基于散列查找和多线程调度的快速提取GRIB数据方法
2019-06-17李鸣野
李鸣野
中国辐射防护研究院, 山西 太原 030006
0 引言
现行的GRIB码版本有grib和grib2两种格式,目前,国内外针对GRIB码解码工具有两种,第一种为NCEP(美国国家环境预报中心)开发的wgrib命令行工具,通过命令行来操作GRIB数据,这种方法在国内广泛使用.第二种为ECMWF(欧洲中期天气预报中心)开发的GRIB API,用户使用编程语言通过GRIB API使用get和set键/值操作GRIB数据,这种方法在国内很少使用,国外针对此方法也在不断更新推出新的API,应用也较为局限,尤其是在应急响应领域还未推广.
传统的解码方式在国内是调用wgrib命令行,使用命令行解码,文献[1]中提及使用多线程技术,由其方式为DOS命令行解码,对于解码提升的效率仅为进程调度的优化,且其在解码后需生成二进制中间文件,再对二进制文件进行多线程读写.由于文件I/O操作占用的时间相对于解码来说占用过大,且为两次读写,则其解码耗时理论上是较大的.在文献[2]中提出了并行化程度较高的方式为按段并行化解GRIB码,其相较于文献[1]中的方法在解码过程中效率有提升,但仍需进行二进制解码后内容拼接,对系统资源的开销较大.在文献[3]和文献[4]中提出了对于GRIB API的使用,调研文献[4]发表时的GRIB API可知由于受当时API版本的局限,其同样需要生成二进制中间文件再进行提取.本文提出的HP算法是基于第二种解码工具GRIB API的使用散列查找和多线程调度的快速解码方法.
1 主要算法
1.1 HP算法
分析传统的解码方式可知,影响解码效率的最大因素有两个,一个是查找所要提取信息的位置;另一个是提取后对内容的写操作.在总结传统解码方式的优缺点和多次实际测试的基础上,分析发现,传统解码方法对系统时间空间资源的开销都过于巨大.对比API方式相较于wgrib方式而言首先是更为灵活,二次开发性较好,其次不需要调度DOS命令,且使用API方式可以构建更为快速的解码数据结构并解决grib和grib2混合压缩的问题.固本文HP算法的设计选择基于GRIB API.NET的解码方式.HP算法的流程图如图1所示.

图1 HP算法解码流程图
Fig.1 HP algorithm decoding flow chart
HP算法核心在于使用散列查找结构和多线程调度来进行解码.构造散列函数的定义域[5]包含需要提取的物理量的关键字,这里的关键字为GRIB码物理量索引,值域的范围依赖于散列表的大小即索引的地址范围,根据不同的数值预报产品不同,其值域范围不同.使用直接定址法,取线性物理量Level层构建散列地址,其函数如公式1所示
H(Key)=a*Key+b
(1)
其中,a为level的增量,b为偏移量,当物理量提取发生冲突时采用除留余数法,并构造再散列法(双散列法)处理,构建第二个散列函数Hash2(Key)计算冲突地址值的增量.它的具体散列函数形式如公式2所示:
Hi=(H(Key)+i*Hash2(Key))%m
(2)
初始探测位置H0=H(Key)%m.其中,m为GRIB中物理量个数长度,i是冲突的次数,初始为0.
HP算法时间复杂度:对散列表查找的时间复杂度为O(1),在查找到地址后对物理量的提取时所需比较的平均次数计算公式如公式3所示:
(3)
其中,Pi为平均查找到目标物理量的概率,n是查找表的长度.使用此按值查找算法的平均时间复杂度为O(n),则整体解码的时间复杂度为O(n)+O(1)=O(n),如果顺序固定,则其最快的时间复杂度为O(1),则整体最快为O(1)+O(1)=O(1).
HP算法空间复杂度:其取决于需要查找的物理量的多少,设一个文件内的所有物理量大小为m1,所需物理量为m2,则对于使用散列表的查找数据的所占用的空间复杂度为O(m2).
使用上述散列结构算法进行数据的查找和提取可大大提高数据在主存中的提取速度,加入多线程并行化资源调度模式[6],可使I/O输出倍数级缩短耗时,理论上当线程数不大于物理核数时,使用线程k个可将整体算法的时间复杂度化为O(n/k),但空间复杂度会增加为O(n*k).
1.2 与传统算法对比
传统算法核心是通过使用系统命令批处理调用wgrib程序进行整个文件的解码,解码的方式为先输出GRIB目录和输出解码为二进制格式的中间数据文件,再对照目录中关键字内容对二进制中间文件进行循环提取.提取后的数据为解码结果.分析其解码原理和算法可知,传统方法在解码时首先在内存中输出一次二进制中间文件和一次GRIB目录内容.之后将二进制中间文件输出到外存.并在外存中打开文件,循环提取所需内容并转换为后续模块需要的格式,再进行一次外存输出.且解码的区域只能为全球范围所有数据.这种传统的解码模式首先由于使用系统控制台命令批处理操作wgrib外部程序进行解码.此方式会导致无法通过多线程调度来实现解码部分的并行化效率提升.且生成中间文件会导致解码过程产生两次外存输出.内存读取数据的次数也为两次,并有一次目录文件的外存输出和读取.其造成大量的空间占用和较大的系统资源浪费.时效性较差.使用外部wgrib程序还会导致该方法的二次开发受到很大的限制.根据文献[1]中的内容可以对传统方法进行改良,即在对中间文件的提取部分加入多线程并行化提取.这种方式可以部分提升解码的速度,传统算法与改良算法的流程对比图如图2所示.
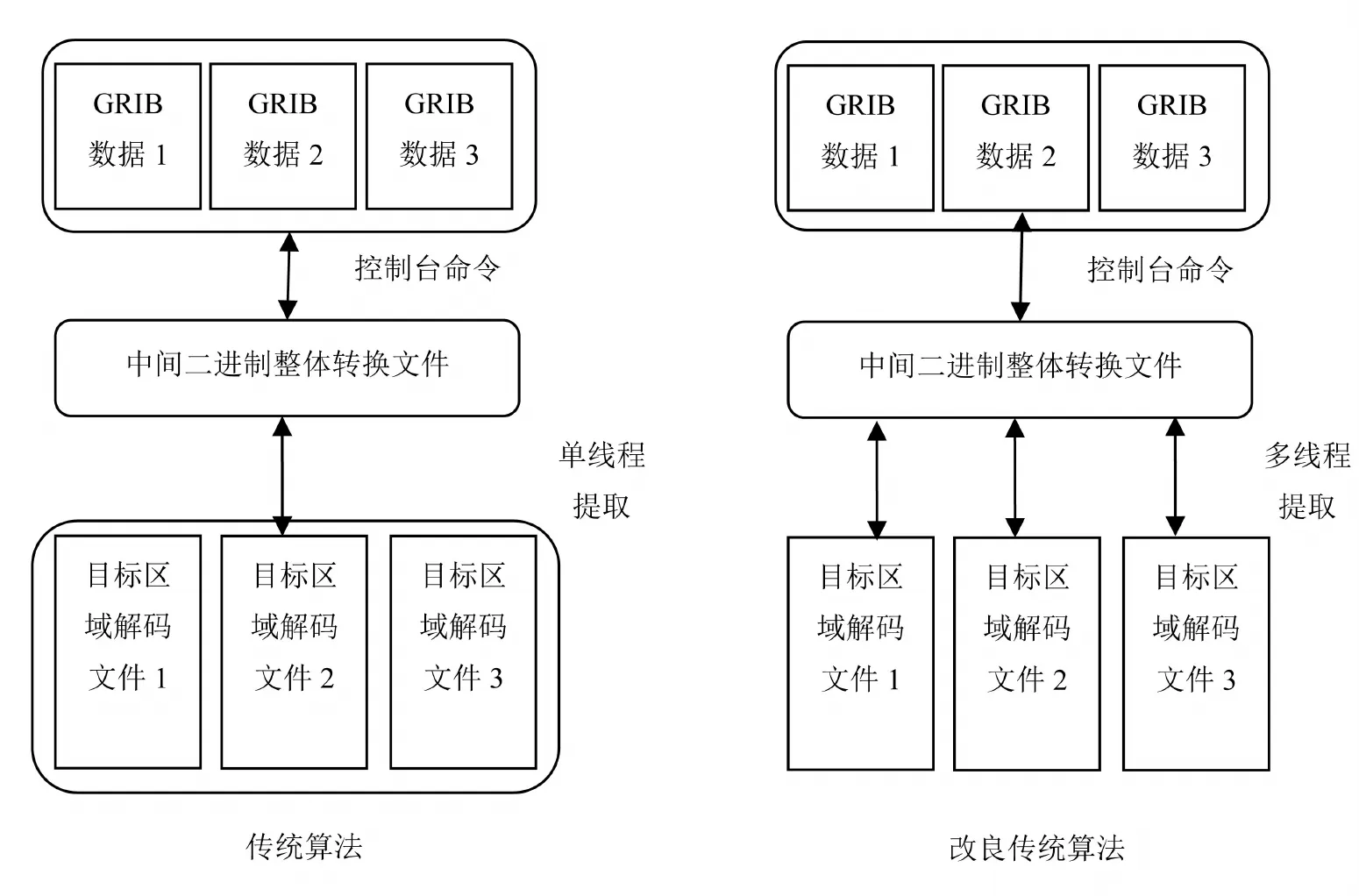
图2 传统算法与改良算法流程对比简图
Fig.2 Comparison of traditional algorithm and improved algorithm flow
采用改良算法仅小部分提升了解码的效率,其他存在问题并未得到根本性的解决,传统改良算法与HP算法的流程对比简图如图3所示.
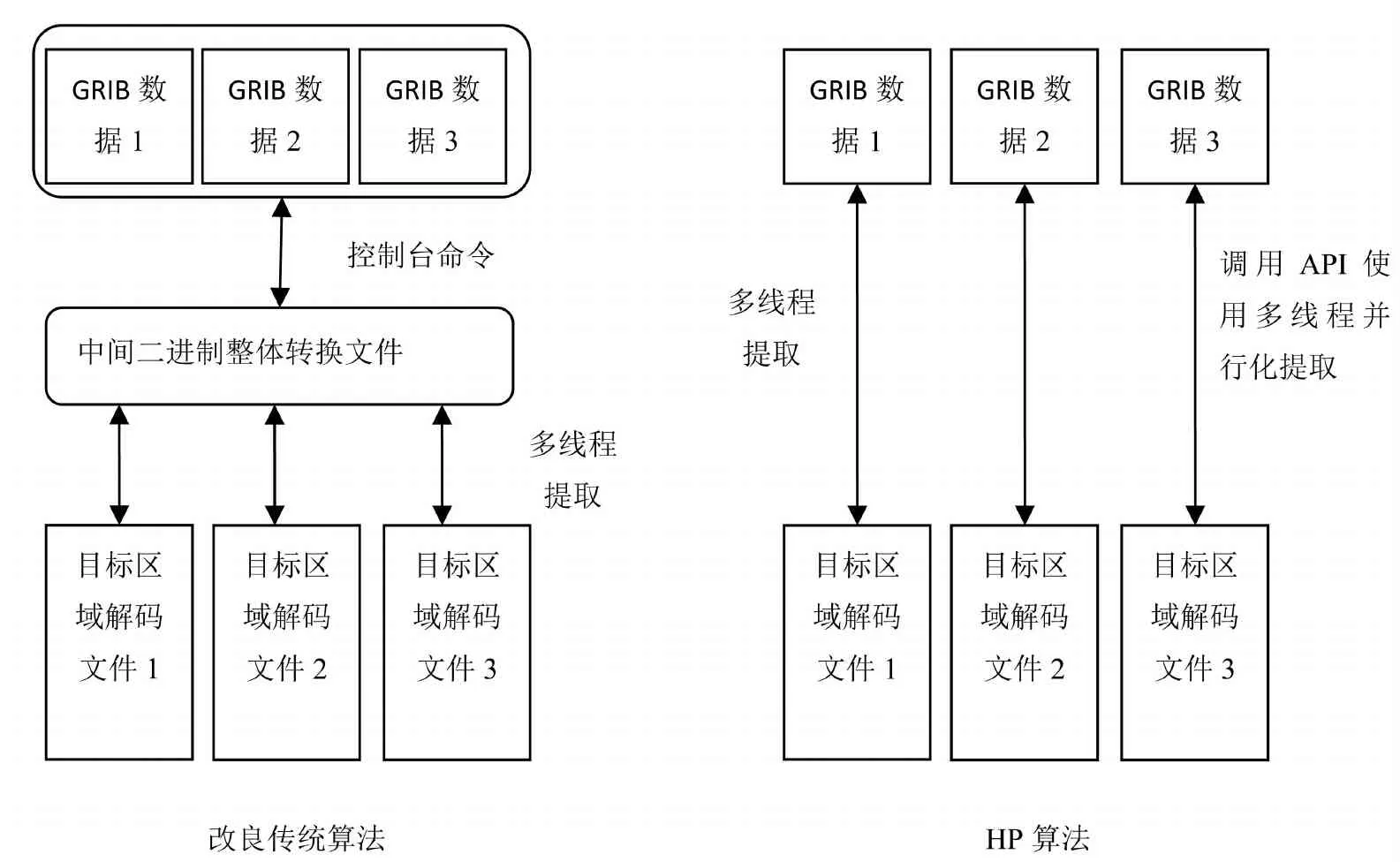
图3 改良传统算法与HP算法的流程对比简图
Fig.3 Shows a simplified comparison of the flow between the improved traditional algorithm and the HP algorithm
HP算法相较于传统算法在运行流程上更为简化,其使用散列查找模式对GRIB结构数据进行提取.仅需读取一次源数据文件,不需要读写目录.并且可根据目标范围直接在主存中缩小提取数据的内容,根据后续物理模块的计算需求,目标范围越小解码速度越快.输出结果也仅为一次.相较于传统算法,HP解码方法节省了生成中间文件所需的时间空间资源,并可实现全过程多线程并行化提速,极大程度上提升了解码的效率.且该方法具有较高的兼容性、封装性和可扩展性.
2 案例测试及结果分析
调研文献和分析解码模式认为当运行物理环境一定的情况下,单从方法角度分析影响解码效率的因素有①解码区域范围、②数据分辨率大小、③所需物理量数量、④预处理文件个数(评价时长)和⑤线程数,分别对单一变量控制进行效率测试.对比组使用文献[7]中提及的应用较为典型的境外核事故放射性后果评价软件(RADCON)中的解码方法.即wgrib解码方法进行对比测试.测试硬件选用的配置为win7-64位操作系统,16 G内存,8核CPU计算机.测试案例选用NCAR(National Center for Atmospheric Research)发布的FNL再分析数据进行测试.首先对解码区域范围的影响进行效率测试.选取2016年10月01日00时刻的以grib2[8]格式压缩的FNL数据,区域分为全球区域360*181°和局部范围40*40°经纬度范围[9].测试长度都选择10天(240小时分析时长),每6小时一个文件,共40个文件.源数据内容长度都控制在328个物理量,分辨率为1°,提取物理量为从100 mb~850 mb共16层高度层的风场U、风场V、垂直速度、温度、相对湿度、位势高度变量和surface层常用的地面压力、对流性降水、总降水、下垫面特征、雪厚度,变量总共101个变量,线程数选择单线程进行测试.测试结果如表1所示.
对五次测试结果中解码耗时取平均绘制对比结果图如图4所示.从图4中可以明显看出,对于解码范围从全球到局部尺度,随着解码范围的缩小,HP算法的耗时大幅下降,而传统算法的解码耗时也有所下降,但是幅度不明显.据分析可知,使用HP算法是根据GRIB压缩格式直接通过散列函数读取内部结构数据的,对于缩小解码范围,可在解码数据读入的过程中缩小提取数据的量,从而在之后的数组建立和文件输出的过程中都减少时间和空间资源的占用.而对于传统算法,缩小解码范围对于解GRIB码的过程无影响,因为其是先对整个区域进行解码生成中间文件之后,当缩小解码范围,那么对于中间文件的数据读取量会缩小,生成最终所需文件的耗时会缩小.这样看来,传统算法在解GRIB码时对于解码范围缩小是不影响其效率的.在二次提取数据时才会有效率的提升.而HP算法在解GRIB码数据之前就缩小了提取数据的范围.所以当解码范围为局地小尺度时,使用HP算法可以在较大程度上提升解码的效率.

表1 不同解码范围对解码耗时的影响表Tab.1 Table of effects of different decoding ranges on decoding time consumption
之后研究不同分辨率对数据解码耗时的影响,数据选取全球范围360*181,分辨率选择1°和0.5°的源数据,上述其他变量都保持不变的情况下再进行测试.测试结果如表2所示.

表2 不同分辨率对解码耗时的影响表Tab.2 Table of effects of different resolutions on decoding time consumption
对五次测试结果中解码耗时取平均绘制对比结果如图5所示.
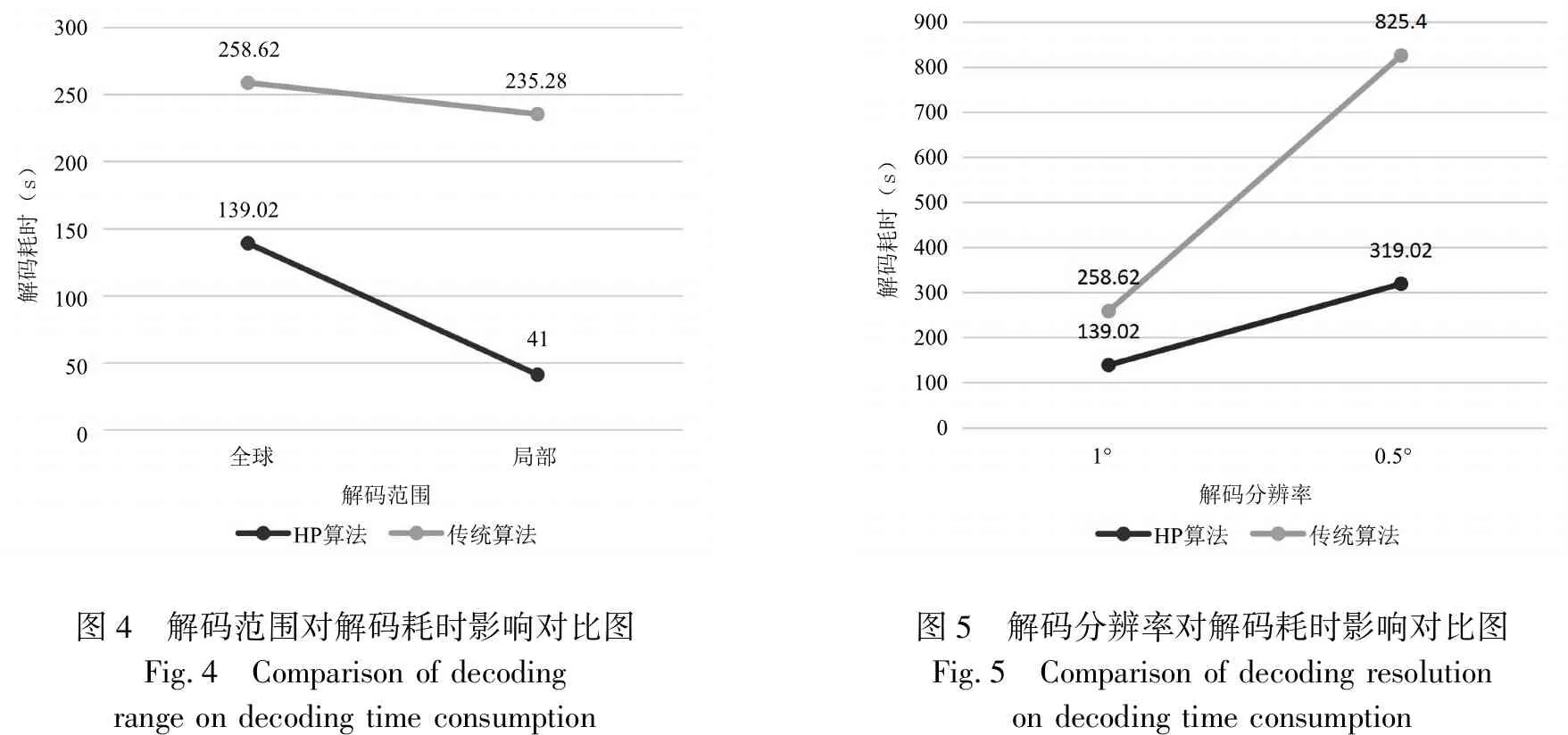
图4 解码范围对解码耗时影响对比图Fig.4 Comparison of decoding range on decoding time consumption图5 解码分辨率对解码耗时影响对比图Fig.5 Comparison of decoding resolution on decoding time consumption
观察图中两种分辨率对解码耗时的影响可知,当解码分辨率扩大一倍时,两种算法的耗时都会增加,对于HP算法来说,当数据量增加一倍,那么其耗时会相应增加一倍,但是由于GRIB数据的基数增加,导致循环索引的数组增加一倍,随着数组量的增加,处理数组所占用的时间资源量要多于一倍,固对于HP算法来说,耗时会增加一倍多一点.根据图中数据可知,分辨率增加一倍耗时为原耗时的229 %.分析传统算法可知,由分辨率的增加,生成的中间文件的数据量会增加,由于文件IO所占的时间空间资源都是很大的,固当分辨率增加一倍时,解码的耗时会大于一倍.据图中数据分析可知0.5°分辨率的解码耗时为原解码耗时的319 %.因此,HP算法在对于高分辨率GRIB数据解码的效率要优于传统解码,且分辨率越高,效果越明显.
再研究变量提取量的多少对解码耗时的影响,选取分辨率1°的grib2压缩格式FNL源数据,物理量提取设置原变量组为101组,新设变量新增土温4层土湿4层,2米高度层露点温度、温度、相对湿度、比湿,10米高度层风场U、风场V、地表温度、海平面压力、地面感应热通量,地表温度t,海平面压力msl,雪厚度,高度层增设为900 mb~1 000 mb共5层高度层的风场U、风场V、垂直速度、温度、相对湿度、位势高度变量,总共148个变量为148组.上述其他变量都保持不变的情况下再进行测试.测试结果如表3所示.

表3 不同变量提取组对解码耗时的影响表Tab.3 Table of effects of different variable extraction groups on decoding time consumption
对五次测试结果中解码耗时取平均绘制对比结果如图6所示.从测试结果可以大致分析得出,当所提取的物理量内容增加时,解码的耗时也会相应增加,且大致推算可以得出两种解码的耗时与所提取物理量的内容成正比,HP算法由于物理量提取组增多,耗时为原来的1.39倍,而传统算法的耗时约为1.44倍,对比可知HP算法略优于传统算法,但差别不大.在实际解码的过程中由于HP算法的耗时基数较小,所以当对于大量的物理量或者是全部物理量的提取来说,HP算法相对于传统算法更节省时间.
分析解码时长对解码耗时的影响,选取物理量提取组为101组,测试预处理数据长度选择10天(240小时分析时长)数据、2天(48小时分析时长)和1天(24小时分析时长),上述其他变量都保持不变的情况下再进行测试.测试结果如表4所示.

表4 不同分析时长对解码耗时的影响表Tab.4 Table of effects of different analysis durations on decoding time consumption
对五次测试结果中解码耗时取平均绘制对比结果如图7所示.根据测试结果可知当分析时长减少时,解码的耗时也相应减少,且对应成正比.分析原因可知,由于两种算法对于解码的过程都是按照一个分析时刻解完后进行下一个分析时刻的解码.其内在的逻辑过程是串行,且如果当每个时刻的文件大小一致的情况下,解码单时刻的耗时是一致的.所以,两种解码方法对于分析时长变化,其解码耗的变化时对应成正比关系.
最后探讨线程数对解码耗时的影响[10],选取预处理数据长度10天(240小时分析时长)数据,线程调度分为使用单线程、双线程和四线程进行解码,上述其他变量都保持不变的情况下再进行测试.由于传统算法未加入多线程并行化方法.固在传统方法的基础上使用改良型传统方法,加入线程调度方法,其核心也是使用wgrib命令进行解码预处理,测试结果如表5所示.

图6 变量提取对解码耗时影响对比图Fig. is a comparison of the effects of variable extraction on decoding time图7 分析时长对解码耗时影响对比图Fig.7 Comparison of the influence of analysis time on decoding time consumption

表5 不同线程数对解码耗时的影响表Tab.5 Effect of different thread counts on decoding time consumption
对五次测试结果中解码耗时取平均绘制对比结果图如图8所示.
根据图中测试结果不难看出,HP线程数的调用对于解码效率的影响成倍数关系,在物理核数对比线程数未达到饱和状态(即N核,M线程,其中N≤M).所调用线程数即为解码耗时缩短的倍数,如图中所示,当线程数为双线程时,解码的耗时大致为原解码耗时的1/2.当线程数为四线程时,解码的耗时为原解码耗时的1/4.而传统算法在调度多线程的情况下无法达到按比例缩短解码耗时.从图中可见其解码调度四线程时耗时为原解码耗时的0.75倍.由上述算法分析可知,传统算法调度线程仅可提升文件I/O速度,并无法提升解码速度.固当解码线程提升时,耗时减少的部分仅为文件I/O部分,而解码过程并无效率提升.由此可得使用HP算法可以在硬件允许的情况下调度多线程来大幅提升解码效率.

图8 不同线程数对解码耗时影响对比图
Fig.8 Comparison of the impact of different thread counts on decoding time
3 结论
本文在分析传统解码方法的基础之上,设计了全新的利用多线程调度模式和高效GRIB码散列查找结构的新算法HP算法.通过与传统解码方法的对比测试,分别讨论了HP算法与传统算法在解码区域范围、数据分辨率大小、物理量提取数量、评价时长和线程数方面对解码耗时的影响.结果证明利用HP算法解码在各方面都优于传统算法且解码效率提升明显.分析认为在实际的解码过程中使用HP算法能大幅提升解码效率,可应用于对解码效率有较高需求的应急响应系统[11]中,为其GRIB数据预处理模块的快速解码提供参考方法.
