基于深度卷积神经网络的SQL注入攻击检测
2019-06-11叶永辉谢加良李青岩
叶永辉,谢加良,李青岩
(集美大学理学院,福建 厦门 361021)
0 引言
随着计算机技术和互联网的迅速发展,Web应用迅速崛起,网络安全问题备受关注[1]。SQL注入漏洞攻击[2]是目前网上最流行最热门的黑客脚本攻击方法之一[3]。SQL注入具有攻击危害大、类型多、变异快、攻击隐蔽等特点。因此,SQL注入漏洞的检测和防御一直是Web安全领域关注的重点。
SQL注入[4]是指攻击者通过恶意查询语句来获取服务器数据库信息的攻击行为,可通过预编译、转义、过滤关键字、部署WAF等方式防御攻击。SQL注入方式有多种,基于攻击方式的不同可分为联合查询注入、报错注入、重言式攻击等[4]。基于此,入侵检测技术保障网络安全的重要性也与日俱增。入侵检测技术主要分为基于分类、基于聚类、基于统计和基于信息理论4大类算法[5-6]。李红灵等[7]在解决检测方法的适用性和提高注入检测准确率方面提出了SVM算法训练注入检测模型;杨连群等[8]提出结合隐马尔科夫模型来降低SQL注入检测误报率;张志超等[9]提出了BP神经网络训练检测模型,其特点是快速高效。卷积神经网络[10]是一种前馈神经网络,相较于其他机器学习算法[11-12],它通过卷积层和池化层的优化降低了网络参数个数,使卷积神经网络的计算量大大降低。卷积神经网络成功应用于图像处理[13]、视觉领域[14]以及围棋人工智能程序[15]等。为了进一步提高对变异攻击的识别率,降低人为因素对检测模型的影响,本文提出使用卷积神经网络(convolutional neural network,CNN)算法[10]训练注入检测模型。
1 基于卷积神经网络的SQL注入攻击检测方法
SQL注入检测模型的主要原理是通过拦截客户端与Web服务器的通信数据,利用SQL注入模型对数据内容进行检测分析。若存在攻击行为,则不对数据包进行转发处理,否则向服务器转发数据包。
本文提出的基于卷积神经网络算法的SQL注入检测系统由以下三个部分组成:
1)文本分词处理 针对文本中的链接、数字进行规范化处理,从而降低分词数量,减小无关变量对系统模型的影响。
2)提取文本向量 使用Word2Vec工具中的CBOW算法,对已经过分词处理的训练样本进行词汇模型训练,进而将文本数据转化为文本向量。
3)训练检测模型 设计卷积神经网络结构,选取卷积层、池化层以及激活函数等参数,进行模型训练。
1.1 文本分词处理
1) URL解码。浏览器向服务器发送数据时,客户端将用户输入的参数进行打包编码后发送到服务端,采集的训练样本往往都进行过编码处理,在训练前则需进行解码。针对存在多重URL编码的样本需采用递归URL解码[16]进行解析,以保证数据编码的一致性。
2) 对已解码的数据进行规范化处理。进行的操作主要有:将URL中数字替换为“0”;替换超链接为“http://u”的形式;对于数字、超链接等无关因素进行统一规范处理,以降低分词后的分词数量。
3)进行分词处理。分词处理模块以特殊符号(‘@#/空格等)为分隔符对样本进行分割处理,将文本字符串转化为文本序列的形式,既保留原本文本信息,也方便进行文本特征提取。
1.2 提取文本向量

图1 CBOW的神经网络结构Fig.1 CBOW neural network structure
Word2Vec[17]是Google在2013年开源的一款将自然语言转化为计算机可以理解特征向量的工具。Word2Vec主要有CBOW和Skip-Gram两种。本文采取CBOW模型进行训练,该模型由输入层、映射层和输出层组成,其神经网络结构示意图如图1所示。
输入层为单词X周围n-1个单词的词向量。例如,n=5,则词X(记为w(t))前两个和后两个的单词为w(t-2),w(t-1),w(t+1),w(t+2)。相应地,4个单词的词向量记为v(w(t-2)),v(w(t-1)),v(w(t+1)),v(w(t+2))。
从输入层到映射层(Pro(t))是将n-1个词向量相加:
Pro(t)=v(w(t-2))+v(w(t-1))+v(w(t+1))+v(w(t+2))。
(1)
映射层到输出层需构造Huffman树(依照各词汇出现频率构造Huffman树),Huffman树构造过程如下:
1)将w(t-2),w(t-1),w(t),w(t+1),w(t+2)看作n棵树,每棵树仅有一个节点。
2)选取权值最小的两棵树进行合并,得到一棵新树,这两棵树作为新树的左右节点,新树的根节点权值等于左右子树的权重之和。
3)重复步骤2)直到n棵树都已合并为止。
然后从根节点开始,映射层的值需要沿着Huffman树不断地进行logistic分类,并且不断地更正各词向量。
词向量模型训练完成后,以字典的形式保存,从而完成单词到向量的映射。
1.3 训练检测模型
本文采取卷积神经网络对文本进行分类,在数据集较大的情况下,也可以自动提取特征。
其输入层由文本向量组成,文本向量的长度即为输入参数的个数。通过若干个一维卷积层进行特征提取;最大池化层将提取的特征再次压缩,并提取主要特征且简化网络计算复杂度;dropout连接所有特征并将计算结果通过softmax分类器进行输出。
一维卷积网络降低维度的原理如下:
1)假设输入数据维度(in)为8,过滤器维度(filter)为5,则卷积操作后数据维度(out)为8-5+1=4,即:out=in-filter+1。
2)如果过滤器数量仍为1,而输入数据的channel数量变为16,则表示输入的数据有8个单词而每个单词的词向量维度为16。此时,过滤器的维度则变为5×16,输出维度仍为4。
3)如果过滤器数量为n,那么输出的数据维度就变为4n,即:out=n×(in-filter+1)。
卷积神经网络属于有监督学习,训练前需对样本进行标签化处理。在这个模型中,将正常样本标记为0,SQL注入样本标记为1。训练过程中,优化器根据预测结果与实际结果的偏差(由损失函数计算所得)不断进行反向传递优化参数,最后得到检测模型。
2 SQL注入检测实验
本文数据来自互联网的SQL注入实例。训练时使用了三种数据集:第一部分为训练集,主要用于训练检测模型;第二部分为验证集,验证当前训练模型的准确率;第三部分为测试集,测试已训练完成的模型对样本的识别率。训练集中正常样本24 500条,SQL注入攻击样本25 527条,XSS攻击样本25 112条;验证集中正常样本10 000条,SQL注入攻击样本10 000条,XSS攻击样本10 000条;测试集共4组,每组正常样本2000条,SQL注入攻击样本2000条,XSS攻击样本2000条。
正常样本数据格式如下:
code%3Dzs_000001%2Czs_399001%2Czs_399006%26cb%3Dfortune_hq_cn%26_%3D1498591852632;
SQL注入样本数据格式如下:
-9500%22%20WHERE%206669%3D6669%20OR%20NOT%20%284237%3D6337%29;
XSS注入样本数据格式如下:
site_id%3Dmedicare%22%3E%3Cscript%3Ealert%281337%29%3C/script%3E%2Casdf。
2.1 文本分词处理
URL解码后,对一些无关变量进行替换,以一些特殊符号(如'@*#$()/空格等)为分割符,对语句进行分词处理。对数据进行规范化处理、分词处理,是非常关键的一个步骤,不仅能最大化地保留文本信息,还减少了一些噪声的影响。提取结果如下:
未分词处理样本 1)))%252bAND%252b8941%25253d8941%252bAND;
分词处理后样本 [‘0’,‘)’,‘)’,‘)’,‘and’,‘0=’,‘0’,‘and’]。
2.2 提取文本向量
通过Python的gensim模块来使用Word2Vec工具,将分词处理后的语句作为输入数据。经过Word2Vec训练后,可得到一个以字典形式保存的词向量模型。通过此模型对每个单词进行向量化,再由词向量组成语句向量作为检测模型的输入。提取词向量结果如下:
样本单词 And;
样本词向量 [-4.609 003 54 2.700 308 80 -0.033 447 10 0.946 626 66 0.517 221 75
1.236 753 94 -2.057 605 03 -2.369 857 31 4.133 568 29 2.375 314 47
-5.805 147 65 -1.499 013 90 -3.302 577 02 -2.151 923 66 0.870 841 15
-1.487 621 19]。
由于训练前的样本经过分类、标签处理,因此需对样本的训练顺序进行随机处理。通过随机处理可以有效避免实验结果的偶然性。本次实验对训练时用到的训练集和验证集的样本数据进行随机处理,使用Python的随机函数产生随机序列,并由该随机序列的顺序决定样本读取顺序。
2.3 训练检测模型
本文采用的卷积神经网络结构参考文献[18],具体由三个卷积层、三个池化层组成,最后连接全连接层。由于CNN只能接受固定长度的向量输入,在训练前需要将样本填充数据,使其输入长度固定。
训练集的准确率(acc)、损失值(loss)与验证集的准确率(val_acc)、损失值(val_loss)如图2所示。

2.3.1 CNN中的参数选取
该卷积神经网络中使用了两种激活函数,卷积层与全连接层使用了ReLu函数作为激活函数,而输出层使用的是Softmax函数作为激活函数。
1) ReLU函数是个分段线性函数,输入为负值时输出为0,而正值输出不变,这种操作被称为单侧抑制。
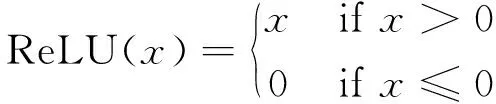
(2)

输入的参数经过Softmax函数,映射成为(0,1)的值,而这些值的累和为1(满足概率的性质)。因此,在最后选取输出结点的时候,选取概率最大(也就是值对应最大)的结点作为预测目标。
2.3.2 代理模块
客户端在与Web服务器进行数据包交互前需进行TCP三次握手,经过TCP连接后传输HTTP报文。代理服务可作为中间者,由代理服务器完成与服务器的TCP连接、传输HTTP报文,而客户端实质上是与代理服务器进行报文交互,由代理服务器决定是否转发数据。
恶意用户可通过修改HTTP数据里的参数,构造攻击载荷,对数据库进行攻击。代理模块拦截客户端与服务端的数据包,通过注入检测模型检测当前数据包是否存在攻击,若不存在攻击则由代理服务器向Web服务器转发数据,否则丢弃数据包。
3 实验结果分析
利用4组测试数据集对前述SQL注入检测模型进行验证。每组测试集对三种样本的识别率和误报率如表1、表2所示。
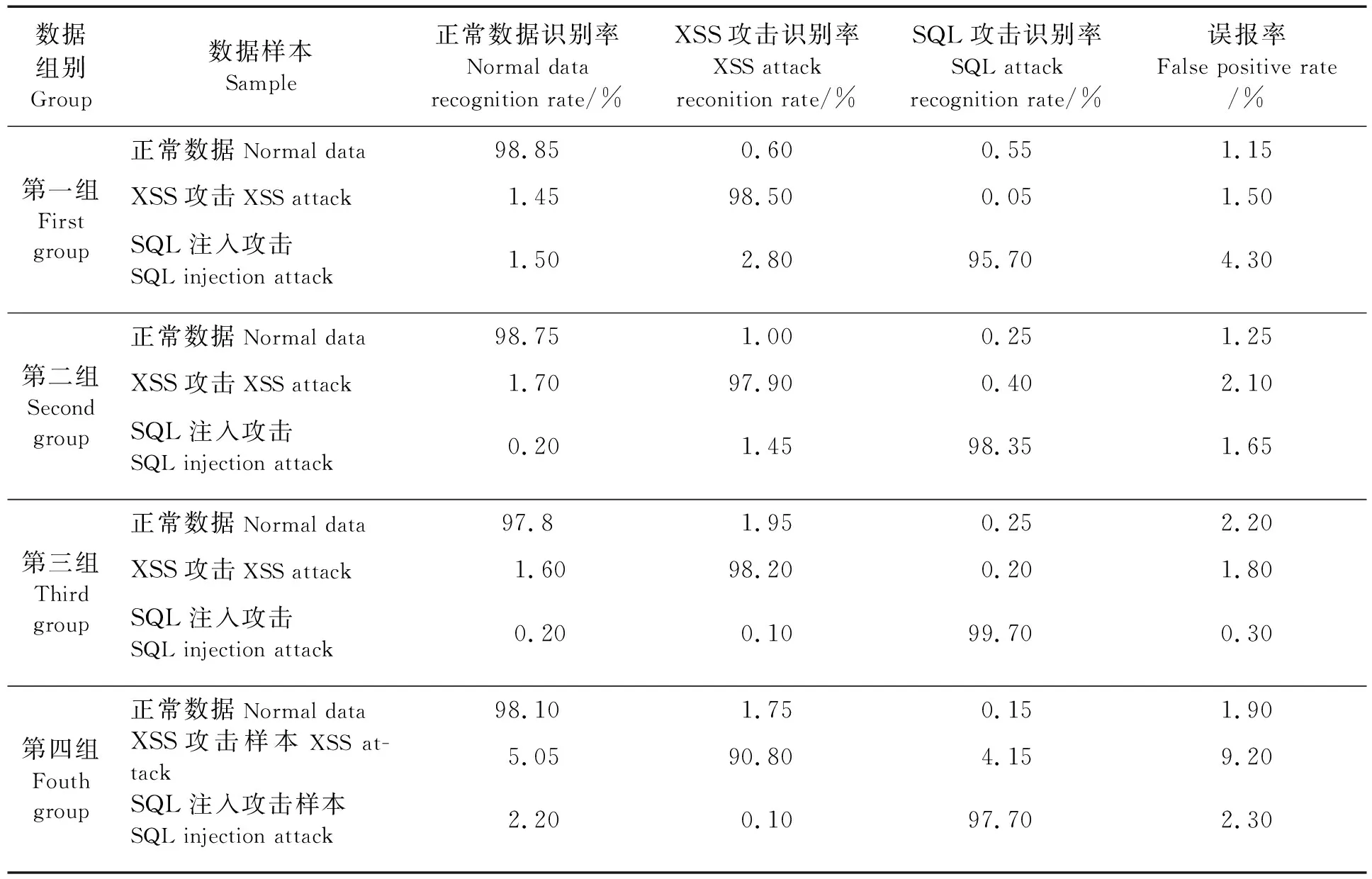
表1 样本检测结果

表2 实验结果数据统计
测试结果表明经过卷积神经网络(CNN)训练的模型具有极强的预测能力,对样本识别的准确率基本都在97%左右并且误报率极低。此方法不仅仅能够识别单一SQL注入或者XSS攻击,只要拥有足够并且典型的训练样本,不需设计更多的算法,就可训练出能识别多种网络攻击的检测模型,且模型的准确性和检测攻击的多样性完全取决于样本数据本身。当然,卷积神经网络对设备的性能也有所要求,随着数据量的增加,设备的计算量也会随之增加,服务器的响应速度也会有所影响。
4 CNN与BP神经网络算法对比
本文对基于CNN算法与BP神经网络算法的SQL注入检测模型进行测试,两种算法选择同样的训练集。
变异SQL注入攻击样本由特殊字符进行混淆,且未曾在训练样本中使用。变异SQL注入攻击数据样本格式为:/?id=-1/*!UnIon/*/*%0n%0y*/ /*/*%0n%0y*/seLeCT*/1,‘test’,3。
实验结果为:1)BP神经模型对4组包含SQL注入的攻击样本进行测试,平均识别率97%,误报率3%;2)CNN模型对1500条变异SQL注入攻击样本测试,显示正常样本1条,SQL注入1499条,准确率99%,误报率1%;3)BP神经网络模型对1500条变异SQL注入攻击样本测试,显示正常样本369条,SQL注入1131条,准确率75%,误报率25%。
通过实验分析,BP神经网络模型与CNN模型对普通SQL注入攻击的识别能力相仿,其准确率均为97%左右,但是,对SQL注入变异攻击的识别能力,CNN模型远远优于BP神经网络,CNN准确率为99%,而BP神经网络仅为75%。面对SQL变异快的特点,基于CNN训练的SQL注入检测模型具有更强的适应性。
5 结束语
本文构建基于卷积神经网络算法的SQL注入检测模型,通过算法本身特性提取攻击样本的特征向量,从而降低漏洞检测的误报率;对多种类型攻击样本进行训练,实现多种攻击(SQL注入与XSS)的检测;利用卷积神经系统的非线性映射能力建立了多种攻击行为的映射关系。通过实验验证了此算法的通用性,其不仅可以应用在SQL注入检测,而且可以推广到多种入侵行为的检测。相比于BP神经网络模型,基于CNN的SQL注入检测模型识别能力更优,具有更强的适应性。当然,在数据量极为庞大的时候,检测模型的检测速度会有所下降甚至影响正常访问,完善模型的检测速率将是后续研究的重点。
