基于深度神经压缩的YOLO加速研究
2019-05-27陈莉君李卓
陈莉君,李卓
(西安邮电大学计算机学院,西安710100)
0 引言
从AlphaGo开始,深度学习渐渐进入业内研究者的视线。深度学习近些年大热的主要原因是由于近些年设备的计算力的增加,尤其是图形处理器(Graphics Processing Unit,GPU)对于浮点数运算的有力支持。YOLO[1]的提出了一种在目标识别领域新的方式,将检测和回归问题集合在一起,大大的增加了对于目标的检测速度。但是,YOLO的网络层数相较于传统的网络也增加很多,导致训练和推理的计算量会大大增加。尤其是嵌入式设备和移动设备,这些设备可能并不能很好地支撑层数增加之后带来的计算量增加。为了能让更多的设备和更多的人用上和享受到深度学习给他们带来的方便,对于深度神经网络推理加速需求就渐渐增多了[2-4]。
国内外现有的研究结果中有一部分是利用并行化神经网络进行加速,这样可以将一个深度神经网络并行化拆分,分布式运行这个模型。另外一部分是使用软件加速深度神经网络的例子。例如:EIE(Efficient Inference Engine)[5]这个软件提出了一个推理引擎,对这个压缩的网络模型进行推理,并利用权重共享进行加速稀疏矩阵的相乘过程。DeepX[6]:用于移动设备上低功耗深度学习推断的软件加速器。Eyeriss[7]:用于深度卷积神经网络的节能可重构加速器。针对深度神经网络模型的压缩,Kim等人在2015年提出了一种压缩CNN模型的方法。Soulie等人在2016年提出一种在模型训练阶段进行压缩的方法。首先在全连接层损失函数上增加额外的归一项,使得权重趋向于二值,然后对于输出层进行量化。
现有的加速方案都是基于大型GPU设备的。对于嵌入式和移动设备,加速的效果并不是很明显。嵌入式和移动设备的硬件限制仍然是影响神经网络发展的一个重要的因素。
针对上述问题,本文中主要对YOLO神经网络进行压缩,测试深度神经压缩[8]中剪枝方式对于卷积神经网络的模型减少和推理加速效果。
1 深度神经压缩
深度神经网络中通常会有过多的参数,存在大量的计算冗余的情况。这种情况将浪费设备的内存和计算资源,加大了嵌入式设备、低功耗设备和移动设备的消耗[9-11]。
深度神经压缩(Deep Compression)存在四种方式,参数共享方法、网络删减方法、暗知识方法和矩阵分解方法。
参数共享的主要思路是多个参数共享一个值。通常实现的方法可以有很多选择。例如Vanhoucke和Hwang等人使用定点方法江都参数精度,从而是值相近的参数共享一个值。Chen等人提出一种基于哈希算法的方法,将参数映射到相应的哈希表上,实现参数共享。Gong等人使用K-means聚类方法将钱全部的参数进行聚类,每簇参数共享参数的中心值。
网络删减用来降低网络复杂度,防止过拟合。Han等人针对模型的训练效果,然后在基于参数共享和哈夫曼编码进一步对网络压缩。
在基于暗知识的方法中,Sau等人基于老师-学生学习框架对网络进行压缩。
基于矩阵分解理论,Sainath、Denil等人采用低秩分解对神经网络不同曾的参数进行压缩。Denton等人在神经网络使用矩阵分解的方法加速了卷积层的计算过程,减少了全连接层的网络参数,对于神经网络进行压缩。
深度神经压缩主要表现在三个部分:存储、训练复杂度和推理复杂度。以上介绍的方法中,都有各自的优点和不足。参数共享方法、网络删减方法、暗知识方法和矩阵分解方法都可以有效的降低模型的存储复杂度,但是在训练复杂度和推理复杂度上没有重要影响。暗知识方法虽然在三个方面都有比较好的表现,但是在准确率方面,相较于其他三种方法,会有较大的变化。
2 YOLO
YOLO属于CNN,由卷积层、池化层和全连接层组成。与CNN不同的是,YOLO的输出层不再是max函数,而是张量(Tensor)。
YOLO的训练和推理过程和其他CNN存在不同之处[12],例如 R-CNN、Fast R-CNN和 Faster R-CNN 三种网络。RCC、Fast R-CNN采用模块分离的方式进行推理过程。在检测目标的过程中,两种网络需要将待检测的目标区域进行预提取,再将包含目标的区域进行卷积/池化操作提取特征,最后进行检测行为。在Faster R-CNN中,使用 RPN(Region Proposal Network)代替R-CNN/Fast R-CNN中的选择搜索模块,将RPN集成到Fast R-CNN模块中,得到一个统一的检测网络。但是在模型的训练过程中,需要反复训练RPN网络和Fast R-CNN网络。上述三种网络最大的特点就是在推理的过程中,需要将待检测的目标区域进行预读取。预读取会耗费大量的磁盘(内存)空间,会对一些嵌入式设备、低功耗设备和移动设备造成压力。YOLO在设计的过程中就针对的进行了改进。
3 基于深度神经压缩的YOLO加速
原始的YOLO模型在完成训练后,模型大小达到200M,对于嵌入式设备和移动设备而言。200M的模型进行内存预读,会对设备的性能造成较大的影响,所以论文主要从深度神经压缩理论入手,对于YOLO进行修改,达到对于模型进行体积压缩,改善其在嵌入式设备和移动设备上的表现[15]。针对YOLO进行深度神经压缩,主要是以下步骤:
(1)权值修剪
(2)权值共享和量化
流程如图1所示。
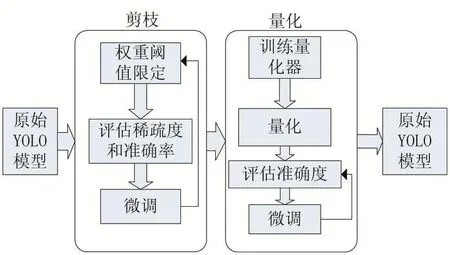
图1 压缩框架图
3. 1 权值修剪
权值修剪[16]主要目的是保存YOLO中重要的链接来达到降低存储数量和计算复杂度的目的。传统的神经网络训练过程中,在神经网络训练之前,神经网络的框架结构就已经被固定了。用户只需要进行数据的输入,就可以在迭代训练后获得需要的权重。但是这种固定框架结构的方式,导致不能在训练的过程中,随时对于神经网络的结构进行优化。因此,常规训练出的模型文件大小都不适合于部署在嵌入式设备或者移动设备上。YOLO常规训练后的模型大小达到200M,对于嵌入式设备,将模型预读进内存中,提供给推理过程使用,将会消耗设备的所有内存。所以,利用深度神经压缩的剪枝思路,对于YOLO模型进行压缩,是提高YOLO在各种设备上通用性的一个方式。剪枝过程分为四个步骤;
(1)通过训练找到权重小于阈值的神经网络链接;
(2)删除权重小于阈值的神经网络链接;
(3)重新对于神经网络进行训练;
(4)将修剪后的以 CSR(Compressed Sparse Row)方式存储。
在训练的过程中使用公式:

对权重进行计算,使一部分权重趋向于0,然后将小于阈值的链接剪枝。使用公式的目的是能够减少在训练剪枝过程中的过拟合现象,并且可以保持较高的精度。相对的,通常训练过程中的Droupout概率也需要进行调整。在深度神经网络训练的过程中,Droupout主要是用来防止训练出的模型数据有过拟合的现象。因为在上述的剪枝过程中,使用了L2正则进行过拟合的预防。所以,在重训练的过程中,按照剪枝后的神经网络数量进行对Droupout概率进行等比例的调整。初步剪枝之后将要进行对于本次链接层的一个重训练。每一次的剪枝过后的重新训练都是一个原子操作。重新训练的目的是为了神经网络模型有更好的精确度,以及更小的过拟合的可能。
剪枝之后的权重按照CSR方式进行存储,CSR方式可以减少存储元素位置index带来的额外存储开销。按CSR方式转换完成的稀疏矩阵,在存储的过程中使用按位存储的方式,存储过程中,每一个非零元素都会进行标记。如果使用3bit形式进行存储,每一个非零元素和另外一个非零元素之间的距离在标记后将会被检查。如果一个非零元素和另外一个非零元素的超过8,则这个第八位的位置将会被填充一个0,这样防止在使用按位存储的时候出现数据的溢出。
3. 2 权值共享和量化
为了进一步的压缩剪枝之后的YOLO,第二部将使用权值共享的方法[17],对于剪枝结束的权值,进行一个K-means聚类。

式(2)中,W代表权值C代表聚类。
聚类之后的结果代表着一类权值的聚类执行,这个质心的值将作为共享的权值进行存储。最后存储的结果是一个码书和一个索引表。
K-means算法中,聚类的核心是聚类中心的选择和初始化。常规的初始化方式有三种:
(1)随机初始化
(2)密度分布初始化
(3)线性初始化
由于在神经网络的训练中,权值越大,对神经网络精确度的影响越高,所以使用将权重排序后进行线性划分的线性初始化较为合适。
本层的权重完成剪枝和共享之后,将执行神经网络层与层之间的前向传播和反向传播。前向传播时需要将每个权值用其经过聚类的中心进行代替,反向传播时,计算每个聚类中权值的梯度,用来进行聚类中心的更新和迭代。
4 实验结果与分析
实验结果分析算法在经过深度神经压缩之后压缩率、准确率和执行速度。运行YOLO模型的设备为NVIDIA TX2嵌入式开发板。YOLO的训练数据集为基于VoC2007和ImageNet的常见数据集。
4. 1 压缩率
表1中展示了YOLO未压缩和已压缩之后的大小对比。

表1 YOLO压缩体积对比
由表1可以看出,经过深度神经压缩后的模型只有原模型的3%,减少了嵌入式设备和移动设备在预读模型时的内存消耗,提高了模型预读的速度。
4. 2 准确率

表2 仅剪枝YOLO模型大小和准确率
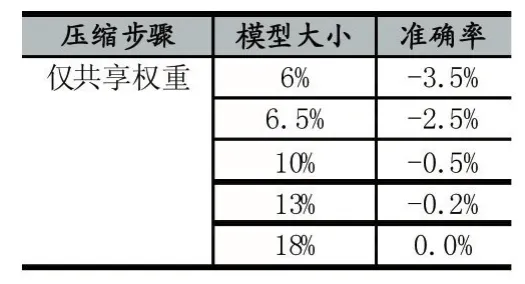
表3 仅共享权重

表4 剪枝+共享权重
从表2、3、4可以得到,准确率随着模型体积的下降而下降。仅剪枝能达到的最低压缩率为4.5%。仅共享权重最低压缩率可以达到6%。剪枝和共享权重可以达到最低的压缩率3%。
4. 3 运行速度

表5 压缩YOLO在嵌入式设备上运行时间
表5可以看出压缩网络对比原始网络,在嵌入式GPU设备上可以获得5倍加速。
5 结语
本方案基于深度升级压缩理论,提出了YOLO算法的改进方案。对于YOLO算法进行剪枝、共享权重、霍夫曼编码等步骤。并且将压缩后的YOLO算法部署到NVIDIA TX2上,进行目标识别实验。实验结果表明,经过优化的YOLO可以在原体积3%的情况下稳定运行,并且准确率相较于原模型只有-2%的差距。并且在嵌入式设备上获得原模型5倍的加速效果。但是该实验只是单纯的进行L2范式的权重衡量,没有做到多情况的权重衡量。并且K-means只选择了线性初始化的情况。后期实验可以进行优化,找到更好的剪枝方式和聚类方式[19-20]。
