大数据视角下学习者选课之推荐模型*
2019-06-19
(陕西广播电视大学 计划财务处,陕西 西安 710119)
开放教育选课是其人才培养模式的重要内容,是依据专业特点和培养目标,结合学习者的时间、空间、兴趣和知识面开展的,用以保证学习者自主学习和个性化发展,而实施的内容。这一实施过程,在激发学习者学习兴趣、开阔专业视野、提高文化素质、培养创新能力等方面具有不可替代的作用, 是实现“宽口径、重能力、强素质” 人才培养模式的有效途径。
一、选课推荐
1.大数据的概念
大数据是近年来在信息化应用中的核心焦点,由于其发展迅速,在定义、特征等方面尚未形成公认的、统一的标准。大数据一般是指数据量巨大,不易用常规方法和传统软件处理分析的数据。 对于其特征的认识从最初的“3 V”发展到“4 V”,再到最新的“5 V”, 即数据量( volume)巨大、数据类型( variety)众多、处理速度( velocity)快、价值( value)密度低、真实性( veracity)强。教育领域的大数据广义上指的是在教育教学活动中所有参与者的行为数据,最主要是学习者。为了保证采样数据对母体的完备性,一般要求学习者的采样数量大于2000人,这些数据除了具有大数据的共性以外,还具有情境性、层次性和时效性,数据采样主要来源于各类远程学习平台、考试平台、教学管理系统、图书馆管理系统、一卡通平台、财务管理系统。
大数据不仅意味着数据量的巨大,同时更主要的是其利用数据的视角发生变化,其数据分析对象,趋向于数据母体而非抽样数据,重视个体数据间的相关性而非因果性,特别是当效率与精确性产生冲突时,可以牺牲一定的精确性,强调以数据分析为本,以数据分析结果驱动决策。
2.选课推荐
大数据的应用使推荐过程更加科学,其核心在于各要素相关性数据挖掘模型的建立。数据挖掘建模过程是着眼于解决推荐应用的过程,源于应用需求,终于应用实践。尽管用数据挖掘技术建立仿真模解决的问题各有不同,但从整个的应用流程上来看,其操作内容具有计划性、规范性、可用性。 其中,CRISPDM方法是目前世界上公认的数据挖掘建模的核心方法。
(1)教学理解阶段。在这一阶段通常从学习者的视角设计建模的要求和目标,并将这些目标与大数据挖掘建模的定义相结合。
(2)数据解读阶段。数据解读阶段的主要内容有:数据的样本采集;数据的初始化;研判数据属性;分析数据特征;数据特征统计;数据质量审核;数据补遗。
(3)数据准备阶段。数据准备阶段涵盖了从原始数据集构建最终数据集(将作为建模工具的分析对象)的全部工作。数据准备工作将被重复多次,而且其实施顺序是无序的。
(4)数据整理。以挖掘目标为基准初步分析数据样本与其的相关性和可用性,遴选作为模型输入数据的数据子集,并进一步对这些数据样本进行清理转换,构造衍生变量,并根据模型的需求,格式化数据。
(5)建模。在这一阶段,研判相关的建模方法,通过构建、评估模型,对模型参数进行校准。
(6)评估。以数据分析的视角对数据进行审读,在这一阶段中,我们已经构建了一个或多个高质量的应用仿真模型。
(7)部署。即将模型输出的结果转换为可阅读的文本形式。
二、基于学习者的协同过滤推荐
基于学习者的协同过滤推荐模型的原理为,以所有学习者对课程兴趣的偏好为基础,挖掘与服务对象偏好相似的“邻居”学习者群,一般使用计算“ K-邻居”的算法完成;然后,基于这个“邻居”学习者群的历史偏好数据,为服务对象进行推荐。下图给出了原理图。
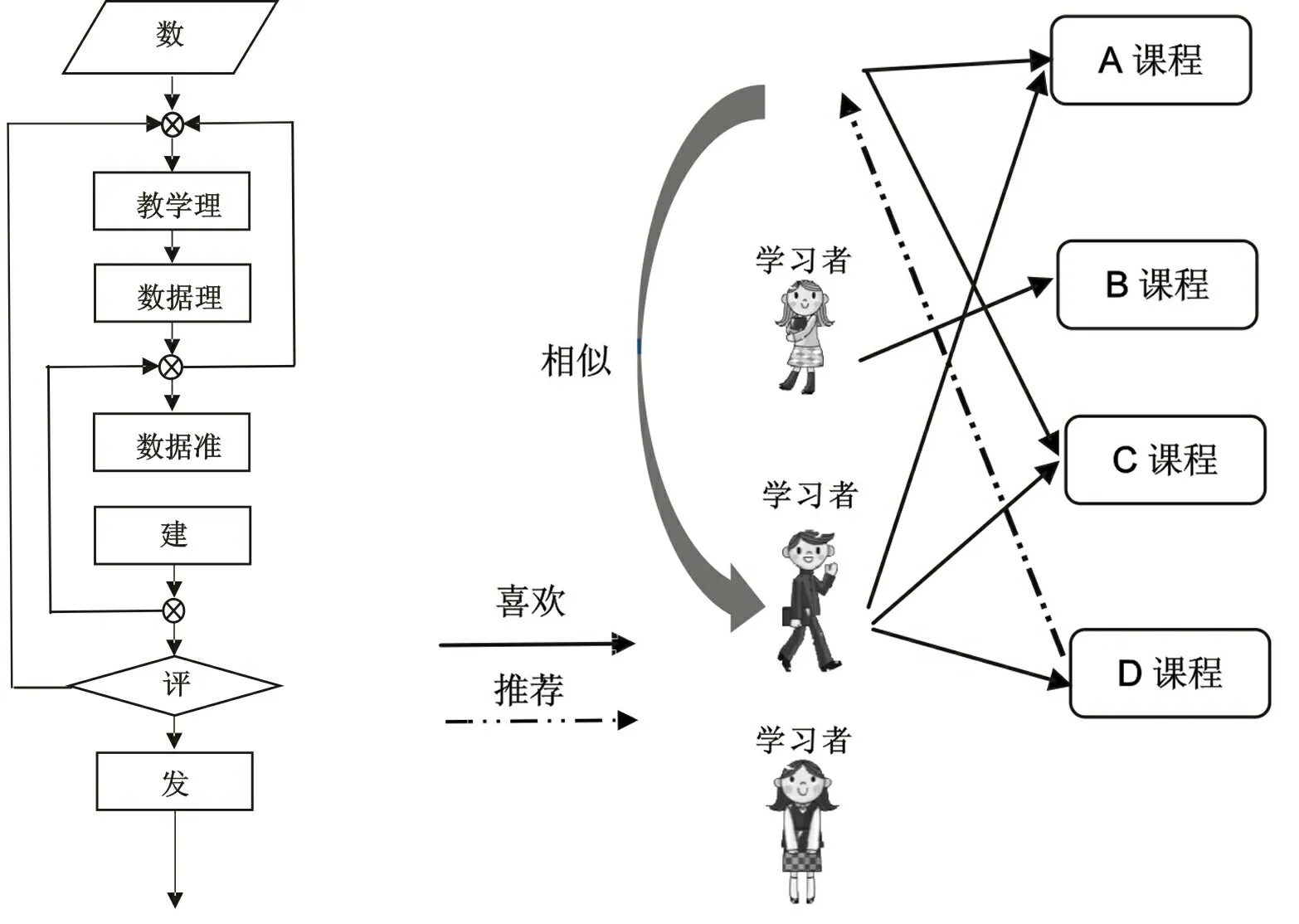
设学习者 A喜欢 A课程, C课程,学习者 B喜欢 B课程,学习者 C喜欢 A课程, C课程和 D课程;从这些学习者的喜好信息中,我们发现学习者 A和学习者 C的喜好是比较类似的,同时学习者 C还喜欢 D课程,那么我们可以推断学习者 A可能也喜欢 D课程,因此可以将 D课程推荐给学习者 A。
基于学习者的协同过滤推荐机制和基于人口统计学的推荐机制都是计算学习者的相似度,都是以学习者的“邻近”群体样本计算推荐的,但它们的核心区别是如何计算学习者的相似度,基于人口统计学处理机制只注重学习者本身的特征,而基于学习者的协同过滤处理机制是在学习者历史偏好数据的基础上进行学习者相似度计算的,它的关键假设是,喜欢类似课程的学习者可能有相同或者相似的喜好。
(一) 基于学习者(Learner-based)的协同过滤推荐算法
基于学习者的协同过滤推荐算法在同类算法中出现的最早,其原理较为简单。这一算法于1992年首次提出并用于电子邮件过滤系统,在1994年被GroupLens引入到新闻过滤中。一直到近年,这一算法还是推荐系统领域中的核心的算法。
当学习者 A需要一个关于他的推荐时,可以在他的朋友中找到和他兴趣相似的学习者集合G,然后将集合G中元素课程属性 A没有的课程推荐给 A, 这就是基于学习者的系统过滤算法。
算法基于两点构成:其一,过滤出与目标学习者兴趣相似的学习者集合;其二,找到这个集合中学习者喜欢的、而目标学习者没接触过的课程推荐给目标学习者。
1. 发现兴趣相似的学习者
一般我们用Jaccard公式或者余弦相似度计算两个学习者之间的相似程度度。设 N(u) 为学习者 u 喜欢的课程集合,N(v) 为学习者 v 喜欢的课程集合,则 u 和 v 的相似度为:
Jaccard公式:
wuv表示学习者 u 与 v 之间的兴趣相似度,N(u)为学习者 u 曾经喜欢过的课程集合, N(v) 为学习者v 曾经喜欢过的课程集合。
余弦相似度:
两个向量间的余弦值可以可以通过下式得到:
a·b=‖a‖ ‖b‖cosθ
A 和B的余弦相似性θ用向量内积形式来表示其大小:
cos(θ)的值域为[-1,1];cos(θ)取值为 -1表示两个向量互为反方向,cos(θ)取值为1表示它们是同向的,cos(θ)取值为0表明它们之间是独立的,而值域中的其他值,则表示相似性的强弱或相异性的强弱。 对于文本匹配而言,文本属性向量A 和B 一般是指文本中的词汇出现频率。余弦相似性,可以被看成是一个比较文件长度的范式。 显然在数据检索时,一个词的频率不能为负数,所以文本的余弦相似性取值区间应该为[0,1]。且词频向量间夹角不能大于90°。
设有4名学习者,分别为: A、B、C、D;他们感兴趣的课程,有5门课程:K1、K2、K3、K4、K5。
根据以上所设,建立兴趣相关矩阵:
这里
得
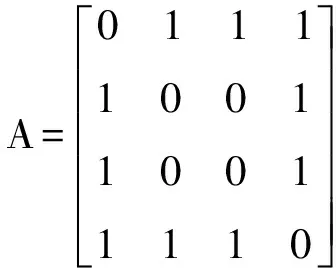
注意,该矩阵仅代表的是similarity的分子部分。下面我们进一步求出该问题的余弦相似度:
至此,计算学习者相似度就大功告成,可以很直观的找到与目标学习者兴趣较相似的学习者。
2. 推荐课程
我们从矩阵中选出与目标学习者 u兴趣最相似的 K个学习者,用集合 S{ u,K}表示,然后,将 S中学习者喜欢的课程全部提取出来,并且除去 u已经喜欢的课程。对于每个候选课程i,学习者 u 对它感兴趣的程度可用下式计算:
其中rvi表示学习者 v 对i的喜欢程度,在本例中全部设为 1,在一些需要学习者进行评分的推荐系统中,则要用学习者评分进行替换。
例如,我们要给学习者 A 推荐课程,设 K = 3 表示3个相似学习者,则这些学习者为:B、C、D,那么他们喜欢过并且 A 没有喜欢过的课程有:c、e,那么分别计算 p(A, c) 和 p(A, e):
根据上述计算结果学习者 A 对 c 和 e 的喜欢程度可能相同,在现实的推荐系统中,我们按得分进行排序,由前向后取前若干个课程即可。
(二)基于课程的协同过滤推荐算法
基于项目的协同过滤算法,简称Item CF,是目前在数据挖掘应用中使用最广泛的算法之一。这一算法现在也用于为学习者推荐那些和他们历史上喜欢过的课程相似的课程。如,该算法会因为你学习过《西方经济学》而给你推荐《国际经济学》课程。
ItemCF主要分为两步:第一步,计算课程之间的相似度;第二步,根据课程的相似度和学习者的历史行为,生成学习者课程需求推荐表。
下图给出一个item CF的例子。学习者user喜欢《C++程序设计》和《算法分析导论》两门课程。然后item CF会为这两门课程分别找到和它们最相似的3门课程,然后根据公式的定义计算学习者对每门课程的感兴趣程度。
Item CF算法,适用于没有频繁更新的课程,数量相对稳定且课程数明显小于学习者数的情况。
三、小结
基于协同过滤模型的算法根据学习者不同的属性特征,按其性别、专业、兴趣爱好归类分群。推荐应用模型可以更加科学与精确的对这些属性信息建立我们关心的关联并计算它们的相似度,从而完成推荐。 大数据下的选课模型,为完全学分制下的学习者选课提供了智能化的支持服务,构建了独立、自主、公平,自由的选课操作,满足了学习者对课程的特性化需求,激发了学习者的学习主动性。
