基于“神威·太湖之光”的区域海洋模式并行优化
2019-07-15倪裕芳黄小猛
吴 琦 倪裕芳 黄小猛
(地球系统数值模拟教育部重点实验室(清华大学地球系统科学系) 北京 100084) (清华大学地球系统科学系 北京 100084) (国家超级计算无锡中心 江苏无锡 214011)
地球系统模拟作为研究全球变化的重要手段,在很多领域都起到了至关重要的作用,是国家经济、军事、农业等多方面发展的重要战略项目.以地球系统模拟中气候模式为例,模式中气象预报的准确程度关乎着国家的农业、军事、经济、国家安全等众多方面,与人民生活息息相关.因此,如何提高模式的计算效率、精准率一直是国家重视的问题.且随着模式分辨率不断的提高,模拟效果会愈加准确,所以高分辨率地球系统模拟将是未来模式发展的必要趋势.
海洋模式在地球系统模式中占有重要地位,通过模拟海洋洋流、漩涡等现象,不仅能够很好地表示海面温度和高度分布,还能够实时预测台风、海啸等现象.尤其在沿海地带,海洋模式在航海、渔业、台风预测等众多方面都有用武之地.除此之外,海洋模式还是地球系统模式中计算量较大的模块,且为海冰等其他模式提供驱动力.综上所述,提高海洋模式的分辨率、计算效率,能够大幅提高地球系统模拟的性能,为国家建设保驾护航.
近年来,为了提高模拟的准确性以及更好地理解和预测海洋气候系统演变,海洋模式变得越来越复杂[1-2].复杂性源于2个主要部分:1)增加更多在之前的研究中未被考虑的物理过程[3-4].考虑到当前典型的海洋模型已经相当复杂,具有数十万行代码[5],实现、调试和维护这些新增加的物理过程对于模式开发人员显然是一个极其沉重的负担.2)对更高时空分辨率日益增长的需求,这不仅源自更高的精确性要求,也是模拟海洋动力学多尺度过程相互依赖的必要条件[6-8].在更广泛的空间和时间尺度[9-12]中对高分辨率海洋建模需要比之前更多的计算资源,这些计算资源只能由超级计算机提供.
超级计算机自出世以来,在天气预报、军事、核业、航天等科技领域大展身手,其性能已成为衡量国家科技能力的一个标准.随着散热和功耗成为通用处理器的主要瓶颈,多核、众核以及由此导致的异构已成为下一代超级计算机的发展趋势[13].近年来,随着NVIDIA公司专门为浮点计算设计的GPU,Intel公司设计的MIC卡逐渐普及,异构体系结构也逐步成为了超级计算机的主流方向.得益于高效率的计算以及并行机制的发展,不少科学研究在超级计算机这个大平台上的取得了显著的效果.例如: 2008年,Michalakes等人[14]利用GPU将WRF模式中的一个计算密集型过程加速了25倍;2010年Song等人[15]利用OpenACC方式,加速了POP(parallel ocean program)中某些函数,达到2.2倍加速效果.由此可见,异构众核的超级计算机体系结构大幅度提高计算效率,推动了模式的发展.
综上所述,为了提高海洋模式的分辨率、计算效率,本文基于国产超级计算机“神威·太湖之光”[16],移植并优化了适用于异构众核体系结构的高分辨率区域海洋模式swPOM(Sunway Princeton ocean model).这一模式充分发挥了国产异构众核平台的特点和优势,能够进行高分辨率的区域海洋数值模拟,并且在性能上与通用平台相比得到2.8倍左右的提升,为实时预报平台提供了保障.本文主要贡献有3个方面:
1) 在区域海洋模式POM[17](Princeton ocean model)的基础上,基于异构众核超级计算机“神威·太湖之光”实现了高分辨率区域海洋模式swPOM.
2) 充分利用众核优势和大规模并行优化技术,swPOM的性能达到传统超算平台的2.8倍以上,并且能够扩展到25万核规模以上.

Fig. 1 Heterogeneous many-core processor — SW26010图1 异构众核处理器——申威26010
1 相关工作
海洋模式自1967年诞生以来发展迅速,至今已经有40多个海洋模式版本,包括对不同区域和不同学科的海洋模式[18].其中比较有代表性有全球海洋模式[19](modular ocean model, MOM),POP[20],区域海洋模式[21](regional ocean model system, ROMS),POM等.目前多数海洋模式已经能够较为精确地模拟海面温度和高度的分布、海流分布等过程,而有些模式更是充分利用海洋资料同化系统开发海气耦合模式,这些都是海洋模式发展的重要方向.海洋模式本质上是用数值方法来模拟和预测海洋未来变化趋势.而大规模模式低下的计算效率、海量的输出数据、频繁的通信以及高需求的存储空间使得高分辨率海洋模式发展成为了一个巨大的挑战.依赖于处理器性能的不断提升和超级计算机体系结构不断的演变与发展,尤其是多核处理器、集成众核处理器等形式的诞生,有越来越多的模式研究人员将模式调整后移植到超级计算机上,计算效率得到了空前的提升.
例如mpiPOM[22](the message passing interface version of the POM)在POM的基础上增加了MPI并行化,在逻辑上采用2维剖分,每个进程的划分模块包含4个方向的halo区,用于与周边进程进行数据交互.2014年Huang等人[23]将POM移植到GPU平台,利用4个K20 GPU进行数值模拟,性能能够媲美408个CPU.除了通过并行提高计算效率之外,针对模式中输出数据海量的特点,美国大气研究协会特地开发了NetCDF(network common data form)标准,以便对输出数据进行格式统一.而基于该标准之上的高效并行IO库PnetCDF(parallel NetCDF)能够提高超级计算机IO资源的利用率,缩短模式IO时间.
综上所述,在国产异构众核超算平台上设计发展高分辨率海洋模式具有深远意义,不仅意味着可以模拟中小尺度、更加细致性的物理海洋现象,而且也能保证模拟速度满足时间约束性极强的实时预报系统.
2 “神威·太湖之光”系统概述及POM性能分析
2.1 “神威·太湖之光”
“神威·太湖之光”超级计算机采用的处理器是我国自主研发设计的异构众核处理器——申威26010处理器.如图1所示,神威众核处理器采用片上融合的异构体系结构,每个芯片共有4个异构群和群间传输网络组成.每个异构群包括1个主核、64个从核簇以及存储器,其中主核的工作频率为1.5 GHz,L1 Cache为32 KB,L2 Cache为256 KB.与一般Intel处理器不同,由于神威众核处理器特殊的从核簇结构,CPU上不包含L3 Cache,从核的工作频率也为1.5 GHz,每个从核可用的独享存储空间(local device memory, LDM)为64 KB,每个从核对其独享的LDM存储空间具有较高的数据读取速度.主核和从核簇通过异构群接口与存储器相连,两者共享存储器存储空间.4个异构群和系统接口总线通过群间传输网络进行存储共享和通信.
相比于一般的处理器,神威众核处理器虽然舍弃了L3 Cache存储空间,但由于其从核的特殊性,若通过有效设计计算核心代码,使其能在从核间并行运行,能够达到比在一般处理器上更好的计算效果.理论上,申威26010处理器的双精度浮点数峰值性能为3.06TFLOPS,“神威·太湖之光”的理论双精度浮点峰值运算速度可达到100PFLOPS.
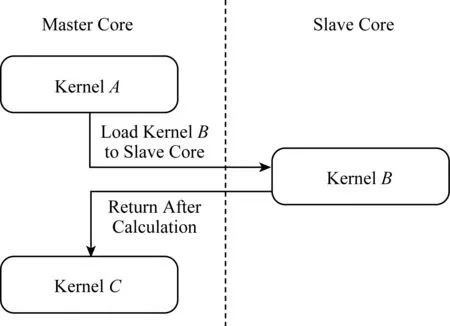
Fig. 2 Master-slave collaborative accelerationparallel mode图2 主从加速并行模式
根据申威处理器异构众核的特性,我们需要分析科学计算中不同计算核心的可并行性,尽量将能够加速并行的计算核心段加载到从核簇上并行运行,主核则完成不可以在从核上并行加速的计算段以及通信部分.如图2所示,在模式中包括A,B,C这3个计算核心,主核在完成计算核心A后,将计算核心B加载到众核上进行并行加速,在此期间主核进行等待,计算完毕后返回主核继续计算计算核心C,这种方式能够充分发挥众核的优势.比主从加速并行模式更理想的是主从异步并行模式,即主核和从核同时计算不同的工作,之后再进行数据同步等操作.但在真实科学计算中很难有如此之高的并行性,尤其是复杂的海洋模式,目前无法进行主从异步并行加速.
2.2 区域海洋模式POM
区域海洋模式POM是一种强大的海洋模型,已广泛应用于模拟河流、江口、湖泊、半封闭海域以及开放的全球海洋中水流的循环和混合过程.同时也是很多实时海洋、台风预报系统的核心模块,已经被运用于地中海预报系统[24]、GFDL(Geophysical Fluid Dynamics Laboratory)飓风预报系统[25-26]、美国飓风预报系统[27-28]以及台湾海洋预报系统[29]等.POM的主要特征是:在垂直方向使用sigma坐标,在水平方向使用Arakawa C[30]网格.为了有效地处理海洋的快速波动,采用模式分裂方法处理快速表面重力波和其他慢波,分别模拟正压(外模态)和斜压(内模态)模式并在一定时间步长后耦合在一起.整个模式的运行流程如图3所示.其中外模态循环迭代次数最多,需要计算的量也多,是POM中最为耗时的模块.
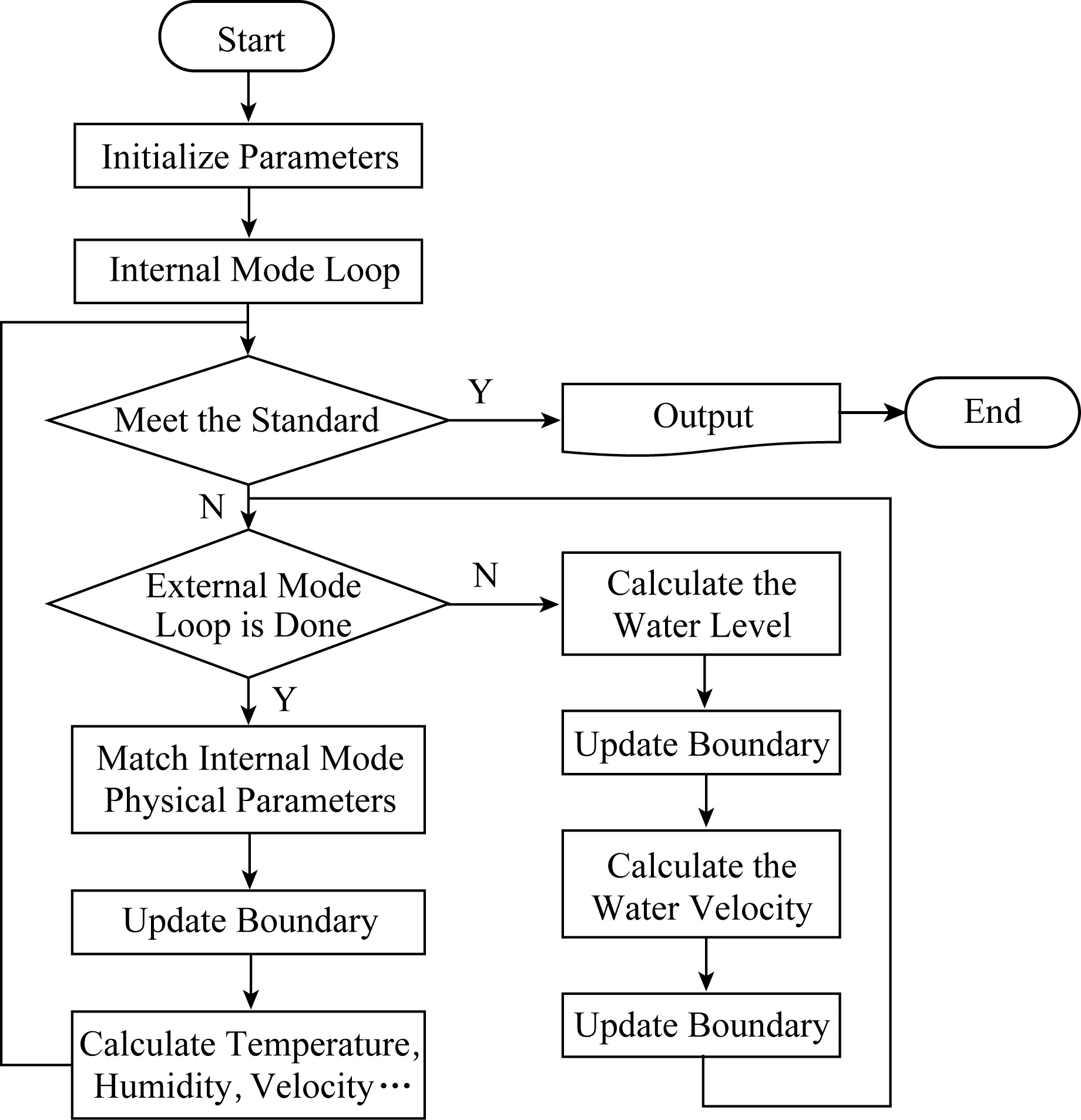
Fig. 3 The flowchart of POM图3 POM程序运行流程图
3 POM移植及性能分析
为了实现高分辨率区域海洋模式的高效模拟,我们首先将mpiPOM从通用x86平台下移植到国产异构众核超级计算机上.而模式的运行效率受模式分辨率、模拟的总时间、程序的并行程度、模式的初始状态等多方面因素影响.因此,设计1组基准实验版本对于后续的测试分析至关重要.我们规定后续的实验中,POM都以台湾海峡作为模拟场景,统一模式的全局分辨率为11 522×5 186,与“高分辨率海洋模式”契合,模式的迭代步长为10 s,一共迭代20步,最后进行1次数据输出.在此基础上,设计2组基准实验.
1) 性能测试.固定全局分辨率(11 522×5 186)、每个进程的局部分辨率(578×578),测试在180核规模下加速后不同版本的POM运行效率,运行时间越短表明并行加速效果越好.
2) 强扩展性测试.固定全局分辨率(11 522×5 186)、改变运行时投入的计算资源,测试POM在不同核数规模下的运行效率,从而反映出区域海洋模式的扩展性.一般情况下,程序运行时间会随着核数规模的扩大而逐渐减小,假如核数规模扩大了k倍,加速后模式的运行时间越接近于原始版本运行时间的1k倍,表明扩展性越好.
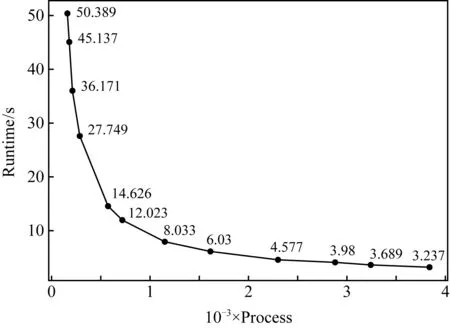
我们将移植后的程序视为基准版本,对其进行2组基准实验测试,对模式中的各个模块测试并进行性能分析.区域海洋模式POM移植前在通用Intel CPU的架构下进行性能测试实验大概需要55 s左右,程序移植到“神威·太湖之光”上采用纯主核运行基准实验1大概需要241 s左右.

Fig. 4 The runtime percentage of each module图4 POM各模块耗时百分比
在进行性能优化之前,我们先对移植后的POM进行性能分析.首先进行热点分析.在基准实验1下,我们分析POM中各个子模块耗时情况和特点,能够帮助我们定位性能瓶颈并针对各个模块的特点找到可行的加速方法.如图4所示,可以发现在180核的情况下,主要是动力计算模块耗时较多,占到了约93%的比例,而通信和其他模块所占比例只有不到7%.动力过程的计算elf,uaf,vaf,pro,vort等模块都是经典的stencil过程.可以看到,POM各模块耗时非常平均,基本没有主要的热点模块,必须针对这些模块的特性进行特定的性能优化.
在扩展性分析方面,我们分别测试基准实验2在160,180,216,288,576,720,1 152,1 620,2 304,2 880,3 240,3 840核数规模下POM的运行时间,如图5所示.可以发现在同一全局分辨率下,随着核数增加,即每个进程内局部分辨率减小,POM的原始版本运行耗时会逐渐缩小,在500核之前扩展性表现都不错.但在核数规模增大到一定规模后,由于进程间通信变得愈加频繁,进程初始化、回收等影响,程序运行耗时变化趋势越来越平缓.此外,在3 840核数规模下运行时间仅仅为8.91 s,比160核规模下提高了高达31倍的运行效率,由此可见扩大高分辨率海洋模式的核数规模能够满足众多实时预报系统对时间的约束性.
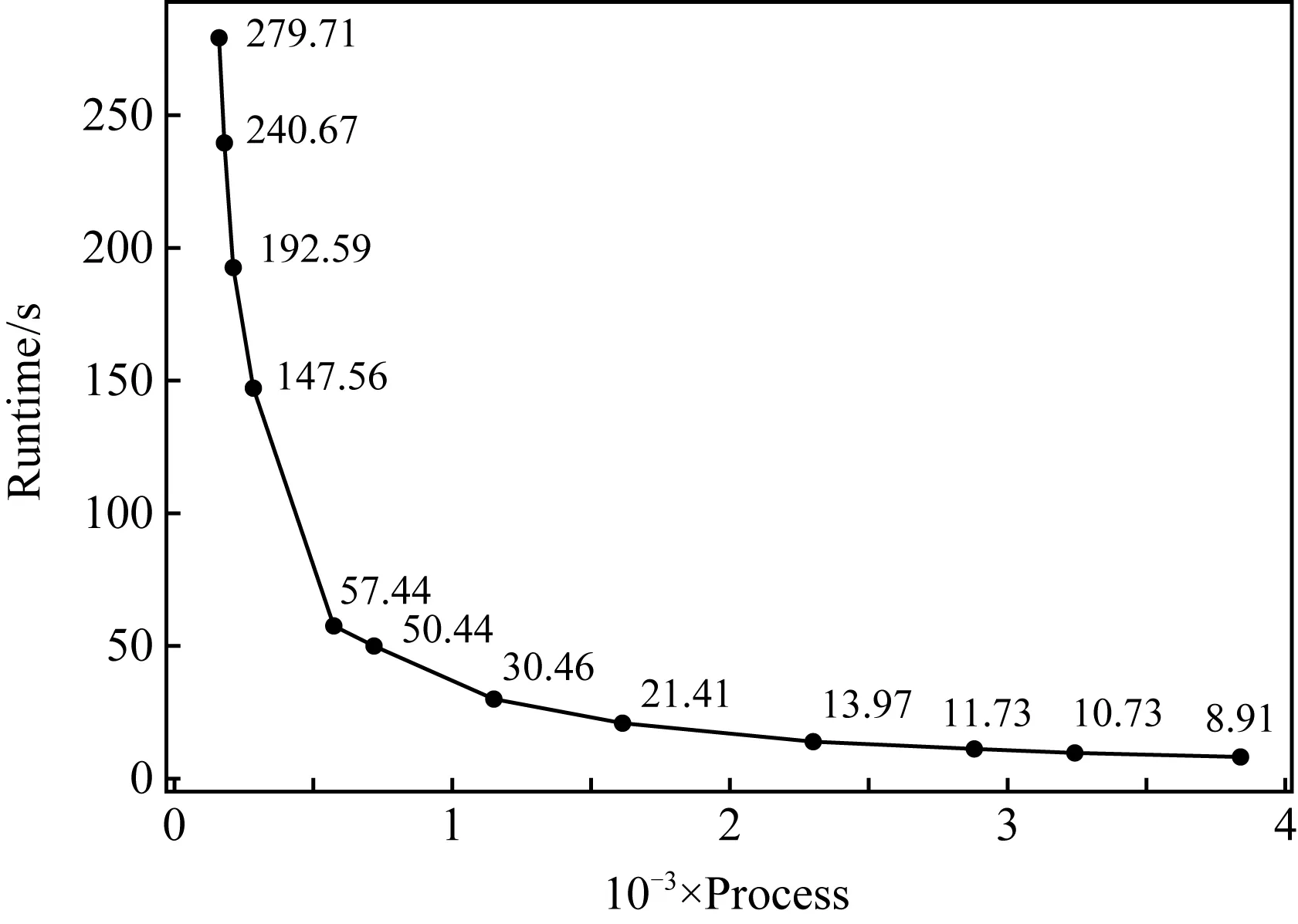
Fig. 5 The strong scalability of original POM图5 POM在纯主核上的强扩展性
图6展示了不同核数规模下通信在POM中的耗时占比的变化情况.在180核数规模下,通信耗时占比为1.1%,而随着核数规模的提升,通信模块耗时占比逐渐上升.在3 840大规模核数下,通信耗时比占到了24%.mpiPOM的通信目的是交换边界数据,假设当前进程内的网格大小为x×y,则需要进行通信的数据为该矩形网格的4个边界(最外围网格除外),即通信部分数据量大小为2x+2y,因此通信耗时占比公式可以简化为
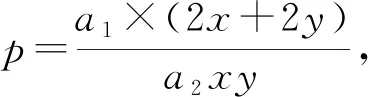
(1)
其中,a1,a2为相关系数,a1表示通信效率,a2表示计算效率.从式(1)能够发现,随着x和y(即局部分辨率)逐渐缩小,通信耗时比p会逐渐增大.式(1)仅仅只考虑了通信量,然而随着更多的计算资源投入其中,大量的MPI初始化、回收等也会成为制约因素.鉴于核数规模上升到一定程度后,通信部分会成为制约效率的关键因素,因此盲目增加计算资源、大肆扩大运行核数所带来的运行效果提升是非常有限的,有时甚至会适得其反.
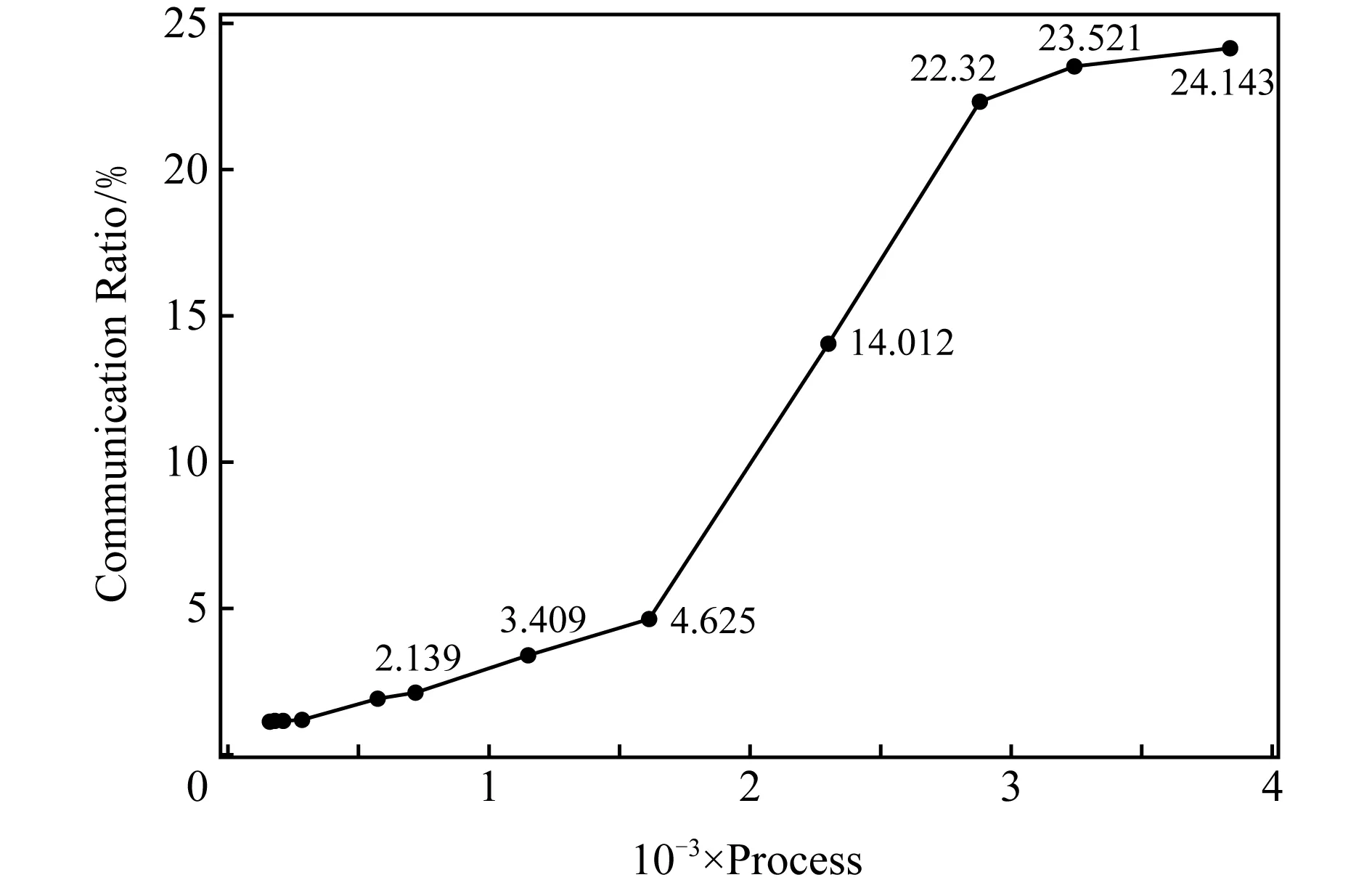
Fig. 6 The proportion of communication time of POM using different number of cores图6 不同核数规模下通信在POM中的耗时占比
4 面向异构众核处理器的并行优化方法
4.1 主从协同计算方案
POM将区域海洋划分为2维网格,每个网格之间具有天然并行性.而对于每一个网格内部,则可以规约为求解每个时刻每个点的速度、位置等变量,且这些变量只与上一步的迭代状态相关,只影响下一步的迭代状态.因此我们可以挖掘更细粒度的并行性,实现“基于MPI进程级并行+众核线程级并行”的两级并行方式.但由于从核中的LDM存储空间仅有64 KB,难以存放计算核心中需要的所有变量,因此我们采用在代码层面对耗时多的循环进行众核并行的方式.
对循环的众核级并行方案如下:最外层循环进行众核加速,由于每个从核簇有64个从核,因此在划分网格时最好能够将外层循环对应的维度设置为64的整数倍,以求最大程度得利用从核.内部循环的计算核心分为2个模块在从核运行:第1模块为所需要的数据访存通信,即从核向主核发起通信读入或写出计算所需数据;第2模块为计算部分,即计算核心在64个从核上并行的运行.众核级加速的伪代码如图7所示.

Fig. 7 The pseudo code of many-core parallelism图7 众核并行伪代码示意图
根据上述众核并行加速方案,假如一个任务在主核上运行的时间为T,则用主从加速并行方法的总时间为从核的计算时间加上从核与主核的通信时间.由于“神威·太湖之光”的主从核频率相当,通过num个从核并行计算,该任务的运行时间为Tnum.假设每次数据通信的开销为cost,一共要进行N次主从核间通信,故通信总时间为cost×N.由此可得众核加速比为
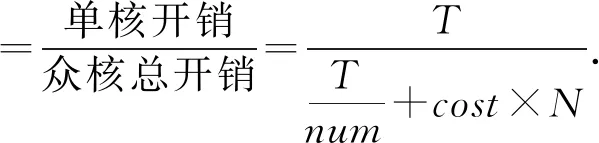
(2)
虽然从核的LDM存储空间仅有64 KB,但在网格剖分时每个网格的分辨率也不会太大,所以绝大部分计算核心都能够进行循环级并行.但模式中少数循环会有较为复杂的操作,导致变量无法全部读进LDM空间,因此还需要对内部循环进行分块处理.
4.2 从核访存优化方案
海洋模式在求解的离散偏微分方程中会使用大量的stencil操作,往往涉及到多个方向上的差分.以POM中计算elf过程为例:
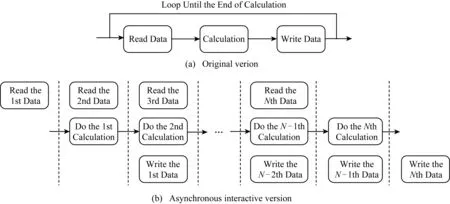
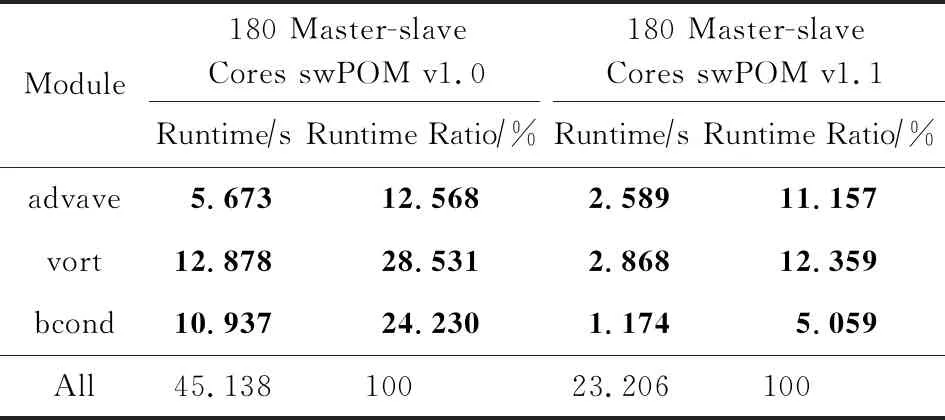
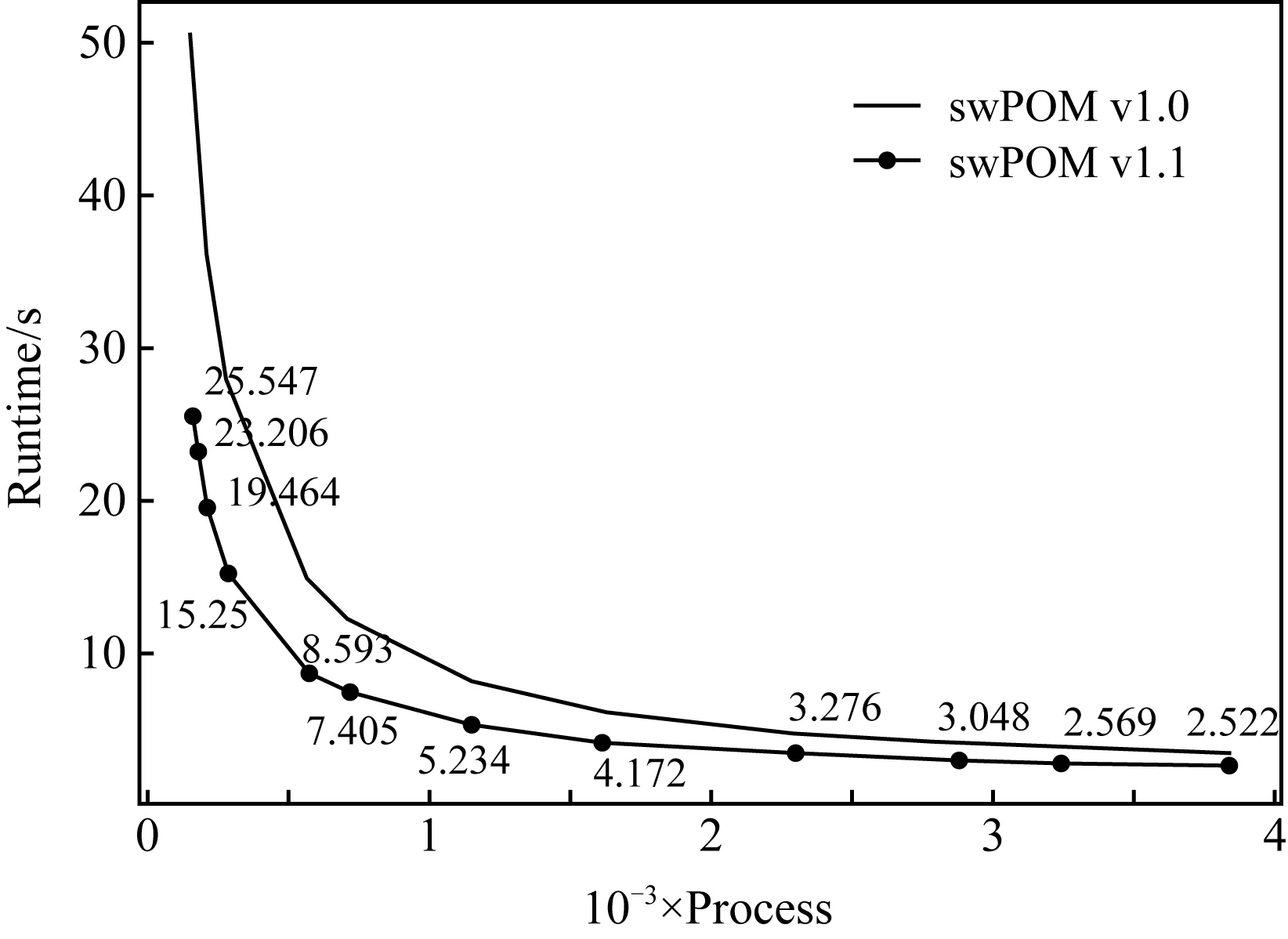
for(j=1;j for(i=1;i elf[j][i]=elb[j][i]+dte2×(-(fluxua[j][i+1]-fluxua[j][i]+fluxva[j+1][i]-fluxva[j][i]art[j][i]-vfluxf[j][i]); } } 在计算点(j,i)点上的物理量时,需要相邻点(j,i+1)和(j+1,i)的值,有些计算过程甚至需要更多相邻点参与计算.而计算机体系结构决定了多维数组在内存中只能有最低维的数据是相邻的,如果要连续访问高维数组便不可避免有大量离散访存的行为,对于cache的重用性极低. 在POM的advave,vort,bcond模块中,有大量跨步访问的方式.这也导致从核从主核读取数据时,需要大量的跨步访问.针对这种现象,我们采用图8所示的优化策略,对计算核心进行调整.首先在主存中将离散访问的数组调整为能够连续访存的数组,本质上就是开辟一块新的空间,调整高低维顺序,之后从核就能够在计算过程中连续访问数组内容.调整之后的访存效率远高于原先的方式,从而大幅度提高计算效率.最后在计算结束后回写数据时再次将数组调整为原始状态. Fig. 8 The diagram of memory access optimization图8 访存优化示意图 观察POM的程序,我们发现在计算uaf,pro,bcond模块的时候,对于从核LDM存储空间的利用率不高.因此我们引入双缓冲机制,让主从核间实现数据的异步交互,从而降低或隐藏从核通信开销. 在对涉及变量较少的计算模块进行主从核加速时,往往在从核的LDM存储空间上申请2倍于通信数据大小的存储空间,用来存放2份同样大小且互相为对方缓冲的数据.原先的循环方式如图9(a)所示,每次迭代的时候都先读入数据、进行计算,最后写回数据.而双缓冲的具体过程如图9(b)所示,除了第1次读入数据以及最后1次写回数据不与计算重叠,其他的数据通信都与计算过程相重叠.在进行当前次计算的同时,读入下一轮次的数据作为下一次迭代的基础,同时在该轮次写回上一轮次已经计算好的数据,通过该方式能够将计算核心和通信过程相互重叠,从而达到加速的效果. Fig. 9 Asynchronous interaction between master and slave cores图9 主从核异步交互示意图 假设每次读入、写回数据的通信开销为cost,n次读入、写回数据中一共有n-1次能够与计算模块重叠,因此能够与计算模块重叠的最大通信开销为cost×(n-1).其中第1次读入数据和最后1次写回数据无法与计算模块重叠,这部分通信开销总和为p.而原先的计算模块在纯主核下消耗的时间为T,通过num个从核的从核簇并行运行计算消耗的时间则为Tnum.因此众核加速比为众核加速比 (3) 与主从核协同交互方法相比较,主从核异步数据交互方法相当于在此基础上又将计算模块与访存通信模块相互隐藏,提高了计算效率.可以发现当计算模块与访存通信模块耗时越相近时,加速效果越好,最多能够达到接近于2倍的加速效果. 当并行规模扩展到一定规模,应用中通信占比也会随之增大,应用的热点也会逐渐从核心计算转移到通信,通信开销会成为整个海洋模式的性能瓶颈. POM中采用的是传统的阻塞型通信,即计算与通信模式是串行的,如图10所示: Fig. 10 The halo region update pattern图10 单进程halo区通信示意图 每一步迭代中每个进程先向其他进程发送边界数据,同时接受周围进程的边界数据;然后再进行核心计算,更新完数据进入下一轮迭代.可以将两者的串行逻辑解耦成计算与通信重叠的运算逻辑.主核在做边界通信的同时,众核没有必要等待其通信结束后再进行计算,而是去进行内部格点的核心计算,从而达到计算与通信相互隐藏.计算与通信重叠的具体方法为: 1) 每个进程首先采用异步方式(非阻塞通信)向周边进程发送其需要的数据; 2) 每个进程发起异步接受req请求,从周边进程接收本进程需要的数据; 3) 每个进程通过从核并行计算内部inner区域并更新内部数据; 4) 检查每个进程req请求是否完成,通过完成后得到的边界数据进行边界的计算并更新边界数据. 通过计算与通信重叠的方式,能够有效地将通信消耗隐藏于计算中,尤其是当核数规模上升后,通信耗时占比增大的情况下,该方法能够取得不错的效果. Fig. 11 Original I/O mode vs CFIO I/O mode图11 原始模式I/O与使用CFIO进行I/O方式对比 使用CFIO的swPOM运行方式与原有方式略微不同.方式1是原有运行模式,先进行数值计算;然后所有进程进行IO,并等待IO完成再进行下一步的数值计算,依次循环.而CFIO中,计算进程会把IO请求转发给IO进程,待请求转发之后便进行下一步的数值计算,从而实现IO与计算的相互重叠. 在POM的不同模块中使用主从协同计算方案,经过加速后的swPOM v1.0版本与Original POM版本在基准实验1的性能对比,如表1所示.除了边界bcond模块与通信comm模块,其他模块均取得了显著的加速比,在180核下swPOM v1.0只需要运行45 s,取得了5.3倍的加速比. Table 1Performance Comparison Between swPOM v1.0 and Original POM 表1 swPOM v1.0与Original POM性能对比 Module180 Master CoresOriginal POM180 Master-slaveCores swPOM v1.0Runtime∕sRuntime Ratio∕%Runtime∕sRuntime Ratio∕%elf18.1467.5401.4323.172uaf36.13215.0131.7863.957vaf34.75714.4422.1674.800pro24.07210.0021.8904.188egf15.3356.3721.0132.244advave36.16115.0255.67312.568vort58.63924.36512.87828.531bcond10.5824.39710.93724.230comm2.7321.1351.2292.723others4.1131.7096.13313.587All240.66910045.138100 Note: The bold cells in the table represent the modules accelerated by the master-slave collaboration. 为了进一步验证swPOM v1.0在各个并行规模下的运行效率,我们也对其进行了强扩展性测试,结果如图12所示.与Original POM相比,在不同的核数规模下均取得了2倍及以上的加速效果. Fig. 12 The strong scalability of swPOM v1.0图12 swPOM v1.0在纯主核上的强扩展性 通过分析POM每个模块的代码,我们发现advave,vort,bcond这3个模块中有大量的离散访问形式.表2中展示了对这3个模块进行访存优化的数据,分别达到了2.2倍、4.5倍以及9.3倍的加速比.而swPOM v1.1版本整体运行效率也比swPOM v1.0加速了2倍左右,该版本相较于通用Intel平台下55 s的运行效率也达到了2倍多的加速比,这为实时预报系统提供了有效的保障.图13展示了swPOM v1.1相比v1.0版本的扩展性,由于v1.1版本中引入了调整数组的过程,3 840核相比160核下的加速比有所下降,但绝对运行时间相比v1.0版有所提升. Table 2The Performance Comparison Between swPOM v1.1 and swPOM v1.0 表2 swPOM v1.1与swPOM v1.0性能对比 Module180 Master-slaveCores swPOM v1.0180 Master-slaveCores swPOM v1.1Runtime∕sRuntime Ratio∕%Runtime∕sRuntime Ratio∕%advave5.67312.5682.58911.157vort12.87828.5312.86812.359bcond10.93724.2301.1745.059All45.13810023.206100 Note: The bold cells in the table represent the modules accelerated by thememory access optimization. Fig. 13 The strong scalability comparison betweenswPOM v1.1 and swPOM v1.0图13 swPOM v1.1与 v1.0在纯主核上的强扩展性对比 主从异步数据交互方案的条件比较苛刻,因此我们只在180核的基准测试实验下对uaf,pro,bcond模块采用了上述优化,运行效率分别提升了20%,95%和30%.其中pro模块95%的效率提升意味着该模块中计算与从核访存通信已经基本完全重叠,相互隐藏. 使用计算与通信重叠的优化方法后,在180核规模下有43%的通信模块与计算重叠,隐藏于计算过程中.而swPOM中还有些通信是一对多的求和收集、广播通知等,无法与计算模块重叠,因此通信模块达到1.8倍加速比已经比较理想. Table 3 The Comparison Between Original IO and CFIO表3 正常IO与CFIO对比 Table 3 The Comparison Between Original IO and CFIO表3 正常IO与CFIO对比 Module180 Processes (I∕O)180 Processes (CFIO)Runtime∕sRuntime Ratio∕%Runtime∕sRuntime Ratio∕%Without I∕O433.28273.537I∕O155.92126.463All589.203100497.216100 CESS是清华大学运行维护的一款通用x86计算平台,由80台服务器组成;每台服务器包含有2个Intel处理器,其中每个处理器的主频为2.1 GHz,具有32 K L1 Cache,256 K L2 Cache,15369K L3 Cache.相比于“神威·太湖之光”,CESS具有更高的主核频率,且具有L3 Cache.我们将最终版本swPOM与运行在CESS上的Original POM进行性能对比,结果如表4所示: Table 4 The Performance Comparison Between swPOM andOriginal POM(on CESS)表4 swPOM与Original POM(CESS)性能对比 可以发现,因为CESS的主核频率高且有L3 Cache,Original POM运行基准实验1只需要55 s.而“神威·太湖之光”的主核频率低,且没有L3 Cache,故Original POM在纯主核下运行基准实验1需要241 s.但经过上述一系列并行优化后,swPOM在众核并行下将运行基准实验1的时间缩短到了19 s内,运行效率达到了纯主核的13倍,CESS通用Intel平台下的2.8倍以上,将模拟时间整整缩短到原先的一半以下.这对于一些实时预报系统是强有力的保障,为构建高分辨率海洋模式奠定了坚实的基础. 近年来发展高分辨率海洋模式已经成为必然趋势,本文基于国产超级计算机“神威·太湖之光”,利用其异构众核体系结构的优势对区域海洋模式POM进行移植并优化,充分发挥了国产异构众核平台的特点和优势.不同于一些简单的科学计算,只有唯一的热点函数,POM的热点模块很多而且耗时占比非常平均.swPOM基于POM各个模块的特点,对其计算核心进行主从协同加速、数据访问优化、从核数据访问与计算重叠和计算通信异步屏蔽等,将整体的模拟效率提升到传统超算平台的2.8倍以上,同时能够扩展到25万核的规模.此外,swPOM还集成了高效的异步IO库CFIO,通过将资源合理分配成计算与IO进程,采用请求转发的方式将IO过程与科学计算过程相互重叠.在相同资源下,与180核同时进行计算与IO的形式相比,整体性能提升了约20%. 在未来的研究工作中,经过一系列优化之后原先占比很小的非热点模块成为了swPOM的主要热点,这些模块后续还有继续优化的空间.此外我们在使用CFIO的时候,通过对比实验选择了一个合适的计算与IO的进程比,而不同的分配比往往会影响程序的性能,这一方面也有待进一步研究.
4.3 主从核异步数据交互方案
5 面向“神威·太湖之光”大规模并行优化方法
5.1 并行通信优化方案

5.2 并行IO优化方案

6 实验结果及分析
6.1 面向异构众核处理器的并行优化方法结果分析

6.2 面向“神威·太湖之光”大规模并行优化方法的结果分析

6.3 与通用平台性能对比分析

7 结束语
