一种结合模型集成的舆情管理模型的研究
2019-06-17唐存琛王極可
唐存琛 王極可
(武汉大学计算机学院 湖北 武汉 430070)
0 引 言
随着互联网技术的发展,由新浪微博所代表的社交平台在网络舆情传播中起到关键性的作用。针对网络舆情的快速传播性导致网络舆情难以监控的问题,本文提出了一种结合模型集成的网络舆情管理模型,使得有需求的研究人员和有关部门能参照此模型更好地实现对舆情信息的监控和社交平台的分析与管理。本文所设计的模型分为两个子模型:舆情信息采集子模型与舆情信息分析子模型。传统的网络舆情管理模型大都注重其分析采集后的舆情信息,而忽略了对数据采集模块的构建。该模型相较于传统模型,增加了采集舆情信息模块化,针对现时主流的公共社交平台,设计出了一个采集模型,使得在舆情采集上,能够以较快的速度获取质量高、数据量大的舆情信息,为下面的舆情分析模型奠定了良好的基础。而在舆情信息分析子模型当中改进了现有的舆情分析算法设计,与传统的舆情分析模型对比,本文提出的新模型在舆情信息采集以及舆情分析方面有了一定的提升。
1 模型总体架构
模型由舆情信息分析模型与舆情信息采集模型两个子模型组成,总体架构如图1所示。整个模型放置两个接口,一个用来连接舆情信息采集子模型与数据预处理模块,另一个用来连接数据库与舆情信息分析子模型。在确定所需要的舆情信息后,通过舆情信息采集模型采集到相关舆情信息数据,然后进行数据预处理存入数据库,数据库里面的数据通过舆情信息分析模型分析后得到舆情报告。
2 舆情信息采集子模型
2.1 模型设计思想
数据是分析的先决条件,只有存在大量有效数据时才能进行分析。因此舆情信息采集是整个网络舆情管理模型的基础,是该网络舆情管理模型的重要组成部分。国外的科研人员在很早之前就针对Twitter、Facebook等大型社交平台开展了一系列的分析[1-2],此外Facebook等知名社交平台都会提供较大量的数据给研究人员,使其研究能顺利开展。而国内的社交平台所提供的API[3]的种类有限,接口对爬取数据也有严格限制,这就导致国内研究人员想通过官方提供的接口获取研究所需的数据难度加大。现在市面上虽然有很多抓取软件,如“Easy Web Extract”、“Data Scraping Studio”、“八爪鱼”等,但经过调研,这些软件都有着一定的缺陷,采集的数据不能完全满足研究和管理人员的需求。因此一些研究和管理人员在实验中为了追求合适的数据,还是需要去实现自己的一套爬虫代码,给舆情的获取增加了时间成本与人力成本。特别是一些实时热点舆情,更需要研究和管理人员能够以最快的速度,分析出舆情走向,得到舆情报告。该子模型对国内各大社交网站进行调研后,为不同的平台设计其特定的采集器模块,能够满足不同场景下的需求。
2.2 社交平台页面分析
本小节对国内各大社交平台网站页面进行分析,根据现时情况将此模型分为三部分。
2.2.1舆情信息采集需求
研究和管理人员在研究一些舆情信息的时候,会对信息的来源等条件有一定的要求,故此模型根据所需数据的要求将数据采集分为两个模块:一是通用采集,即全站采集,对数据不进行筛选,将页面上所有信息进行采集,数据清理后,存入数据库;二是聚焦采集,对特定的信息进行采集,例如关键字采集等[4-5]。
(1) 通用采集 在通用采集中,一般有深度优先和广度优先两种策略[6],即采用广度优先与深度优先不断获取URL,进而爬取到所有所需的页面数据。算法1是通用采集深度优先的策略的伪代码。
算法1深度优先伪代码
Begin
def depth_crawler(main_page):
get main_page.data
get main_page URLS
for url in URLS:
get url.data
depth_crawler(url)
End
(2) 聚焦采集 聚焦采集是采集模块中的重点和难点。例如对于较为常用的关键字、特定发布时间、特定发布地点信息的采集,算法2是聚焦采集的伪代码。
算法2聚焦采集伪代码
Begin
Get key_words, key_time, key_location
def key_word_crawler(data.url):
If match(key_words, key_time, key_location):
Get page_data
def key_word_crawler(data.url)
End
2.2.2页面信息获取
现阶段各大社交平台都有动态页面,这些页面利用JavaScript动态加载页面数据,这种页面用普通爬虫是爬取不到页面内的关键数据的,因此该模型设计了两个采集模块:获取静态页面数据的静态页面采集器和获取动态页面数据的动态页面采集器。静态页面采集器可直接获取页面当中所有的信息数据,而动态页面采集器又分成两个子模块:请求分析采集模块与模拟浏览器模块。请求分析采集模块需要根据动态页面数据加载情况采用特定的获取方式,以获取后台传输的数据;模拟浏览器则相对简单,此模块模拟人为操作浏览器的方式,使页面动态数据传输到前端然后根据静态页面采集器的采集方式采集信息数据。
2.3 模型基本架构
通过对社交平台网站分析,设计出了如图2所示的舆情信息采集子模型框架,该子模型包括4个大模块分别是:聚焦采集接口、通用采集接口、静态页面采集器与动态加载采集器。请求分析采集与模拟浏览器是属于动态页面采集下的子模块。图3是整个舆情信息采集子模型的流程图,舆情信息采集通过通用采集与聚焦采集后,根据采集页面加载数据的形式,采用不同的采集器,在完成获取之后,执行数据处理并将其存储在数据库中。
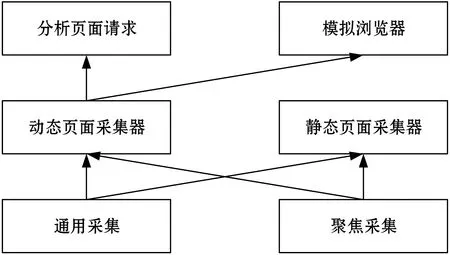
图2 舆情信息采集子模型架构

图3 舆情信息采集子模型流程图
2.4 模块化采集器
通过上小节对各大社交平台网站的分析,本模型提出了数据采集模块化的概念。即是针对各种不同的场景将静态页面采集器划分为不同的采集模块如图4所示,例如新浪微博采集模块与知乎采集模块,使其能方便快捷应对各类需求与场景。研究人员与管理人员可以根据不同的场景调用不同的模块,对不同的平台网站信息进行采集。
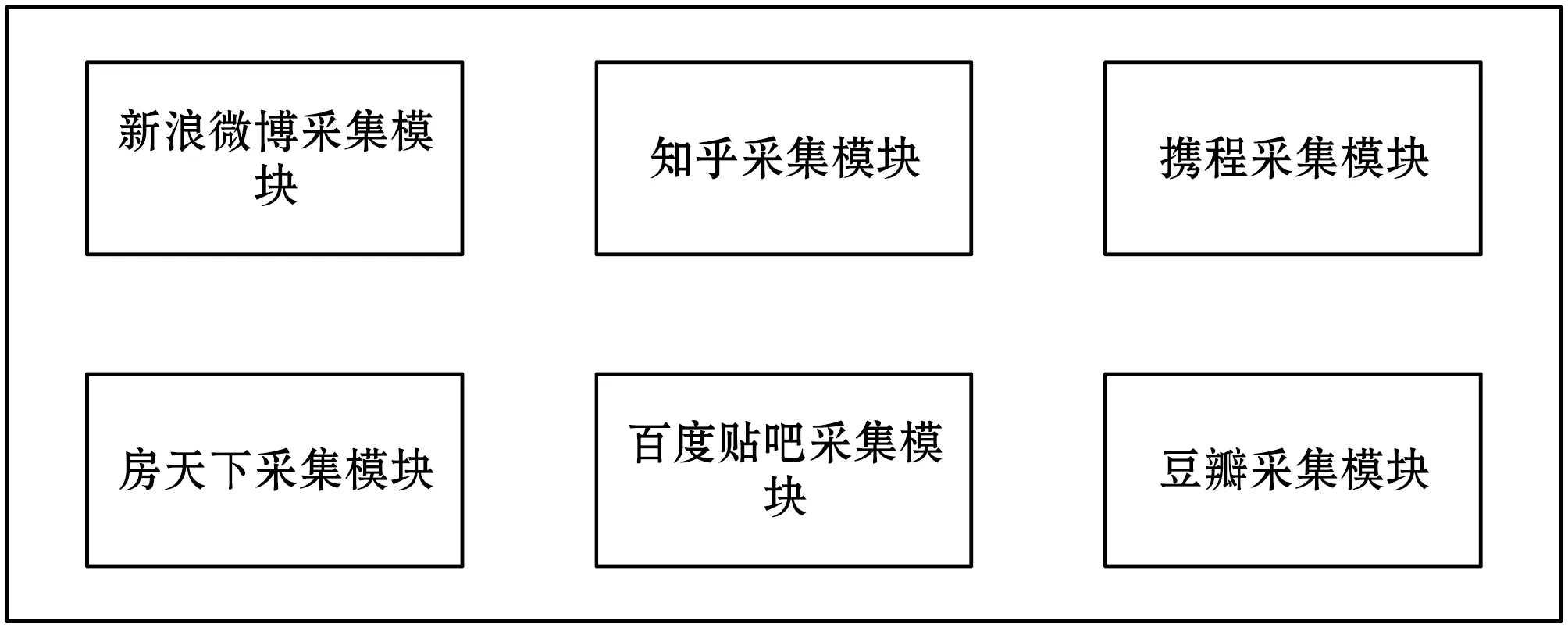
图4 模块化采集器
3 舆情信息分析子模型
舆情信息子模型的作用是将数据库中的舆情信息进行分析,产生分析结果。对比现在各种单一的分类器模型,为使得到的分析数据更加精准,模型在原有的单个分类器模型基础上进行调整,设计了如图5所示的集成模型框架。新的分析模型主要由一个聚类器和一个分类集成器组成。舆情信息首先通过聚类器得到聚类分析结果,然后通过一个分类集成器得到分类分析结果。该模型可确保不同组的基分类器之间的差异性,使得最终的结果更加精确。

图5 舆情信息分析子模型架构
3.1 聚类器
聚类自从其诞生已来就已经被用在了各大领域中,其作用是把具有相似特征的个体划分到一个簇当中,本文中聚类器起到了将所有具有相似含义、情感的舆情划分到一起的作用。到目前为止,聚类算法大体上可以分为基于划分的方法、基于层次的方法、基于密度的方法、基于模型的方法[7]。基于划分的方法的核心步骤是将数据划分为多个簇,而K-Means算法则是该聚类方法中最为简单有效的一种。
3.2 分类集成器[8]
我们以3.1节提到的聚类器生成的聚类结果为输入数据,在此基础之上在每个簇团上进行分类操作,将具有相似特征的舆情数据进行更加详细的分类。分类常用的分类集成模型有串行的Boosting[9],并行的Bagging[10]以及随机森林[9]。集成模型由两部分组成:一是作为基本分类器的弱分类器;二是分类器的结合策略。本模型根据实际情况,调研各种集成模型,最终设计采用以下三种弱分类器作为基本分类器:决策树、逻辑回归、神经网络。
决策树:决策树跟数据结构当中的树相似,通过每一次的分枝来一次次分类,最终解决分类问题。
逻辑回归:逻辑回归模型是现在用来处理分类问题的比较常用的模型,它是在线性回归的基础之上加上了一个逻辑函数,使其能够较好地处理分类问题。
神经网络:神经网络是近年来较为火热的领域之一,其主要分为循环神经网络(RNN)、深层神经网络(DNN)以及卷积神经网络(CNN)。而在文本分类上,循环神经网络有着较好的效果,故该模型采用此神经网络,能够更好地处理文本分类的问题。
利用单独模型对微博信息进行情感分析,然后通过集成的方式,对所有单独模型的分类结果进行集成,最后利用“简单投票法”的集成策略将多个分类模型集成在一起,得到最终分类结果。
设计好聚类器与分类集成器之后,将这两部分连接起来组成完整的舆情信息分析子模型。训练时,先将训练样本的舆情信息数据经过K-Means聚类器,从而形成多个簇,然后在每个簇上利用由神经网络、逻辑回归、决策树三种弱分类器组成的分类集成器进行训练,最终得到训练好的模型。
4 模型实现与测试
4.1 模型实现
为了测试本模型的应用性,本节中就以此模型为基础,采用标准的Django架构,前端使用AngularJS框架。通过以上两个主要的框架,使得舆情管理系统能够在短时间内完成搭建。Diango是基于Model-Template-View(MTV)的一个Python框架。将Control层改为了Template层,将之前的Control层植入框架自动完成。正因为如此,模型搭建维护更加简单方便,更易于二次开发。其中数据存取层(Model)用于处理与数据相关的所有事务;业务逻辑层(Template)用于处理与表现相关的决定;表现层(View)用于存取模型及调取恰当模板的相关逻辑[11]。模型实现后的系统架构如图6所示。
根据上述系统架构,设计了如图7所示的网络舆情管理系统流程图,首先用户需要登录模型,如未注册用户,需经注册才能使用本模型。登录后根据用户其需求采集相关的舆情信息;采集完毕后,选择所采集的数据集进行分析,最后选择所需要的图表生成舆情报告。

图7 网络舆情管理系统流程图
4.2 舆情采集子模型效率测试
基于上小节所实现的系统,本节对模型的性能进行测试。在众多数据的采集过程中,新浪微博信息的采集是比较困难的,现以新浪微博中关键字数据采集为例,将“邪典视频”与“直播答题”作为关键词进行舆情信息采集。图8是本模型的信息采集子模型与“八爪鱼采集器”采集信息数据量的对比。从图中可明显观察出,本文所采用的模型在新浪微博的关键字采集量上大约是“八爪鱼采集器”的十倍,在采集量上有明显的优势。

图8 关键词采集数据量对比
4.3 舆情分析子模型准确率测试
本测试使用了两个数据集,分别是Reuters数据集和斯坦福德的IMDB电影评论情感二分类数据集。而作为对比的是集成模型随机森林,随机森林是由多个决策树组成的强分类器。图9是分类正确率的测试结果。通过图9可以观察出,本文所提出的舆情分析集成模型较随机森林算法在正确率上有一定地提升。
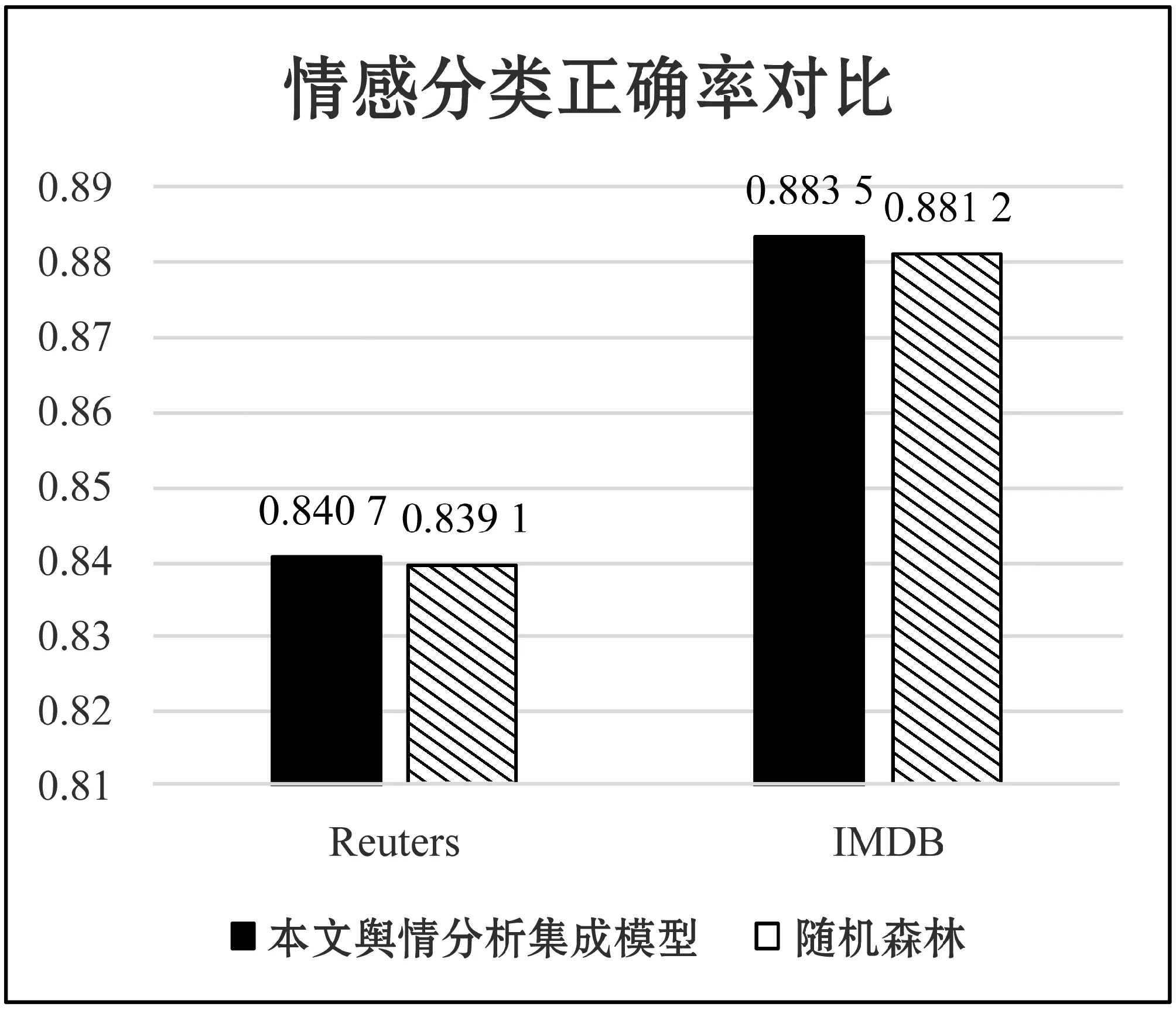
图9 情感分类正确率对比
5 结 语
针对网络舆情的快速传播性导致网络舆情难以监控的问题,设计出一种结合模型集成的网络舆情管理模型。该模型提出了新型的模块化采集信息子模型,在与现时一些爬虫软件的对比中有较强优势;同时根据一种新的集成学习算法思想设计出舆情信息分析子模型,相较于单个分类器分析模型在精度上有一定的提高。本文所提出的舆情管理模型有较强的应用性,为网络舆情分析与管理提供了新的途径。同时此模型也有一些需要改进的地方,特别是在舆情分析子模型上还存在很大的提升空间,以后的工作将围绕提升集成模型的正确率展开。
