基于网页浏览内容的心理健康预测模型的研究
2019-06-06蔡伟鸿刘健全
蔡伟鸿,胡 江,刘健全,杜 鑫
(1.汕头大学工学院计算机系,广东 汕头 515063;2.日本NEC 公司,日本 东京 211-8666)
0 引言
随着社会的发展和科技的进步,人们的生活水平得到了极大的提高,身体健康已不再是制约个人发展的主要因素,而和人们密切相关的另一个因素:心理健康[1],逐渐浮现出来,成为了社会关注和研究的新焦点.心理问题在严重的情况下会导致精神障碍,进而对个体健康和社会稳定产生消极影响[2].有研究表明,心理问题会对个体的主观幸福感造成不利影响[3],导致情感失衡和对生活的满意度下降.另外,心理健康与身体健康之间存在着千丝万缕的联系[4],与一般人群相比,存在心理问题的个体的身体健康更容易出现问题[5],患有精神障碍的人群的慢性病的发病率和死亡率均高于一般人群[6].同时,心理问题也是导致人群“失能”的主要原因[7],到2020年有很大可能会成为仅次于HIV 的社会疾病负担[7].据调查,心理问题在我国人群中的覆盖率已经达到了17.5%[8].在中国,心理治疗非常昂贵而且繁琐,大量的精神障碍患者因为得不到有效的治疗而不得不忍受病痛带来的折磨,所以,做好有效的心理健康问题预防工作是非常迫切和必要的.
1 背景知识及相关工作
1.1 背景知识
通常,需要先获取个体的心理状态才能对其提供合适的心理健康服务,获取心理状态的方法之一就是进行“心理状态评估”.但是,心理状态具有内隐性,不能被直接观察到,比如嫉妒心理产生时大都不为主体所察觉,具有明显的内隐性[9],因此必须先将心理状态外显化和形象化才能进行下一步的心理状态评估,简单来说,就是通过设定一些合适的外显指标来进行间接的测量,这种方法就是心理测量.目前主流的心理测量技术是心理测评量表(如图1),因其在问卷编制、施测操作和结果统计等方面所具有的客观性、高效性和量化性,已经获得了在心理测量领域的广泛临床应用.但是,心理测评量表的测量结果的准确性会受到个体主观意识的影响,因为个体在填写量表时,既是“被观察个体”,又是“观察主体”,其回答会不可避免地受到其认知能力和社会虚荣心理的影响.为了克服心理测评量表存在的缺陷,本文提出利用用户的网页浏览内容作为外显指标来预测其心理状态(如图2),从用户的网页浏览内容中提取出相关特征,进而训练出心理健康预测模型.

图1 传统心理健康测量方法

图2 本文提出的心理健康测量方法
1.2 相关工作
心理健康和身体健康缺一不可,都是主体健康的必要条件.随着互联网的发展与应用,网络行为逐渐成为主体行为的重要组成部分,能够作为主体心理状态的外显指标,反映出主体的一部分内心世界.所以,将网络行为用于心理状态预测,是非常具有前景的研究方向.目前,国内外已经有学者和机构开始着手于网络行为与心理状态之间关系的研究,并取得了一些成果.王丽等人将神经网络技术用于预测研究生这一群体的心理健康状况[10],取得了较好的预测效果,在一定程度上为我国高校心理教育工作提供了有价值的研究成果,为高校完善心理教育工作提供了帮助.张磊等人通过分析中国庞大的社交网络,利用个体样本的主体特征和动态词典特征提取方法实现了对社交网络用户的心理指标的预测,找出了社交网络特征与心理指标之间的关系[11],更新了国内心理指标预测的记录.田玮等人采用深度学习技术对微博用户作出自杀风险预测,实验结果表明,基于深度学习的算法模型可以有效地对微博用户的自杀风险进行预测,为自杀预防工作开辟了新的方向[12].朱廷劭等人通过对用户的网络行为进行时频分析来预测其抑郁状况[13],实验结果表明,用户的网络行为的时频特征能够有效地反映用户心理健康状况的变化,有助于公共心理健康服务的广泛提供.郝碧波等人使用半监督学习的方法来预测社交网络用户的人格[14],实验结果表明,使用未标记数据可以提高预测的准确性,促进心理学人格研究的发展.朱廷劭等人发现用户的智能手机使用行为与其主观幸福感之间存在一定的联系[15],基于这些研究结果,他们利用智能手机的使用行为训练了主观幸福感的预测模型,实验结果表明,利用采集到的用户智能手机的使用浏览记录可以较好地预测其主观幸福感.郝碧波等人提出利用用户新浪微博的使用行为来衡量其大五人格[16],通过使用多任务回归算法和增量回归算法来预测在线行为中的大五人格.实验结果表明,通过用户的新浪微博使用行为可以对其大五人格进行预测.朱廷劭等人通过建立决策树模型来找出网络用户的网络行为与其心理健康状态之间的关系[17],实验结果表明,预测模型的准确率和召回率表现良好.此外,朱廷劭等人将机器学习应用于认知行为治疗过程,开发了一套心理健康自助系统.通过对随机用户进行比对调查,实验结果表明,这套系统可以有效地缓解用户的抑郁症[18].再者,朱廷劭等人提出利用用户看过的文章内容来预测其情绪,开发了一个带有可选加权系数的情感字典,并且训练了支持向量机模型和朴素贝叶斯模型,实验结果表明,预测模型的准确率、召回率表现良好[19].
通过对以上的工作进行详细调研,我们可以得到如下结论:
1.网络行为与心理状态显著性相关,网络行为能够用于预测心理状态;
2.国内外关于将网络行为用于心理健康预测的研究较少,并且截至目前还没有将网页浏览内容用于心理健康预测的相关研究;
3.很多研究收集网络行为的形式都是问卷调查,无法获得更加详实的用户的网络访问记录,这更凸显出了本文的工作意义.
网页浏览内容是网络行为的一种内容载体,能够用于心理状态的预测,而且比一般性的网络行为更加具体和可信.所以,利用用户的网络行为预测其心理状态是可行的.
2 心理健康预测模型
在本章节中,我们提出了自己的心理健康预测模型,介绍了它的原理和涉及到的算法应用.构建的模型流程可以分为数据收集、数据处理、模型训练、模型评估,具体流程如图3 所示.
2.1 模型的原理
在Brunswik 提出的“透镜模型”理论中指出,个体的周边环境中会包含有一些能够预示该个体精神状态的信息线索[20],这些信息线索可以看作是不同场景下的“行为残余”[21].用户的网络访问历史会被记录在访问控制系统的日志中,这些日志数据是客观而且准确的,可以从中获取更加精准和客观的用户网络行为数据.通过这种方式,不仅可以充分利用互联网的普及性和便利性进行大范围的数据采集,而且能够解决心理测评量表的测量结果会受到个体主观意识影响的问题.
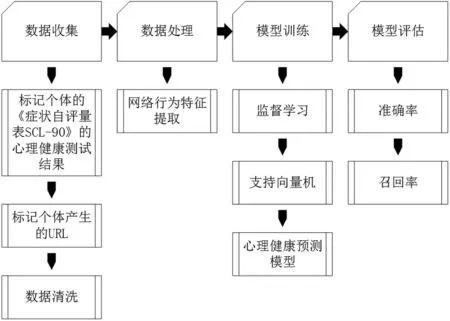
图3 心理健康预测模型构建流程
正是因为个体的网络行为是其在互联网上的行为残余,并且也属于人类行为总体的一部分,所以可以利用个体样本的网络行为作为外显指标来推测其心理状态.但是目前并没有一套公认的网络行为分类方法,由于本模型只需要能够显著反映心理健康状态的网络行为,为了使对心理健康的预测更加准确,所以用户的网页浏览内容这一网络行为在模型的原理中显的格外重要.
2.2 模型训练和评估
《症状自评量表SCL-90》是目前世界上最出名的心理健康测评量表之一,该量表共有90 个项目,包含有较为广泛的精神病症学内容,这90 个项目包含9 个因子,分别是躯体化(somatization)、强迫症状(obsessive-compulsive)、人际关系敏感(interpersonal sensitivity)、抑郁(depression)、焦虑(anxiety)、敌对(hostility)、恐怖(phobic anxiety)、偏执(paranoid ideation)及精神病性(psychoticism)。
本文利用机器学习中的监督学习方式,采用支持向量机建立了一个关于心理健康状态的分类模型.这种模型是一种典型的二类分类模型,它的定义域和函数的表示如下:

U是标记个体样本的网络行为特征矩阵,P 是标记个体样本的心理健康状态矩阵,R 是一个能够揭示标记个体的网络行为特征和心理健康状态之间潜在映射关系的投影矩阵.每个用户的网络行为特征是一个b 维的特征向量,定义为《症状自评量表SCL-90》某个因子下的项目个数.如果我们能够收集到标记个体样本的网络行为特征,就能建立起U;如果我们能够收集到标记样本的《症状自评量表SCL-90》的测评结果,就能建立起P.当U 和P 都建立好之后,就能建立起在心理健康预测模型中能够预测心理健康状态的关键的R.为了能够得到最优的R,我们定义了如下对象函数:

P0是《症状自评量表SCL-90》的测试结果,r是投影矩阵,本文的任务就是找到一个能够最小化f的r:
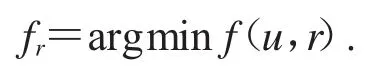
这种二类分类模型对应的评价指标被设定为精确率(precision)和召回率(recall).

表1 混淆矩阵
表1 所示的矩阵是一个二类分类模型的混淆矩阵(confusion matrix).混淆矩阵是数据科学、数据分析和机器学习中总结分类模型预测结果的情形分析表,以矩阵的形式将数据集中的记录按照真实的类别与分类模型作出的分类判断进行汇总,是对分类模型进行性能评价的重要工具.计算精确率和召回率需要用到4 个数值,它们分别是真阳值tp(true positive)、假阳值fp(false positive)、真阴值tn(true negative)和假阴值fn(false negative),这4 个数值的总和是样本集中样本的总数,即tp+fp+tn+fn=n,n 是样本的总数.
精确率衡量的是模型预测结果的精确度,对于一个二类分类模型,分为positive 类和negative 类,可以分别计算它们的精确率,计算公式如下:

召回率衡量的是样本集中样本被成功预测出的比率,positive 类和negative 类的召回率计算公式如下:

模型的准确率计算公式如下:

3 模型的实现
根据上文中的内容,我们根据理论模型搭建起了一整套系统,并对模型进行了实验和评估.在这节中详细介绍了两部分内容:1.模型实现的步骤和遇到的问题;2.将不同的算法进行对比,对它们的预测效果进行评估.
具体来说,首先需要收集模型建立过程中所需要的原始数据并进行数据清洗以达到实验标准,这一过程会利用现有技术和设备实现.其次,结合网络行为指标体系[22]从处理好的数据中提取出网络行为特征.接着,采用机器学习中的监督学习方式并利用支持向量机建立起基于网页浏览内容的心理健康预测模型.最后,结合现有预测模型的评价指标对基于网页浏览内容的心理健康预测模型的性能进行评估.
3.1 数据收集
本次实验中的样本数据收集来自课题组的80 位成员,62 位作为训练样本,18 位作为测试样本,实验周期为一年,从2016年1月1日至2017年1月1日.在实验周期内,收集了样本个人的上网记录,并标记了每个人的上网行为,对所有的数据进行脱敏,通过替代法去除隐私信息.最后,在这些完成后对他们进行《症状自评量表SCL-90》测试.需要注意的是,在这个过程中,我们计算统计出该标记样本在每一个因子下的得分,如图4 所示.
接下来需要获取标记样本产生的URL.为了获取标记样本在网络访问过程中产生的URL,需要在访问控制系统中部署网络流量监测设备,能够收集所有流经网关的数据包.网关是标记样本与互联网之间连接的关口,标记样本产生的所有网络访问请求都必须经过网关才能访问互联网.课题组所在实验室的网关处部署了一套访问控制系统,其中的网络流量监测设备会记录下所有的网络访问行为.该网络流量监测设备记录的网络访问行为日志较为详细,有用户ID、组名、源IP、终端类型、位置、目标IP、网站分类、标题、访问域名、URL 地址、时间,收集到的数据即刻利用替代法进行脱敏.
当网络流量监控设备截获到标记样本产生的数据包后,通过分析这些数据包的结构,解析出其中的URL,如图5 所示.
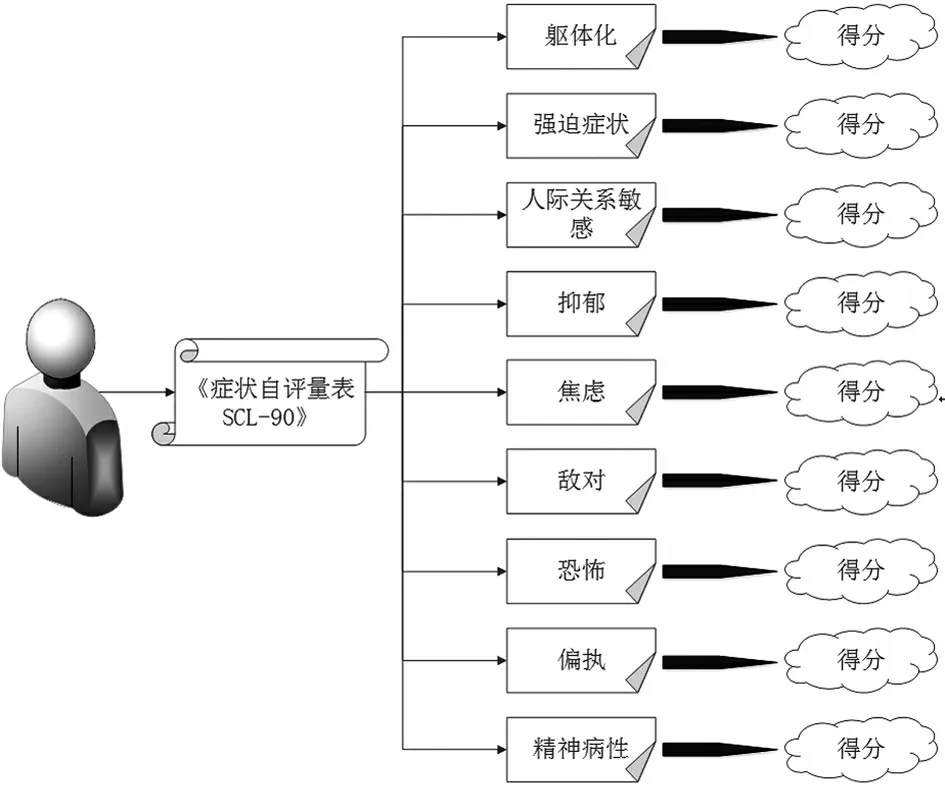
图4 获取标记个体的《症状自评量表SCL-90》的测量结果
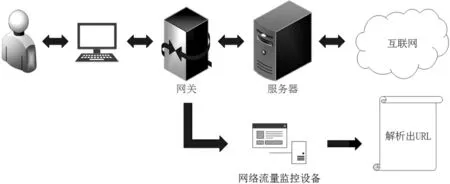
图5 获取标记个体产生的URL
在获取到某个标记样本产生的URL 之后,需要对URL 进行过滤和清理.因为不是所有的URL 都指向包含内容的HTML 文件,而且也有可能存在URL 重复的情况,所以有必要进行数据清理.首先去除重复和冗余的URL,然后清理掉指向非HTML 文件的URL.这一过程可以通过爬虫框架Scrapy 完成,使用的过滤规则如表2 所示.

表2 URL地址清理类别
3.2 数据处理
在这一个阶段,本文结合现有网络行为指标体系[22]和网络行为研究成果[23],从标记样本产生的网页URL 对应的网页浏览内容当中提取出标记样本的网络行为特征,即需要从这些网页浏览内容当中抽象出具有一般性和代表性的网络行为特征,提取流程如图6 所示.
Elasticsearch 是一个开源的全文搜索引擎框架,提供分布式多用户能力,可以快速地存储、搜索和分析海量数据.本文以标记个体访问的网页URL 作为源数据,使用Elasticsearch 即可得到属于该标记样本的搜索引擎实例,具体流程如图7 所示.
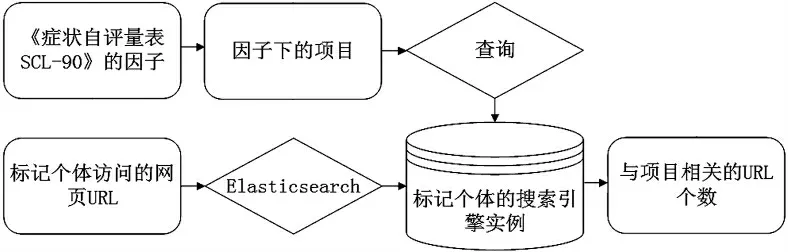
图6 网络行为特征提取流程

图7 标记样本的搜索引擎实例构建流程
《症状自评量表SCL-90》有9 个因子,每个因子下有一系列项目.标记样本的搜索引擎实例构建完成之后,在标记样本的搜索引擎实例中查询某个项目,得到与该项目相关的URL 个数,作为标记样本的网页浏览内容特征数据.具体流程如图8 所示.

图8 标记样本的网页浏览内容特征数据获取流程
例如,在“躯体化”因子下,有“头痛”、“头晕和昏倒”、“胸痛”、“腰痛”、“恶心或胃部不舒服”、“肌肉酸痛”、“呼吸有困难”、“一阵阵发冷或发热”、“身体发麻或刺痛”、“喉咙有梗塞感”、“感到身体的某一部分软弱无力”和“感到手脚发重”这12 个项目,以某个项目作为查询,在标记样本的搜索引擎实例中进行查找,得到与该项目相关的URL 个数,如图9 所示,实际结果如表3 所示.

图9 网络行为特征获取流程示例
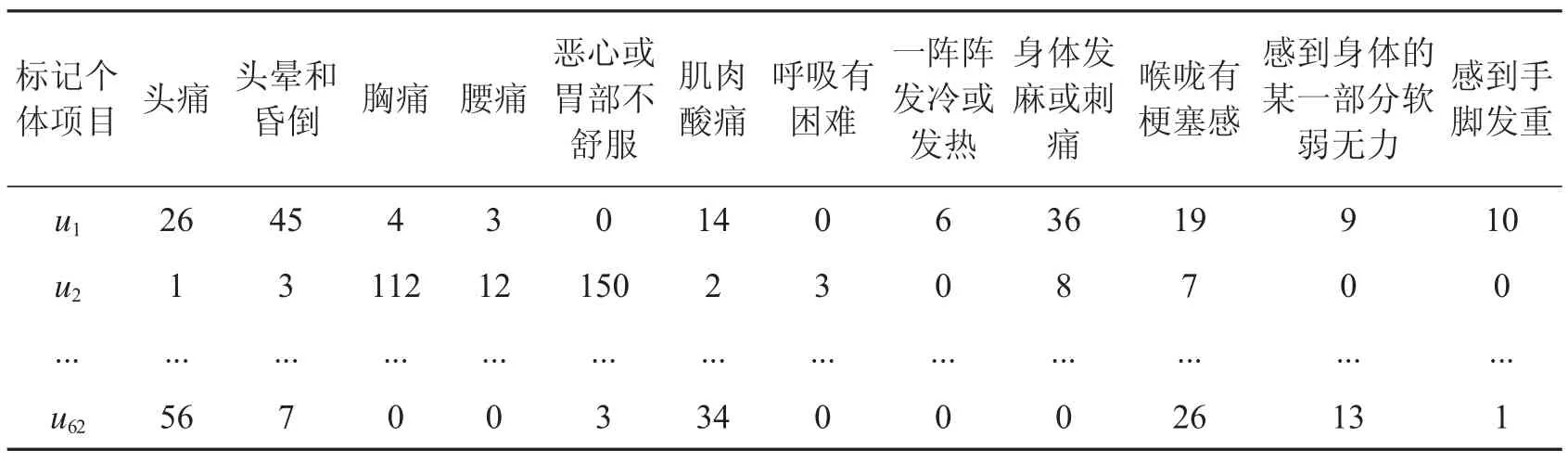
表3 “躯体化”因子下所有标记个体的网络行为特征
通过相同的方法,我们统计得出了“强迫症状”、“人际关系敏感”、“抑郁”、“焦虑”、“敌对”、“恐怖”、“偏执”及“精神病性”共8 种网络行为特征.
3.3 心理健康预测模型的建立
我们已经建立了数据基础,接下来是构建心理健康预测系统的详细步骤.相关原理已经在上文中有了充分的阐述.在接下来的系统建立中,主要工作是对标记样本的《症状自评量表SCL-90》的测评成绩进行处理.
进行这种处理的根据来源于心理学.研究表明心理状态是一个连续变化的过程,人群中的大部分个体的心理健康状态是稳定和积极的,相邻区间的差异较小.本文实验关注的目标是那些有可能存在心理健康问题的人群,为了尽可能地筛选出这部分人群,在心理测量学中,公认的测量方法是将所有被测试样本的心理测评量表的得分情况划分为高分组和低分组,即极端健康的样本组和极端不健康的样本组,希望能够通过这种划分找出显著的心理状态特征,高分组的样本有很大可能存在心理健康问题,低分组的样本存在心理健康问题的可能性较小.本文的实验即采取了这种划分方法.
首先,在每个因子下,根据标记样本的得分进行排序.然后,在每个因子下,根据排序结果,取前27%的标记样本作为低分组,用标签“-1”代表,取后27%的标记样本作为高分组,用标签“+1”代表.最后,利用之前收集好的每个因子下的标记样本的网络行为特征,再结合每个因子下的标记样本的分组结果,就得到了可用于模型训练的支撑数据,如表4 所示.

表4 “躯体化”因子下的训练数据
在得到每个因子下的训练数据之后,使用支持向量机为9 个因子分别建立了预测模型,这9 个预测模型相互独立.其中,模型训练所使用的程序来自LIBSVM,训练过程中使用的核函数是RBF(Radial Basis Function),并进行了相关参数调优,每个因子下的预测模型的参数如表5 所示.
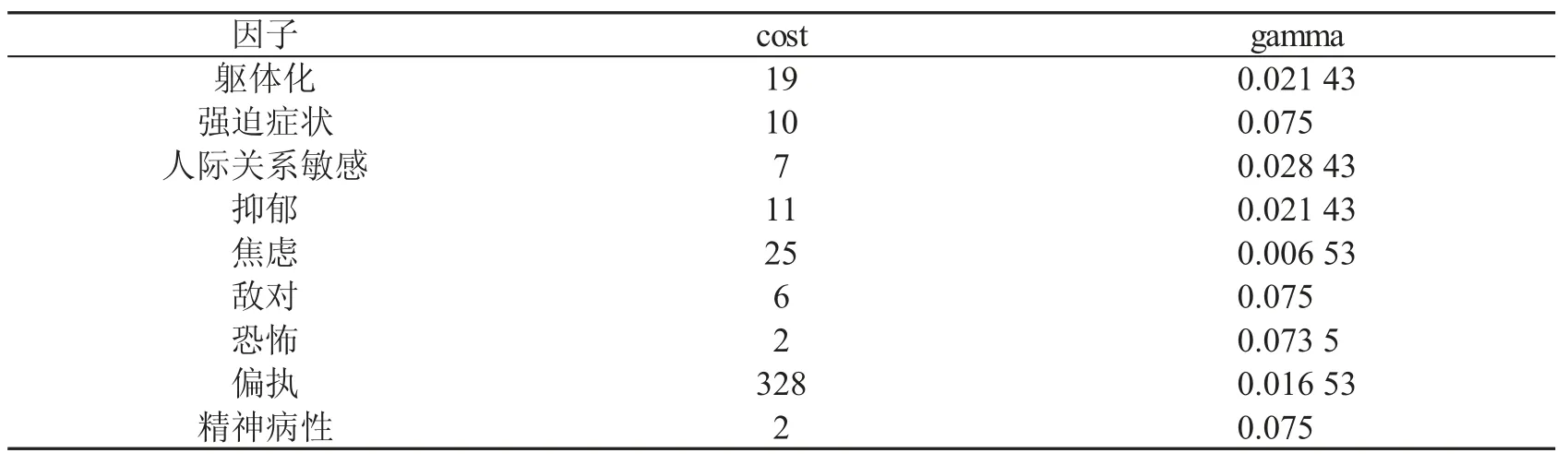
表5 每个因子下的预测模型训练时所使用的参数
通过以上这种形式,该实验建立了成型的系统,区分出了研究样本的具体参数的不同,并得到了每个对象心理健康的预测结果.
3.4 心理健康预测模型的评估
为了体现该模型的实用性和准确性,我们将本模型中使用的支持向量机与随机森林、朴素贝叶斯这两种传统机器学习算法进行了详细对比.它们都在9 个因子上进行了预测,并进行了5 折交叉验证,分别从模型准确率(如图10)与高分组召回率(如图11)进行了对照.
通过实验结果对比,可以得到使用支持向量机建立的预测模型的准确率平均值为89.39%,而使用随机森林和朴素贝叶斯建立的预测模型的准确率平均值分别为87.21%和82.28%.特别是支持向量机在“焦虑”因子下建立的预测模型的准确率最高,达到了95.01%,并且其高分组召回率也最高,达到了95.62%,反映出它可以很好地召回“焦虑”因子下的高分组人群.另一方面,使用支持向量机建立的预测模型的高分组召回率平均值为88.19%,而使用随机森林和朴素贝叶斯建立的预测模型的高分组召回率平均值分别为85.57%和81.13%.
综上可以得出,在本次实验的环境下,使用支持向量机建立的模型的预测效果整体上远优于使用随机森林和朴素贝叶斯建立的模型的预测效果.这种评估结果充分说明了本文中选择的机器学习算法的创新性和实用性.
4 结语
本文使用支持向量机分别为《症状自评量表SCL-90》的9 个因子建立了基于网页浏览内容的心理健康预测模型.在给出理论基础的前提下,设计出了区别于传统方式的心理健康模型.不仅如此,为了验证模型的可行性和准确性,本文展开了一系列具体的实验和结果评估,最终得到了良好的实验效果,充分说明本文提出的方法模型能够在一定程度上替代传统的心理测评量表,为心理卫生事业的发展提供帮助.

图10 模型准确率对比结果

图11 高分组召回率对比结果
虽然本文提出的模型取得了一些创造性的发现和效果,但仍然存在一些可以改进的地方,比如采取更加高效的机器学习算法来训练更加准确的心理健康预测模型;研究如何提取更加准确和有效的网络行为特征等.
