旅游知识图谱特征学习的景点推荐
2019-05-22贾中浩古天龙宾辰忠常亮张伟涛朱桂明
贾中浩,古天龙,宾辰忠,常亮,张伟涛,朱桂明
(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004)
科技的进步在给人们的生活带来便利的同时,也给人们带来了选择的困扰——如何在庞大而繁琐的知识中获取有价值的信息。推荐系统的出现为解决信息过载问题提供了一条有效途径[1]。但随着大数据时代的到来,传统推荐系统在挖掘数据价值上存在的问题正在限制其性能发挥[2]。传统的推荐方法已经得到广泛的应用,但依旧存在许多问题,如项目冷启动和数据稀疏问题[3-4]。知识图谱[5]的提出为解决大数据下推荐系统的复杂问题带来了技术革新。
利用知识图谱解决推荐问题的技术核心在于如何从丰富的异构数据中有效地建立用户项目之间的相关性。因此,如何更精准地从网络图中对节点间复杂关系建模是基于知识图谱做推荐的一个技术难点。Node2Vec[6]作为一种有效的网络嵌入方法,将灵活的随机游走策略与神经网络模型相结合。但这种方法并不适用于知识图谱,它处理的是一种无标签的网络图。知识图谱是一种特殊的带标签(属性)的图,不同的标签对节点的影响力不同。扩展Node2Vec使其适用于知识图谱的特征学习,通过将知识图谱分割为独立的属性子图,同一标签将在同一个子图中,进而对特定属性的子图独立训练,从而达到区分知识图谱中标签的目的。基于此得到融合各个属性语义的用户和项目的特征向量,最后通过计算用户项目相关性得到推荐列表。
本文提出了一种利用多源公开数据进行旅游知识图谱的构建方法,提出了一种利用景点具有多个属性来构建其属性子图的知识图谱,利用一种随机游走策略对知识图谱(属性子图)进行节点序列的生成,利用一种深度学习模型进行图节点语义的挖掘学习,提出了一种基于游客景点相关性的评分预测算法及其评价方法。
1 相关工作
随着信息科学的发展,互联网平台上的数据呈现爆发式增长,以知识图谱为代表的数据组织模式开始受到工业界和学术界的广泛关注。据估计,Google的知识图谱可以理解超过5亿个实体以及35亿个属性和关系。国内百度、搜狗、阿里等都在自己庞大的数据基础之上构建各自的知识图谱,如百度知心、搜狗知立方以及阿里基于商品及卖家信息构建的商品知识图谱等。由此可见,知识图谱正在引发一场新的技术革命。
1.1 知识图谱
知识图谱的概念由谷歌公司于2012年提出[5]。知识图谱旨在描述真实世界中存在的各种实体或概念,以及它们之间的关联关系[7]。其中,每个实体或概念用一个全局唯一的ID来标识,每个属性-键值对刻画了实体的内在属性,而关系用来连接两个实体,刻画它们之间的关联。依据其覆盖范围,知识图谱可以分为通用知识图谱和专业知识图谱。通用知识图谱注重广度,强调融合更多的实体信息,相较于专业知识图谱,其准确度不够高,典型的如YAGO、DBpedia、Google知识图谱等。通用知识图谱主要应用于智能搜索领域。专业知识图谱描述的目标是特定行业,通常需要依赖特定行业的数据来构建,具有特定的行业意义,与通用知识图谱相比较其描述范围有限,典型的如电影知识库(internet movie database, IMDB)[8]、音乐知识库MusicBrainz[9]等。
在本文工作中,知识图谱用一种由三元组以及三元组之间相互的链接形成的一个网状知识库来表示。这种三元组富含实体以及实体的属性信息。其中节点表示实体,边表示实体之间的关系。以旅游领域为示例,景点实体中主要包含景点等级、价格、适宜游玩时间等主要特征,这些特征总体上可以描述一个景点,利用景点的特征可以得到类似图1所示的一个旅游知识图谱三元组。

图 1 知识图谱三元组Fig. 1 Knowledge graph triple
1.2 基于知识图谱的推荐算法
在知识图谱提出后,有相关学者将知识图谱应用于推荐领域并取得了较好的效果。Passant等[10]较早地提出将知识图谱引入到推荐系统中。Oramas 等[11]也引入了开放链接数据库DBpedia,通过DBpedia丰富历史数据集的语义信息,从而提升推荐效果。OstuniV等[12]更进一步融合开放链接数据库中隐含的语义反馈信息,提出基于隐式语义反馈的路径算法(SPrank),基于路径的特征对数据集进行挖掘,以捕获项目之间的复杂关系。Piao等[13]在文献[11]的基础上提出改进的链接数据语义相似距离,同时兼顾了节点之间的距离和路径,更加充分地反映数据的语义信息。
1.3 网络图特征学习
知识图谱解决推荐问题的核心在于如何精准地对知识图谱进行特征学习。最近,网络嵌入方法[14]被用于图的特征学习,并被证明是一种有效的图特征学习方法。Perozzi[15]最早提出Deep-Walk,并利用它来对网络图进行特征学习。Deep-Walk是以随机的方式在网络图中游走,生成网络图中节点的序列,用生成的序列集合作为训练集来学习网络图中节点的特征。Tu等[16]对Deep-Walk的随机游走过程进行了改进,在随机游走的过程中跳过无关的节点,从而更精准地对网络图中的节点进行表示。Grover等[6]针对网络图节点序列的生成提出一种带偏执的随机游走算法,通过设置两个参数p、q来控制游走过程,当p、q都等于1的时候相当于DeepWalk,q不等于1的时候在深度优先和广度优先之间取得均衡,实验表明,带偏执的随机游走相比于传统的DeepWalk有更好的性能,更加适用于网络图的特征学习。
2 旅游知识图谱的构建
2.1 数据采集
本研究从旅游垂直网站携程网以及百科类网站(百度百科、互动百科、wikidata)上以桂林市为例抓取桂林周边旅游景点信息及游客评分信息。共采集到395个景点、12 398名游客、28 477条景点评分记录以及百科网站中对景点的描述信息。表1为采集信息的样本示例,如第一行表示漓江景区相关信息包括:景点地址、地理位置、景点等级、平均评分、景点类型、适宜游玩时间以及门票价格等。

表 1 数据采集示例Table 1 Example of data collection
2.2 构建知识图谱
对采集到的信息进行预处理:删除重复的游客评分记录;选择游客对景点最近的评分作为该游客对该景点的评分;选择景点等级、地理位置、平均评分、景点类型、适宜游玩时间,门票价格等6个属性作为景点的特征;标记评分大于3分的游客与景点之间为喜爱关系;通过数据库工具对采集到的数据进行实体对齐(如桂林市和桂林表示同一个实体)。
通过预处理后的信息构建旅游知识图谱的模式图,包含景点、游客的相关属性以及游客和景点之间的喜爱关系,如图2所示。

图 2 模式图示例Fig. 2 Example of a pattern diagram
利用预处理后的数据及设计好的模式图构建旅游知识图谱。旅游知识图谱最终包含383个景点、3 940名游客、19 724条评分记录以及各个景点的6个属性共计22 994个三元组。图3为旅游知识图谱存储于Neo4j中的部分景点、游客及其属性所构成的网络结构。

图 3 旅游知识图谱示例Fig. 3 Example of travel knowledge graph
3 基于知识图谱特征学习的景点推荐
基于知识图谱特征学习的景点推荐基本思想是:针对景点具有多个属性,构建属性子图[17]的知识图谱。这样做的好处是不同属性的子图具有不同的语义值。就景点而言,不同的景点可能有相同的等级,但类型或者适宜去游玩的季节可能不一样,如果处理整个知识图谱则完全忽略了景点不同属性的语义。将景点适宜去游玩的季节也考虑进来作为属性子图,因为它提供了丰富的分类。例如漓江可以夏季游玩,但冬季去游玩漓江显然不符合常理。
Node2Vec可以把结构相似和属性值相同的节点聚集在一起的性质,通过带偏执的随机游走策略对旅游知识图谱中每种属性子图进行节点序列生成,将生成的节点序列输入到一个神经网络模型Word2Vec[18]中,对节点序列建模并将其映射到低维空间,得到每个景点在特定属性空间下的特征向量表示,具有相似结构和相同属性的节点的语义值更加相似。
通过知识图谱子图游走训练得到同一节点在不同属性子图中的特征向量表示后,对其6个子图属性特征向量相加并平均,得到融合各个属性语义的所有景点和游客节点的特征向量,该融合向量所表示的语义信息更加全面。利用余弦相似度计算游客与景点相关性分数,将相关性分数归一化处理后得到景点预测评分及推荐列表。图4为推荐流程图。
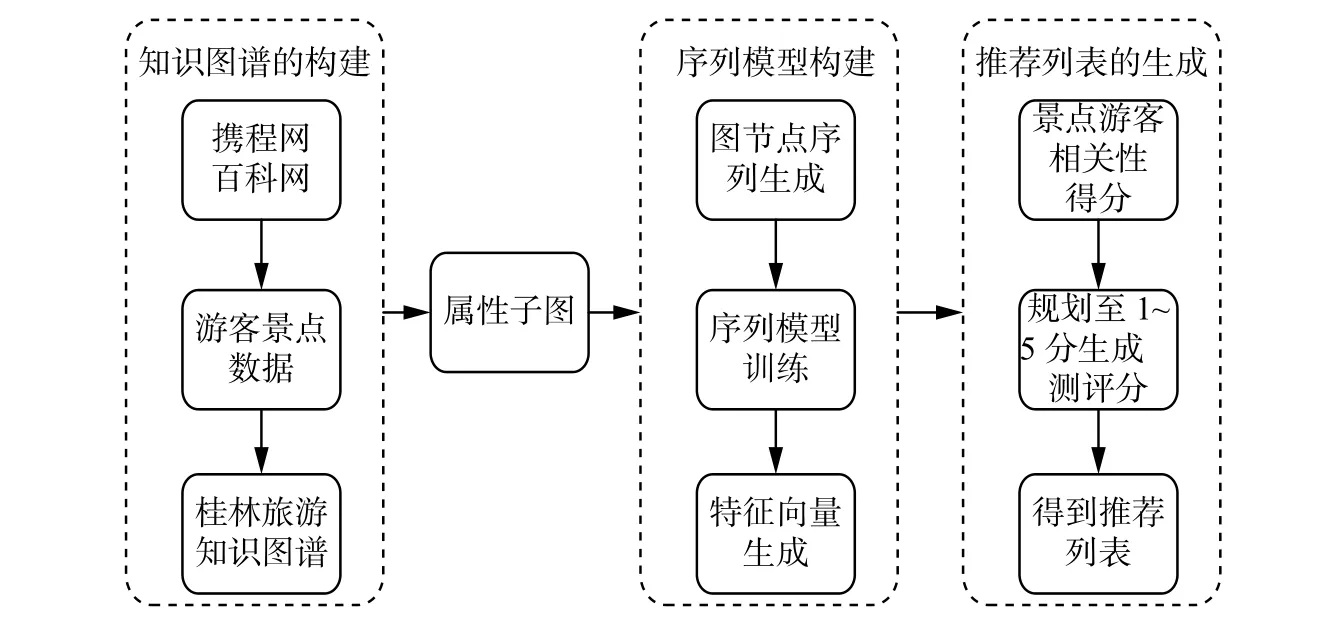
图 4 基于知识图谱特征学习的景点推荐流程Fig. 4 Flowchart of attraction recommendation flowchart based on knowledge graph feature learning
3.1 图节点的序列生成
构建好的旅游知识图谱通过SPARQL语句分割存储为7个独立的子图。针对每个子图通过带偏执的随机游走策略生成相应节点序列S ={u1,u2,···,un}。 对于一个给定的源节点 u ,模拟一个固定长度 L 的 随机游走, uj表示游走过程中第j个节点,初始节点 u0= u 。 节点 uj由 概率分布生成,即式中:D表示知识图谱中边的集合, πvx是节点v和x之间的转移概率,Z是一个正则化参数,本文的实验中 Z = 1。如图5所示:随机游走遍历了边 (v , x ), 并 停留在节点v。通过计算边 (v , x )上的转移概率πvx来判断序列中的下一个节点。计算公式为


式中: wvx是边上的权重(没有权重时默认为1);αpq(t,x)表示节点之间的边上的偏执,计算公式为

式中: dtx∈(0,1,2),表示节点t和x之间的最小跳数。如图5所示, dtx=0表示x就是t本身;dtx=1表 示 x 为x1或者 x3; dtx=2表示x为 x2,p和q是两个监督随机游走的参数。
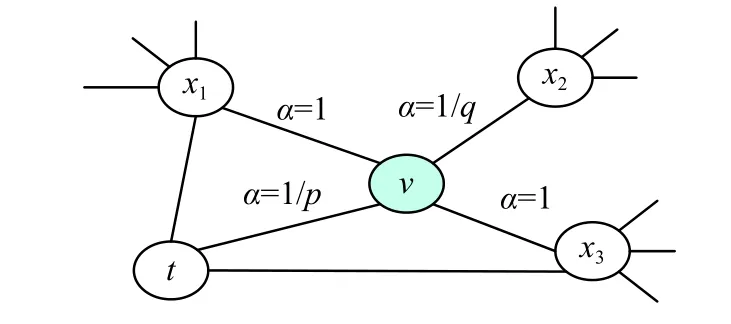
图 5 随机游走示例Fig. 5 Example of random walk
参数p可以控制重新访问当前节点的可能性。将p设置为较大的值( p >max(q,1))可以确保在后续采样过程中不会对已经访问的节点进行采样(除非下一个节点没有其他的邻居节点)。如果将p设置为较小的值( p <max(q,1)),算法将会回退一步,这将使得采样的节点靠近初始结点t。
参数q允许在当前节点周围或者远离当前节点采样。如果q>1,随机游走采样的序列将靠近节点t,这样随机游走采集到的节点序列和广度优先类似。相反,如果q<1,随机游走采样的节点将逐渐远离节点t,这样采集到的节点序列和深度优先类似。通过设置合适的参数q可以使得采样在深度优先和广度优先之间达到平衡。当p=q=1时,相当于传统的DeepWalk。
3.2 节点序列特征学习
3.2.1 特征学习模型

4.1节已经生成7个独立子图的节点序列。以一个子图的节点序列为例, S ={u1,u2,···,un},将Word2Vec模型扩展为基于图节点序列数据,由3层神经网络构建的节点序列表示模型,其网络结构如图6所示。基于神经网络语言模型的目标函数通常取为对数似然函数,见式(4):式中:N表示当前序列中节点的个数; xuj表示一个特征向量,由目标节点 uj的 上下文节点组成。的每一维都表示特定的上下文节点。简单的来说,假设 xuj是 一个非负的向量,其中每一项都表示相应上下文中一个节点的出现次数。在形式上,用d维向量 vf∈Rd为序列中每一个节点建模。定义第f个上下文节点特征为一个d维向量vf∈Rd。
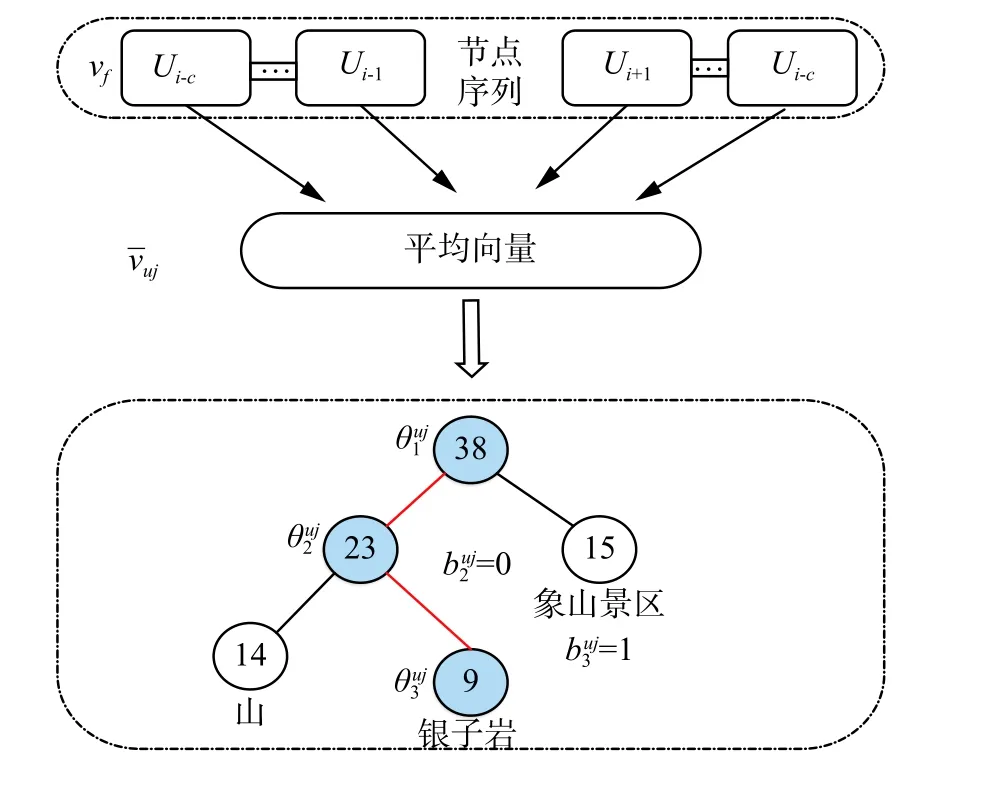
图 6 序列模型网络结构Fig. 6 Sequence model network structure diagram
选取序列集合中节点的前后2c个位置节点作为训练样本举例:
输入层:包含序列中2c个位置的随机初始化向量序列。
投影层:将输入层的2c个向量进行求和平均,得到投影层向量。
输出层:其结果为一颗完全二叉树,是由序列集合中出现过的节点作为叶子节点,以各个节点在序列集合中出现的次数作为权值所构造的Huffman树。树中每条分支均可作为一次二分类,建树即为多个二分类拟合多分类的过程。此处将非叶子节点的左子节点划分为负例,即编码为j=0 ; 右子节点为正例,编码为。该树的叶子节点共有N个,每个叶子结点即为节点的特征向量;非叶子节点共有N-1个,同为归一化形式,但是其本身不具有任何语义含义。
3.2.2 参数估计与求解优化
通过实例化式(1)中的上下文节点特征向量,在生成的各个特定属性节点序列集合中定义目标函数,即
得到目标函数需要对其进行参数学习和优化。在序列模型中,参数的学习是为了更好地利用上下文节点特征向量 vf来 学习目标节点的向量vu。一般情况下通过最大化式(5)中的对数概率来学习参数。本文采用hierarchical softmax代替sof tmax对目标函数进行优化,这样可以简化由softmax进行优化时所带来的计算量大的问题。

更确切地说,给定一个实体 uj的 投影向量 v¯Tu,
j用 L (uj)表 示根节点到 uj节 点的路径长度,当 uj的 路径在左边的分支的第n层时=0 , 否则=1。从而可以利用hierarchical softmax定义logPr(uj|xuj)形式,即
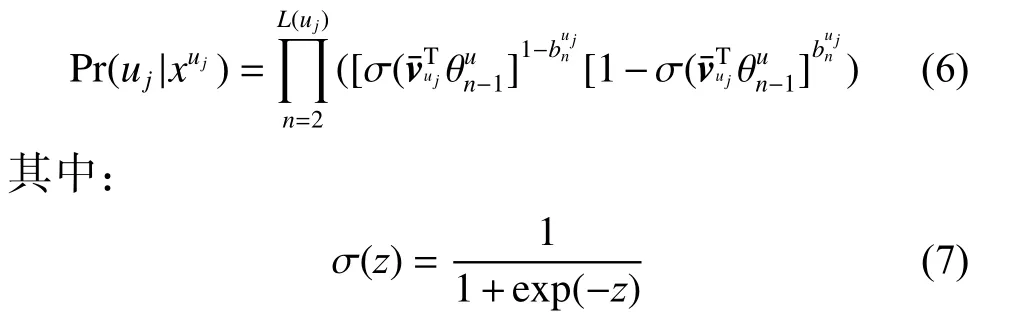
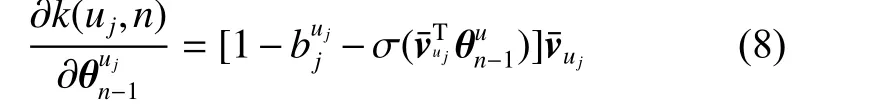

式中 µ 表示学习率,为了方便计算上下文节点特征向量的更新,¯uj的梯度表示为
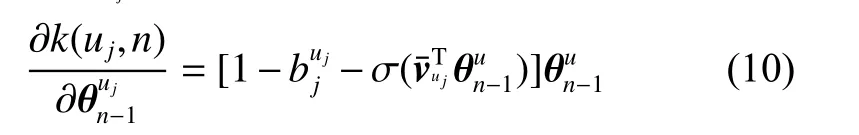
通过上述计算,节点 uj的 上下文节点特征向量可以通过式(11)更新:
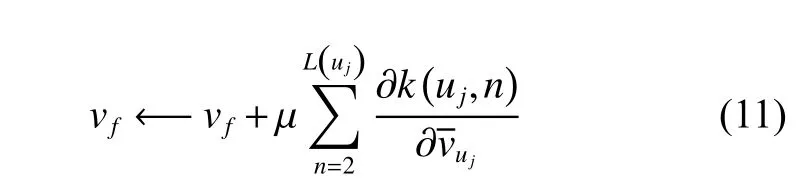
3.2.3 用户景点相关性计算
已经将知识图谱中每个属性的游客以及景点的特征映射到了同一个向量空间,因此可以对其进行加和平均,从而得到融合各个语义属性的景点向量和游客向量:

式中: v ( attract)表示包含各个属性语义的景点特征向量; m =6表示知识图谱中的景点属性的个数;v(user)表示游客的特征向量。得到同一向量空间中景点和游客的特征向量,定义游客与景点的相关性得分为
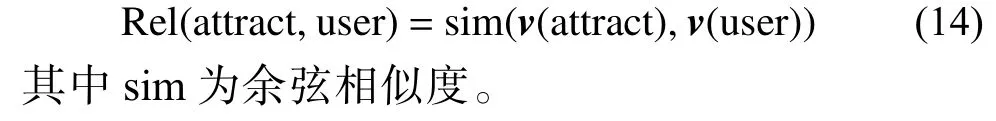
利用上述已经得到相关性的得分,通过式(15)得到用户对景点的预测评分:

4 实验结果
4.1 实验数据环境
实验环境:操作系统Ubuntu16.04,64 B,处理器Intel Core i7-6700,内存大小8 GB,编程平台Pycharm,Python2.7版本。在本次实验中,选择不同的采样次数、随机游走参数。采用交叉验证方法(cross validation)对算法进行测试,并且与传统的协同过滤算法进行了对比。其中模型训练数据包含从真实旅游知识图谱中生成的6 238条序列,序列的平均长度为2 000。
4.2 评测指标
通过采用常见的推荐系统评测指标来衡量算法的高效性:平均绝对误差、F-measure。1)平均绝对误差(mean-absolute error,MAE)。平均绝对误差是绝对误差的平均值,能够反映预测值误差的实际情况。
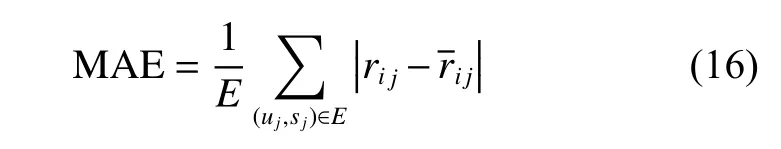
2) F-measure。
F-measure是准确率和召回率的加权平均,均匀地反应了推荐效果,数值越大越准确。

其中:
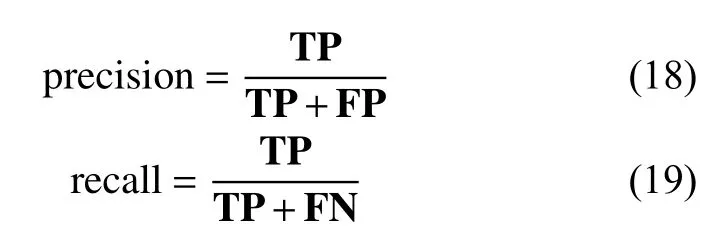
式中TP、FP、FN、TN组成的混淆矩阵如表2所示。
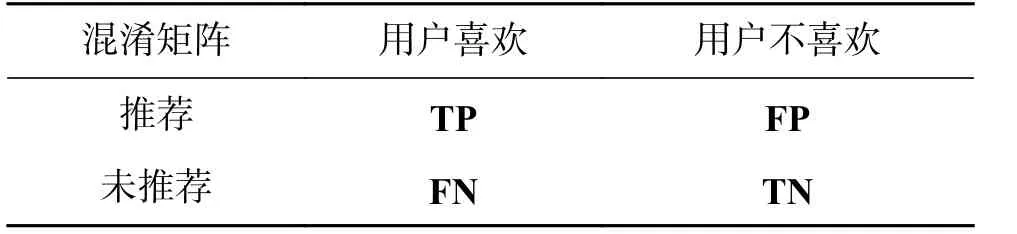
表 2 混淆矩阵Table 2 Confusion matrix
4.3 实验结果与分析
4.3.1 采样次数比较
在特征向量的学习过程中,属性节点序列集合的生成对特征向量的学习会有不同的影响。实验分别选取采样次数为100、200、300、400、500进行实验分析。
从图7和图8中可以看出,采样次数的不同,各项指标都会有所变化。在采样次数为400次的时候在各项指标上取得的效果最佳。分析结果可知:采样次数过少,对数据特征的学习不充足;采样次数过多会产生过多的冗余信息,导致实验结果不准确。采样次数为400次时效果最好,因为在实验中景点节点有383个。
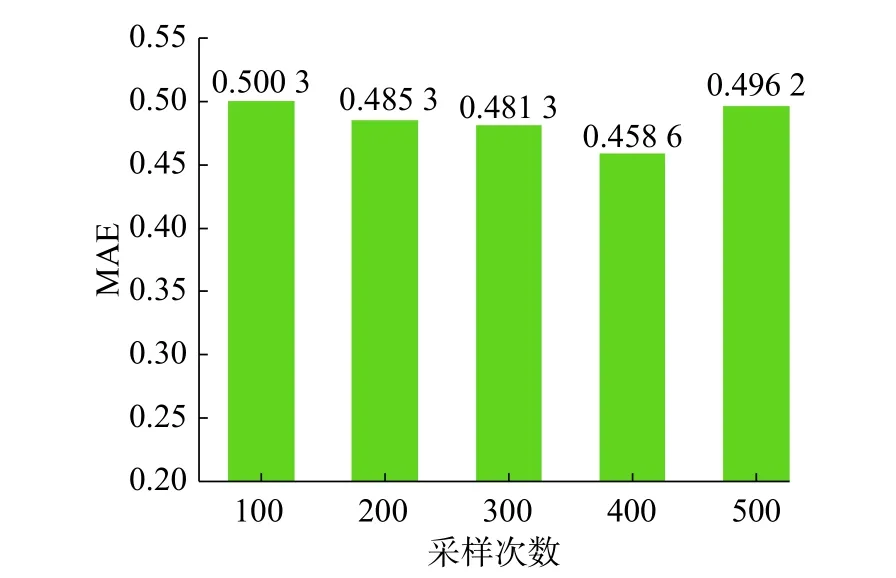
图 7 不同采样次数的MAEFig. 7 Different MAE sampling times

图 8 不同采样次数的F-measureFig. 8 F-measure for different sampling times
4.3.2 随机游走参数
改变参数p、q,可以在特定属性图中采样形成不同的节点序列。节点序列的生成结果会对推荐效果产生不同的影响。选取p、q属于{0.25,0.5,1,2}进行实验分析。
从图9和10中可以看出,不同的随机游走参数的组合对训练结果影响不同,随机游走参数p、q取{0.25,0.25}时在各项指标上效果最佳。也就是说,此时带偏执的随机游走可以在广度优先和深度优先之间取得平衡,能更加全面地对知识图谱中节点的特征进行学习。
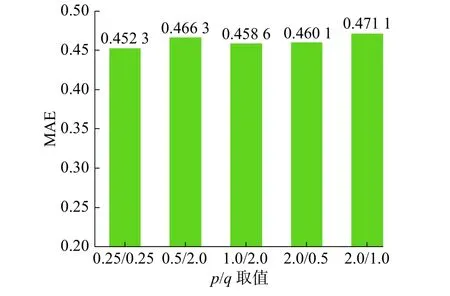
图 9 不同 p、q 的 MAEFig. 9 Different p、q MAE values
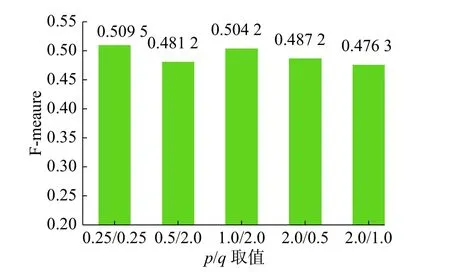
图 10 不同 p、q 的 F-measureFig. 10 Different p、q F-measures
4.3.3 算法比较
协同过滤算法的最近邻K为10、20、30、40,设置序列模型节点采样次数为100、200、300、400、500。序列模型游走偏执 p、q属于{0.25,0.5,1,2}。
从表3中可以看出,基于知识图谱特征学习的景点推荐,相较于传统的推荐算法在各项指标上均有所提升,可以在语义上弥补传统协同过滤算法的不足。分析实验结果:对于Norm-CF,在最近邻选取10~40,实验效果出现起伏,在最近邻选取为20时效果最好。对于序列模型,在选取组合参数为(400, 0.25, 0.25)时实验效果最好。也就是说,当p、q取{0.25, 0.25}时在深度优先和广度优先之间取得平衡,可以更好地学习节点的特征。
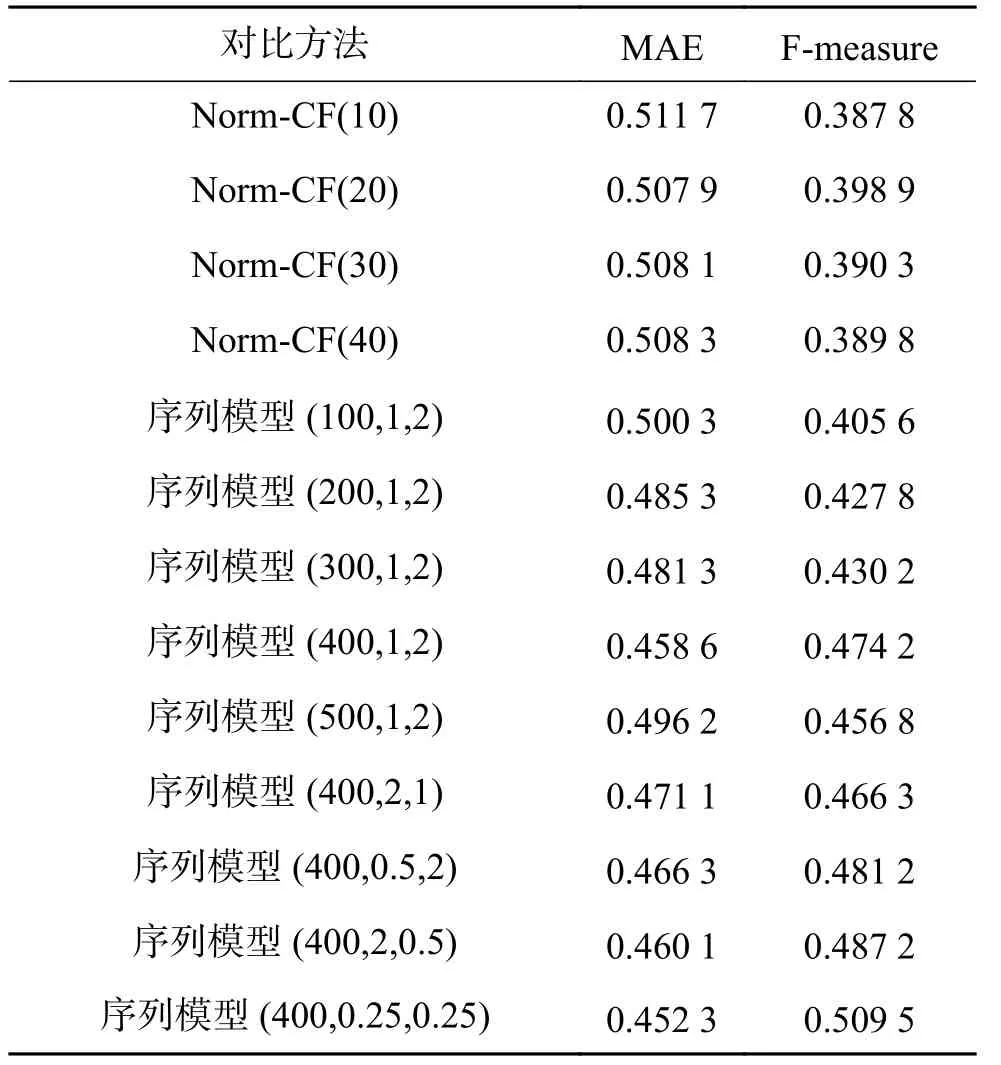
表 3 算法对比Table 3 Algorithm comparison
5 结束语
本文基于知识图谱子图特征学习的景点推荐,用以高效地挖掘知识图谱中实体特征,从而更好地建模游客与景点的相关性。本文所提出的基于标准系统对其他推荐系统也具有适用性;从携程网以及百科类网站上采集桂林周边旅游景点信息及游客评分信息,构建旅游知识图谱;利用网络嵌入方法对旅游知识图谱进行特征学习,利用余弦相似度计算游客与景点的相关性生成推荐列表;设计对比实验方案,并利用推荐系统评测指标在真实旅游知识图谱上验证效果。实验结果表明,相比于传统基于评分的协同过滤推荐算法,该方法对旅游知识图谱中游客与景点节点的特征建模更加准确,从而更加精准地作出推荐。未来将考虑利用更多的旅游信息(照片、游记以及评论信息)挖掘游客细粒度的偏好以及对景点进行更加精准的建模,以进一步提高推荐准确度。
