下一个出行方式进行识别分析.结合得到的未来出行方式,同时根据历史出行方式的先验知识建立Markov模型对未来位置进行预测并根据概率高低得到位置结果候选集.而在频繁轨迹模式挖掘中,位置的预测结果是将位置轨迹树中符合路径的子节点位置提出来当作预测的结果,然而一个节点有多个子节点,因此我们将这些多个子节点都提取出来当作要预测的位置候选集,最后结合2部分位置候选集合中具有高概率值且高得分的结果作为最后的预测结果.整体算法如图10所示.
我们可以根据未来出行方式及用户历史轨迹数据建立模型来对未来位置进行预测.在对未来位置进行预测的研究内容中.我们将结合出行方式和历史位置轨迹建立基于Markov模型的位置预测模型,该模型如图11所示.其中将出行方式设置为对应Markov模型中的状态,轨迹位置则设为对应模型中的观测值.因此,设状态对应出行方式的集合M={m1,m2,…,mN},观测值对应兴趣点位置的集合D={d1,d2,…,dL},其中N是出行方式的种类数,L是可能的不同位置数.长度为T的交通模式序列W=(w1,w2,…,wT),对应的出行轨迹序列O=(o1,o2,…,ov).同时设置出行方式转移矩阵R=[rij]N×N,其中:
rij=P(it+1=mj|w=mi),i=1,2,…,N;j=1,2,…,N.
rij表示时刻t到时刻t+1时出行模式从mi到mj模式的转移概率值.
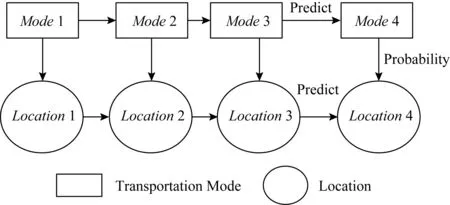
Fig. 11 The Markov model combined with transportation mode图11 结合出行方式的Markov模型
用户的历史轨迹位置概率矩阵B=[bj(k)]N×M,其中:
bj(k)=P(ot=dk|wt=mj),
k=1,2,…,L;j=1,2,…,N.bj(k)表示时刻t时用户在使用出行模式mj下行驶到兴趣位置dk的概率值.同时结合出行方式的先验知识,即θ作为用户选择出行方式的概率:θ=(θi).其中θi=P(w1=mi)是当时刻t=1时选择不同出行方式mi的概率.
本模型将结合用户的出行方式先验概率θ、出行方式之间的转换概率R和得到的历史轨迹对应的位置概率B对未来位置进行预测.其中隐藏的出行方式序列由其模式的初始概率和不同模式之间的转换概率来决定,而用户行径的轨迹位置预测则由在不同出行模式下到达的位置概率和位置间转换的概率来共同决定,最后根据不同的出行方式结合用户的轨迹位置序列得到未来位置预测结果.
因此在计算最后的概率时,我们将计算最后位置的概率.如图11所示,假设观测到的位置序列为(o1,o2,o3),其中o4为要预测的结果,且隐含出行方式序列为(m1,m2,m3),其中m4为识别的未来出行方式结果,那么预测位置的概率为
P(oi=o4|w1=m1,w2=m2,w3=m3,w4=m4)=P(m1)×P(m1→o1)×P(m1→m2)×P(m2→o2)×P(m2→m3)×P(m3→o3)×P(m3→m4)×P(m4→o4),
由此可以得到o4为各个位置下的概率,最后根据概率的大小组合成位置候选集合.
在得到由频繁模式挖掘得到的位置轨迹集合S1和由Markov链得到的位置轨迹集合S2后,将从S2中选出含有集合S1中的位置,并将概率最大的位置作为预测的位置,即可得到最后的预测结果.
4 实验评估
4.1 实验数据集
在本次实验中,我们将采用微软亚洲研究院的Geolife项目中的数据[13],采用17个在2007-04—2008-10的用户数据,共400万条数据.数据中用户外出时选择的出行方式包括走路、骑自行车、坐公交车、坐汽车(出租车)、轻轨等.根据以上数据,将选择80%的轨迹数据作为训练数据,测试数据源则为余下的数据集.
4.2 实验设计
本次实验主要分为2个部分:1)对结合语义轨迹和位置轨迹的轨迹频繁模式挖掘的位置预测算法进行有效性验证;2)对结合出行方式和轨迹频繁模式挖掘建立的位置预测模型进行有效性验证.
4.2.1 结合语义轨迹的位置预测算法验证
在本次实验中主要包括2部分实验内容:1)对算法中存在的阈值进行合理性调试,并观察阈值对结果精确度的影响;2)对整个算法框架进行在不同阈值下的结果验证.在本次实验中,第1部分是对2个阈值进行调整,第1个阈值是对语义模式树和轨迹模式树2种加权结合得分的权值设定,通过对语义模式树权值和位置模式树权值的高低调整来分析两者对于最后预测位置结果的影响;第2个阈值是在前缀匹配算法中,对于轨迹位置距离要预测的位置远近进行加权的权值设定.轨迹中距离当前轨迹位置越近,位置距离的权值设置越高,使其对要预测位置的结果产生影响,本次实验也将从结果中来确定算法的有效性.
我们将对算法中各个参数的范围设定进行分析,并讨论关于参数对预测结果的影响.
1) 对语义模式树和位置模式树的权值α进行讨论.为了防止其他阈值变量对结果的影响,将设定β=1,即对轨迹上的位置权值都设为相等,以免其值对预测结果产生不必要的影响.同时,为了说明阈值对结果的影响性,我们对支持度分别为11%和15%这2种情况进行分析,验证阈值对结果的影响.实验结果如图12所示:
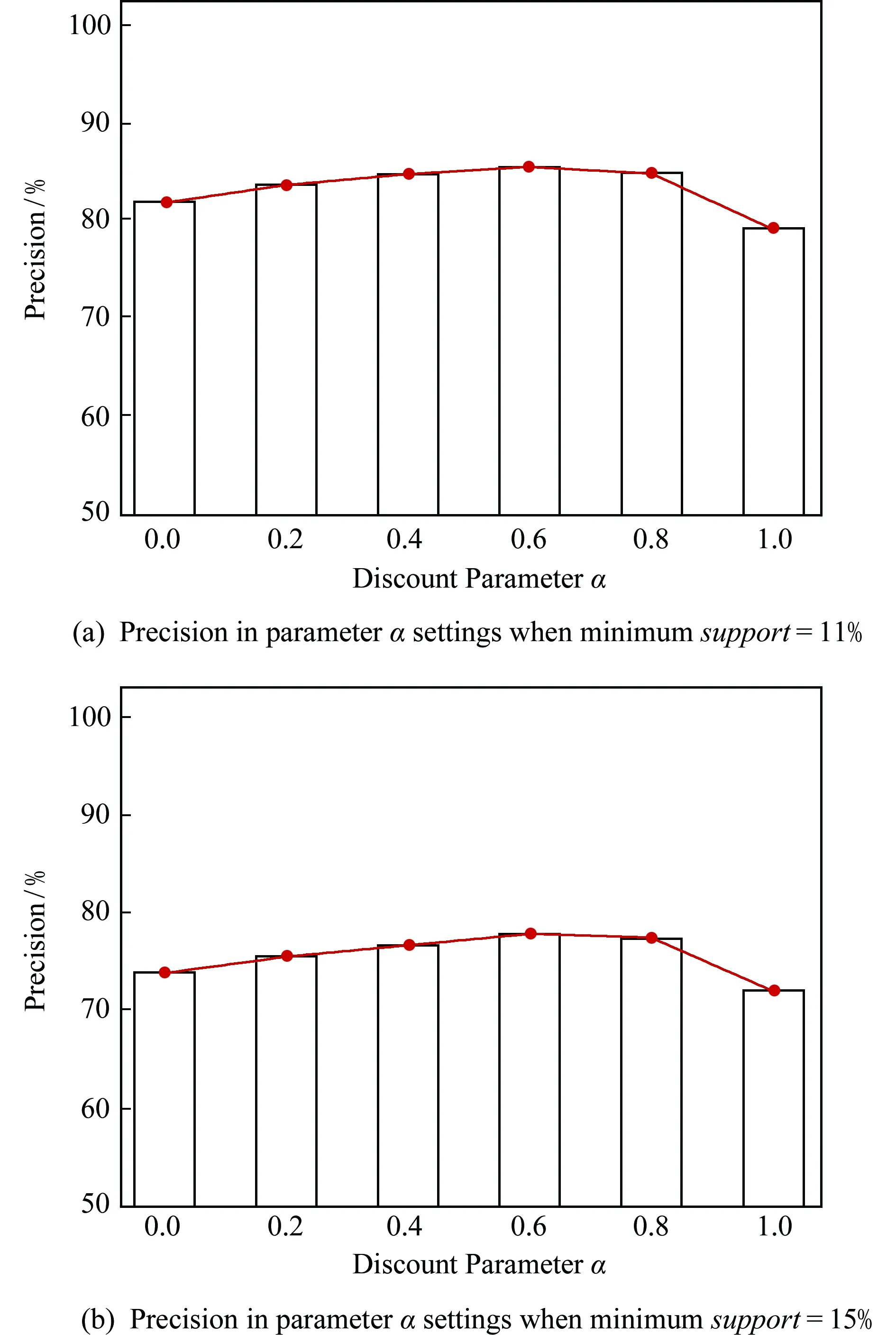
Fig. 12 The accuracy of prediction result with semantic parameter ɑ图12 语义参数ɑ对预测结果的精确度
从图12中我们看到,对于语义参数α<0.6时,其参数值越高,对语义模式树赋予的权值也越重,其预测结果的精确度也越高,这表明结合语义轨迹后的精确度提高;当α=0.6时达到85%的精确度,验证了语义轨迹对位置预测的有效性.我们相信:因为有相同语义的用户进行聚类后,有相似行为活动的用户其经常活跃的兴趣区域大致也是相同的.但是当语义参数α越接近1时,精确度反而会下降,这也说明了只考虑语义轨迹而不考虑位置轨迹,得到的实际位置预测精确度也不会很高,说明位置轨迹也需要考虑,并且是不可或缺的一部分.
2) 分析轨迹位置的距离参数β对预测结果的有效性.在对轨迹进行预测时,我们有理由相信,距离要预测的位置越近,其对预测的结果越有影响;而距离要预测的位置越远,说明去过这些地方的时间越久,对要预测的位置的影响力并不是很大.因此需要对位置的不同权值进行分析,并观察权值大小对预测结果的影响.为了验证参数β对结果的有效性和必然性,我们同样查看2种不同的支持度下的预测结果.在这里同样对支持度取11%和15%,查看不同支持度下的结果.结果如图13所示:
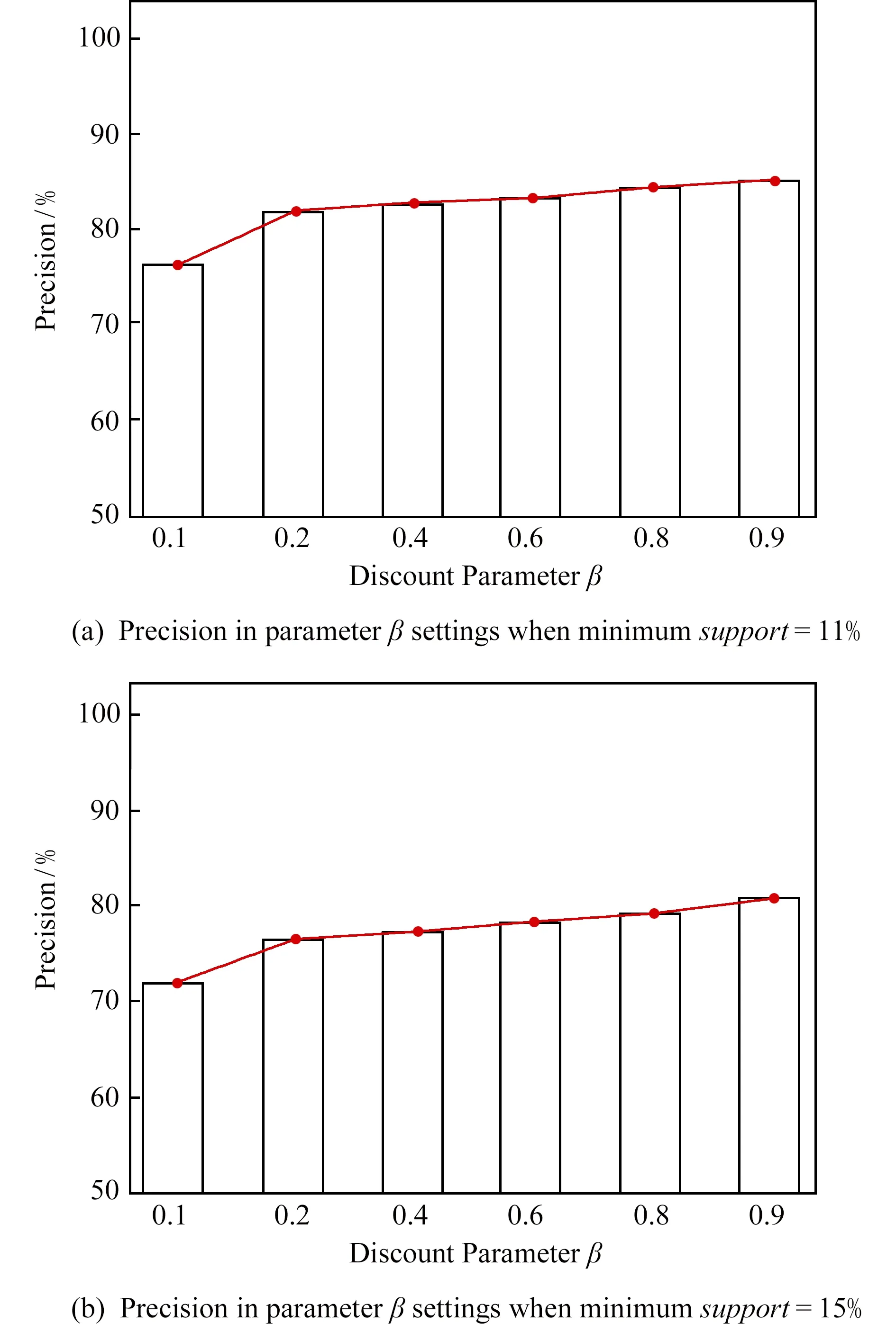
Fig. 13 The accuracy of prediction result with locationdistance parameter β图13 位置距离参数β对预测结果的精确度
根据图13中的结果可得,随着距离参数β的值越大,其预测位置的精确度也越高,达到84%左右,说明轨迹上距离要预测的位置近的权值越大,对位置结果的预测越有效;而在轨迹上的位置来说,距离要预测的位置越远,其对预测结果的影响也越小,这也证实了我们猜想的正确性.
综上所述,根据对2种不同阈值的分析,得到2种参数各自对位置预测的结果,不仅证明了语义轨迹对于位置预测的有效性,同时也证明了在轨迹上距离当前预测位置越近的对预测结果的影响越大.
4.2.2 结合出行方式的位置预测模型
在本次实验当中,我们将采用4.1节中介绍的实验数据集,对轨迹进行兴趣点位置的挖掘,并对总的兴趣点位置进行总的位置统一并由固定个数的兴趣点位置来表示轨迹.在得到由兴趣点位置表示的轨迹后,我们同时得到相应位置之间所使用的出行方式及时长、位置间距离等属性来对后续的实验进行验证.
本部分实验的内容主要分为2大部分:1)根据轨迹中所经过的历史出行模式及相应的兴趣点位置对未来出行方式进行预测;2)根据未来出行方式、历史出行方式及历史位置对未来位置进行概率计算得到最后的结果.
4.2.2.1 出行方式识别算法验证
在本节实验中,我们根据用户的轨迹数据所经过的历史出行方式,对未来的出行方式进行识别.根据轨迹数据中我们将提取兴趣点位置之间的用户经过的路径长度、用户用时时长、当前兴趣点的类别以及当前的出行方式进行特征提取,并采用随机森林模型进行建立模型,我们将采用80%的实验数据作为训练数据,剩下的数据将作为测试数据来对模型进行精确度验证.我们将对每个用户都进行实验,实验结果如表6所示:
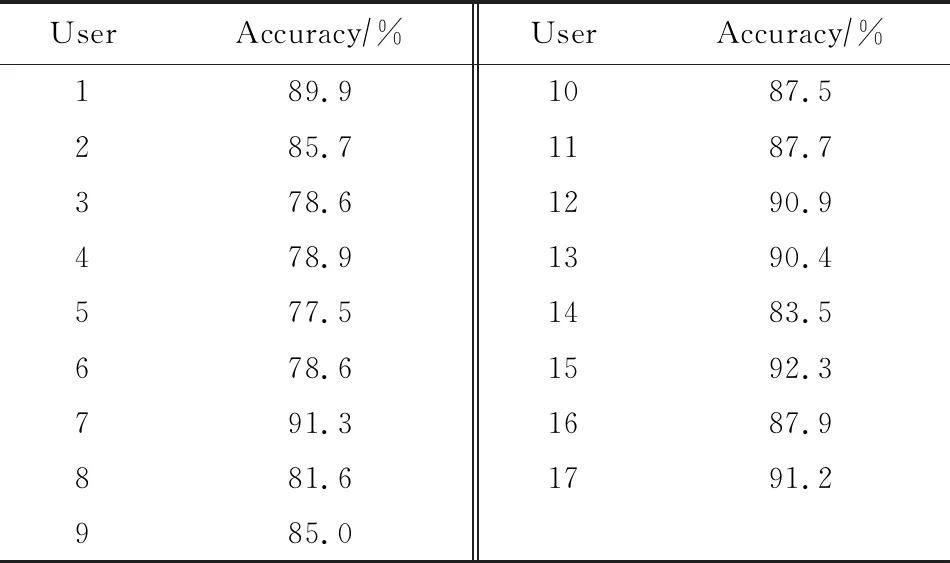
Table 6 The Transportation Recognition Accuracy ofEach User表6 各用户的出行方式识别结果
表6所示为对每个用户的出行方式的识别精确度的结果,可以看出识别结果在80%左右,因此识别精确度较高,模型具有较强的泛化能力.
4.2.2.2 未来POI位置的预测实验
在本次实验中,我们将根据4.2.2.1节中得到的未来出行方式以及历史轨迹位置数据,基于Markov模型,得到下一个的位置结果结合,并得到概率从高到低排列的位置集合,然后从第1部分结果中得到的候选位置集合选择概率最大的作为预测结果.
在本次实验中,我们将对此实验数据仍采用80%作为训练数据,剩下的数据作为测试数据.我们将仍用17个用户的轨迹数据来进行实验,并将所有用户的均值作为最后的精确度.在实验中,为了证明我们算法的有效性,我们将用结合语义和位置轨迹的位置预测算法SemanticPredict的和本模型算法TransPredict的结果进行对比,同时根据不同支持度下的算法得到的精确度变化查看模型的有效性和泛化能力.具体结果如图14所示:
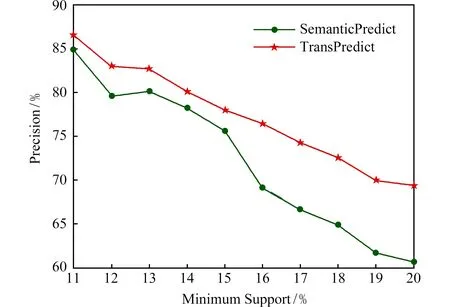
Fig. 14 The comparison of TransPredict model algorithom and SemanticPredict model algorithom图14 TransPredict模型算法与SemanticPredict模型算法精确度的对比
由图14中的结果所示,在结合出行方式数据之后,本模型算法TransPredict得到的位置预测精确度达到86%左右,同时在不同支持度下要始终比根据频繁模式轨迹的模型SemanticPredict得到的精确度高,且平均高5%.另外本模型算法TransPredict的变化趋势随着支持度的增加是稳定地下降,因此可以得到我们的模型具有普适性和较强的泛化能力.最后,由于本方法使用来自微软亚洲研究院的数据,故将与同样使用该数据的文献[14]对位置进行预测的方法进行比较.由于本方法同时结合用户的出行方式,采用用户路径数据均包含大于等于2次不同的方式,即用户的路径中包含至少多于2种不同的位置.因此本方法将与文献[14]中历史位置数量大于2种的结果进行比较.由图14可得本方法最高精确度能达87%左右,而该论文中使用同样的数据集,当历史位置个数大于2时进行实验所达到的准确率最高在85%左右,因此可得在对未来位置预测时本方法能给出更高准确率的结果.
5 结 论
本文提出一种挖掘轨迹信息数据同时结合出行方式的外源数据建立未来位置预测模型.在轨迹信息数据挖掘方面,本文首先通过对轨迹数据进行分析,设计实现一种同时结合语义轨迹和位置轨迹模式的组合模型,通过对语义轨迹进行频繁模式挖掘得到语义轨迹结合并挖掘相似用户簇.再对相似用户的位置轨迹进行模式挖掘得到位置轨迹集合,得到2种不同方式的集合.最后在对轨迹位置进行预测时,对目标轨迹进行匹配得到预测结果的位置.
在结合出行方式作为外源数据方面,通过对轨迹数据和用户的出行方式进行分析,设计实现一种结合用户出行方式和用户频繁模式结合的模型,即根据用户的GPS轨迹数据,以及用户的历史出行方式对用户的未来出行方式建立的模型进行预测,同时结合根据用户的行为活动和轨迹频繁模式挖掘得到的位置候选集合,使用Markov模型对用户的下一个位置预测得到结果.最后结合2部分模型得到的候选集获得最终未来位置的结果.实验方面通过在真实数据集上进行实验,验证本模型位置预测结果具有较高的精确度且具有较强的泛化能力.
