ARL中Clean算法的并行化研究
2019-06-24刘慧慧闻萌莎钱慎一吴怀广张伟伟李代祎
刘慧慧 闻萌莎 钱慎一 吴怀广 张伟伟 李代祎
中图分類号:TP301文献标识码:ADOI:10.3969/j.issn.2096-1553.2019.02.012
文章编号:2096-1553(2019)02-0088-07
关键词:ARL;去卷积算法;CUDA;并行计算;Clean算法
Key words:ARL; deconvolution algorithm; CUDA; parallel computing;Clean algorithm
摘要:针对SKA算法参考库ARL中的去卷积算法运行效率低、无法满足海量数据实时处理的问题,提出了CPU和GPU协同工作模式下的并行化Clean算法.该方法将Clean算法中可以并行计算的步骤利用多线程在GPU上并行执行,将无法并行计算的步骤在CPU上串行执行.验证实验结果表明,在数据逐渐增大的过程中,
并行化Clean算法比在CPU上的串行处理运行时间显著减少,当图达到4096像素×4096像素时,可以有10倍的提速.这说明并行化Clean算法在处理海量数据时,能够显著提高运算效率.
Abstract:The deconvolution algorithm in the ARL of the SKA algorithm reference library is inefficient and cannot meet the needs of real-time processing of massive data. The parallelized Clean algorithm in the cooperative working mode of CPU and GPU was proposed. The steps of parallel computing in Clean algorithm were executed in parallel on GPU using multi-threads, and the steps in the Clean algorithm that couldnt be parallelized were executed serially on the CPU. The results showed that the running time of parallel Clean algorithm under CPU and GPU cooperative mode was significantly shorter than that under CPU. When the image size reached 4096×4096, the parallel Clean algorithm GPU cooperative mode could be speeded up by 10 times, which showed that the parallel Clean algorithm could significantly improve the efficiency of operation when dealing with massive data.
0 引言
射电望远镜是观测和研究来自天体的射电波的基本设备,但天线的数量有限,从而导致空间频率覆盖不完整[1],影响最终图像的构建.平方公里阵列SKA(square kilometre array)[2]是国际上建造的最大综合孔径射电望远镜.与现有射电望远镜相比,SKA的灵敏度提高10~100倍,测量速度提高105倍[3].ARL(algorithm reference library)算法参考库是SKA的候选算法库,其中去卷积算法[4]是ARL的一个重要组成,在射电天文成像中起着至关重要的作用.
去卷积算法可以消除图像不完整、图像模糊对观测结果的影响,引发很多学者的关注和研究.在ARL中,去卷积算法采用的是Clean算法.1974年,J.A.Hgbom [5]首次提出了Clean算法,一种非线性去卷积的迭代方法,用以消除旁瓣干扰.该算法虽然消除了旁瓣的干扰,但需要消耗大量的时间,运算效率较低.2004年,S.Bhatnagar等[6]提出了一种用于无线电干涉图像的尺度敏感的反卷积(Asp-Clean)算法,将图像建模为自适应尺度像素的集合,可以更准确地重建非对称结构的天空图像,但是该算法增加了算法复杂性和计算成本,其计算时间是Clean算法的3倍多.2008年,T.J.Cornwell[7]提出了一种Multiscale Clean算法,
该算法
可以更好地处理扩展源,提高图像质量,但是比Clean算法需要的运行时间更长.2011年,U.Rau等[8]在Multiscale Clean算法的基础上,结合Multi-frequency算法,在更高的灵敏度和采样频率的情况下,重建了天空图像,但此算法仍存在运算时间较长、运行效率较低的问题.2016年,L.Zhang等[9]提出自适应环路增益自适应规模Clean(Algas-Clean)算法,该算法可以提供更准确的模型,具有更强的收敛性,比Asp-Clean算法的运算速度快了50%.2017年,J.Cheng 等[10]
为解决传统Clean算法出现的问题,
提出了一种小波Clean算法,该算法对小波滤波器的参数进行了优化,提高了图像质量,但没有缩短运行时间,未提高算法运行效率.目前,大部分学者都是针对提高图像质量进行研究,在运算效率方面研究成果很少.然而,随着SKA项目的实施,海量的天文数据迅速增加,如何有效、快速地处理数据成为当今计算机领域研究的重点,这使去卷积算法运算效率的提高变得刻不容缓.
鉴于此,本文拟通过对Clean算法进行耗时分析,利用多线程来设计算法的CUDA核函数,提出一种基于CPU和GPU协同工作模式的并行化Clean算法,以期提高海量天文数据下的去卷积算法的运算效率.1 Clean算法在ARL中的应用Clean算法 [11]是一种非线性去卷积方法,专门用于处理不完整的射电数据,将其运用于ARL中,可以消除图像中旁瓣(天线方向图通常都有两个或多个瓣,其中辐射强度最大的瓣称为主瓣,其余的瓣称为旁瓣)的影响.若天空亮度分布用I(x,y)表示,其中x,y分别表示点源的横纵坐标,则与之对应的复可见度函数用V(u,v)表示,其中u,v称为空间频率.在uv平面(基线投影所在的平面)中,u指向东,v指向北,其基线如图1所示.
由于SKA中天线数目是固定的,所以uv采样点的数目有限.将uv采样点的分布函数称为采样函数,对采样函数进行傅里叶逆变换可得到脏束,将射电望远镜经过预处理后的数据进行傅里叶逆变换可得到脏图,通过一个迭代过程找到脏图中的最大亮度点及其位置,将上述结果与拟合光束(高斯光束)进行卷积即得到恢复的图像.
式③说明了脏图是真实图像和脏束的卷积.具有旁瓣的脏束称为点扩散函数PSF(point spread function).Clean算法可以从已知的脏图和PSF中得到图像点Ip的一系列位置,其主要计算步骤如下:
1)对采样函数进行傅里叶逆变换,得到脏束;
2)将射电望远镜经过预处理的数据进行傅里叶逆变换得到脏图,找到脏图中的最大值点,并记录该坐标;
3)将脏束的中心点移到这个最大值点的位置上,且使脏束乘以因子γ;
4)从脏图中减去该脏束;
5)重复步骤2)—4),直到剩余圖像的最大值小于给定的噪声水平;
6)对一拟合光束和δ函数(被减去的最大值点的总和及其位置称为δ函数图)进行卷积;
7)将步骤6)的结果加上剩余图像,得到最终的清晰图像.
2 Clean算法的GPU并行化实现
ARL中的Clean算法是基于CPU的,运行时间较长,本文根据GPU并行的特点,利用多线程,设计并实现基于GPU并行化的Clean算法.
2.1 Clean算法的并行化分析
研究表明,去卷积算法在数据处理过程中迭代计算耗时较长,对计算机内存和CPU要求较高.GPU[13]是具有数千个计算核心的大规模并行架构,可以在有限时间内执行多次浮点运算,因此在GPU上并行实现去卷积算法可以大大提升运算速度,节省时间.NVIDIA公司提出了一种并行计算架构CUDA(computer unified device architecture)[14],通过CUDA C编程在GPU上实现并行计算,其运算速度比CPU提高了几倍甚至上百倍[15].
通过对ARL中deconvolution模块的分析可知,在Clean算法的实现过程中,需要进行多次迭代计算,而每次迭代都需要使用上一次迭代的结果,因此无法将Clean算法的整个过程写成内核函数,但可以将其中的部分操作写成内核函数,使其可以在GPU上进行并行计算,以此来提高计算效率,而将无法进行并行计算的操作在CPU上串行执行.
并行处理主要分为任务并行处理和数据并行处理.基于CUDA的组织结构,结合Clean的算法分析,本文将采用数据并行处理方式.并行算法的执行过程从CPU开始,当内核函数被调用时,执行过程转移到GPU设备上.另外,GPU的内存分为全局存储器、常量存储器、共享存储器和寄存器[16].在整个程序中,数据需要被Grid网格中的所有线程访问,因此需要将数据放置在全局存储器中;将在脏图中找到的最大值放入共享存储器,方便存取;每一个点源数据都需要相同的高斯核,将高斯核放置在常量存储器中,以此来加强程序的快速访问.
2.2 Clean算法的并行化实现
Clean算法的并行化实现步骤如下.
1)初始化洁图,并将脏束和脏图作为形参传入.
2)在GPU上调用CUDA编写的dirtyFabs-Max核函数,找到脏图中的最大值点,并记录该点的位置坐标.
3)将脏束的中心点移到这个最大值点的位置上,且使脏束乘以因子γ.
4)在GPU上调用CUDA编写的subPsf核函数,从脏图中减去该脏束.
5)判断剩余图像的最大值是否小于给定的噪声水平,若未满足条件,则继续进行迭代计算;若满足条件,则退出迭代,继续向下执行.
6)对一拟合光束和δ函数进行卷积.
7)将步骤6得到的结果加上剩余图像,得到最终的清晰图像.
8)把GPU上经过处理得到的数据传给CPU并进行图像绘制.
Clean算法的步骤2主要是为了找到脏图的最大值点及其位置,该操作可以采用并行方式进行处理.初始化最大值点,将图像中的每个点与该点进行比较,若图像中的点大于该点的值,则把图像中的点赋值给最大值点.因为找到脏图中最大值点及其位置的操作都是比较操作,可以同时进行,所以能够并行计算.由于ARL中的Clean算法是采用Python语言实现的,因此本文采用PyCUDA来实现Clean算法的并行化.具体实现方式是内核函数采用CUDA C编程,其余部分仍采用Python编程,通过PyCUDA使Python程序可以访问Nivida的 CUDA 并行计算API,从而达到GPU并行的目的.dirtyFabsMax核函数将Blocksize和Gridsize作为相关参数传入,指定网格和线程块的大小,通过计算Blocksize和Gridsize的乘积得出网格中线程的数量,进而指定并行处理多线程运算GPU上创建线程的个数.另外,需要syncthreads函数来保证线程同步,否则由于线程执行具有无序性和异步性,可能会出现元素覆盖的问题,导致运行结果不正确.dirtyFabsMax核函数的伪代码为
Clean算法中的步骤4是从脏图中减去脏束,此操作可以进行并行处理.因为脏图和脏束上的每个点是相互独立的,可以同时进行减法操作,而GPU可以为每一个元素分配一个线程,因此每一个元素的相减操作就可以并行执行,提高了Clean算法的计算效率.编写subPsf核函数用来实现从脏图中减去脏束的操作.因为实验所用的GPU每个线程块最多支持1024个线程,而处理大小为1024像素×1024像素的图像则需要1024×1024个线程,所以需要在一个网格中划分多个线程块来得到1024×1024个线程,函数被调用时的执行配置为<<<1024,1024>>>,这样就可以满足GPU为每一个数据元素分配一个线程.subPsf核函数的伪代码如下:
3 验证实验结果与分析
验证实验所用平台是高性能计算平台,配备有型号为NVIDIA Tesla K80的GPU,内存共128 GB,存储器为512 GB的SSD硬盘和1 TB的SAS高速硬盘,操作系统为CentOS7,使用PyCUDA作为开发语言.
实验的测试数据来源于ARL提供的天文测试数据.
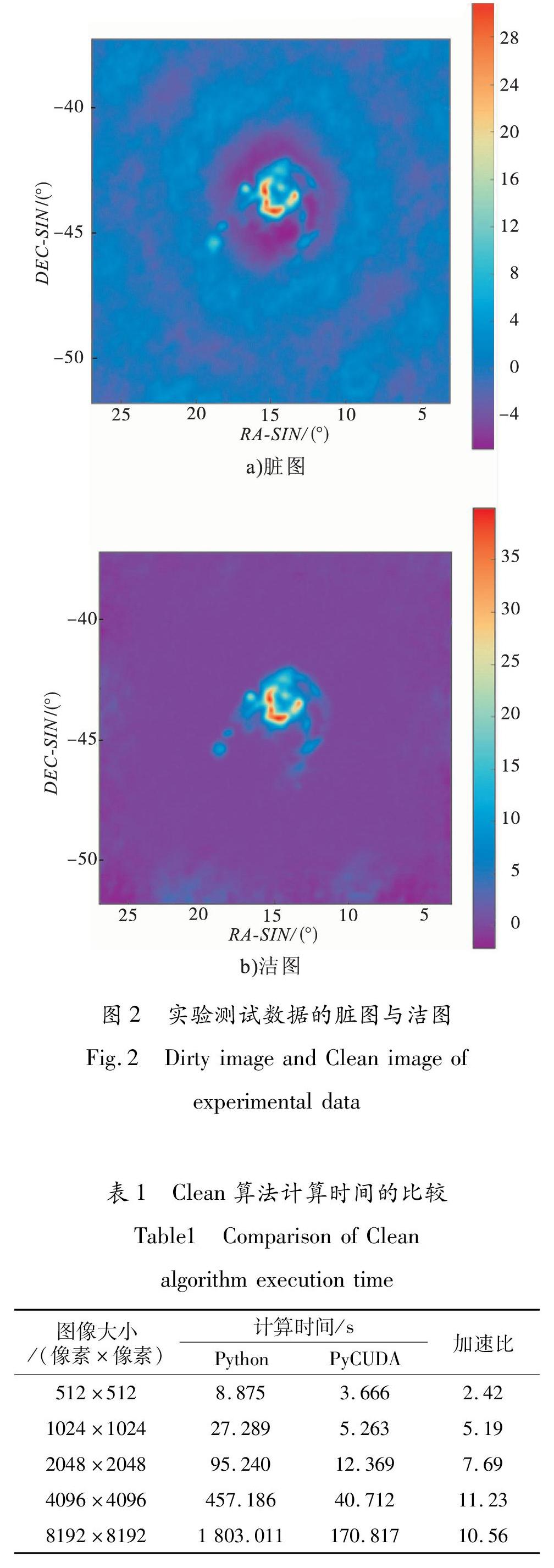
首先将ARL中的数据进行预处理,生成脏图和脏束,然后调用并行化后的Clean算法对脏图进行处理,生成洁图,结果如图2所示.从图2可以看出,脏图中大量的模糊点被清除,洁图更清晰地反映出天空亮度的分布情况.
将ARL中的Clean算法用PyCUDA语言在CPU和GPU协同工作条件下实现,用Python语言在CPU条件下实现,
测试迭代次数均为104次,两个实现过程的计算时间如表1所示,加速比是Clean算法在CPU下的运行时间与在GPU下运行时间的比值.
從表1可以看出,在CPU与GPU协同作用下,用PyCUDA实现的Clean算法对数据的处理速度更快,用时远远小于CPU下用Python实现Clean算法的处理数据时间.当图像大小为512像素×512像素时,数据量较小,只有26×104条左右,加速的效果不是很明显,只有两倍
左右的加速效果.但是当图像大小增大后,特别是大于4096像素×4096像素后,此时的数据量增加到107条以上,加速比急剧增大,加速效果有了明显提升.当图像大小为8192像素×8192像素时,Clean算法在CPU上需要运行30 min才能得出结果,但本文实现的并行算法只需要2 min左右就可以得到结果,可以达到10倍的提速,极大地节省了时间,提高了算法的运行效率.
从并行化实现的Clean算法在不同图像大小下的加速比可以明显看出,当图像大小增大时,加速比增大,在GPU上运行的加速效果非常显著.
4 结论
针对SKA算法参考库ARL中去卷积算法处理海量数据负担过重,时间太长的问题,对ARL中Clean算法进行并行化研究,提出了CPU和GPU
协同工作模式下的并行化Clean算法.将Clean算法中耗时较长的两个部分,即在脏图中找到最大值点和从脏图减去脏束,采用多线程并行处理,并使用syncthreads函数来保证线程同步,无法并行处理的步骤在CPU上串行执行,从而完成对海量数据的处理.验证实验结果表明,处理同样的天文数据时,本文基于GPU并行化的Clean算法与CPU上的串行Clean算法相比,可以达到10倍的提速.
本文使用的是单GPU与CPU协同工作,没有实现算法的最大并行化,因此,今后的工作是将单GPU上的算法移植到多GPU上,以便进一步优化ARL中去卷积算法的并行化.
参考文献:
[1] DABBECH A,FERRARI C,MARY D,et al.Moresane:model reconstruction by synthesis-analysis estimators-a sparse deconvolution algorithm for radio interferometric imaging[J].Astronomy & Astrophysics,2015,576:7.
[2] BROEKEMA P C,VAN NIEUWPOORT R V,BAL H E.The square kilometre array science data processor:Preliminary compute platform design[J].Journal of Instrumentation,2015,10(7):14.
[3] VAN HEERDEN E,KARASTERGIOU A,ROBERTS S J,et al.New approaches for the real-time detection of binary pulsars with the Square Kilometre Array (SKA)[C]∥ General Assembly and Scientific Symposium.Piscataway:IEEE,2014:1-4.
[4] LA CAMERA A,SCHREIBER L,DIOLAITI E,et al.A method for space-variant deblurring with application to adaptive optics imaging in astronomy[J].Astronomy & Astrophysics,2015,579:1.
[5] HGBOM J A.Aperture synthesis with a non-regular distribution of interferometer baselines[J].Astronomy and Astrophysics Supplement Series,1974,15:417.
[6] BHATNAGAR S,CORNWELL T J.Scale sensitive deconvolution of interferometric images-I:adaptive scale pixel (Asp) decomposition[J].Astronomy & Astrophysics,2004,426(2):747.
[7] CORNWELL T J.Multiscale CLEAN deconvo-lution of radio synthesis images[J].IEEE Journal of Selected Topics in Signal Processing,2008,2(5):793.
