Application of Big Data analysis in gastrointestinal research
2019-07-10KaShingCheungWaiLeungWaiKaySeto
Ka-Shing Cheung, Wai K Leung, Wai-Kay Seto
Abstract Big Data, which are characterized by certain unique traits like volume, velocity and value, have revolutionized the research of multiple fields including medicine. Big Data in health care are defined as large datasets that are collected routinely or automatically, and stored electronically. With the rapidly expanding volume of health data collection, it is envisioned that the Big Data approach can improve not only individual health, but also the performance of health care systems. The application of Big Data analysis in the field of gastroenterology and hepatology research has also opened new research approaches. While it retains most of the advantages and avoids some of the disadvantages of traditional observational studies (case-control and prospective cohort studies), it allows for phenomapping of disease heterogeneity, enhancement of drug safety, as well as development of precision medicine, prediction models and personalized treatment. Unlike randomized controlled trials, it reflects the real-world situation and studies patients who are often under-represented in randomized controlled trials. However, residual and/or unmeasured confounding remains a major concern, which requires meticulous study design and various statistical adjustment methods. Other potential drawbacks include data validity, missing data, incomplete data capture due to the unavailability of diagnosis codes for certain clinical situations, and individual privacy. With continuous technological advances, some of the current limitations with Big Data may be further minimized. This review will illustrate the use of Big Data research on gastrointestinal and liver diseases using recently published examples.
Key words: Healthcare dataset; Epidemiology; Gastric cancer; Inflammatory bowel disease; Colorectal cancer; Hepatocellular carcinoma; Gastrointestinal bleeding
INTRODUCTION
The etymology of “Big Data” can be dated back to the 1990s, and this term has become popular after John Mashey, the then chief scientist at Silicon Graphics[1].Datasets are exponentially expanding every day, fed with a wide array of sources[2]like mobile communications, websites, social media/crowdsourcing, sensors,cameras/lasers, transaction process-generated data (e.g., sales queries, purchases),administrative, scientific experiments, science computing, and industrial manufacturing. The application of Big Data analysis has proven successful in many fields.Technology giants (e.g., Amazon, Apple, Google) have boosted sales and increased revenue by means of Big Data approaches[3]. It has also been adopted as part of the electoral strategies in political campaigns[4].
There is currently no consensus on the definition of Big Data, but the characteristics pertinent to the process of collection, storage, processing and analysis of these data helps to forge Big Data as a more tangible term. It was first described by Doug Laney in 2001 that Big Data possessed 3Vs: Volume (storage space necessary for data recording and storage), Velocity (speed of data generation and transformation) and Variety (various data sources)[5]. Since then, many other traits to define Big Data have been proposed, including veracity, value, exhaustivity (n = all), fine-grained resolution, indexicality, relationality, extensionality, scalability, and variability[2].
BIG DATA RESEARCH IN GASTROENTEROLOGY AND HEPATOLOGY
The digitalization of nearly every aspect of daily life has made no exception in the field of healthcare, with the importance of Big Data application being increasingly recognised and advocated in recent years. While there are various definitions of Big Data outside of the medical field, the specific definition with respect to health has only been proposed in recent years. According to the report produced under the third Health Programme (2014-2020) from the Consumer, Health, Agriculture and Food Executive Agency mandated by the European Commission[6], Big Data in Health are defined as large datasets that are collected routinely or automatically, and stored electronically. It merges existing databases and is reusable (i.e., multipurpose data that are not intended for a specific study), with the aim of improving health and health system performance. A further supplement is the scale and complexity of the data that mandates dedicated analytical and statistical approaches[7]. Such large volume and scale of Big Data arise not only from the number of subjects included, but also the diversity of variables from different domains (clinical, lifestyle, socioeconomic,environmental, biological and omics) at several time points. The estimated healthcare volume of 153 exabytes (1018) in 2014 is projected to hit 2,300 exabytes by 2020[8,9].
Big Data in Health relies on a wealth of sources: Administrative databases,insurance claims, electronic health records, cohort study data, clinical trial data,pharmaceutical data, medical images, biometric data, biomarker data, omics data (e.g.,genomics, proteomics, metabolomics, microbiomics), social media (e.g., Facebook,Twitter), income statistics, environmental databases, mobile applications, e-Health tools, and telemedicine (diagnosis and management at a distance, particularly by means of the internet, mobile phone applications and wearable devices)[9]. The importance of “data fusion” therefore relies on the systematic linking of datasets from different sources to add values and new insights, enabling the analysis of health data from different perspectives (individual, group, social, economic and environmental factors) across different regions or nations.
Disease entities in the field of gastroenterology and hepatology are often heterogeneous [e.g., malignancy, inflammatory bowel disease (IBD)] with a wide range of clinical phenotypes (e.g., age of onset, severity, natural course of disease,association with other diseases, treatment response). Big Data analysis allows for the subclassification of a disease entity into distinct subgroups (i.e., phenomapping),which enhances understanding of disease pathogenesis, as well as the development of more precise predictive models of disease outcomes. The use of only clinical and laboratory data (as in traditional clinical research) in predicting disease course,outcome and treatment response may not achieve a high accuracy[9]. Similarly,although genome-wide association studies (commonly known as GWAS) and identification of single nucleotide variants have linked particular disease phenotypes to genetic defects, most genetic variants have a small impact on disease risk,behaviour and treatment response[10]. This inaccurate differentiation has led to the unnecessary use of therapeutics (which are sometimes costly with undesirable side effects) in many patients (e.g., biologics in IBD patients). It therefore appears that only by considering the complex interactions between genetic, lifestyle, environmental factors, and previously unconsidered factors (e.g., omics) in Big Data approaches can a reliable predictive prognostic model be developed, which ultimately guides a targeted approach for selecting treatment regimens for individual patients (i.e., precision or personalized medicine)[9,11,12].
Apart from phenomapping and precision medicine, other important implications of Big Data approaches are drug discovery and safety. Drug research and development(R and D) is an expensive and lengthy process, with each drug approval costing $3.2-32.3 billion US dollars[13]. Many of the trial drugs have proven futile or harmful in early or even late stages of the development (e.g., secukinumab in Crohn's disease[14]).Even for drugs proven to be beneficial, they may only work in certain subgroups of patients. The heterogeneity of therapeutic outcomes is again likely multifactorial.Precision medicine from Big Data approaches will help pharmaceutical companies predict drug action and prioritize drug targets on a specific group of patients[15]. This ensures a cost-effective approach in developing new therapeutics with a lower chance of futility.
Recently, “drug repositioning” or “drug repurposing” has been advocated, in which currently approved drugs are explored for other indications of gastrointestinal and hepatic diseases. However, to make sense of the large-scale genomic and phenotypic data, advanced data processing and analysis is an indispensable element,hence giving rise to the term “computational drug repositioning or repurposing”[16].This involves a process of various computational repositioning strategies utilizing different available data sources, computational repositioning approaches (e.g.,machine learning, network analysis, text mining and semantic inference), followed by validation via both computational (electronic health records) and experimental methods (in vitro and in vivo models). Applicable disease areas include oncology [e.g.,hepatocellular carcinoma (HCC)][17,18], infectious diseases, and personalized medicine,just to name a few. New indications of existing medications constituted 20% of 84 drugs products introduced to the market in 2013[19]. Drug repositioning is expected to play an increasingly important role in drug discovery for gastrointestinal and liver diseases.
With regards to drug safety, monitoring currently relies on data from randomized controlled trials (RCTs) or post-marketing studies. However, RCTs may be underpowered to detect rare but important side effects, and fail to capture adverse effects that only manifest beyond the designed follow-up time (e.g., malignancy). Postmarketing studies based on registries are resource-intensive in terms of cost and time,and the safety profile of a drug can only be depicted several years after marketing.The application of text mining, the computational process of extracting meaningful information from unstructured text, has proven useful to improve pharmacovigilance(e.g., arthralgia in vedolizumab users in IBD[20]). The sources are not limited to medical literature and clinical notes, but also product labelling, social media and web search logs[21,22].
ADVANTAGES AND SHORTCOMINGS OF BIG DATA APPROACHES
In healthcare research, RCT is regarded as the gold standard to investigate the causality between exposure and the outcome of interest. Randomization balances prognostic factors across intervention and control groups. It eliminates both measured and unmeasured confounding, making the establishment of causality possible.However, it is resource-intensive to conduct RCTs in terms of money, manpower and time. It is difficult to study rare events (e.g., cancer, death) or long-term effects. Due to the stringent inclusion and exclusion criteria, as well as differential levels of care and follow-up in a clinical trial setting, results from RCTs may not reflect real-life situations, and may not be generalizable to other populations. Finally, effects of harmful exposure cannot be studied due to ethical concerns.
To circumvent these shortcomings of RCTs, observational studies are alternatives.Case-control studies are cheaper and quicker to conduct, and can study multiple risk factors of rare diseases, as well as potentially harmful exposure that is otherwise impossible in RCTs. On the other hand, prospective cohort studies can investigate multiple exposures and outcomes, effects of rare exposure, as well as potentially harmful exposure. Nonetheless, it is difficult to study rare exposures in case-control studies, as well as rare diseases or long-term effects in prospective cohort studies. It is also impossible and unethical to prospectively follow the natural history of chronic diseases and its complications without appropriate interventions[23]. In addition, for both study designs, multiple biases (e.g., reverse causality, selection bias, interviewer bias, recall bias) can exist, and confounding, whether measured or unmeasured, is always possible.
The application of Big Data analysis in healthcare research has revolutionized clinical study approaches. Clinical studies making use of these datasets usually belong to either retrospective cohort studies (non-concurrent/historical cohort studies) or nested case-control studies. As the clinical data are readily available without delays, and easily retrieved from the electronic storage system, a multitude of risk factors can be included to analyse the outcome. It also enables the study of rare exposures, rare events and long-term effects within a relatively short period of time.Resources are much less than that required for prospective cohort study design,except for dedicated manpower with the aid of high-performance computers and software, e.g., R, Software for Statistics and Data Science, Statistics Analysis System,Python. In essence, it retains most of the advantages while avoiding some of the disadvantages of case-control and prospective cohort studies. Unlike RCTs, it reflects the real-world efficacy, and studies patients who are often under-represented in or completely excluded from RCTs (e.g., the elderly, pregnant women). Furthermore, the huge sample size of Big Data permits subgroup analysis to investigate interactions between different variables with the outcome of interest without sacrificing statistical power. It enables the investigation of varying effects due to time factors (i.e., division of the follow-up duration into different segments) on the association between exposure and outcome, given a sufficiently long observation period (in terms of years or decades) and sample size. It also allows for multiple sensitivity analyses by including certain sub-cohorts, modifying definitions of exposure (e.g., duration of drug use), or different statistical methods to prove the robustness of study results. A reliable capture of small variations in incidence or flares of a disease according to temporal variations also heavily depend on the sample size. In the most ideal situation of n = all, selection bias will no longer be a concern.
However, it should be acknowledged that without randomization, residual and/or unmeasured confounding remains a concern in Big Data research. As such, one may argue that causality cannot be established. The inclusion of RCT datasets with the extensive collection of data and outcomes for trial participants or linkage with other data sources may partly address this issue[24]. The possibility of causality can also be strengthened via the fulfilment of the Bradford Hill criteria[25]. Second, data validity concerning the accuracy of diagnosis codes (e.g., International Classification of Diseases) in electronic databases has been challenged[26]. In addition, milder disease tends to be omitted in the presence of more serious disease, and hence the absence of a diagnosis code may not signify the absence of that particular disease[27]. For instance,depression, which is often not coded among the elderly with other serious medical diseases, may be paradoxically associated with reduced mortality. To a certain extent,data validity can be verified through validating the diagnosis codes by cross referencing the actual diagnosis of a subset of patients in the medical records.
Third, missing data can potentially bias the result via a differential misclassification bias. There are different remedies, although the use of multiple imputation is preferred, which involves constructing a certain number of complete datasets (e.g., n =50) by imputing the missing variables based on the logistic regression model[28].Nonetheless, missing data with differential misclassifications are not a major problem in Big Data health research, as diagnosis codes are recorded by healthcare professionals, with other clinical/laboratory information being automatically recording in electronic systems. This is unlike questionnaire studies in which missing data occur due to patient preferences to reveal their details (i.e., misclassification bias).
Fourth, some clinical information may be too sophisticated to be recorded[26](e.g.,lifestyle factors, dietary pattern, exercises), incompletely or selectively recorded (e.g.,smoking, alcohol use, body mass index, family history), or not represented by the coding system (e.g., bowel preparation in colonoscopy research). This may be partially addressed by using other variables as proxies for unmeasured variables. For example,chronic pulmonary obstructive disease is a surrogate marker of heavy smoking.Certainly, in the most ideal situation, adjusting for a perfect proxy of an unmeasured variable achieves the same effect as adjusting for the variable itself. Large healthcare datasets will usually contain a sufficient set of measured surrogate variables, insofar as it represents an overall proxy for relevant unmeasured confounding. A more fascinating and precise approach is the analysis of unstructured data within the electronic health records [e.g., natural language processing (NLP) to extract meaningful data from text-based documents that do not fit into relational tables][29]. As an example, free-text searches outperformed discharge diagnosis coding in the detection of postoperative complications[30]. In the field of pharmacoepidemiological studies, over-the-counter medication usage is frequently not captured in electronic database systems. These “messy data” (false, imprecise or missing information), more often representing non-differential misclassification bias instead of a differential one,will usually attenuate any positive association, and even trend towards null[23].Generally, a “false-negative” result is preferred to a “false-positive ” one in epidemiological studies.
Lastly, ethical concerns over an individual's right to privacy versus the common good have yet to be satisfactorily addressed[31]. The issue of privacy can be tackled with de-identification of individuals using anonymous identifiers (e.g., unique reference keys in terms of numbers and/or letters), although in rare occasions a remote possibility of discerning individuals still exists[23]. For instance, individuals with a very rare disease may be identified via mapping with enough geographical detail.
Although Big Data analysis generates hypothesis-free predictive models wherein no clear explanation accountable for the outcome may be found, it provides a valuable opportunity to derive hypotheses based on these observations, which may not be otherwise conceivable. This strategy (in silico discovery and validation) applies to both candidate biomarkers and therapeutic targets to accelerate the development process for an earlier clinical application. In the end, traditionally hypothesis-driven scientific method research should still be applied to validate the results in multicentre, prospective studies or RCTs. Table 1 summarizes the advantages and shortcomings of Big Data analysis in gastroenterology and hepatology research, as well as its proposed solutions.
PROPENSITY SCORE METHODOLOGY IN BIG DATA ANALYSIS
As stated previously, confounding is an inevitable problem of observational studies,irrespective of the sample size. Confounding is a systematic difference between the group with the exposure of interest and the control group[27]. It arises when other factors that affect the exposure of interest are also independent determinants of the outcome. Common sources of confounding include confounding by indication/disease severity, confounding by functional status and cognitive impairment, healthy user/adherer bias, ascertainment bias, surveillance bias, access to healthcare, selective prescription, and the treatment of frail and very sick patients[27].
Propensity score (PS) methodology has become a widely accepted and popular approach in Big Data analysis of analytic studies in healthcare research. A PS is the propensity (probability) of an individual being assigned to an intervention/exposure conditional on other given covariates, but not the outcome[32]. It is derived from the logistic regression model by regressing the covariates (exclusive of the outcome) onto the exposure of interest. By taking into account this single score in further statistical analysis, a balance of the characteristics between exposure and control groups could theoretically be achieved in the absence of unmeasured confounding. PS methodology entails PS matching, PS stratification/subclassification, PS analysis by inverse probability of treatment weighting, PS regression adjustment, or a combination of these methods, and we refer readers to other articles for further details[33].
To control for confounding, outcome regression models are traditionally applied.However, this is constrained by the dimensionality of available variables in healthcare datasets (i.e., “curse of dimensionality”). In the simulation study on logistic regression analysis by Peduzzi et al[34], a low events per variable (EPV) was found to be more influential than other problems, such as sample size or the total number of events. If the number of EPV is less than ten, the regression coefficients may be biased in both positive and negative directions, the sample variance of the regression coefficients may be over- or under-estimated, the 95% confidence interval may not have proper coverage, and the chance of paradoxical associations (significance in the wrong direction) may be increased. The use of PS methodology, by condensing all covariates into one single variable (PS), can thus address this “curse of dimensionality”[35].However, PS methodology may not offer additional benefits if the EPV is large enough. Statistical significance differs between the two methods in only 10% of cases,in which traditional regression models give a statistically significant association not otherwise found in PS methodology[36]. In addition, the effect estimate derived by traditional models differs by more than 20% from that obtained by PS methodology in 13% of cases[37].

Table 1 Advantages and shortcomings of Big Data analysis (with proposed solutions)
The use of PS allows the recognition of subjects with absolute indications (or contraindications) of an intervention, who have no comparable unexposed (or exposed) counterparts for valid estimation of relative or absolute differences in the outcomes[35]. This can be easily identified by plotting a graph of PS distribution between the two groups to look for areas of non-overlap. This pitfall is unlikely to be recognised by traditional modelling, and could be influential as a result of effect measure modification or model misspecification. PS methodology allows trimming(i.e., excluding individuals with areas of non-overlap in PS distributions) or matching to ensure comparability between exposure and control groups. In particular, PS matching does not make strong assumptions of linearity in the relationship of propensity with outcome, and is also better than other matching strategies to achieve an optimal balance of a large set of covariates. The interaction effect of PS with treatment may exist, as effectiveness of an intervention varies according to the indications. An intervention is beneficial in patients with clear indications, but paradoxically provides no benefit, or is even harmful in those with weak indications or contraindications. This was nicely illustrated in the study by Kurth et al[38]on the effect of tissue plasminogen activator on in-hospital mortality. Table 2 summarizes the major advantages of PS methodologies.
EXAMPLES OF GASTROINTESTINAL DISEASE RESEARCHE USING BIG DATA APPROACHES
Tables 3-7 show a list of research using Big Data approaches from different regions/countries worldwide. This list is by no means exhaustive, however provides a few distinct examples of how Big Data analysis can generate high-quality research outputs in the field of gastroenterology and hepatology. Specifically, in the following section, we will demonstrate how researchers conducted research on some important gastrointestinal and liver diseases, including gastric cancer, gastrointestinal bleeding(GIB), IBD, colorectal cancer (CRC), and HCC. It should be noted that the majority of database systems fulfil the characteristics of the 3Vs (volume, velocity and variety).This is with the exception of the Nurses Health Study (known as NHSII) and Health Professionals Follow-up Study (known as HPFS), which are prospective studies without instantaneous updates of the clinical information using participant questionnaires, thus limiting the velocity of data generation and transformation.
Gastric cancer
Gastric cancer is the fifth most common cancer and third leading cause of cancerrelated deaths worldwide[39]. Around two-thirds of patients have gastric cancer diagnosed at an advanced stage, rendering curative surgery impossible[40,41]. Infection by Helicobacter pylori (H. pylori), a class I human carcinogen[42], confers a two- to threefold increase in gastric cancer risk[43,44]. RCTs and prospective cohort studies on the effect of H. pylori eradication on gastric cancer development are difficult to perform due to the low incidence of gastric cancer, as well as the long lag time of any potential benefits, which mandate a huge sample size with long follow-up duration.
However, Big Data analysis may shed new light on the role of H. pylori eradication on gastric cancer development based on population-based health databases. It was shown in a Swedish population-based study that H. pylori eradication therapy was associated with a lower gastric cancer risk compared with the general population, but this effect only started to appear beyond 5 years post-treatment[45]. Stratified analysis in a Taiwanese study based on the National Health Insurance Database (commonly known as NHID) showed that early H. pylori eradication was associated with a lower gastric cancer risk than late eradication when compared with the general population[46]. Based on a territory-wide public healthcare database in Hong Kong called the Clinical Data Analysis and Reporting System, H. pylori eradication therapy was beneficial even in older age groups (≥ 60 years)[47]. Apart from H. pylori eradication, regular non-steroidal anti-inflammatory drug use was also shown to be a protective factor for gastric cancer based on the study from NHID from Taiwan[48].Long-term aspirin use further reduced gastric cancer risk in patients who had received H. pylori eradication therapy[49]. Moreover, the long-term use of metformin was associated with a lower gastric cancer risk in our patients who had received H.pylori eradication therapy[50].

Table 2 Advantages of propensity score methodology
On the other hand, long-term proton pump inhibitor (PPI) use was associated with an increased gastric cancer risk in patients who had received H. pylori eradication therapy[51], which is otherwise difficult to be addressed by RCTs[52]. This finding was echoed by another nationwide study[53]. A study on the interaction between aspirin and PPIs further showed that PPIs were associated with a higher cancer risk among non-aspirin users, but not among aspirin users[54]. However, pantoprazole, a longacting PPI, was not associated with an increased gastric cancer risk compared with other shorter-acting PPIs in a United States Food and Drug Administration(commonly known as FDA)-mandated study[55]. Other risk factors for gastric cancer determined by large healthcare datasets included the extent of gastric intestinal metaplasia, as well as a family history of gastric cancer[56]. In addition, racial/ethnic minorities had a 40%-50% increase in gastric cancer risk compared with the Hispanic and white populations[57].
GIB
Upper GIB is one of the most common causes of hospitalization, and emergency department visits that pose significant economic burdens on the healthcare system.Antiplatelet agents (including aspirin and P2Y12inhibitors) were major causative agents[5]. In a nationwide retrospective cohort study, it was shown that H. pylori eradication and PPIs were associated with reduced incidences of gastric ulcer (42%-48%) and duodenal ulcers (41%-71%)[58]. However, importantly, concomitant use of clopidogrel, H2-receptor antagonists (referred to as H2RAs) and PPIs was associated with an increased risk of acute coronary syndrome or all-cause mortality[59]. This harmful effect was particularly prominent for PPIs with high CYP2C19 inhibitory potential[60]. These findings raised the need for judicious use of gastroprotective agents in clopidogrel users, and called for further studies to determine causality versus biases(e.g., indication bias).
When novel oral anticoagulants (NOACs) were first introduced, there was a paucity of real-world data on the GIB risk and its preventive measures[61]. In a territory-wide retrospective cohort study, the risk of GIB was determined in dabigatran users, with risk factors identified and effects of gastroprotective agents(PPIs and H2RAs) investigated[62]. All patients who were newly prescribed dabigatran were identified (n = 5041). There were 124 (2.5%) GIB cases, with an incidence rate of GIB of 41.7 cases per 1,000 person-years. PPIs were found to protect against upper GIB. This important finding has recently been echoed by an even larger-scale study involving more than 3 million NOAC users[63], with a consistent beneficial effect of PPIs on upper GIB across various NOACs (dabigatran, rivaroxaban and apixaban).Head-to-head comparisons between different NOACs and their interaction with PPIs would barely be possible in other study designs, given the huge number of study subjects required to ensure statistical power. These drug safety data can be easily ascertained by Big Data analysis of electronic health databases, which would be otherwise difficult in other observational studies or RCTs due to the various limitations previously mentioned, especially if the absolute risk difference is small.
IBD
Precise outcome prediction in IBD remains challenging, as it is a highly heterogeneousdisease with numerous predictive factors. Machine learning algorithms are particularly useful in deriving predictive models, including risk factors[64], disease outcomes[65]and treatment responses[66,67], hence allowing the identification of at-risk individuals who require early aggressive intervention. Today, there is still an unmet need for newer therapeutic agents for IBD, as the long-term efficacy of current options including anti-tumour necrosis factor (anti-TNF) and anti-integrin α4β7are still unsatisfactory. However, the process of new drug discovery for IBD is prolonged and costly, and success is not guaranteed. For instance, mongersen, an antisense oligonucleotide showing a promising effect in a phase II trial in Crohn's disease[68],was prematurely terminated in the phase III program[69]. The results for secukinumab,an anti-IL-17A monoclonal antibody, was also disappointing in moderate to severe Crohn's disease, in which it was less effective and carried higher rates of adverse events compared with placebo[14], despite the potential role of IL-17 in Crohn's disease as suggested by animal models and GWAS. Drug repurposing from Big Data applications helps in this regard, as illustrated by Dudley et al[70]. In that study,computational approaches were used to discover new drugs for IBD in silico by comparing the gene expression profiles from 164 drug compounds to a gene expression signature of IBD from publicly available data obtained from the NCBI Gene Expression Omnibus[70]. A technique, called “signature inversion”[16], was used to identify drugs that can reverse a disease signature (transcriptomic, proteomic, or other surrogate markers of disease activity). Topiramate, an FDA-approved drug for treating epilepsy, was identified to be a potential therapeutic drug in IBD with experimental validation in a mouse model[70]. The potential role of topiramate,however, was later refuted by a retrospective cohort study[71], and no further studies have been conducted.

Table 3 Examples of studies on gastric cancer research by utilization of large healthcare datasets

This list is not exhaustive, but serves to provide a few distinct examples of how Big Data analysis can generate high-quality research outputs in the field of gastroenterology and hepatology. 3V: Volume/velocity/variety; GC: Gastric cancer; SIR: Standardized incidence ratio; H. pylori: Helicobacter pylori;NSAIDs: Non-steroidal anti-inflammatory drugs; PS: Propensity score; PPIs: Proton pump inhibitors; IPTW: Inverse probability of treatment weighting.
As discussed previously, some diseases may not be coded in the electronic database. As an example, the effects of anti-TNF versus vedolizumab on arthralgia in IBD patients were studied using NLP[20]. As the electronic coding of arthralgia is not commonly performed in gastroenterology practices, Cai et al[20]used NLP to directly extract this non-structured information from the narrative electronic medical records,and converted it into a structured variable (joint pain: yes/no) of analysis. Without NLP, simply relying on a diagnosis code may bias any potential positive association towards null. On the other hand, manual review of the electronic medical records demands an intensive input of manpower, and accuracy is also not fully guaranteed.
In a study that involved 827,239 children, antibiotics exposure during pregnancy was found to be associated with an increased risk of very early onset IBD[72]. This study was achieved by merging data from several databases with the unique personal identity number assigned to Swedish residents. One of the databases, the Swedish Medical Birth Register, enabled the identification of child-mother links. This study illustrates the unique role of Big Data applications in investigating childhood exposure that affects disease development in adulthood, which is nearly impossible in the setting of RCT (ethical and resource issue) and other types of observational studies (e.g., recall bias, resource issue).
CRC
CRC is the third most common cancer and the second leading cause of cancer-related death[39]. As a period of 10 years is required for the development of the adenomacarcinoma sequence[73], identification of risk factors of CRC would have been difficult with RCTs. A large number of high-quality research has been conducted based on the NHS, NHSII and HPFS cohorts. Type II diabetes mellitus was associated with a 1.4-fold increase in CRC risk[74]. A positive association between obesity and early-onset CRC also existed among women[75]. Some of the risk factors (e.g., smoking, body mass index, alcohol intake) and protective factors (e.g., physical activity, folate and calcium intake) of CRC were found to be associated with the development of its precursors,adenomas and/or serrated polyps[76]. Among non-metastatic CRC patients, higher coffee[77], calcium[78]and fibre[79]intake were found to be associated with a lower CRCspecific and all-cause mortality.
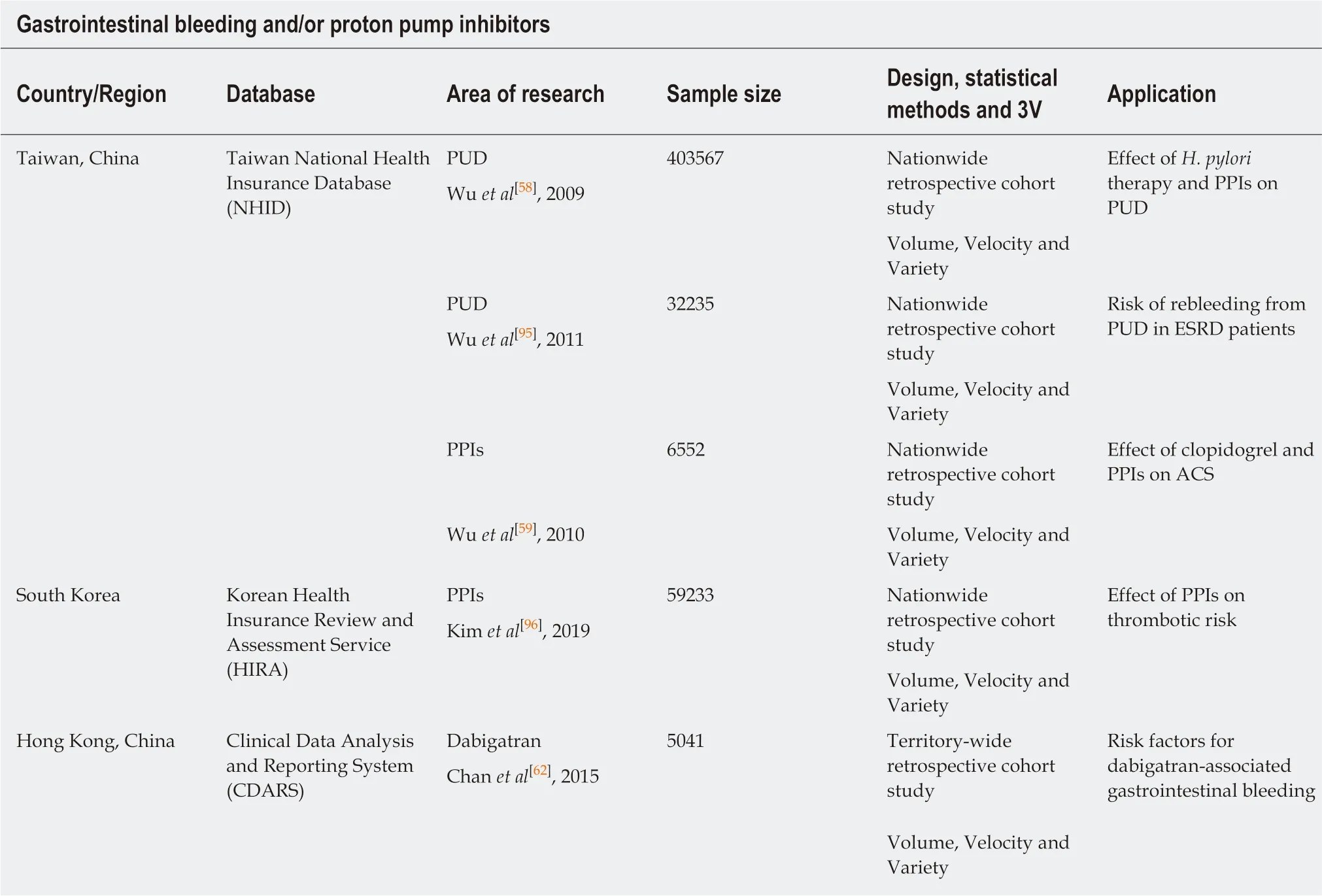
Table 4 Examples of studies on gastrointestinal bleeding and/or proton pump inhibitor research by utilization of large healthcare datasets
Concerning hereditary cancer syndromes, the Dutch Lynch syndrome Registry is one eminent example of the hereditary cancer registries. It was noted that surveillance could reduce CRC-related mortality[80]. However, in a subsequent study involving three countries (the Netherlands, Germany and Finland) with different surveillance policies, a shorter surveillance colonoscopy interval (annually) was not associated with a reduction in CRC when compared with longer intervals (1-2 yearly and 2-3 yearly intervals)[81]. The Dutch polyposis registry is another example that includes adenomatous polyposis coli patients[82].
HCC
Chronic hepatitis B virus (HBV) infection is a major public health threat that results in significant morbidity and mortality[83]. The prevalence of chronic HBV infection was estimated at 3.5% (257 million people) worldwide in 2016. Major complications of chronic HBV infection included HBV reactivation with hepatitis flare[84], cirrhosis and HCC[85,86].
Nucleos(t)ide analogue (NA) therapy was found to be associated with a lower HCC risk among chronic hepatitis B (CHB) patients[87]. This was in line with the finding from an ecologic study showing that NA therapy was associated with a reduction in age-adjusted liver cancer incidence[88]. The beneficial effect of NA was further proven among CHB patients who had undergone liver resection for HCC, in which NA therapy was associated with a lower risk of HCC recurrence[89]. The recent finding that tenofovir was associated with around a 40% reduction in HCC risk compared with entecavir has guided the choice of antiviral therapy in CHB patients at high risk of HCC (e.g., cirrhosis)[90]. Although diabetes mellitus was associated with an increased HCC risk[91], each incremental year increase in metformin use resulted in a 7%reduction in HCC risk for diabetic patients.
The choices of therapeutics drugs for HCC are still currently limited. Big Dataapproaches in drug repurposing have once again shed light on the potential anticancer role of some medications currently approved for other purposes. For example,Chen et al[17]collected publicly available data from HCC studies on HCC-related genes, and 6,100 drug-mediated expression profiles from Connectivity Map, which is a search engine cataloguing the effects of pharmacological compounds on different cell types. By using “signature inversion” approaches, chlorpromazine and trifluoperazine were found to have anti-cancer effects on HCC. Another study using a similar computational approach unveiled the potential anti-HCC effect of prenylamine[18].
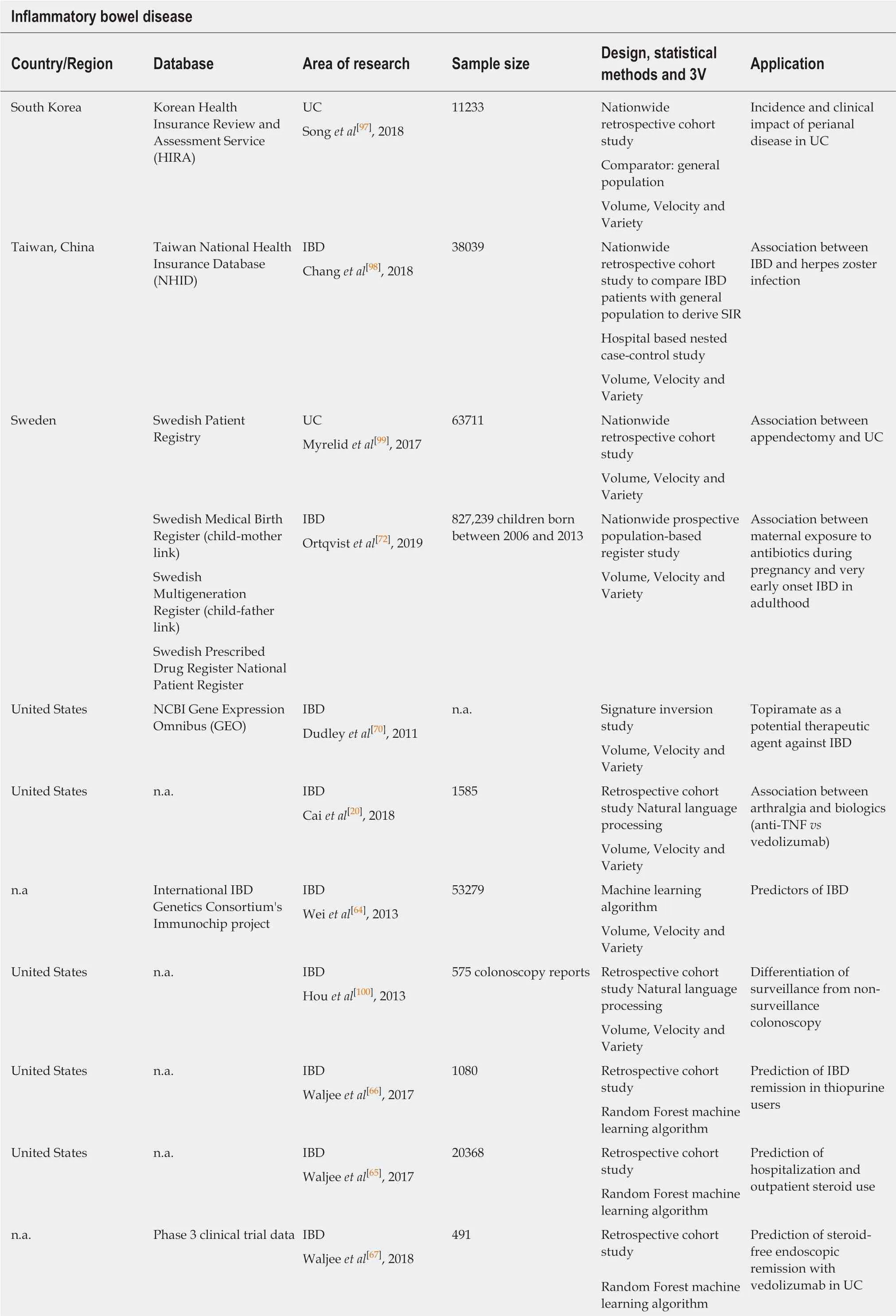
Table 5 Examples of studies on inflammatory bowel disease research by utilization of large healthcare datasets

This list is not exhaustive, but serves to provide a few distinct examples of how Big Data analysis can generate high-quality research outputs in the field of gastroenterology and hepatology. 3V: Volume/velocity/variety; UC: Ulcerative colitis; IBD: Inflammatory bowel disease; SIR: Standardized incidence ratio; anti-TNF: anti-tumour necrosis factor.
FUTURE PERSPECTIVE OF BIG DATA RESEARCH
Clinicians and scientists in the field of gastroenterology and hepatology should aspire to optimize the potential advantage of powerful Big Data in translating routine clinically-collected data into precision medicine, the development of new biomarkers,and therapeutic agents in a relatively short and effective manner for preventing diseases and/or improving patient outcomes. However, some areas are still primitive or under-explored.
Parent-child linkage is one of the examples unique to Big Data analysis. Parental factors could have important bearings on the development of various diseases during childhood. One example is linking racial/ethnic and socioeconomic data from both parents with childhood obesity[92]. As for gastrointestinal and liver diseases, one study showed that maternal use of antibiotics during pregnancy was associated with an increased risk of very early onset IBD[72]. One possible mechanism is via the alteration of the gut microbiome[93]. However, the unavailability of direct linkage is still a major issue that can only be partly addressed by indirect inference, such as a probabilistic linkage of maternal and baby healthcare characteristics[94]. It is therefore imperative to have a database system that has direct parent-child linkages, of which many of the currently existing electronic databases are still devoid.
Drug safety is another field that could benefit from Big Data research. First,preclinical computational exclusion of potentially toxic drugs will improve patient safety while reducing the delay in drug discovery and expense. Second, the efficiency of post-marketing surveillance on drug toxicities can be enhanced. Concerning the missing data for some important risk factors (e.g., smoking, alcohol intake, body mass index), administering institutions should be aware of the immense potential of Big Data, and take pre-emptive actions to start collecting these data. Although the hypothesis-free approach of Big Data analysis facilitates the discovery of new biomarkers and drugs, the results should still be validated in multi-centres. A network involving multiple centres across nations should be established to foster a centralized, comprehensive collection and validation of data. While patient privacy should be upheld, regulatory mechanisms should be realistically enforced without jeopardizing the conduct of Big Data research.
CONCLUSION
The advent of Big Data analysis in medical research has revolutionized the traditional hypothesis-driven approach. Big Data analysis provides an invaluable opportunity to improve individual and public health. Data fusion of different sources will enable the analysis of health data from different perspectives across different regions. In this era of digitalized healthcare research and resources, manpower and time are no longer hurdles to the production of high-quality clinical studies in a cost-effective manner.With continuous technological advancements, some of the current limitations with Big Data may be further minimized.
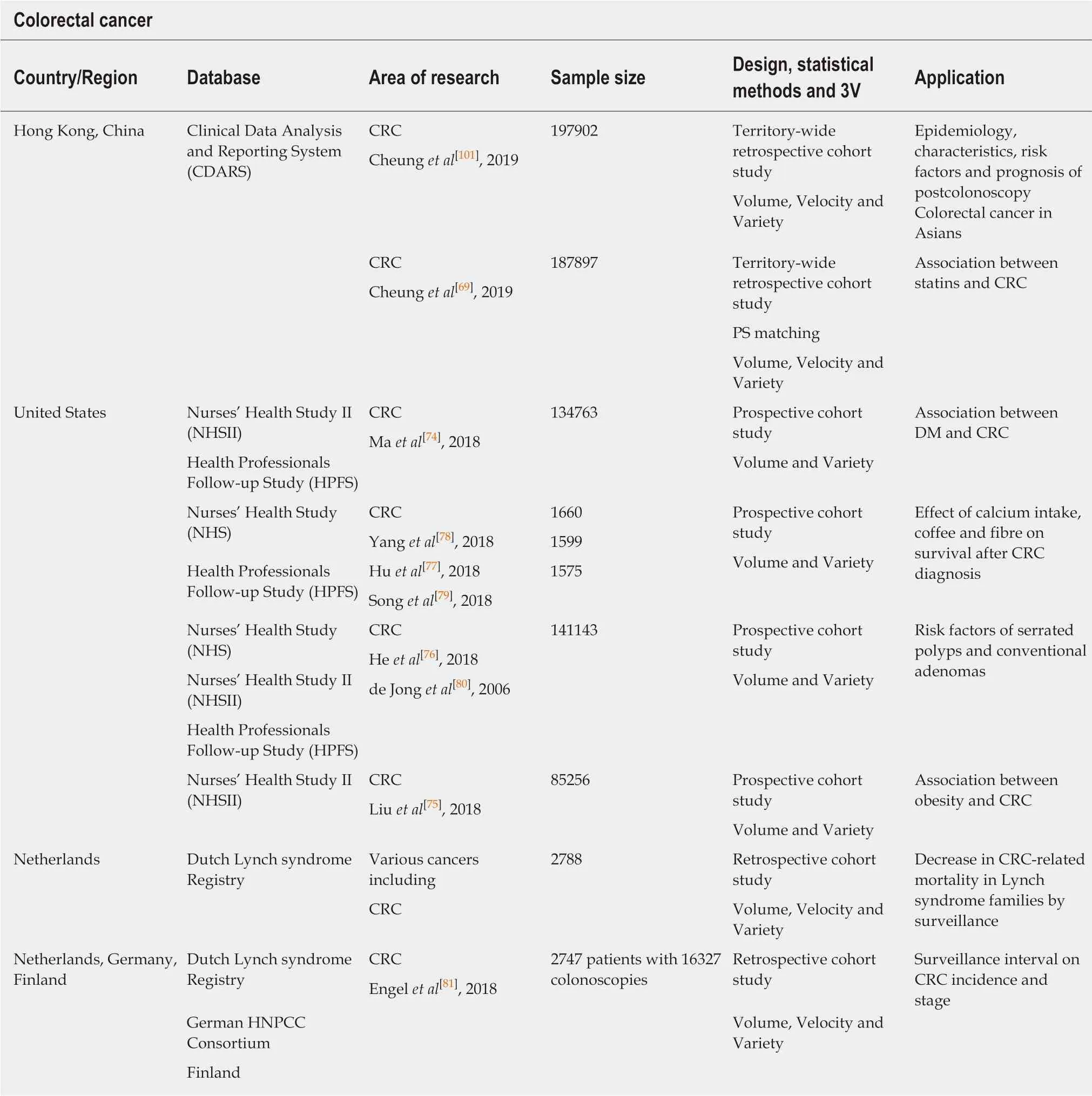
Table 6 Examples of studies on colorectal cancer research by utilization of large healthcare datasets

Table 7 Examples of studies on hepatocellular carcinoma research by utilization of large healthcare datasets
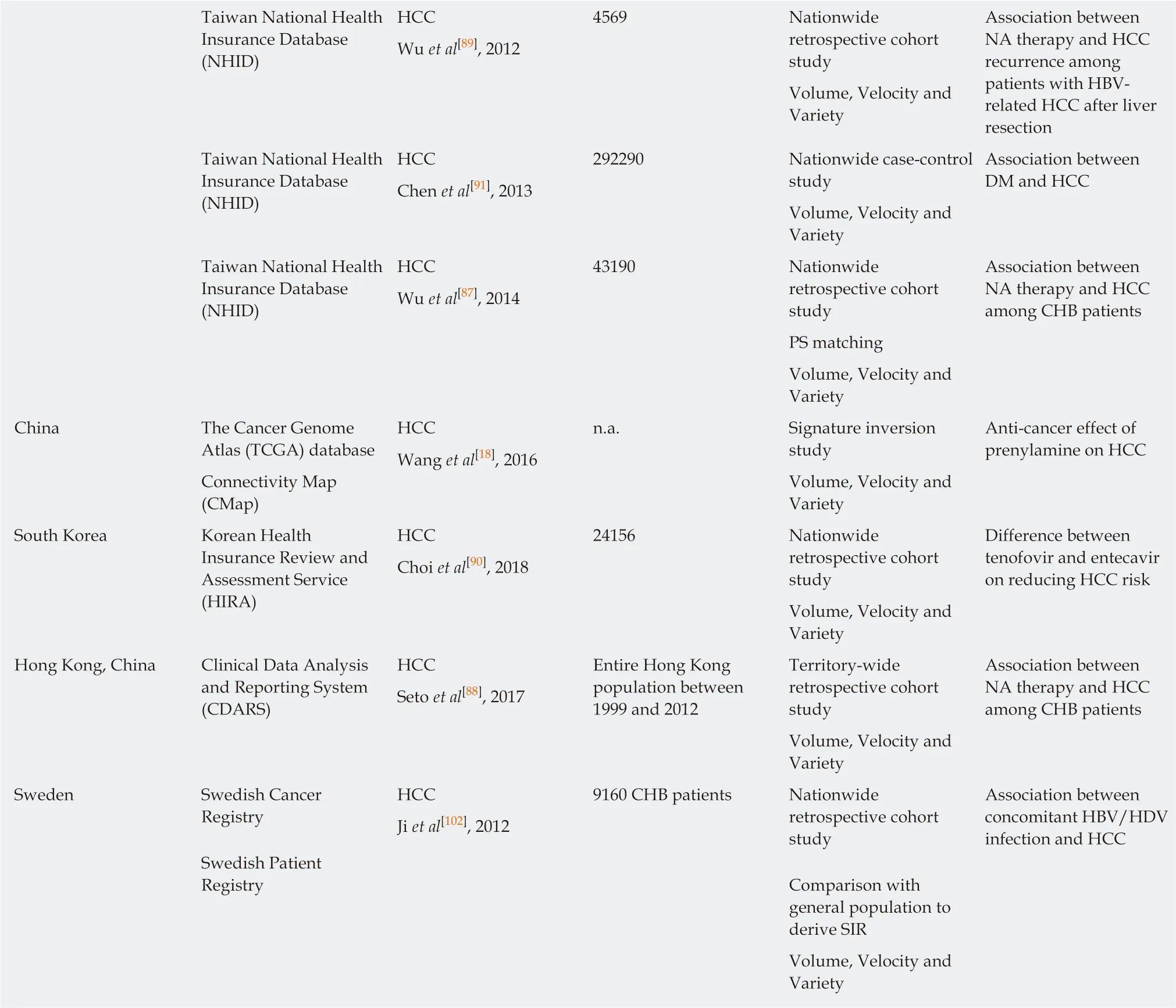
This list is not exhaustive, but serves to provide a few distinct examples of how Big Data analysis can generate high-quality research outputs in the field of gastroenterology and hepatology. 3V: Volume/velocity/variety; HCC: Hepatocellular carcinoma; NA: Nucleos(t)ide analogue; DM: Diabetes mellitus; PS:Propensity score; CHB: Chronic hepatitis B; SIR: Standardized incidence ratio; HDV: Hepatitis D virus.
杂志排行

World Journal of Gastroenterology的其它文章
- Immunotherapy for hepatocelluiar carcinoma:Current and futrure
- Biomarkers and subtypes of deranged lipid mettabolism in non-alcohlic fatty liver disease
- Imaging biomarkers for the treatment of esophageal cancer
- Development and in vitro study of a bi=specific magnetic resonance imaging molecular probe for hepatocellular carcinoma
- Effect of NLRC5 on activation and reversion of hepatic stellate cells by regulating the nuclear factor-κB signaling pathway
- Freeze-dried Si-Ni-San powder can ameliorate high fat diet-induced non-alcoholic fatty liver disease