汉语否定与不确定覆盖域检测
2019-07-15邹博伟洪宇沈龙骧朱巧明周国栋
叶 静 邹博伟 洪宇 沈龙骧 朱巧明 周国栋
(苏州大学计算机科学与技术学院 江苏苏州 215006)
自然语言文本存在大量否定与不确定语义表述,将其与事实性信息分离处理,能够为自然语言处理的下游应用(如知识库构建、信息抽取、情感分析等)提供准确性保证.本文旨在研究识别出句子中包含否定或不确定语义的文本片段.其中,否定语义指对某一命题或断言的存在或发生进行反转[1];不确定语义指事物的类属边界或性质状态不明确,人们对事物属性处于一种模糊认识状态[2].
通常地,否定与不确定表述由一个关键词或短语及其在句子中支配的语义作用范围(覆盖域)组成.例句[注]以加粗字体表示关键词,以方括号表示关键词对应的覆盖域.:
例1.我建议大家和提醒其他人[不要到这家酒店]!
例2.[唯一觉得还可以的是中餐厅],用餐也不贵.
其中,例1中否定关键词“不要”的语义作用范围是“不要到这家酒店”,而前半句内容并未受否定关键词的影响;同样,例2中表示不确定语义的关键词为“觉得”,其对应的语义作用范围是“唯一觉得还可以的是中餐厅的菜”,句子中其余部分未包含不确定语义.
覆盖域检测(scope detection)是否定与不确定性信息抽取研究中的核心任务,对给定的否定或不确定关键词,识别其在句子中管辖的文本片段.覆盖域检测研究最早集中于生物信息抽取领域,自动抽取科技文献或病程记录中被否定或推测的实体或文本[3-5].近年来,该任务逐渐开始作为基础的自然语言理解任务,受到广泛关注[3-5].
由于语料资源相对缺乏,面向汉语的否定与不确定检测研究仍处于探索阶段,现有方法大都基于规则或传统的特征工程方法[1-2,4,6-9].例如Zou等人[4]提出了一种基于树核的否定与不确定覆盖域检测方法,其中抽取了包括词性、成分句法与依存句法等21种特征模板.这些方法需要领域专家进行特征模板的设计,费时费力,且可扩展性较差.相比传统方法,神经网络模型能够从原始数据中自主学习,获取更深层次、更抽象的潜在特征,其优势已在自然语言处理领域的其他任务,如机器翻译[10-11]、情感分析[12-13]、信息抽取[14-15]等中,得到了验证.
本文首次采用神经网络模型解决面向汉语的否定与不确定覆盖域检测问题,将其作为序列标注任务,采用双向长短期记忆网络(bidirectional long short-term memory, BiLSTM)[16-17]和条件随机场(conditional random fields, CRF)[18]进行建模.首先,将句子中每个词通过预训练的词向量进行向量化,并将每个词的相关特征(位置、词性、句法特征、依存特征)进行向量化,然后进行组合作为BiLSTM网络的输入,通过BiLSTM学习上下文信息,并通过CRF层学习相邻标签之间的依赖关系,最终解码出最优的标签序列.
在CNeSp语料库[8]上的实验结果表明:本文基于BiLSTM-CRF模型的覆盖域检测方法性能分别达到79.16%(否定)和76.79%(不确定),比目前基于传统机器学习的系统分别提升了25.06%和34.46%.
本文的主要贡献可归纳为3个方面:
1) 将覆盖域识别任务作为序列标注问题,提出了一种面向汉语覆盖域检测任务的基于双向长短期记忆网络(BiLSTM)与条件随机场(CRF)融合模型,该模型能够有效地学习和优化上远距离下文中的依赖关系;
2) 探索了词性、相对位置、成分句法标记、依存句法路径等特征在基于神经网络模型中,对覆盖域检测任务的影响;
3) 较大程度地提升了汉语覆盖域检测系统性能,为相关研究提供了基准系统.
1 相关研究
本节主要介绍否定与不确定覆盖域检测任务的研究进展,以及BiLSTM-CRF模型在自然语言处理领域中的相关应用.
1.1 否定与不确定覆盖域检测
覆盖域检测研究最早出现于面向生物信息文本的自然语言处理领域.早期的覆盖域检测方法通常基于启发式规则.例如Chapman等人[19]发布了基于正则表达式算法的NegEx系统;Huang等人[20]在句法树结构上,利用启发式规则判定句法树结构是否处于某个否定关键词的作用范围之内.基于规则的方法实现简单且准确率较高,但其可扩展性较差;随着BioScope语料库的发布[6],基于特征工程的方法逐渐成为主流,例如Morante等人[21]首次采用机器学习方法对否定关键词的覆盖域进行检测,此后,其又融合浅层句法特征与依存句法特征,获得了CoNLL’2010-Task2 评测的最优性能.
由于缺少语料资源,面向汉语的否定与不确定覆盖域检测研究起步较晚.Zou等人[8]标注了汉语否定与不确定语料库(CNeSp),该语料库共16 841句,其中包含科技文献、金融新闻、酒店评论3种不同领域的数据集.同时提出了一个基于特征工程的基准系统,该系统的性能达到54.10%(否定)和42.33%(不确定).本文提出的模型在该语料库上进行验证与比较.
以上基于特征工程的方法不仅依赖大量的领域知识和经验,模型的泛化能力也较差.而本文提出基于双向长短期记忆网络和条件随机场的覆盖域检测模型能够有效利用上下文信息,并考虑相邻标记的依赖关系,自动学习潜在特征.
1.2 BiLSTM-CRF模型
近年来,神经网络模型在自然语言处理的各个任务中均取得了突破性进展.其中,循环神经网络(recurrent neural network, RNN)[13]能够很好地处理序列信息并从中学习有效特征,其最初由Goller等人[22]提出;但由于RNN在深度学习中存在梯度消失和梯度爆炸问题,Hochreiter等人[23]继而提出了RNN的变体长短期记忆网络(LSTM);之后,在单向LSTM 学习序列特征时,其仅考虑该序列的上文信息,而忽略了下文信息.为克服这个问题,Graves等人[24-25]提出双向LSTM(BiLSTM)模型,并将其应用于语音识别任务,该模型能够在一定时间内充分利用上下文信息;此外,条件随机场(CRF)由Lafferty等人于2001年[18]提出,在序列标注任务中,CRF能够学习相邻标记之间的依赖关系.
基于BiLSTM和CRF模型在序列标注任务中的各自优势,相关研究尝试将其进行融合.例如Huang等人[20]首次将BiLSTM与CRF的融合模型用于词性标注、语块分析、命名实体识别3类序列标注任务;Ma等人[16]将BiLSTM,CRF,CNN这3种模型进行融合并应用于端到端的序列标注任务中;Lample等人[17]将BiLSTM-CRF模型用于命名实体识别任务中.BiLSTM-CRF模型在以上序列标注任务中均取得了较高性能,基于此,本文尝试将该模型应用于面向汉语的否定与不确定覆盖域检测任务中.
2 汉语否定与不确定覆盖域检测
本节首先介绍BiLSTM-CRF模型,其次我们将覆盖域检测作为序列标注任务,给出序列标记方案及特征集合.
2.1 BiLSTM-CRF模型
LSTM单元能够有效消除冗余的上下文信息,并学习长距离依赖特征,因而被广泛应用于解决序列标注任务上.LSTM单元通常包含4个部分:输入门(input gate)、遗忘门(forget gate)、输出门(output gate)和细胞状态(cell).形式地,设x为输入,h为隐藏状态的输出.LSTM单元的状态不仅取决于当前输入xt,还受到上一时刻的输出值ht-1的影响.单个LSTM单元更新步骤为
it=σ(Wixt+Uiht-1+bi),ft=σ(Wfxt+Ufht-1+bf),ot=σ(Woxt+Uoht-1+bo),ct=ft⊗ct-1+it⊗tanh(Wcxt+Ucht-1+bc),ht=ot⊗tanh(ct),
(1)
其中,it,ft,ot,ct,分别表示时刻t输入门、遗忘门、输出门和细胞状态的输出,xt和ht表示时刻t的输入向量和隐藏层向量,σ(·)表示sigmoid激活函数,W和b分别表示权重矩阵和偏置向量,下标表示其所属归类,例如Wi和bi分别表示属于输入门结构中的权重矩阵和偏置向量.
由于LSTM结构无法同时学习2个方向的上下文特征,本文采用双向LSTM(BiLSTM)模型.如图1所示,该模型包含2个不同方向的并行层、前向层和后向层,分别从句子的前端和末端开始运行,存储2个方向的上下文信息.
在覆盖域检测中,当前词的标签通常与其周围的词存在关联,例如表示出现于关键词之前的标签B必须位于表示出现于关键词后的标签A(具体标记方案参见2.2节).CRF模型能够通过相邻词之间的条件概率,学习标签之间的依赖关系,本文在BiLSTM结构上层增加CRF结构,以获得全局最优的标签序列.给定句子:
x=(x1,x2,…,xn),
其预测标签序列为
y=(y1,y2,…,yn),
得分为
(2)
其中,C为BiLSTM网络的输出,大小为n×k,k表示不同标签个数,Ci,j表示句子中第i个词的第j个标签的得分;Ai,j表示第i个标签到第j个标签的转移概率,矩阵A大小为(k+2)×(k+2),由于在一个句子首尾添加了START和END标签,即y0和yn+1.对句子所有可能的标签序列采用柔性最大值(softmax)进行归一化:

(3)
其中,Y表示所有可能的标签序列集合.训练过程中,对正确标签序列进行最大化似然概率的计算:
L=max ln(p(y|x)).
(4)
最后,在解码端将最高得分的标签序列作为最终的标签序列输出:

(5)
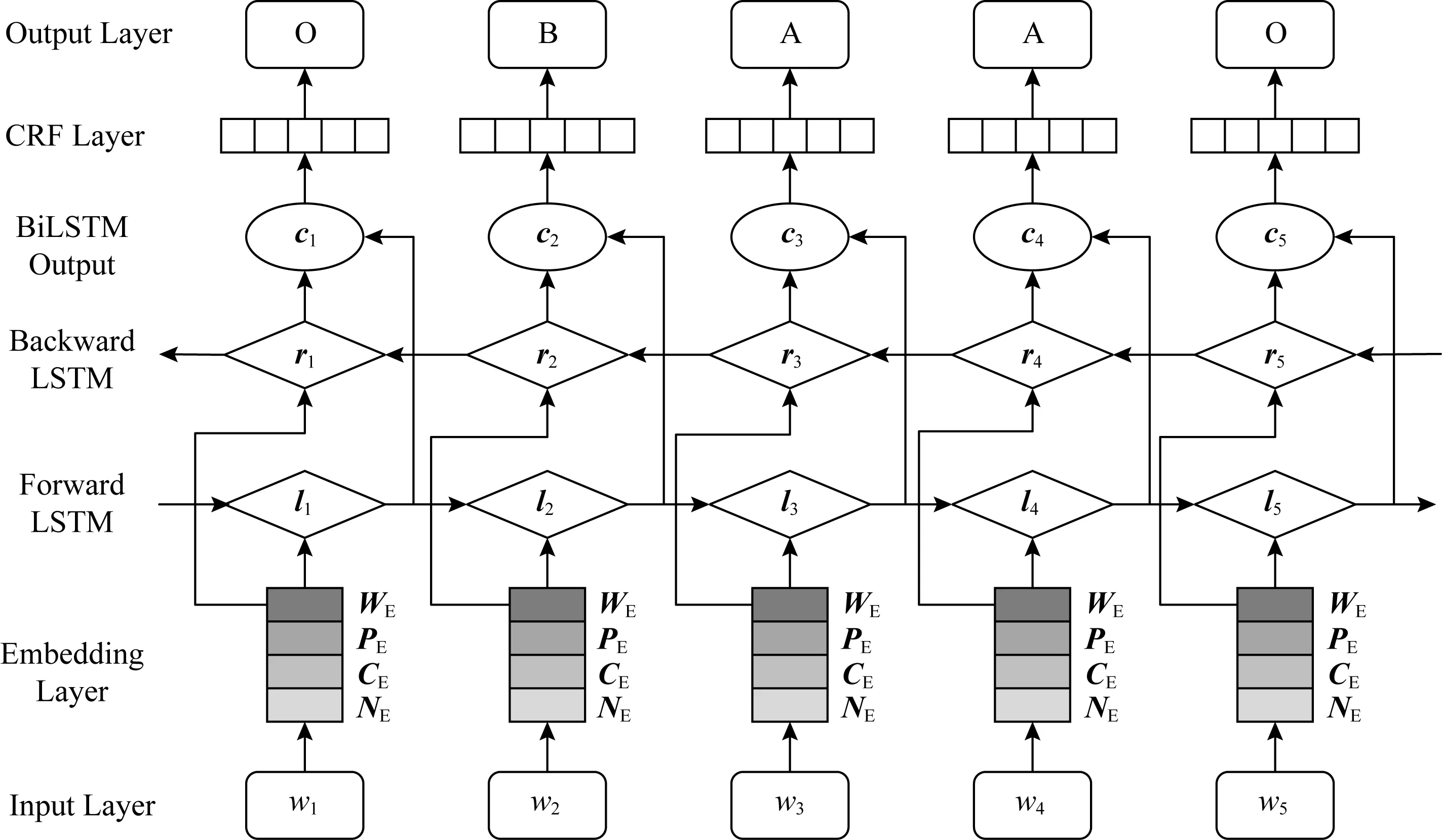
Fig. 1 Framework of the BiLSTM-CRF model图1 BiLSTM-CRF模型框架
2.2 面向汉语的否定与不确定覆盖域检测模型
本文提出的基于BiLSTM-CRF的覆盖域检测模型框架如图1所示.首先,将句子中的单词进行向量化表示,除了词向量(WE),本文还探索了其他特征,如位置特征(PE)、句法结构特征(CE)、词性特征(NE)、依存特征(DE).然后,将嵌入层向量送入前向LSTM和后向LSTM,学习相关的上下文特征,再将输出进行拼接,作为CRF层的输入,学习标签依赖关系,最终解码出全局最优的标签序列.此外,本模型为了减少过拟合,在BiLSTM网络两端各添加了dropout层.
1) 标记方案
本文采用BAO标记方案,含义如下.
标记B(before):位于覆盖域内,关键词之前;
标记A(after):位于覆盖域内,关键词之后,包含关键词;
标记O(outside):位于覆盖域之外.
对分词后的句子进行标记举例:
例3.唯一B 觉得A 还A 可以A 的A 是A 中餐厅A 的A 菜A ,O 用餐O 也O 不贵O .O
2) Embedding层
该层作为模型的输入,本文将词及其对应的特征进行编码.给定句子S=(w1,w2,…,wn),首先用向量矩阵WE将每个词转化成维度大小为dw的向量,其中,WE∈Rdw×|V|,V表示词表.
在自然语言处理领域,相关研究已经验证了词性、相对位置、成分句法、依存句法等特征的重要性[4,8-9,26].本文同时探索了这些特征对覆盖域检测任务 的有效性,其向量化表示如下.
词性.向量矩阵NE将每个词的词性映射为一个维度为dnat的实值向量,其中,NE∈Rdnat×|Vnat|,Vnat表示词性集合,采用随机初始化;
相对位置.向量矩阵PE将每个词与关键词之间的相对距离映射为一个维度为dpos的实值向量,其中,PE∈Rdpos×|Vpos|,Vpos表示相对距离的集合,采用随机初始化;
短语句法节点.向量矩阵CE将每个词在句法树中的父亲节点映射为一个维度为dcon的实值向量,其中,CE∈Rdcon×|Vcon|,Vcon表示成分句法节点的集合,采用随机初始化;
依存句法节点.向量矩阵DE将每个词在依存句法树中的父节点映射为一个维度为ddep的实值向量,其中,DE∈Rddep×|Vdep|,Vdep表示依存句法节点的集合,采用随机初始化.
3 实验结果与分析
本节首先介绍实验数据集、参数设置以及实验所采用评价指标、基准系统;然后给出实验结果,对参数的选择进行比较,并对错误结果进行分析;最后,与现有的覆盖域检测系统进行比较,验证本文方法的有效性.
3.1 实验设置
本文实验数据采用CNeSp语料库.该语料库包含科技文献、金融新闻、酒店评论3种类型的数据集,共16 841句,其中覆盖域实例数据为6 429个[8].每个实例均标注了否定或不确定关键词及对应的覆盖域.表1对CNeSp语料库进行了统计.可以看出,酒店评论数据的句子平均长度最短,其覆盖域平均长度也最短;总体来说,不确定覆盖域长度大于否定覆盖域.此外,值得注意的是,在酒店评论数据集中,否定实例的比例为52.9%,远高于其他2种类型的数据集,其原因是在酒店评论数据中负面评论较为常见,而在表述负面观点时,通常包含否定语义.
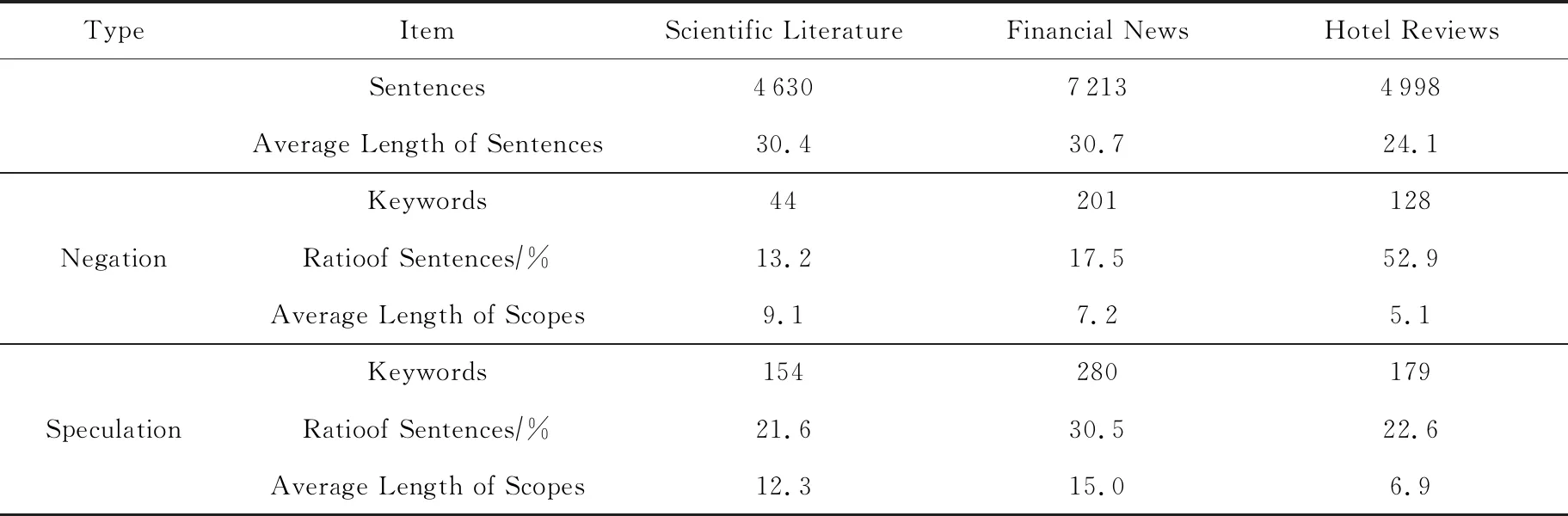
Table 1 Statistics of the CNeSp Corpus表1 汉语否定与不确定语料库(CNeSp)数据统计
实验分别将3个数据集按照70%,15%,15%的比例划分为训练集、验证集和测试集[27].本文采用准确率(precision)、召回率(recall)和F1值评价模型在标签标记时的性能.而在评价覆盖域检测的准确性时,本文采用该任务的标准评价指标[3-4,8-9],正确覆盖域的百分比(percentage of correct scopes,PCS),其计算方式为覆盖域标记正确句子数目与句子总数目的比值.两类评价指标各有侧重,F1值以词为单位,主要评价模型在标注序列中对每个单元的识别性能;而PCS指标以句子为单位,直接衡量模型在覆盖域检测任务上的性能.总体而言,后者作为主要性能指标,比前者更严格.
本文采用斯坦福句法分析工具(CoreNLP)获得句法特征[注]http://nlp.stanford.edu/software/lex-parser.shtml;中文分词工具采用结巴软件[注]https://pypi.org/project/jieba/;通过CLSim[注]http://nlp.csai.tsinghua.edu.cn/~lzy/src/acl2015 bilingual.html预训练出50维的词向量进行向量化[28].超参数设置方面,词性特征、位置特征、短语句法特征和依存句法特征维度均为20,dropout=0.4,LSTM隐藏层维度为150,学习率为0.015.本文选择带冲量(momentum)的随机梯度下降(stochastic gradient descent, SGD)算法训练神经网络模型,其中momentum=0.9.
为比较不同模型及不同特征的性能,本文采用3个模型作为基准系统.
1) LSTM_P.采用单向长短期记忆网络,输入为词向量和位置特征.
2) BiLSTM_P.采用双向长短期记忆网络,输入为词向量和位置特征.
3) BiLSTM-CRF_P.该系统为本文提出的方法,在BiLSTM网络上添加了CRF层,输入为词向量和位置特征.
此外,为验证不同特征对覆盖域检测任务的有效性,文本在BiLSTM-CRF_P模型上分别添加不同类型的特征.注意,由于位置特征在该任务上最为重要,因此在对比不同特征影响时,系统中始终保留此特征.对比系统有5个:
1) BiLSTM-CRF.输入仅包含词向量.
2) BiLSTM-CRF_P_POS.输入包含词向量、位置特征、词性特征.
3) BiLSTM-CRF_P_C.输入包含词向量、位置特征、短语句法特征.
4) BiLSTM-CRF_P_D.输入包含词向量、位置特征、依存句法特征.
5) BiLSTM-CRF_P_C_ POS.输入包含词向量、位置特征、词性特征、短语句法特征.
3.2 实验结果及分析
3.2.1 不同模型对系统性能的影响
表2和表3中行1~3对比了采用不同的序列标注模型的性能.可以看出,本文系统(BiLSTM-CRF_P)获得了最好性能,否定和不确定覆盖域检测的正确率(PCS)分别达到77.17%和76.43%.此外,对比实验结果可以看出:1)BiLSTM模型的性能在不同类型的数据集上均比LSTM模型高出15%左右,其原因主要是BiLSTM能够从前向和后向2个方向上学习,比后者能够更加充分地利用上下文信息;2)与BiLSTM相比,本文提出的基于BiLSTM-CRF覆盖域检测系统在否定和不确定性能上均有较大幅度的提升(PCS性能提升在10%左右),其原因主要是覆盖域通常为连续的文本片段,相邻词之间具有较强的依赖关系,CRF模型能够通过对转移概率的学习更好地捕捉相邻标签之间的依赖关系,弥补了BiLSTM的不足,使得系统性能获得较大提升.

Table 2 Influence of Different Models and Fearures on Performance of Systems onThree Different Datasets for Scope Detection in Negation表2 不同模型和不同特征对否定覆盖域检测系统性能影响 %
Note: The best result is bold.

Table 3 Influence of Different Models and Fearures on Performance of Systems on Three Different Datasets for Scope Detection in Speculation表3 不同模型和不同特征对不确定覆盖域检测系统性能影响 %
Note: The best result is bold.
表2和表3中行3~8对比了采用不同特征时BiLSTM-CRF系统的性能.可以看出:
1) 仅采用词向量作为输入的BiLSTM-CRF模型时,由于缺乏足够的特征,其性能相比其他系统差距较大.
2) 加入位置特征后(BiLSTM-CRF_P),其性能获得明显提升,接近最好的系统性能.说明位置特征对覆盖域检测任务最为重要.注意,在实验中本文同时也尝试了在BiLSTM-CRF模型中单独加入其他特征,其性能虽有提升,但均与位置特征有较大差距.
3) 在BiLSTM-CRF_P模型中分别加入词性特征(BiLSTM-CRF_P_POS)和短语句法特征(BiLSTM-CRF_P_C)时性能均有小幅度提升,在不同语料集上都达到各自最好性能.然而,当同时添加以上2个特征(BiLSTM-CRF_P_C_POS)时性能反而有所下降,其原因可能在于这2个特征包含的语法信息较为相似,同时添加时存在较大冗余,反而降低了系统的泛化性能.
4) 加入依存特征(BiLSTM-CRF_P_D)后,系统性能几乎未获得提升,其原因可能是由于依存句法表示词之间的依赖关系,而BiLSTM-CRF模型本身善于学习这种关系.
3.2.2 标记方案对系统性能的影响
除了2.2节中介绍的BAO标记方案,本文还尝试2种标记方案.
1) BIO标记方案
B:覆盖域内的第1个词;
I:覆盖域中除第1个词之外的其他词;
O:不在覆盖域中的.
2) IO标记方案
I:覆盖域中的词;
O:不在覆盖域中的词.
表4以BiLSTM-CRF_P_POS系统为例,给出了采用不同标记方案时覆盖域检测系统的性能比较.可以看出,BAO标记方案获得了最好的性能.此外,除科技文献数据集外,其他数据集上的性能差别不大,其原因可能是该数据集上的否定覆盖域实例仅有161个,远小于其他数据集,导致模型训练不稳定,测试集上的泛化性能较差.
3.2.3 训练数据集大小对系统性能的影响
图2验证了训练集大小对本文模型性能的影响.可以看出:训练集由60%逐渐增加至100%,系统性能提升较为缓慢(仅提升了6.7%);而训练集由10%提升至60%过程中,系统性能上升幅度较大.该结论说明训练本文提出的模型所需的数据量占CNeSp语料训练集的60%左右.
3.2.4 超参数对系统性能的影响
本节验证了超参数设置对模型的影响,旨在为相关研究提供参考.实验采用BiLSTM-CRF_P_POS模型,数据采用金融新闻否定覆盖域数据集.由

Table 4 Comparison of the Systems with Different Label Schemes in PCS表4 不同标记方案系统PCS性能比较 %
Note: The best result is bold.

Fig. 2 Comparison of the performance when utilizing different sizes of training set图2 训练数据集大小对系统性能的影响
表2和表3的实验结果可以看出位置特征在本文模型中的有效性,本文尝试采用不同维度对位置特征进行向量化表示.图3(a)给出了位置特征维度对系统性能的影响.可以看出,在维度为20时,系统性能最好;特征维度继续增大时,其表示信息的能力开始变弱,导致系统性能逐渐降低.
LSTM单元的隐藏层维度对神经网络模型的性能具有一定的影响,其在训练阶段容易出现过拟合:隐藏层维度偏大使得模型更复杂,泛化能力下降;隐藏层维度偏小则可能导致学习能力下降.因此,本文尝试用了不同维度的LSTM隐藏层,实验结果如图3(b)所示.可以看出:适当提升隐藏层的维度能够使系统性能获得提升,当隐藏层维度达到150时,系统性能达到最高值;而继续增大隐藏层维度时,系统性能开始降低,说明其泛化性能下降,出现过拟合.

Fig. 3 Effect of performance with different feature dimensions and different hidden layer dimensions of LSTM图3 位置特征维度和LSTM隐藏层维度对系统性能的影响
3.2.5 错误分析
本节对实验结果进行了定性分析,在金融新闻测试集上,分别选取了BiLSTM-CRF_P_POS系统的否定与不确定覆盖域各50个错误实例进行分析.主要集中在2类错误[注]加粗字体表示当前关键词,下划线表示无关关键词,方括号表示覆盖域正确答案,小括号表示系统识别的覆盖域.:
1)当句子中存在多个关键词时,在识别当前关键词对应的覆盖域时,会受到其他关键词的影响(否定,2350;不确定,2650).
例3.([虽然股市不再继续下跌],但是也没有上升趋势)…
例4.([这意味着变盘走好],近期可能不会再跌至这个点位之下).
例3中当前关键词为“不再”,其对应覆盖域为方括号所示,由于受到关键词“没有”的影响,系统最终识别为圆括号所示;同样,例4中,当前关键词为“意味着”,但受到关键词“可能”的影响,覆盖域也被识别错误.该类型错误占所有错误的50%左右.未来研究中,可以尝试采用随机初始化非当前关键词向量,以减弱其他关键词的影响.
例5.…[国内公布的相关数据(不太令人意)]…
例6.…[他也(建议如果基本面预期不是太差)]…
在例5和例6 中,位于关键词之前的覆盖域片段均未被正确识别.本文对金融新闻数据集的3 978 个否定与不确定覆盖域实例进行了统计,其中77%以关键词为开始,换言之,这些句子中没有标签为B的实例,此类错误可能由于训练不足导致.在未来工作中,可以尝试调整训练集中包含标签B的实例分布,使模型能够有效地学习.
3.3 与现有方法的性能比较
目前,面向汉语的否定与不确定覆盖域检测处于探索阶段,相关研究较为匮乏.因此,本文采用2个英文中最好的系统,以及1个汉语上最好的系统进行比较.
1) CNN_C和CNN_D.Qian等人[3]将覆盖域检测作为分类任务,分别采用短语句法路径与依存句法路径作为特征,该方法获得了目前英文BioScope语料上的最好性能.
2) BiLSTM.Fancellu等人[5]将覆盖域检测作为序列标注任务,与本文不同的是缺少CRF层,同时添加了词性特征.
3) MetaTree.文献[8]在发布汉语覆盖域检测语料的同时,提出了一个基于元决策树的基准系统,该系统融合了CRF模型与卷积树核模型.
表5比较了本文模型与以上4个模型在CNeSp语料库上的性能.

Table 5 Comparison with the States-of-the-art System in PCS表5 不同系统PCS性能比较 %
Note: The best result is bold.
可以看出,除了在科技文献数据集上的否定覆盖域检测之外,本文基于BiLSTM-CRF模型的覆盖域检测系统性能较最好系统均有大幅度提升.其中,本文方法与基于CNN模型的2种方法相比,具有显著提升.其原因是CNN方法将该任务作为分类任务,对每一个词独立地进行标签分类,而本文将其作为序列标注任务,通过BiLSTM学习上下文信息,能够有效学习到覆盖域的连续特征.此外,通过添加CRF层与BiLSTM方法相比有了进一步改善,说明CRF学习标签之间依赖关系对本任务更为有效.而在科技文献数据集上,否定覆盖域检测性能比MetaTree低6.74%.其原因可能是该数据训练集的实例过少,仅有121个实例,从而导致神经网络很难学到有效特征.
4 结 论
本文提出了一种基于双向LSTM网络与CRF融合模型的否定与不确定覆盖域检测方法,该模型借助BiLSTM网络学习上下文特征和长距离特征,并通过CRF层学习相邻标签之间的依赖关系,在CNeSp语料库上取得了目前的最好性能.此外,本文验证了位置特征、词性特征和短语句法特征在覆盖域检测任务中的有效性.
未来工作除了尝试进一步优化模型以解决3.2.5节中提到的主要错误之外,还需要研究跨领域的覆盖域检测任务.此外,由于面向英语的覆盖域检测模型相对成熟,如何将这些方法迁移到面向汉语的覆盖域检测任务中也是未来工作需要探索的方向.
