基于位置服务隐私自关联的隐私保护方案
2019-06-11李维皓曹进李晖
李维皓,曹进,李晖
(西安电子科技大学网络与信息安全学院,陕西 西安 710071)
1 引言
随着移动智能终端的普遍应用,社交网络已经成为了人们生活中必不可少的一部分,其中基于位置服务(LBS, location-based service)的使用最为频繁。如今,智能终端可以下载多样化的应用程序,增添多样化的服务和个性化的操作。然而,这种便利也带来了安全隐患。基于位置服务中,用户的位置信息被用户视为一项“无关紧要”的信息无偿地发送给了服务提供商来换取相关的服务。然而这些信息一旦被恶意用户或是具有强大计算能力的服务提供商获取,那么用户的个人信息安全就会受到威胁。位置信息能够泄露用户的诸多敏感信息,因此保护用户的位置信息隐私也成为了必不可少的研究课题。
在基于位置服务中,用户的位置信息分为2种,即单点的位置信息和连续的位置信息。其中,单点的位置信息为在某个时间点发起的基于位置的请求,例如,寻找附近的商家、查询某个城市的天气等。连续的位置信息则为在某个时间段内多次的位置信息的记录,例如,路线导航、查询交通拥堵情况等。无论是单点的位置信息还是连续的位置信息,都存在很多隐私保护方案[1-4],在保证用户的位置隐私不被泄露的同时,也使用户能够享受相应的基于位置的服务。背景信息的存在提高了攻击者实现攻击的精准度,因此,在设计隐私保护方案时,背景信息是必须考虑的因素。现有的隐私保护方案中,背景信息是指地图中位置点的历史查询概率[5-7]。根据历史查询概率的大小,攻击者可以将低概率的位置过滤掉。随着移动智能终端的不断升级,存储成本已经大幅降低,用户在享用基于位置服务的同时,移动终端也存储了短时间内的查询记录,同样,服务提供商也有相关的信息存储,可以通过分析用户的查询记录获取用户位置信息,因此用户自身信息也成为了隐私保护方案设计中不可忽略的一项。
本文方案的创新点包括以下3个方面。
1) 现有的隐私保护方案大多基于历史的背景信息,通过普遍存在性来实现隐私保护方案,然而针对个体差异性的考虑并不充分。本文方案从历史信息的关联性和用户自身信息的关联性2个方面设计来保护用户的隐私,提出了一个简易隐私自关联的隐私保护算法(Ba-2PS, basic privacy self- correlation privacy- preserving scheme)实现对用户的隐私保护。
2) 在考虑历史信息的关联性和用户自身信息的关联性的同时,从时间的维度和查询范围的维度扩展了简易隐私自关联的隐私保护算法,提出了扩展隐私自关联的隐私保护算法(En-2PS, enhanced privacy self-correlation privacy-preserving scheme)。本文提出的隐私保护方案基于匿名技术,由于发送给服务提供商的请求信息中包含了用户的真实请求,并将真实信息隐藏在匿名信息中,因此不影响用户所享有的服务质量。
3) 不同于现有隐私保护方案的单一保护用户的位置隐私或者查询隐私,本文方案在考虑到背景信息存在的前提下,同时个性化地保护用户的位置隐私和查询隐私。
2 相关工作
基于位置服务中,用户的隐私信息包含位置隐私[8-10]和查询隐私[11-13],现有的隐私保护方案主要分为基于密码学的隐私保护方案[14-15]、基于模糊的隐私保护方案[16-17]、基于差分的隐私保护方案[3,10]、基于匿名的隐私保护方案[18-19]。其中,基于匿名的隐私保护方案分为基于匿名中心的隐私保护方案[14-15]和基于移动终端的隐私保护方案[7-8,16]。在基于匿名中心的隐私保护方案中,匿名中心位于用户终端和服务提供商之间,承担了性能和安全的责任,对用户的信息进行处理,经过匿名化操作的请求信息由匿名中心发送至服务提供商,降低了用户的计算、存储开销。然而,匿名中心成为了性能和安全的瓶颈,大量的隐私请求由匿名中心来处理,执行效率会大幅降低,同时一旦匿名中心被攻破,那么所有的隐私信息将会泄露。目前,移动网络不断发展,智能终端不断智能化,存储能力不断增加,计算处理能力不断加强,为了避免匿名中心的单点泄露问题,基于移动终端的隐私保护方案也不断涌现。Niu等[5]设计实现了基于匿名的隐私保护方案,考虑到背景信息中每一个位置的历史查询概率,同时为了避免所选的匿名位置位于相同的建筑之内降低隐私保护效果,通过计算匿名位置之间的距离,确保所选取的匿名位置单元两两之间的距离尽可能远。基于混合区域(Mixzone)的隐私保护方案中,Palanisamy等[20]通过更换用户离开Mixzone时的假名,使攻击者不能够通过分析进入Mixzone和离开该区域的关联性来获取用户的真实信息,以保护用户的位置隐私。CacheCloak方案[21]利用缓存用户请求的服务信息来避免和服务提供商的多次交互,通过减少交互次数保护用户的隐私信息。Xu等[18]提出了一种基于感知的隐私保护模型,利用信息熵来衡量位置区域的受欢迎程度,并且利用四叉树来分离请求信息和特定用户,针对不同的分类提供个性化的隐私保护。
在保护用户位置隐私的同时,用户请求中的查询内容同样包含了用户的隐私,根据基于匿名的隐私保护算法演变出了l-多样性方案[23-25]和t-接近性方案[26-28]。其中,l-多样性方案在基于k匿名方法的基础上,保证了每个等价类中敏感属性达到阈值,避免了敏感属性的泄露。k匿名技术是一种利用混淆的方法使观测者无法辨别出真实信息的技术,例如,将用户的真实信息和k-1个匿名信息一起发送给服务提供商,服务提供商不能够分辨出接收到的k个请求中哪一个是真实的请求信息。He等[25]提出了空间多样性,结合用户的路径和随机模型,分析得到用户的空间差异度,提出了一个优化停顿的隐私访问方案,实现了较高的隐私保护效果。Li等[28]分析了l-多样性的隐私保护算法的局限性,设定在等价类中敏感属性的分布距离不大于预设的阈值,实现对敏感属性的保护。
现有的隐私保护方案为保护用户的位置隐私和查询隐私奠定了深厚的基础。本文根据现有的隐私保护方案,考虑了用户自身信息之间的关联,在保证位置信息不被泄露的同时,从时间的维度和查询范围的维度保护了用户的查询隐私。
3 准备工作
3.1 基本概念
1) POI
POI(point of interest)是指在某一个位置点区别于坐标信息来辨别该位置的性质。例如,Alice在某商场请求周围公交车站,那么此商场就是该位置的POI,而该位置的坐标则是位置信息,公交车站是查询内容。
在某种程度上,POI和查询内容在语义上具有重合性。例如,在上述的例子中,商场是该位置的POI,公交车站是查询内容,然而从公交车站的位置坐标来说,公交车站是该位置的POI。综上所述,POI是位置坐标上基础建设(或者其他能够区别辨识的设施)的语义内容,能够作为用户进行查询的关键字成为查询内容。
2) 背景信息
随着科技的发展和信息的海量增加,任何一个具有计算、处理和存储功能的个体都能够获取地图中用户所处区域的历史查询数据,其中包含了某个地点曾经发生和当前发生的请求记录、该地的查询概率以及该地所处的商圈和POI。现有的隐私保护方案单一地考虑了背景信息中历史数据的集合,而未关注某个特定时间点的查询概率以及相邻时间点的查询概率。本文所指背景信息不仅包含了查询概率,同时包含了区别位置的兴趣点POI。本文中的背景信息是通过Google地图的API(application programming interface)来获取区域内每个位置的查询概率,并将背景信息存储于智能终端中。
3.2 LBS基本框架结构
基于位置服务的基本架构主要由 4个部分组成:GPS卫星、移动终端、通信基站和服务提供商,如图1所示。

图1 LBS基本框架结构
用户通过移动终端获取其所处的位置信息,然后通过移动蜂窝网络或者Wi-Fi将服务请求发送至服务提供商的服务器。服务提供商在接收到由通信基站转发来的请求后,将用户所需的服务信息作为响应发送给用户的移动终端,从而完成一个完整的请求服务和响应服务的过程。
1) GPS卫星为移动终端提供当前的地理位置信息。基于位置服务的隐私保护算法对此过程中的信息不进行考虑,默认在位置获取的过程是安全的。
2) 用户通过移动终端对请求信息进行隐私保护,将保护后的信息发送至通信基站,在该过程中,用户的请求信息已经过隐私保护处理。
3) 通信基站将接收到的信息发送至相应的LBS提供商的服务器,通信基站只对用户的请求和收到的响应进行转发,不对请求信息进行修改。同样,通信基站在收到服务器的响应后将其转发至移动终端,不对响应信息进行修改。
3.3 研究动机
在设计基于位置服务的隐私保护方案时,背景信息的存在为攻击者提供了线索来分析推测出用户的真实信息。本节通过一个例子来解释本文的研究动机。如图2所示,将地图等分为6×6的位置单元,根据背景信息中的历史查询概率,每一个位置单元用不同的灰度来表示该位置单元历史查询概率的不同,灰度越高表示在该位置单元的历史查询概率越高,灰度越低表示该位置单元的历史查询概率越低。
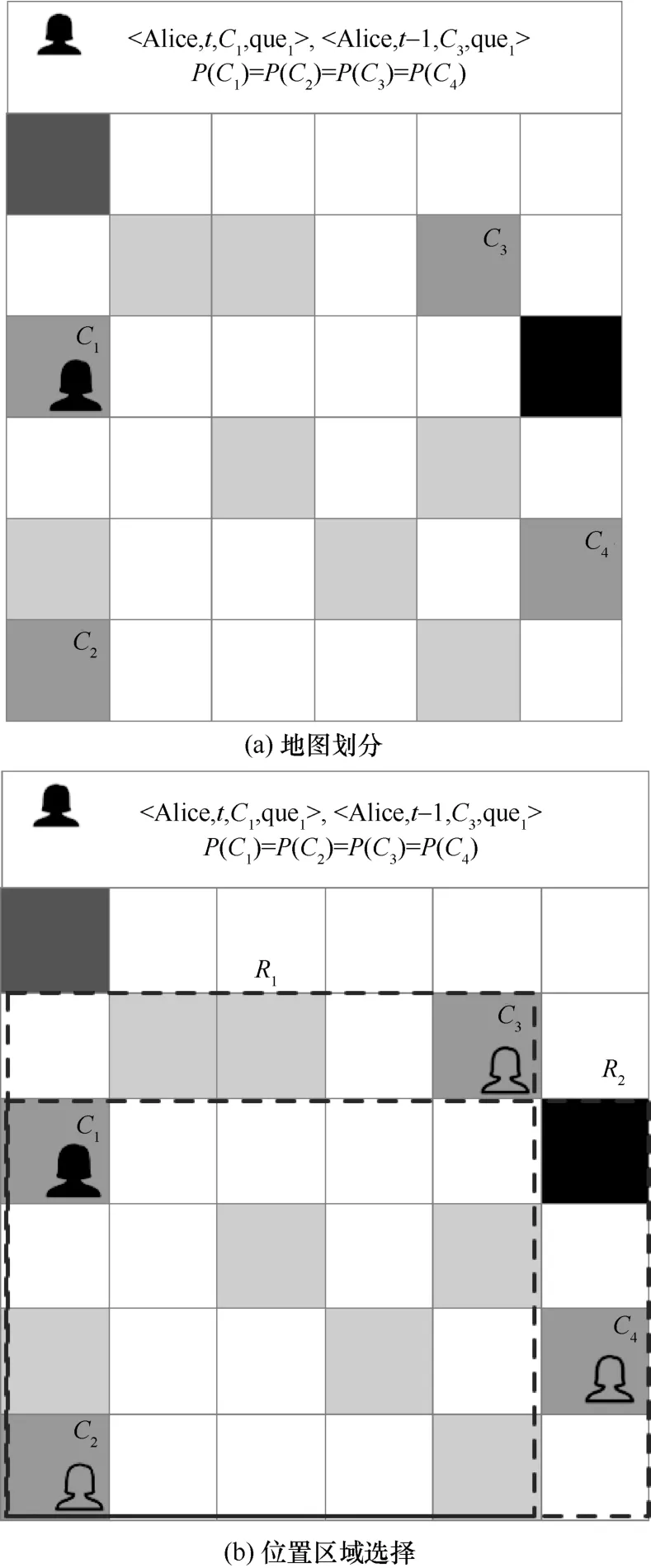
图2 研究动机
现有的隐私保护方案为了达到最佳的隐私保护效果,所选取匿名位置的历史查询概率和用户(Alice)真实位置的历史查询概率相同,从而使隐私度量值最高。在t时刻,Alice位于位置区域C1中,该地图中和 Alice所处位置区域C1具有相同的历史查询概率的位置区域为C2、C3、C4,即

其中,P(Ci)表示位置区域Ci的历史查询概率,如图2(a)所示。假设在该例子中,选取的k匿名算法中的k=3,则需要选择k-1=2个匿名位置区域,则从3个具有相同历史查询概率的位置区域中选出2个,即C2、C3,如图2(b)所示的虚线区域R1。
然而,有很多APP对用户的历史查询信息进行存储。例如,在t-1时刻,Alice曾在位置区域C3发起过对于que1的查询请求,由于2个时间点之间的时间差值足够小,即Δt=ε,εN+∈,那么攻击者则会认为Alice在短期内搜索过该位置的服务,且服务内容相同,则该位置区域C3为匿名位置,从而用户的泄露概率由增加为,增加了隐私泄露的风险。
因此,单一地考虑地图中位置的历史信息无法抵御攻击者从用户自身信息的关联性来推断出用户真实信息的攻击。本文从历史信息和用户自身信息2个方面同时考虑,提出了2个隐私保护算法:简易隐私自关联的隐私保护算法(Ba-2PS)和扩展隐私自关联的隐私保护算法(En-2PS)。其中,Ba-2PS考虑到用户自身关联的隐私信息,在选取匿名位置区域时,将区域C3过滤,从而选取区域位置C4为匿名区域,如图2(b)中的虚线区域R2所示。
3.4 隐私度量
在基于k匿名的隐私保护方案中,用户发送给服务提供商的请求包含了用户的身份、发送请求的时间戳、用户的当前位置、查询内容和查询范围。本文为了衡量隐私保护的程度,采用k匿名概率和信息熵来衡量隐私信息被推测的不确定性[28]。其中,k匿名概率表示用户隐私信息的泄露概率,泄露概率越大则表示隐私保护的程度越低。在基于信息熵的隐私度量中,信息熵值越大,说明计算的信息的不确定性越高,则隐私保护的程度就越高。信息熵的具体定义如下。
定义1基于k匿名概率的隐私度量。已知所选取的匿名位置构成区域为R,,即|R|=r,则基于k匿名概率中k的取值为该区域中位置单元的个数,即k=|R|,则泄露概率为

定义 2基于信息熵的隐私度量。已知用户真实的位置区域为j,经过k匿名算法得到k-1个匿名位置区域,则信息熵为

其中,Pri表示根据用户的真实位置区域j选取的匿名区域i的概率。信息熵具有极值性,即事件的发生概率相同,信息熵值达到最大值,概率事件的不确定性最高,在隐私保护算法中则说明用户的隐私保护程度最高。
4 简易隐私自关联的隐私保护算法
Ba-2PS算法由地图预处理算法和双筛选算法组成。其中,地图预处理算法实现了对地图的初始化分割,根据历史背景信息初始化位置单元的历史查询概率,进而通过双筛选算法选取匿名位置发送给服务提供商来换取相应的服务。
4.1 地图预处理算法
在地图预处理算法中,获取地图,将地图等分为m个位置单元,每个位置单元作为后续进行位置选取的最小位置单元。其中,m的数值决定了地图划分的粒度,loci表示第i个位置单元,且+i,m∈N 。
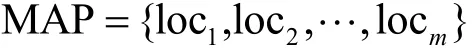
在t时刻,用户Alice位于位置单元locu中,请求附近的POI的信息,其中请求范围记作radu,所查询的内容记作queu。用户Alice的真实请求向量为。根据背景信息获取位置单元locu的查询概率Pr(locu),遍历地图中的位置单元,选择和Alice当前位置单元具有相近查询概率的位置单元,即其中γ≥0,将满足条件的位置单元存储在集合η中,并将集合η作为双筛选算法的一个输入,则loci∈η。具体如算法1所示。
算法1地图预处理算法
输入地图,用户当前位置信息
输出集合η
1) 等分地图为m个位置单元;
3) 存储于集合η中;
4) 输入集合η。
4.2 双筛选算法
根据地图预处理算法得到一个位置单元的集合η,在该集合中每个位置单元的历史查询概率和用户当前所处位置单元具有相同的历史查询概率。在双筛选算法中,假设用户的移动终端中缓存了用户在T时间段内的查询记录,该时间段的查询记录存储于集合ζ中,其中用户u在T时间内的查询记录为,其中locali∈ζ,
根据已知位置单元集合η和查询记录集合ζ,对位置单元集合η和查询记录集合ζ中的向量求交集,如果集合η中的位置单元存在于集合ζ中,则将该位置单元从集合η中删除。经过第一次筛选,集合η中的位置单元个数小于或等于最初从地图预处理算法中得到的位置单元个数。此次筛选得到的位置单元避免了因用户自身信息关联而降低隐私强度的问题。
然而,此时集合η中的位置单元不能满足距离用户的位置尽可能远,而一旦选取的匿名位置单元和用户的真实位置十分接近时,无法避免两者位于同一座建筑内,从而失去进行匿名保护的意义。第二次筛选操作的目的则是尽可能地选取距离较远的位置单元,保证匿名位置单元尽可能分散。
为了方便第二次的筛选操作,本文采用四叉树地图进行存储,根据背景信息迭代划分地图,每次四等分,如图3所示。查询概率高的区域位置单元的密度较高,查询概率低的区域位置单元的密度较低,因此,在中,设置。根据迭代划分,对应由四叉树来进行存储,为了保证所选的匿名位置尽可能分散,则所选的匿名位置单元中不存在任意2个位置单元属于同一个父节点,且深度检索该位置单元所属分支的深度满足的节点不存在相同的父节点。

图3 迭代四等分划分
最后将得到的k-1个位置单元作为匿名位置单元构成匿名查询请求和用户的真实位置一起发送给服务提供。具体如算法2所示。
算法2双筛选算法
输入集合η、ζ,k值
输出集合η′

5 扩展隐私自关联的隐私保护算法
En-2PS算法是Ba-2PS的扩展方案,在考虑到历史背景信息和用户自身信息的同时,分析位置单元、查询内容、查询半径之间的关联关系,设计匿名查询内容生成算法和请求生成算法。
5.1 匿名查询内容生成算法
在匿名查询内容生成算法中,从时间的维度分析位置单元和查询内容的关系,从而确定匿名查询内容。时间维度的不同,所查询的POI的种类也不相同。用户请求服务的时间为t,根据Ba-2PS选取的k-1个匿名位置单元满足以下3个要求。
1) 根据背景信息所选取的位置单元和用户所处的位置单元有相近的查询概率。
2) 不存在用户在T时段内的查询记录中。
3) 所选取的位置单元分散在地图中且互不相邻。
为了保护用户的查询隐私,在发送给服务提供商的请求信息中的查询内容不能和用户真实的查询内容相同,同时避免在特定时间点发送不可能的请求信息(例如,在清晨时间查询酒吧)。已知用户Alice在位置单元请求的查询内容queu,集合'η中的匿名位置单元loci,根据背景信息,在t时刻,匿名位置单元曾查询的POI中选取查询概率较高的POI作为查询请求中匿名位置单元loci的查询内容quei,则该查询内容的查询概率满足其中0<θ<1。具体如算法3所示。
算法3匿名查询内容生成算法
输入集合'η,背景信息
输出集合δ

5.2 请求生成算法
在请求生成算法中,从查询范围的维度重新选择每一个匿名请求对应的查询半径,从而避免攻击者利用背景信息推测匿名位置单元的查询半径过大或者过小,进而降低匿名位置单元的个数,提高用户隐私的泄露概率。例如,位置单元的查询半径过大,包含了不可能的地方(例如河、湖),从而攻击者推测此位置为匿名位置单元。
已知 Ba-2PS中对地图利用四叉树进行存储,假设k=3,选取的 2个匿名位置单元分别为loc1和loc2,如图4所示。根据深度优先搜索四叉树,得到位置单元的深度分别为Dep(loc1)、Dep(loc2)和Dep(locu)。如果所选的位置单元的深度满足Dep(loci)>θ,则说明该位置单元所处区域密度较高,进而相应的查询半径为radi=radi+β,其中β<0,如果Dep(loc1)≤θ,则查询半径为,其中β>0。

图4 四叉树
最后,得到查询半径和相应的位置单元、查询内容,重新构成匿名请求和用户的真实请求一起发送给服务提供商。具体如算法4所示。
算法4请求生成算法
输入集合'η,集合δ
输出真实请求和匿名请求

6 隐私性分析和实验验证
本节分别从隐私性分析、性能分析以及隐私性验证对Ba-2PS和En-2PS方案的性能和隐私性进行测试和验证。通过分析证明 En-2PS方案能够抵御的攻击类型,同时通过隐私度量对保护隐私的保护程度证明了方案的隐私性。
本文实验采用Matlab软件在PC机(2.9 GHz Intel i7 CPU, 16 GB 内存)上进行模拟仿真,并对方案的性能进行验证。
选取了某城市内8 km×8 km的地图,划分为160×160个位置单元,每个位置单元为50 m×50 m的矩形。实验中参数k是指k-匿名中发送给服务提供商的请求数量,选取范围为[5,50]。
6.1 隐私性分析
本节分别从共谋攻击和推断攻击2个方面分析了 En-2PS方案的安全性。在基于位置服务中,用户利用无线信道和基于位置的服务提供商进行交互。无线信道是开放的,基于密码学的隐私保护算法可以避免恶意用户窃取无线信道中的隐私信息,然而基于密码学的隐私保护算法(例如,AES、3DES、RSA等)计算和处理开销较大。
定义 3已知∀i∈C,满足其中集合C为共谋集合,是攻击者通过接收到的信息推测出用户的位置信息,loci为攻击者接收到的位置信息,且loci∈O,集合O是攻击者所观测到的位置信息集合,表示攻击者通过收集到的位置信息推测出位置信息的概率。
引理1En-2PS可抵御共谋攻击。
证明攻击者为了获取用户的真实位置信息,可能联合其他用户甚至服务提供商实现共谋攻击。在本文方案中,无论多少用户或者服务提供商联合,通过公布的位置信息推断出真实位置信息的概率为一常数。En-2PS利用了k匿名技术来实现匿名位置单元的选取,则从k个公布出的位置单元中得出用户真实位置单元的概率为
En-2PS是根据真实的背景信息来选取匿名位置单元的,其中背景信息可以被任意用户或服务提供商获取,因此,无论共谋用户有多少,用户的真实信息始终隐藏在k-1个匿名位置信息中。综上所述,En-2PS能够抵御共谋攻击。证毕。
定义4已知loci∈O,集合O是攻击者所观测到的位置信息集合,且|O|=k,攻击者推断出的位置信息为,如果方案满足,则表明攻击者观测到的位置单元两两相同,因概率相同从而不可分区;如果满足,则表明攻击者观测到的位置单元两两不同,使攻击者不能分辨。因此,没有孤立点和通过背景关系可分析出的特殊点,说明该方案能够抵御推断攻击。
引理2En-2PS可抵御推断攻击。
证明在 LBS中,服务提供商具有强大的计算、处理和存储能力,在推断攻击中视服务提供商为主动攻击者,可以基于背景信息来分析推断用户的隐私。在 En-2PS中,根据背景信息选取的匿名位置单元满足,其中γ>0,攻击者不能根据位置单元的查询概率对观测到的信息进行筛选来分析得出用户的真实位置单元。从而,攻击者推断用户的真实信息满足。此外,En-2PS中对用户的查询内容和查询范围进行个性化选择,成功地避免了攻击者通过背景信息和事件发生的可能性来推断用户真实信息的情况,因此,En-2PS能够抵御推断攻击。证毕。
基于隐私度量的隐私性分析,根据第3.4节中提出的隐私度量,利用信息熵计算隐私保护方案所实现的隐私保护程度。参照3.4节中用户真实的位置区域为j,所对应的熵值如式(1)所示。
在地图预处理算法中,所选取位置单元locu的查询概率为Pr(locu),遍历地图中的位置单元,选择和当前位置单元具有相近查询概率的位置单元,即,其中γ≥0。根据信息熵的定义,当选择的位置单元具有相同的查询概率时,信息熵值达到最大。假设locx和locy满足,其中0<p<1,当locx越接近时,的值越大,求导可得
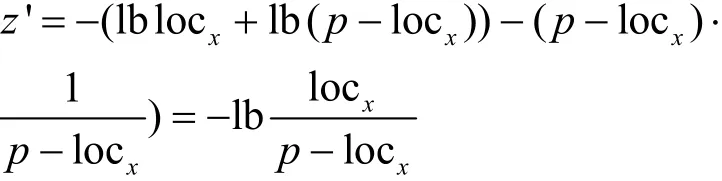

在地图预处理算法中参数γ≥0,则有当γ=0时,上述式子得到,即当所选取的位置单元的查询概率相同时取最大值。
6.2 性能验证
1) 执行时间和存储开销与参数k关系
本节评估了Ba-2PS和En-2PS的执行时间和存储开销随k匿名算法中参数k值变化的情况,如图5所示。Ba-2PS中没有参数γ的参与,故只考虑了En-2PS中γ=0.02和γ=0.12的情况。参数γ决定了选取匿名位置单元的查询概率的偏差度,参数γ越大,则集合η中的元素就越多,从而影响了算法的执行时间。Ba-2PS和En-2PS的计算和存储都在用户的智能移动终端中进行,终端中存储的数据大小并不会因为选取的k值大小而改变,故在图5(b)中算法的存储开销保持不变。En-2PS中,参数γ不影响通信开销,因此γ=0.2与γ=0.12这2条曲线重合。

图5 执行时间和存储开销与参数k关系
2) 执行时间和通信开销与参数γ关系
本节评估了执行时间和通信开销和参数γ的关系,如图6所示。Ba-2PS没有参数γ的参与,故只选取了k=20和k=50对En-2PS进行性能评估。用户利用移动终端将请求信息发送给服务提供商来换取服务,其中请求信息的大小决定了通信开销的大小,而请求信息的大小取决于匿名算法中参数k值的大小,而和参数γ无关。然而,参数γ的大小影响了集合η的大小,参数γ的值越大,则满足条件的位置单元就越多,故集合η中元素越多,在进行迭代遍历时消耗的时间更多。

图6 执行时间和通信开销与参数γ关系
6.3 隐私验证
本节分别从泄露概率、位置隐私和查询隐私3个方面对Ba-2PS和En-2PS的隐私性进行评估,同时与Spati-PPM算法[6]进行比较,验证本文方案的安全性。
实验比较了理论上的最佳值(optimal)、随机值(baseline)和Ba-2PS、En-2PS、Spati-PPM方案随参数k变化的泄露概率,如图7所示,k值越大,发送给服务提供商的请求信息就越多,则攻击者能推测出真实信息的概率就越低。
本文采用信息熵作为用户位置隐私和查询隐私的度量标准,具体的计算方式如定义2所示。信息熵,其中熵值越大,对应的位置隐私度量和查询隐私度量越高。因为 En-2PS在构造请求时对用户的请求范围进行了个性化选取,减小了攻击者利用查询范围和位置单元的可能性,进而实现推断攻击,降低了分析出用户敏感信息的可能性,提高了位置隐私和查询隐私的不确定性,如图8和图9所示。其中,Spati-PPM算法考虑了时间和空间之间的关联性,为攻击者推断用户的真实信息增加了难度,因此图8中该方案的位置隐私效果优于Ba-2PS,但因其未涉及对查询隐私的保护,图9中该方案的效果最差。En-2PS在考虑请求范围的同时,也在选取匿名位置单元时将时间因素考虑在内,避免了利用时空关联因素来推断出用户的真实位置信息和查询内容的可能性。
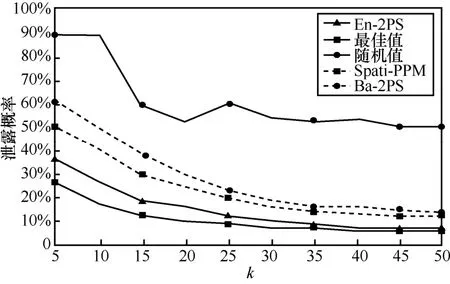
图7 参数k与泄露概率关系

图8 参数k与位置隐私度量关系

图9 参数k与查询隐私度量关系
7 结束语
在基于位置服务中,用户和服务提供商都会存储一定时间内的用户请求信息,因此,攻击者可以通过对历史查询信息的分析降低匿名效果。本文提出了一种隐私信息自关联的隐私保护方案,在选取匿名位置单元时考虑到用户自身的查询历史的自关联关系,避免了攻击者利用该信息来实现推断攻击。本文首先提出了一个基本的隐私保护方案Ba-2PS考虑了用户信息的自关联,进而从查询范围出发,提出了En-2PS,实现了对用户位置隐私和查询隐私的保护。最后,本文通过详细的性能和安全性实验验证了方案的有效性和安全性。
