结构化加权稀疏低秩恢复算法在人脸识别中的应用
2019-05-22吴小艺吴小俊
吴小艺,吴小俊
(江南大学 物联网工程学院,江苏 无锡 214122)
作为计算机视觉和模式识别中最具挑战性的研究课题之一,人脸识别(FR)[1-8]在近几年一直是研究的热点课题。在实际生活中,人脸识别也被广泛应用,比如视频监控、安全相关访问和人机交互技术等。随着研究的深入,目前无污损情况下的人脸识别已经达到理想的效果。但在面部有遮挡和伪装的情况下进行人脸识别和分类仍然是一个具有挑战性的难题。
1 低秩稀疏表示理论
近年来,基于稀疏表示的方法在人脸识别领域内被广泛使用。Wright等[5]提出基于稀疏表示rank representation),将对表示系数的块对角约束和权重约束相结合,得到了更加理想的表示系数。而上述这些基于低秩矩阵恢复的方法的主要思想都是构造一个干净的具有判别性的字典,消除训练样本中的遮挡带来的影响,但是并没有考虑到测试样本中存在遮挡的情况。如果测试样本中也存在遮挡且没有通过算法被有效地移除,也将导致测试样本无法正确分类,会对实验结果产生很大的影响。
针对样本中存在污染的问题,本文提出一种结构化加权稀疏低秩恢复算法。该算法在原始低秩表示的基础上对低秩系数进行了加权和结构化稀疏约束,可以得到一个结构化的判别低秩系数,而且同类样本的表示系数会有更强的相关性。跟上述方法不同的是,受到Chen等[19]提出的DLRR(discriminative low-rank representation)的启发,本文在得到训练样本的恢复样本后,根据原始训练样本和恢复后的干净训练样本学习到一个低秩投影矩阵,并对存在遮挡的测试样本进行投影,有效地消除了测试样本中存在的遮挡,解决了测试样本中存在遮挡从而影响最终分类结果的问题。最后使用SRC方法对恢复后的测试样本进行分类识别。在几个标准数据上的实验结果验证了所提出方法的有效性和鲁棒性。
2 相关工作
2.1 稀疏表示分类
稀疏表示分类方法的主要思想是将测试样本表示为训练样本的稀疏线性组合,并计算测试样本和每个类别的重构误差,最后将测试样本分在最小重构误差对应的类别中。假设分类(SRC)。稀疏表示分类的主要思想是将一个测试样本看成一个过完备字典中少量原子的线性表示,并计算出测试样本关于字典矩阵的编码系数,最后利用最小重构误差法分类。近年来,很多基于SRC的算法被相继提出。Zhang等[9]提出了基于协同表示的分类(CRC),将SRC中的l1-norm换为l2-norm,在保证分类结果理想的同时加快了分类速度。针对小样本问题,Deng等[10]提出ESRC,使用辅助的类内变化字典表示训练样本和测试样本之间可能存在的变化。RRC[8](regularized robust coding)算法和JRPL[11](joint representation and pattern learning)算法进一步增强了SRC算法在存在污染情况下的鲁棒性。虽然SRC及其改进算法达到了较高的识别率,但是当测试样本和训练样本中都存在遮挡或像素污损的时候,算法的分类效果依然会受到影响。而直接忽略被遮挡的训练样本,隐藏在原始训练样本中的判别信息就不能被充分地利用,从而导致性能变差。因此,SRC在实际的应用中受到了限制。
最近的研究表明,视觉数据具有低秩结构,低秩矩阵恢复技术成为研究的热点题。Candès等[12]提出的鲁棒主成分分析(robust principal component analysis, RPCA)可以从被污染的数据中恢复出原始数据的低秩矩阵,随后Liu等[13]提出了低秩表示(low-rank representation,LRR)方法。基于RPCA和LRR,研究者提出了很多方法来处理训练样本中存在的遮挡和污损。Chen等[7]使用RPCA把原始的训练数据分解为低秩矩阵和误差矩阵,同时让不同类的低秩部分结构不相关,在一定程度上增加了鉴别信息。Ma等[14]提出的DLRD_SR(discriminative low-rank dictionary for sparse representation)在字典学习的过程中加入了低秩和稀疏约束,在样本存在污染时取得了较好的分类效果。Zhang等[15]提出LSLR(learning structured low-rank representations),通过在训练过程中加入结构化约束,构造出了一个结构化的字典,使得系数更加趋近于块对角结构,并通过优化后的系数对测试样本进行分类,但是LSLR并没有着重加强每类子字典对同类训练样本的表示能力。Nguyen[16]在LRR的基础上增加了标签约束项和重构误差约束项,让类内的重构误差减小而类间的重构误差增大,进一步加强了每一类子字典的判别性。Chang[17]在算法中加入权重约束项,使得在块对角上的低秩系数值更大,非块对角上的值更加趋于0,同时提高了表示系数和字典的判别性。Zhang等[18]提出BDLRR (block-diagonal low- 表 示 C 类 训练样本,样本总数为 T , X 的每列为一个训练样本图像,在本文中也记为X=[X1X2···XC], 其 中 Xi表 示第 i 类训练样本,测试样本 y ∈ Rm。SRC的目标函数为

式中: λ >0 为正则化参数,用来平衡误差项和稀疏项。在得到系数 α 后,测试样本 y 可以通过最小残差法分类,即

式中 αi是 第 i 类训练样本对应的系数。
2.2 低秩矩阵恢复
要从有遮挡的训练样本中恢复出干净的训练样本,需要借助于低秩矩阵恢复技术。有遮挡的训练样本可以表示为低秩矩阵 D 和对应的稀疏误差 E 之和,即 X =D+E。
因此,Candès等[14]提出使用鲁棒PCA方法来对 X 进行恢复,目标函数为

由于式(3)是非凸的,常用的做法是把 l0范数换成 l1范数,把秩 函数换成核范数 ‖ D ‖∗( 矩阵D的奇异值之和),因此式(3)变为

RPCA假设数据来自一个单独的子空间,但是实际中的数据通常来自多个子空间[20],基于此,Liu等[15]推广了RPCA的概念并提出了更一般的秩最小化问题,即低秩表示,目标函数为

式中: A 为字典矩阵;Z 为表示系数。上述凸优化问题可以使用不精确的增广拉格朗日乘子(ALM)算法在多项式时间内有效地解决。在得到算法的最优解(Z∗, E∗) 后, A Z∗(或 X - E∗)就是原始数据 X 的低秩恢复数据。
3 学习结构化的加权稀疏低秩表示
通过结构化加权稀疏低秩表示SWLRR(structured and weighted low-rank represen -tation)将污染的样本恢复成干净的样本,同时学习一个原始训练样本到恢复训练样本的投影矩阵。SWLRR利用了原始训练样本的标签信息,并对低秩表示系数进行加权稀疏约束,使得相似的样本尽可能有相似的表示,也增强了恢复矩阵的判别能力。
3.1 结构化的加权稀疏低秩表示(SWLRR)
为了提高SRC的性能,可以利用低秩矩阵恢复技术来解决上面提到的几个影响分类效果的问题。把原始的训练样本分解为干净的训练样本和对应的稀疏误差。受Zhang等[15]和Zhang等[18]的启发,本文在原始式(5)的基础上增加了两个对低秩表示系数的约束项,提出了用SWLRR来恢复污染的样本,同时增强恢复矩阵的判别性。


式 中: α 、 β 、 λ 是 标 量 参 数; ⊙ 表 示Hadamard积(逐元素相乘); ‖ D ⊙Z‖0利用了加权的方法来提升对类内样本表示的相关性; D 是一个和矩阵 Z 大小相同的矩阵, D 的 元素 dij表 示第 i 个 基 ai到第j个训练样本 xj的距离(有很多度量样本之间距离的方法,本文用欧氏距离的平方来定义两个样本之间的距离,即的目的就是通过对低秩系数矩阵进行加权约束,来提高类内表示的相关性,让相似的样本有更加相似的表示,加强训练样本的自表示能力,也在一定程度上提高了表示系数的鉴别性。因为 l0范数最小化问题是 N P 难问题,所以我们把第2项写成它的替代形式 ‖ D ⊙Z‖1。因此,式(6)可以改写为为结构化约束项,由于当训练样本去除噪声、遮挡、表情和光照影响后,每一类的样本有着相似的基结构[14]。根据2.2节的讨论,给定一组基A,低秩矩阵恢复可以将污损的矩阵X分解成低秩部分AZ和稀疏噪声部分E,即X=AZ+E。根据文献[15],基A关于训练样本X的低秩表示矩阵 Z 应该具有块对角结构:



3.2 算法优化求解
为了将变量分离,引入辅助变量 P 、 J,则式(8)变成:

式(9)可以用ALM求解,它对应的增广拉格朗日函数为

式中: Y1、 Y2、 Y3为 拉格朗日乘子; µ >0 为惩罚参数; < Y2,Z-P>=tr(Y2T-(Z-P)),本文利用含有自适应惩罚项的线性交替方向法(linearized alternating direction method with adaptive penalty, LADM AP)[21-22]来优化式(10),为描述方便,式(10)可以进一步简化为

可以交替优化变量Z、P、J、E,即优化其中一个时,固定另外3个变量。每次迭代时变量的更新情况如下。


式(16)、(17)中的 T 为软阈值算子,算法1总结了式(10)的优化过程。通过算法1迭代更新得到问题,即式(7)的最优解(Z∗, E∗)那么被恢复的图像和对应的误差则为 A Z∗和 E∗。图1展示了不同类的训练样本和对应的恢复结果。

图 1 SWLRR算法得到的恢复结果Fig. 1 Recovery results obtained using SWLRR method
算法1 用LADMAP求解问题 (即式(8))
输入 训练数据样本 X =[X1X2···XC]∈ Rm×n,参数 λ > 0,β > 0;
输出 (Z∗,E∗)。
初始化 Z0= P0=J0=E0=Y1,0=Y2,0=Y3,0=0,µmax=108, ρ0=1.1 , δ=10-6,m a xiter=1 000,k=0。
若不满足式(7)中的收敛条件,则循环下列更新步骤:
1)根据式(13)更新 P ;
2)根据式(16)更新 Z ;
3)根据式(17)更新 J ;
4)根据式(18)更新 E;
5)更新拉格朗日乘子:
Y1,k+1=Y1,k+µk(X-XZk+1-Ek+1);
Y2,k+1=Y2,k+µk(Zk+1-Pk+1);
Y3,k+1=Y3,k+µk(Zk+1-Jk+1);
6)更新参数 µ: µk+1=min(ρµk,µmax);
7)检查收敛条件:
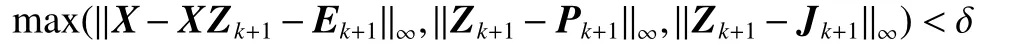
8)更新 k ← k+1;
3.3 低秩投影矩阵
在对样本进行分类时,训练样本和测试样本中存在的遮挡都会对分类结果产生影响。所以将训练样本恢复成干净样本后,接下来要考虑的问题就是如何移除测试样本中可能存在的遮挡。受Bao等[24]启发,可以通过学习一个低秩投影矩阵,将受污染的测试样本投影到相应的低秩子空间。
根据算法1求出低秩表示系数 Z∗后 ,Y=X Z∗∈Rm×T即为训练样本的低秩恢复。通过原始训练样本 X 和其低秩恢复 Y,可以学习一个低秩投影矩阵 A。可通过优化如下问题得到低秩投影矩阵 A :

假设 A∗为上述优化问题的最优解,通过Y=AX 可 知上述优化问题的最优解为 A∗=YX+,X+为 X 的 伪逆矩阵。 X+的伪逆矩阵可以通过X+=VΣ-1UT求 解, U ΣVT为 X 的 瘦 形 奇 异 值 分解。样本 X 的主要成分和误差部分分别为A∗X和 X -A∗X 。 因为 A 反应的是污染样本和干净低秩恢复之间的一种映射关系,所以当给定一个测试样本 y , A∗y 即 为测试样本 y 的低秩恢复。
图2是AR数据库中部分测试样本图像经过?低秩投影矩阵恢复后的图像,可以看到通过将测试样本投影到低秩投影矩阵,测试图像中的遮挡区域得到一定程度的消除,接下来就可以开始进一步地降维和分类操作,SWLRR的整体流程如算法2所示。
4实验结果与分析
为了验证SWLRR的有效性,本文将SWLRR和一些已经提出的经典算法如DLRR、SRC、LRMR、RRC[8]、SVM[25-27]进行了对比。所有算法均使用SRC算法进行分类。实验中SWLRR和DLRR算法引入了低秩投影思想。实验分别在CMU PIE、AR和Extended Yale B人脸数据库上进行。

图 2 测试样本经过矩阵 A 投影后的恢复结果Fig. 2 Recovery results using low-rank projection A


我们使用有光照、表情变化以及饰物遮挡的人脸图像对SWLRR算法进行测试,实验中所有训练样本和测试样本的污损类型都是相同的,且每一次样本选择都是随机的。实验涉及4个重要参数,包括3个SWLRR的权重参数 α 、 β、λ 和1个SRC参数 s r cλ,参数值通过多次实验确定。在 A R[28]、Extended Yale B[29-30]、CMU PIE[31]数据库参数均设为= 0 . 05。
实验在CPU为Intel core i5-6500 @3.20 GHz,内存为12.0 GB,操作系统为Windows 7,MATLAB版本为MATLAB R2015a的环境下进行。
4.1 无遮挡的人脸识别实验
4.1.1 Extended Yale B数据库
Extended Yale B数据库由38个人的2 414张人脸图片组成,每个人大约有59~64张不同的光照环境下的图片。在实验中,每张人脸图片大小为192像素 × 168像素。图3(a)展示了Extended Yale B数据库中某类的少量样本。在Extended Yale B 数据库我们进行了2次无遮挡实验,分别在每一类中随机选择16和32个样本作为训练样本,其余作为测试样本。每个实验重复10次,取10次结果的均值为最终结果。特征维度选择为25、50、75、100、200和300。训练样本个数为16和32的实验结果如表1、2所示。
两组实验结果显示以上所有算法的识别率都随着图像特征维度的增加而增加,这是因为相对较高的维度提供了更多的图像信息,从而提高了识别性能。而且在维度相同时,SWLRR的识别率远高于其他算法,尤其是在特征维度较低时,本文提出的方法更加有优势。例如:特征维度为25时,以上的2组实验中SWLRR的识别率高达92.41%和97.75%,远远高于其他算法。实验结果可以证实,SWLRR可以较好地解决样本中存在不同的光照和表情的问题。

图 3 实验中用到的样本图像Fig. 3 Images used in our experiments

表 1 Extended Yale B数据库在无遮挡条件下不同维度的算法识别率(16训练样本)Table 1 The recognition rate of different dimensions in Extended Yale B database without occlusion(16 tr aining samples) %

表 2 Extended Yale B数据库上在无遮挡条件下不同维度的算法识别率(32训练样本)Table 2 The recognition rate of different dimensions in Extended Yale B database without occlusion(32 tr aining samples) %
4.1.2 AR数据库实验
AR数据库包含126个人的4 000多张人脸图片,每个人有26张,被分为两部分,每部分由含有表情光照变化的7幅无遮挡图片、3幅戴墨镜图片和3幅戴围巾图片组成,每幅图片大小被裁剪成165像素 × 120像素,图3(b)展示了AR数据库中某类的少量样本。实验中每人前半部分图片中的7张无遮挡图片作为训练样本,后半部分中的7张无遮挡图片作为测试样本,特征维度选择为 2 5、50、100、200、300,对比结果如表 3 所示。从实验结果来看,SWLRR在AR数据库上无遮挡条件的识别率也均高于其他算法。

表 3 AR数据库在无遮挡条件下不同维度的算法识别率Table 3 The recognition rate of different dimensions in AR database without occlusion %
4.1.3 CMU PIE 数据库实验
CMU PIE数据库由68个人的41 368张图片组成,所有图片在不同姿势、光照和表情条件下采集。本文选用编号为C07的子数据库用来实验,其包含68个人的1 629张图片,每人大约24张,每张图片大小为64×64,图3(c)展示了CMU PIE数据库中某类的少量样本。实验中每类随机选择12张图片作为训练样本,其余图片作为测试样本,共进行10次实验,取10次结果均值为最终结果。特征维度选择为25、50、100、200、300,对比结果如表4所示。

表 4 CMU PIE数据库上不同算法在无遮挡条件下的识别率Table 4 The recognition rate of different dimensions in CMU PIE database without occlusion %
从表4可以看出,在CMU PIE数据库上SWLRR算法在不同维度下识别率同样远高于其他算法。在维度为25时,SWLRR算法识别率为93.39%,高于DLRR算法将近11%。但是,随着维度的增加,各种算法识别率的差异变得越来越小,主要是因为在低维度情况下,DLRR算法缺乏结构化特征,数据的线性特征不足以分离不同子空间的样本,SWLRR增强了不同类样本的结构性,进一步提高了样本的判别能力,从而提高了识别率。
4.2 有噪声的人脸识别实验
4.2.1 加入人工噪声的人脸识别
为了验证SWLRR算法的鲁棒性,首先在Extended Yale B数据库上进行添加随机高斯噪声的实验。实验中,每张图片大小为192×168像素。对整个数据库分别随机选择10%和20%比例的样本进行高斯噪声污染,污染比例为10%,污染后,每类随机选择32个样本进行训练,剩余样本进行测试,每次实验重复5次取均值。在维度为50、100、300时对2种污染比例下不同算法进行比较,结果如表5所示。

表 5 Extended Yale B 数据库上不同算法在两种比例噪声污染下的识别率Table 5 The recognition rate of different methods on the Extended Yale B database with two kinds of pixel corruptions %
表5中,前3行和后3行分别是随机选择数据库中10%和20%比例的样本进行污染后,SWLRR算法在该数据库上的识别库(不同特征维度下)。
4.2.2 有真实遮挡的人脸识别
本节进一步研究SWLRR算法在不同类型的面部遮挡情况下的性能,实验选用了难度较大的AR数据库,因为AR数据库中的图像会存在多种类型的遮挡。主要通过选取以下2种类型的遮挡来评估算法的鲁棒性。
1)太阳镜:验证SWLRR在选取的训练样本和测试样本中均含有太阳镜遮挡时的性能,太阳镜大概遮挡了人脸的20%。选择每一类前半部分中的7张中性图片(表情光照)加上随机选取的一个有太阳镜遮挡图片作为训练样本,则后半部分的7张中性图片和所有剩下的5张太阳镜图片作为测试样本(8个训练样本,12个测试样本)。
2)太阳镜围巾混合情形:验证SWLRR在选取的训练样本和测试样本中均含有太阳镜和围巾遮挡时的性能。每一类前半部分中的7张中性图片(表情光照)和随机选取的一个有太阳镜遮挡图片、一个有围巾遮挡图片作为训练样本,则后半部分的所有图片和前半部分剩下的的2张含有太阳镜和2张含有围巾的图片作为测试样本(9个训练样本,17个测试样本)。
实验中,对类型1)进行3次实验,每次选择不同的遮挡图片作为训练样本,最后取3次分类结果的均值;对类型2),进行9次实验,每次选择不同组合的太阳镜样本和墨镜样本作为训练样本,最后取9次结果的均值。特征维度选择为25、50、100、200和300。以下列举了各种算法在类型1)和2)时的识别率,如表6、表7所示。

表 6 AR数据库上不同算法在太阳镜遮挡条件下的识别率Table 6 The recognition rate of different methods on the AR database with the occlusion of sunglasses %

表 7 AR数据库上不同算法在混合遮挡条件下的识别率Table 7 The recognition rate of different methods on the AR database with mix occlusion %
从表6、表7可以看出,在样本存在真实遮挡的情形下,SWLRR算法在不同维度时,性能仍然优于其余所有算法,这表明SWLRR算法在样本存在真实遮挡时有着较好的鲁棒性。
5 结束语
本文提出了用于人脸识别的结构化加权稀疏低秩恢复算法(SWLRR),主要解决了训练样本和测试样本同时存在污染导致无法正确分类的问题。SWLRR首先对低秩系数进行权重和结构化约束,继而通过移除训练样本和测试样本中的污染,有效减少了样本中的污染对实验结果造成的负面影响。因此SWLRR算法样本在有无遮挡的情况下都有着较为突出的性能。在AR、Extended Yale B、CMU PIE数据库上的实验验证了SWLRR算法在不同情况下的有效性和对噪声的鲁棒性。下一步将尝试将本文思想与其他解决样本中存在污染的算法结合,进一步提升算法性能。
