单目多视角全景视觉感知三维重构技术研究
2019-07-09郭伟青吴小刚汤一平
郭伟青,吴小刚,汤一平
1(浙江工业大学 之江学院,浙江 绍兴 312030) 2(浙江工业大学 信息工程学院,杭州 310023)
1 引 言
基于机器视觉的三维测量和三维重构技术,是一门新兴而实用的技术,可广泛应用于工农业检测、地理勘测、医学诊断、文物复制、模具快速成型、刑侦取证、保安识别、机器人视觉、虚拟现实、动漫游戏、动画制作等领域[1].
基于单目视觉(Monocular Vision)的三维重构是指利用单台摄像机拍摄成像进行三维重构.图像可以使用单视点的单幅或多幅图像,也可以使用多视点的多幅图像[2].单视点成像可通过分析图像二维特征来获取物体深度信息,即X 恢复形状法.该类方法具有简单的设备结构,采用单幅图像或者少量几幅图像即可实现三维几何模型重构,但要求成像及重构的条件比较理想化.多视点成像则在不同图像中根据相关约束条件匹配特征点,根据匹配约束推导出三维空间坐标,实现三维模型重构.该类方法可实现重构过程摄像机自标定,适用于大型三维场景重构,当图像信息较充分时重构效果较好,但运算复杂,且重构时间较长.
Shum等依据用户提供的被测物体约束信息,通过全景成像系统重构出被测物体的三维模型[3],该系统首先为每张图片恢复出摄像机的位置,然后使用有效的几何限定来重构三维几何模型,重构问题通过解线性限定的最小二乘问题来解决.Devevec等将基本几何形体进行参数化,从而实现建筑场景等几何形体的交互式三维建模[3],文献使用单张或少量照片,采用与视点相关的纹理映射来产生渲染效果,模拟出基本模型的几何细节.上述方法仅适用于由平面或基本几何形状构成的物体或场景.
Lipson等采用手工绘制图像进行三维实体重构[4].文献通过识别和计算几何规律来得到相关的三维外形结构,适合于线框型物体重构几何模型.由于轮廓内部的不确定性,算法无法识别一些重要特征,易产生一定程度的变形,且该方法在处理曲线曲面型物体时会产生较大的误差.
基于单目视觉的三维重建,一般采用以下几种方法:
基于知识库数据三维重建方法.Blanz等使用人头模型数据库,从单幅图像中恢复出人脸模型[5,6],文献[5]通过转换示例的形状和纹理成为一个向量空间表示,导出一个形变的脸部模型,新的脸部及表情通过原型的线性组合来重构.文献通过计算与数据库中某一脸部模型的密集点的对应来识别新模型,但是该方法依赖于模型数据库.
基于深度估计的三维重建方法.研究者采用传统图像编辑方法设定图像中各像素点的深度值[7,8].Chen Y[8]等在图像编辑系统中,采用参数优化、深度赋值使图片作自由形状复制,但是其深度值依赖于操作者的经验.Saxena等对单张场景图片的深度估计及模型重建做了系列的研究[9,10],文献[9]使用一种具有图像深度线索和不同区块之间关系模型的MRF方法表示系列参数,用于获取不同区块的三维位置和方向,算法优点是单图像线索可提供大量几何信息进行深度和形状检测,而不需要多幅图像的线索去推出深度值,但该方法在物体或场景识别中会出错.
基于表面法向量局部约束条件的三维重建方法.文献通过用户交互方式,给出图像中特征点的对应法向,得到物体曲面的几何形状估计[11,12].文献[11]根据用户给出的一些局部场景的约束,如曲面位置、法向、轮廓等,得到平滑且符合约束的三维曲面.通过交互操作,对添加的约束条件实时修改模型.该方法可重构出自由形状的曲面,曲面法向相对于深度估计更易交互指定,但只能重构图片中可见的曲面,在边界附近会产生失真.
基于图像几何分类的三维模型重构.通过对图像进行几何分类、分割、区域标识来进行三维模型重构[13,14].文献[14]按几何分类对图像做标记,用于描述图像区域的三维场景定位,通过颜色、纹理、透视等线索确认几何标记.不同线索提供区域不同类型的信息,识别能力强.但由于阴影反射等因素会混淆算法的执行效果.文献[15,16]使用单目全景成像一次获取物体表面多视图,对多视图区域进行切割,依据多视图的几何约束、纹理颜色约束等得到物体表面轮廓信息,因为镜面数的限制,该方法存在遮挡和失真现象,在处理较复杂物体时易出现形状的变形.文献[17,18]提出了基于双曲镜面单目全景成像的管道内壁三维检测及重构方法.对管道横断面进行全景扫描,获取管道切面全景扫描图像,根据标定结果解析出管道内壁的三维信息.该方法在处理非均匀截面采样点数据时易出现形状的失真和不稳定.
本文提出了一种基于单目多视角视图的轮廓体素极坐标遍历算法用于真实脚型的三维重构.使用一种以物为中心的单目全景视觉传感器获取多个不同视角的被测物体全景图像,单目多视角成像克服了系统中相机的颜色系统和内外参数很难保持一致的问题,减少了硬件使用成本,同时降低了被测物体立体图像匹配复杂度,增加了实时性;采用Otsu算法对图像进行分割,图像数据的取值范围只有前景和背景区分,降低了运算复杂度;通过轮廓体素极坐标遍历得到物体的三维点云数据是一种明确、不含二义性的信息,具有较好的鲁棒性,在实际系统应用中验证了本文方法的有效性.
2 以物为中心的单目多视角全景视觉传感器
为同步、实时、全方位得到被测对象整体表面信息,我们设计了由平面镜、折反射镜、光源及高清CMOS相机组成的单目全景立体成像装置,采用摄像机在成像孔处拍摄,实时同步获取7个不同方位摄取的被测物体表面成像,实现以被测物体为观察中心的全方位成像用于三维重构,其原理如图1所示.

图1 单目多视角全景成像装置Fig.1 Monocular multi-view panoramic imaging equipment
其实现方法为:在相机成像范围区域内配置6枚平面镜构成一个斗型镜腔,反射面朝向镜腔内部,被测物体表面光线通过6枚平面镜反射,再经反射镜两次改变光路方向,最终投影于相机成像平面上的不同区域,物体在相机成像平面上的多个影像,构成单目多视角全景立体成像.该装置一次成像即能获取7个不同方位摄取的物体多视图,且该7张多视图具有相同的相机参数和统一的颜色系统.
单目多视角全景视觉系统主要由摄像机、反射镜和斗型镜腔组成.斗型镜腔由6面等腰梯形镜面构成,镜腔各组成镜面呈上小下大朝向腔体内侧放置;摄像机光轴与成像装置反射镜I夹角为45°,反射镜I与反射镜II互成90°放置,反射镜II与斗型镜腔的轴心成45°放置.
成像镜头入射光线由腔内直射光线和腔内镜面反射光线经反射镜II->反射镜I折反射构成.通过腔内的直射光线依次经反射镜II->反射镜I反射投影于成像平面中心区域;腔内镜面反射光线经反射镜II->反射镜I反射投影于成像平面周边区域.利用镜面折反射成像原理得到被测物体多个视角成像.因此,斗型镜腔可视为存在7个透视投影点,即:1个真实相机投影点及6个虚拟相机投影点,对应的成像分别为俯、主、左、后、右、辅助1和辅助2等7个视图.
单目全景视觉装置从成像效果上,等同于配备了7台内外参数统一,且颜色系统保持一致的摄像机,各摄像机坐标之间位置固定且成一定的角度.为减少来自成像系统的外部干扰及环境多义性对成像的影响,该单目立体视觉装置还设计了一个外壳及内部光源,与外界相对屏蔽.
3 基于轮廓体素极坐标遍历的三维重构算法
利用上述以物为中心的视觉传感器一次成像可以得到被测物体多个视角的图像.根据获得的多个不同视图之间的空间几何关系,设计了一种轮廓体素极坐标遍历算法获取物体表面三维型值点数据.
3.1 三维型值点获取的原理
对带有颜色信息的被测物体表面点云数据,我们用高斯极坐标表示为(α,β,r,R,G,B),将被测物体中心点作为高斯极坐标的原点,记为O,拍摄主视图与左右视图的摄像机的光轴分别与世界坐标系的X轴和Y轴重合;拍摄俯视图的相机光轴与世界坐标系Z轴重合.被测物体表面任一点A的世界坐标为(x,y,z),A点到O的距离为r,OA连线投影于XOY平面,X轴与该投影线的夹角称为方位角α,Z轴与OA连线的夹角称为入射角β[15],如图2所示,R,G,B为A点的颜色分量值.
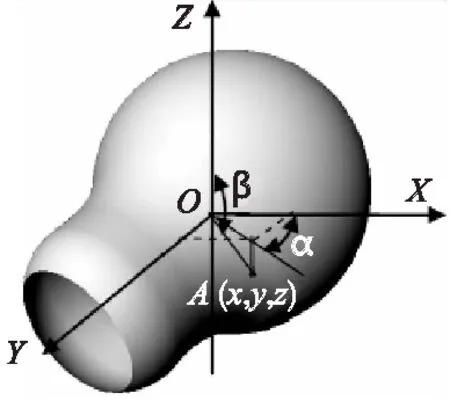
图2 被重构物体在世界坐标系中的位置示意图Fig.2 Location image of reconstructed object in the world coordinate system
根据以上定义的变量,以第一象限为例,设物体表面任一型值点A,其世界坐标记为 (x,y,z),则A在XOY平面、XOZ平面、YOZ平面上的投影点分别对应俯视图中的坐标点(x,y)、主视图中的坐标点(x,z)及左右视图中的坐标点(y,z);辅助镜面位于第一、第二象限,与X轴夹角分别为-θ和θ.根据以上约束关系,以方位角α、入射角β及距离r为变量,本文采用遍历高斯极坐标的方式,遍历整个被测物体表面,获取被测物体表面型值点数据.
遍历整个被测物体表面时,XOZ平面沿着OZ轴对被测物体进行遍历切分,XOY平面沿着OY轴对其进行遍历切分,分别按照方位角α从 0度到90度、90度到180度、180度到270度、270度到360度的顺序,以及入射角β从-90度到90度顺序,依次遍历.不同的方位角对应不同的约束条件,各方位角范围和各视图间的约束关系如表1所示.
表1α的范围与各视图间的约束关系
Table 1 Constraints between theαscope and the views

α的范围0°~90°90°~180°180°~270°270°~360°变量α与各视图间的约束关系主视图右半部分与左视图左半部分以及辅助视图1(参照俯视图第一象限)主视图左半部分与右视图右半部分以及辅助视图2(参照俯视图第二象限)右视图左半部分与后视图右半部分(参照俯视图第三象限)后视图左半部分与左视图右半部分(参照俯视图第四象限)
各视图中物体表面轮廓信息可采用边缘检测算法获得,当α=0°、90°、180°、270°时,可直接计算获取物体的轮廓体素,其余角度则无法直接获取,需要通过遍历算法查找物体表面体素.
本文对物体表面轮廓信息用离散体素来表示,物体经入射角和方位角的遍历,被均匀切分成一个个独立的小立方体空间,依据长、宽、高几何约束关系限定被测物体表面离散体素的几何范围,对方位角α从 0度到360度,入射角β从-90度到90度,依次遍历,计算出在各方位角α和各入射角β时的最长估算极半径Re-out与最短估算极半径Re-in,形成系列可视化几何立方体,定义为最小包围体,其外形大小为Δβ×Δα×(Re-out-Re-in).采用空间雕刻算法在Re-out与Re-in之间查找被测物体表面体素,该方法基于光一致性约束原则,如果一个体素属于被测物体表面体素,则在所有可见该体素的视图上投影像素的亮度值应相同.
本文采用比较体素投影的亮度值方差和阈值设定来判定光一致性,用Pro(v)表示物体表面体素v投影在K幅相关约束视图上的像素集,Con(v)表示像素集Pro(v)的光一致性函数,设定阈值为λ,Lm(m∈{1,2,…,K})为像素集v在相关约束视图m上的投影亮度值,计算亮度值方差用公式(1):
(1)
计算物体表面体素v的光一致性用公式(2):
Con(v)=σ-λ
(2)
若Con(v)<0,判定该像素满足光一致性条件,则该体素为被测物体表面体素.
3.2 图像预处理及三维型值点获取的算法流程
3.2.1 图像预处理
Step 1.单目多视角全景视觉传感器获取被测物体的一次成像(包括俯视图、主、后、左、右视图及辅助视图);
Step 2.对原始成像进行图像分割,以镜腔的边缘作为切割基准,按照一定的比例对原始图像进行以各个镜面为基准的切割,获得以每个镜面为切割单位的各个视图;
Step 3.采用阈值分割将各个视图的前景从背景中分离出来,获得二值化图;
Step 4.对二值化图进行归一化处理,通过等比例的旋转和缩放将主视图与俯视图进行宽相等的归一化,以这两个视图为基准,再对其他视图进行归一化操作,两个辅助视图根据固定的镜面角度参数与侧视图进行归一化,得到不同视角的七张视图.
3.2.2 三维型值点获取流程
Step 1.根据表1对不同的方位角α进行划分,将被测物体划分成四个部分;
Step 2.初始设定入射角β和方位角α,使得初始方位角∠α=0°,初始入射角∠β=-90°,设置每次增量为1°;
Step 3.根据表1确定在α范围内与之相应的视图遍历区域;
Step 4.用公式(3)、公式(4)计算出在当前方位角α和当前入射角β时的最长估算极半径Re-out和最短估算极半径Re-in,从而获得被测物体表面点的一个包围体Δβ×Δα×(Re-out-Re-in);
(3)
(4)
xe、ye、ze是当方位角为α入射角为β时所遍历视图的边缘点坐标值,遍历视图范围由表1确定;
Step 5.若方位角α处于第一、第二象限,将第一、第二象限划分为四个区域,分别为(0°,90°-θ),(90°-θ,90°),(90°,180°-θ),(180°-θ,180°).从最长估算极半径Re-out开始遍历查找被测物体表面体素ve,利用公式(5)计算出遍历点在辅助镜面中的坐标值.
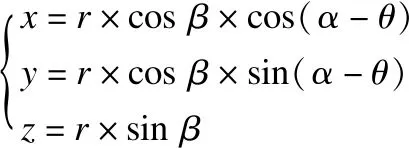
(5)
式中,θ为辅助镜面与x轴的夹角.由公式(2)进行光一致性检测,在(0°,90°-θ)区间采用左视图与辅助镜面1中的视图进行光一致性判断;依此类推,在(90°-θ,90°)区间采用辅助镜面1中的视图与主视图,在(90°,180°-θ)区间采用主视图与辅助镜面2中的视图,在(180°-θ,180°)区间采用辅助镜面2中的视图与右视图进行判断,对于匹配成功的点则跳转到Step7,否则继续遍历;
Step 6.若方位角α处于第三、第四象限,以最长估算极半径Re-out为起始位置向内遍历查找被测物体表面点ve,若某点在表1对应的视图中可见,且符合光一致性约束,则记录该点信息为(α,β,r);若遍历的最小包围体内所有点均不满足条件,则按公式(4)计算最小值,将其作为候选体素点ve,记为(α,β,r);
Step 7.Step 5和Step 6中所获取的点(α,β,r),采用公式(6)计算出对应的三维点坐标(x,y,z),保存于文件用于后续测试;

(6)
Step 8.计算β←β+Δβ,判断是否满足β≤ 90°,若满足,则跳转到Step 4执行;
Step 9.计算α←α+Δα,判断是否满足α<360°,若满足,令β=-90°,跳转到Step 3执行;
Step 10.三维点云获取完成.
4 实验测试
为了验证上述轮廓体素极坐标遍历算法,本文采用真人脚型进行实验测试.
采用单目全景成像装置一次性同步获取7个视角被测脚部全景视图,图3为镜腔实物及被测脚部在镜腔中的成像.
4.1 脚型图像的预处理
脚型图像的预处理主要包括多视角全景图像分割、图像的灰度化、二值化以及图像的归一化处理.
4.1.1 图像的分割
通过图像分割将图5切分成7个不同视角的图片,用于获取脚型的7个轮廓的信息.图像分割调用JDK的图像分割函数,为了避免过分割,将脚图中镜腔的边缘作为分割的依据,在切割左辅助视图与右辅助视图时,需将全景图分别旋转-θ与θ角度,实际系统中θ取值根据需要设定.

图3 镜腔及镜腔全景成像Fig.3 Image of the mirror cavity and panoramic imaging
4.1.2 图像的灰度化处理
图片任何一个像素点具有RGB三个颜色属性,而灰度化处理通过参数转换使得R=G=B,将原来的彩色表示成一种灰度颜色.图像像素由三个字节处理成一个字节表示,可提高图像的处理速度.图像中各像素点灰度值由加权平均法计算获取,其计算公式如公式(7)所示:
f(x,y)=0.30*R(x,y)+0.59*G(x,y)+0.11*B(x,y)
(7)
运算后获得灰度图,该灰度图中各像素的灰度值作为亮度值参与物体表面光一致性判断.
4.1.3 图像的二值化处理
在初始分割中得到的7张视图中,图像背景会干扰各个视图的后续操作,需要做前景的提取.由于在拍摄装置中将背景设置为黑色,所以被测物体成像颜色与装置中背景的颜色有较大差异,本文使用阈值法进行分割,当像素灰度值>阈值时设为白色,当像素灰度值<=阈值时设为黑色,经过遍历处理获得被测物体初始二值化图.
4.1.4 图像的降噪
初始二值化图不可避免地存在噪声,图像前景有许多黑点,即丢失的前景部分,背景有许多白点,即多余的背景部分.因此需进一步消除背景中多余信息,修复前景丢失的信息,排除噪声对后续的干扰.
由于前景主要为白色,而噪声区域普遍较小,通过深度优先遍历,计算各个白色连通块的面积,消除较小的白色连通块,留下最大白色连通块,初步消除背景区域的噪声.然后用同样方式消除较小的黑色连通块,留下最大黑色连通块,初步修复前景区域丢失的信息.采用膨胀和腐蚀算法,对二值化图进行后续降噪.
4.1.5 图像的归一化处理
以俯视图为基准,将7张视图进行旋转和等比例缩放,使之符合约束关系:左、右视图的长与俯视图的长保持一致,主、后视图的宽与俯视图的宽保持一致,左、右辅助视图的长与俯视图上的投影部分相对应.
根据装置镜腔的几何关系,确定脚部重心在各个视图中的位置,可获得统一的多视角图像重心.将得到的二值化图统一转化为500*500像素的图像,便于三维型值点的提取.图4(a)-图4(g)为经过预处理获取的7视图的二值化图,图4(h)-图4(n)为经过预处理获取的7视图的灰度图.
4.2 型值点数据的获取及三维重构
在三维型值点数据的获取过程中,为了便于点匹配数据处理,首先将二值化图像转化为布尔类型的二维数组.点匹配过程采用了高斯极坐标遍历,需要确定脚型表面体素的极半径R的值,算法中通过各视图的边界检测来获取R的取值范围,通过对入射角β和方位角α的遍历,在R取值范围内从最短估算距离到最长估算距离依次进行点匹配,获取脚型各个表面体素.
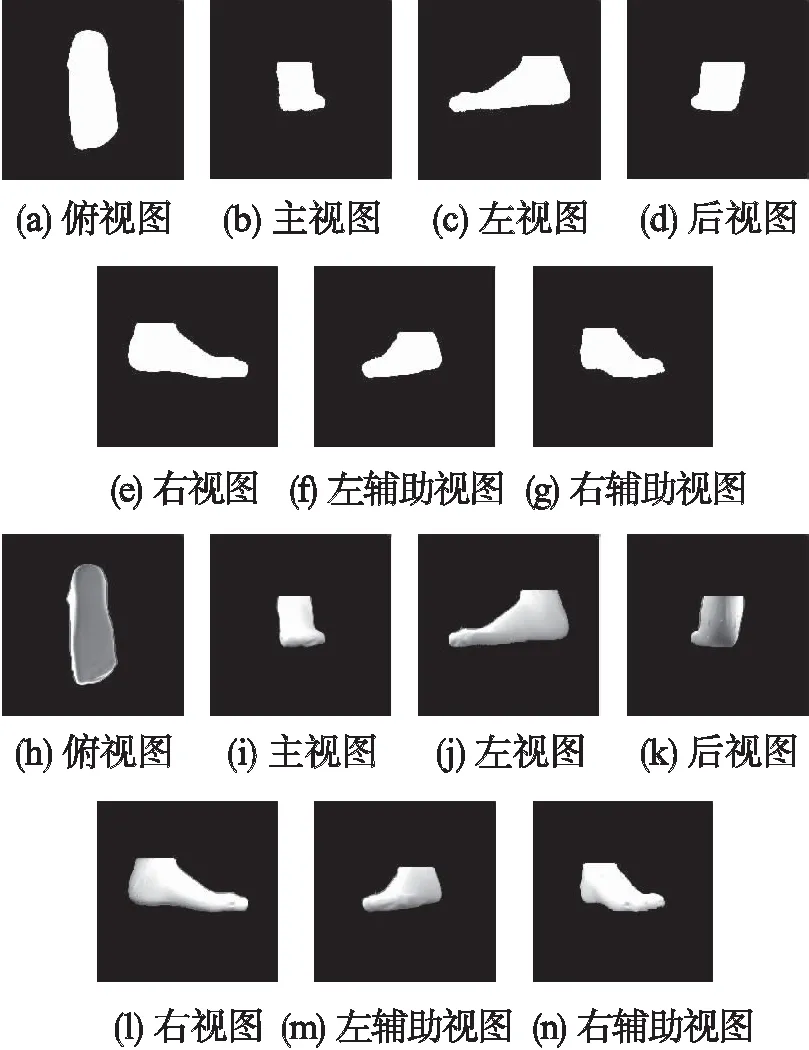
图4 预处理获取的7视图的二值化图(a-g)和灰度图(h-n)Fig.4 Binary images(a-g)and grey images(h-n)of the 7 views obtained by preprocessing
图5为采用本文所述轮廓体素极坐标遍历法得到的脚型三维点云重构图.

图5 被重构脚型的三维点云显示Fig.5 Three-dimensional point cloud displays of the reconstructed foot
4.3 误差测试
为了对重构误差进行分析,本文通过对被测物体的投影与原始分割进行比较,得出误差数据.
首先计算点云数据的投影,其过程如下:
点云数据中每个点(x,y,z),通过计算实现点云数据在高斯坐标系内的旋转.
如某点以Z轴为中心旋转k度:
Step 1.用t=arctan(y/x)求得该点在XOY平面上的角度;
Step 2.使t=t+k,得出旋转后的角度;
Step 3.令R= sqrt(x*x+y*y),求得该点在平面XOY上的投影与原点O的距离;
Step 4.用x′=R*cos(t)求得新的x坐标,y′ =R*sin(t)求得新的y坐标;
Step 5.计算完成.旋转后的坐标为(x′,y′,z).
同理,同样方法可完成以Y轴为中心以及以X轴为中心的旋转.
要获得相应视图的投影,则可将对应的面旋转至Z轴正方向,然后根据点的x,y坐标映射到投影缓冲区.表2 为不同视图的原始分割和投影图.
表2 不同视图的原始分割和投影
Table 2 Original segmentation and projection of different views

序号视图原始分割投影1俯视图2主视图3左视图4后视图5右视图6辅助视图17辅助视图2
误差测试方法1为通过膨胀腐蚀进行闭运算,将投影图中的空洞填充,然后利用得到的图与原始分割图按照同一中心点重叠,分别统计其共同区域、仅原图存在区域、仅投影存在区域,重叠图为表3中所示.统计各区域像素点,按照Max{仅原图存在区域像素点,仅投影存在区域像素点}/共同区域像素点,计算误差率,数据见表3.
误差测试方法2为比较投影和原视图各方向上的截线长度.利用表2中列出的原始分割和投影,以中心点为基准,计算投影各个角度上通过中心点的截线长,同时也计算原始分割各个角度上通过中心点的截线长.对每个视图方向的投影和原始分割的每个角度,计算误差率|Ws-Wo|/Wo,Ws为当前投影在当前角度下的截线长,Wo为当前原始分割在当前角度下的截线长.对180个方向上的误差求平均值作为最后该视图方向上的平均误差.
计算通过中心点每个方向上的截线长.遍历像素点,根据像素点相对于中心点的(x,y)值计算角度t= arctan(y/x).按照t的整数部分k分别计算dist[k]k=0,1,2,…,359,表示360个方向的边缘点到中心点的最大距离.
遍历角度[0,180),令length[k] =dist[k] +dist[k+180] 得到角度k上的截线长.按照以上方法计算得到各视图各方向通过中心点的截线长,可求得误差.
表3 原始分割和投影叠加图及数据分析
Table 3 Overlay image of original segmentation and projection with data analysis
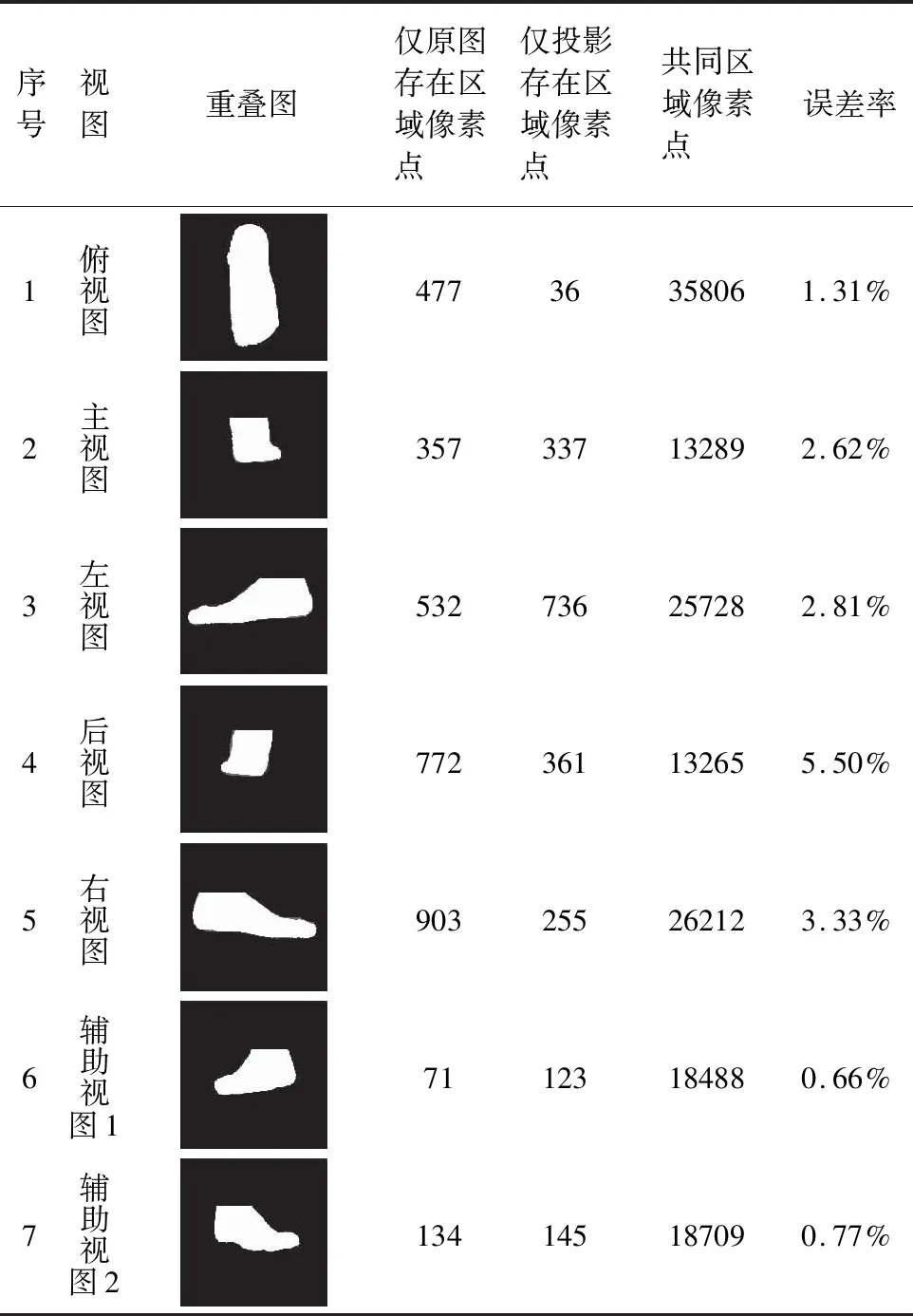
序号视图重叠图仅原图存在区域像素点 仅投影存在区域像素点 共同区域像素点 误差率1俯视图47736358061.31%2主视图357337132892.62%3左视图532736257282.81%4后视图772361132655.50%5右视图903255262123.33%6辅助视图171123184880.66%7辅助视图2134145187090.77%
误差数据如表4所示.
表4 方法2在不同视图上的误差数据
Table 4 Error data of method 2 on different views
整理各角度误差,得到各视图各角度误差数据,如图6(a)所示,其中俯视图与辅助视图1各角度误差率数据图如图6(b)、图6(c)所示.
从上述实验所得的数据进行分析,用两种方法测试误差均显示后视图误差相对较大.理想状态的主后视图轮廓应按镜面垂直对称,因此该误差可通过调整被测物体摆放角度、相机拍摄位置及镜头角度等方法以减少拍摄误差,从而得到较好的成像效果.实验过程中还发现由于物体表面对光线的反射作用,有时在对初始图像二值化处理中产生噪声较大,针对这一影响因素,我们通过调整光源及阈值,获得较好的重构效果.后续需进一步提高装置精度,同时减少环境干扰,以提高前景提取的准确度,降低重构误差.文献[15]和文献[16]提出用单目多视角全景视觉传感器进行脚型测量及重构,采用的方法是基于5视图全景成像,因为镜面数的限制,该方法在重构过程中存在遮挡和失真现象.本文采用单目多视角7视图实现被测物体的三维重构,增加了镜面数,即增加虚拟视点,获取了更多的物体表面信息,实验结果显示较好的重构效果.
5 结束语
针对基于机器视觉的物体三维建模,本文研究了单目折反射成像机理,利用由多个折反射镜面组成的矩形状斗型腔所形成的多视角立体视觉特性,探索以物为中心的全景立体感知理论与方法,实现了一种基于单目多视角成像的轮廓体素极坐标遍历重构方法.通过单目全景立体视觉传感器获取几何物体的全景视图,采用Otsu算法对图像进行分割,提取前景信息,用轮廓体素极坐标遍历得到物体的表面采样点数据.克服了通用多视角成像在三维重构中存在的摄像机的颜色系统和内外参数很难保持一致;在图像特征提取及立体匹配过程中实时性不足且所花计算资源较多;软件系统复杂度过高等问题.该方法计算过程简单,易于软件编程实现,并用真人脚型三维重构实验验证了该方法的有效性.
