约束条件下联盟生成研究进展
2019-05-22任子仪童向荣
任子仪,童向荣
(烟台大学 计算机与控制工程学院,山东 烟台 264005)
联盟生成是多Agent系统(multi-agent system,MAS)研究基本问题之一[1-2],主要将Agent进行合作或协商,使其效用增加。Agent联盟基本上被认为在MAS的框架内的一组Agent,愿意与这组中的其他Agent合作,共同合作活动的目的是达到最佳的标准。当Agent通过组建联盟共同工作时,联盟结构生成就会发生[3]。目标就是求一种最优的联盟结构,使得所求的社会福利最大,并返回其值[4-5]。
Agent在联盟生成时达到最优方案不一定是全局最优解,但是应该是Nash最优解[6-7]或者次优解,因此联盟生成主要包括以下活动:
1) 联盟结构生成:Agent之间进行协商生成联盟,但不考虑各个联盟之间的协商。
2) 解决每个联盟优化问题:将Agent的任务和资源集中在一起,共同解决问题。Agent之间进行协商使联盟的社会福利尽可能最大化,即寻找最优的方法使得联盟本身的效用最大化。
3) 划分值:在进行收益分配的时候,常用的方法有两种,即公平(每个Agent所得到的收益是Agent在博弈中的贡献的体现)和稳定(存在没有和其他Agent协商而单独形成自己的自私利益联盟)。
同样,存在很多方法寻找和创建一个最优的联盟——协商或搜索以及用于找出解决问题的几种潜在的方法,例如:遗传算法、博弈论、粒子群算法等。但是,随着研究的不断深入,在现实世界的应用中有一些联盟结构是不允许生成的[8]。目前,联盟研究的热点问题主要是约束条件下联盟生成。在现有研究中,很多文献已经考虑将联盟进行广泛应用,例如:通过形成联盟,自主传感器可以改善某些区域的监控情况[9];认识无线电网络可以增加它们的吞吐量[10];购买者可以通过批量购买而获得较低的价格[11];自主连接车辆进行护航工作[12];形成联盟促进社交网络关系[13-14]等。
在Agent联盟研究发展中,Sandholm等[15]最先提出最坏情况有限界联盟结构生成;Yeh等[16]首次使用动态规划算法联盟生成并求得精确最优解;随着研究的不断深入,Agent数量的增加,先前的算法越来越不能满足当前的需求,Dang等[17]首次提出建立次优联盟结构并求得次优解;Greco等[18]经过进一步研究,提出了一种新的联盟结构生成的方式——约束联盟结构,即在生成联盟的过程对联盟添加约束。
1 基本定义
1.1 主要定义
假设所有的Agent都是理性的,并使用合作博弈建模进行Agent之间的合作和协商。在博弈中,令 N 是一个 A gent集,其中 n = |N| 表 示 N 中Agent的个数,则 N =(a1,a2,···,an), 联 盟即 N 中非空的子集。
定义1 联盟 结 构。对 于任意 联 盟 C , 在 C 上形成的联盟结构 C S ={C1,C2,···,Ck}, 其 中 ∪ C S=C,并 且 对 于 任 意 i , j∈ { 1,2,···,k},i≠ j 都 需 要 满 足Ci∩Cj=Ø。
例1 一个集合 N ={a1,a2,a3},N上的联盟一共 有7种 情 况,分 别 是 { a1}、 { a2} 、 { a3} 、 { a1,a2}、{a1,a3}、 { a2,a3}、 { a1,a2,a3},联盟结构一共存在5种情况,分别是 {{ a1},{a2},{a3}}、 { { a1},{a2,a3}}、 { { a2},{a1,a3}}、{{a3},{a1,a2}}和 { a1,a2,a3}。
定义2 社会福利。社会福利即为联盟结构CS中所有的联盟 Ci,i∈ { 1,2,···,k} 的收益之和,将联盟的值记为 v ( Ci), 并 且要求 v ( Ci)≥0,联盟结构的社会福利记为 V ( CS),将具有最大的社会福利联盟结构称为最优联盟结构,记为 C S∗,其最优社会福利记为 V ( CS∗),则

定义3 次加性。对于任意的不相交的联盟S,T∈N , 都 存 在 v ( S ∪T)≤v(S)+v(T)。换 言 之,{{a1},{a2},···,{an}}为最大社会福利的联盟结构。
定义4 特征函数。给定一个 n 个Agent的博弈, C 是一 个 联盟, v ( C) 是 指 C 和 N - C 两个Agent博弈中 C 的最大效用, v ( C) 称 为联盟 C 特征函数(characteristic function),规定 v ( Ø )=0。
1.2 博弈类型
在常用的联盟博弈模型中,通常用货币来表示联盟的价值(或奖励[19])。在进行博弈的过程中,假设存在一个在Agent之间可以自由流动的交换媒介(如货币),每个Agent可以根据自己的绩效得到相应的货币,这种博弈被称为“单边支付”博弈或可转移效用(transferable utility,TU)博弈。相反,联盟的绩效是用向量表示的,直接指定每个成员的绩效,Agent只能服从这种分配方案,不能对分配方案进行修改,这种博弈被称为不可转移效用(non-transferable utility,NTU)博弈。在多Agent系统中,可转移效用博弈受到了很大的关注。
1) 特征函数博弈
特征函数博弈(characteristic function games,CFGs)是联盟的价值完全取决于它所包含的Agent的值。将特征函数博弈定义为 ( N ,v),其中N表示Agent数据集,v 是一个函数,称为特征函数,对于每个联盟C映射到函数中的值 v ( C ) 记为v:2N→R。
2) 分区博弈
在分区博弈(partition function games,PFGs)中联盟的价值不仅仅取决于所包含的Agent的值,也会受非成员分区的影响。将分区博弈定义为(N,w), 其 中 N 表 示Agent数据集, w 是一个分区函数,每个嵌入式联盟 ( C ,CS) 映射到函数中的值是 w ( (C,CS)) 或 w ( C,CS)。
CFGs是PFGs的子集,联盟C在CFGs中有一个精确值,但在PFGs中却存在很多值,这是因为使用PFGs有不同的方法对 N / C 中的Agent进行分区。因此,在进行研究的过程中,使用CFGs更容易得到解决方案,提高算法的效率。
1.3 空间表示
在联盟结构生成问题中,通过联盟结构搜索得到最优联盟结构。
1) 联盟结构图
Sandholm等[15]提出的联盟结构图中,每个节点代表一个联盟结构,并且将节点进行了划分,表示为其中表示由i个联盟组成的所有的联盟结构的节点;边缘连接两个联盟结构,当且仅当它们属于不同的划分,如和;其中中的联盟结构是由中的联盟分裂成两个联盟形成的。图1所示为具有4个Agent集联盟结构图。
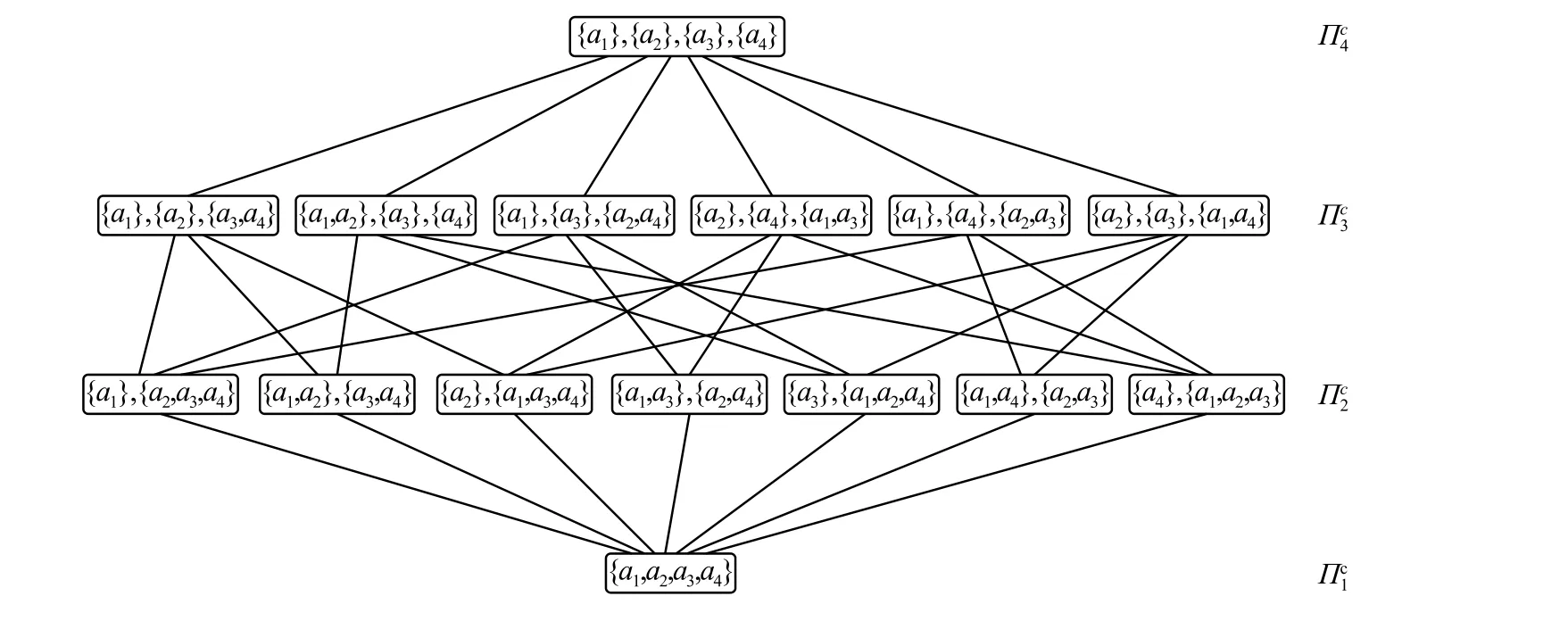
图 1 4个Agent联盟结构Fig. 1 The coalition structure graph with 4 Agents
2) 整数分区图
在联盟结构图中,能直接看出具有i个联盟所组成的联盟结构的情况。而Dean等[20]提出的整数分区图中,则是基于联盟结构中所包含的联盟的数量,将联盟结构中的空间划分成不相交的子空间,每个子空间是由n个整数分割表示的。整数n的分区值可以通过递归的方法计算[21],用Pn表 示整数分区。例如:P4={{4},{1,3},{2,2},{1,1,2},{1,1,1,1}}。
假设 I ∈ P , 定 义 ΠIC∈ΠC是所有联盟结构组成的子空间,其中联盟的大小受 I 部分的影响。例如:表示是由2个只有1个Agent联盟和1个有2个Agent组成的联盟形成的联盟结构。对于这种表示一般用整数分区图来表示。整数分区图也是一个无向图,其中每个节点代表一个子空间。两个节点 I , I′∈ Pn是通过边连接的,当且仅当 i , j ∈ I 时 , I′=(I{i,j})Ξ{i+j}( Ξ 表示多重集的结合操作)。图2给出了有4个Agent整数分区图。
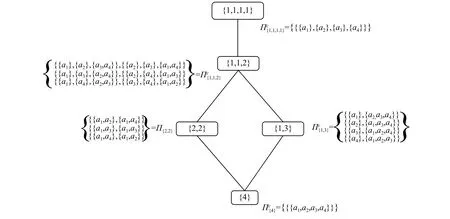
图 2 4个Agent整数分区图Fig. 2 The integer-partition graph representation of 4 Agents
2 联盟生成的复杂度
2.1 输入值的大小
对于具有n个Agent的数据集,会产生2n-1个非空的子集,生成 2n-1 个联盟,在进行运算时需要输入 2n-1 个值。联盟结构生成算法的输入值和Agent的个数之间呈指数关系。
理论上,在进行输入操作时即可排除一些不合理的联盟,或者在进行联盟结构生成的时候就可以忽略一部分的输入。但是在接下来进行的操作过程中无法保证存在单一的联盟与其他的联盟进行合作之后的社会福利不是最佳社会福利,这是因为:被排除在外的联盟中可能存在比其他的联盟社会福利更大的联盟。
2.2 联盟结构的数量
随着联盟结构不断发展,Agent数量的增多,新问题也随之产生。联盟结构的个数表示为
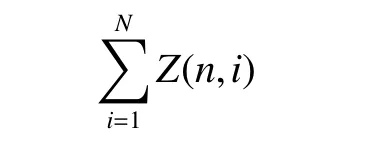
其中:n代表数据集中的Agent个数; Z ( n,i) 表示具有i个联盟组成的联盟结构的个数; Z ( n,i) 满足第2类Striling数的特征,即

式中: Z ( n,i)=Z(n,1)=1; i Z (n-1,i) 表示在现有存在的联盟中增加一个新的Agent形成的联盟结构的个数; Z (n-1,i-1) 表示将一个新的Agent加入到已有的联盟中,因为现在的联盟结构中只有i-1个联盟被计算。有以下基本结果[22-24]:
命题1 对于具有n个Agent的集合,具有2n-1个 联盟, O (nn) 和 ω ( nn/2) 个联盟结构(即联盟结构的个数的阶介于~n之间)。
命题2 寻找最优联盟结构是NP难问题。
随着Agent数量的增加,联盟结构的数量也随之增加。经过实验的证明,当数据集中Agent个数超过15时,使用穷举法列举出所有联盟结构是不可行的。
3 最坏情况有限界联盟结构生成
Dean和Boddy在时间依赖规划(time dependent planning)的基础上提出了Anytime算法,其本质是一种反复求解使得结果更加精确的算法。在算法的运行过程中,能够很快得到一个不精确的解,然后进行若干次的重复过程,经过重复后逐步提高解的质量,Anytime算法一个最显著的优点就是能够很好地权衡计算时间和解的质量。Sandholm等[15]使用Anytime算法开创性地提出了一种最坏情况有限界联盟结构生成。
命题1表明,在联盟结构图上找到最优的联盟结构是不可行的。所以,在进行联盟结构图的搜索的时候设定一个限界。
对联盟结构的子集N进行搜索,目的在于寻找搜索中的最优联盟结构,即局部最优联盟结构,记:
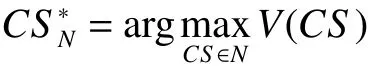
同时,为了保证设定的联盟结构在最佳范围内,即存在一个有限的但是尽可能小的值k,k被称为搜索的解的界限,也是衡量局部最优解的标准。能够建立起界限的最小的k记为
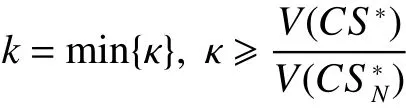
通常,如果没有对联盟结构进行完全搜索,设定一个正确的界限是很难的。这是因为:在剪枝的过程中虽然可以减少一些联盟结构的搜索,但是很难保证没有剪掉的比剪掉的具有更优性。在进行社会福利的定义的时候,令任意一个联盟Ci的值 v ( Ci)≥0,并且一个联盟结构的社会福利这两点就保证了上述假设是不存在的,即在没有对联盟结构进行搜索的前提下设置一个界限来缩小搜索联盟结构的数量。
3.1 建立界限
本节主要讨论如何尽可能地减少对图的搜索的前提下,建立一个界限k。
定理1 对于界限k,可以只搜索联盟结构图的最低的两级(图1中第、层)。在这个搜索中,界限k=n,需要搜索的联盟结构节点的数量是 2n-1,这也是能够建立起界限的最小的搜索,即nmin=2n-1。并且,没有其他的算法对于联盟结构的搜索的数量会比 2n-1少。
最底层具有1个联盟结构,第二最底层中具有 2n-2 个联盟(N中的所有子集,除掉全集和空集)。在这一层中,每个联盟结构都有2个联盟,所以一共有个联盟结构。只搜索最底下两层,一共搜索个联盟结果。
3.2 算法描述
算法1 最坏情况有保证联盟结构生成算法1) 搜索联盟结构图的最底二层;
2) 从联盟结构图的顶层(第n层)开始,作宽度优先搜索,一直搜索到时间不允许为止或搜索完整个联盟结构图;
3) 返回迄今为止所得到的最优的联盟结构。
先前使用特征函数的方式[25-26]进行联盟结构生成,算法1是一种任意时间算法,可以在任何时间中断。如果将第1、2层搜索完成后,还存在剩余时间,则可进一步地搜索缩小界限。

在 2n-1个节点被搜索完之前,无法建立一个界限。当搜索到 2n-1+1 个节点时,可以建立界限k=n;搜索到 2n-1+1 个节点的时候,界限变成k=。通过更多实验验证:当界限k变成时,搜索的层数就会增加2层。当搜索的层数每增加2层,界限k前面的除数就会加1,若只多搜索一层时,没有明显效果。
总之,最坏情况有限界联盟结构生成算法中第2步具有很强的理性,即界限k能够迅速地下降,同时该算法的收益递减,如图3所示。
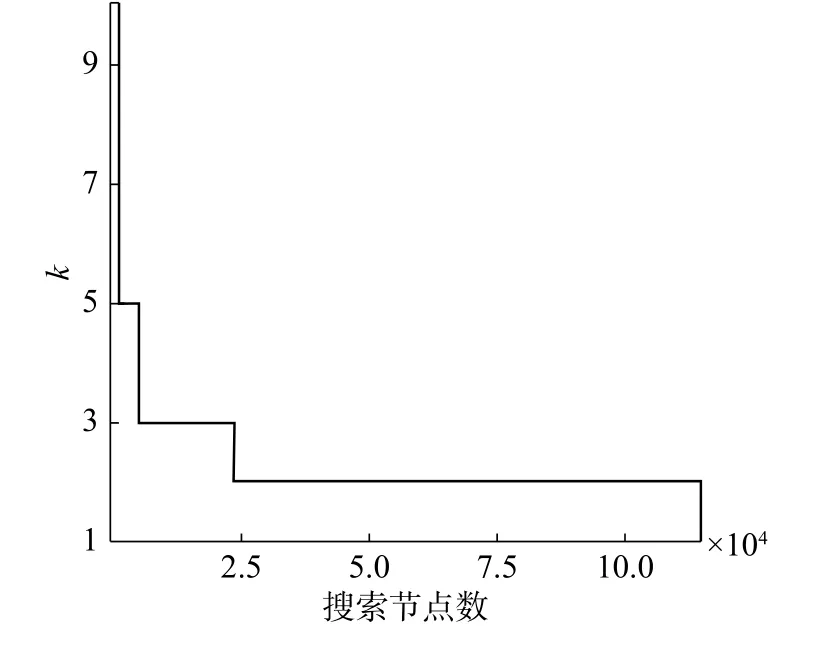
图 3 界限k作为10个Agent博弈中搜索的函数Fig. 3 Ratio bound k as a function of search in a 10-Agents game
胡山立等[27-28]对算法1深入研究并进行改进,给出了解决问题的一种任一时间联盟结构生成算法和给定界限要求的联盟结构生成。Dang等[29]提出不以层为单位最坏情况有限界的联盟结构生成。
4 动态规划联盟生成求精确最优解
动态规划(dynamic programming,DP)算法和分治法类似,其基本思想是将待求解的问题分解成若干个次级子问题,在求解的过程中,先求解子问题,然后从子问题的解中得到要求解的问题的答案。将动态规划算法应用于最优化的问题,一般分为4个步骤来完成:
1) 找出最优解的性质,并刻画其结构特征;
2) 递归定义的最优值;
3) 以自顶向下的方式计算出最优值;
4) 根据计算最优值所得到的信息,构造最优解。
将动态规划算法应用于联盟中的想法是Yeh 在 1986 年 首 次 提出的[16];Rothkopf[30]及刘惊雷等[31]使用DP算法对求解最优联盟结构的算法进行了改进,主要解决存在大量重复子问题计算的问题;Rahwan等[32]提出了IDP(improved dynamitic programming)算法;张新良等[33]在2007年提出了一种快速动态生成 (search of coalition structure,SCS) 算法,主要降低搜索次数。本文中,DP算法主要基于定理3。

使用定理3进行动态规划,先计算只有一个Agent的联盟,接着迭代具有2个Agent的联盟,然后是具有3个Agent的联盟,一直迭代到具有n个Agent的联盟。对于每个联盟C都需要使用式(1)计算。从式(1)中易知:当 |C |≠1 时,需要分别计算) 的值,然后将两个值进行比较,得到具有较大社会福利的联盟。在此过程中,将所产生的暂存结果保存在变量 t ( C ) 中。
通过上述操作,计算出来的最大 v ( C ) 就是我们最终要求的 V ( CS∗)。 计算 C S∗的迭代过程具体操作如例2所示。
例2 令数据集 N ={a1,a2,a3,a4},假设特征函数为
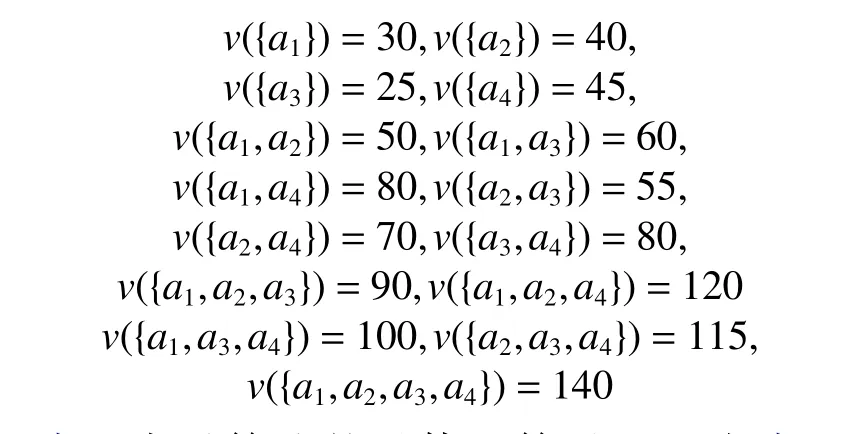
表1表示算法的具体运算过程。由表1知,t(N)=({a1,a2},{a3,a4}), 能够将N分裂成 { a1,a2} 和{a3,a4}, 而 t ( { a3,a4})={{a3,a4}}, 这 是 因 为 { a1,a2} 分裂成 { a1}、{a2} 后 的社会福利比较大, { a3,a4} 不需要进行分裂。所以 C S∗={{a1},{a2},{a3,a4}}。

表 1 4个Agent动态规划算法Table 1 The dynamic programming algorithm for 4 Agents
定理4 给定一组Agent集,使用动态规划算法求得最优联盟结构的时间复杂度 O ( 3n)。
DP算法在该算法的运行过程中实际做了如下几方面:
1) 评估图上的运动;
2) 在表t中存储最优结构;
3) 从底部节点开始向上运动。
5 联盟生成求近似最优解
Rahwan等[34]将联盟配置与Anytime算法进行结合提出一种联盟结构相似最优解算法;为Albizuri等[35]基于整数分区对联盟结构进行推广从而对联盟配置(coalition configuration)进行了定义。
5.1 基本定义
在进行求解的过程中,设 C Ls∈2n,其中s ∈ { 1,2,···,k} 是 联盟列表, C Li是 联盟列表 C Ls的集合(见表2)。设 G1,G2,···,Gςcs∈ ςcs是所有的存在的唯一配置的结合(即不存在具有相同联盟大小的两个元素),令 F :ςCS→ 2CS是一个函数,按照提前设定好的配置返回所有的联盟结构。 N 表 示一个列表,里面的每一个元素表示一组具有相同配置的联盟结构。形式上, N 定义为:N ={F(G1),F(G2),···,F(G|ςCS|)},N1,N2,···,NςCS∈ N 表 示N中的每个元素(见表3)。

表 2 4个Agent联盟列表Table 2 The coalition list of 4 Agents
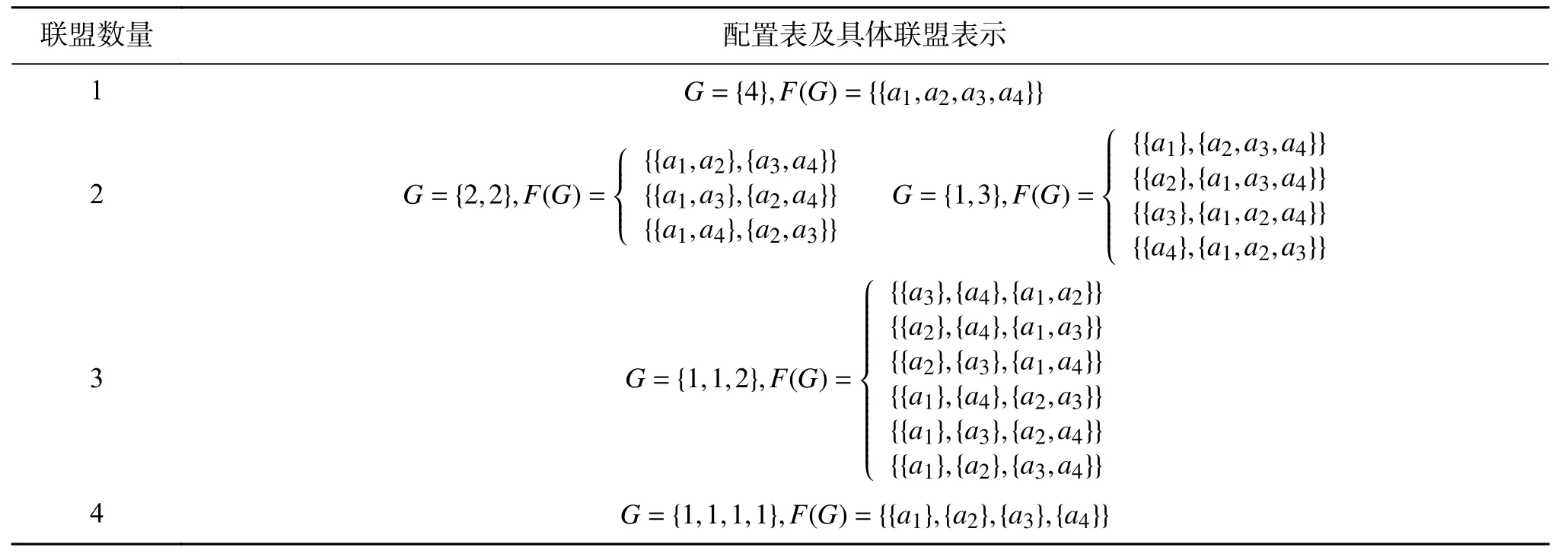
表 3 4个Agent配置表及具体联盟表示Table 3 The configuration table and specific coalition representation of 4 Agents
5.2 具体实现
算法实现分为3个部分:1)预处理操作;2)构造和选择合适的配置;3)搜索元素。
1) 预处理操作
预处理的主要目的是计算 C Ls的 最大值maxs和平均值 a v gs并返回计算值,同时将当前搜索社会福利最大的联盟结构返回记为 C S′。此过程中,主要进行2种操作,分别是评估互补大小和包含配置为 { 1 , 2,···,i} 的联盟。
①评估互补大小:将 C Ls和 C Ln-s称为互补的,如 C L3和 C L1。在此过程中需要计算由互补中的联盟组成的不相交的联盟结构的值。
②包含配置为 {1 , 2,···,i} 的 联盟:计算G={1,2,···,i}配置的联盟结构的值。
经过上述两个操作搜索联盟结构,可以搜索空间的一部分(随着n的增加而减小)。表4表示的是8个Agent搜索结果,其中配置 G ={8},G={4,4},G={3,5},G={2,6},G={1,7}, G ={1,1,6},G={1,1,1,5} , G={1,1,1,1,1,3} , G={1,1,1,1,1,3},G={1,1,1,1,1,1,2},G={1,1,1,1,1,1,1,1}是在预处理操作中需要将被搜索的配置。
2) 构造和选择合适的配置

表 4 8个Agent配置表Table 4 The configuration table of 8 Agents
在搜索过程中,进行剪枝操作主要目的是减少搜索空间。 G′为 搜索完后找到可能存在最优联盟结构的配置。
①构造独一无二的配置:保证所有的配置的集合等于所有Agent可能产生的整数分区。例如,有5个Agent,可能存在的整数分区的配置G 为 {5},{4, 1},{3, 2},{3, 1, 1},{2, 2, 1},{2, 1, 1,1}和{1, 1, 1, 1, 1}。计算每个配置G对应于F(G)的上界 U BG和 平均值 A v gG。 将 V ( CS′) 和UBG′β 进 行比较,如果 G′中所有的配置都满足前者大于后者,那么该解即为最优解。否则,进行②操作。
3) 搜索元素
搜索过程的关键在于构建联盟结构。在该算法中,构建联盟结构的主要问题是,在执行时会进行重复操作,从而形成冗余和无效的联盟结构。
①避免重叠的联盟结构:重叠的联盟结构是 { { a1,a2}{a2,a3}} 这样。使用快速索引技术[36]进行解决。
6 约束条件下联盟生成求最优解
Frankovi等[37]将关注点从所有Agent之间的联系转移到只关注给定Agent之间建立最优的联盟。Greco等[18]经过进一步研究,提出了一种新的联盟结构生成方式——约束联盟结构,即在生成联盟的过程对联盟添加约束。
6.1 约束联盟的基础
在进行约束联盟结构形成的过程中,主要是定义在一对 < N ,v> 上 的, < N,v> 称为联盟博弈,其中N = ( a1,a2,···,an) 是Agent集,v是评估函数。
例3 假设一个联盟博弈为 < N,v>,其中N=(a1,a2,a3),评估函数为
易知,最优联盟结构是 { a1,a2,a3} 和 { { a1,a2},{a3}},这是因为 v ( { a1,a2})+v({a3})=v({a1,a2,a3})=3。
假设在联盟博弈 < N,v> 中,Agent集上定义一个无向图G,G称为交互图。联盟C是可行的,当且仅当C在G的子图上是连通的。
6.2 约束联盟结构生成
令 Γ = <N,v> 是 联盟博弈, D =(N,E) 是联盟博弈上的一个交互图,其中图中的交点是N中的Agent,边是节点集,设 S ∈N 是一个可能为空的Agent集,称为枢纽Agent。规定任意一个可行联盟结构中不允许存在两个及其以上的枢纽Agent。α,β : S ■→ R 是 两个评估函数,而 x , y∈ R 是两个实数,则 σ = < D ,S,α,β,x,y> 是 < N ,v> 的评估结构。
例4 给定一个联盟博弈 Γ = <N,v>,其中N ={a1,a2,···,a7}。 评 估 结 构 为 σ = (D,{a1,a2},α,β,x,y),其中图D如图4所示。
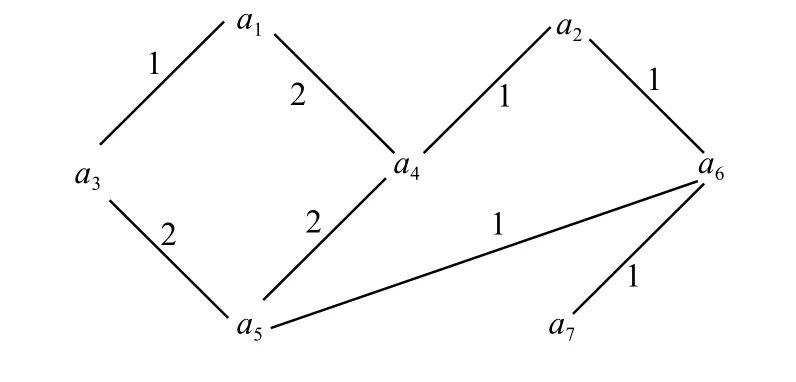
图 4 7个Agent交互图Fig. 4 The interactive graph of 7 Agents
图4中 C1={a1,a3}, C2={a4,a5,a6} 是2个可行联盟,而 { a1,a2} 和 { a5,a7} 是2个不可行联盟,前者是因为联盟中2个Agent都是枢纽Agent,后者则是因为联盟不是图4的子图。
如果C是可行联盟结构,将函数α、β和实数x、y 通过式({2)定义成评估函数v的映射 v a lσ。

例5 假设图4中,估值函数为v,C是一个可行联盟,则 v ( C ) 被定义为由C所覆盖的边的权值的总和,即 ∑假设函数 分别为 ,

,而实数 x=0,y=-12,则 +。
6.3 边际贡献网上联盟生成
α、β α:{a1,a2}→{1} β:{a1,a2}→ {0} valσ(C1)=1×v(C1)0=1,valσ(C2)=0×v(C2)-12=-12
边际贡献网[38]在过去的几年里收到了相当大的关注。边际贡献网(marginal contribution network, MC-net)是包含一系列代表Agent的布尔变量的规则,每个规则的形式为 { p a ttern}→value,其中pattern可以包含正面的连接或负面的连接,value是与此pattern相关的附加贡献。
例6 给定一个联盟博弈 Γ =<N,v>,其中N={a1,a2,···,a5},v({a1,a2})=v({a2,a3})=v({a1,a3})=2;∃i∈ { 1,2,···,5},v({ai})=0;v({a1,a2,a3})=5;∃C ⊆ { a1,a2,a3} , v(C∪{a4})=v(C∪{a5})=v(C)=v(C∪{a4,a5});根据边际贡献网,给定规则为

h≥0 Γ=<N,v>v D σ= < D,S,α,β,x,y> (Γ,σ)
定理5 令 是一个固定自然数,是一个博弈,其中 是独立于不相交成员的评估函数,交互图 所构成的树的高大于h。令,则 的联盟结构生成的值可以在多项式时间内解决。
约束满足问题具有较强的灵活性,能够进行推广解决文献[32]中提到的约束问题。
7 结束语
联盟结构生成问题中如何能够更快更精确地进行优化整体性能对于研究人员一直都是挑战。本文针对这一问题进行了全面的综述:1)搜索空间的不同表示;2)动态规划算法的时候来解决这个问题;3)使用近似最优来代替最优解;4)使用评估的方法,主要是添加了约束条件。所有的这些结构都是以一种独立的方式展示出来的。
但是,在现有联盟生成的研究中,大多数是以Agent之间具有相同的协商资源和态度为前提的,只考虑了协商中的相同性,却忽略了协商中的异质性。在未来的工作中,可以考虑将协商的异质性与约束联盟中的评估结构相结合。
同时,在约束K-means聚类算法的启发下,可以将一般形式的无法连接的约束进行合理操作后有理性地加入到评估结构中。另外,可以进行扩展,将允许联盟生成的概率使用先验知识进行检验或者将Agent之间的动态相互信任添加到联盟生成的过程中。
