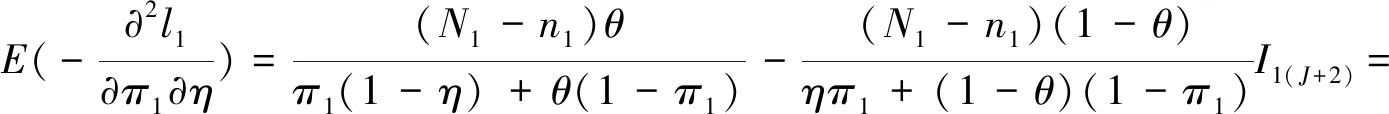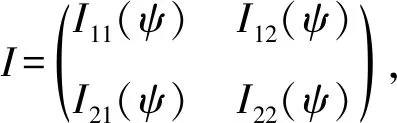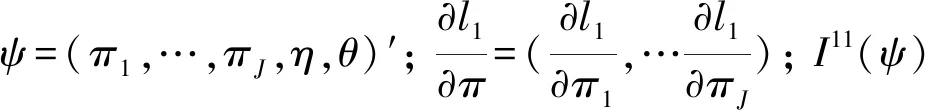基于有金标准下的部分核实数据对疾病流行率的齐性检验
2019-06-14刘多伟邱世芳
刘多伟,邱世芳,何 杰
(重庆理工大学 理学院, 重庆 400054)
在临床实验和医学研究中,对疾病的流行率进行估计是一项重要的研究工作。为了估计疾病的流行率,需要对感兴趣的总体是否患有某种疾病进行诊断。为了节约成本或更快获得诊断结果,常使用一种价格便宜、能迅速获得结果但有误判的筛检方法进行第一次诊断,而利用这种有误判数据去估计流行率又会导致有偏的结果(Bross[1])。为此,没有误判的金标准常用于进一步诊断。但是,金标准往往价格昂贵、对被检验个体有伤害等不足,因而不适用于每个个体。为此,Tenenbein[2]提出了一种折中的抽样方法——二重抽样。所谓二重抽样,是指从感兴趣的总体中随机抽取N个个体,使用筛检方法对他们进行诊断,然后从中再随机抽取n个个体接受金标准诊断。由于这n个个体接受了两种诊断,它反映了个体的真实特征并对筛检方法的分类结果进行了核实,因而这种二重抽样方法获得的数据又被称之为部分核实数据[3]。
基于部分核实数据的统计研究已成为重要的研究课题。自Tenenbein[2]提出基于二分类数据估计二项比例的二重抽样方法以来,已有大量文献进行了研究。如Tenenbein[4]将二重抽样框架推广到多项分布数据的研究中, Yiu等[5]基于潜在变量模型研究了二重抽样数据的统计推断。最近,Tang等[6-7]对于部分核实数据的统计推断进行了一系列的研究,给出了单组样本下基于部分核实数据对疾病流行率的假设检验、区间估计以及样本量的统计推断方法,以及两组独立样本下基于疾病流行率差的统计推断方法[8-9]。当金标准不存在时,基于不完全无误的“金标准”下的部分核实数据,Qiu等[10-11]给出了疾病流行率的假设检验过程、区间估计以及样本量的确定方法;邱世芳[12]研究了在给定的置信水平下,区间宽度控制在给定范围内的样本量的估计公式。但是,疾病流行率可能与个体的年龄、性别或病人是否吸烟、喝酒等生活习惯有关。因此,为了避免这些不同因素带来的混杂效应,常将这些因素看作分层变量考虑分层设计下的统计推断。对于不同的层,疾病流行率是否有显著的不同是人们关心的问题。为此,本文将研究在金标准存在时基于分层设计下的部分核实数据对疾病流行率的齐性检验过程。
1 模型与参数估计及检验统计量
1.1 模型与参数估计
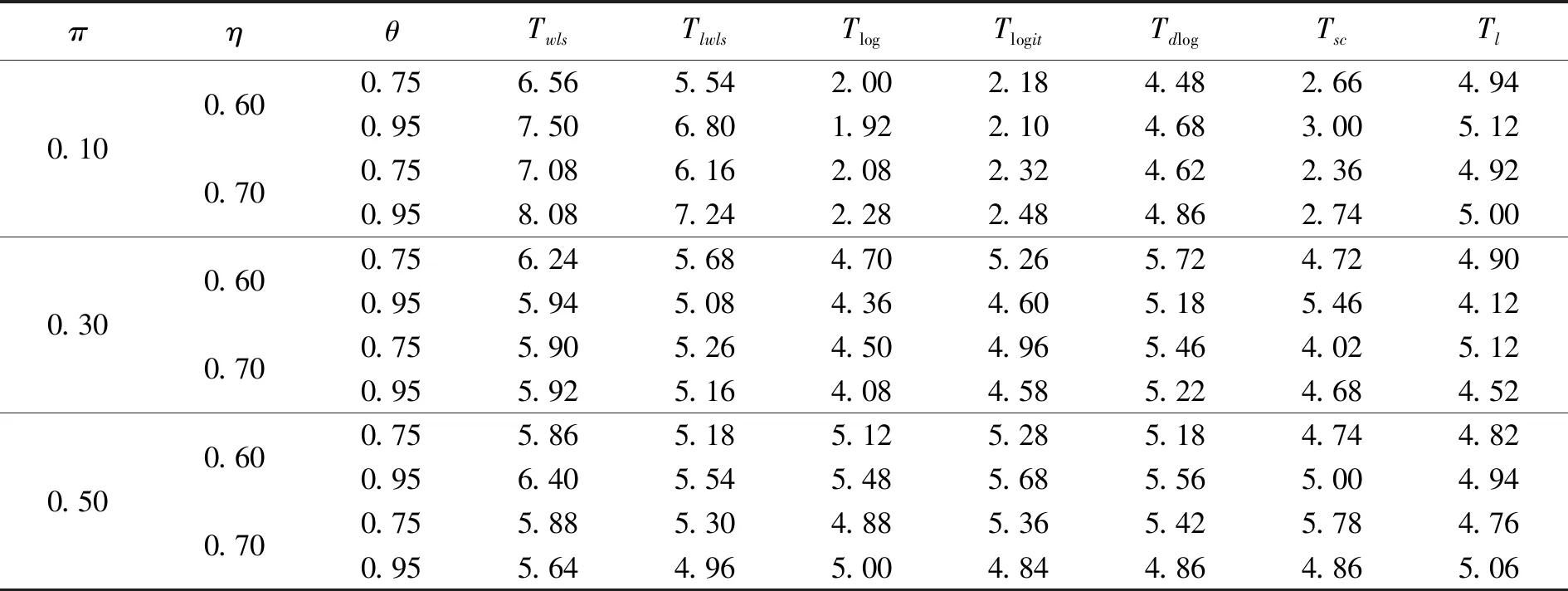
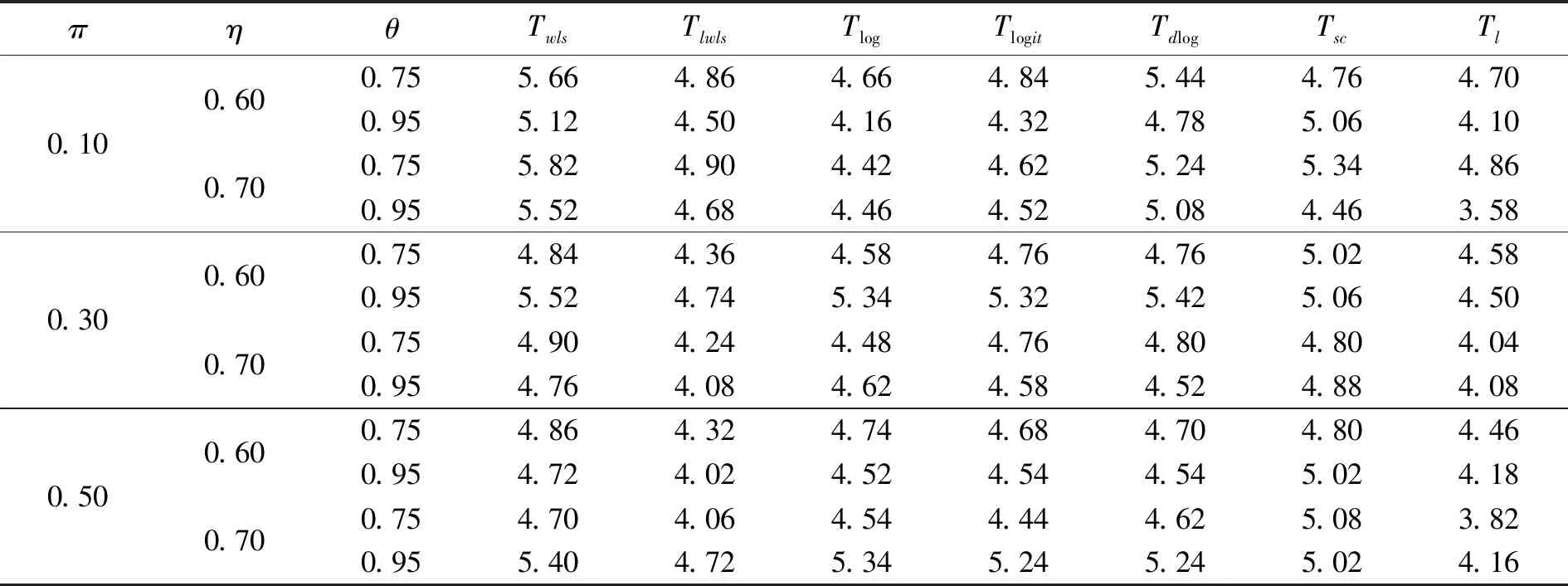
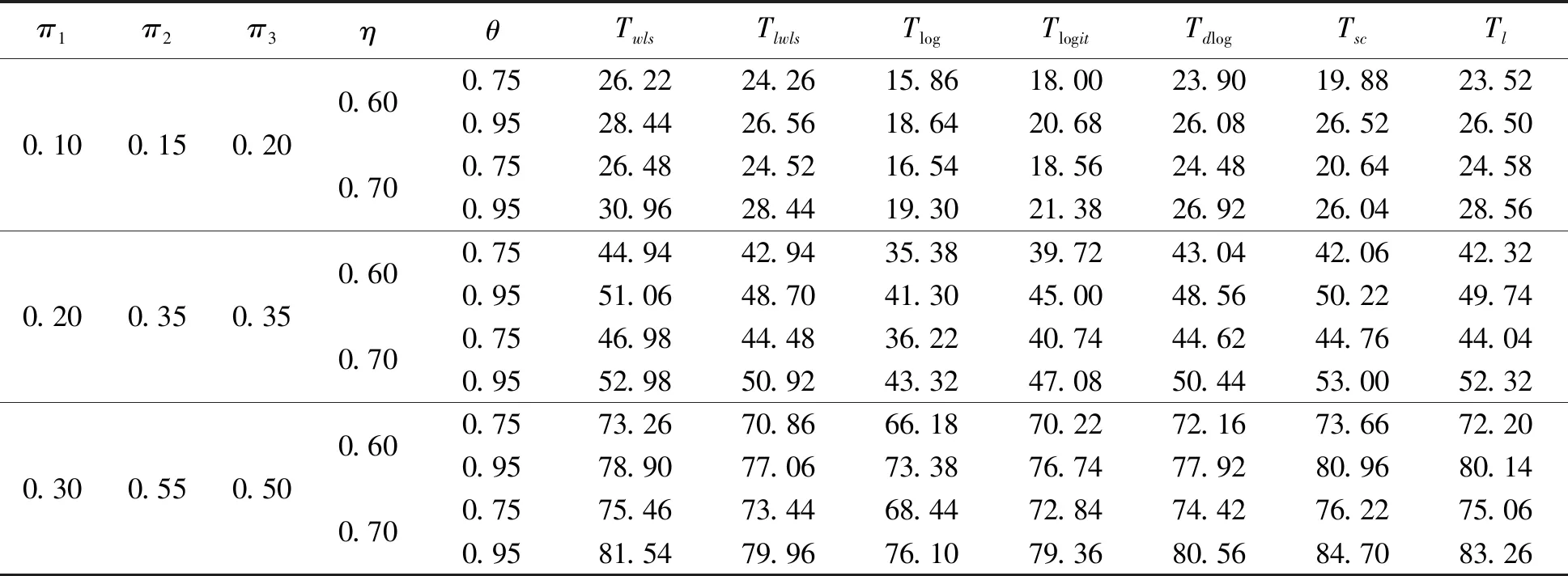
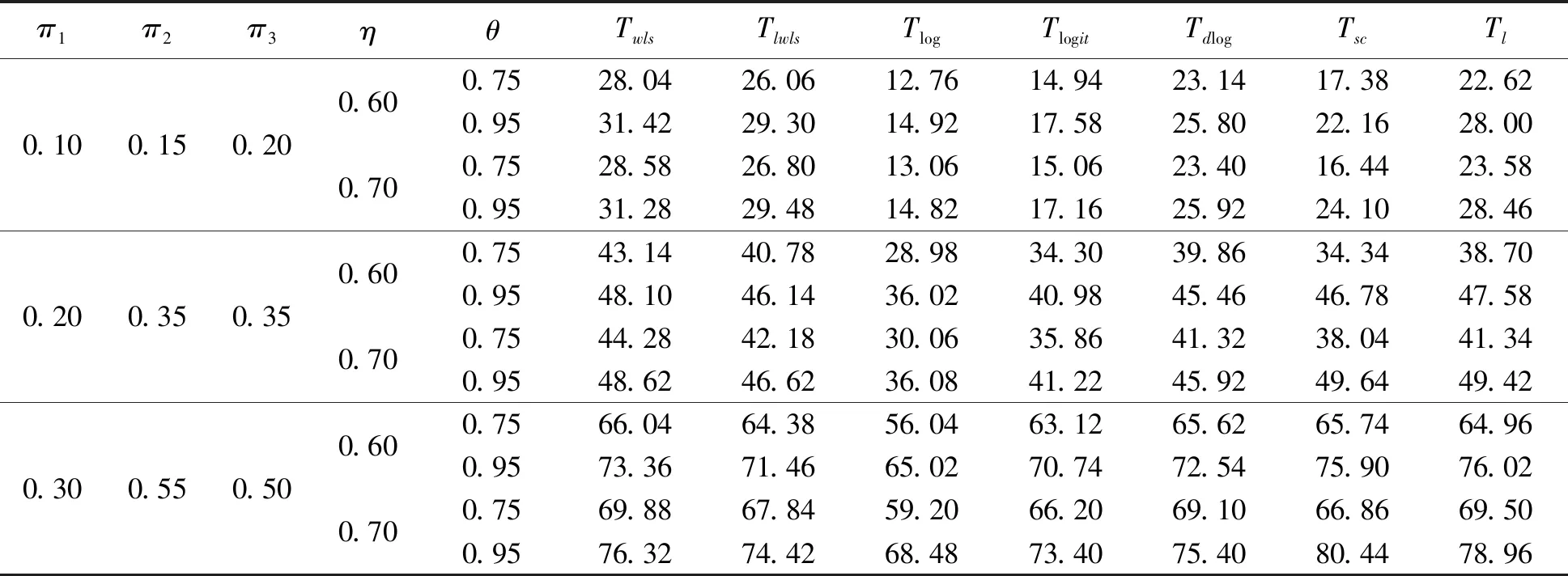
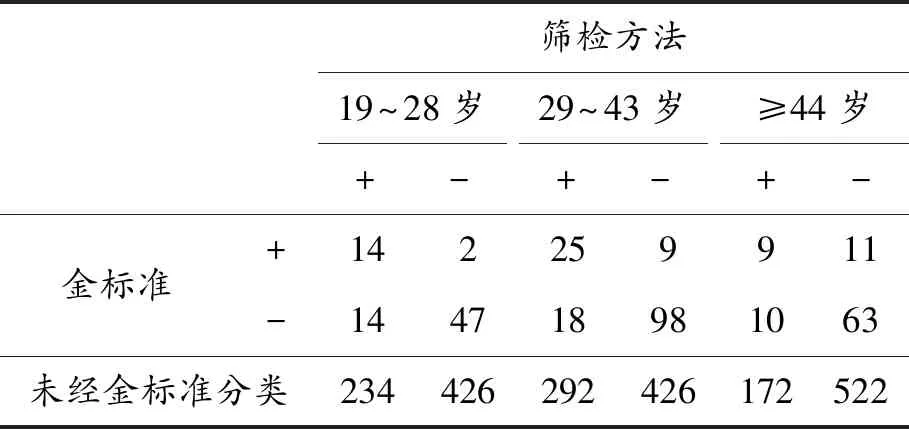
假设从第j个总体中随机抽取了Nj个个体,每个个体都接受筛检检验,检验结果记为Fj。假设Fj=1表示该个体检验为阳性,否则,Fj=0;不考虑筛检的结果和其他因素,从这Nj个个体中再随机抽取nj(nj 令πj=P(Dj=1)为在第j组中被诊断为患病的概率;筛检方法的敏感度为ηj=P(Fj=1|Dj=1);特异度为θj=P(Fj=0|Dj=0)。假设ηj=η,θj=θ对所有j=1,2,…,J,易知pj=πjη+(1-θ)·(1-πj)。概率结构如表1所示。 表1 第j组的数据和概率结构 本文研究如下的假设检验:H0:π1=π2=…=πJ↔H1:π1,…,πJ不全相等。令m={(n11j,n10j,n01j,n00j,xj,yj)′,j=1,…,J},π=(π1,…,πJ)′,则对数似然函数为: l1=l1(m;π,η,θ)= A1+n11+log(η)+n10+log(1-η)+ n00+log(θ)+n01+log(1-θ)+ (n01j+n00j)log(1-πj)+ xjlog(pj)+yjlog(1-pj)} j=1,2,…,J 求解以上方程组,可以得到πj(j=1,…,J),η,θ的非限制性极大似然估计。其中: j=1,2,…,J (1) (2) 在原假设H0:π1=π2=…=πJ下,不妨令π1=π2=…=πJ=π,则对数似然函数为: l=l2(m;π,η,θ)= A2+(n11++n10+)log(π)+ (n01++n00+)log(1-π)+n11+log(η)+ n10+log(1-η)+n00+log(θ)+ n01+log(1-θ)+x+log(p)+y+log(1-p) 其中:A2是常数;p=p(π,η,θ)=πη+(1-θ)(1-π)。根据Tang等[3],易得π、η、θ的限制性极大似然估计分别为: 对于齐性检验:H0:π1=π2=…=πJ↔ H1:π1,…,πJ不全相等。本文考虑了如下检验统计量。 1.2.1加权最小二乘统计量 (3) 在原假设成立的情况之下,当Nj,nj→∞(j=1,…,J),Twls~χ2(J-1),其中χ2(J-1)表示自由度为J-1的卡方分布。 1.2.2加权最小二乘统计量的对数变换统计量 为了使加权最小二乘统计量Twls更接近正态分布,根据Fisher[14],考虑对检验统计量Twls进行对数变换后的统计量: Tlwls={log(Twls/(J-1))/2+ (4) 当Nj,nj→∞(j=1,…,J),该检验统计量渐近服从标准正态分布,即当Tlwls≥z1-α,则拒绝原假设,其中z1-α为标准正态分布的上α分位数。 1.2.3基于对数变换的加权最小二乘检验统计量 (5) 1.2.4基于logit变换的加权最小二乘检验统计量 (6) 1.2.5基于双对数变换的加权最小二乘检验统计量 (7) 1.2.6Score检验统计量 通过非限制性的对数似然函数,可得到关于向量π=(π1,…,πJ)′的一阶偏导数,根据Score检验的一般理论(Rao[15]),可以给出检验H0:π1=π2=…=πJ的Score统计量为: (8) pj=πjη+(1-θ)(1-πj),j=1,…,J。 在原假设H0成立下,当Nj,nj→∞(j=1,…,J),Tsc~χ2(J-1)。 1.2.7似然比检验统计量 通过以上给出的对数似然函数l1(m;π,η,θ)和H0:π1=π2=…=πJ下的对数似然函数l2(m;π,η,θ),可进一步考虑如下的似然比检验统计量: Tl=2{l1(m;π,η,θ)-l2(m;π,η,θ)} (9) 根据似然比检验理论可知,在原假设成立时,当Nj,nj→∞(j=1,…,J),Tl~χ2(J-1)。 设ti是检验统计量的Ti(i=wls,lwls,log,logit,dlog,sc,l)的样本观测值,根据这些检验统计量的渐近分布,在显著性水平α下拒绝H0:π1=π2=…=πJ,当 或者 tlwls≥z1-α 为了考察本文提出的检验统计量的统计性质,通过Monte Carlo模拟方法对基于以上检验统计量的各种检验过程进行评价。考虑了J=3的模型和如下的样本量:平衡样本量设计① 小样本(n1,n2,n3,N1,N2,N3)=(30,30,30,50,50,50);② 中等样本(n1,n2,n3,N1,N2,N3)=(50,50,50,100,100,100);③ 大样本(n1,n2,n3,N1,N2,N3)=(200,200,200,500,500,500)和(4)非平衡样本(n1,n2,n3,N1,N2,N3)=(40,50,60,100,80,100)。为了考察每个检验统计量犯第一类错误的概率,在以上设置的各种样本量下,考虑参数设置:π=0.1,0.3,0.5,η=0.6,0.7,θ=0.75,0.9,即考虑了3(π的值)×2(η的值)×2(θ的值)=12种参数组合。 为了考察每个检验统计量的经验功效,考虑参数设置:η=0.6,0.7,θ=0.75,0.9,(π1,π2,π3)=(0.1,0.15,0.2),(0.2,0.35,0.35),(0.3,0.55,0.5),即考虑了3×2×2=12种参数组合。对于每个样本量和每种参数组合,随机产生5 000组随机样本{(n11j,n10j,n01j,n00j,xj,yj):j=1,2,3}分别计算本文提出的7种检验统计量的值,其中,{(n11j,n10j,n01j,n00j):j=1,2,3}从多项分布(nj:πjη,πj(1-η),(1-θ)(1-πj),θ(1-πj))中产生,{(xj,yj):j=1,2,3}从二项分布(Nj-nj:pj,1-pj)中产生,进而估计每个检验统计量下犯第一类错误的概率和检验功效。其中,犯第一类错误的概率估计公式为:被检验统计量T拒绝的次数/5 000(H0成立下),经验功效的估计公式为:被检验统计量T拒绝的次数/5 000(H1成立下)。显著性水平α=0.05,犯第一类错误的模拟结果如表2~5所示。 由于篇幅的限制,本文只列出了中等样本(平衡设计和非平衡设计)下的经验功效的模拟结果,如表6和表7所示。 表2 小样本(n1,n2,n3,N1,N2,N3)=(30,30,30,50,50,50)下各种检验统计量犯第一类错误的概率(%)(显著性水平为α=0.05) 表3 中等样本(n1,n2,n3,N1,N2,N3)=(50,50,50,100,100,100)下各种检验统计量犯第一类错误的概率(%)(显著性水平为α=0.05) 表4 大样本(n1,n2,n3,N1,N2,N3)=(200,200,200,500,500,500)下各种检验统计量犯第一类错误的概率(%)(显著性水平为α=0.05) 表5 不平衡样本(n1,n2,n3,N1,N2,N3)=(40,50,60,100,80,100)下各种检验统计量犯第一类错误的概率(%)(显著性水平为α=0.05) 表6 中等样本(n1,n2,n3,N1,N2,N3)=(50,50,50,100,100,100)下各种检验统计量的检验功效(%)(显著性水平为α=0.05) 表7 不平衡样本(n1,n2,n3,N1,N2,N3)=(40,50,60,100,80,100)下各种检验统计量的检验功效(%)(显著性水平为α=0.05) 根据模拟结果可知,① 即使在小样本(如(n1,n2,n3,N1,N2,N3)=(30,30,30,50,50,50))下,似然比检验统计量都表现很好,其犯第一类错误的概率都很接近给定的显著性水平且具有较高的功效;② 除了π很小(如π=0.1)外,即使在样本量较小的情况下,score统计量都能很好地控制其犯第一类错误的概率且具有较高的检验功效;③ 随着样本量的增大,各个统计量犯第一类错误的概率都越来越接近名义水平,特别地,当样本量较大(如(n1,n2,n3,N1,N2,N3)=(50,50,50,100,100,100))时,Tlog、Tlogit、Tdlog也能够很好地将犯第一类错误的概率都控制在名义水平左右。综上所述,从各个检验统计量犯第一类错误的概率和检验功效角度研究,可以看出统计量Tsc、Tl总是具有较好的统计性质,因而实际应用中推荐使用这两个统计量。当样本量较大时,Tlog、Tlogit、Tdlog也值得推荐。 为了评价本文所提出的检验统计量的统计性质,本文利用Nedelman[16]中的疟疾数据来说明本文提出方法的有效性。世界卫生组织和尼日利亚加尔基当地政府为了研究当地疟疾的患病率,分别考虑了调查的方法、村庄类型、年龄、性别等不同因素对当地疟疾患病率的研究。为了研究不同年龄对疟疾患病率的影响,本文选取了3个年龄段(成年人数据):即19~28岁、29~43岁、≥44岁的调查数据进行分析,数据如表8所示。 表8 尼日利亚加尔基疟疾数据 注:+表示阳性,-表示阴性。 为了研究基于分层设计下的部分核实数据的疾病患病率是否相等的问题,即对于如下的齐性检验:H0:π1=π2=…=πJ↔ H1:π1,…,πJ不全相等,本文提出7种检验统计量Twls、Tlwls、Tlog、Tlogit、Tdlog、Tsc、Tl,并通过随机模拟研究了各种检验统计量的统计性质,即研究了基于这些检验统计量的渐近检验过程的犯第一类错误的概率和经验功效。模拟结果表明,Tsc、Tl统计量不论犯第一类错误还是经验功效都表明基于它们的齐性检验过程都有良好的表现,即它们犯第一类错误的概率接近名义水平,同时具有较高的功效,因此,在实际应用中推荐使用。当样本量较大时,Tlog、Tlogit、Tdlog也能很好地控制犯第一类错误的概率,因而被推荐使用于实际应用中。 附录:Score检验统计量的推导 由对数似然函数l1,可得到Fisher信息阵为: I(J+1)1=I1(J+1) 则I11(ψ)是J×J矩阵,I12(ψ)是J×2矩阵,I21(ψ)是2×J矩阵,I22(ψ)是2×2矩阵。 在原假设H0成立之下的Score检验统计量为
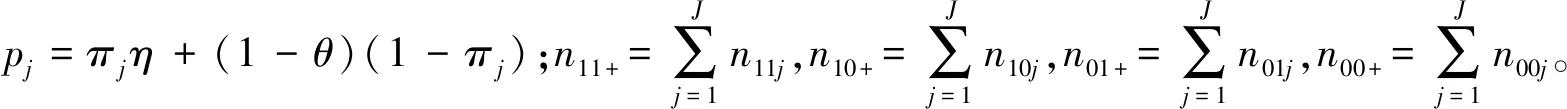
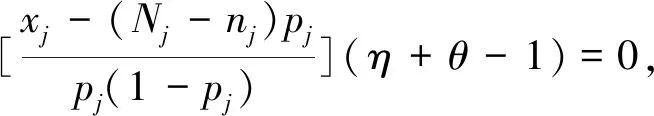
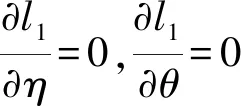
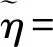
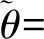

1.2 齐性检验统计量
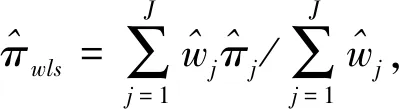
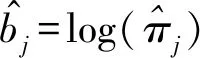
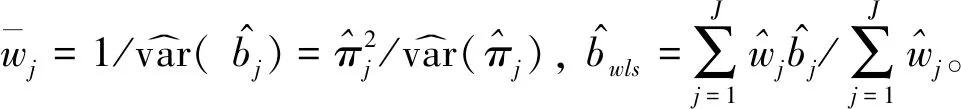
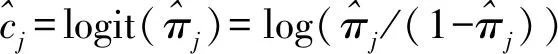
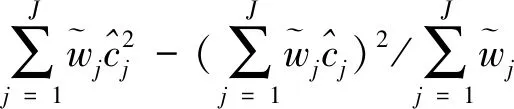
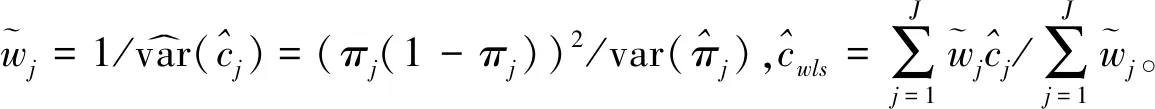
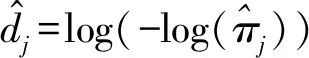
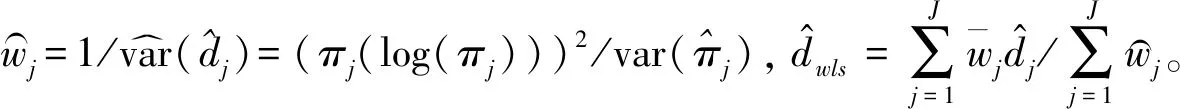
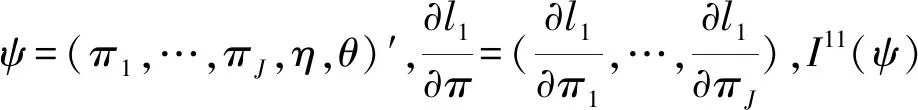
1.3 渐近的检验过程
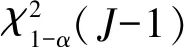
2 模拟研究


3 实际数据分析
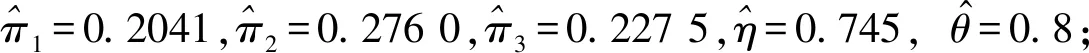
4 结论