基于IndRNN-Attention的用户意图分类
2019-07-15张志昌张珍文张治满
张志昌 张珍文 张治满
(西北师范大学计算机科学与工程学院 兰州 730070)
人机对话作为智能场景中的关键技术,近年来引起了学术界和产业界的广泛关注,相关方法已经在不少产品(如苹果Siri[注]https://en.wikipedia.org/wiki/Siri、Google Now[注]https://en.wikipedia.org/wiki/Google_Now、微软Cortana[注]https://en.wikipedia.org/wiki/Cortana和阿里小蜜[注]http://alixiaomi.com等)中得到了广泛应用.人机对话系统运行时,首要的任务就是在用户输入消息(文本或者语音)后,准确理解用户对话意图[1],例如判断用户是想和系统闲聊,还是希望系统完成特定的任务(如预定机票、订外卖、查询天气等);然后再根据用户意图做出正确的回应,让对话顺利进行.精准的用户意图理解能有效提高人机交互的自然度[2-3],提升用户体验.因此,用户意图分类在人机对话系统研究中具有重要的研究意义.表1为常见用户意图举例:

Table 1 Examples of User Intent表1 用户意图举例
针对人机对话中的用户意图分类问题目前已有不少研究,但依然存在很多需要深入解决的问题,如万能回复、回复相关性差及对聊天文本语义理解不够深入,无法从较短的用户聊天文本中理解用户意图等问题.如当用户输入“我的ThinkPad已经用了5年了”时,可能是称赞这个笔记本电脑性能很好,也可能是表达想换新笔记本电脑的一种意愿.在这种情况下,对话系统很难准确判断用户的真实意图到底是哪一种.现有的用户意图分类方法存在对聊天文本语义理解不够深入、难以有效表达用户聊天文本的真实语义信息等问题.
针对上述问题,本文提出了基于独立循环神经网络(independently recurrent neural network, IndRNN)和词级别注意力机制(word-level attention mechanism)的用户意图分类方法.通过多层IndRNN[4]网络作为编码器对用户聊天文本编码,有效改善了传统循环神经网络(recurrent neural network, RNN)结构在序列任务处理中出现的“梯度消失”和“梯度爆炸”等问题,而词级别注意力机制[5]则显著地增强了领域词汇对意图分类的突出贡献.通过在第六届全国社会媒体处理大会中文人机对话技术评测[6](SMP2017-ECDT)用户意图领域分类语料上实验发现,本文提出的方法相比其他已有的几种分类方法,取得了更好的分类效果.
1 相关工作
对用户意图分类方面已有的研究方法进行总结,可以划分为3类:
1) 基于规则的方法.这种方法主要是根据知识工程师或领域专家的经验和知识归纳总结出相关分类规则,然后构建相应的规则模板作为分类器分类.Yang等人[7]提出了人们日常生活中经常出现的12 种普遍需求,通过模板匹配方法获得了购买产品的用户,然后基于Twitter 中的Unigram特征、WordNet 中词的语义特征和表达需求的动词特征来训练分类器完成对用户消费意图的识别.Fu等人[8]采用基于模板的匹配方法来检测用户微博消费意图.基于规则的方法优点是分类准确率较高.缺点是:①规则之间的关系不透明,缺乏分层的知识表达;②不具备从经验中学习的能力,维护困难;③覆盖率低,规则制定需要专业人员参与,耗时耗力,可扩展性较差,很难在多领域推广使用.
2) 基于传统机器学习的方法.传统机器学习方法基于特征工程[9],常用的方法有朴素贝叶斯(Naive Bayes, NB)、支持向量机(support vector machine, SVM)、最大熵等.用户意图分类任务需要获取用户输入文本的语言特征,如词法、句法等.大量相关研究证明模型所学习的语言学特征对于自然语言处理能够提供十分重要的价值[10].Pang等人[11]提出使用N-gram特征可以有效地识别影评的极性,其中,Unigram特征的效果最佳;Wang等人[12]利用词语Bigram特征训练NB和SVM模型,在句子或文本主题分类问题中取得一致较好的效果;Huang等人[13]在用户消费模式识别中提出了基于SVM的识别方法.基于传统机器学习的分类方法,其优点是不需要手动编写规则模板,能有效解决基于规则的方法中所存在的问题.缺点是:①提取特征耗时,其消耗往往随着数据集规模的变大而增长,容易出现维度灾难;②不容易构造有效的分类特征,且大部分的特征基于字或词,难以表达句子较深层的语义信息.
3) 基于深度学习的方法.深度学习的出现极大降低了获取文本特征的难度.Kim[14]首次将卷积神经网络(CNN)应用到句子分类任务中,并提出了几种变形;Gao等人[15]在句子分类任务中提出基于稀疏自学习卷积神经网络对句子编码,实现句子分类;Xu等人[16]提出利用神经网络的方法评估书法练习者书法临摹的质量;Bhardwaj等人[17]在搜索引擎查询意图识别任务中提出利用卷积神经网络获取查询文本的向量表示作为查询分类的特征;Bhardwaj等人[18]提出利用记忆网络对用户交互信息编码以实现应用推荐任务中的意图分类;Kim等人[19]在口语对话理解中提出利用Bi-LSTM方法对用户交互文本编码实现领域和意图分类.端到端的深度学习方法使用词向量表示,可不依赖于特定语言的句法关系,减少了人工设计和构造分类特征的负担,还可以抓取到视觉上无法获取的特征,从而提高了分类的精度.
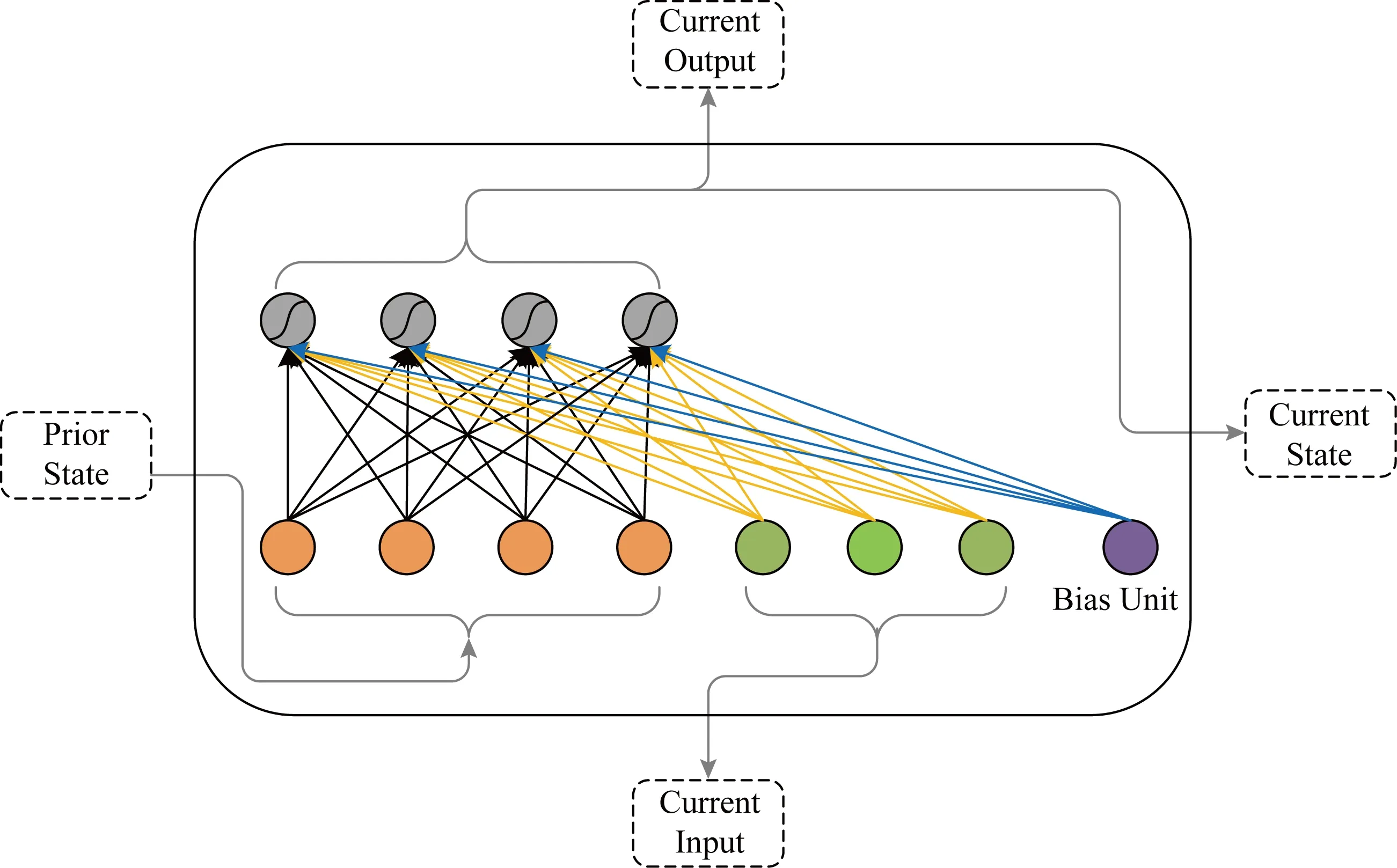
Fig. 2 Basic RNN unit structure图2 基本RNN单元结构
2 基于IndRNN-Attention的用户意图分类方法
本文提出的基于IndRNN-Attention的用户意图分类方法模型结构如图1所示,由输入层、编码层、注意力层和分类层组成.
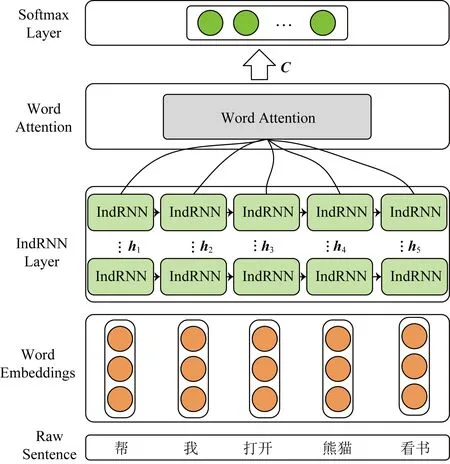
Fig. 1 Architecture of IndRNN-Attention图1 IndRNN-Attention结构
2.1 输入层
模型的输入是用户输入的一个句子对应的词向量矩阵,词向量由预先训练好的word2vec模型得到.对于数据集中的任意一个句子,将其分词后参照数据集中句子的最大长度进行填充,并将句子中的每个词转换成对应的词向量表示,便可得到该句子的词向量矩阵.
2.2 IndRNN层
RNN被广泛地应用在动作识别、场景标注和自然语言处理等领域.基本的RNN单元结构如图2所示.
在RNN中每个神经元接收当前时刻的输入和上一时刻的输出作为输入,时刻t的状态更新为
ht=σ(Wxt+Uht-1+b),
(1)
其中xt∈RM和ht-1∈RN分别是时刻t的输入和时刻t-1的隐藏状态,W∈RN×M和U∈RN×N分别是神经元当前时刻的输入和循环输入的权重矩阵,b∈RN是偏置项,σ是神经元激活函数,N是每个RNN层神经元数量,M是输入层的大小.
RNN在训练过程中容易出现“梯度消失”和 “梯度爆炸”问题,这使得RNN学习长期依赖关系的能力比较差.为解决这些问题,研究人员提出了长短时记忆网络[20](long short-term memory, LSTM)和门控循环单元[21](gated recurrent unit, GRU).虽然这2种网络结构在一定程度上改善了这些梯度问题,但是由于LSTM和GRU使用tanh函数和sigmoid函数作为激活函数,会导致层与层之间的梯度衰减,因此要构建和训练一个深层的循环神经网络实际上较困难.
通过使用IndRNN可以有效地解决上述问题.IndRNN单元结构如图3所示.
IndRNN状态更新如式(2)所示:
ht=σ(Wxt+U⊙ht-1+b),
(2)
其中,xt∈RM和ht-1∈RN分别是时刻t的输入和时刻t-1的隐藏状态,其中W∈RN×M表示输入层到隐层的权重,U∈RN表示上一时刻隐层到当前隐层的权重,⊙表示哈达马积(hadamard product).IndRNN中每一层的每个神经元之间都是独立的,神经元之间的连接可以通过堆叠2层或者多层IndRNN单元实现.对于第n个神经元,时刻t的隐藏状态可通过计算得到:
hn,t=σ(wnxt+unhn,t-1+bn),
(3)
其中,wn和un分别表示第n行神经元的输入权重和隐层权重.

Fig. 3 IndRNN unit structure图3 IndRNN单元结构
在IndRNN中,每个神经元只接收来自当前时刻的输入和它本身在上一时刻的隐藏状态信息,每个神经元独立处理一种类型的时空模式.传统的RNN通常被视为通过时间共享参数的多层感知机,而 IndRNN则展现了一种随着时间步的延伸(通过u)独立地聚集空间模式(通过w)的新视角.通过堆叠2层或多层神经元,下一层中的每个神经元独立地处理前一层中所有神经元的输出,降低了构建深度网络结构的难度,增强了对更长序列的建模能力.同时,借助ReLU等非饱和激活函数,训练之后的 IndRNN 鲁棒性更高.
2.3 注意力机制层
获取文本语义表示常用的方法是取编码器最后时刻的隐藏状态输出向量作为最终的编码向量,优点是一定程度上可以有效地涵盖文本语义信息,缺点是这种办法很难将输入文本的所有信息编码在一个固定长度的向量中.如果直接将每个时刻的输出向量相加或者平均,那么可以认为每个输入的字或词对计算输入文本的语义表示结果的贡献是相等的,这种方法降低了那些对表达文本含义有重要作用的字或词的贡献度.
利用智能移动终端帮用户完成订机票、导航、订酒店等是常会发生的情景.例如用户输入“上海回合肥怎么坐汽车?”,用户意图是查询路线,属于“bus”类,在分类过程中“汽车”这个词对正确分类贡献最大,所占的权重也应该最高.因此,我们引入词级别注意力机制来提取对句子含义重要的词的信息.
给定一个序列S=(w1,w2,…,wT),T表示序列长度.序列S中的第i个词在时刻t的隐藏状态hit可由式(3)计算得到,词级别注意力机制可以通过3个步骤实现:
1) 使用多层感知机获得hit的隐藏表示uit:
uit=tanh(Wwhit+bw);
(4)
2) 计算uit和词级别上下文uw的相似性将其作为单词的重要性度量,通过softmax函数计算归一化权重αit:
(5)
单词上下文向量uw是在训练过程中随机初始化和共同学习的.
3) 计算句子向量C:
(6)
2.4 分类层
将句子编码结果C输入到一个全连接层并使用全连接层的输出作为句子最终的特征向量,将其输入softmax层即可输出各类别的概率.计算方法为
(7)

3 实验与分析
3.1 数据集
本文实验数据集来源于SMP2017-ECDT,该数据集覆盖闲聊和垂直类2大类,其中垂直类细分为30个垂直领域,数据集统计结果如图4所示:
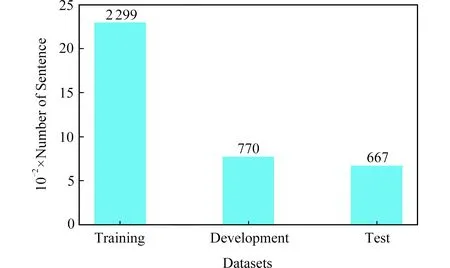
Fig. 4 Size of SMP2017-ECDT dataset图4 SMP2017-ECDT数据集规模
3.2 评价指标
本文用户意图分类是一个多分类问题,我们使用精确率(precision,P)、召回率(recall,R)和F值作为每个类别的评价指标,使用宏平均值(macro-average)作为每种分类方法最终的评价指标,计算方法为
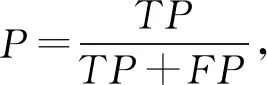
(8)
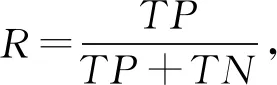
(9)
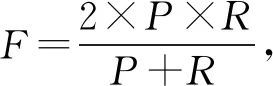
(10)
(11)
(12)
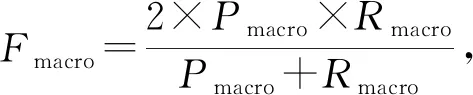
(13)
其中,TP表示将正类预测为正类数,TN表示将负类预测为负类数,FP表示将负类预测为正类数,FN表示将正类预测为负类数,n是类别总数.
3.3 实验设置
在数据预处理过程中,我们使用结巴分词工具对用户聊天文本分词,并去除了原始文本中包含的标点符号和特殊字符等.
在基于CNN的分类实验中,设置卷积核大小为3,4,5的过滤器各100个;在基于LSTM的分类实验中,采用了2层LSTM网络结构;在基于IndRNN和IndRNN-Attention的分类实验中,attention_size=128.上述4种实验中隐藏层大小均设置为128,词向量的维度设置为300,batch_size=64,Padding的最大长度参考训练语料中最大文本长度设置为26,在倒数第2层与最后1层的softmax层之间设置dropout_rate=0.5,在softmax层中使用了值为1的l2正则化项.
3.4 结果与分析
3.4.1 实验结果
5种分类方法在测试语料上的整体分类性能见表2,各个子类别上的F值如表3所示:
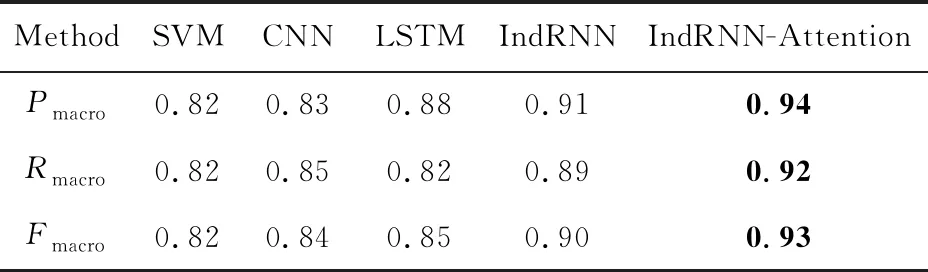
Table 2 Comparison of Overall Classification Result of Different Models表2 各种方法对比实验结果
Notes: The bold values are the best results obtained by our method.

Table 3 F Score Comparison of Different Models onIndividual Category表3 不同方法在每个类别的F值比较
3.4.2 实验分析
从表2中可以看出:相比其他4种方法(SVM,CNN,LSTM和IndRNN),本文基于IndRNN-Attention的方法取得了最好的分类效果,在Pmacro,Rmacro,Fmacro这3个指标上有显著的提高.通过对不同方法与本文方法在31个类别上的F值进行统计t检验发现,本文方法在所有类别上显著地(p<0.01)超过了SVM,CNN和LSTM这3种方法,而与IndRNN方法在统计上没有显著差异(p=0.067),但在19个类别上,本文方法相对于IndRNN方法有一定提高.
从表2中可以看出,基于SVM的分类方法分类结果最差.可能的原因有2点:
1) 传统机器学习方法基于特征工程,以词或者句法结构作为分类特征,难以考虑句子中词之间的时序关系,也很难将句子表达的语义信息通过固定的分类特征来进行体现.如“上海到北京的火车”和“刚下火车,到上海了”,2句表达在用词和结构上基本相似,但是表达的意图不同,使用传统的机器学习方法很难将其进行准确分类.
2) 验证集和测试集中的部分句子(验证集23条、测试集24条)分词后的结果不在通过训练集构造的词典中,导致这些句子的特征表示结果是一个全零向量,影响了模型的训练和测试.
在基于CNN的分类实验中,本文采用Kim[14]提出CNN分类结构.CNN可以抽取句子中丰富的局部特征,提高文本表示质量,但是CNN对句子整体的语义结构和上下文时序信息表达不够,对句子的语义表达不全面,因此分类结果较基于SVM的方法在性能上有所提高,但比其他3种方法(LSTM,IndRNN和IndRNN-Attention)要低.
利用LSTM网络,不仅考虑到了用户聊天文本的上下文时序关系对语义的影响,还可以在一定长度范围内有效处理长期依赖问题.本文采用双层LSTM网络结构对用户聊天文本进行编码,取隐层最后的输出作为句子的编码表示并通过softmax层得到分类结果.
实验结果表明:基于LSTM的分类方法比基于SVM和CNN的分类方法性能有所提高,但存在一定的问题.LSTM网络需要依赖原始的词向量输入,无法从聊天文本中挖掘句子表达的深层隐含信息,同时存在“梯度消失”和“梯度爆炸”等问题.对比表3发现,基于LSTM的分类方法在部分类别上的性能提高不明显,反而有所下降,如“calc”,“website”等类别.通过分析实验结果,我们发现基于LSTM的分类方法将“你知不知道三十四加六十五等于多少”和“帮我算一算45的平方根”等表达错分到“chat”类别中,而它们的真实标签是“calc”.
针对这些已有分类方法中出现的问题,本文提出了多层独立循环神经网络和词级别注意力机制融合的用户意图分类方法(即IndRNN-Attention),通过堆叠多层IndRNN网络,构建了一个更深更长的网络结构对用户聊天文本编码,有效地解决了语义信息获取不足、梯度消失和梯度爆炸等问题;词级别注意力机制的使用显著地提高了对聊天文本的编码质量,增加了对文本含义表达有重要贡献的相关词汇的贡献度,提高了分类性能.图5是attention权重的可视化示例.
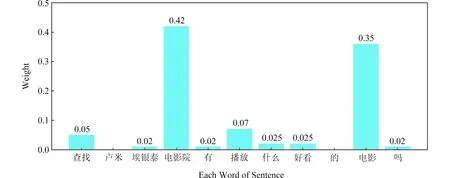
Fig. 5 Attention based weighting sample for a sentence from SMP2017-ECDT dataset图5 SMP2017-ECDT数据集中一条用户输入的注意力权重示例
3.4.3 分类错误原因分析
表4是本文提出方法在测试集上分类错误的代表性示例:

Table 4 Classification Error Samples表4 分类错误示例
分类错误的原因可归纳为3个方面:
1) 部分类别之间的领域相似度高,用户输入的上下文信息严重不足.通过对比实验数据集发现,“website”和“app”,“video”和“cinemas”等类别之间的领域差异较小.对于用户输入“搜索米聊”,其中的上下文信息较少,用户的确切意图难以区分,表达的意思有可能是想查找手机中安装的“米聊”软件,也有可能是想在浏览器中搜索“米聊”软件的信息.在这种情况下,仅根据已有的文本信息无法做出正确的分类,需要结合额外的场景信息或上下文信息来做出判断.
2) 训练数据类别分布不平衡.训练集整体的规模较小,但类别偏多,训练集在各类别上的数据分布严重不平衡,如“chat”,“cookbook”,“video”等类别的训练数据有几百条,而“bus”,“calc”,“datetime”等类别仅包含十几条.在这种情况下,对某些类别或者领域来说,给定的训练数据远远无法覆盖领域所包含的大量专业术语,如“health”类中的术语“鼻息肉”在该类别的训练数据集中不存在,从而在测试时模型将“鼻息肉”错分到“cookbook”类别.
3) 数据集中存在噪声数据.数据集中存在部分如“瓷我要上QQ”、“天最新新闻”和“你是不是”等表达错误或表达不规范的句子,这样的句子影响模型的训练效果,也影响测试性能.
4 结 论
本文提出了一种基于独立循环神经网络和注意力机制的用户意图分类方法,通过构造一个多层独立循环神经网络模型和融合词级别注意力机制的网络结构实现对用户聊天文本的编码,解决了传统循环神经网络中出现的“梯度消失”和“梯度爆炸”等问题,提高了领域相关词汇对用户聊天文本编码的贡献度,增强了句子表示能力.在SMP2017-ECDT评测数据上的实验表明,本文方法取得了最好的分类效果,Fmacro值达到0.93,与本文实验中其他4种方法相比显著提高了用户意图分类的效果.
在后续工作中,我们将尝试在神经网络结构中引入各类外部语义知识库来进一步提高用户意图分类的性能.
