阅读中词汇识别依赖词内字序编码的阶段性特点:眼动证据 *
2019-06-15刘志方陈朝阳
刘志方 陈朝阳 仝 文 苏 衡
(1 杭州师范大学心理学系,杭州 311121) (2 宁波大学心理学系,宁波 315211) (3 山西师范大学心理学系,临汾 041000) (4 浙江大学心理与行为科学系,杭州 311121)
1 引言
成功识别词汇是阅读理解文本的必经阶段(Reilly & Radach, 2012)。研究发现,中文读者基于词汇单元识别文字、理解句子文本(Bai, Yan,Liversedge, Zang, & Rayner, 2008; Bai et al., 2013; Shen et al., 2012; Blythe et al., 2012; Li, Bicknell, Liu, Wei, &Rayner, 2014; 白学军等, 2011;沈德立等, 2010),表明中文阅读中的文字加工过程有符合语言普遍性规律的方面。然而还有证据显示,中文词汇识别过程有其语言特殊性特点,即是中文读者识别加工多字词识别时,词内汉字的加工也非常重要(Yan, Tian, Bai, & Rayner, 2006)。申薇和李兴珊(2012)还发现,汉字加工除了受其所在词汇加工的影响外(这与拼音文字相似),它也在一定程度上独立于其所在词汇的加工,从而表现出较强的独立性。中文字的加工与词的加工间的相互影响模式有语言特殊性特点(Li, Rayner, & Cave,2009; 李兴珊, 刘萍萍, 马国杰, 2011)。不过,在阅读中探讨这种相互影响的实证研究尚不成系统。
字、词加工相互影响意味着,词汇加工会影响汉字加工过程,而汉字加工也会影响词汇加工过程。Li, Gu, Liu 和Rayner(2013)采用移动窗口技术检验了“词汇加工是否影响汉字加工过程?”问题,结果发现,移动窗口内保持两个汉字可见的情况下,窗口内两个汉字属于同一词汇的条件对阅读的影响程度低于窗口内两个汉字不属于同一词汇的条件,其作者认为这一结果反映了词汇在汉字识别其所起的积极促进作用。不过,在阅读中探讨汉字加工如何影响词汇识别的实证研究尚不多见。词内字序编码属于汉字加工的一个过程,词汇识别在一定程度上依赖于词内字序编码(Gomez, Ratcliff, & Perea, 2008)。词频效应是判断文字加工程度达到词汇水平的客观标准(Blythe,Liversedge, Joseph, White, & Rayner, 2009),因而检验词内字序编码对词频效应的影响可探讨“汉字加工如何影响词汇加工”问题,进而有利于探讨阅读中的词汇加工机制问题。
读者对特定词汇的识别加工可被划分成预视加工和注视加工两个阶段。目前为止,只有两项研究涉及预视中的汉字顺序编码特点,一项研究发现,预视中跨词间两个汉字顺序颠倒对注视时间的影响程度甚于词内两个汉字顺序颠倒,这意味词切分早于汉字顺序编码过程(Gu & Li, 2015);第二项研究则发现,当预视中目标词汇内两个组成汉字的相对位置被颠倒时,读者依然能够从这种条件中获取预视增益,表明词内汉字顺序编码早在预视阶段就开始影响词汇加工过程,但此阶段内词汇加工并不严格依赖词内汉字顺序编码(Gu, Li, & Liversedge, 2015)。可见预视阶段,词汇加工开始影响汉字顺序编码加工,词内汉字顺序编码也开始部分地影响词汇加工过程。然而,注视阶段内汉字顺序编码与词汇加工之间的相互影响模式如何?尚没有研究探讨这一问题。除此之外,也无研究系统探讨和对比词汇识别在预视和注视阶段内依赖汉字顺序编码的差异性问题。
根据“词汇识别不严格依赖于词内字序编码”的假设可以预测,颠倒词内汉字的位置将不会影响词频效应;而根据“词汇识别严格依赖于词内字序编码”的假设则可以预测,颠倒词内汉字的位置一定会影响词频效应。本研究将组织两项实验检验上述假设,还将分别探讨和对比“预视阶段词内汉字顺序编码影响词频效应的模式”与“注视阶段内汉字顺序编码影响词频效应的模式”差异特点,以澄清阅读中词汇识别依赖于词内字序编码的阶段性特点。实验一采用边界范式,考察预视中词内字序颠倒是否影响词频效应,以确定预视阶段内词汇识别对词内字序编码的依赖性,实验二也采用边界范式,考察注视中词内字序颠倒是否影响词频效应,以确定注视阶段内词汇识别对词内字序编码的依赖性。通过整合两项实验结果,整体上勾画阅读中词汇识别依赖词内字序编码的阶段性特点。
2 实验一:词内字序颠倒对词频效应的影响
目的:通过考察预视中词内字序颠倒条件对词频效应的影响,澄清该阶段内的词汇加工对词内汉字顺序编码的依赖性特点。实验假设:如果预视中词内字序颠倒条件不影响词频效应表明,该阶段内的词汇加工不完全依赖于词内汉字顺序编码;否则则说明该阶段内词汇加工严格依赖于词内汉字顺序编码。
2.1 方法
2.1.1 被试
某大学32 名大学生参加本次实验,其中男生10 名、女生22 名。被试的视力或矫正视力正常,之前均未参加过类似实验。实验结束后可获得报酬20 元。
2.1.2 实验材料
实验材料的编制过程为:首先,参考《现代汉语频率词典》挑选词义相近、笔画数匹相配,但词频差异较大的名词词对。然后,参照这些词对编造框架句子,框架句子完全由7 或6 个词汇构成,词对中的两个词汇(高频词和低频词)都可以放置在同一框架句子中相同的接近句子中间的位置(第三或第四个词的位置)。以“战士-官兵”词对(“战士”为高频词,“官兵”为低频词)举例见图1 所示,在同一位置,框架句子既能包含词汇“战士”形成完整句子“司令调集后方战士支援前线”也能包含词汇“官兵”形成完整句子“司令调集后方官兵支援前线”。
框架句子编制完成后,让10 位未参与实验的大学生对实验材料进行通顺性评定,所选取的句子的平均通顺性为6.48(7 点评定,分值越高代表越通顺);另外10 名未参与正式实验的本科生根据目标词位置以前内容填充补全句子,依此评估和控制词对中两个词汇的预测性程度,最终获取词对内两个词汇的预测性程度差异不显著(高频词汇预测比例: M=0.08, SD=0.14, 低频词汇预测比例: M=0.04, SD=0.12, t=1.57, p>0.05), 参照《现代汉语频率词典》确定目标词汇的整词词频,以及词内汉字的字频。最终所选取的词对中高频词与低频词汇的词频差异显著(t=6.73, p<0.05),高频词与低频词汇的首字字频差异不显著(t=0.08,p>0.05),高频词与低频词汇的尾字字频差异不显著(t=1.27, p>0.05),高频词与低频词汇的首字笔画数差异不显著(t=0.63, p>0.05),高频词与低频词汇的尾字笔画数差异不显著(t=1.62, p>0.05)和高频词与低频词汇的整词笔画数差异不显著(t=0.88, p>0.05)。词对中两个词汇的整词词频,首字字频、尾字字频、首字笔画数、尾字笔画数和整词笔画数的均值见表1。
正式实验中设置了16 个阅读理解判断题,以确定被试是否认真阅读句子。为让被试理解并熟悉实验过程,在正式实验前先进行练习,练习中共包含另外的10 个阅读句子,其中穿插有4 个判断题。

表1 高/低频词汇的整词词频、词内汉字字频和整词笔画数、词内汉字笔画数参数
2.1.3 实验仪器
通过加拿大SR 公司生产的Eye Link1000 型桌面式眼动仪记录被试的眼动。该设备的采样频率为1000 Hz。句子呈现在19 英寸的DELL 显示器上,显示器分辨率为1024×768,刷新频率为75 Hz。被试距离刺激呈现屏幕54 cm。
2.1.4 实验程序
每个被试单独施测。被试进入实验室坐好后,下颚置于头托,要求其尽量不要移动头部。实验开始前呈现指导语,确保被试理解整个实验程序后对仪器进行校准。校准结束后开始练习,被试理解并熟悉整个实验过程后开始正式实验。完成整个实验大约需要15 分钟。
2.1.5 实验设计
实验采用边界范式呈现“预视中词内字序颠倒条件”下的实验材料。实验设计为2(目标词汇呈现方式: 控制条件vs 预视中词内字序颠倒条件)×2(目标词词频: 高频vs 低频)完全被试内设计。控制条件是呈现方式没有做任何处理的呈现条件。预视中词内字序颠倒条件是在预视阶段(注视点越过目标词左侧边界之前)组成目标词的两个汉字的位置顺序被颠倒,注视点一旦越过目标词左侧边界词内汉字顺序立刻恢复正常(边界在实际实验中不可见),比如,以包含目标词汇“战士”的实验句子为例,在“预视词内字序颠倒条件”的呈现方式为:在注视点越过目标词汇左侧边界之前,目标词汇的呈现方式为“士战”,注视点越过目标词汇左侧边界的同时,目标词汇的呈现方式变为“战士”(见图2 所示)。采用拉丁方排列顺序平衡4 个实验条件与实验句子材料。40 个句子均随机呈现。
2.2 结果
被试对于问题回答的正确率都在85% 以上,且呈现条件主效应不显著(p>0.05),表明被试均认真阅读各种呈现条件下的句子。注视点的持续时间过长或是过短都被认为不能反映正常的词汇加工,根据以往研究的做法将小于80ms 或大于800ms 的注视点数据剔除(Angele, Slattery, Yang,Kliegl, & Rayner, 2008; Yang, Wang, Xu, & Rayner,2009),总计剔除数据小于4.5%。根据本研究的目的,报告基于目标词汇兴趣区域的跳读概率和凝视时间两项指标。跳读概率是指第一遍阅读中被跳读的目标词数与其总目标词数之间的比率;凝视时间则是第一遍阅读中在目标词汇兴趣区内所有注视点持续时间之和(离开目标词汇兴趣区后再次进入兴趣区的注视点不在考虑范围内)。词汇的跳读概率反映预视阶段内的词汇加工(Reichle, Rayner, & Pollatsek, 2003),因而不能作为衡量整体词汇加工过程的决定性参考。由于预视效应普遍存在(Rayner, 1998),因而凝视时间同时反映预视和注视阶段内的词汇加工,因而该指标能够较为完整地反映词汇加工过程。采用lme 4 包构建线性混合模型在R 中分析上述指标,其中凝视时间作为连续变量处理,跳读概率被作为两分变量处理(Baayen, Davidson, & Bates, 2008; Bates,Mächler, & Bolker, 2011; Barr, Levy, Scheepers, & Tily,2013)。鉴于跳读概率本身还会损失部分信息,故从反映词汇加工的完整性和敏感性方面考虑,本研究主要基于“凝视时间”指标结果做出推论,将“跳读概率”作为辅助性指标说明研究问题。表2 列出了实验一各条件下基于被试的跳读概率和凝视时间均值和标准差。
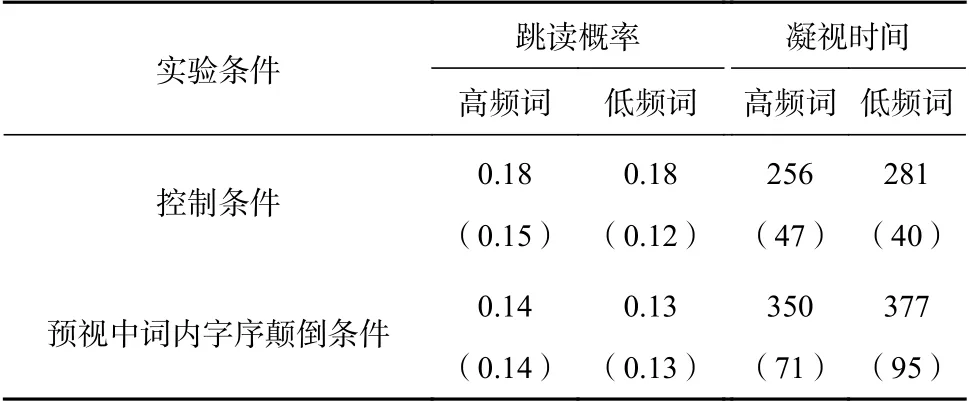
表2 实验一各实验条件下目标词跳读概率和凝视时间的均值和标准差
目标词汇的跳读概率的结果发现,词频效应不显著b=0.08,SE=0.25,z=0.32;目标词呈现方式主效应不显著b=0.05,SE=0.26,z=0.20;目标词汇呈现方式与词频间交互作用不显著b=0.08,SE=0.36,z=0.23。目标词汇上的凝视时间的结果发现,读者对高频目标词汇的凝视时间显著少于对低频目标词汇的凝视时间b=25.12,SE=11.38,t=2.21,p<0.05;预视中词内字序颠倒条件显著高于控制条件b=92.318,SE=11.39,t=8.11,p<0.05;目标词汇呈现方式与词频间的交互作用不显著b=1.24,SE=16.10,t=0.08。
2.3 讨论
实验一考察预视中词内字序颠倒对词频效应的影响,结果发现:预视中将目标词汇两个汉字的位置颠倒会导致凝视时间增加,说明预视中词内字序编码影响该阶段内的词汇加工过程;但预视中颠倒词内汉字的顺序并不影响词频效应,说明预视阶段内的词汇加工过程并不严格依赖于词内汉字顺序编码。为进一步研究注视阶段内词汇识别对词内字序编码的依赖性特点,继续进行实验二。
3 实验二:注视中词内字序颠倒对词频效应的影响
目的:考察注视中词内字序编码对词频效应的影响,澄清在该阶段内词汇加工对词内汉字顺序编码的依赖性特点。实验假设:如果注视中词内字序颠倒不影响词频效应表明,该阶段内词汇加工不完全依赖于词内汉字顺序编码;否则则说明该阶段内词汇加工严格依赖于词内汉字顺序编码。
3.1 方法
3.1.1 被试
某大学36 名大学生参加本次实验,其中男生14 名、女生22 名。被试的视力或矫正视力正常,之前均未参加过类似实验。实验结束后可获得报酬20 元。
3.1.2 实验材料、实验仪器和实验程序
实验材料、实验仪器和实验程序同实验一。
3.1.3 实验设计
实验采用边界范式呈现“注视中词内字序颠倒条件”下的实验材料。实验设计为2(目标词汇呈现方式: 控制条件vs 注视中词内字序颠倒条件)×2(目标词词频: 高频vs 低频)完全被试内设计。注视中词内字序颠倒条件则是在预视阶段(注视点越过目标词左侧边界之前)组成目标词的两个汉字的相对位置顺序正确,注视点一旦越过目标词左侧边界词内两个汉字的顺序颠倒(举例见图3 所示, 边界在实际实验中不可见),比如,以包含目标词汇“战士”的实验句子为例,在注视词内字序颠倒条件的呈现方式为:在注视点越过目标词汇左侧边界之前,目标词汇的呈现方式为“战士”,注视点越过目标词汇左侧边界的同时,目标词汇的呈现方式变为“士战”(见图3 所示)。采用拉丁方排列顺序平衡4 个实验条件与实验句子材料。40 个句子均随机呈现。
3.2 结果
被试对于问题回答的正确率都在85% 以上,且呈现条件主效应不显著(p>0.05),表明被试均认真阅读各种呈现条件下的句子。实验二选取的因变量眼动指标,及其剔除标准与实验一相同。采用与实验一完全相同的方法分析这两个因变量指标。表3 列出了实验二各条件下基于被试的跳读概率和凝视时间均值和标准差。
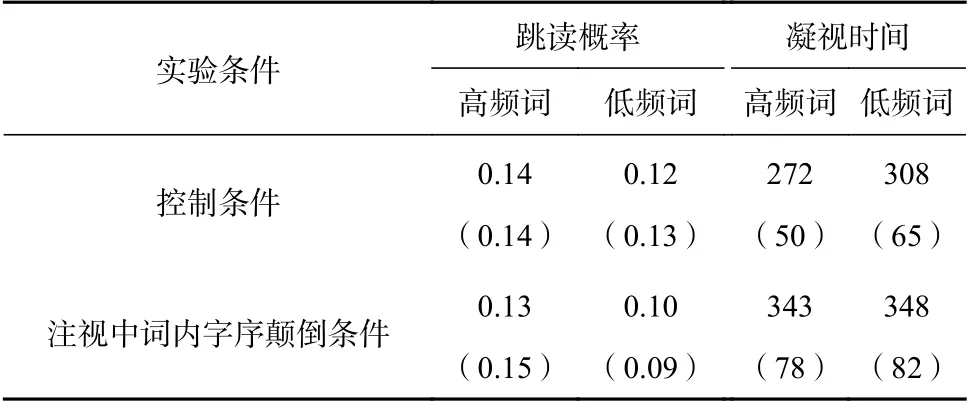
表3 实验二各条件下目标词兴趣区内跳读概率和凝视时间的均值和标准差
目标词汇的跳读概率的结果发现,词频主效应不显著b=0.33,SE=0.24,z=1.35;目标词呈现方式主效应不显著b=0.10,SE=0.22,z=0.46;目标词汇呈现方式与词频间交互作用不显著b=0.14,SE=0.33,z=0.42。目标词汇凝视时间的结果发现,词频效应不显著b=3.75,SE=10.60,t=0.35;目标词汇呈现方式主效应显著b=71.35,SE=10.43,t=6.84,p<0.05;目标词汇呈现方式与词频间的交互作用显著b=34.17,SE=14.77,t=2.31,p<0.05,这种交互作用表现在控制条件下高频词汇与低频词汇上凝视时间差异显著(p<0.05),在注视中词内字序颠倒条件下高频词汇与低频词汇上的凝视时间差异不显著(p>0.05)。
3.3 讨论
实验二通过考察注视中词内字序颠倒对词频效应的影响,确定该阶段内词汇识别对词内字序编码的依赖性特点。结果发现,注视中将目标词汇两个汉字的位置颠倒会导致凝视时间增大,这意味着注视阶段词内字序编码影响该阶段内的词汇加工过程;目标词汇呈现条件和词频在凝视时间指标上的交互作用显著,简单效应分析表明注视中词内字序颠倒条件导致词频效应消失,这意味着注视阶段内的词内汉字顺序编码会影响词频效应。总之,实验二结果说明,注视阶段内的词汇识别过程较为严格地依赖于词内字序编码。
4 总讨论
中文词汇大多数由两个或以上的汉字按照固定顺序排列组成,识别词汇必须获取词内汉字的顺序编码。编码汉字顺序是自下而上加工(Gomez et al., 2008),扰乱词内汉字顺序必将影响自下而上文字识别加工过程,词频效应则是文字识别是否达到词汇水平的参照标准(Blythe et al., 2009),故本研究中包含的两项实验分别考察预视阶段与注视阶段内词内字序颠倒对词频效应的影响,推测词汇识别依赖性词内字序编码的阶段性特点。结果发现,预视阶段和注视阶段颠倒目标词内两个汉字的相对位置,都导致目标词汇上凝视时间增加,说明词内字序编码对词汇加工有重要作用;然而,预视阶段内词内字序颠倒条件不影响词频效应,注视阶段词内字序颠倒条件则会导致词频效应消失,说明词汇识别对词内字序编码的依赖性随着加工时间的推进而逐渐增加。总的来说,本研究对于深化理解阅读中的字、词加工,及其相互作用有一定价值。
首先,以往研究显示,汉字顺序编码是在明确词边界基础上的词内汉字顺序编码(Gu & Li,2015)。汉字加工是词汇识别的必经环节(Li et al,2009, 2014; Ma, Li, & Rayner, 2015; 李兴珊等,2011),词频效应是文字识别加工达到词汇水平的参照标准(Blythe et al., 2009),因而预视中词内字序颠倒只是消极影响眼动过程,而并没有影响词频效应,说明读者对目标词汇的预视加工程度还停留在汉字层面,尚不能达到词汇水平,这与以往的研究结论一致(Ma et al., 2015)。由此可见,本研究结果说明,词汇成功识别之前对汉字的识别是非常必要的加工环节,从而再次验证李兴珊等人提出中文字词加工模型的合理科学性,该模型认为,中文阅读中词切分与词汇加工必须经历汉字加工与词汇加工两个环节,而这两个环节之间是相互影响的关系(Li et al., 2009; 李兴珊等, 2011)。
其次,考察注视中词内字序编码对词频影响则可以探索较晚期的字词加工过程特点。实验二发现,在注视中颠倒目标词内两个汉字的相对位置导致注视时间增加,并完全消除的词频效应,结合实验一的结果,可得出以下结论:一、中文词汇(多字词)的基本构成单元是汉字,识别词汇意味着首先必须识别其组成汉字,注视中颠倒词内汉字顺序条件干扰了汉字加工,说明中文读者在注视阶段中仍要进行汉字加工。二、预视中干扰汉字加工不影响词频效应(实验一),注视中干扰汉字加工则导致词频效应消失,说明词频变量仅能影响注视阶段内较晚期的文字加工。三、预视中词内汉字顺序颠倒条件和注视中词内汉字顺序颠倒条件都导致凝视时间增加,说明阅读中词汇加工的整个过程都受到汉字加工的影响。
最后,本研究发现,颠倒目标词汇词内汉字顺序会普遍地导致凝视时间增加,这意味中文阅读中的词汇加工依赖于词内字序编码。综合两项实验的结果可知,词汇加工的早期阶段较为灵活地依赖词内字序编码,但随着加工的深入,词汇识别更加严格地依赖词内字序编码。根据交互激活假设,词内汉字顺序信息早在词汇加工的初期就已经被严格编码,晚期同样遵守严格的词内字序编码原则,因此字词交互激活假设不能解释本研究的结果。有研究者主张,引人词汇加工灵活地依赖词内字序编码机制有利于完善字词交互激活模型(Gu & Li, 2015; 滑慧敏, 顾俊娟, 林楠, 李兴珊, 2017),而根据本研究结果还可以深入推测,引人“词汇加工对词内字序编码的依赖程度随着加工深入逐步增大”的机制,利于进一步增加字词交互激活理论对中文阅读字词加工现象的解释力。
5 结论
预视阶段内的词汇加工并不严格依赖词内字序编码,注视阶段内的词汇识别则较为严格地依赖于词内字序编码。随着加工的深入词汇识别对词内字序编码的依赖变得越来越严格。
