基于分层模糊支持向量机的油液磨粒自动识别*
2019-05-30
(重庆大学煤矿灾害动力学与控制国家重点实验室 重庆 400030)
视情维修理念的提出为机械设备的运行维护提供了一个新的突破口,解决了长期定期维修下的种种弊端,在故障潜在阶段即可采取相应的维修维护措施,避免其进一步扩大引起设备的功能故障。油液分析技术是视情维修理念指导下典型的设备故障诊断与监测方法之一,它以油液性能检测及油液中的磨损颗粒分析为核心,通过磨粒的形貌特征来识别磨粒类型,继而判断设备当前的磨损程度及失效原因,减少甚至消除设备以磨损失效为主的突发性故障。磨粒分析是油液监测的重要内容,该项工作提出之际均为人工分析,耗时长、误差大,严重限制了油液分析技术在工程领域的广泛应用。近年来,不少学者在磨粒的智能分析领域开展了大量研究,灰色系统[1]、神经网络[2-4]、支持向量机[5-7]、决策树[8]、证据推理规则[9]等都被用于磨粒识别领域且取得了一定的成果,磨粒分析工作逐步实现自动化,分析效率得到了明显的提高。
受磨粒样本数量、高维特征参数的影响,以小样本为研究对象的模式识别方法在磨粒分析工作中表现出更强的适用性,支持向量机在解决小样本、非线性、高维特征问题上的特有优势,更是在磨粒自动识别领域显示出了十足的发展前景。传统支持向量机、最小二乘支持向量机作为目前应用最广泛的识别模型,其在测试样本集上虽然表现出较高的识别精度,但在实际应用过程中,模型的泛化能力依旧不足。受运行工况影响,设备在用油液携带有各种形态的磨损颗粒,某些磨粒呈现多种磨损机制作用下的复合特征,当这些磨粒作为训练样本时,其本身包含了对类别的隶属信息,而传统支持向量机(Support Vector Machines,SVM)、最小二乘支持向量机(Least Squares Support Vector Machines,LSSVM)模型均未考虑训练样本对分类结果的贡献程度这一因素,而将所有样本同等对待,使得支持向量机的理论优越性在磨粒自动识别工作中难以完全凸显,模型的泛化能力受到影响。
除此之外,支持向量机现有的构造多类别分类器的方法,包括一对多法(one-against-rest,o-a-r)、一对一法(one-against-one,o-a-o)、有向无环图法(Directed Acyclic Graph,DAG)、二叉树法(Decision Tree,DT)[10]等,在完成磨粒多类别分类时也出现了不少问题。例如,o-a-r法的每个二分类器都有庞大的训练样本集,模型的分类效率难以提高;o-a-o法与DAG法需要构造的二分类器数量多,模型的累积误差严重;DT法的分类效果很大程度上取决于二叉树的结构选型,分类误差始终处于不可控状态。因此,有必要考虑更适合磨粒识别的多类别分类模型,让模型在分类器数量、训练效率及分类精度之间取得最佳折中,充分发挥支持向量机的性能。
本文作者将模糊支持向量机应用到油液磨粒的自动识别工作中,通过引入隶属度函数来使训练样本集包含对类别的隶属信息,同时基于现有的多分类算法构造一种更适用于磨粒识别的参数自适应分层多分类模型,以期进一步提高油液磨粒分析技术的工程实用性,促进故障诊断在工业生产中的广泛应用。
1 油液磨粒自动识别的核心内容
1.1 待识别磨粒类型的确定
机械设备在用油液中的游离金属磨粒包括正常磨损磨粒与异常磨损磨粒,异常磨粒按磨损机制可以划分为切削磨粒、严重滑动磨损磨粒、滚滑复合磨损磨粒、疲劳片状磨粒、疲劳块状磨粒及球状磨粒。正常磨粒产生于设备运行全寿命周期的各个阶段,单个粒子不携带有任何设备异常磨损的信息。而异常磨粒与磨损工况密切相关,油液中一旦出现这些类型的磨粒,无论数量分布多少,都预示着机器内部可能已经出现了相应形式的磨损。这是异常磨损信息最早期的表现形式,磨粒类型的判定对磨损部位的判断和磨损严重程度的确定都有很强的指导作用。因此,本文作者选择6类异常磨损磨粒为待识别对象,设计分层多类别模糊支持向量机模型完成磨粒的自动识别工作。
1.2 磨粒自动识别流程
利用铁谱技术或滤膜谱片技术提取油液中的磨损颗粒,基于显微镜获取磨粒图谱,作为磨粒自动识别工作开展的前提。完成图像的获取后,即可开展磨粒的自动识别工作,其实现流程如图1所示。
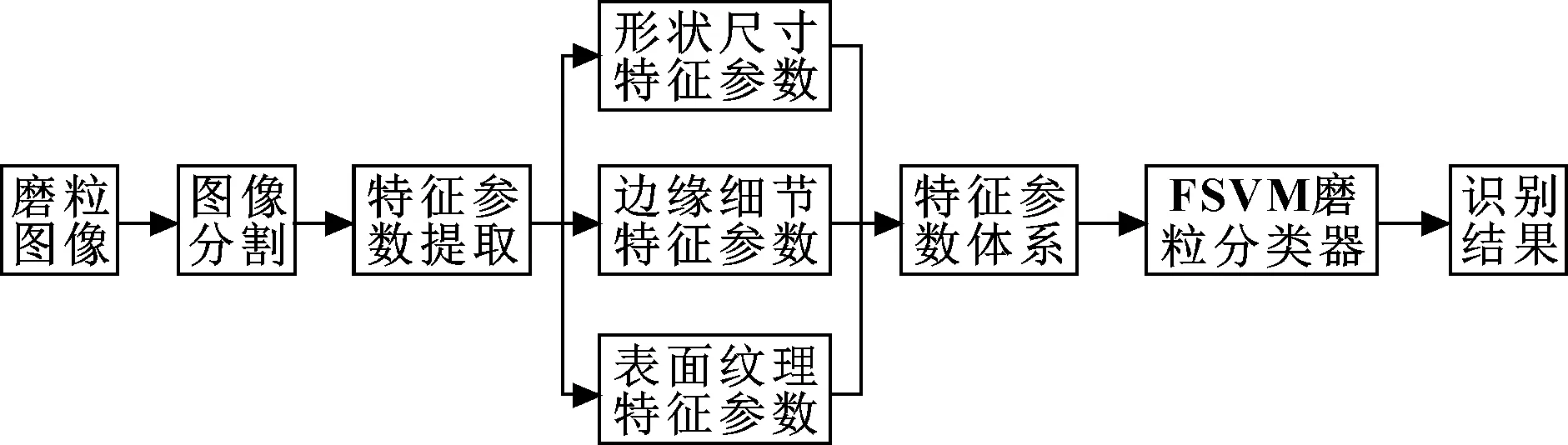
图1 磨损颗粒自动识别流程
1.3 磨粒图像分割
为了实现磨粒与背景的准确分割,最大化保留原始图像的信息,文中直接对彩色图像进行分割,在Lab颜色空间中利用K-均值聚类算法实现目标磨粒的提取,具体分割流程参照文献[11]。图2所示为一严重滑动磨粒的分割实例。

图2 严重滑动磨粒图像分割实例
1.4 磨粒特征参数提取
特征参数作为磨粒的量化表征,必须能够代表磨粒的典型形貌特征,以保证在特征量化的过程中不会丢失磨粒形貌的关键信息,最大化还原磨粒的区分度。根据六类待识别磨粒的形貌特征,文中选择形状尺寸特征参数、边缘细节特征参数、表面纹理特征参数构成了磨粒的18维特征参数体系。
(1)形状尺寸特征参数
对磨粒的轮廓曲线进行Fourier变化即可提取具有平移旋转不变性的形状特征参数。文中主要基于磨粒的轮廓曲线提取了其相应的傅里叶描述子[12],计算得到圆形度F1、细长度F2、散射度F3、凹凸度F4等形状特征参数。为了尽可能降低磨粒轮廓跟踪过程存在的误差,文中又基于磨粒的二值图像提取了区域形状描述子作为修正,包括矩形度AP及体态比AR,形成6维形状尺寸特征参数。区域描述子的定义如下:
AP=A/P
(1)
AR=a/b
(2)
式中:A、P分别为基于区域统计的磨粒面积与周长;a、b分别为磨粒区域最小外接矩形的长轴与短轴。
(2)边缘细节特征参数
边缘细节特征参数是反应磨粒轮廓随机程度和复杂程度的典型参数,文中采用FAENA法[13]提取磨粒的边界分形维数D作为其边缘细节表征。
(3)表面纹理特征参数
表面纹理参数主要基于灰度共生矩阵[14]提取。将原图像的灰度级压缩至16级,提取对比度CON、相关性COR、能量ENG、熵ENT、一致度HOM等二次统计量在0°、45°、90°、135°方向上的均值m与方差v作为磨粒的纹理表征。考虑到图像灰度级压缩过程可能造成的信息损失,提取磨粒表面灰度值的方差GM作为补充,形成11维表面纹理参数。参数GM的定义如下:
GM=
1pixels∑p∈s[gray(xp,yp)-1pixels∑p∈sgray(xp,yp)]2
(3)
式中:s为磨粒区域;gray(x,y)为磨粒区域(x,y)点的灰度值;pixel为磨粒区域s的像素点个数。
表1所示为待识别6类磨粒的18维特征参数提取结果示例。

表1 磨粒特征参数提取结果示例
1.5 二分类模糊支持向量机模型的建立
模糊支持向量机[15](Fuzzy Support Vector Machines,FSVM)是传统支持向量机的一种变形算法,通过隶属度函数实现样本集的模糊处理,使训练样本集包含有对类别隶属程度的信息,以此来提高分类器的推广能力。
对于二类别分类问题,选择n个类别已知磨粒的特征参数体系构成训练样本集,首先定义适当的隶属度函数完成样本的模糊化,将训练集转化为模糊训练集:
train={(xl,yl,tl),l=1,.....,n}
其中:l表示第l个样本;xl为磨粒样本的特征参数向量;xl∈Rn;yl为样本xl的所属类别;yl∈{-1,1};tl为样本xl属于某类的隶属度,满足δ≤tl≤1,其中δ为任意一个极小的正数。
对于非线性可分的训练数据集,(w,b)在特征空间中确定唯一的最优超平面,满足w·x+b=0,使得两类样本之间有最大的分类间隔。模糊支持向量机在最优超平面的求解问题上,采取将其转化为目标函数的最优解问题这一思路进行求解:
min12‖w‖2+C∑nl=1tlξl
s.t.{yl(wlxl+b)≥1-ξl,l=1,2,......,n
ξl≥0,l=1,2,......,n
(4)
式中:ξl为松弛变量,是对样本xl错分程度的度量参数;C为惩罚因子,代表优化过程对分类误差的关注程度。
式(4)为典型的二次规划问题,引入Lagrange乘子α,将该约束最优化问题转换为相应的对偶问题:
maxα∑nl=1αl-12∑nl=1∑nq=1αlαqylyq(xl·xq)
s.t.{∑nl=1αlyl=0,l=1,2,......,n
0≤αl≤Ctl,l=1,2,......,n
(5)
假设优化问题的最优解α*=(α*1,......,α*n)T,则最优分类函数表示为
f(x)=w*·x+b*
(6)
式中:w*表示最优权值向量;b*表示最优偏置,计算公式分别为
{w*=∑α*lylxl
b*=mean(yq-∑nl=1α*lyl(xl·xq))
l=1,......,n
q=1,......,n且q∈{q|0<α*q≤Ctq}
(7)
根据式(6)与式(7)获取样本x的最优分类函数值后,样本x的类别决策规则为
F(x)={ 1,f(x)>0
-1,f(x)<0
(8)
基于上述原理构建模糊支持向量机二分类模型,以磨粒的特征参数提取结果为输入向量,即可获取磨粒分类的最优决策函数值,实现类别的自动判断。隶属度函数的确定是构建模糊支持向量机分类器的关键环节,合理地选择隶属度函数可以最大程度地提取样本包含的信息,让模糊支持向量机的特有性能获得充分表现。反之,隶属度函数如果不符合样本的实际情况,往往会混淆不同数据点对分类结果的实际贡献程度,在分类过程中引入新的误差。文献[16-18]提出了几类隶属度函数的确定方法。就目前而言,模糊隶属度函数的形式并未有统一标准,隶属度函数的优劣应结合样本数据点的测试情况来具体判断。
2 分层多类别FSVM模型的构造
2.1 分层多类别FSVM分类器的设计
考虑6类磨粒的形貌特殊性,球状磨粒和切削磨粒与其他4类磨粒在形状特征上有明显的差异性,因此在构造球状磨粒和切削磨粒分类器时可以不考虑表面纹理特征参数,而仅以形状尺寸特征参数及边缘细节特征参数为主,构成分类器的输入向量。对于严重滑动磨粒、滚滑复合磨粒、疲劳片状磨粒及疲劳块状磨粒,这4类磨粒的形状特征参数与球状磨粒、切削磨粒之间有明显的区分点,但彼此之间的分布较为接近,主要在表面纹理特征参数上表现出一定的差异性,想要实现这4类磨粒的准确分割,需要以18维特征参数作为输入向量,完成各个二分类器的训练。
为了最大程度地简化分类器结构、缩短训练时间、提高分类速度与精度,文中结合DT法和o-a-r法,提出了一种更适合磨粒自动识别的分层多类别FSVM分类器的构造方法,将这种构造方法下的模型记为DT/oar-FSVM模型。记球状磨粒为类别1,切削磨粒为类别2,严重滑动磨粒为类别3,滚滑复合磨粒为类别4,疲劳层状磨粒为类别5,疲劳剥块磨粒为类别6,该模型的分解策略和组合策略描述如下:
分解策略:首先将类别1作为正类样本,其余所有类别作为负类样本,选择形状尺寸特征参数和边缘细节特征参数组成7维输入向量,训练球状磨粒分类器FSVM1;其次将类别2作为正类样本,除类别1以外的4类磨粒为负类样本,同样以形状尺寸特征参数和边缘细节特征参数为输入向量,训练切削磨粒分类器FSVM2;对于其他4类磨粒,则结合表面纹理参数形成18维输入向量,以待识别磨粒为正类样本,其余三类为负类样本,依次训练分类器FSVM3、FSVM4、FSVM5、FSVM6。这种分解策略下共需要训练6个二分类器,但训练样本的数量相较于o-a-r法明显减少,训练速度快,同时,该方法避免了二叉树结构的选型问题,使得累积误差可控。
组合策略:基于训练好的6个二分类器,结合DT法和o-a-r法完成三层多类别FSVM分类器的构造。选择FSVM1作为分类器的根节点,其组合模型如图3所示。

图3 DT/oar-FSVM模型的组合策略
2.2 测试样本的识别过程
假设m个待识别磨粒的特征参数集构成18维输入向量Xi,其中i为磨粒的编号,i=1,......m。在识别过程中,首先选择Xi的前7维特征参数构成新的输入向量xi,进入分类器FSVM1,利用决策函数f1(x)确定属于类别1的样本,不属于类别1的样本继续进入FSVM2,判断其是否属于类别2。对于不属于类别1和类别2的样本,再基于18维特征参数集重新构成输入向量xj,同时进入FSVM3、FSVM4、FSVM5、FSVM6四个分类器,将决策函数f(x)取最大值时的二分类器作为识别结果。图4所示为基于DT/oar-FSVM模型的磨粒识别过程。

图4 基于DT/oar-FSVM模型的磨粒识别过程
2.3 DT/oar-FSVM识别模型的参数优化
在FSVM模型的训练过程中,参数的选择是影响分类器性能的重要因素,文中基于粒子群优化算法(Particle Swarm Optimization,PSO)完成DT/oar-FSVM模型的参数优化工作,该算法在SVM、LSSVM模型中已经表现出较优的性能[19-20]。参考文献[6],以磨粒识别率为适应度函数,选择能对惯性因子实现动态调整的改进PSO算法优化模型参数,以迭代中止时识别率最高的解变量为优化结果,获取分类模型的最佳参数,实现参数自适应的PSO-DT/oar-FSVM模型。
3 工程实例分析及对比研究
3.1 样本获取与试验设计
以某台正常施工的旋挖钻机为监测对象,设备运行5 000 h左右时分别在其液压回路和润滑点取样,利用滤膜谱片技术完成油液中磨损颗粒的提取,获取试验样本。图5所示为油样中典型磨粒的图像。

图5 旋挖钻机油液中的典型磨粒
选取6类磨粒各50个,共300个磨损颗粒构成样本集data,data={data1,data2,data3,data4,data5,data6}。磨粒识别工作的各个环节均在MatLab平台上完成。通过交叉验证来测试PSO-DT/oar-FSVM模型的性能,并通过对比试验分析PSO-DT/oar-FSVM模型在磨粒识别中的实用性,具体试验步骤如下:
(1)完成磨粒图像的分割及特征参数的提取工作,获取18维特征参数体系,形成分类器的输入样本集。
(2)在各类磨粒中分别随机选择40个作为训练样本,10个作为测试样本,组合成训练样本集与测试样本集,训练PSO-DT/oar-FSVM识别模型,模糊隶属度函数参考文献[16]。PSO算法的基本参数选择如下:粒子总数为40,最大循环迭代次数N为100,学习因子均为2,惯性因子的最大值和最小值分别为0.9和0.4。
(3)为了评估PSO-DT/oar-FSVM模型对测试数据集的泛化能力,分析训练样本及测试样本的选择情况对模型性能的影响,对模型的性能进行交叉验证评估,对比测试样本集的识别率。交叉验证试验流程如下:
①将各类磨粒的50个样本随机均分成5份,分别形成5个相斥的子集。记为datai={datai1,datai2,datai3,datai4,datai5},i=1,2,3,4,5,6。
②轮流在data1、data2、data3、data4、data5、data6中选择1份作为测试样本集,其他的4份作为训练样本集,组合成240个数据点的训练样本集与60个数据点的测试样本集,得到5个分类模型。测试样本集的组成如下所示:
testdata1= {data11,data21,data31,data41,data51,data61}
testdata2= {data12,data22,data32,data42,data52,data62}
testdata3= {data13,data23,data33,data43,data53,data63}
testdata4= {data14,data24,data34,data44,data54,data64}
testdata5= {data15,data25,data35,data45,data55,data65}
③重复验证模型5次。获取当前样本集下PSO-DT/oar-FSVM模型对训练样本及测试样本的识别率。
(4)为了测试多类别分类器的构造方法对分类结果的影响,在同等条件下分别基于o-a-r法、DT法构造多类别分类器,二叉树结构选择为分类器性能最佳时的最优结构,依次建立PSO-oar-FSVM模型与PSO-DT-FSVM模型,基于步骤(3)中的样本集完成训练样本和测试样本的分类测试。
(5)为了测试PSO-DT/oar-FSVM模型是否优于其它类型的支持向量机分类模型,同时测试隶属度函数的选择是否正确,在相同的多类别构造方法和参数优化算法下对步骤(3)中的样本集利用SVM和LSSVM模型进行分类测试,分别建立PSO-DT/oar-LSSVM模型与PSO-DT/oar-SVM模型,对比样本的识别结果。
3.2 PSO-DT/oar-FSVM模型的测试结果
基于磨粒的特征参数集训练分类器模型。在训练过程中,利用PSO算法优化模型的惩罚因子C值,C的取值范围选择为[10,1000]。分类结果表明:在当前样本集下,PSO-DT/oar-FSVM模型对训练样本的识别率为90.42%,对测试样本的识别率为90%。表2所示为模型的主要参数及对样本集的识别率。

表2 PSO-DT/oar-FSVM模型的参数优化结果及识别率
3.3 模型的交叉验证
模型的交叉验证结果如图6所示。结果表明,在不同的训练样本集下,PSO-DT/oar-FSVM模型对测试样本集的识别率均不低于85%,模型的性能较为稳健。

图6 PSO-DT/oar-FSVM模型的交叉验证
3.4 对比分析3.4.1 不同多类别分类方法下的识别率对比
从模型的复杂程度、分类效率以及分类精度等方面对不同构造形式下的多类别分类器的性能进行对比分析,图7为分类器的识别率对比图。结果表明:PSO-oar-FSVM模型识别率最低、误差最大,该模型需要构建6个二分类器,每个二分类器的训练样本数量均为240个,模型训练速度慢;PSO-DT-FSVM模型与PSO-DT/oar-FSVM模型相对稳定,DT法只需要构造5个二分类器,且训练样本数量逐层减少,依次为240个、200个、160个、120个、80个,分类效率显著提高,但该分类器在测试样本上表现不佳,推广性能有待提高;而文中提出的DT/oar分层构造多类别FSVM模型的方法,测试样本的识别率明显提高,最高达90%,说明这种方法最大化平衡了模型的学习精度和学习能力,使模型的泛化性能达到最佳。就磨粒自动识别而言,PSO-DT/oar-FSVM模型表现出一定的优越性。

图7 不同多类别分类方法下模型的识别率对比图
3.4.2 不同支持向量机模型的识别率对比
在相同的多类别分类方法下,FSVM模型相较于同等参数优化条件下的LSSVM模型和SVM模型也表现出一定的优势,表3为模型交叉验证时随机生成的样本集在不同形式支持向量机上的识别率平均值。从测试结果可以看出,在样本集模糊化处理后,无论是对训练样本的分类精度,还是对未知样本的识别能力,PSO-DT/oar-FSVM模型都表现出较优的性能,说明FSVM模型在磨粒自动识别工作中有较强的适用性,隶属度函数的引入对磨粒的识别率提高起到正相关作用。
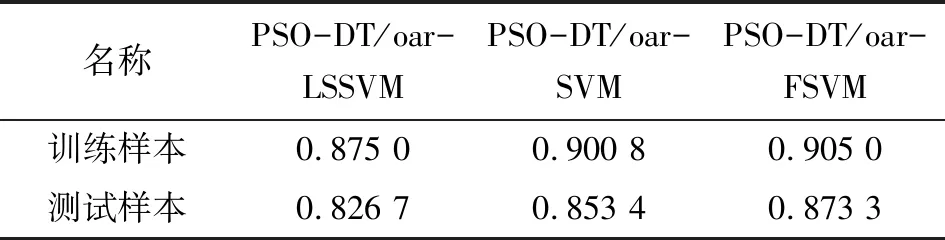
表3 三类SVM模型的识别率对比
3.5 讨论
文中提出的PSO-DT/oar-FSVM模型虽然在磨粒识别中表现出了较好的分类效果,但其准确率也不是100%,表4明确地给出了识别率最高时60个测试样本的具体误分情况。可以看出,滚滑复合磨粒的识别率最低,疲劳片状和剥块磨粒也出现误分的现象。分析磨粒误分的原因,滚滑复合磨粒的形成受多种磨损机制共同影响,疲劳磨损和黏着磨损下都有可能出现滚滑复合磨粒,使得该类磨粒的形貌呈现多样性,容易将其识别为单一磨损机制下的严重滑动磨粒或疲劳磨粒。对于疲劳片状磨粒和疲劳剥块磨粒而言,厚度信息是区分和识别这两类磨粒的重要信息,而灰度图像往往难以明确地反映出这类特征信息,同时,图像分割的后处理环节也使片状磨粒丧失了表面孔洞等信息,从而影响了这两类磨粒的识别率。
磨粒自动识别的准确程度受磨粒获取、图像分割、特征参数提取等各个环节影响,由于每个环节都存在或多或少的误差,误差累积后最终都会体现在模型的识别性能上。为了进一步提高磨粒自动识别工作的准确程度,可以从磨粒识别工作的各个环节入手,优化磨粒识别体系,将累积误差降到最低。
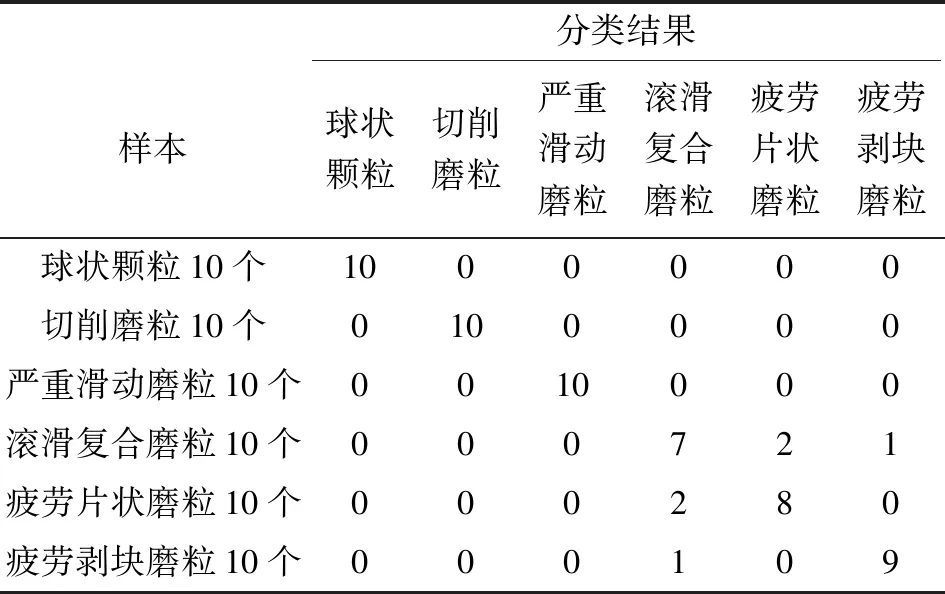
表4 PSO-DT/oar-FSVM模型下各测试样本的分类结果
4 结论
(1)通过将模糊集理论引入支持向量机,充分考虑了样本对类别归属的模糊性,最大化地利用了训练样本集的信息,对于磨粒识别而言,在样本来源非常广泛时也可以获得较高的识别精度。
(2)在各个二分类器的训练过程中,输入向量可以根据待识别正类样本的形貌特征视情选择。选择最能反映该类磨粒的典型特征参数作为训练该类磨粒分类器的输入向量,这样可以在最大化分类精度的条件下通过降低输入参数的维数来提高分类器的训练速度,减少多余参数的干扰。
(3)在磨粒的自动识别工作中,结合二叉树和一对多法构造的分层多类别分类器表现出了单一组合法难以比及的效果,这种构造方法最大程度地简化了分类器的结构,降低了累计误差,显著提高了分类效率和泛化能力。
(4)采用PSO-DT/oar-FSVM模型对旋挖钻机齿轮油和液压油中的磨粒进行识别,模型对测试样本的识别准确率最高可达90%,优于同等条件下的其他支持向量机模型。该模型有较大的工程实用性。
