基于深度学习的行人检测技术研究进展
2019-05-23黄同愿向国徽杨雪姣
黄同愿,向国徽,杨雪姣
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
目标检测是计算机视觉领域的重要研究内容之一,它从给定图像中检测出特定类物体实例(例如“汽车”“飞机”等)[1],近年来引起了学术界和工业界的广泛关注。行人检测作为目标检测的典型任务,其发展历程与目标检测一致,在大数据驱动发展的今天,机遇与挑战并存[2-58]。行人检测的目标是在一张给定图片或视频帧中,精确定位出每一个在检测范围内的行人。如果存在行人,给出该行人的空间范围信息。行人检测可以与行人跟踪相结合应用于辅助驾驶系统的视觉场景感知,并进一步对行人目标进行测距和测速,计算碰撞时间TTC(Time to Collsion)。此外,行人检测结合行人重识别后能广泛应用于智能视频监控和智能安保等领域。
作为无人驾驶的基础任务,无论是从数据集的发布、公开挑战赛的举办,还是从各大顶会(CVPRICCVECCVIJCV等)和学术期刊的关键词分布来看,行人检测无疑都是重头戏。目前,对行人检测领域的综述研究较少。例如,文献[2,12-13]主要调研行人检测的传统算法,未涉及目前焦点的深度学习技术;文献[4,11]等因时间节点关系,并未谈及近一两年来的研究进展。在近两年以深度学习技术为主导的目标检测领域快速发展背景下,行人检测未再被作为单独的方向综合研究。然而,行人作为现实世界中形态和姿态最变化多端的特殊目标,是目标检测中最具挑战的检测任务。本文主要针对行人检测在近两年与深度学习技术结合的研究进展进行综合讨论,为该领域前沿综合研究提供参考和依据。
1 背景
社交媒体网络和移动/可穿戴设备的普及导致了对分析可视化数据的需求越来越大。然而,移动/可穿戴设备极大地限制了计算能力、存储空间,因此高效的对象检测器至关重要。受成像条件、个体差异和外界干扰以及实验误差等因素的影响,行人检测的速度和精度很难做到双高,只能达到某种平衡。行人检测面对的主要挑战总结见图1。
图1 行人检测的挑战总结
理想的行人检测模型应满足高精度和高效率要求。其中,精度包括定位精度和分类精度,效率可分为时间效率、存储效率以及内存效率。一般情况下,行人检测的研究可以分为学术类研究和工程研究,不同的团体可能的侧重点也不同。学术研究多注重检测器的性能(即精度),而工程研究则把效率放在第一位,但不能牺牲太多的精度。
一般而言,视觉图像中的行人会受到来自外界(如光照、天气、环境等)和行人本身(姿态、大小、遮挡等)的影响,行人之间也会造成严重的干扰。例如,密集行人的区分和同一行人的整合(受遮挡物的影响,行人整体被切割成不相连通的块)。在现实生活中,海报、模具等具有高干扰性的对象区分极具挑战性,加之噪声等的干扰则进一步提升了区分难度。为了应对这些复合式的叠加干扰,行人检测的模型必须具有高度的鲁棒性和泛化能力,这种能力通常来自海量的可训练参数,这就对行人检测的效率提出了极高的要求。
2 相关研究
在过去的几十年中,对于行人检测的相关研究成果较多,本文主要关注基于计算机视觉的算法和模型,一些典型的研究总结见表1。

表1 行人检测相关经典文章列表
早期的研究主要基于模板匹配和身体部件的思想[48]。在20世纪90年代以前,通用检测器主要使用对象的几何信息并设计先验模型;之后,机器学习的浪潮使得基于表现特征的几何分类器成为研究的热点,例如神经网络(neural network,NN)、支持向量机(support vector machine,SVM)和AdaBoost。1999年,具有尺度不变性的SIFT[49]特征的提出开启了特征描述器的研究。特征检测也从全局特征向局部特征演化,例如形状上下文(shape context)[50]、方向梯度直方图 (histogram of gradients,HOG)[51]、局部二值模式(local binary patterns,LBP)[52]等,使得分类器能更好地应对行人这类尺度和形态多样的对象。
特征表达的相关研究极大地促进了行人检测的发展,几何特征[14-16]、形状特征[19-21]、动作特征[22-23]以及多种特征的融合[24]是研究的主流。在特征提取发展的同时,学习框架的研究也有不少成果。Tuzel 等[25]利用协方差矩阵计算局部特征作为对象描述符, Boost框架被修改后可用于黎曼流形,从而提高了性能。Maji等[51]提出了一种与直方图交叉内核近似的方法SVMs,允许大幅度加速,从而使非线性SVM能够用于基于滑动窗口的检测。
2008年,Felzenszwalb 等[52]描述了一种差异训练、多尺度、可变形的目标检测模型DPM。该模型在VOC挑战赛中取得了2006年的最佳性能,并在2007年的20个项目中有10个超越最佳性能,Pedro Felzenszwalb也因此被VOC授予“终身成就奖”。DPM可以看做是HOG(histogrrams of oriented gradients)的扩展,它先计算梯度方向直方图,然后用SVM训练得到物体的梯度模型。
多年来,手工提取的特征一直制约着行人检测的发展。直到2012年,Krizhevsky等[18]应用深度卷积神经网络(deep convolutional neural networks,DCNN)模型取得了ILSVRC的冠军,从此开启了基于深度学习的行人检测新篇章。
深度卷积神经网络作为一种能自动直接从原始数据中提取抽象特征的特征提取器[3],在计算机视觉任务中取得了不少成果[4-10]。这类体系结构能够应用在通用目标分类、通用目标检测、特征匹配、立体匹配、场景识别、姿态估计、动作识别[11]等多项任务中,行人检测也受益于DNN技术的发展。以DNN为基础的深度学习技术擅长发现高维数据中错综复杂的结构,不需要太多的专业领域知识,从而降低了研究者的入门门槛。
随着检测技术的不断进步和应用场景的不断拓展,行人检测结果的表示方式也呈现多样化,如基于更精准像素级分类的实例分割形式。实例分割与语义分割的区别在于前者要区分类内差异,即同种类别的不同个体用不同的掩码标识,而后者不需要区分,具体示例如图2所示。可以看出:行人实例分割不仅可以识别出每个行人,还能区分不同的个体,其相对于行人检测的边界框表示结果来说更精细。基于边界框行人检测可以包含非行人(背景、其他个体等)部分,而行人实例分割则完全贴合行人真实边缘。

图2 行人识别、行人检测、行人语义分割和行人实例分割示例图
Benenson 等[52]提出了一种新的行人检测器,速度和质量都优于最先进的检测器,能有效处理不同的尺度,提高了检测速度。Sermanet 等[35]采用多级特征、跨层连接等方法,将全局形状信息与局部特征信息融合在一起,并应用基于卷积稀疏编码的无监督方法在每个阶段对过滤器进行预训练。P.Doll’ar等[54]通过对自然图像的统计分析,证明了跨尺度预测的可靠性。R-CNN系列、SSD、Mask-RCNN以及YOLO系列[55-63]等通用对象检测器的研究也促使了行人检测的发展。Zhang等在文献[44]中通过改进Faster R-CNN,并在共享的高分辨率的卷积特征图上使用改进的随机森林算法验证了通用目标检测器应用于行人检测的可能性。目前,在著名行人检测数据集Caltech上性能最好的是Wang等[70]应用边界框回归损失的方法,其在FPPI值为9时可达4.0%的对数平均误检率。在更加复杂的数据集KITTI上,行人Easy、Moderate和Hard的最好结果(AP)分别是87.81% 、78.29% 和74.46%。
3 数据集介绍
在深度学习的背景下,完善而标准的数据集在行人检测的研究中至关重要。数据集不仅可以用来训练模型的参数,评价模型的优劣,通常还作为一种挑战赛的形式促进领域研究的发展。本文调查和统计的能用于行人检测的常见数据集见表2。
数据集分为两类:第一类是诸如Caltech这种专用于行人检测的数据集,其他非行人类不进行标注;另一类是类似COCO和BDD这样的数据集,标注文件中不仅对行人进行标注,其他类如车、飞机等也包括在内。两类数据集的共同点是:单类行人的标注样本较多,可以将行人样本提取出来用于行人检测的训练。
在此,特别说明EuroCity数据集。该数据集拍摄于欧洲的31个城市,标注类别为行人,同时对自行车、手推车、摩托车、滑板车、三轮车和轮椅上的行人进行了区别标注,在47 300张图像中手动标记了238 200个行人实例,平均每张图片包含5.04个行人。特别地,区分了海报、广告和商店橱窗的模特等,额外信息如镜头光晕、运动模糊、雨滴或在相机前面的雨刷等也作为图片标注。更多详细的信息参考文献[64]。

表2 能用于行人检测的常见数据集
4 评价标准
评价检测器性能的指标通常有对数平均漏检率(log average miss-rate,LAMR)、帧率(frame per second,FPS)、查准率(average precision,AP)和查全率(recall)。帧率表征模型的效率、查准率、对数平均漏检率和查全率反映模型的精度。对于行人检测而言,给定一张测试图片模型的输出为{bi,ci,pi}i。bi为检测框(bounding box,BBOX)的信息,通常由矩形框的中心点坐标(x,y)和宽、高w,h组成,也可以由矩形框的left、top、right、bottom表示。ci是类别信息,pi表示该矩形框的对象属于ci的条件概率。对于一个检测框,当它满足下列条件时,可以视为一个真正例(true positive,TP):
1) 预测的类别信息c与标签的类别相同。
2) 预测框与某个真实框之间的IOU(intersection over union)大于一定的阈值ε,
(1)
其中:bp为预测框,bg为真实框,area(bp∩bg)表示预测框与真实框相交部分的面积,area(bp∪bg)表示相并的面积。当2个框完全重叠且大小一致时,IOU值为1;当2个框无交叉部分时,IOU=0,说明位置预测完全错误,所以IOU的取值范围是0~1。阈值ε为超参数,通常设置其值为0.5。不是真正例的框,都当作假正例(false positive,FP)。假正例的个数越多说明误检率越大。类别概率p通常也和超参数β进行比较,大于阈值则认为属于该类,否则属于其他类,β的取值通常为0.5。
一般情况下可通过绘制相对每张图像误检数(false positive per image,FPPI)的漏检率(miss rate,MS) 曲线或者P-R曲线来动态评估模型性能。
(2)
(3)
其中,给定阈值c,FN(c)表示假反例(false negative,FN)的个数,TP(c)表示真正例的个数,则可以定义对数平均漏检率为:
fppi(c)≤f
(4)
9 FPPI是参考[10-2,100]区间的等间隔分布,对于每一个FPPI,统计其对应的MR。例如,常见模型在EuroCity数据集的MR-FPPI图如图3所示。
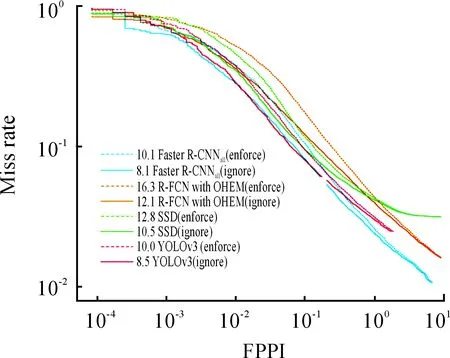
图3 常见模型EuroCity的MR-FPPI性能表现
同样地,计算AP:
(5)
其中,给定阈值c,召回率re(c)为:
(6)
查准率AP为
(7)
选取不同的re,计算其对应的AP则可得到P-R曲线。
5 子问题研究
结合之前分析的行人检测中的主要问题和挑战,对影响行人检测的子问题展开分析。例如检测框架、特征表达、损失函数、上下文信息和训练策略等。
5.1 检测框架
目前基于深度学习的检测框架可以分为两类:
1) 两阶段检测框架:包括生成候选区域和区域分类两个阶段。
2) 一阶段检测框架:分类和检测一步到位,不需要预先生成候选区域。
一般而言,一阶段的检测框架相对于两阶段的检测框架在模型检测速度上较有优势,但精度不足。典型的YOLO V3网络在COCO数据集上mAP达到57.9%的同时,速度能保持20FPS,是经典的通用对象检测框架,许多变体网络也应用在了行人检测中[42-43,65-66]。
基于行人检测框架通常由通用目标检测框架改进而来。典型的两阶段和一阶段检测框架情况见表3和表4。

表3 典型2阶段检测框架列表

表4 典型1阶段检测框架列表
5.2 特征表达
基于深度学习的检测框架通常使用VGG,AlexNet、GooleNet、ResNet50、RestNet101、DarkNet、MobileNet[18,26-31]等作为骨干网络提取特征。基于滑动窗口的策略需要对每个像素均匀处理,在多个尺度的不同宽高比上穷举搜索进一步增加搜索空间。为了解决不同尺度的问题,通常的做法是采用图像金字塔的方法,例如检测器[32]。但这种方案的测试时间和存储开销都极大。考虑到CNN提取的特征具有如下特性:
1) 低层的特征具有较小的感受野,对于小尺度的目标有更敏感的位置和细节信息,但是缺少语义信息。
2) 高层的特征感受野较大,语义信息更丰富,对光照、形变等的鲁棒性更高,但由于几何信息的丢失,导致对小目标检测的效果较差。
在行人检测的具体应用中,大部分行人目标为小目标,因此融合低层的具有较小感受野的特征更有利于行人目标检测,尤其是针对距离较远的行人效果更好。这种层次性的特征正好内在地形成了特征金字塔的分布,加之不同尺度对象的检测需求,利用DNN多中间层特征的检测器成为目前行人检测的主流方法。对于这种多层次的特征使用方式一般有3种:
1) 使用多个DNN的层次特征组合进行检测,典型的网络如HyperNet和ION等[33-34]。
2) 在DNN的多层进行检测。如SSD、MSCNN、RBFNet和DSOD[36-39]等网络利用不同层次的特征来检测不同大小的目标。
3) 混合上述两种方法,如SharpMask、DSSD、FPN,YOLO V3[40-43]等,以YOLO V3为例,其网络结构如图4所示。
参照图4,YOLO V3采用416×416的三通道彩色原图作为输入,首先经过一系列卷积块和残差块进行32倍下采样,得到13×13的特征图,在此特征图上预测输出第1批检测结果。此时对应大尺度的anchor,能够检测大目标,接着将此特征图反卷积上采样至26×26,与前面下采样后同等大小的特征图进行跨通道融合,在此基础上预测输出第2批结果。第3次上采样至52×52后进行预测,对应小尺度anchor能够较好地检测小目标。类似YOLO V3这种综合多个层次特征检测的方法是现阶段检测框架的主流,对于其他网络的设计有很强的借鉴意义。针对行人检测还可以更改anchor的分配机制,分配更多的anchor给低层特征,同时鉴于行人大部分0.41的宽高比,可以微调anchor值以进一步提升效果。
5.3 上下文信息
在DNN检测框架的设计中,目前越来越注重如何有效地利用上下文信息。上下文信息可以分为语义上下文、空间上下文和尺度上下文3类。从应用范围又可以归纳为全局上下文和局部上下文信息。语义上下文描述了一个对象处在某个特定场景的可能性,例如:坦克不可能在天上跑,鱼只能在水中游等;空间上下文限定了目标只能出现在特定的位置,例如:基于零部件的检测限定,头只能出现在脖子的上面;尺度上下文检查检测对象与它周围物体的大小关系是否正常,例如:一个正常的行人是不会比紧挨着他的汽车大的。
Chen等[67]设计了多阶上下文产生器(multi-order contextualco-occurrence,MOCO)明确地模拟上下文。Zeng等[68]提出一种新的DNN模型,该模型能够通过反向传播的几个阶段联合训练多阶段分类器,通过训练策略的特定设计,可以将其作用在上下文信息以支持下一阶段训练的决策。为了处理遮挡和复杂背景的干扰,Wang等[66]提出了部分和上下文网络(part and context network,PCN),采用局部竞争机制进行自适应的上下文规模选择。Yu等[69]提出IOU损失,使真实框与预测框之间的重叠最大化。
5.4 损失函数
损失函数的设计和选择也影响着行人检测的研究。在预测行人的定位信息时,通常会把它当作一个回归问题。在RCNN中针对候选区域坐标的欧氏距离训练了线性回归模型。在Fast RCNN中,提出了SmoothL1损失替换了欧式距离。在Faster RCNN中,RPN的提出使边界回归使用了2次。为了解决遮挡和密集的行人检测,Wang等[70]基于目标的吸引力和周围目标的排斥力假设提出了排斥损失(repulsion loss)。对于样本类别不均衡带来的问题,Lin等通过重新设计标准的交叉熵损失来解决,从而降低分配给分类良好的样本的损失。FocalLoss的使用在现有检测器的基础上提升了一定的检测精度。
5.5 训练策略
训练DNN的首要条件是要有大量的标注样本。标注的质量要尽可能地高,训练样本的多样性和分布也同样重要。行人检测或目标检测不同于图像分类任务,标注的复杂度要高很多。现阶段,如ImageNet和 Places数据集等是拥有大量分类任务的数据集,因此,通常的训练策略是在ImageNet或Places上预训练骨干网络,以此作为检测网络的特征提取器,然后再在特定检测任务如行人检测数据集上进行微调,训练其定位功能。这是迁移学习的典型应用,类似的成果有很多,如RPB+BF[70]、SA-Fast RCNN[71]、SDS-RCNN[17]等。
5.6 其他子问题
为了得到更丰富的特征表达,数据增强通常也作为训练行人检测模型中必不可少的手段。数据增强一般包括裁剪、旋转、翻转、缩放、调整宽高比、更改曝光、色调和对比度等手段。更复杂的做法还涉及背景切换、环境迁移、虚拟目标等,如原始图像加雾、雨天效果等。
对于候选区域生成算法的研究也有不少代表。Chavali等在文献 [47]中全面评估了已有各种算法,并发布工具箱集成了主流的算法实现。Hosang等提出一种新的度量标准——平均召回率AR,用以更好地选择各种区域推荐算法[48]。其他一些研究则涉及了对非极大值抑制(nonmaximum suppression,NMS)算法的改进[53,45-48]。
6 结束语
行人检测是通用对象检测中一个典型且最具挑战性的问题,受到了社会各界的广泛关注。虽然深度学习的发展极大地促进了行人检测的进步,但针对复杂场景和特殊环境的行人检测仍有待提高。目前亟需解决的问题是需要更加丰富的数据集和更加高效的特征提取器。对于数据集来说,目前标准的大型数据集都基于国外的环境和场景,这在一定程度上影响了相关研究的进展。国内数据库在大型行人目标检测数据集的构建上还有很多发展空间。轻量化模型有利于设计高效的特征提取器,但精度的损失如何弥补也是未来研究的重点。综上,行人检测仍是一个机遇与挑战并存的课题。
