基于启发式搜索算法的扫地机器人路径规划
2019-07-11谢坤霖李宗根代宇航曾晟珂
谢坤霖,李宗根,代宇航,周 敏,曾晟珂
(1.西华大学西华学院, 四川 成都 610039; 2.西华大学计算机与软件工程学院, 四川 成都 610039)
随着科学技术的高速发展,智能化控制也成为当下家庭对家电选择的一个重要考虑因素。智能扫地机器人成为了目前比较受欢迎的一类机器人。一般来说,将完成清扫、吸尘、擦地工作的机器人,统一归为扫地机器人[1],它融合了机器人、传感器和人工智能等技术[2]。当前市面上的扫地机器人虽已能完成扫地的基本任务,但依旧无法完全像人力劳动者一样,还存在清扫区域不全、对不规则物体无法完全躲避、路径重复率高和效率低等问题[3-4]。基于此,本文对智能扫地机器人的路径规划提出了一种新方案,通过建立恰当的基本工作流程体系、构造合理的评价函数以及利用传感器设立沿边清扫机制等,来实现整体清扫工作的高覆盖率和低重复率。
1 基本路径规划方案
1.1 路径规划的衡量指标
作为评价智能扫地机器人优劣的关键技术之一的路径规划是学者研究的重点之一。点与点的路径规划,其效果是时间最短、路程最短,但覆盖率低;全遍历路径规划实现的是全区域覆盖且无碰撞,但其在时间与路程方面则无法做到效果良好[5]。换言之,路径规划是一种满足时间、路程和覆盖率等约束条件下的优化问题,无法在每个方面都做到最佳,只能对现有路径规划进行改进从而体现其综合优势。路径规划的衡量指标主要有3个。
1)覆盖率。覆盖率C是指机器人完成清扫时实际清扫面积与任务区域总面积的比值[6]。机器人在覆盖率方面的最优要求是实现环境全遍历的清扫,但根据简单约束条件下的约束方程可知,在实现覆盖率最优的条件下(即C趋近于1),必定是其他条件的最低实现。用S1表示实际清扫面积,S表示任务总区域面积,则覆盖率可表示为
(1)
2)重复率。重复率R是衡量一个数量性状在同一个体多次度量值之间的相关程度的参数。本文指机器人完成清扫时重复清扫面积与任务总区域面积的比值[7]。与重复率相关度最高的衡量指标应属覆盖率,在保证覆盖率最优的条件下,极大可能会破坏重复率的设置,因此在衡量重复率指标时须结合覆盖率列出约束方程。用S2表示完成清扫时重复清扫面积,S表示任务总区域面积,则重复率可表示为
(2)
3)付出的代价。扫地机器人付出的代价是指其在运行时的各种消耗,主要指时耗与能耗。智能扫地机器人的时效性是评价机器人工作优劣的一项重要指标,通过优化路径规划方案的细节,可以合理减少清扫时间。另一个重要指标是能量的消耗,由于不同的扫地机器人电池不同,能量总量也就不同,在规划路径、规定扫地任务的同时需要考虑到能量的消耗是否足够,这是设计机器人的重要考量参数。本文主要从路径规划着手,来尽量降低能量消耗。
总言之,一般来说应首先对覆盖率和重复率进行考量,因为将这2个指标优化后,机器人的时耗与能耗自然也会相应降低;故本文更侧重于对覆盖率和重复率的直接优化,使扫地机器人路径规划的各项指标达到更优水平。
1.2 建立基本路径规划方案
面对家庭扫地机器人出现的清扫覆盖率不高、清扫重复率高、时间效率低等问题[8],本文提出一种有效的路径规划方案:通过栅格法建立一个二维栅格地图[9-10],再将整个栅格地图划分为矩形子区域,并在各分区内逐个进行全覆盖的清扫,以达到扫地机器人基本的清扫目的。基本的清扫流程如图1所示。

图1 基本的清扫流程
1.2.1 构建栅格地图
W.E.Howden提出的栅格法常用于移动机器人的地图建模,基于栅格法建立二维空间模型,可以使扫地机器人在障碍物较少区域中的路径规划变得更加简单[11-13]。由于现实中的障碍物多是不规则或零散分布的,故先利用膨胀原理将未占满栅格的不规则障碍物做膨胀处理并将零散分布的障碍物隐藏,其后再对不规则和零散分布的障碍物的寻路方法进行单独讨论。
如图2所示,将扫地机器人需要清洁的区域表示成二维的平面工作空间,并将整个工作区域划分成M×N个边长为S的栅格,S是单位长度,其中白色栅格代表无障碍区、黑色栅格代表障碍物[4,14-15]。在程序中建立地图时,将白色栅格所代表的无障碍自由区域用0表示,黑色栅格所代表的障碍物用1表示。值得注意的是,单位栅格的边长取图1 基本的清扫流程值,较为理想的栅格长度是机器人的直径。
1.2.2 划分矩形子区域
在建立二维空间栅格地图后,整体上地形复杂、障碍物分布毫无规律,使扫地机器人清扫起来会产生清扫效率低、清扫时间长、重复率高等问题。将一个问题划分为子问题往往能使问题更简化[2],故本文采用将整个工作区域划分为子区域的方案。基于栅格法的特性,将各区域划分为矩形最为理想,且矩形子区域有便于用坐标标识、方便实现等优势。分区的好坏直接决定了内置模板的数量以及清扫的效率。最理想的情况是使分区内没有障碍物,内置模板的形式便能够大大减少,清扫效率也会随之提升。基于此,本文对传统的分区算法提出了一些改进。

图2 栅格化地图
分区的方法须满足3个原则:1)以左上角为原点,对栅格地图建立X,Y坐标轴;2)将相邻物体边界横坐标值X或纵坐标值Y相同的边界添加一条分割线[16];3)优先在非矩形物体周围的区域添加分割线,分割线要使矩形子区域面积最大化,如图3所示。对于物体1#、2#和3#的右边界具有相同横坐标2S,添加分割线作为1号区域和2号区域的右边界;对于中间的物体6#和4#,它们的左边界具有相同的横坐标5S,添加分割线作为3号区域的右边界;对于左下方的物体3#的上边界和物体6#的下边界,它们具有相同的纵坐标10S,添加分割线作为4号区域的上边界;对于上方物体4#和5#的下边界,它们具有相同的纵坐标3S,添加分割线作为6号区域的下边界;对于中间的物体6#上半部分的下边界和右边物体7#的上边界,它们具有相同的纵坐标6S,添加红色分割线作为7号区域的下边界;在原则2)的分割线都划分完成后,再对非矩形黑块周围按照矩形最大化进行划分得到5号区域的右边界、8号区域的下边界、9号区域的左边界。通过合并所有的自由子区域,得到一个完整的栅格地图。通过该方法划分为多个自由子区域可以减少扫地机器人因清扫路径过多而产生的错误,提高清扫的效率和准确性[17-19]。
1.2.3 子区域内的遍历方法
类似于分解法,把一个复杂问题分解成多个简单问题。在划分好各个子区域后,需要对各子区域内的路径进行规划[2,4]。得益于区域的理想划分,大部分无障碍物子区域用模板法即可高效解决,并且本文中的模板法让扫地机器人只存在一种转向方式,在一定程度上能降低扫地机器人清扫路径的重复率。其中,最主要的工作是建立恰当的起止点和往返遍历规则。规则制定得越恰当整体效率将越高。
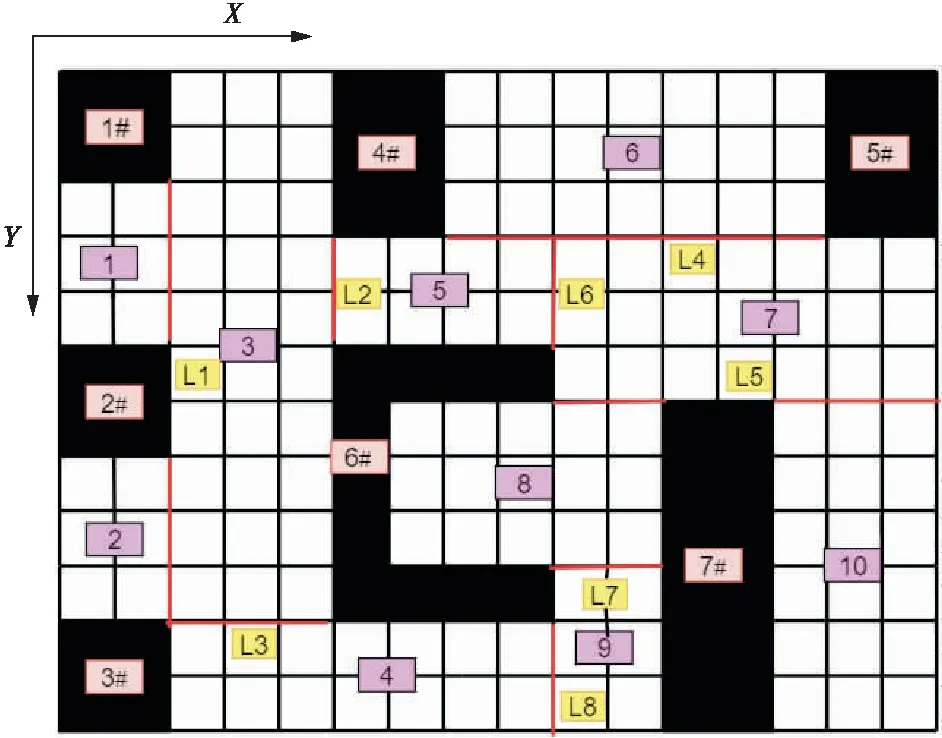
图3 栅格化地图的分区结果
首先确定各自由子区域的工作起点和终点位置。规则如下:将自由子区域的起点定义在横坐标值纵坐标值最小的节点(Xmin,Ymin)处,清扫终点的坐标由规则式(3) 确定。
if (Xmax-Xmin)<(Ymax-Ymin){
if (Xmax-Xmin=2KS(K=1,2,3,…)),(X,Y)=(Xmax,Ymin);
else if (Xmax-Xmin=(2K+1)S(K=0,1,2,3,…)),(X,Y)=(Xmax,Ymax);
}
if (Xmax-Xmin)>(Ymax-Ymin){
if (Ymax-Ymin=2KS(K=1,2,3,…)),(X,Y)=(Xmin,Ymax);
else if (Ymax-Ymin=(2K+1)S(K=0,1,2,3,…)),(X,Y)=(Xmax,Ymax);
}
(3)
如图4所示,绿色栅格代表扫地机器人的出发点,红色栅格代表扫地机器人的终点,扫地机器人须从起点开始清扫,到终点结束,从而完成单个自由子区域的清扫。该起终选取规则可以减少机器人转向次数。完成这些清扫动作还需要引入往返机制,参照函数为式(4)。
F(X)={X=1,Turn∪X=0,Go}
(4)
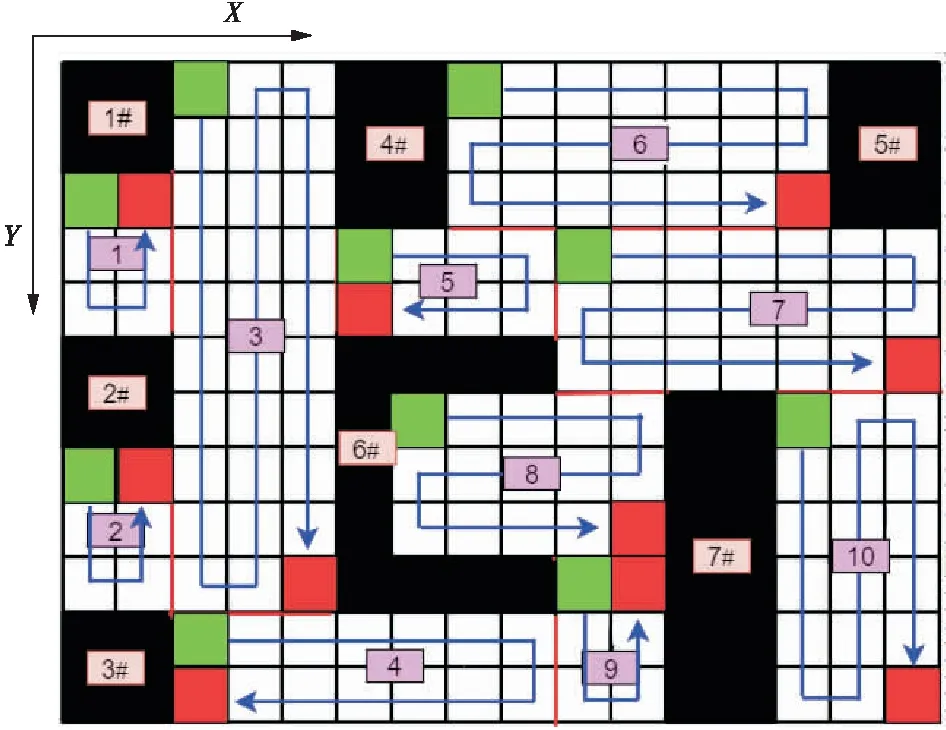
图4 子区域内的遍历方法2改进的路径规划方案
接着扫地机器人从绿色栅格出发,沿着四周的墙壁、黑色障碍物的边界或者划分好的由分割线构成的各个区域的边界,以直线运动的方式进行清扫。利用类似于气味遗留的算法,在扫地机器人完全通过一个栅格后,将上一个栅格标为0.01,代表已经通过路径,避免区域内遍历地图时重复清扫该栅格,并与0代表的未通过路径和1代表的墙壁、黑色障碍物、分割线等区别。具体的转向规则为:在一个子区域内,当扫地机器人碰到1时,立即向左边或右边相邻且未被清扫的自由栅格0转向,并进入到该自由栅格中。在扫地机器人完成上述操作后,它会继续完成一次转向,转向方向为上次转向方向。例如扫地机器人在自由子区域1清扫时,在碰到物体2#的上边界,它立即向行进方向的左方向转动进入到下一个自由栅格,之后它将立即左转进入再下一个自由栅格继续直线运动,直到到达绿色栅格。在清扫完一个自由子区域后进入下个自由子区域继续从绿色栅格到红色栅格的清扫,直到清扫完所有的自由子区域,具体的子区域遍历路线如图4所示。由于本文对栅格地图采取多个矩形自由子区域的划分和沿最长直线路线的清扫方式,让扫地机器人只存在一种转向方式,在一定程度上降低了扫地机器人清扫的重复率,提高了时间效率[2]。
2 改进的路径规划方案
2.1 基于启发式矩形子区域间的遍历方法
矩形子区域间的路径规划问题是研究一组对象如何在有限的区域内彼此尽量不重叠的优化布局问题[20]。它的研究具有广泛的应用价值,但作为NP难问题,很难准确地解决这一问题。
2.1.1 矩形子区域间遍历顺序的确定方法
矩形子区域间遍历顺序的确定依靠于图的相关遍历算法。深度优先遍历是遍历图中最重要的方法,它适用于无向图和有向图。将各分区抽出10个节点相连形成一个无向节点图,如图5所示。

图5 区域间节点图
利用深度优先算法很容易对节点图进行遍历并得到多解,但这些解的效率往往参差不齐[3]。例如经过节点A3时存在重复路径、拐角的选取问题。不考虑这些问题很可能产生一些不必要的重复路径。这时需要引入适当的评价函数来对解进行筛选,使路径整体规划效率达到较优的目的。评价函数直接影响着解的效率,但是评价函数的选取往往是比较困难的,并且没有绝对的好坏;所以只能在保证评价函数的选择要达到对模型的高度适应的前提下对所使用的评价函数进行较优择取。深度优先算法将启发信息引入搜索过程,并对周边的每个搜索位置进行评价,得到评价条件的最优位置,再把搜索到的位置作为基点进行搜索指导,以搜索到目标点,这样可以显著提高路径搜索的效率。
深度优先算法在路径搜索中采用评价函数F(n)对节点n进行评价,F(n)的表达式为
F(n)=G(n)+K(n)
(5)
式中:G(n)为起始点距当前位置的实际路径长度;K(n)为机器人转向角度和。设起始点为(xg,yg),当前位置为(xi,yi),则G(n)可表示为
(6)
设第i次转角的消耗为wi,则转向角度和K(n)可表示为
(7)
对该函数的各项做加权处理,使G(n)的权重最大,作为第一原则,以此保证整体效率较高;使K(n)的权重第二大,作为第二原则,能够在一定程度上降低重复率。
如图5所示,由于A3节点的存在,该图没有只遍历1遍的解,且满足G(n)最优的解也有多个,主要是在经过A3、A7节点时存在不同选择,但G(n)+K(n)对解做出进一步筛选,同时满足这2个条件的最优解路径是A10→A7→A6→A5→A3→A1→A3→A2→A3→A4→A9→A8。另外,若规定了不同的起点也会得到不同的解,这里本文采用A10为起点的最优解。
2.1.2 子区域间衔接路径的规划方法
选定好子区域间遍历顺序后,需要给出衔接路径的规划方法。
首先对衔接路径的长度进行最优化。利用传统的A*算法可以方便地规划出最短路径,但是需要对一些特殊情况做一些特殊讨论,以降低重复率[21]。对于相邻子区域的转移,可以进行直接规划,但本文给出的地图中有多处需要经过其他子区域来进行转移。如果按照从一个子区域终点到另一个子区域起点的方式来进行转移,会产生多且不必要的重复路径。对于这种情况需要使用程序进行识别归类。例如A3→A1→A3→A2这一转移过程,应直接对A1→A2进行规划。
接着引入启发函数,筛除冗余无用解。在实际规划中往往存在多解的情况,并且这些解的实际效率却并不一定都是最优,而传统的A*算法可能对这些解一视同仁[4]。如图6,A1→A3→A2这一过程,路径代价是一样的,转角代价却不一样,这很可能会在整个地图中增添一些不必要的功耗和时间代价。基于此,需要引入转向角度和对解做进一步的约束。用于子区域间衔接路径规划的评价函数F(n)的表达式为
F(n)=G(n)+K(n)+H(n)
(8)
式中:G(n)为起始点距当前位置的实际路径长度;K(n)为机器人转向角度和;H(n)为当前位置距终点的最佳路径的估计距离。仍然是G(n)的权重最大,K(n)的权重第二大。G(n)、K(n)的形式与上节一致。启发函数H(n)的引入使当前位置每次都会优先向终点方向进行移动,以达到先筛除冗余的无用解的目的。H(n)越复杂,约束条件越多,时间成本就越高;但降低H(n)的值,即如果减少约束条件,并不一定能得到最优路径,当H(n)=0时,便意味着正在进行盲目搜索。
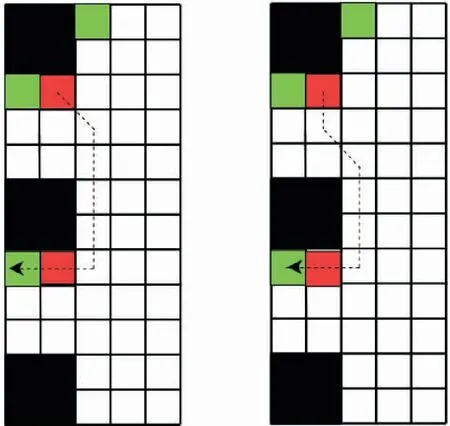
图6 最短路径的多解示意图
常用的启发函数如下。
1)曼哈顿距离。标准的估计函数为曼哈顿距离,即在南北方向上2点之间的距离和东西方向的距离。

3)欧氏距离。如果一个单元可以以任意角度而非栅格方向移动,那么可以使用欧氏距离。
如图1所示,与对照组比较,TGF组HLFs细胞α-SMA、ColI蛋白表达水平升高,差异有统计学意义(P<0.01);与TGF组比较,Tβ4中剂量组及高剂量组HLFs细胞α-SMA、ColI蛋白表达水平降低,差异有统计学意义(P<0.05或P<0.01);提示中剂量(10 mg/L)及高剂量(100 mg/L)Tβ4对TGF-β1诱导 HLFs细胞 α-SMA、ColI蛋白表达有显著抑制作用。
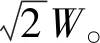
设栅格地图中曼哈顿距离为Hh(n),则有
Hh(n)=|xn-xg|+|yn-yg|
(9)
设栅格地图中对角线距离为Hd(n),则有
(10)
将Hh(n)和Hd(n)合并,并且简化可得
h(n)=W·[Hh(n)+Hd(n)]
(11)
因而,可得到完整的H(n)表达式,为
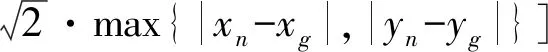
(12)
2.2 改进子区域内的遍历方法
2.2.1 多障碍物子区域内的遍历方法
当障碍物较多时,需要启用路径搜索功能[1]。目前大多数扫地机器人采用的是随机碰撞的寻路方式,即随机覆盖法,其普遍存在清扫效率低且在复杂地形下很难达到各方面高效的理想目标[22]。本文利用深度优先搜索算法保证了扫地机器人在障碍物较多的环境下能快速、精准地达到高覆盖率,但同时产生的重复率较高的问题很难完全解决。通过设置合理的评价函数以控制多种情况下的深度优先行为,能在一定程度上减少重复率[1]。评价函数有以下特点:当目标太低时,可以得到最短路径,但是速度会慢;当目标太高时,可以放弃最短路径,但是确保路径搜索算法运行得更快[22]。在这一点上,必须在运行效率和路径选取之间进行权衡[23]。
从这个例子不难看出,将H(n)取一个较为中间的值最为妥当。深度优先算法的内部内容是在每个节点上计算。当H(n)与G(n)完全匹配时,F(n)的值不会沿该路径变化。不在正确路径上的所有节点的F(n)值均大于正确路径上的F(n)值。一般情况下,能够保证路径长度和运行时间可以达到较为均衡的状态,并且解不会偏离最短路径[25]。
2.2.2 不规则障碍物区域的路径规划方法
在区域衔接时若遇到不规则障碍物区域,应该对膨胀处理后的不规则的障碍物边缘进行规划清理。针对不规则障碍物,在分区衔接的路径规划中,需要运用传感器对不规则障碍物的边进行探测,控制机器人与障碍物之间的距离,以使其沿不规则障碍物的边清扫。
在沿边搜索时,需要利用传感器来采集环境信息,路径规划规则需在环境信息模型的基础上针对障碍物来寻求一系列行为动作。对在沿边行进的多条路径中的不同地形的评估,可以使用评估代价的算法来计算一条初始路径[26-28]。
例如,定义低幅度路面不平的代价是1,大幅度
(a)
(b)

(c)
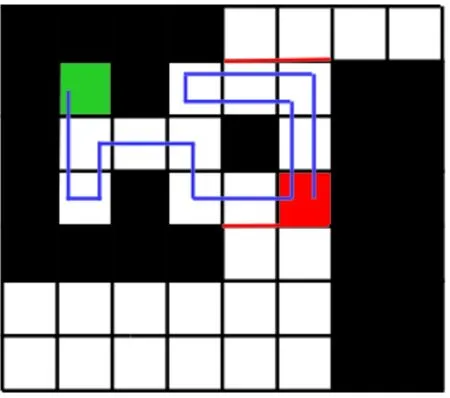
路面不平的代价是2,路线曲折的代价是3,路径狭窄的代价是4,那么程序会考虑通过3个低幅度不平的路段来避免通过一个路线曲折的路段。通过把路段通过的难易程度进行量化来计算初始路径,可以使用更少的时间规划,且可以更快地找到一条路径使其接近于精确启发函数的效果[29]。一旦找到一条路径,物体就可以开始移动,当多余的CPU时间是可用的时候,也可以用更细致的阶梯式移动代价去计算更好的路径。在RobotBASIC中能模拟出带有传感器的机器人,可实现机器人对不规则障碍物进行沿边遍历,效果如图8所示。
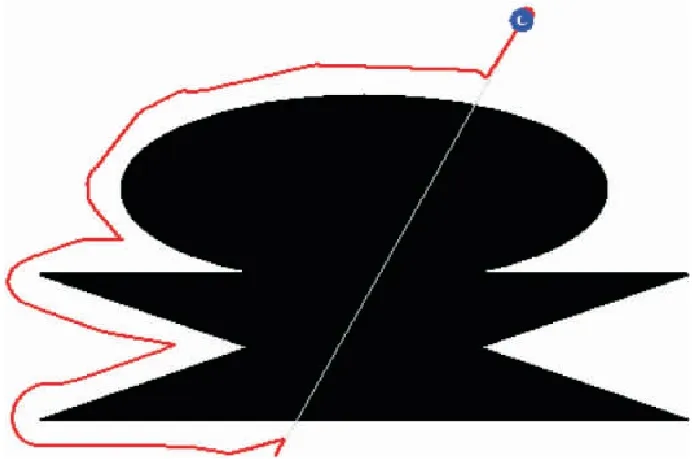
图8 对不规则障碍物的沿边清扫示意图
3 测试
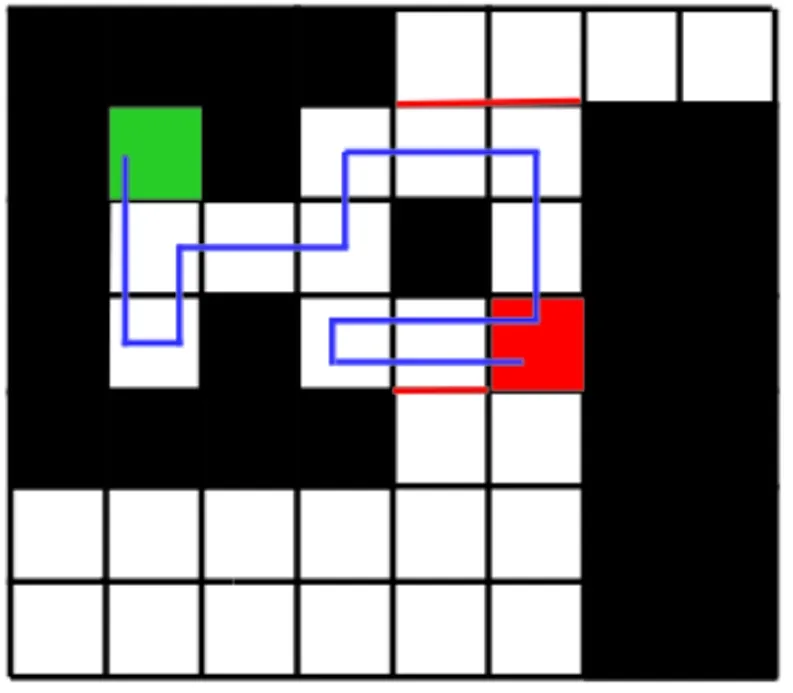
如图9所示的全遍历路径规划图,深蓝色的圆为整个清扫过程的起点,深蓝色的勾为整个清扫过程的终点。该图一共有16×12个栅格,黑色的障碍物区域约占50个栅格,自由栅格一共142个。其中,重复遍历的栅格为45个,重复率约31%,覆盖率近100%。本文所设的地图较小、栅格数量较少,且障碍物较为紧凑,便于示意。在实际中,栅格的数量会大大增加,覆盖率也会随之减少。如图10所示,将地图倍增后,重复率降为18%。总的来说,该算法可将重复率控制在10%~18%的范围内。传统算法与改进算法路径规划的覆盖率和重复率对比如表1所示。
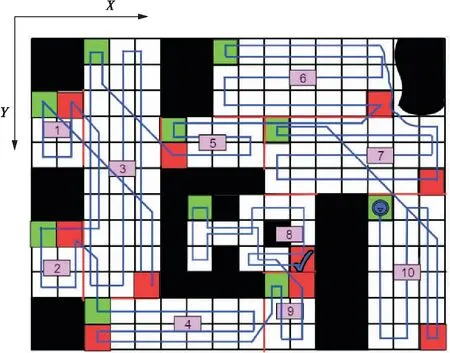
图9 全遍历路径规划图

图10 全遍历路径重复率示意图

遍历方式覆盖率/%重复率/%传统规划算法90~94>20改进规划算法> 9910~18
另外,在实际工作中,扫地机器人的转向也会影响清扫效率。在该算法中,由于增加了对角度的约束,减少了转向角度和,在一定程度上提高了整体的清扫效率[2]。
综上,改进后的算法在整体的清扫覆盖率、重复率和效率上都有不同程度的提高。
4 结束语
经过对扫地机器人路径规划的探讨,发现不管是使用哪一种规划路径的方法,都会出现一定的重复,只能通过不断优化整体方案来逐渐降低重复率。本文提出的方案在覆盖率和重复率上表现较为突出,且总体时耗、能耗也相应略有降低。在面对不规则障碍物时,由于机器人本身的直径大小会使其在清扫不规则障碍物周身时出现一定的盲区,导致该部分区域无法清洁。接下来可以从以下几方面来考虑改进:改进地图分区方式;改进复杂环境下扫地机器人的寻路算法;对机器人的机器形态、运动方式、运动和转向能耗进行优化等。
