2015年中国1∶10万土地覆被数据河南地区精度评价
2019-05-21孙九林
朱 筠,孙九林,秦 奋,王 航
(1.河南大学黄河中下游数字地理技术教育部重点实验室,河南 开封 475004;2.河南大学环境与规划学院,河南 开封 475004;3.中国科学院地理科学与资源研究所,北京 100101)
1 引言
土地覆被数据是认识人类活动和全球变化之间复杂关系的关键信息源[1-2]。它可以广泛应用于气候和水文过程模型[3-5]、碳循环模型参数确定[6-7]、公共健康和生态系统评价[8-9]、自然资源或农业活动管理[10-11]等研究领域。20世纪90年代以来,学术界一直高度关注全球和区域土地利用/土地覆被变化的研究[12-16]。目前,国内外土地覆被数据产品空间分辨率在30 m~1000 m[2,17],国际上,有马里兰大学的全球土地覆被数据集UMD(1 km),美国地质调查局的全球土地覆被数据集IGBP-DISCover(1 km),波士顿大学的全球土地覆被数据集MOD12Q1(1 km),欧盟联合研究中心的全球土地覆盖数据集GLC2000(1 km),欧洲空间局的全球土地覆被数据集GlobCover 2005(300 m);在国内,有国家基础地理信息中心、中国科学院遥感应用研究所、国家气候中心等单位共同研制的全球土地覆被数据集GlobeLand30(30 m),清华大学2013年研发的全球土地覆被数据集FROM-GLC(30 m),国家科技基础条件平台——国家地球系统科学数据共享平台牵头完成的2015年中国1∶10万土地覆被数据产品。
以上土地覆被数据产品都以遥感影像作为数据源,受空间分辨率、光谱分辨率、地物特性等影响,影像质量具有不确定性,分类结果与地面实际情况也有不完全一致性,这些因素都影响土地覆被数据产品的精度,因此,土地覆被数据产品的精度评价是一项十分重要的工作[17-20]。研究表明,多数常用的全球1 km土地覆被数据集在中国区域的总体分类精度较低[17,21],对于较高分辨率土地覆被数据产品,精度评价方法不同,分类精度也不完全一致。因此,研究一种合理的土地覆被数据产品精度评价方法,科学界定土地覆被数据产品精度,对于土地覆被数据产品的应用具有重要意义。
2016年国家地球系统科学数据共享平台发布了国内首套“2015年中国1∶10万土地覆被数据产品”,这是国际上首套反映近5年来中国地表覆盖动态变化且精度较高的土地覆被数据产品,其数据精度还有待进行更为详细的检验和评价。
2 数据与方法
2.1 研究区概况
河南省位于中国中东部、黄河中下游(110°21′E~116°39′E、31°23′N~36°22′N),全省土地总面积约16.7万km2,占全国土地面积的1.73%。河南省地处北亚热带与暖温带两个气候带,境内秦岭东延部分伏牛山主脉与淮河干流构成两个生物气候带的分界线,南北各地气候显著不同,山地和平原气候也有显著差异;横跨中国第二、第三两级地貌阶梯,地貌类型多样;自北向南横跨海河、黄河、淮河、长江4大水系,境内有1500多条主干河流纵横交错;土壤类型多样,西部和南部山地主要为棕壤、褐土和黄棕壤,东部平原主要为潮土和砂礓黑土, 还有少量盐碱土、草甸土等;植被类型复杂多样,分布有常绿针叶林、常绿阔叶林、落叶阔叶林等。河南省地域辽阔,加之地形、气候、植被等分异因素,土地覆被类型丰富,是研究中国土地覆被数据产品的典型地区。
2.2 数据来源
2015年中国1∶10万土地覆被数据产品由国家地球系统科学数据共享平台研制,并于2016年底面向中国科学领域发布。该数据集的研发,在已有国内外土地覆被分类系统的基础上,针对中国土地覆被实际情况,从遥感制图角度和陆地生态系统观点出发,建立一种新的土地覆被分类体系,包括一级地类7类,二级地类28类,并对每一种土地覆被类型二级类分别进行编码、定义,以及主要特征和空间分布的描述(表1)。以2015年Landsat8 OLI多光谱数据为主要数据源(选用2014年9月—2015年10月各期高质量遥感数据,云量控制在10%以内),辅以高空间分辨率影像和其他参考数据,包括Google earth影像数据、无人机影像数据、MODIS时间序列数据,中国植被区划数据、DEM数据等。通过野外考察建立分区域分类别的样点解译标志辞典,采用面向对象自动分类和人工目视解译两种分类方法生产全国1∶10万土地覆被数据集,其中,河南地区数据基于ArcGIS软件平台人工目视解译获得。
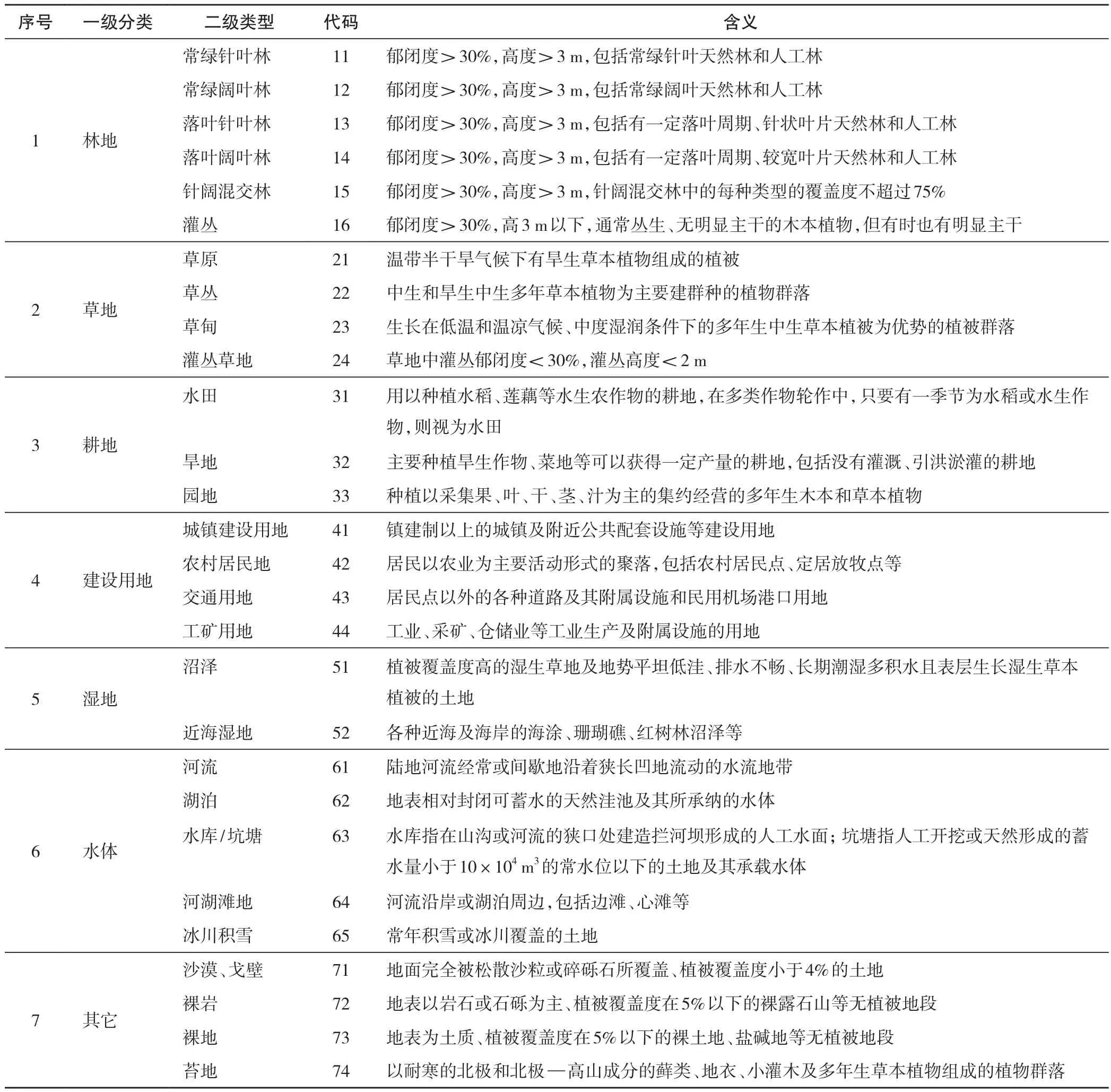
表1 2015年全国土地覆被分类体系Tab.1 China land cover classi fi cation system in 2015
根据研究区地理环境本底状况,按照《2015年全国土地覆被分类体系》,河南省土地覆被类型除去落叶针叶林、草原、沼泽、近海湿地、湖泊、冰川积雪、沙漠/戈壁,以及苔地8个地物类型,共包含6个一级地类,20个二级地类(图1)。
2.3 样本设计方法
目前,常用的土地覆被数据精度评价方法主要有两种,一是利用已有的土地覆被数据进行比较分析的间接评价法,二是利用验证样本计算土地覆被数据精度的直接评价法。前者通过多个数据集的对比研究,分析数据集间的空间一致性和面积一致性,从而得到数据的相对精度[22],该方法成本低、速度快,但由于不同的土地覆被数据使用的数据源、分类体系、分类方法等的不同,可比性受到限制[12],且精度评价结果受参考数据精度影响较大;后者通过野外实地考察,或从中高分辨率遥感影像中采集一定数量的土地覆被样本,与数据集的像元类型进行对比,建立混淆矩阵或评价模型,从而计算出数据集精度[23],此评价方法得到的验证结果不依赖于其他土地覆被数据集精度,更具客观性,但样本获取成本高,且样本数量、样本质量和抽样设计是制约评价结果客观性的重要因素[22]。

图1 2015年河南地区1∶10万土地覆被数据Fig.1 The 1∶100 000 land cover data of Henan Province in 2015
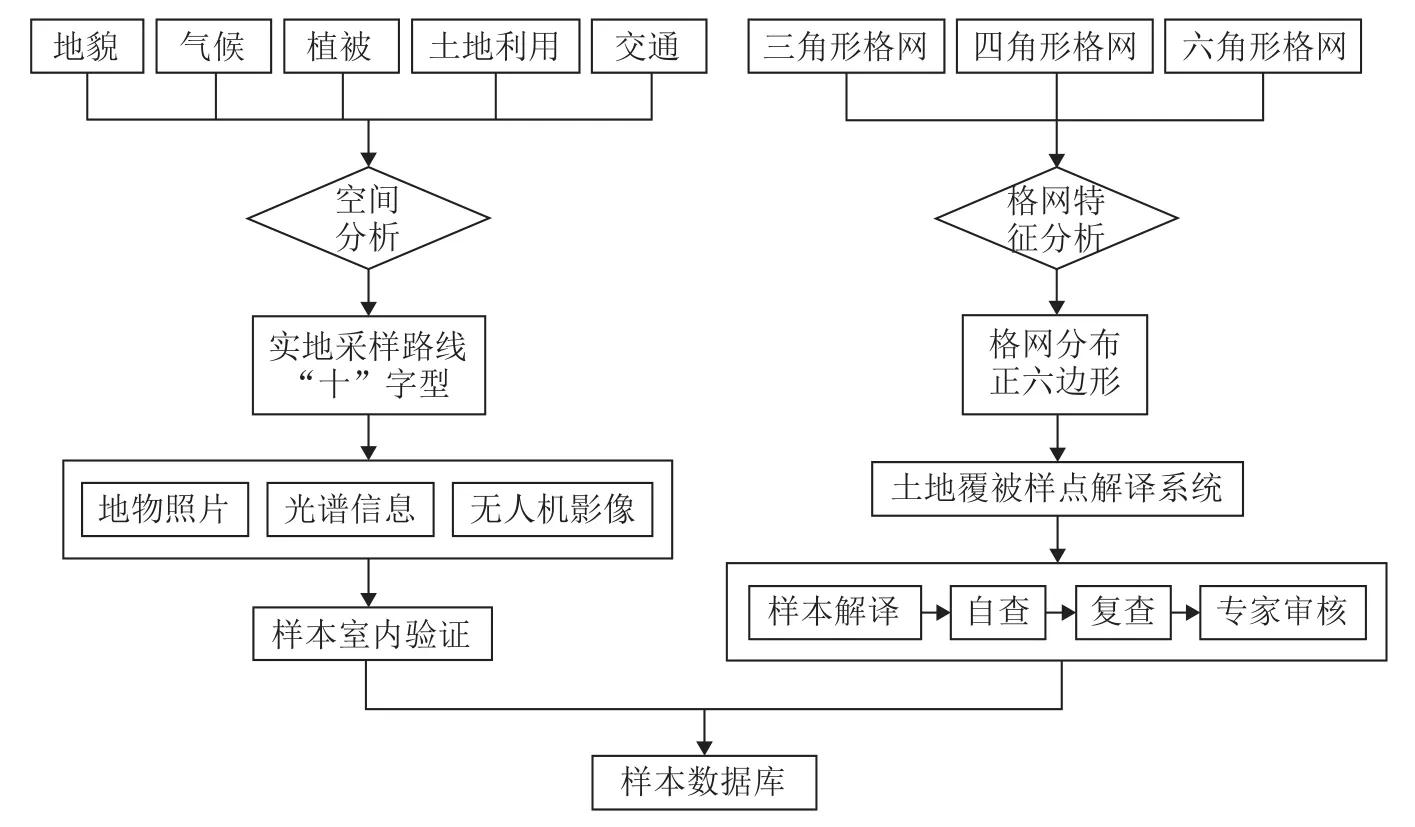
图2 样本设计方法Fig.2 The method of sample design
本文采用样本评价方法,考虑野外实地验证样本的真实性、客观性,部分样本来自实地采样,但由于采样成本、可达性、时间等因素的限制,无法进行区域全覆盖野外采样,因此,采取一种野外实地采样与格网采样融合的区域全覆盖样本设计方法(图2),既能更大程度地保证样本质量,又能保证样本分布的密度。
2.3.1 实地采样设计与样本采集
野外实地采样综合分析河南省地貌、气候、植被分异等生态环境特征,土地利用类型分布特征,交通可达性特征,采样路线设定为从北向南、由东向西跨越地貌阶梯、气候带的 “十”字型线路。共获取2015年1月、8月、11月3次实地采样结果,考察覆盖中东部平原、南部山区、西部山区以及北部山区和平原等河南省大部分区域,每个采样点的土地覆被调查面积不小于500 m×500 m,采集了样本所在位置的地物照片、光谱信息、无人机影像等信息,对样本进行室内高分影像对比验证,形成271个实地样本点数据(图3)。
2.3.2 格网样本设计与样点解译
格网样本的采样设计基于多面体剖分的全球离散格网系统,选取斯奈德等面积二十面体格网,格网单元不仅等面积,且当投影到一个二十面体时,它们是六边形;在三角形、四边形、六边形3种常见的能够进行规则化空间剖分的几何格网图形中,六边形是最紧凑的一种,它具有各向同性、邻域一致、角分辨率大等特性[24,25],目前,这种采样方法已应用于全球环境变化与监测领域[2,26-28]。研究采用全球离散格网软件生成全球等面积正六边形格网,每个正六边形面积约为96 km2,整个研究区被分割成约1900个正六边形格网,剔除271个实地采样点所在的格网,剩余每个正六边形生成一个中心点作为样本点,共1623个格网样本(图3)。

图3 样本空间分布图Fig.3 The spatial distribution of samples
研究中样本数据库共包含1894个验证样本,通过对一级地类样本点个数百分比和地类面积百分比进行相关分析(表2),得出相关系数为0.99,可见样本点地物类型分配符合研究区土地覆被类型面积比例。
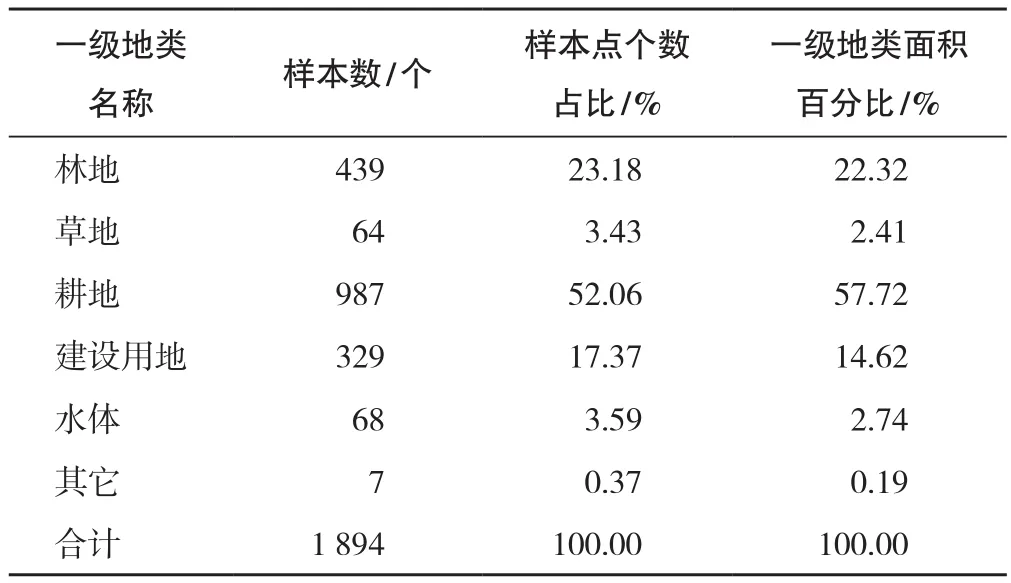
表2 一级地类样本个数占比和面积占比Tab.2 The proportion of sample number and the area of level 1 class
格网样本解译利用国家地球系统科学数据共享平台——土地覆被样点解译系统(http: //159.226.111.26:58080/),本系统充分利用多源信息,整合多时期、多时相的Landsat影像、Bing Maps高分影像、MODIS时间序列数据,通过时空匹配在影像上自动提取样本点,并生成NDVI时间序列曲线,辅助解译人员快速完成样本点位置不同时期土地覆被类型解译的同时,大大提高了样本点解译的准确度。样点解译和质量控制过程采用三轮核查方式,先由2人初步解译出样点土地覆被类型,并对样点解译结果进行自查,再由1名技术人员复查,最后,由1名解译经验丰富的专家对样点类型进行最终审核。最终,对样本进行质量评价,评价结果显示样本精度达到100%,可用于土地覆被数据精度评价。
2.4 评价方法
混淆矩阵被广泛应用于遥感分类数据精度评价,是土地覆被数据精度评价重要的方法[2,20,23],它是反映地表观测或参考数据与分类结果关系的一张简单纵横列表,为精度评价提供一个明显的基础[17,29],用来计算Kappa系数、总体精度以及制图精度等评价信息。式(1)—式(3)中:N是真实参考像元总数;n为混淆矩阵中总列数(即总类别数);Xkk表示k类中正确分类的像元数量;Xk+表示k类中真实参考像元数量;X+k为k类中被分类像元数量。

3 结果分析
3.1 混淆矩阵分析
利用验证样本建立研究区土地覆被数据一级地类混淆矩阵,计算得出耕地、建设用地、水体、林地一级地类制图精度都在90%以上;草地制图精度84.68%,其它地类制图精度85.7%;从二级地类混淆矩阵计算得到该数据产品在研究区内二级地类总体精度达到91.34%,Kappa系数为0.88。
由图4可以看出,所有土地覆被二级地类中,旱地、城镇建设用地、农村居民地、交通用地、河流、水库/坑塘、裸岩制图精度达到90%以上;常绿针叶林、落叶阔叶林、针阔混交林、草丛、水田、园地、工矿用地制图精度在80%以上;灌丛、灌丛草地、河湖滩地、裸土4个地类精度稍低,在75%左右;常绿阔叶林、草甸2个地类精度最低,均为66.67%。
(1)建设用地。建设用地包括城镇建设用地、农村居民地、交通用地、工矿用地4种类型,解译过程中参考中国1:10万基础地理数据(2012年)中居民点图层,加之建设用地在Landsat影像上光谱特征明显,相对容易判读,因此,建设用地解译精度较高。建设用地中精度最低的一类是工矿用地,制图精度为85.29%,共有5个样点被误分,包括3个分布在城镇建设用地和1个农村居民地中的工矿用地样点漏分,1个尾矿样点被误分成了裸地。农村居民地精度为90.26%,略低于城镇建设用地和交通用地,从混淆矩阵可以看出,该类样点中有6.15%被误分为城镇建设用地,这些误分样点所在斑块的共同特点是面积较大,容易划分为城镇建设用地。
(2)耕地。水田、旱地、园地3个二级地类中,旱地制图精度超过90%,水田和园地制图精度分别为84.62%和88.89%,主要是因为11.11%的水田错分成旱地,从空间分布看,表现在淮河北部平原部分水田被误分成旱地,南部山区交错在林地中的少部分水田漏分;平原地区多数园地分布在旱地周边,或与旱地交错种植,人工目视解译过程中容易出现园地漏分现象,导致11.11%的园地被误分为旱地。
(3)水体。河流和水库/坑塘2类精度比较高,但河湖滩地多与其他土地覆被类型的界限比较模糊,分类精度仅为75%,从混淆矩阵可以看出,6个河湖滩地样点中有2个被错分,其中,1个样点被误分为旱地,1个样点被误分为裸地。
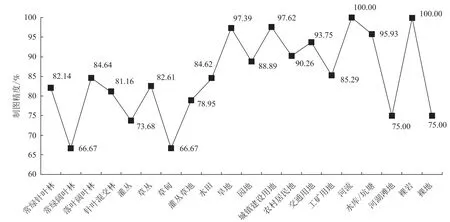
图4 二级地类制图精度Fig.4 The producer’s accuracy of level 2 class
(4)林地。林地的分类误差主要表现在:8个常绿针叶林样点被误分为落叶阔叶林和针阔混交林,1个常绿阔叶林样点被误分为针阔混交林,6.83%和3.75%的落叶阔叶林样点被误分为针阔混交林和旱地,8.70%的针阔混交林样点被误分为落叶阔叶林,灌丛样点中有2个被误分为落叶阔叶林、1个被误分为针阔混交林、1个被误分灌丛草地。总体来看,针阔混交林易产生与其他林地二级地类的混分,是因为目视解译中,对于针阔混交林中的每种类型的覆盖度不超过75%的判断受主观因素影响较大;灌丛易与落叶阔叶林、针阔混交林、灌丛草地产生光谱混淆,精度较低。
(5)草地。草地在所有土地覆被中精度较低,主要由于草地3种二级地类本身,及其与林地二级地类容易产生光谱混淆。草甸是几种地类中精度最低的,因为研究区典型草甸稀少,共3个样点,其中1个错分成草丛是导致制图精度低的主要原因。
(6)其它。其它地类包含裸岩和裸地,裸岩在遥感影像上光谱特征明显,易于识别,样点没有出现错分现象;裸地精度比较低,主要是因为休耕地的光谱特征和裸地相近,3个裸地样点中有1个被误分为旱地。
3.2 地形对分类精度的影响分析
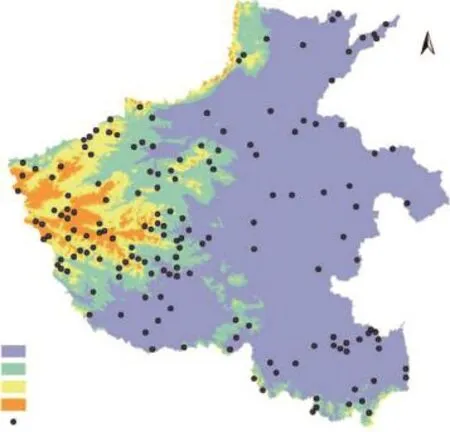
图5 研究区DEM与误分样点空间分布Fig.5 DEM and the spatial distribution of error classi fi cation samples in the study area
地形因素是影响土地利用/土地覆被的基本因素,通过研究区DEM与误分样点空间分布之间的对比(图5)发现:在海拔低于200 m的平原和盆地,误分样点的比例是5.5%(表3),该区域占研究区总面积的67.63%,土地覆被类型以耕地、建设用地、水体为主,误分地类主要体现在耕地周边林地的漏分(17.65%)、信阳北部地区水田和旱地的混淆(17.65%)及城镇建设用地和农村居民地的混淆(16.18%);在海拔200~500 m的丘陵地带,误分样点的比例为14.87%,该区域是平原向山地过度地带,地形破碎度增加,土地覆被类型交错分布、复杂度提高,判读难度增加,误分地类以林地、草地间二级地类的混淆为主(63.83%),其次是耕地与林地的混淆(14.89%);在海拔500~1 000 m的低山区,误分样点所占比例为14.29%,有林地、耕地、草地三种主要地类,主要为落叶阔叶林、针阔混交林、灌丛和灌丛草地几个地类之间的混淆(58.62%);在大于1 000 m海拔高度的豫西山地,样点所在图斑错分比例最高,为17.65%,该区域土地覆被类型以林地、草地为主,混淆地类集中体现在落叶阔叶林和针阔混交林(55.56%)、常绿针叶林和针阔混交林(22.22%)、针阔混交林和灌丛草地(11.11%)。

表3 不同海拔范围的误分样点比例Tab.3 Proportion of error classi fi cation points at different elevation
从以上对比分析看出,研究区样点所在图斑被误分的比例随海拔高度的提升呈现上升趋势,海拔在200 m以下的区域,地势平坦,地物类型复杂度低,被误分的样点比例最低。200~500 m和500~1 000 m两个海拔范围内,误分样点的比例提高且趋于一致,因为两个区域主要地物类型相似,地物类型交错区增多。在1 000 m以上的山地,虽然地物类型复杂度降低,但其主要地类林地、草地的二级地类光谱信息相似度高,造成样点所在斑块错分比例最高。
3.3 误分样点的分布模式分析
利用平均最近邻指数方法来分析误分样点的空间分布集聚特征,误分样点平均最近邻计算结果如图6所示,误分样点的平均观测距离为16.76 km,期望平均距离为16.05 km,平均最近邻指数为1.04,z值为1.07,p值为0.28,平均观测距离接近期望平均距离,z得分在-1.65~1.65之间,分布模式与随机模式没有显著差异,表明误分样点呈现随机分布的趋势。因此,研究中计算得到的土地覆被数据误差是非系统性误差,说明本文的精度评价结果可信。
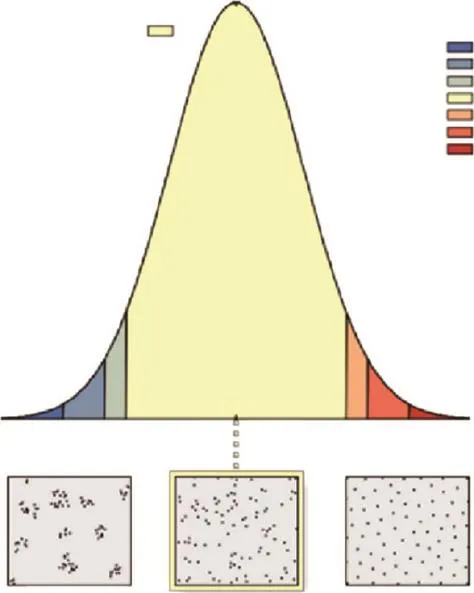
图6 误分样点平均最近邻统计结果Fig.6 Average nearest neighbor summary of error classi fi cation points
4 结论
为给2015年中国1∶10万土地覆被数据产品的用户提供科学依据,采用融合实地采样与格网采样的区域全覆盖样本对河南地区数据产品进行精度评价,结合评价结果,得到以下结论:
(1)样本设计方法可行。首先,精度验证样本库融合实地采样与格网采样结果,在野外采样的基础上,补充正六边形格网采样点,保证样本在研究区的全覆盖;其次,样点个数和地类面积百分比相关分析结果表明,样点布局合理,能够代表区域土地覆被类型;第三,样本采集和获取能够充分利用历史数据和已有数据资源,提高精度评价的工作效率和科学性。本文的样本设计方法,兼具样本典型性和分布均匀性的优势,使得精度评价结果更加客观、合理,且此方法可以推广到全国其他地区。
(2)评价区域的数据产品精度较高。通过区域全覆盖样本评价可知,数据总体精为91.34%,一级地类除草地、其他2种地类的精度在80%以上,其余5种地类精度都超过90%;二级地类中建设用地、耕地、水体除个别地类在85%左右,其余均在超过90%,林地、草地、其它3类除去研究区内少数地类,其余在80%左右。并且,通过对误分样点的空间分布集聚特征分析可知,误分样点在空间上随机分布,说明这套数据产品质量较高。
(3)从混淆矩阵分析和地形对分类精度影响的分析可以看出,对于高分辨率土地覆被遥感制图,可以从以下几方面提升制图精度:第一,耕地中平原地区的水田易与旱地混分,解译过程中引入作物物候特征,有助于区分一年中多类作物轮作的耕地类型;第二,针对林地、草地二级地类光谱特征相似,容易产生混淆问题,解译过程中除了参考植被物候信息外,可结合地形特征,尽量丰富地貌过度地带各地类的解译标志库,为解译者提供更加丰富的参考信息,从而提高解译精度;第三,针对农村居民地和城镇建设用地混分问题,随着中国城镇化进程的加快,农村人口逐渐向城镇聚集,农村居民地逐渐转变为城镇建设用地,建议土地覆被分类体系中,农村居民地合并到城镇建设用地中;第四,研究区内土地覆被分类精度随海拔提升呈现降低趋势,解译过程中,重点控制高海拔地区的数据质量有助于数据产品总体精度的提升。
综上所述,2015年中国1∶10万土地覆被数据产品在河南地区具有较高的精度,可为气候、水文、生态等相关科研领域提供基础数据。需要指出的是,采用样本评价法,特别是区域全覆盖样本评价这种直接精度评价方法对于大范围的土地覆被数据精度验证较少,实地采样点的野外采集和格网采样点的目视解译,都需要较高的成本和很大的工作量,并且样本自身质量也影响数据评价结果,在未来的研究中,在全国范围内建立一套通用的野外采样体系以及高质量格网样本库,是提高土地覆被数据精度评价科学性、可信度的重要工作,对未来持续更新的全国土地覆被数据精度评价也具有深远的意义。
致谢:感谢国家科技基础条件平台—国家地球系统科学数据共享平台提供的“土地覆被样点解译系统”(http: //159.226.111.26:58080/);感谢国家科技基础条件平台—国家地球系统科学数据共享平台—黄河下游科学数据中心(http: //henu.geodata.cn)提供数据支撑。
