基于本体技术的高血压知识库平台构建*
2019-05-21杨美洁熊相超
杨美洁 张 兴 熊相超
(重庆医科大学医学信息学院 重庆 400016)
1 引言
高血压是最常见的慢性病,也是心脑血管病最主要的危险因素[1]。随着我国经济的发展和人口的老龄化,高血压患病率持续增加,高血压引起的冠心病、脑卒中等疾病的致残率、致命率高[2],在我国心脑血管疾病死亡的第1位危险因素是高血压[3]。目前我国医疗资源紧张导致看病难等问题,在人工智能、大数据时代背景下,将新兴信息技术应用到医疗服务中,使患者在家中通过网络就能得到医疗建议,缓解就医压力。
目前关于高血压本体构建和知识库平台的研究主要包括:张宇[4]等构建高血压非药物治疗知识库Web端界面,从Web获取的大量文档,利用文本分类技术以及词频(Term Frequency,TF)和文件频率(Document Frequency,DF)方法提取文档和类别特征,通过支持向量机(Support Vector Machine,SVM)方法对文档分类,最后建立本地高血压非药物治疗知识库。吴昊[5]等提出基于本体和案例推理的高血压诊疗系统的框架结构。巩沐歌[6]等将高血压疾病、知识库和本体结合起来,构建具有推理功能的高血压知识库。张巍[7]等提出基于本体和案例推理的高血压诊疗系统模型。构建高血压领域本体及推理规则,使用Jess推理机进行推理操作,使用Jena实现对本体库和案例库并行的查询。李博[8]等结合本体方法将文本临床指南转变成临床指南知识库。本文利用Python爬虫技术爬取网络高血压数据,通过本体技术和Protege工具构建高血压本体库,描述领域概念及其之间的约束和联系,将其存储在Mysql数据库中,本体构建完成后以RDF/XML形式存储,用于网络本体语言(Web Ontology Language,OWL)或规则推理。使用Jieba分词与正则化技术对用户输入的自然语言进行分词处理,Jena推理引擎返回结果,采用Python Web的Django框架进行构建前台可视化界面。
2 高血压本体库构建
2.1 构建流程
高血压知识库平台构建流程,见图1。Studer等在1998年对本体定义为本体是共享概念明确的形式化规范说明[9]。本文参照《中国高血压防治指南2017》版,结合Python爬取的高血压网络数据、相关文献图书等资料,借鉴7步法和骨架法,采用美国斯坦福大学开发的本体编辑软件Protege 5.0软件进行本体的构建[10]。主要构建高血压的症状体征、检查检验、药物等。
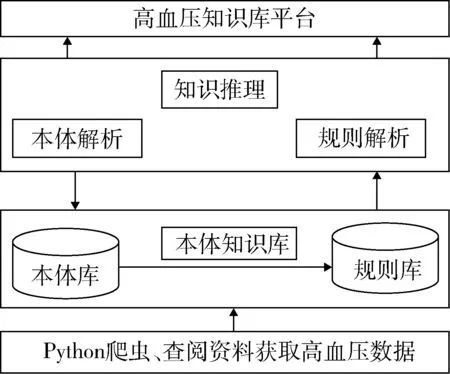
图1 高血压知识库平台构建流程
2.2 本体模型
高血压本体模型,见图2。本文构建高血压的领域本体包括症状体征、检查检验和药物。其中症状体征主要表现为:头晕、恶心、呕吐、咳嗽、心悸、尿频、四肢麻木、下肢水肿等。检验检验主要包括血压、血尿素氮、肌酐、低高密度脂蛋白、胆固醇、三酰甘油等。抗高血压药物主要包括ACE和ARB、α受体阻滞剂、β受体阻滞剂、抗高血压药物、拮抗剂、利尿剂等。利用Protege 5.0为高血压本体构建3大类,分别是检查检验、药物、症状。Protege中有两个属性定义,分别是类属性和关系属性。检查检验类属性项目、结果、单位、参考值;药物类属性:药物名、副作用;症状类属性:症状名、症状概述。构建3个类之间的关系属性完成本体的构建。本体构建完成后以RDF/XML形式存储,用于OWL或规则推理。Jena是一个开源的Java语义网框架,可构建语义网和链接数据应用。Jena利用TDB组件将上述构建的RDF形式的高血压知识本体存储起来,再通过资源描述框架定义集(Resource Description Framework Schema,RDFS)、OWL以及Jena的Rule Reasoner进行本体推理,进一步自动识别补全数据,避免数据缺失、失真等情况。最后使用Fuseki组件,通过SPARQL语言对RDF数据进行查询,实现高效的知识提取。
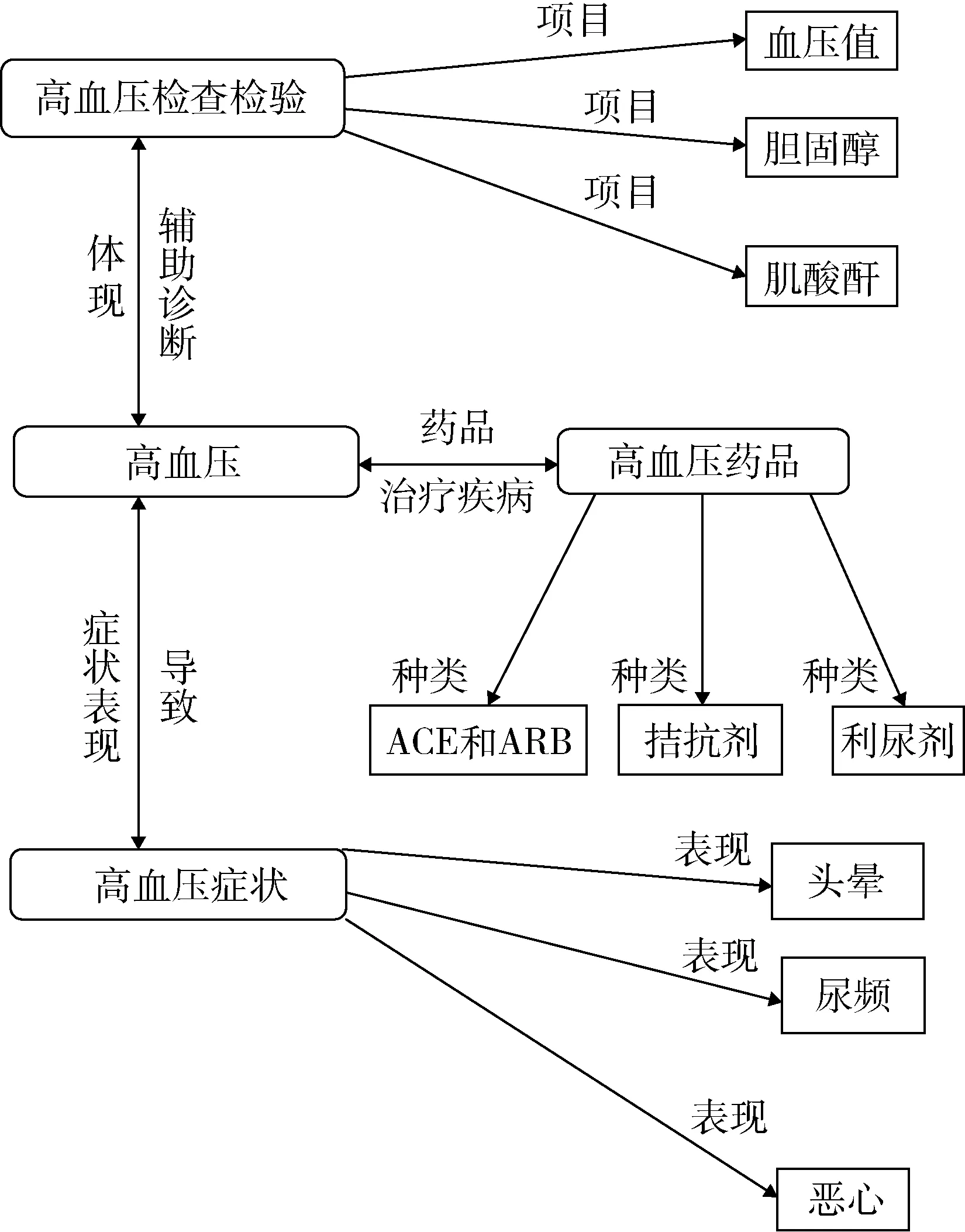
图2 高血压本体模型
3 高血压知识库Web端
3.1 概述
利用Python Web框架构建高血压知识库。通过Python的Django框架开发高血压知识库的Web端界面[11]。用户在使用Web端进行查询时需要将输入的自然语言转换成计算机识别的SPARQL语句,因此要用Python正则Refo模块、中文分词Jieba模块,实现对高血压知识中字符串及词句段切、关键字提取等,将自然语言转化为SPARQL语句,解析返回查询结果。
3.2 Jieba分词
在Python的Jieba模块中加载自定义字典可实现对自然语言较准确的分词。以输入“高血压症状体征有哪些?”为例,利用Python的Jieba模块分词的部分代码和结果如下:
# jieba自动分词
words=jieba.cut(hyper_str)
print(′---------------默认分词效果jieba---------------′)
print(′/′join(words))
# 加载自定义字典
jieba.set_dictionary(′sym.txt′)
words=jieba.cut(hyper_str)
print(″------------加载自定义字典后,分词效果----------------″)
print(′/′join(words))
------------------jieba默认分词效果----------------------
高血压/疾病症状/有/哪些/?
---------------加载自定义字典后,分词效果---------------
高血压/疾病/症状/有/哪些/?
3.3 词性标注及关键字提取
为提高检索查询结果的效果和效率,需要对自然语言进行词性标注[12]。词性标注(Part-of-Speech Tagging)是指为分词结果中每个字符串标注一个词性,避免出现汉语歧义问题,进一步提高分词效率、精确度。对上述例句进行词性标注和关键词提取的部分代码和结果如下:
##词性标注及关键字提取
print(′--------------词性标注及关键字提取--------------′)
import jieba.posseg as pseg
words=pseg.cut(hyper_str)
for word,flag in words:
print(′%s %s′%(word,flag))
--------词性标注及关键字提取结果--------
高 a
血压 n
疾病 n
症状 n
有 v
哪些
? x
3.4 正则Re及REfO
用户在Web端进行检索时会输入某些问题,本文采用正则为每个问题设定语义模板,主要使用Re和REfO两种正则模块,两者的区别是REfO适于任意序列的对象,而Re则是匹配字符串。用户在Web端进行检索时,平台首先利用Re模块将用户的问题分词处理后与Jena后端数据进行匹配,如果匹配成功则返回相应结果,否则失败。Re和REfO模块代码如下:
class W(Predicate):
def_init_(self,token=″.*″pos=″*)
# 正则表达式
self.token = re.compile(token + ″$″
self.pos = re.compile(pos+″$″
super(W,self)._init_(self.match)
def match(self,word):
m1 = self.token.match(word.token.decode(′utf-8′))
m2 = self.pos.match(word.pos)
return m1 and m2
def apply(self,sentence):
match =[]
for m in finditer(self.condition,sentece):
# m.span() 从头部匹配
i,j = m.span()
matches.extend(sentence[i:j])
return self.action(matches),self.condition_num
#规则集合
rules=[
Rule(condition_num=2,condition=disease_entity+Star(Any(),greedy=False)+zhengzhuang_keyword + Star(Any(),greedy=False),action=QuestionSet.has_zhengzhuang_question),
Rule(condition_num=2,condition=disease_entity+Star(Any(),greedy=False)+bingfazheng_keyword + Star(Any(),greedy=False),action=QuestionSet.has_bingfazheng_question),
Rule(condition_num=2,condition=disease_entity+Star(Any(),greedy=False)+yufang_keyword+Star(Any(),greedy=False),action=QuestionSet.has_yufang_question),
Rule(condition_num=2,condition=disease_entity+Star(Any(),greedy=False)+gaishu_keyword+Star(Any(),greedy=False),action=QuestionSet.has_gaishu_question),
Rule(condition_num=2,condition=disease_entity+Star(Any(), greedy=False)+zhiliao_keyword,action=QuestionSet.has_zhiiao_question),
Rule(condition_num=2,condition=Star(Any(),greedy=False)+yufang_keyword+disease_entity,action=QuestionSet.has_yufang_question),
.....
]
for rule in self.rules:
# print(rule)#
word_objects是一个列表,元素是包含词语和词语对应词性的对象query,num = rule.apply(word_objects)
最后利用Pycharm平台的Django项目来进行高血压知识库平台Web端界面的开发。利用腾讯云服务器部署LNMP环境。将所有项目数据上传,成功后启动Apache Jena Fuseki服务,在Python项目中启动manage.py,界面成功运行。
4 结语
本文利用本体技术构建高血压知识图谱,人工智能大数据技术处理自然语言,Python语言实现基于本体的高血压知识库平台开发。此平台可以辅助医生进行医疗活动,对公众进行高血压知识的普及,减缓就医难和医疗资源紧张等问题。基于本体的高血压知库平台构建为其他慢病(糖尿病等)知识库平台构建提供借鉴。后续的研究将对重庆市某医院的电子病历数据进行采集,进一步获取高血压的相关资料以对高血压本体进行完善。
