基于边缘特征融合和跨连接的车道线语义分割神经网络
2019-06-11庞彦伟修宇璇
庞彦伟,修宇璇
基于边缘特征融合和跨连接的车道线语义分割神经网络
庞彦伟,修宇璇
(天津大学电气自动化与信息工程学院,天津 300072)
无人驾驶中的车道线检测任务需要同时确定车道线的位置、颜色和线型,而现有方法通常仅识别车道线的位置,不识别车道线的类型.为了端到端地解决这一问题,设计了一种语义分割神经网络,将一幅图像中不同车道线分割为不同区域,用每个区域的类别标签表示其对应的车道线类型.首先,在主流的编码器-解码器框架下,构建了一个结构较为简单的基础网络.考虑到边缘特征是车道线检测中的重点,为基础网络的编码器并联了一个边缘特征提取子网络,通过逐层融合边缘特征图和原始特征图增强车道线的特征.边缘特征提取子网络的结构与基础网络的编码器相同,其输入是对车道线图像进行Sobel滤波的结果.此外,编码器和解码器对称位置的卷积层输出的特征图尺寸相同,但具有不同的语义层级.为了更好地利用这一特性,建立从编码器到解码器对称位置的跨连接,在解码器逐层上采样的过程中融合编码器对应尺寸的特征图.在TSD-Lane车道线检测数据集上的实验表明,相比于基础网络,基于边缘特征融合和跨连接的神经网络的分割性能得到了较为显著的提高.该网络具有较好的车道线分割性能,能够在确定车道线位置的同时,区分黄线或白线、虚线或实线.在计算资源充足的前提下,该网络能够达到实时的检测速度.
车道线检测;语义分割;边缘特征;跨连接;神经网络
车道线检测是无人驾驶汽车的关键任务之一.车道线规定了无人驾驶汽车的行驶规范,是路径规划和智能决策的重要依据.当车辆沿当前车道行驶时,车道线的位置确定了路径规划的搜索边界;当无人车执行避障和超车等任务时,黄色和白色车道线用于区分对向和同向车道,车道线的虚实决定了车辆能否压线或越线行驶.因此,准确地识别车道线的位置、颜色(黄色或白色)和线型(虚线或实线),对无人驾驶汽车的安全、可靠行驶起着重要的作用.
目前,车道线检测算法主要分为两类:①基于手工设计特征的方法[1-2];②基于深度学习的方法[3-4].其中,基于手工设计特征的方法通常采用某种变换(如逆透视变换[1]、时空图[2]等),将车道线从交汇变为平行或接近平行,使用一维霍夫变换检测平行于车身的直线,通过样条曲线(spline curves)拟合或求解车道线模型的参数方程,获得车道线的位置信息.
Aly[1]提出的基于逆透视变换的方法,有效地降低了搜索直线的参数空间,加快了检测速度.基于该方法设计的车道线检测模块,在天津大学无人驾驶汽车系统上进行了测试.在实际应用中,发现该方法对于相机参数的变化较为敏感,同时,要求车道线较为平直,且平行于车身.此类方法在车身颠簸,车辆航向与车道线夹角较大,以及车道坡度较大等情况下都较易失效;同时,该方法不能区分车道线的颜色和 虚实.
近年来,随着深度学习的发展,国内外学者提出了多种基于深度学习的车道线检测方法.Li等[3]将卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural networks,RNN)结合起来,将待探测区域分成若干小块,卷积神经网络按照是否包含车道线对每块图像进行二分类,循环神经网络对包含车道线的图像块进行回归,以获得车道线的方向和位置.Gurghian等[4]通过在车辆侧面安装的俯视摄像头获取车道线图像,提出了一个端到端的卷积神经网络,直接估计车道线的位置.在检测车道线的位置方面,这些方法取得了很好的效果,但不能识别车道线的类型(如颜色、虚实等).
语义分割是将一幅图像分割为不同区域并识别出每个区域对应的类别标签.基于深度学习的语义分割算法[5-7]在交通场景认知和可行驶区域检测等方面取得了很好的性能.本文考虑在车道线检测任务中应用语义分割,将一幅图像中的不同车道线分割为不同区域,其类别标签即为不同的车道线类型(包括黄色实线、黄色虚线、白色实线和白色虚线),用于同时检测车道线的位置和类型.
基于上述思想,本文提出了一种基于边缘特征融合和跨连接的车道线语义分割神经网络,在编码器-解码器结构的基础上,为编码端并联一个边缘检测子网络,同时建立从编码端到解码端的跨连接,以融合不同语义层级的特征图.本文所提网络能够同时识别车道线的位置、颜色和线型,在TSD-Lane车道线检测数据集上取得了很好的实验结果.
1 相关工作
1.1 基于深度学习的语义分割
图像的语义分割可以视为对图像进行像素级别的分类,一直是计算机视觉领域的一个研究热点.深度学习具有强大的特征表达能力,泛化能力强,鲁棒性好,不仅能很好地完成图像分类任务,而且在图像的语义分割方面也取得了很大的进展.Long等[5]提出了全卷积网络(fully convolutional networks,FCN),用卷积层替换了传统分类网络中的全连接层,并用反卷积进行上采样,将端到端的卷积神经网络推广到图像的语义分割任务中.
SegNet[6]和U-Net[7]两种语义分割网络采用逐层降采样-逐层上采样的编码器-解码器(encoder-decoder)结构.其中,SegNet结构保存了编码器中池化层激活的位置,降低了上采样过程中的信息损失,在语义分割方面取得了良好的性能.
1.2 利用边缘信息的语义分割神经网络
在语义分割中,有效地利用边缘信息,有助于精确恢复分割区域的边界.DeepLab[8]采用条件随机场(conditional random field,CRF)对神经网络的分割结果进行优化,以获得更准确的边缘.针对CRF计算复杂度较高的问题,Chen等[9]使用域变换(domain transform,DT)保留图像中的边缘信息,在不降低分割精度的前提下,提升了网络的计算速度.在可行驶区域检测方面,Wang等[10]将局部先验信息引入全卷积网络,利用边缘检测引导语义分割,提升了网络的收敛速度,在KITTI路面检测数据集上达到了93.26%的准确率.
1.3 深度学习中的特征金字塔和跨连接
在深度神经网络中,随着网络层数的加深,每层输出特征图的语义层次逐渐提高,分辨率逐渐降低.浅层特征图中的语义信息较少,但目标的位置和边缘轮廓信息较为准确;深层特征图的语义信息较为丰富,但损失了目标的位置和边缘轮廓信息.因此,各层特征图可以视为一个自然形成的特征金字塔.有效地利用各层特征图中不同语义层级的信息,是提升基于深度学习算法性能的一个重要方法.
许多基于深度学习的方法显性或隐性地用到了神经网络中的特征金字塔,其中很重要的一种方法就是建立跨层的连接,融合不同层次的语义信息.Pinheiro等[11]提出的SharpMask结构,在传统的自下而上计算的卷积神经网络基础上,建立了一个自上而下的通路,使信息反向传递,起到了利用低层次语义特征的作用.Stacked Hourglass网络[12]和Recombinator网络[13]均采用了跨连接的网络结构,分别在人体姿态分析和人脸识别方面取得了很好的效果.Lin等[14]提出的特征金字塔网络(feature pyramid networks,FPN)同样采用跨连接的方式,在不同的特征层独立预测目标的位置和类别.
2 网络结构
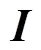


图1 网络结构
2.1 基础网络
本文所提网络以语义分割中广泛应用的编码器-解码器结构为基础,如图2所示.与传统语义分割任务相比,车道线的语义分割任务较为简单.因此,本文设计的基础网络与DeconvNet[15],U-Net[7]和SegNet[6]等网络结构相比采用了更少的卷积层.其中,编码器由4组“卷积-池化”块结构组成,每个卷积层包含64个7×7大小的卷积核,采用最大池化进行降采样.解码器由4组“上采样-卷积”块结构组成,选择反卷积(deconvolution)层实现解码器中的上采样.
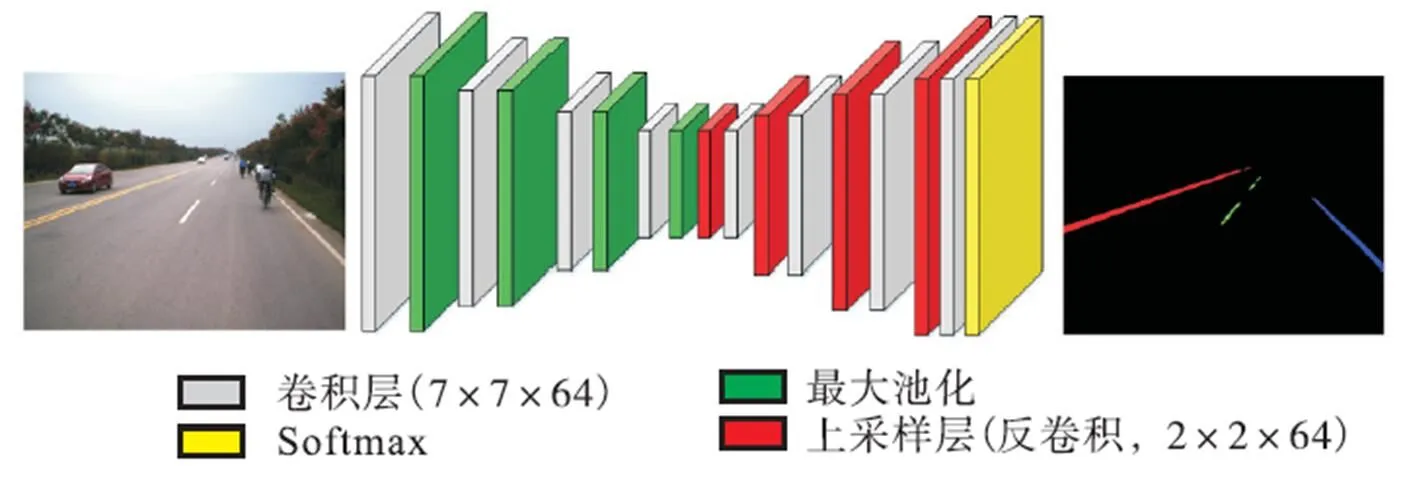
图2 基础网络结构
2.2 边缘特征融合的编码器
Wang等[10]指出,FCN等语义分割网络难以提取图像中的空间结构和边缘轮廓信息.由于Sobel边缘检测算子已经在车道线检测任务上取得了较好的效果,本文考虑在基础网络上融合Sobel边缘检测的结果.首先利用两个并列的子网络分别提取RGB图像和边缘图像中的特征,然后对两个子网络中对应尺寸的特征图进行逐像素运算,得到融合边缘特征的特 征图.
2.2.1 基于Sobel算子的边缘检测
在RGB图像转换为灰度图像的过程中,遵循式(1)进行颜色空间的转换.

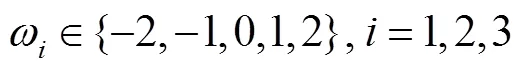
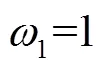
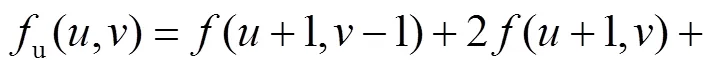
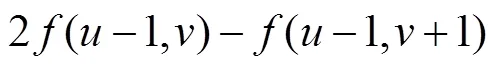
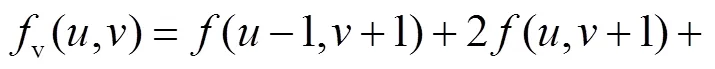
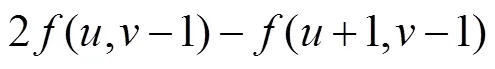

2.2.2 编码器的特征提取与融合
编码器由两个并列的子网络构成,分别提取RGB图像和边缘图像的特征.其中,RGB图像对应的子网络由4组“卷积-池化”块结构级联形成.池化层采用步长为2的2×2最大池化.卷积层首先用64个7×7的卷积核提取特征,然后进行批规范化(batch normalization,BN)[17],最后通过ReLU[18]函数进行激活,如式(5)所示.
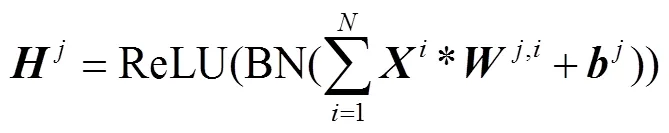


(7)

2.3 跨连接解码器
通过引入边缘特征融合策略,编码器在逐层降采样的过程中很好地保留了车道线的边缘信息.然而,在基础网络的解码器中,上采样是通过反卷积实现的,没有引入额外的边缘信息,因此难以恢复车道线的边缘和轮廓,甚至可能使得边缘特征进一步衰减和模糊.为了更加充分地保留和利用边缘信息,在边缘特征融合的编码器的基础上为解码器建立了跨连接,通过在上采样的过程中逐层融合对应尺寸的边缘增强特征图,进一步提升边缘特征融合的效果.
在基础网络中,解码器通过4组与编码器完全对称的“反卷积-卷积”块结构逐步恢复特征图的大小,直到与输入图像相同.这种网络结构的对称性,使得编码器和解码器中对称位置的特征图的尺寸恰好相同.同时,这些对称位置上的特征图具有不同的语义层级.编码器的特征图的语义层级较低,包含了丰富的边缘信息,但不能显著地区分车道线与非车道线区域.解码器的特征图具有较高的语义层级,能够显著地区分车道线与非车道线区域,但其边缘和轮廓则通常较为模糊.
为了更好地利用这种语义层级的互补性,采用类似FPN的结构建立跨连接,融合编码器和解码器中对称位置上尺寸相同的特征图.与FPN不同的是,每层融合得到的特征图不是单独进行预测,而是直接向下一层传递.如图5所示,每个跨连接通过1×1的卷积层对编码器输出的特征图进行选择;采用逐像素相加的方法,融合编码器和解码器中对应分辨率的特征图.
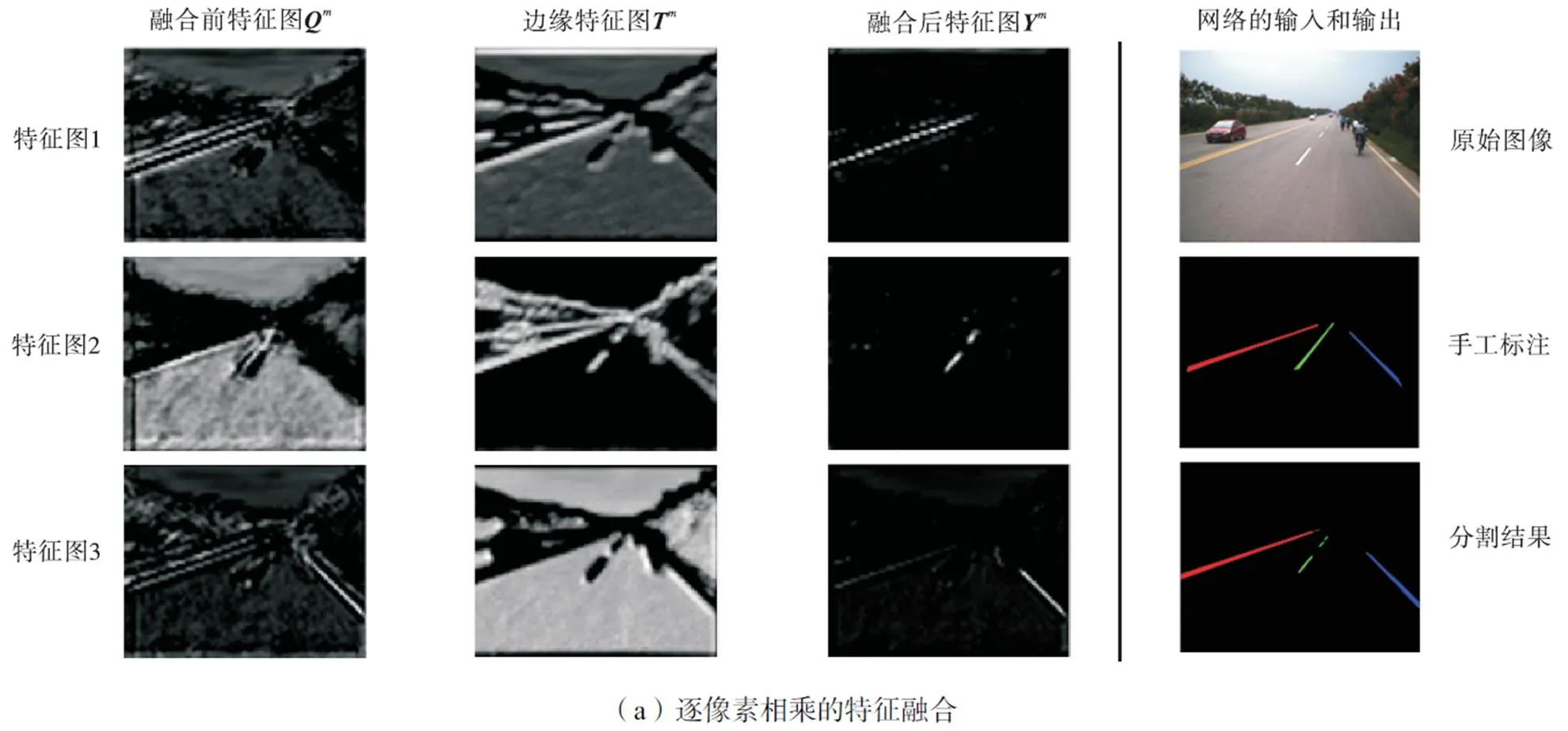
图6说明了跨连接特征融合的作用.在解码器逐层上采样的过程中,随着语义层次逐渐提高,获得的特征图丢失了车道线的部分位置和边缘信息.而编码器中语义层次较低的特征图,对车道线的位置和边缘信息保存得较好.跨层信息融合后,特征图在保留丰富的高层语义信息的同时,边缘和细节信息也得到了增强.
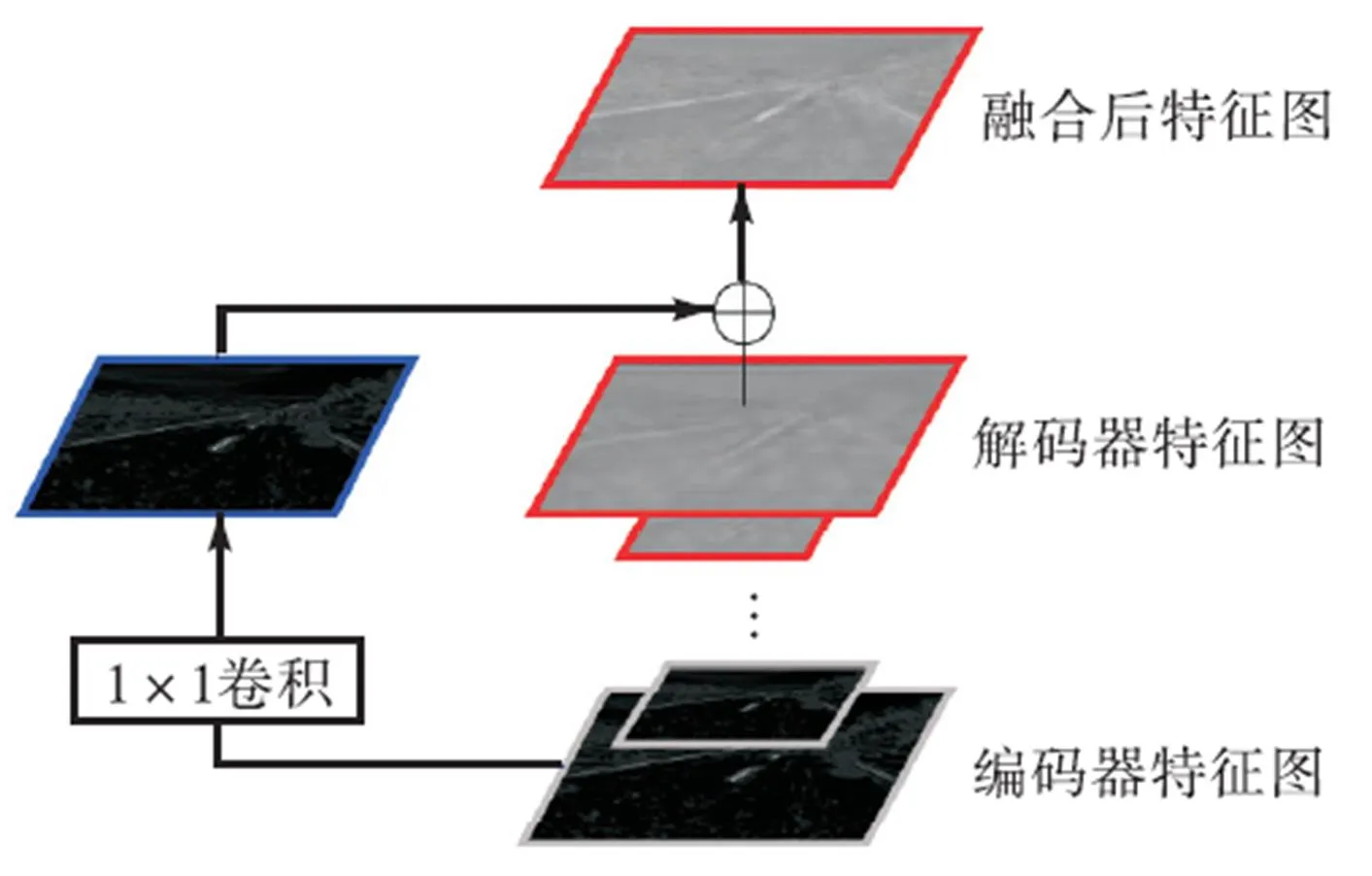
图5 编解码器对应特征图融合方法

图6 特征融合前后特征图的比较
3 实验及结果分析
为了验证提出方法的有效性,基于“中国智能车未来挑战赛”离线测试的车道线检测数据集(TSD-Lane)进行了实验,选择平均交并比(mean intersection over union,mIoU)作为网络性能的评价标准.
3.1 评价标准
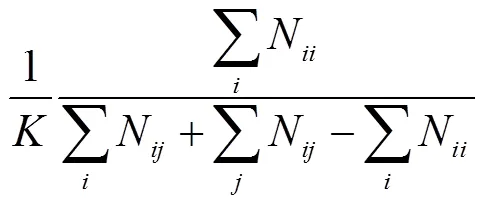
3.2 数据集介绍
TSD-Lane车道线检测数据集由西安交通大学人工智能与机器人研究所提供,是TSD-max交通场景数据集的一部分.该数据集的车道线图像由交通场景视频截取得到,分辨率为1280×1024.每段视频对应的标注数据由一个xml文件给出,其中包括车道线数量、车道线类型和车道线位置.车道线类型由字符串标明,有“黄色实线”、“白色实线”、“黄色虚线”、“白色虚线”4种.车道线位置由车道线左右边缘上的有序点表示.
为了适应实验的实际情况,首先将图像和标注同时降采样到分辨率为640×512.此外,对数据集的标注方式进行了改进,使用xml标签为每帧图像生成车道线语义分割的标签.车道线类型用颜色标注,“黄色实线”、“白色实线”、“黄色虚线”、“白色虚线”4种车道线类型分别以红色、蓝色、黄色和绿色显示.实验采用的数据集如图7所示,其中(a)为车道线图像;(b)为xml格式的标注数据;(c)为原始的车道线标注;(d)为改进的车道线标注.
选用视频编号为00~44的样本作为训练集(共5149张图像);视频编号为45~49的样本作为验证集(共450张图像).采用2017年“中国智能车未来挑战赛”离线测试数据集作为测试集(视频编号为51、52、56~58、65、68、74、76和96,共910张图像).
3.3 训练过程
考虑到交通场景图像中车道线所占区域很小,车道线像素数量远小于非车道线像素数量,选取如式(9)和式(10)所示的加权熵函数作为训练的损失函数.
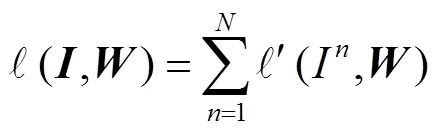

算法 中位数频率均衡算法.


图7 TSD-Lane数据集示例
3.4 实验结果
实验采用2017年“中国智能车未来挑战赛”离线测试数据集提供的910张样本图像及类别标签作为测试集,选择mIoU作为评价指标.
表1比较了逐像素相乘和逐像素相加两种特征融合策略,可以看出,逐像素相加的性能稍优于逐像素相乘,因此本文最终选用逐像素相加作为特征融合的方法.
为了分析边缘特征融合编码器和跨连接解码器对网络性能的影响,表2比较了基础网络在引入这两种结构前后的分割性能.
表1 两种特征融合方法mIoU的比较

Tab.1 Comparison of the two feature merging methods’ mIoU
表2 4种网络的mIoU比较

Tab.2 Comparison of the four networks’ mIoU
实验表明,在没有跨连接的情况下,引入边缘特征融合编码器之后,网络的性能比基础网络有所提升,但没有显著的提高.采用跨连接解码器能够较为显著地提高网络的分割能力.而在跨连接的基础上引入边缘特征融合编码器,能够进一步提高网络的分割能力.这可能是因为单独使用边缘特征融合编码器虽然能够增强特征图中的边缘和细节信息,但是这些信息又会在逐层上采样的过程中逐渐衰减.建立从编码端到解码端的跨连接,能够在上采样的过程中利用低语义层级特征图补充高层特征图的细节信息,因此能够更好地利用边缘特征融合的结果.
在Tesla P40、TITAN X以及Tesla K40三种主流深度学习显卡上测试了基础网络和本文所提网络的速度,对单张图像的测试时间如表3所示.实验表明,在计算资源充足的前提下,本文所提方法能够达到实时的检测速度.
上述实验证明了本文所提网络的性能相比于基础网络有了较为显著的提升.然而,通过观察发现,与其他类型车道线相比,实验结果中黄色虚线的分割效果较差.经分析,这是由于数据集的样本分布不平衡造成的.数据集的全部6509张图像中共包含19621条车道线,而其中黄色虚线仅有697条.为了改善这一问题,采用数据增强(data augmentation)扩充黄色虚线的样本,通过进一步训练微调(finetune)上文所述已训练好的模型.部分测试结果如图8所示,其中前6列为数据增强前的分割效果,后2列为数据增强后的分割效果.第1行为原始的车道线图像;第2行为人工标注的真实车道线标签(ground truth),由测试集提供,作为评价车道线识别算法准确程度的参照.第3、4行分别为基础网络和本文所提方法的分割结果.白色矩形框标注的区域对比了本文所提网络和基础网络对车道线的分割效果.可以看出,这两种基于语义分割的神经网络都能够同时识别车道线的位置、颜色和虚实.与基础网络相比,基于边缘特征融合和跨连接的语义分割神经网络提高了车道线的分割精度,能够更好地区分颜色相同的虚线和实线,尤其能够更好地识别磨损的车道线、距离较远而不清晰的车道线、前方较远处的转弯等复杂情况,在无人驾驶和辅助驾驶等方面有较高的应用价值.
表3 两种网络对单张图像的测试时间
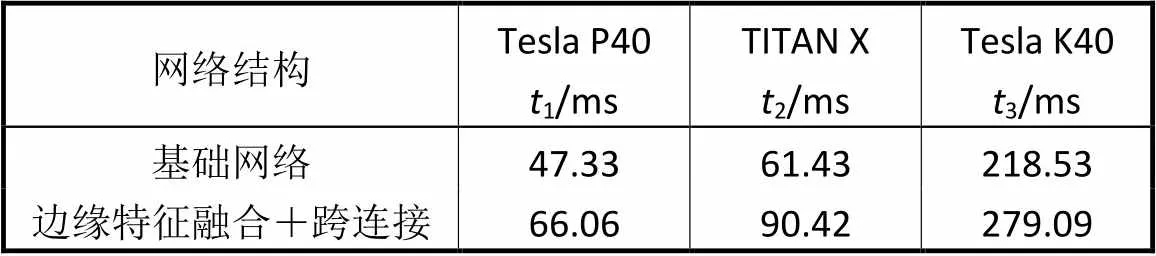
Tab.3 Testing time of the two networks on single image

图8 两种网络语义分割结果的比较
4 结 语
本文提出了一种基于边缘特征融合和跨连接的车道线语义分割神经网络,以编码器-解码器结构为基础,通过一个并联的子网络提取Sobel边缘检测结果的特征图,与原始特征图逐像素相加,增强车道线分割结果的边缘和细节.为了进一步利用语义层级较低的特征图,通过跨连接实现了特征融合,在保留高层语义信息的同时,优化了分割结果的边缘和细节.实验结果表明,本文所提方法能够较为准确地识别车道线的位置和类型,在计算资源充足的前提下,能够做到实时的车道线检测.
[1] Aly M. Real time detection of lane markers in urban streets[C]//Proceedings of IEEE International Vehicles Symposium. Eindhoven,Netherlands,2008:7-12.
[2] Jung S,Youn J,Sull S. Efficient lane detection based on spatiotemporal images[J]. IEEE Transactions on Intelligent Transportation Systems,2015,17(1):289-295.
[3] Li J,Xue M,Prokhorov D,et al. Deep neural network for structural prediction and lane detection in traffic scene[J]. IEEE Transactions on Neural Networks & Learning Systems,2017,28(3):690-703.
[4] Gurghian A,Koduri T,Bailur S V,et al. DeepLanes:End-to-end lane position estimation using deep neural networks[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Las Vegas,USA,2016:38-45.
[5] Long J,Shelhamer E,Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Boston,USA,2015:3431-3440.
[6] Badrinarayanan V,Kendall A,Cipolla R. SegNet:A deep convolutional encoder-decoder architecture for scene segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(12):2481-2495.
[7] Ronneberger O,Fischer P,Brox T. U-Net:Convolutional networks for biomedical image segmentation[C]//Proceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich,Germany,2015:234-241.
[8] Chen L C,Papandreou G,Kokkinos I,et al. DeepLab:Semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2018,40(4):834-848.
[9] Chen L C,Barron J T,Papandreou G,et al. Semantic image segmentation with task-specific edge detection using CNNs and a discriminatively trained domain transform[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:4545-4554.
[10] Wang Q,Gao J,Yuan Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection[J]. IEEE Transactions on Intelligent Transportation Systems,2018,19(1):230-241.
[11] Pinheiro P O,Lin T Y,Collobert R,et al. Learning to refine object segments[C]//Proceedings of European Conference on Computer Vision. Amsterdam,Nether-lands,2016:75-91.
[12] Newell A,Yang K,Deng J. Stacked Hourglass networks for human pose estimation[C]//Proceedings of European Conference on Computer Vision. Amsterdam,Netherlands,2016:483-499.
[13] Honari S,Yosinski J,Vincent P,et al. Recombinator networks:Learning coarse-to-fine feature aggregation [C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,USA,2016:5743-5752.
[14] Lin T Y,Dollár P,Girshick R,et al. Feature pyramid networks for object detection[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:936-944.
[15] Noh H,Hong S,Han B. Learning deconvolution network for semantic segmentation[C]//Proceedings of International Conference on Computer Vision. Santiago,Chile,2015:1520-1528.
[16] Li Q,Zheng N,Cheng H. Springrobot:A prototype autonomous vehicle and its algorithms for lane detection [J]. IEEE Transactions on Intelligent Transportation Systems,2004,5(4):300-308.
[17] Ioffe S,Szegedy C. Batch normalization:Accelerating deep network training by reducing internal covariate shift[C]//Proceedings of International Conference on Machine Learning. Lille,France,2015:448-456.
[18] Krizhevsky A,Sutskever I,Hinton G E. ImageNet classification with deep convolutional neural net-works[C]//Proceedings of Advances in Neural Information Processing Systems. Lake Tahoe,USA,2012:1097-1105.
[19] Eigen D,Fergus R. Predicting depth,surface normals and semantic labels with a common multi-scale convolutional architecture[C]//Proceedings of International Conference on Computer Vision. Santiago,Chile,2015:2650-2658.
Lane Semantic Segmentation Neural Network Based on Edge Feature Merging and Skip Connections
Pang Yanwei,Xiu Yuxuan
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
In autonomous driving,the lane detection task is required to detect the color,the type and the position of each lane. However,most existing methods usually detect the lane positions only,without recognizing the color and the type of each lane. To find an end-to-end solution to this problem,a semantic segmentation neural network is designed.In an image,different lanes are segmented into different regions.The label of each region represents the type of the corresponding lane. First,a rather simple base network is constructed basing on the main-stream encoder-decoder framework. Considered that edge features are important in lane detection,an edge feature extracting subnetwork is parallel connected to the encoder of the base network,enhancing lane features by merging original feature maps with edge feature maps layer by layer. The results of applying the Sobel filter to lane images are fed into the edge feature extracting subnetwork,which shares an identical architecture to the original encoder of the base network. Besides,the feature maps from the symmetrical convolutional layers of the encoder and the decoder have the same size,but their semantic levels are different. In order to make better use of this property,skip connections from the encoder to the decoder are implemented symmetrically,merging the corresponding encoder feature maps to the decoder feature maps in the procedure of upsampling. Experiments on TSD-Lane lane detection dataset demonstrate that the performance of the neural network based on edge feature merging and skip connections is improved rather significantly,compared with the base network. The proposed network provides good performance on lane segmentation,and it is able to detect the color,the type and the position of each lane simultaneously. Under the condition of having enough computational resources,the proposed network can achieve real-time detection.
lane detection;semantic segmentation;edge features;skip connections;neural networks
TP391
A
0493-2137(2019)08-0779-09
10.11784/tdxbz201802018
2018-02-08;
2018-04-16.
庞彦伟(1976— ),男,博士,教授.
庞彦伟,pyw@tju.edu.cn.
国家自然科学基金重点资助项目(61632081).
the Key Program of the National Natural Science Foundation of China(No.61632081).
(责任编辑:王晓燕)
