基于激活漏洞能力条件的软件漏洞自动分类框架
2019-06-14王飞雪
王飞雪,李 芳
(1.重庆人文科技学院 计算机工程学院, 重庆 401524; 2.重庆大学 计算机学院, 重庆 400044)
随着软件系统的发展,软件漏洞识别变得越来越重要[1-3]。能导致未经授权的用户破坏系统安全策略的特定类型的缺陷称为漏洞或安全漏洞。漏洞是信息系统安全领域的重大威胁[4]。例如,2012年,FLAME病毒攻击了中东地区使用微软操作系统的计算机,该病毒利用操作系统的数字签名欺骗漏洞进行自我隐藏[5]。计算机应急响应小组称,软件开发中的大量漏洞是在其他系统中重复检测到的漏洞。
目前,关于安全漏洞和缺陷分类策略分析方面的文献较少。对影响失效再现性条件的缺陷分类的研究中,在软件bug类型方面引入了两个定义[6-8]:① 玻尔bug(bohr bug,BB),在测试阶段容易再现的bug; ② 曼德博bug(mandel bug,MB),在测试阶段难以重现的bug。BB是可预知的,其激活和错误传播并不复杂。如果让软件在相同条件下运行, bug可以再次显现。MB是另一种类型的软件缺陷,具有复杂的故障激活或错误传播条件,在复杂条件下触发,且没有规律,不容易重现。采用BB和MB分类法来解决安全性缺陷,从重现性角度分析漏洞。在本文中,具有BB和MB特征的安全漏洞分别称为BV(bohr vulnerability)和MV(mandel vulnerability)。
对于缺陷分类,文献[9]通过文本挖掘bug数据库提出了一种隐藏影响bug识别方法,利用错误报告的文本描述来提取文本信息,文本挖掘过程中提取错误报告的语法信息并压缩信息以便于操作,然后利用压缩信息生成呈现给分类器的特征向量。文献[10] 提出了手动分类的自动替代方法,能根据漏洞描述自动对漏洞进行分类,并使用神经网络和朴素贝叶斯方法评估了该方法。文献[11]中提出了一种新的软件漏洞分类方法,该方法基于漏洞特征,包括错误或资源消耗的累积、严格的时序要求以及环境与软件之间复杂的交互。
对于软件缺陷分类的研究,文献[12]中提出一种软件缺陷检测和分类方法,并集成数据挖掘技术对大型软件库中的缺陷进行识别和分类。文献[13]提出了一种名为USES的基于文本挖掘的解决方案,用于根据故障触发器的概念对错误进行分类,该方法适用于文本错误报告、BB和MB分类以及USES分类。由于文本中可能存在噪声,这两种技术无法提供准确的结果,基于错误报告的分类方法性能高度依赖术语选择和噪声消除的有效性。
针对软件漏洞分类中存在的问题,本文提出一种软件漏洞分类框架,它能够有效区分BV和MV,从文本报告和漏洞代码修复中提取特征,然后采用不同的机器学习技术(随机森林、C4.5决策树、Logistic回归和朴素贝叶斯)来构建静态模型,选择具有最高F值(精确度和召回的加权平均值)的模型来识别未见漏洞的类别。该方法评估了从Bugzilla收集的Mozilla Firefox发布的580个发布后漏洞(发布后发生的漏洞)。结果表明:该方法可以通过C4.5决策树获得69%MV的F值。所提框架能够识别风险文件,指导开发人员增加对故障部件的测试工作。
1 软件漏洞分类框架
本文软件漏洞分类框架包括两个阶段:训练阶段和部署阶段。训练阶段将一组漏洞与漏洞报告、漏洞代码修复和已知漏洞类别相关联。由于所有特征可能不适合区分MV和BV,因此找到了最相关的特征。不同机器学习算法(随机森林、C4.5决策树、Logistic回归和朴素贝叶斯)被用来建立适当的分类。选择具有最高F值的分类器,并将其传递到部署阶段。
部署阶段有2个输入:训练阶段的模型和未知类别的漏洞,用于提取对漏洞进行分类的最具辨别力特征的值。最终,确定漏洞是否属于BV或MV类别。软件漏洞分类框架具体过程见图1。
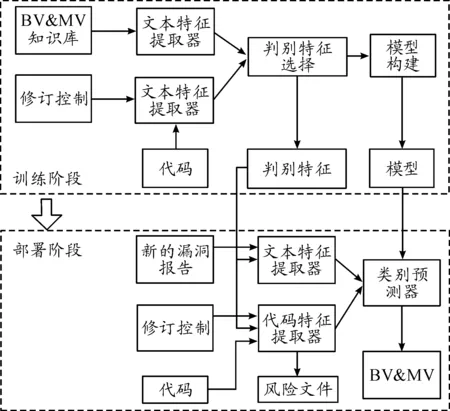
图1 软件漏洞自动分类框架
1.1 文本特征提取
在大多数软件问题研究中,未明确提及激活漏洞的条件,而本文研究中分析了可能与激活条件具有直接或间接关系的特征。某些特征已成功用于缺陷分类,如修复时间和严重性应用在分析大型OSS(开源软件)项目的bug报告中,安全漏洞位置可以作为漏洞分类的分析维度。本文选择4个主要维度:修复时间(time to fix,TTFX)、开发人员、安全漏洞位置和严重性,挖掘漏洞报告的不同部分,包括标题、描述和摘要,以方便使用Python脚本和C代码提取特征。具有相应提取机制的特征将在以下内容中描述。
1) 修复时间(TTFX):TTFX是开发人员用于解决安全问题的时间段,可以显示漏洞对安全缺陷管理的影响。由于MV在再现安全性故障方面比BV更复杂,因此MV可能需要比BV更长的TTFX。
提取机制:在漏洞存储库中,当检测到安全性故障时,将时间记录为报告日期(reported date,RD)。当它被修复时,时间被报告为修改日期(modified date,MD)。在MD和RD之间的时间内,漏洞已打开,该时间段包括4个任务:① 由开发人员重现安全故障;② 认识其根本原因;③ 实施和测试所提出的修复方法;④通过测试验证修复方法。虽然MV的预期TTFX由于其性质而高于BV,但不应预先判断比较。假设有时漏洞的TTFX可能受到其他因素的影响,例如:涉及的开发人员可能同时忙于处理大量漏洞,因此,下一个特征考虑了开发人员的角色。
2) 开发人员:此特征演示了开发人员与漏洞类型之间的关联。具有两个子集:开发人员数量(number of developers,NOD)和开发人员体验(developer experience,DE)
开发人员数量:NOD衡量修复漏洞所需的安全专家人数。本文假设具有复杂激活条件的漏洞会吸引更多开发人员。
开发人员体验:本文假设对于难以重现的安全问题,安全测试人员或专家的知识可以有效地处理类似问题,经历过大量MV的开发人员可能比其他人能更专业地解决复杂的漏洞。
提取机制:为了识别NOD,计算编写注释并尝试解决安全问题的唯一开发人员的数量。有时开发人员可能会写1个以上的评论,本文只计算1次。提取分配了漏洞的专家开发人员(expert developer,ED)的名称,当确定所有漏洞的ED时,检查数据集以确定每个ED解决了多少漏洞。
3) 位置:位置维度表示漏洞出现的位置,位置可以是组件、版本、模块或文件。提取机制:在大多数漏洞存储库中,明确记录了发生安全漏洞的组件和版本。本研究中,根据文件识别系统的易受攻击部分。版本或模块对于统计分析来说很大,细节提取机制在1.2节中描述。
4) 严重性:严重性发现漏洞是否被利用,其后果是从用户的角度来看严重程度,可以具有不同的级别,例如崩溃、数据丢失和内存泄漏。否定此特征背后的动机是实现最终用户是否因BV和MV引起的安全故障而感知到不同的行为。提取机制:开发人员从各自的角度报告每起安全性故障的严重性,可以直接从漏洞数据库的字段中提取此特征值。
1.2 代码特征提取
以确定源代码和漏洞类型之间的更改和修复之间的相关性定义代码特征提取部分。代码修复的复杂性是MV复杂性的一个主要原因,为了测量漏洞代码修复的定量复杂度,提取了3个特征:改变文件的数量(number of changed files,NOC-F)、改变代码行的数量(number of changed (added/deleted) line of code,NOC-LOC)和漏洞修复熵(vulnerability fix entropy,VFE)。
1) 更改文件数:在软件系统中,大多数故障属于少量模块。复杂的代码X过程需要大量的变化,识别潜在易受攻击系统的某些部分对测试人员和质量管理人员有较大的帮助,这可以指导软件开发团队增加对易出现漏洞的系统部分的测试工作,从而提高下一版本中软件的安全性,还可满足时间和预算限制。
2) 更改代码行的数量(添加/删除):假设更多更改的代码行来解决安全问题与更多的代码复杂度相关。
3) 漏洞修复熵:要解决安全问题,可能需要更改多个文件(例如,添加和删除)。开发人员通过许多修改来遵循修复过程并不容易。假设MV复杂性的一个原因可能与修复过程的复杂性有关,与简单漏洞BV相比,修复复杂漏洞MV可能涉及许多文件,因此预计MV具有高熵。
提取机制:漏洞数据库不存储有关代码修复的信息,本文使用Mercurial分布式源代码管理工具(一个分布式修订控制系统)来提取有关源代码的信息。在本地系统复制Mozilla Firefox源代码后下载其提交日志,然后应用文本挖掘算法将安全问题映射到已更改的文件。
寻找到数据集中的漏洞后,存储其相关字段(如父项,日期,文件和摘要)以提取代码特征。这种集成方法取决于开发人员的评论,在修订控制系统中,进行了许多更改以增强系统的一部分而不解决任何安全问题。本文专注于C/C++及其头文件,其他文件类型(如脚本和配置)将被排除在外,从而为每个有风险的文件提取代码特征。在为数据集中的漏洞提取风险文件后,使用版本控制工具的diff命令来获取NOC-LOC。
基于已更改文件列表及其对应的NOC-LOC,通过应用Shannon熵计算漏洞修正熵,定义为:
(1)
其中:v是1个漏洞;n是变化文件的数量;pi是特定文件i的发生概率,其被改变以修复漏洞v。当所有文件具有相同的概率值时,熵是最大的(Hn(v)=1),pi=1/n∀i∈(1,2,…,n),这意味着大量的文件被改变。另一方面,当只有漏洞集中在一个文件中时,熵将是最小的(Hn(v)=0)。为了计算每个漏洞的熵,使用具有相应NOC-LOC的改变文件,然后将Shannon的熵应用于漏洞熵。漏洞熵的计算过程如下:
通过更改fileA和fileB来解决问题。在fileA中分别添加2行和删除5行代码,共7个变化。在fileB中添加4行和删除1行代码,共5个变化。为了计算每个文件的概率,将其改变的LOC除以所有更改的行(在这种情况下为12),则有p(fileA)=7/12,p(fileA)=5/12。为了标准化香农熵,将等式除以ln(n)。对于该过程,归一化的Shannons熵是0.980 864。如果所有变化分散在12个更改行而不是2个更改行上,则漏洞x的熵变为1。
1.3 判别特征选择与模型生成
所有维度可能没有足够的能力来区分BV和MV类别,这是因为不相关或冗余的特征会降低分类器的效率和性能。为了解决这个问题,使用Fisher得分(或Fisher内核)识别最相关的特征。该技术基于标准偏差和特征平均值计算分数,通过等式(2)分别计算每个特征的Fisher得分来判别维度。
(2)
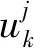
在表示具有最具辨别力的漏洞特征之后,需要知道它们与漏洞类型(BV或MV)的关系,其他系统的关系可能会发生变化。模型构建器部分的目标是构建一个可以根据特征向量学习每个类的特征的分类器。
将1组具有对应类别(BV或MV)的输入给予系统以训练模型;然后,模型根据数据集中实例的特征来学习BV和MV特征。提供各种机器学习算法用于构建模型,每种算法对输入数据做不同的假设,这些假设会影响分类的性能,不同的技术有不同的性能。
选择几种经典机器学习算法,包括随机森林(random forest,RF)、C4.5决策树、Logistic回归(logistic regression,LR)和朴素贝叶斯(naive bayes,NB),在Weka工具包(怀卡托环境知识分析)中使用默认参数值实现。
类别预测器部分使用分类器来标识未见漏洞的类别。对于分类器的选择,采用上述几种经典学习算法中性能最优的算法来实现类别预测。通过对分类指标的分析,计算漏洞属于BV或MV的可能性,最后选择具有最高概率的类别。
2 实验结果与分析
使用MFSA(mozilla foundation security advisory)解决安全问题。考虑到用户数量(大约2.7亿)和代码行(每个版本有超过200万LOC)数量,本研究选择数量较大的Mozilla Firefox项目,从不同版本收集安全缺陷,以确保特定版本不会影响分类器。
软件漏洞分析中大多数漏洞属于以下类别:① 内存错误:内存故障会导致内存损坏、内存安全错误和内存泄漏;② 空指针:可能导致分割故障;③ 验证初始化检查:在没有任何适当初始化的情况下使用资源可能导致信息泄漏或分段错误;④ 竞争条件:允许锁定或链接系统资源;⑤ 访问控制:操作允许获得适当的权限以获得对整个资源的控制。
2005年1月21日——2015年1月13日收集了MFSA中与上述类别相关的软件漏洞。尽管假设在测试阶段可以检测到BV并将其消除,但Mozilla Firefox有非漏洞与BV相关的释放后漏洞数量可忽略不计。一个可能的原因是大型系统的实际测试困难,或者没有足够的测试技术。此外,扩展或修改项目可能给系统带来新的漏洞。在本文研究中,BV和MV的分布几乎相似,53%和47%的漏洞分别属于BV和MV。此外,检测到漏洞的主要比例(725中的702个)属于内存。BV和MV分布取决于所分析系统的性质、系统与硬件设备或与其开发的语言交互的频率。对于使用C/C++开发的系统,由于内存由开发人员管理,所以更容易出现与内存相关的漏洞。
在提取特征值之后,判别特征选择器部分为其计算Fisher分数,然后选择具有大分数的排名靠前的相关特征,如表1所示。
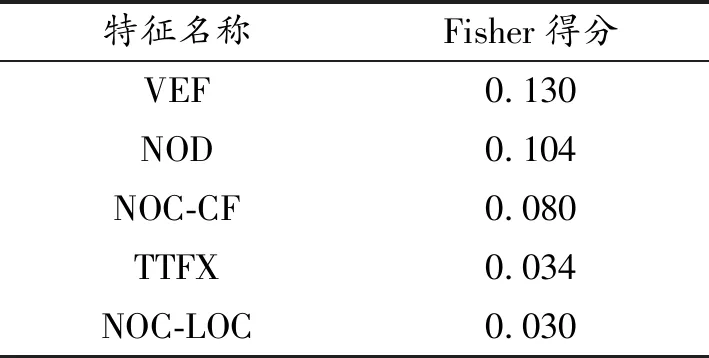
表1 TOP判别特征
尽管MV显示出比BV更复杂的行为,但由MV引起的感知安全性失败与由于开发者的BV导致的安全性失败没有显著差异。本文使用10折交叉验证来进行实验,其中数据集被分为10份,模型学习9份,评估1份,所有正确分类实例的平均值表示模型的准确性。评估指标包括准确率、精确率、召回率和F值。
准确率(Accuracy)表示正确的分类率,在本研究中表示所有漏洞中正确分类的BV和MV的数量。
(3)
精确率Precision表示正确分类到所有分类漏洞的比例作为目标类别,精度是衡量分类器有效性的重要指标。
(4)
召回率Recall也称为检测概率,表示正确分类的漏洞与属于目标类别的所有实际漏洞的比例。具有高召回率的模型具有发现更多漏洞的能力。
(5)
式(3)~(5)中,TP表示被归类为MV的漏洞数量,它们都是真正的MV;FP表示被归类为MV的漏洞数量,它们是真正的BV;TN表示被归类为BV的漏洞数量,它们是真正的BV;FN表示被归类为BV的漏洞数量,它们是真正的MV。
F值表示精确度与召回率的加权调和平均值,召回率和精确度的值不可能同时较高,因此本文采用F值进行最终判断。
(6)
不同分类算法的性能比较结果如表2所示。由于基于安全性失败重现性的漏洞分类没有相关工作,将结果与缺陷分类研究结果进行比较,将其分为BB和MB。
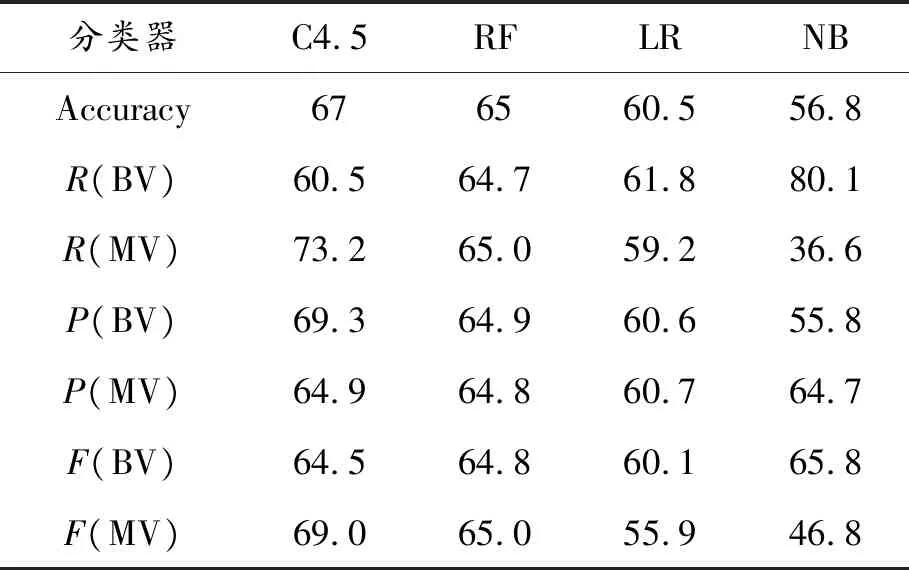
表2 不同分类算法的性能比较 %
所有分类算法的准确度均超过56.8%,表示基于文本报告和代码修复定义度量的效率。具有67%准确度的C4.5决策树,可以识别69%的MV。在漏洞分类中,将BV错误地视为MV相比不检测MV更好,因为它们可以保留在系统中并导致严重的安全故障。
因此得出结论,决策树方法在准确性和F值方面比其他方法获得了更好的结果。主要原因在于其简单性和对数据集中噪声的鲁棒性。具有67%准确度的C4.5决策树可以识别69%的MV。由此认为,在漏洞分类中,将BV错误地视为MV相比检测不到MV更好,因为BV在系统中将导致严重的安全故障。
为了体现本文方法的有效性,将本文算法与文献[13]基于自然语言描述分析缺陷方法进行比较。分类器使用C4.5,实验数据库为Redhat Bugzilla数据集,结果见表3。
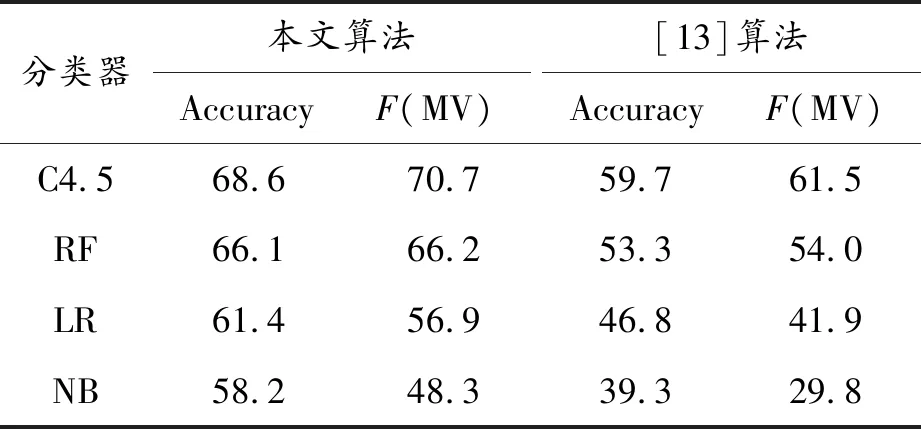
表3 不同软件漏洞算法的性能比较 %
从表中数据可得:无论机器学习方法的类型如何,根据文本错误报告,文献[13]计算的F值范围为29.8%~61.5%,而本文方法获得MV的F值在48.3%~70.7%范围内,说明了本文方法的有效性。
3 结束语
本文提出一种自动软件漏洞分类框架以区分BV和MV。该方法基于文本报告和代码修复定义一组特征,使用不同的机器学习技术来构建分类器,选择具有最高F值的分类器实现分类判别。解决方案对Mozilla Firefox项目收集的580个漏洞进行了评估。结果显示,具有十折交叉实验结果的C4.5决策树实现了最高的F值(69%)识别不可见漏洞类别。此外,该框架能够检测包含BV和MV的文件。与其他方法相比,本文方法在准确性和MV识别性能方面优于现有方法,证明了本文方法的有效性。在下一步工作中,将根据软件复杂性指标研究BV和MV特征。
