基于差分隐私的混合位置隐私保护
2019-06-17徐启元陈珍萍付保川许馨尹邵雪莲
徐启元 陈珍萍 付保川 许馨尹 邵雪莲
(苏州科技大学电子与信息工程学院 江苏 苏州 215009)
0 引 言
随着智能终端的广泛应用,智能手机、平板等设备已经成为人们生活中的必须品,用户使用全球定位系统(Global Position System,GPS)和通信运营商的定位服务也在日益精确,基于位置的服务(Location-Based Services,LBS)得到越来越广泛的应用,用户可以通过这些LBS应用搜索附近的所有餐厅、距离自己最近的电影院等[1]。然而,LBS的广泛应用也带来了一系列问题,其中一个重要问题就是用户位置信息存在被泄露的风险[2]。近些年来,关于位置隐私保护的研究非常活跃,取得了很多研究成果。
文献[3]采用模糊策略对位置进行模糊化处理,虽然可以保护位置隐私,但影响了感知数据的服务质量,降低了数据可用性。文献[4]采用假名替换,即把用户真实身份用预先设定的假名替代,从而隐藏了用户真实身份,但若攻击者掌握了替代规律,也可能挖掘出用户的真实信息。文献[5-6]通过K-匿名方法来保护位置隐私,将K个用户位置组成一个匿名集,使得攻击者即使获得了每个用户的具体位置,仍无法从K个用户中确定真正的查询请求用户,从而在一定程度上达到了保护用户位置隐私的目的。然而,K的增加可能会使隐形区域最大化,由于是在服务器端处理开销,导致响应时间延迟。因此,隐形区域的最大化可能会降低LBS应用程序提供查询服务的质量。文献[7]提出了地理l-多样性原则,要求用户位置信息不能被l个位置集所识别,防止由于用户间相距过近而被攻击者推导出用户所处区域的大致位置。
上述方法都是在假定对手没有用户背景信息的基础上进行的研究,因而当对手拥有用户的背景信息时,上述方法很可能将用户的信息泄露,例如在利用k-means聚类算法进行位置泛化时,简单地通过欧几里得函数计算每个距离当前用户位置最近的聚类中心很容易遭到数据攻击进而泄露位置信息。文献[8]提出一种将k-means聚类算法与差分隐私保护技术相结合的方法,差分隐私是一种具有完全独立于攻击者背景信息的强隐私保护技术,使得该方法具有较强的隐私保护能力。但是在仿真实验过程中,这种差分隐私k-means隐私保护方法的聚类结果可用性较低,本文针对这一问题并结合LBS的自身特点提出一种基于差分隐私的k-means混合位置隐私保护方法。
用户先将位置发送到可信匿名服务器,通过对用户位置的人流密度参数进行分析将用户位置点分成离散位置点和非离散位置点。对于离散点我们采用基于差分隐私的单独加噪技术进行隐私保护;对于非离散点,选取其中人流密度较大的点作为初始聚类中心点,通过改进的k-means聚类算法来实现位置数据的泛化处理,并在泛化过程中使用差分隐私技术对可能泄露的发布数据进行加噪,最终将算法收敛后的聚类中心点和离散点位置集发送给LBS服务器来获取位置服务。仿真实验证明算法能够在相同隐私性的条件下提高数据的可用性。
1 位置隐私保护模型
1.1 差分隐私技术
差分隐私技术是文献[9]提出的,是一种与背景知识无关的强隐私保护模型。文献[10]在此基础上提出位置差分隐私,其定义如下:
定义1ε-位置差分隐私:对于2个位置数据集D和D′,假定两者最多只有一条位置信息不同,即两者的线性相异距离|D-D′|≤1,M为随机查询函数,并具有差分隐私保护,Rang(M)代表M的取值范围,若D和D′在查询函数M下得到的任意位置L(L⊆Rang(M))满足下式,则查询函数M满足ε-位置差分隐私[10]。
Pr[M(D)∈L]≤Pr[M(D′)∈L]eε
(1)
式中:Pr[·]表示位置信息被泄露的概率,由算法M的随机性控制;参数ε为隐私保护预算,ε越小隐私保护程度越高。
全局敏感度是差分隐私保护算法的一个重要度量指标。它的大小只与函数f本身有关,与数据集大小无关。全局敏感度的定义如下。
定义2全局敏感度[11]:对于任意函数f:D→Rd,f的全局敏感度定义为:
(2)
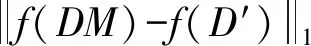
差分隐私保护的实现机制主要有拉普拉斯机制[12]和指数机制[13],其中拉普拉斯机制多用于数值型数据,指数机制一般用于非数值型数据。本文采用拉普拉斯加噪机制。
定义3拉普拉斯机制:给定位置数据集D,对任意函数f:D→Rd,其敏感度为Δf,若函数f输出结果满足:
M(DM)=f(DM)+Lap(b)
(3)
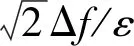
1.2 位置隐私保护
标准差分隐私被证明可以应用于有多用户位置的信息发布,但并不适用单个用户位置。文献[14]提出一种满足差分隐私的地理不可区分性理论,它通过向用户的真实位置添加平面拉普拉斯噪声生成干扰位置,这种满足差分隐私的加噪方式即使被有背景信息的对手观察到,也不能以较高准确率判断出真实位置。
对于用户位置x=(s,t),其中s和t分别为位置的二维坐标,给定隐私保护预算ε,若添加噪声后生成位置x′的概率P(x)(x′)满足:
(4)
则称该加噪保护机制满足ε-位置差分隐私。
从式(4)可以看出,在隐私预算ε一定且d(x,x′)>0时,概率P(x)(x′)随着x′到x的距离增大而减小,取值只与x′到x的距离d(x,x′)有关。为简化起见,可将该概率转化为极坐标形式,具体为:
(5)
式中:r表示x′到x的距离,θ为x′在极坐标下与极轴的夹角。同样可将式(5)分解到半径R和角度Θ上,以得到如下概率分布函数:
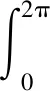
(6)
(7)
2 混合位置隐私保护方法
现有差分隐私k-means算法在进行位置数据的隐私保护时,少量的离群点会导致算法输出结果产生较大的偏差,且对初始中心点较为敏感,导致其具有较低的位置数据可用性。本文提出一种混合位置隐私保护方法,在k-means算法进行初始中心点选择时,根据不同地理空间区域人流密度的不同,将一些离群用户从用户集合中剔除,以减少因为离群点对聚类稳定性的干扰。然后将初始中心点分配到人流较集中的区域而不是随机选取,使初始中心点距离最终输出的中心点位置较接近,减少算法的迭代次数,提高了聚类结果的稳定性和LBS服务的可用性。对于离群用户点进行单独加噪方法来对其进行位置隐私保护。本文所提方法根据不同用户周围人流密度的不同,采取的混合隐私保护方法可以提高聚类的稳定性,同时也对离群位置点进行了很好的隐私保护。
2.1 离群点的判定
对于用户位置数据集X={x1,x2,…,xn},任一用户位置点xi为中心、半径为Rm的区域称为点xi的邻域,领域内的用户数ui称为点xi基于Rm的人流密度。对包含有n个用户的数据集X={x1,x2,…,xn},取用户间的平均距离为半径Rm,则Rm可为:
(8)
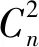
ui=|Ni|Ni={xj|d(xi,xj)≤Rm}
(9)
ui值可以反映位置xi周围点的稀疏程度。
离群点是指与其他点有明显不同的数据点,一般可分为全局离群点、情境离群点、集体离群点[15-16],鉴于本文主要面对的是数值型数据的保护,不涉及具体情境或者群组,因此只考虑全局离群点,即位置数据集X={x1,x2,…,xn}中与其余点差别均很大的数据点。对于离群点的判定,由文献[17]数据集中X的稀有类由至多5%的数据点组成,因而数据集中离群点数目nD不超过n×0.05,可表示为nD=└n×0.05┘ 。对于位置数据集X={x1,x2,…,xn}的nD个离群点的判定,可通过式(9)计算得到的每个位置点xi处的人流密度参数ui,取密度参数最小的nD个点作为位置隐私保护中的离群点。
2.2 离群点隐私保护方法
在本文所提混合位置隐私保护中,对于离群点采用单独加噪的方法来进行隐私保护。具体如算法1所示。
算法1离群点隐私保护
输入:用户位置数据集X={x1,x2,…,xn}(xi=(st,ti),隐私预算ε;
输出:加噪离群点集D′,非离群点集X2。
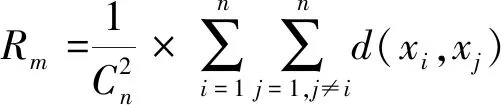
2) 由式(9)计算每个位置点xi处的人流密度参数ui(i=1,2,…,n);
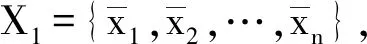
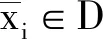
确定位置极坐标表的随机噪声ri和θi,其中θi为[0,2π)间均匀分布随机数,νi为[0,1)间均匀分布的随机数,而Cε(νi)为概率密度函数Pε,r(νi)在[0,νi]上的积分函数,满足:
用以表示随机半径ri落在0到νi上的累积概率。
5) 按照:
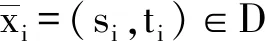
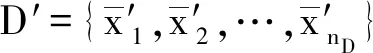
2.3 混合k-means隐私保护方法
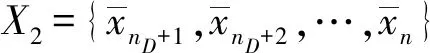
算法2混合k-means隐私保护
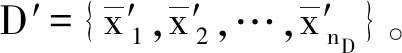
输出:差分隐私保护的位置数据集X′=D′∪C″。
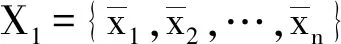
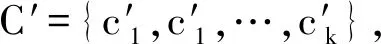
确定位置极坐标表的随机噪声ri和θi,νi为[0,1)间均匀分布的随机数,而Cε(νi)为概率密度函数Dε,r(νi)在[0,νi]上的积分函数,按照:
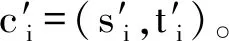
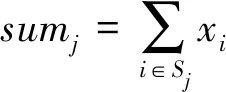
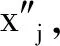
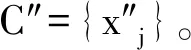
8) 输出通过差分隐私保护的位置数据集X′=D′∪C″。
这时离散点的位置由单独加噪后的位置代替,非离散点的原始位置由加噪后的聚类中心点代替。
3 仿真结果与分析
为验证本文所提混合位置隐私保护方法的有效性,在MATLAB仿真平台上进行算法的数值仿真。数值仿真主要关注目标为用户在获取LBS服务的过程中位置数据的安全性和可用性,以及改进算法在聚类过程中的聚类效果。
3.1 参数设置
本实验在MATLAB环境中在2×2的空间随机生成n=80个二维数据点来模拟用户位置,也即有用户xi=(si,ti)(i=1,2,…,n),si∈(0,2),ti∈(0,2)。聚类簇数通过文献[18]给出的评价指标误差平方和(Sum of the Squared Errors,SSE)来确定,通过计算不同k值下的SSE观察到当k取3为其最佳聚类数,因此取k=3,对算法运行10次取平均值作为输出的结果进行比较分析。
3.2 聚类误差分析
下面进行本文所提混合位置隐私保护方法、基于差分隐私的k-means算法以及位置单独加噪方法的聚类误差Error的分析。分别记E1、E2、E3为本文所提差分隐私k-means混合隐私保护方法、单独加噪和传统差分隐私k-means方法运行结果的偏移误差,即每个位置点的原始位置与输出的加噪后的查询位置点之间的误差。
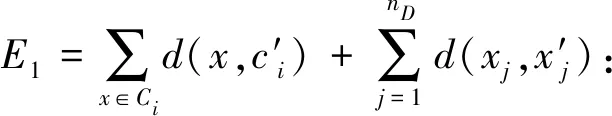
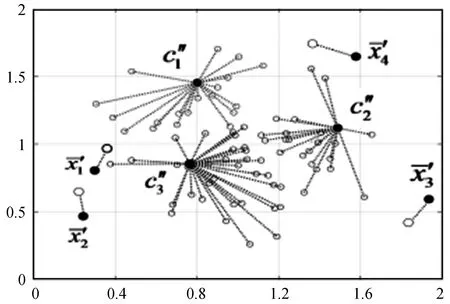
图1 本文算法的聚类输出结果,其中ε=2
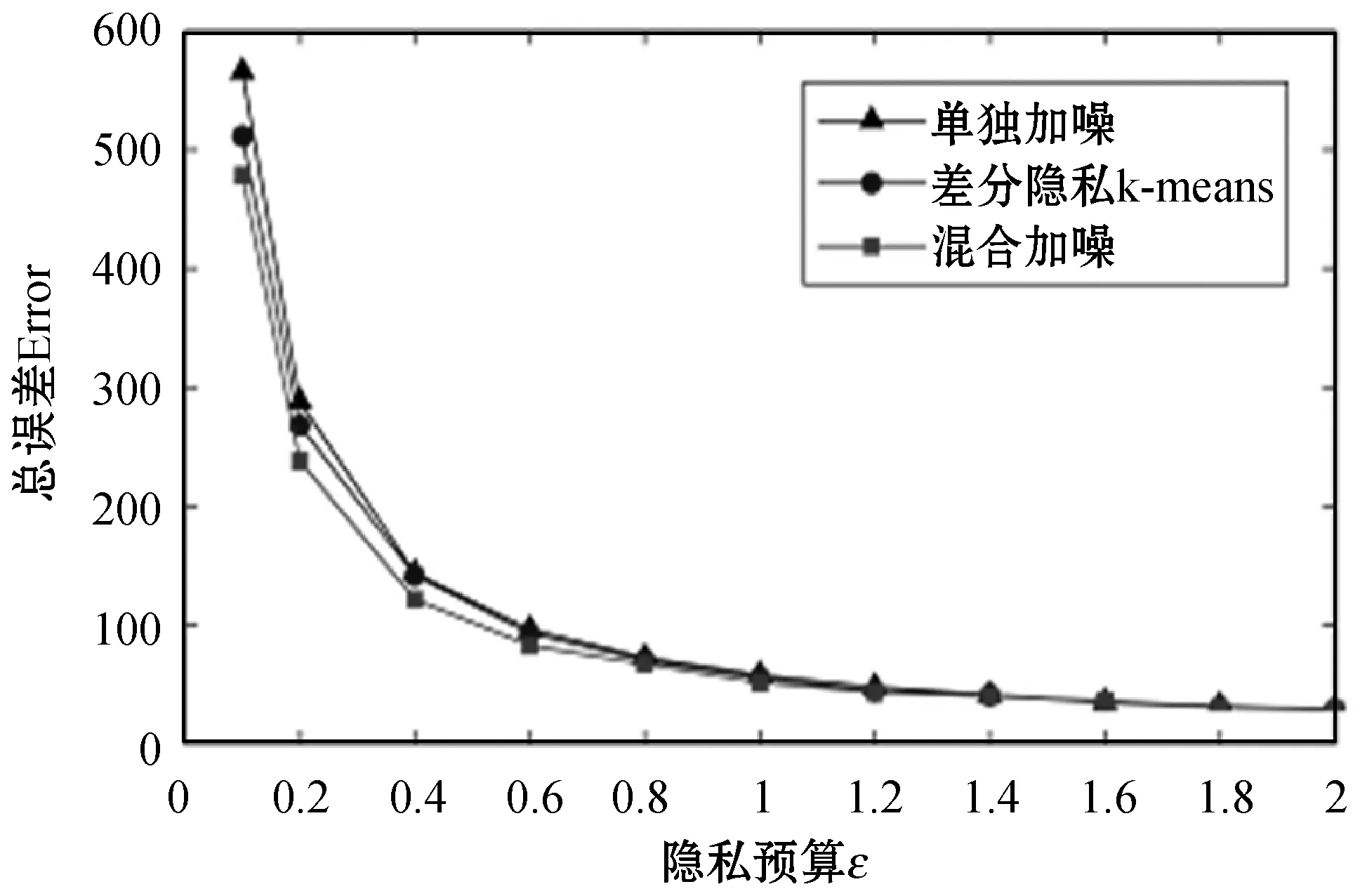
图2 不同隐私预算ε下对算法误差的影响
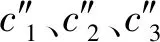
通过图2可以看出,在隐私预算ε较小的时候,三种加噪方法的输出距离原始数据误差均过大;随着隐私预算ε的不断增加,误差先是急剧减小,然后下降幅度逐渐减少并趋于稳定。因而在实际应用过程中,可以取趋于稳定后并且ε较小的值作为隐私预算。通过比较三种不同的加噪方式发现,在相同的隐私预算ε下本文提出的混合位置隐私保护算法的误差比另外两种算法的误差较小。
3.3 数据可用性分析
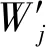
(10)
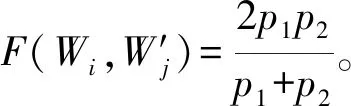
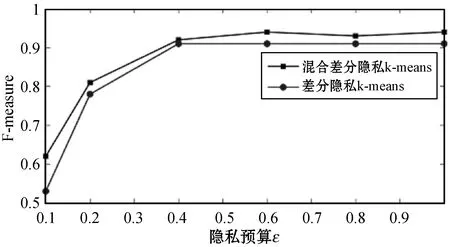
图3 不同隐私预算ε下的F-measure运行结果
通过图3可以看出,本文提出的基于差分隐私的混合k-means聚类算法满足ε差分隐私的要求,能够有效地保护用户的位置隐私,并且与差分隐私k-means算法相比,F-measure值有了较大提升,这说明本文提出的算法在相同隐私预算ε下具有更高的数据可用性。
4 结 语
对于传统使用k-means进行数据泛化可能导致位置数据泄露的问题,本文提出了一种结合LBS数据特点的差分隐私混合k-means位置隐私保护算法。通过使用密度参数来选择聚类的初始中心点,对中心点和聚类过程中可能泄露用户隐私的数据添加满足差分隐私的Laplace噪声,并将离散点提取出来单独加噪减少来增加聚类可用性。实验结果表明,改进后的算法减少了聚类中簇的迭代次数,提高了聚类中心精度,并且在添加相同噪声的情况下提高了位置数据的可用性。下一步将根据用户对查询结果的反馈,根据不同用户对数据的隐私需求程度不同添加不同的噪声等级,从而给用户更好的LBS体验和满足用户的安全性要求。
