基于深度卷积网络的糖尿病性视网膜病变分类
2019-05-27杜霞
杜霞
(四川大学计算机学院,成都 610065)
0 引言
糖尿病性视网膜病变(Diabetic Retinopathy,DR)是一种严重的糖尿病眼底微血管并发症,DR在导致20-74岁成人失明的因素中排列首位[1]。据WHO发布的2016年《全球糖尿病报告》数据,全球截止2014年成人中糖尿病患者已经达到4.22亿,患病率显著上升。在已有15年以上糖尿病史的患者中,80%以上患有DR。DR的病情发展是渐进变化的,及时检查和治疗是预防失明的有效手段。在医学上,根据视网膜眼底图像的特征对DR病情阶段进行了准确的分类,也是医生临床诊断的重要标准。在实际诊断中,主要存在的问题包括:分类准确性极度依赖医生的临床经验;眼底照相的质量受到操作技术、设备、光线等影响较大;图像中存在的细微特征依靠肉眼难以辨别等[2]。
基于DR在人工诊断存在的困难,大量研究尝试用计算机技术进行DR的自动诊断,研究方法主要分为传统机器学习和深度神经网络算法。在传统机器学习方向,Roychowdhury[3]等人综合利用高斯混合模型、k紧邻分类器、支持向量机以及AdaBoost四种算法来训练分类器,最终在小型数据集的二分类问题上得到了较好的效果。Jelinek[4]等人采用Gabor小波变换,对27张血管被荧光标记的视网膜图像进行分割,并根据面积、边界等五个传统特征进行病变分类,在多特征判别下,对是否存在DR增殖性病变分类任务上取得了90%的AUC值。Nayak[5]等人通过提取渗出物面积、血管面积和纹理特征,使用这些特征训练神经网络,将彩色眼底图像分为非DR、增值性DR和非增值性DR三类,并在140张图片的小型数据集上取得了93%的准确率。传统机器学习在小数据集上可以取得良好的效果,但面对大量数据时则难以突破,研究者开始尝试深度神经网络方法。Gulshan[6]等人采用卷积神经网络方法,在拥有128175张眼底图像的大规模数据集上训练,最终在DR的三分类任务上获得了最高97.5%的灵敏度。Ghosh[7]等人在Kaggle提供的超过30000张图像的数据集上,分别在二分类和五分类问题上获得了95%和85%的准确率。Li等人[8]采用迁移学习的方法,对预训练好的卷积网络进行微调,在1000张左右的小数据集上实现了92.01%的准确率,证明了迁移学习对提升神经网络在小数据上的表现有所帮助。Li等人[9]基于CNN网络,在超过70000张图片的中国人眼底数据集上达到了95.5%的诊断率。
本文通过深度卷积网络模型,实现了对DR眼底彩照的自动分类。通过数据清洗、标定等完成了DR_data私有数据集的建立;并采用翻转、旋转、平移等方法进行数据增广,克服了数据量不足以及数据类别分布不均衡问题。本文采用了迁移学习的方法和Inception-V4网络模型,在DR的四分类任务上获得了较好的准确率和鲁棒性。
1 实验方法
1. 1 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNNs)是一种常用的深度神经网络模型,在图像处理问题上具有突出表现。最早于1962年,Hubel和Wiesel等人受到猫的启发,提出了感受野的概念[10];由Yann LeCun等人于1989年正式提出了卷积神经网络模型[11];2012年Hinton等人[12]提出加入权重衰减的CNN模型,将ImageNet[13]数据集上的图像分类错误率大幅降低至16%,后续许多基于该架构的网络模型取得了惊人的成果[14-16]。
CNN主要由输入层、卷积层、池化层、全连接层以及输出层等五种结构组成,其中卷积层(convolutional layer)和池化层(pooling layer)是CNN中非常关键的结构。卷积层的每个节点与前一层网络的部分区域相连,通过卷积操作提取输入层的特征,深层的卷积网络可以提取抽象程度更高的特征[17]。其中池化层的操作与卷积类似,但并不计算神经元的加权和,只影响一个深度上的神经元。常用的池化操作有最大池化和平均池化两种,池化层可以快速地减少矩阵的大小,加快计算速度并防止过拟合。卷积运算中的三个关键思想,包括稀疏连接、权值共享和等值变化,对减少网络参数、提升计算效率起到了重要作用。
1. 2 Inception模型
传统CNN在发展过程中,由于不断加深网络深度和宽度,导致网络参数增加,更容易出现过拟合现象。Szegedy等人[18]于2014年提出了GoogleNet网络结构,该网络在ImageNet竞赛上取得了非常好的效果。该网络中设计的Inception-V1模块包含了多维度的卷积结构叠加和最大池化操作来减少参数数目,具有不同感受野的卷积可以实现不同级别的特征提取。在Inception-V2模块中,增加了对中间特征的归一化操作,可以使用较大的学习率以加快收敛速度,同时也具有正则化效应。Inception-V3中引入了“因子化”(Factorization)的概念,将一些尺寸较大的卷积分解为更小的卷积,在保证网络效果等价的前提下减少了参数量。Inception-V4网络主要对前几个版本做了规范和简化并将网络迁移到TensorFlow平台执行,可以更好地利用计算资源。在残差网络(ResNet)[19]的基础上,Szegedy等人提出的Inception与ResNet集成的网络结构,在ILSVRC 2012上达到了3.08%的top5错误率。
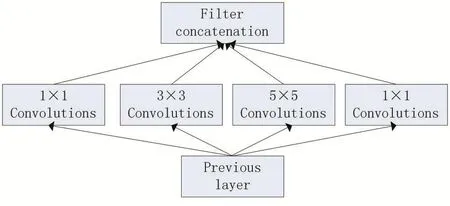
图1 Inception模块
通常CNN模型例如LeNet、AlexNet、VGG等通过使用卷积、池化、标准化和激活函数的叠加来增加网络深度以期达到更好的效果。Inception-V4更是增加了残差连接这一设计理念,Christian[20]发现利用残差连接设计更深更宽的Inception网络可以显著提高网络表现。因此Inecption-V4有着更多Inception模块其中包括4个Inception-A和7个Inception-B和3个Inception C模块。本文在实验中使用了Inception-V4网络结构。
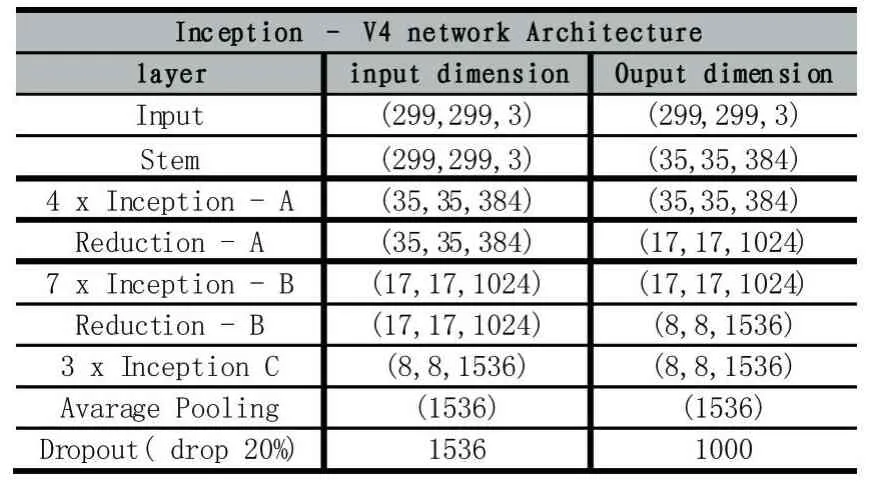
表1 Inception-V4网络模型
1. 3 迁移学习
对于医学图像数据集来说,获取数据的成本十分高昂,因此缺乏大量训练数据是一个主要问题。神经网络参数较多,如果训练样本不足,模型容易出现过拟合现象,所以数据增强和迁移学习方法[21]是必要的。类似于人脑的神经系统,卷积神经网络对模型的学习是一种层级结构,从图形的边缘、角点到局部特征,再到全局特征,预训练模型在提取图像深度特征的过程被广泛使用。深度神经网络通常具有大量参数使得训练一个深度网络需要大量时间和计算资源,迁移学习方法可以使能我们把在大数据的模型(源领域)迁移到小数据(目标域)上仅仅做参数的调优而不用从头训练。本文使用基于ImageNet的预训练模型,其中包含120万副图像和1000种分类类别,最后在DR_data数据集调优以达到减少训练时间和对样本量的需求。
2 实验设计
2. 1 数据集
本文采用的DR_data数据集为私有数据集,与四川省人民医院合作建立,由该院眼科、内分泌科和体检中心采集的部分眼底检查彩照组成。一位患者单次眼底检查会分别对左眼和右眼进行拍照,诊断时左右眼的结果相互独立,因此将一位患者的检查结果整理为左眼和右眼两例数据,每例数据对应一位患者的一只眼睛,包含若干张眼底彩照。DR_data数据集共有1333例数据,2409张眼底彩照。
数据收集完成后,由三名专业眼科医师(包括一位眼科主任医师)进行病变程度人工标定。根据DR在病变发展阶段的特征,国际上主要将DR分为非增生性(PDR)和增生性(NPDR)两期[23]。在数据标记阶段中,参与医生根据眼底彩照所表现的病变特征和临床对应的治疗措施,将病变划分为四个类别:正常、轻度(非增生性)、中度(非增生性到增生性之间)、重度(增生性)。
标定后的数据集中包含正常56例、轻度367例、中度700例、重度210例。为了在网络训练时进行交叉验证,将数据集随机划分为两部分:80%的训练集和20%的测试集。
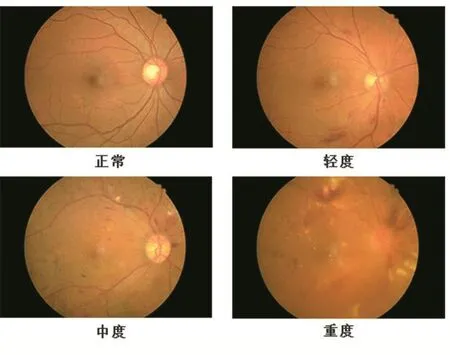
图2 数据集示例
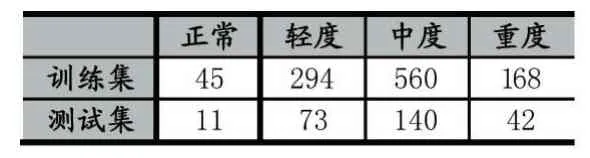
表2 数据集分布
2. 2 预处理方法
数据集原始图像的分辨率为2464×1632,较高的分辨率可以保留图像更多细节特征,但也会增加模型参数量、需要大量计算资源。通过已有研究和多次尝试结果比较,本文将输入图像的尺寸减小到512×512分辨率,可以在模型效率与分类准确率之间取得较好的平衡。
样本间差异导致的数据分布的偏移经过多层卷积网络的叠加,会影响梯度变化的方向。本文使用了归一化方法将不同数据的亮度、颜色等数值都归一化到同一个范围,该操作一定程度消除了数据差异带来的噪声。
相较于其他图像分类问题的数据集规模,本文数据集规模较小,并且各类别的数据量不平衡。因此,为了让模型有更好的泛化能力以及避免学习结果偏向某个类别,本文采用了一些数据增强的方法如:随机翻转、旋转 45°/90°/180°等角度、从图像上下左右四个方向剪裁等。
2. 3 参数设置
本文模型使用随机梯度下降优化器(SGD),SGD算法可以收敛到局部最小值,如果学习速率小则学习速度过慢,学习速率过大又容易造成模型震荡。为了抑制误差更新中存在震荡过大的问题,本文使用了RMSProp算法,该算法计算了微分平方加权函数,有利于消除震荡,使网络收敛速度变快,本文将模型的学习速率设为1e-3,梯度衰减设为1e-4。
由于数据样本偏少,本文采用了k-折叠交叉验证来调整超参数并验证模型泛化能力。交叉验证的基本思想:是把原始数据分为k组,其中(k-1)组作为训练集,1组作为验证集。首先对模型进行训练,然后在验证集中验证误差,最后选择误差最小的模型。
2. 4 评价指标
混淆矩阵是对分类模型性能评价的重要工具,通过样本真实类别与模型预测类别的组合,衍生出真阳性、假阳性、准确率、精确率等各种评价指标,可以更为准确地度量不同任务场景下的分类模型。
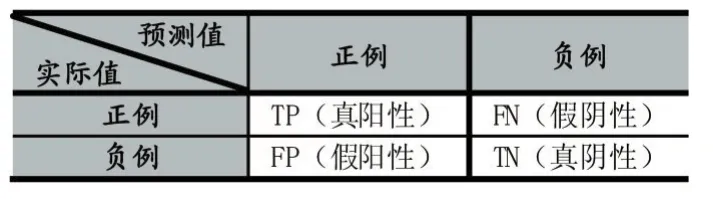
表3 混淆矩阵
准确率(Accuracy)是最为直观的评价指标,即正确分类的样本占所有样本的比例。但在正负样本不平衡的情况下,准确率无法很好地观察到负类的预测情况。
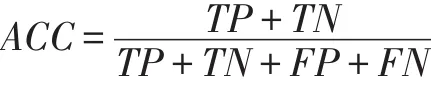
召回率(Recall)是预测正确的正例占所有样本的比例,表示了模型对正例的预测能力。该指标在医学问题中非常重要,因为在临床诊断中必须极力降低漏诊率,本文在实验中引入了召回率来评价模型。
受试者工作特征曲线(ROC)以假阳率为横坐标、真阳率为纵坐标,反映每个位置对同一型号刺激的感受。在实际问题中,常常存在样本不均衡的情况,但ROC曲线不因样本分布而变化,是评价模型泛化能力的有效指标。
3 实验结果
本实验基于PyTorch深度学习框架,在GPU平台上运行,处理器为Intel Xeon E5-2620@2.4GHz,GPU为NVIDIA Tesla K40m,运行内存64GB。
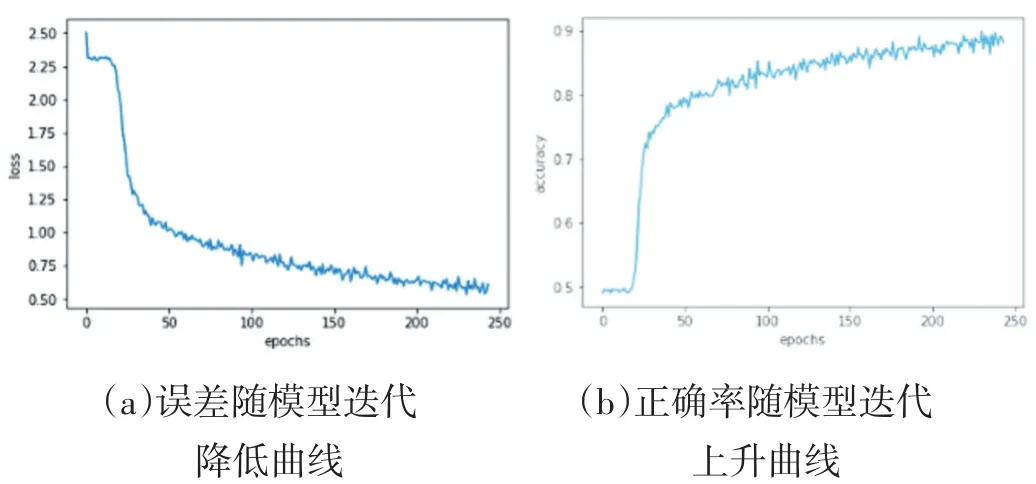
图3 训练集结果
图3(a)为实验在测试集上的准确率,可以看到随着训练迭代次数逐渐升高,同时模型误差逐渐降低,在25次左右迭代的时候模型很好的学习到了误差下降的方向。在迭代250次之后模型逐渐收敛,最终模型的准确率达到88.25%。
模型对测试集进行预测,预测结果在图4中所示。

图4 测试集结果
在样本容量足够的前提下ROC曲线可以直观的评价分类器的好坏,视网膜病变检测是个4分类问题,针对每一个分类将它视为2分类(是或否),以假阳率为横轴、真阳率为纵轴,并画出ROC曲线。
除了ROC曲线外,本文还从精确率、召回率和F1-分数等方面,针对每一类的分类结果来评价模型效果。从表4看到,模型的精确率和召回率较高,模型预测结果对临床诊断有一定参考价值。

表4 各分类评价

图5 各类别ROC曲线
4 结语
本文基于深度卷积网络,实现了对糖尿病患者眼底彩照的病变程度自动分类。通过归一化操作克服了数据质量差异较大的问题,利用数据增强的方法解决了原始数据集规模较小的问题,通过加载预训练模型克服了数据量较少造成的过拟合问题,同时缩短了训练时间。在训练过程中较为精确地提取了图像的深层病变特征,在四分类任务上获得了较高的准确率,该分类模型有助于医生在临床诊断中提高效率和准确率。在实验的网络结构上,我们仅采用了Inception-V4结构用于训练,在未来的工作中考虑融合多个网络模型,尝试进一步提高分类准确率。
