基于粗糙集的企业财务长期趋势预测算法
2019-06-14李珊珊梁小红
李珊珊,许 萍, 梁小红, 徐 琳
(1.福建商学院 a.会计系; b.财会智能与服务研究中心, 福州 350012;2.福州大学 经济与管理学院, 福州 350003;3.福建师范大学福清分校 创新信息产业研究所, 福建 福清 350300)
财务金融系统是国家与企业单位的关键系统之一,财务分析是企业执行国家政策、决策及完善经营的重要依据[1]。财务金融系统的时间序列具有非线性、非平稳性与噪声大的特点,使得传统的分析模型无法获得较好的分析效果[2-3]。神经网络具有极强的学习能力与拟合能力,但神经网络需要大量样本,且模型的参数较多,因此难以广泛应用于实际应用中[4-5]。目前,在财务金融预测领域中应用最为广泛的是支持向量机(SVM)[6]。SVM能够解决维度灾难与过度学习的问题,但核函数对其性能影响极大。基于径向基函数(radial basis function,RBF)的SVM具有较强的学习能力,但泛化能力弱。基于多项式核函数的SVM则具有较强的泛化能力,但学习能力弱[7]。此外,SVM对于噪声与孤立点十分敏感,而财务金融时间序列存在大量的噪声与孤立点,因此许多研究人员为支持向量机引入了模糊化处理,以期提高支持向量机的泛化能力与鲁棒性[8-9]。
粗糙集理论处理不精确、不一致、不完整等各种不完备信息的效果较好,非常适合财务金融时间序列的分析与处理,已经取得了一定的效果[10-11]。文献[12]采用粗糙集模型构建金融时间序列与多指标的混合模型,实验结果证明该模型的分类准确率较高,但算法具有不可忽略的采样偏差。文献[13-14]设计了轮转窗口验证模型,有效地解决了粗糙集模型将时间序列离散化处理所导致的采样偏差问题。
基于粗糙集模型的财务金融预测模型主要通过粗糙集的化简概念删除输入数据集的冗余信息,根据事实信息生成无噪声的决策规则,但此类算法未考虑训练样本与测试样本的间隔时间长度对分类准确率的影响。本文对基于粗糙集的金融时间序列预测方案进行了改进,考虑训练样本与测试样本之间时间间隔对分类准确率的影响,设计了加权调和的粗糙集模型,为时期久远的训练样本分配较低的权重,为时期较近的训练样本分配较高的权重,从而提高近期训练样本对粗糙集模型的贡献。
1 理论分析
1.1 粗糙集(RS)
RS理论建立在分类机制的基础之上,将分类理解为在特定空间上的等价关系,等价关系构成了对该空间的划分。RS理论将知识理解为对数据的划分,每一被划分的集合称为概念。粗糙集理论的主要思想是利用已知的知识库将不精确或不确定的知识用已知的知识库中的知识来近似刻画。
RS理论中,假设I=(U,A)构成一个信息系统,其中U是一个非空有限目标集(论域),A是一个非空有限属性集。RS的核心概念是不可区分性,即给定一个信息系统I=(U,A),不可区分关系可定义为:
IND(B)={(x,y)∈U2,
B⊆A|∀a∈Ba(x)=a(y)}
(1)
从式(1)可看出:如果(x,y)∈IND(B),那么目标x与y是B-等价类或B-基本集,表示为[x]B,x∈U。
1.2 下近似集与上近似集
财务时间序列是一种典型的不一致决策系统,包含冲突的目标集合,即目标有相同的条件属性值,但决策属性值不同,因此目标属于不同的决策类。不一致决策系统的表示是RS理论的核心,能够近似任意的数据集X⊆U,下近似集与上近似集分别定义如下:
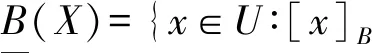
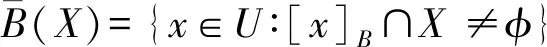
任意明确集的并集也是一个明确集,其他集合X⊆U均为等价类[x]B的近似,称为粗糙集。粗糙集包含了无法明确分类的目标,这些目标组成了X的区域,表示为如下关系式:
(2)
X的近似精度定义为:
(3)
经典的上、下近似集的定义可能因为孤立点导致等价类的划分不准确,研究人员对经典粗糙集模型进行了扩展,提高了上、下近似集的弹性。本文采用变化精度粗糙集(VPRS),算法允许控制分类的不确定性,控制因子表示两个集合(X,Y∈U)的非空子集,定义为c(X,Y)=1-|X∩Y|/|X|。此外,定义了期望分类误差参数β,用于控制不确定级别,VPRS的下、上近似集分别定义为:
(4)
(5)
式中:[x]B表示B的等价类。如果β=0,那么VPRS是经典的RS模型;如果β>0,则放松了下近似集的条件。
1.3 粗糙集的化简与核
财务时间序列具有大量的候选特征,例如:经济变量、技术指标、财务专家分析等。大量的候选特征包含了许多冗余信息,因此需要寻找一个最小的候选特征集合,且该集合应保持充分的区别能力。利用RS的化简技术完成上述目标,给定决策系统S=(U,C∪{d}),最小决策化简是属性的子集R⊆C,其中∀x∈U∶[x]C⊆[x]d→[x]R⊆[x]d。
本文采用区分矩阵M(S)寻找决策系统的化简S=(U,C∪{d}),M是一个n×n的对称矩阵(n=|U|),其元素cij(i,j=1,…,n)定义为:
cij=cij=

(6)

(7)

决策系统S中存在许多化简,所有化简的条件属性集称为粗糙集的核。搜索决策系统的最小化简是NP-hard问题,因此本文使用启发式贪婪算法[15]搜索最小化简。
1.4 决策规则
RS的决策规则可定义为IF-THEN的条件语句形式,决策规则定义为:

(8)
使用决策类[x]d的下近似集与上近似集基于化简机制引入决策规则与非决策规则。
1.5 基于时间加权调和的决策冲突方案
粗糙集中分类一个新目标可能导致以下3种情况:
1) 新目标与具有相同基本决策的一个决策规则匹配。
2) 新目标与具有不同基本决策的多个决策规则匹配。
3) 新目标与所有可用规则均不匹配。
第1种情况容易解决,第2、3种情况需要通过搜索最优的匹配决策类解决。第2种情况一般采用多数投票法[16],将匹配认证对象的条件属性集合的每个决策规则设为与训练数据目标数量相等的权重,为分类的验证样本分配1个决策值,以匹配最多匹配训练数据目标的决策规则。对于给定的式(8)决策规则集合L,使用它的前项φ匹配验证样本x:
φ∈L,Fψ⊆Fφ⊆Fφ
(9)
相等权重的多数投票法忽略了财务时间序列样本的时间特征,即训练数据与目标数据之间的时间长度,而财务时间序列中训练数据与目标数据之间的时间长度极为重要[17]。
在财务时间序列的场景下,针对第2种情况设计了加权调和的多数投票法,考虑训练样本与目标样本之间的时间长度。该方法引入1个时间加权函数τ(x,y),基于训练样本与目标样本之间的间隔天数修改决策规则的强度,因此,式(9)可改为:
y∈Fφ,φ∈L,Fψ⊆Fφ⊆Fφ
(10)
在多数投票程序中,近期的训练样本对规则的影响更大,使用以下两式定义时间加权函数:
τ(x,y)=1/(1+(Δ/λ)k),
k>0,λ>0
(11)
(12)
式中:Δ为测试样本y与训练样本x之间间隔的天数;λ为半衰期因子;k为斜率系数。
时间衰减函数定义了不同速度的时间衰变过程,因此可对预测准确率进行配置。图1是不同k值与λ=365时粗糙集的时间衰减函数,可看出近期样本的因子λ较小、k较大。第3种情况通过返回一个无活动决策来解决。
2 指标股标度曲线拟合与特征提取

图1 粗糙集的时间衰减函数

图2 基于前进分析法的实验流程
使用相同ETF指数时间序列数据训练、校准与测试各个模型。实验环境:SQL与Rosetta粗糙集系统[18]。
采用香港恒生指数(HSI)训练与测试各个预测模型,数据被分为训练集、校准集与测试集,所有数据来自(http://finance.yahoo.com)网站下载。采用文献[19]的条件属性方案,表1所示是股票指数不同条件属性的定义[19]。

表1 股票指数不同条件属性的定义
3 实验结果与分析
本算法包含向前分析法与加权多数投票的粗糙集模型,对向前分析法与SVM模型组合进行了实验,比较分析粗糙集模型与SVM模型的优劣。
3.1 粗糙集的规则集结构
测试的VPRS模型轮询3 333个交易日(固定长度)的训练样本,为向前分析法生成准确的策规则与近似的决策规则,向前分析法的每个实验中均生成了新的规则集合。每个测试样本设置了不同的β参数,获得3个候选规则集合,选择其中准确率最高的预测规则用于测试集的实验。
图3所示在不同时间间隔下,VPRS生成的决策规则数量,VPRS的β参数对生成规则的数量与质量具有明显的影响:β越大,决策规则数量越大,当β=49%时,决策规则数量最多。HIS指数生成的规则数量从2010年开始降低直至2011年底,然后从2011年底增长直至2014年。
3.2 模型的预测性能结果
表2与图4所示是本模型、原VPRS模型与SVM模型的分类结果。从表2可看出:原VPRS预测模型的性能优于SVM模型,本算法模型的预测准确率则同时优于原VPRS模型与SVM模型。VPRS模型使用相等权重的规则选择方案,因此,VPRS模型的所有规则均参与了分类程序,且VPRS模型仅基于β值选择最优的匹配规则集。该模型的性能随着校准时段长度的增加而降低,因此对校准时间长度较为敏感。
本算法模型与VPRS模型的规则集相似,但使用更长的校准时间段校准模型的参数,从而提高模型的分类准确率。从实验结果可看出:本文加权调和的多数投票机制有效地提高了VPRS的分类准确率。
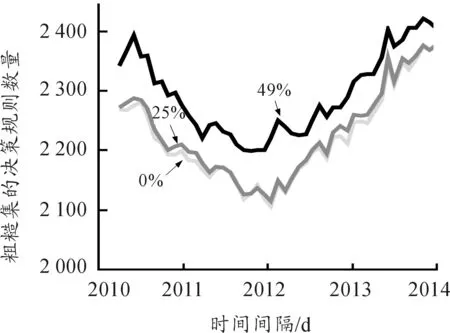
图3 VPRS生成的决策规则数量图
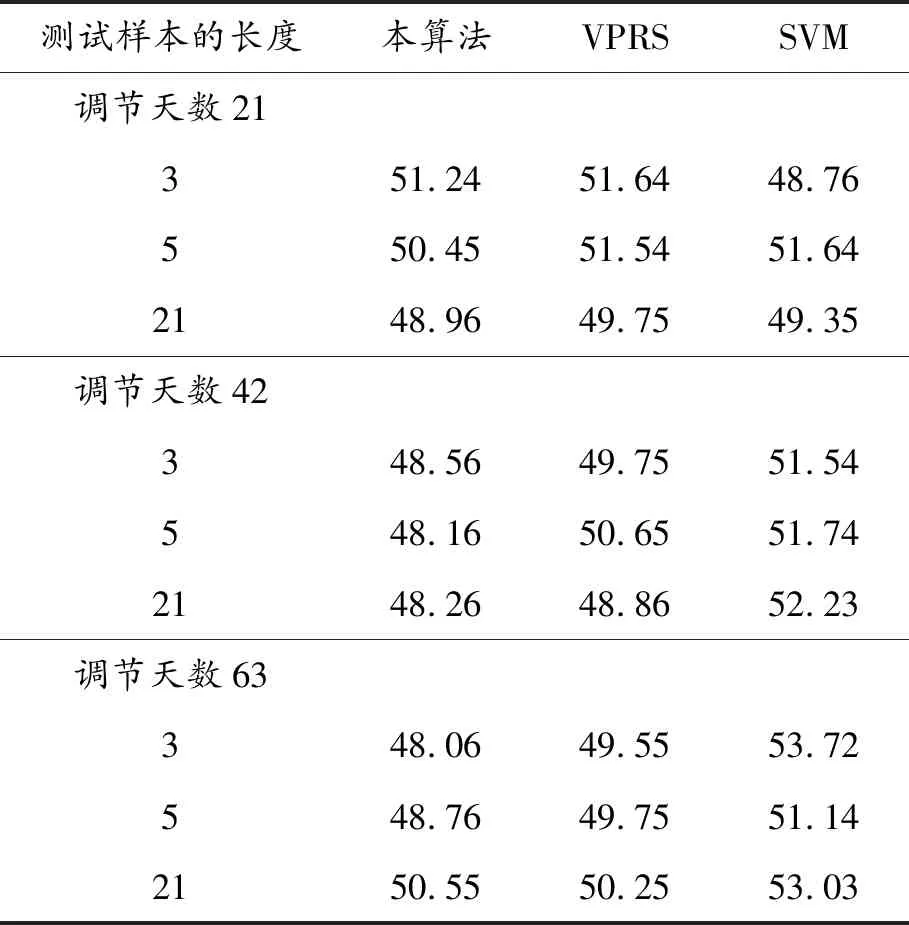
测试样本的长度本算法VPRSSVM调节天数21351.2451.6448.76550.4551.5451.642148.9649.7549.35调节天数42348.5649.7551.54548.1650.6551.742148.2648.8652.23调节天数63348.0649.5553.72548.7649.7551.142150.5550.2553.03
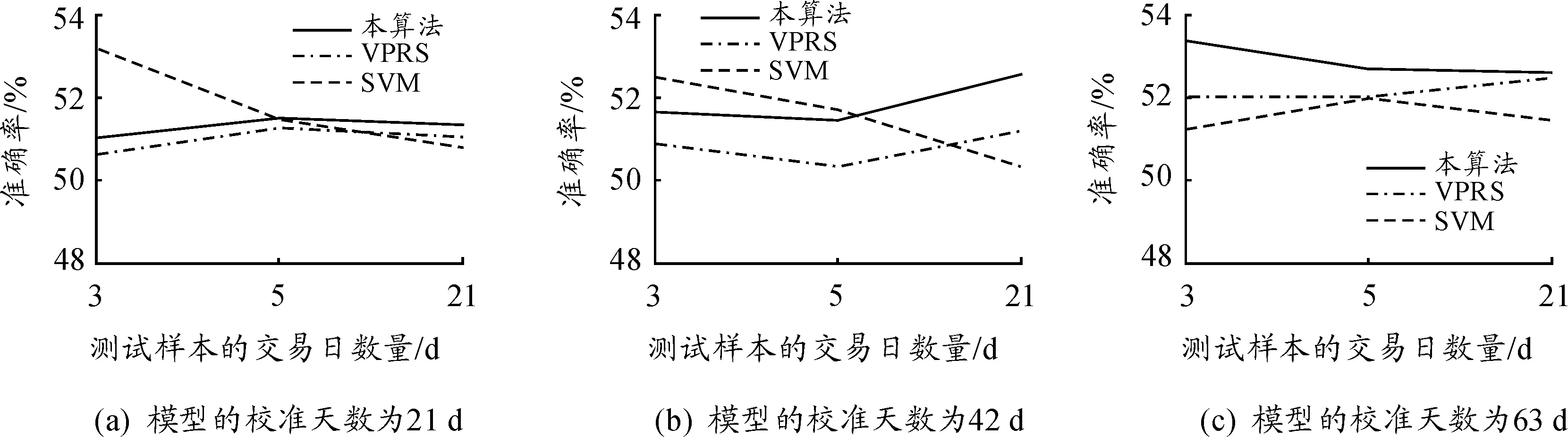
图4 本算法、VPRS模型与SVM模型对恒生指数的分类结果
4 结束语
为提高企事业单位财务金融长期趋势的预测准确率与可靠性,提出了一种基于粗糙集的财务金融时间序列预测算法。该算法考虑了训练样本与测试样本之间时间间隔对分类准确率的影响,设计了加权调和的粗糙集模型,为时期久远的训练样本分配较低的权重。基于香港恒生指数的实验结果表明:本算法获得了较高的预测准确率。
