图书馆海量网络学术数据的关联检索技术研究
2019-06-19张文晶
张文晶


摘 要: 为解决传统PIT图书馆学术数据检索方法存在索引定位数组数量有限、检索承载额度较低等弊端,设计新型图书馆海量网络学术数据的关联检索技术模型。通过定义数据包类型的方式,判断网络学术数据的衍生结构、设置准确的数据命名机制,完成图书馆海量网络学术数据的结构分析。在此基础上,利用关联数据节点的空间编码,确定严格的检索分级法则、完善数据的关联检索流程,实现新型技术模型的搭建,完成图书馆海量网络学术数据的关联检索技术研究。对比模型应用结果可知,与传统PIT检索方法相比,应用新型关联检索技术模型后,索引定位数组数量提升至5.0×1011 TB以上,检索承载额度也达到预期水平。
关键词: 网络数据; 关联检索; 数据包定义; 衍生结构; 命名机制; 空间编码; 分级法则; 技术模型
中图分类号: TN911?34; TP391 文献标识码: A 文章编号: 1004?373X(2019)11?0181?06
Abstract: The traditional PIT library′s academic data retrieval method has some disadvantages, such as the limited number of index positioning arrays and low retrieval load quota. Therefore, a new association retrieval technology model of library′s massive network academic data is designed. By defining the data packet type, the derivative structure of network academic data is judged, and the accurate data naming mechanism is set up to complete the structure analysis of library′s massive network academic data. On this basis, the spatial coding of the associated data nodes is used to determine the strict retrieval grading rules, improve the process of data association retrieval, realize the construction of new technical model, and complete the association retrieval technology research of library′s massive network academic data. The model application results show that, in comparison with the traditional PIT retrieval method, the number of index positioning arrays obtained by the proposed method can reach up to more than 5.0×1011 TB, and the retrieval load quota can reach the expected level.
Keywords: network data; association retrieval; data packet definition; derivative structure; naming mechanism; spatial coding; hierarchical rule; technical model
0 引 言
关联检索是一项常见的引擎式检索手段,可以通过输入的主要关键词得到准确的检索结果,且在结果页面中会显示一到多个不固定数量的关联搜索词,单击这些搜索词,会得到大量的关联参考结果。这种关联检索手段既能在一定程度上避免关键词的重复输入,也能在海量网络空间中规划出关键词的大致存在范围,对于使用者来说,信息的检索速率得到大幅提升,大大节省了有效信息的传輸消耗时间[1?2]。在现代社会环境中,大多数图书馆都利用Bloom filter技术搭建网络学术信息的检索数据库,并通过MBF的二叉树结构,将这些学术信息传输至各级定位数组,再在PIT传输结构的促进下,将这些数组按照关键词的关联差异性进行按需分配,完成PIT图书馆学术数据检索方法的搭建。但随着科学技术手段的进步,这种传统的数据检索技术开始出现定位数组数量有限、检索承载额度达不到预期水平等问题。为避免上述情况的出现,通过数据衍生结构判断、数据节点空间编码等手段,建立一种新型图书馆海量网络学术数据的关联检索技术模型,并通过对比实验数据的方式,证明该新型技术模型的应用可行性。
1 图书馆海量网络学术数据结构分析
图书馆海量网络学术数据结构分析是新型检测技术模型的搭建基础。在数据包类型定义、数据衍生结构判断等关键环节的支持下,具体搭建方法按如下步骤进行。
1.1 数据包类型定义
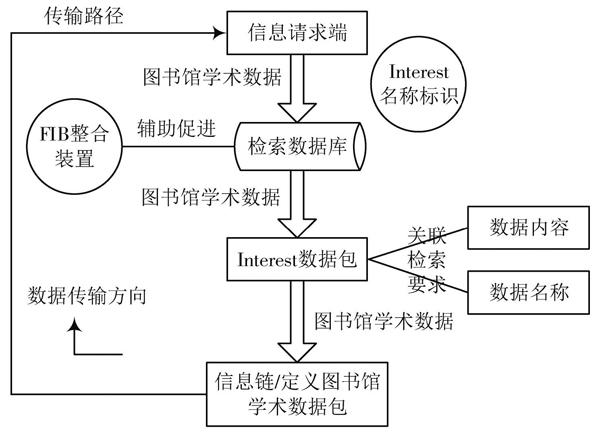
在图书馆海量学术网络中,数据包定义过程由信息请求端发起。信息请求端发送的原始数据包具备明显的Interest名称标识,且在整个数据类型定义过程中,图书馆网络的输入结构会对学术信息内容进行基础判断。当图书馆学术网络处理中心收到检索数据库发出的连接请求后,在FIB整合装置的促进下,这些连接请求中的数据信息会脱离原结构,进入信息请求端的数据定义组织中,并在其中按照一定的物理排列顺序生成全新的Interest数据包[3?4]。当Interest数据包中包含大量的图书馆关联数据时,各项与学术网络相关的数据内容、数据名称等信息会在信息请求端的促进下形成全新的分级Data包,然后再将所有图书馆学术数据按照关联检索要求整合成一条完整的信息链,再通过传输路径将完成数据包类型定义的信息链返回至内容请求端。具体图书馆学术数据包类型定义原理如图1所示。
图1 图书馆学术数据包类型定义原理详解图
1.2 网络学术数据衍生结构判断
图书馆学术数据的衍生结构包含Counting Bloom filter,Dynamic Bloom filter,Spectral Bloom filter,Compressed Bloom filter四种类型。其中,Counting Bloom filter图书馆学术数据的衍生结构可以与所有相邻关联检索节点进行比特数组共享,且隶属于该结构的图书馆学术数据不能进行单独删除操作,必须始终以集合的形式存在。Dynamic Bloom filter图书馆学术数据衍生结构的比特数组位数始终固定,且随着学术网络中数据总量的不断增加,隶属于同一集合的图书馆学术数据必须保持相同的衍生趋势[5]。Spectral Bloom filter图书馆学术数据衍生结构具备较为固定的比特数组检测频率,在与相邻关联检索节点进行信息共享时,这些数组也只能维持二进制的编程形式。Compressed Bloom filter图书馆学术数据衍生结构具备较大的比特数组共享空间,可满足数据包类型定义过程中的弹性压缩要求,使各关联检索节点间的物理距离得到适当缩短。综上可知,比特数据的存在形式是判断图书馆网络学术数据衍生结构的主要依据。表1为四种衍生结构的详细判断依据。
表1 图书馆网络学术数据衍生结构判断方法总结表
1.3 数据命名机制设置
新型关联检索技术模型的数据命名机制主要存在于中心网络层中,且可以在信息传输的过程中对已完成类型定义的数据包进行单元式命名。这种新型的数据命名机制采用URL层次处理方式定义数据包名称,并在丰富的词元组织支持下,界定每个词元的字符串长度。图书馆学术数据在海量传输网络环境中始终保持分层连接的状态,而数据命名机制主要作用于中心网络层及协议流通层[6?7]。当中心网络层传出大量的图书馆学术数据时,由于受到关联检索网络不透明特点的影响,这些数据中的节点词元不能得到清晰显示。为解决上述问题,数据命名机制首先利用词元自身的名称前缀完成图书馆学术数据的聚合处理,再通过IP分类统筹的形式,将这些数据传输至协议流通层进行长久储存。图2为新型关联检索技术模型数据命名机制的运转原理。整合上述操作原理,完成图书馆海量网络学术数据的结构分析。
2 基于数据结构分析的关联检索技术模型搭建
在图书馆海量网络学术数据结构分析的基础上,通过节点的空间编码、分级法则确定等关键环节的运行,实现新型关联检索技术模型的顺利搭建。
图2 数据命名机制运转原理详解图
2.1 关联图书馆海量学术数据节点的空间编码
关联图书馆海量学术数据节点的空间编码以GeoSOT体系作为程序编写的主要原则,且所有待编码的图书馆学术数据都具备固定的节点数值和空间属性参数。在编码形式恒定的条件下,不同的空间属性参数是区分每个图书馆学术数据的唯一法则,参数值越大代表与该参数对应图书馆学术数据的比特数组位数所占存储空间越大,反之则越小[8?9]。在不发生数据命名紊乱情况的前提下,关联图书馆海量学术数据空间编码节点的排列结构如图3所示。
图3 图书馆学术数据空间编码节点排列结构图、
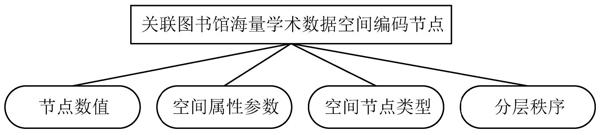
圖书馆学术数据命名机制直接影响空间节点的类型及相关分层秩序。因此,在不发生数据命名紊乱情况的前提下,空间节点的类型、相关分层秩序两项始终保持不变。设某固定图书馆学术数据的节点数值为[l],该节点的空间属性参数为[k],则与该数据相关的空间编码标准可表示为:
式中:[x]代表标准情况下,与该项图书馆学术数据相关的编码因子;[log d]代表编码执行系数;[g]代表空间编码标准的关联项。
2.2 检索分级法则的确定
新型技术模型的检索分级法则具备元数据区分、网络映射属性判断、编码节点创建等主要功能。当关联图书馆海量学术数据节点完成空间编码后,所有数据信息中的元成分都会发生定向改变,且空间属性参数不再是判断图书馆学术数据类型的唯一标准[10?11]。比特数组位数较大的图书馆学术数据会在检索分级法则的促进下,将元数据成分迁移成更加紧凑的结构类型,并以此扩充在单位空间内索引定位数组的数量,解决检索承载额度较低的问题。网络映射属性判断是关联检索技术模型的核心处理功能,随着检索分级法则的逐渐完善,图书馆网络中映射脉络得到有效划分,学术数据的流通速率得到一定程度的促进。编码节点创建是检索分级法则中的核心环节,且随着网络中图书馆学术数据总量的增加,该功能会促进关联检索识别程序的快速运行。图4为检索分级法则的确定原理。
