Lambda架构下基于用户行为的机构知识库推荐系统建设研究
2019-05-30邱煜炎
邱煜炎
摘 要:本文利用用户在线行为数据,构建了针对机构知识库的个性化推荐系统。具体方法为:基于大数据Lambda架构,实现系统对用户隐式和显式行为的数据采集、汇总、融合、计算功能,构建基于本体的加权向量用户兴趣离线计算模型;同时针对用户对机构知识库行为的反馈,进行实时推荐。最后得出结论:利用大数据思维和技术,构建多维度用户行为模型,对机构知识库的个性化推荐有一定实用价值。
关键词:机构知识库;推荐系统;大数据
中图分类号:TP393 文献标志码:A 文章编号:1673-8454(2019)07-0066-04
一、研究背景与意义
机构知识库(Institutional Repository)又称机构库、机构仓储、机构典藏等,是指大学或研究机构通过网络来收集、保存、管理、检索和利用其知识资源的数据库群。[1]随着开放存取运动的发展,机构知识库已经成为促进科技信息共享、提升机构知识管理和利用的重要力量,已经被全球学术界广泛接受并形成普遍共识。[2]
在国内,大型的机构知识库由于知识规模量大、分类详细、检索便捷,因此普及率较高[3];而对于单位自建的机构知识库,如果不能精确地推送用户感兴趣的信息,将很难建立稳定的用户群体。因此,为用户提供个性化精准实时的知识推送服务是提升机构知识库利用率的有效方法。
二、研究现状
针对机构知识库的个性化推荐研究,国内学者主要集中在系统设计和算法模型两方面。曹畋[4]针对中小型机构知識库的特点,提出一种综合性的智能推荐系统,通过分析用户行为数据对用户可能的偏好或有价值信息进行预测推荐。姜凯曦[5]利用占机构知识资源较大比重的隐性知识,针对用户隐性偏好构建基于社会网络模型的专家推荐系统。卞艺杰等[6]针对机构知识库资源推荐准确率低的问题,提出基于机构知识库用户模型隐性信息和显性信息的兴趣权重计算公式,提出了个性化推荐的总体架构。
综上所述,国内学者对于机构知识库推荐领域的研究都以用户兴趣建模作为首要切入点。但是,无论是模型还是算法,数据的规模决定了推荐质量的好坏。因此,笔者在前人研究的基础上,结合大数据数据量大、多维度、实时性高的特点,遵循机构知识库开源软件DSpace的开发原则,引入基于Lambda架构的大数据平台。利用大数据Hadoop[7]生态组件对用户的行为数据进行采集、汇总、清洗,并融合DSpace业务数据,在统一数据源的基础上,采用本体加权向量模型,对用户兴趣模型进行离线训练。此外,在离线推荐的基础上,利用大数据实时流技术对用户的机构知识库在线日志数据做实时过滤,获取用户当前所需资源信息,融合离线推荐和实时推荐结果,实现对用户隐式行为进行实时推荐反馈的功能。
三、系统架构设计
1.设计思路
用户在机构数据库使用过程中,会产生大量显式和隐式行为数据。其中显式行为数据包括用户所属的专业领域、输入的兴趣项以及搜索记录、用户对资源评价等;隐式行为数据分为点击记录、浏览记录以及页面驻留时间等。机构知识库开源软件DSpace无法获取用户隐式行为日志,并做到有效分析,因此无法满足系统实时推荐的需求。本文的设计思想是通过对用户显式和隐式行为进行综合分析,建立用户兴趣模型库,将资源文本特征模型与用户兴趣模型进行匹配,从机构知识库中查找出与用户模型相匹配的资源。同时,在传统离线推荐的基础上,实时分析用户在线行为,并融合离线推荐模型,及时反馈针对用户当前行为的实时推荐列表。
2.系统架构
传统单机环境下的推荐系统无法满足大数据规模资源的存储与计算需求,Hadoop平台作为大数据技术的事实标准能够处理海量数据。Lambda[8]架构由Storm项目发起人Nathan Marz提出,集成了Hadoop、Kafka、Storm、Spark、HBase、Redis等各类大数据组件,提供了一个结合实时数据和Hadoop预先计算的数据环境混合平台,具有高容错、低延时和可扩展的特点,见图1。
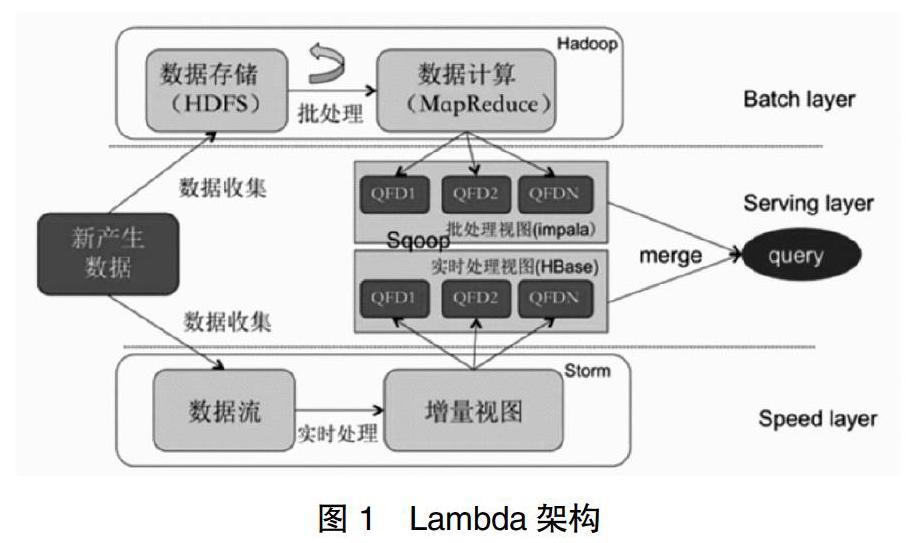
本文采纳了Lambda架构的技术特点,设计了融合历史数据离线计算、分布式日志采集、推荐数据及时反馈的机构知识库推荐系统,见图2。
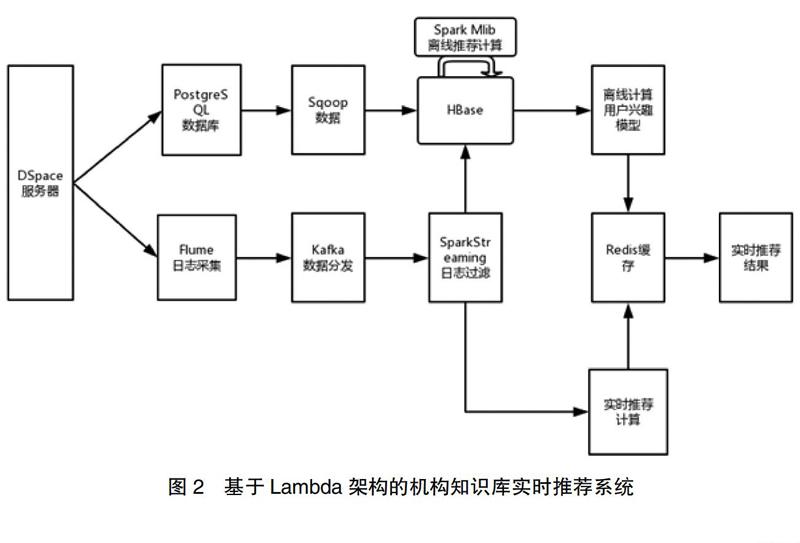
3.系统模块
基于Lambda架构的机构知识库实时推荐系统主要分为三大模块:数据采集模块、数据处理模块和实时推荐模块。
数据采集来自两部分数据:关系型数据库PostgreSQL和日志采集工具Flume。机构知识库软件DSpace的用户服务接口包括浏览、检索、定制、订阅、RSS,并将用户显式行为数据存储在关系型数据库PostgreSQL中。此外利用分布式日志收集工具Flume,实现对用户点击、浏览、页面有驻留时间的日志进行收集。系统植入在应用网关处的日志监控可以实时监测日志文件的变化,并根据偏移量,读取最新日志信息,然后将日志输出到 Redis 中缓存起来。
数据处理分为离线和在线计算两部分。离线计算采用Spark[9]平台构建用户兴趣模型,其主要思路是将用户行为数据对应的项目所匹配的本体关键词进行提取,根据不同的行为权重构建用户关键词向量矩阵,以此将最重要的TopN向量作为该用户兴趣模型。在进行离线计算前,需要将数据进行汇总,关系型数据库PostgreSQL的数据可以通过Sqoop工具加载到分布式数据库HBase中。而日志缓存数据库Redis利用消息分发工具Kafka接入实时处理框架Spark Steaming进行日志过滤,抽取出用户点击行为、用户浏览行为和页面驻留时间数据,写入HBase数据库中。
系统实时推荐主要对用户行为进行及时响应处理。本文针对用户的每次访问,可以通过Spark Streaming实时过滤日志信息,抽出所需要的信息,获得与该项目相似的前N位资源列表,并与用户兴趣模型进行混合处理,进行重新排序,使得机构知识库可以感知用户实时行为,提高知识服务质量。
四、关键技术
1.用户兴趣模型设计
对于用户兴趣模型的表示,文献[10]提出了基于本体的加权向量表示方法,是指将本体引入向量空间模型中,向量空间的每个词都来自于本体。因此,本文提出基于本体加权向量模型的用户兴趣模型PM(Personal Model),将用户偏好表示为一个二元组特征向量PM={(c1,w1),(c2,w2)...(cn,wn)}。
对于(ci,wi,bi),i∈[1,n],n为兴趣总量,Ci表示用户的某一兴趣项,即本体中的概念或实例名称;Wi是用户兴趣的权重值,值域为[0,1],数值越高,兴趣值越大。用户兴趣模型初始化值全为0。
2.用户兴趣项权重值设定
用户对机构知识库行为数据反映出用户的兴趣偏好程度,合理的行为量化指标,决定了推荐模型的质量。用户行为分为显式行为和隐式行为两部分,根据前人研究[6]发现,显式行为反映了用户的主观兴趣表达,是用户的长期兴趣偏好。而隐式行为反映的是即时兴趣表达,具有临时性、随意性的特点。因此,显式行为偏好权重要高于隐式行为权重。
(1)在DSpace平台中,用户选擇若干初始设定的本体关键词作为兴趣项Ci,说明对这些领域非常感兴趣,对应的权重Wi值为1。
(2)当系统获取到用户的搜索关键词与本体关键词Ci匹配时,说明用户对这一领域表示出了一定兴趣,由于搜索具有临时性、随意性特点,因此权重Wi应低于用户自己设定的兴趣项,记为0.6。
(3)在用户主动上传知识资源的过程中,通过已提交的关键词与本体关键词匹配,说明用户对这一领域表示出极大的兴趣,对应的权重Wi值为0.8。
此外,机构知识库资源可以由若干本体概念来描述,本文以本体概念的前三位关键词作为资源的主要描述,每个资源对应关键词的首尾位置赋予不同的权重Pj(j∈[1,2,3]),分别是1.0,0.8,0.6。用户对资源兴趣度记作Sk(k∈[1,m],m为资源的个数),因此,用户通过兴趣度反馈获取用户兴趣项权重值Wi=Sk*Pj。
(4)用户对资源的显式行为表现在对资源的评价反馈上,评价标准分为不关注、不太关注、比较关注和很关注四个层次,对应用户对资源的兴趣度Si值为0(不关注)、0.3(不太关注)、0.6(比较关注)、1.0(很关注)。
(5)通过Lambda平台的Flume日志采集软件,可以获取用户对资源的隐式行为数据,主要表现在对资源的点击次数(记为f)和页面驻留时间(记为t)上,由于点击行为具有一定偶然性,只有当驻留页面时间超过一定阈值t1时,才能反映出用户对该资源表示出一定的兴趣。而且在一段时间t2内,用户如果对某一资源点击次数增加,说明用户对此资源表示出极大的兴趣。综上,得公式如下:
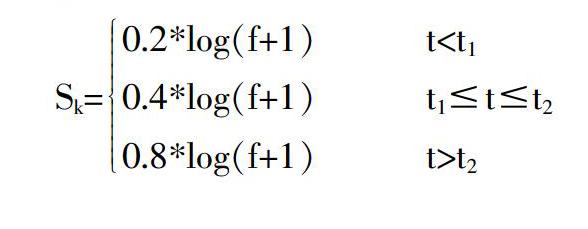

矩阵UiIj表示第i个用户对第j个资源的兴趣程度,对UI矩阵按行进行排序,即可生成用户离线推荐模型。离线模型训练完毕后,将每个用户的推荐列表写入Redis缓存系统,优化平台性能。平台根据用户实时点击行为,取得资源ID,利用离线推荐模型取得与之相似的前5个资源。最后在Redis缓存系统中找到对应用户ID的推荐列表,删除原有的最后5个资源,将刚刚计算的5个资源放入Redis推荐列表队首中。
通过上述离线推荐和实时推荐的融合,完成基于Lambda架构的机构知识库实时推荐模型,达到及时响应、实时反馈的目的。
五、实验分析与结果
1.数据来源
本文以蚌埠医学院口腔医学机构知识库作为实验数据,该资源包含文献602篇、视频资源22部、图片资源85张;用户数391人,其中包括本科生327人、研究生23人、专业教师13人、附属医院口腔专业医生28人。
2.实验环境
本文实验环境如下:6台Linux服务器,版本为CentOS6.5;每台服务器配置8核CPU、16GB内存和1TB硬盘。其中3台服务器用来搭建Lambda平台,1台服务器用来进行数据采集,1台服务器用于数据缓存,1台服务器用来进行前端展示。软件配置如表1所示。

3.实验说明
为了验证用户兴趣度模型以及推荐系统的有效性,笔者邀请10位不同角色的用户进行测评。利用推荐系统结合用户在线行为,为用户推荐20项资源,并对推荐结果进行打分。采用信息检索领域广泛使用的查准率(precision)来评价实验效果。结果如表2所示。
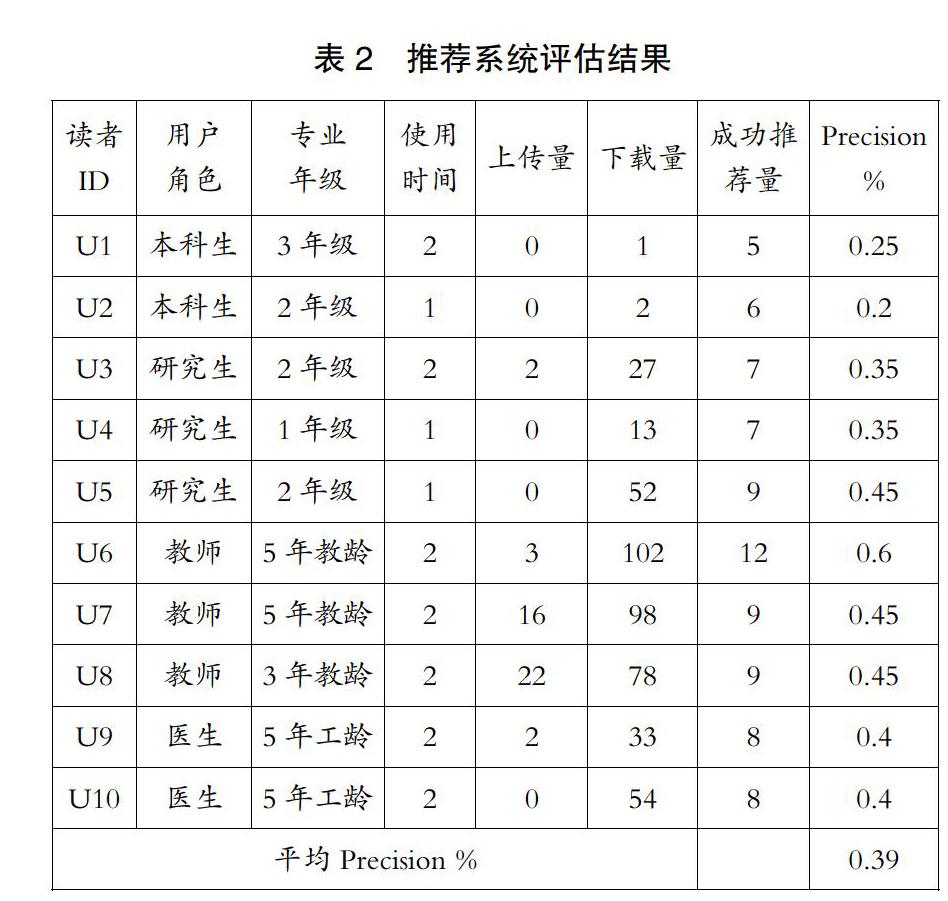
结果显示,10位用户对推荐质量的总体评价不高,均值为39% 。而随着用户对机构知识库使用频率的上升,推荐质量呈一定的上升趋势。
六、结束语
本文设计和实现了大数据环境下基于Lambda架構的机构知识库在线推荐系统,提出了基于用户行为的评分模型,并将隐式行为添加到评分模型中,优化模型结构。实验证明,随着用户对机构知识库使用频率的上升,推荐系统效果提升明显。鉴于Lambda架构获取的数据具有数据量大、实时性高、多样性等优势,下一步工作将引入对资源描述的特征提取算法,而不仅仅依赖于用户设置的关键词作为本体特征进行提取,设计多模型的数据处理方式,进一步提升推荐效果。
参考文献:
[1]张恒娟,邱亚娜.基于Dspace的中医药机构知识库构建研究[J].科技情报开发与经济,2010(1):19-21.
[2]中国机构知识库推进工作组.2018年第六届中国机构知识库学术研讨会报告[R].2018.5.
[3]张雅琪,盛小平.国内外机构知识库评价研究进展与评述[J].图书情报工作,2015,59(9):127-135.
[4]曹畋.探究适合中小型机构知识库的智能推荐系统[J].农业图书情报学刊,2016,28(3):5-9.
[5]姜凯曦.IR中基于社会网络模型的专家推荐系统构建分析[J].电子测试,2013(19):139-140.
[6]卞艺杰等.机构知识库个性化推荐的用户模型研究[J].情报理论与实践,2013,36(12):78-82.
[7]林子雨.大数据技术原理与应用[M].北京:人民邮电出版社,2017:286.
[8]佚名.技术文档[EB/OL].https://en.wikipedia.org/wiki/Lambda_architecture,2018.
[9]Matei Zaharia, M.C.M.J., Spark: Cluster Computing with Working Sets, in Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010.
[10]蒋秀林,谢强,丁秋林.基于领域本体的用户模型的研究[J].计算机应用研究,2012,29(2):606-608.
[11]Peter,H., Machine Learning in Action[M].北京:人民邮电出版社,2013.
(编辑:王晓明)
