语保工程的语料资源利用问题
2019-05-17范俊军
范俊军
(暨南大学 文学院,广东 广州 510632)
教育部、国家语委于2015年启动了中国语言资源保护工程(以下简称语保工程),至今已实施四年。按总体规划,语保工程将采录我国境内(含港澳台地区)约1 400个地点的汉语方言和少数民族语言样本,包括汉语方言字音、汉语方言和少数民族语言的词汇、语法例句和部分口传文化(话语),要求有书面调查笔记、数字音频视频摄录。目前已验收的多媒体语料都汇集在“家乡话”网络数据库,同时每个项目组留存各自单点数据资料,整个工程的数据量超过T级。随着语保工程将于2019年底结束,如何有效利用这些耗巨资采集的数字语料,这既是摆在管理者和语保人面前的重要任务,也是语言社群和公众的关切和期盼。
一、语保工程语料资源的效用分析
任何工程都是基于当下或未来社会需求而产生的,语保工程也不例外。教育部、国家语委《关于启动中国语言资源保护工程的通知》陈述了工程的目标:“利用现代化技术手段,收集记录汉语方言、少数民族语言和口头文化的实态语料,进行科学整理和加工,建成大规模、可持续增长的多媒体语言资源库,并开展语言资源保护研究工作,形成系统的基础性成果,进而进行深度开发应用,全面提升我国语言资源保护和利用的水平,为传承中华优秀传统文化、促进民族团结、维护国家安全服务。”[1]这也是语保工程的资源应用指针。要将这一精神贯穿工程实施过程并通过成果产品得以体现和实现,这就要求顶层设计对具体需求和应用有明确规划和描述。但从工程所发布的系列规范文件中,尚未见到工程的核心成果——资源库的应用领域和方向的陈述,也未见到关于资源主体——多媒体语料的利用和开发指针,以致有语保人和语言社群产生了“这么多语言音像资料作何用、何时才能用”的疑问。因此,对语保工程数字多媒体语料的效用进行评估,明确开发利用的方向,回应语保人和社会公众的关切和期盼,是对国家工程服务公众的必然要求。
(一)多媒体语料资源的效用评估
资源的效用是指资源的有效性和可用性。通常,资源的品质、形态、种类和数量决定它的效用。评估资源的效用就是评估资源的可用性和可用度。语保工程的主体资源是数字多媒体语料,其品质、形态、种类和数量决定了它的效用。
已有学者从不同角度论述过语言资源。这里将语言资源的范围限定在原生资源和次生资源,前者指语言社群生活交际中产出的自然口语(言语),后者指采用书面或媒体手段记录下来的言语样本;而其他资源(如语言描写、分析和研究著述等)则不属语言资源,而属于语言知识资源。数字多媒体语料属于次生语言资源。我们知道,语言产品和语言服务的效用,例如语言学习图书、音像制品、语言翻译、语言考试、语言培训等等,可通过市场运营的产值指标来评估。虽然目前未见到评估汉语方言和少数民族语言语料效用的操作案例,但我们可以采用通常的方法,从形态、种类、品质和数量四要素进行分析。
语保工程多媒体语料的形态有数字文本、音频、视频、图像以及纸质图书,种类有碎片化单个电子文件集(文档文件、音频文件、视频文件、图形文件),以及有组织结构的网络数据库(目前未见到单机版数据库),形态和种类较为完整和齐备。数字多媒体语料的品质可从质量、特性和内容三方面衡量。质量包括音频的音质、视频的画质和流畅度、图形的画质以及文本正确率。语保工程有严格和规范的质量检验制度,验收合格的语料,质量都有保证,因而下面的品质分析主要放在特性和内容两方面。
表1语保语料样本的效用分析
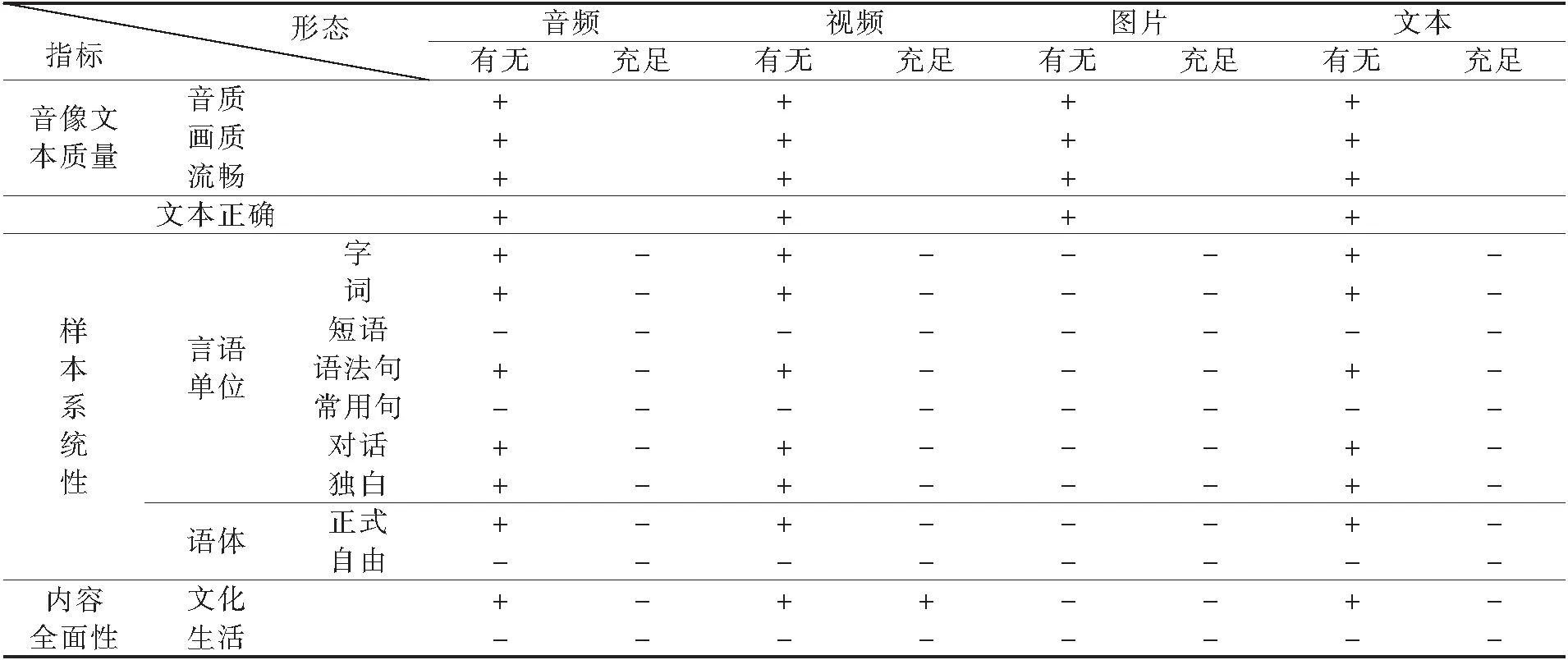
从资源保护和利用角度看,记录和保存任何语言的语料都应具有样本系统性和内容全面性。样本系统性有两方面含义:一是语料样本要体现语言结构的系统特点,包含不同结构层级的言语单位样本。例如,汉语方言应有全部音节(字)、词和短语、句子、语篇等不同层级单位的样本。二是语料样本要体现言语交际生活内容和语体风格。例如,句子不应仅有语法句型样本,还应有日常生活用句样本,而且后者是主体;语篇应有对话和独白样本,对话和独白还应有正式和非正式语体的样本。内容全面性则指言语样本的语义内容所表达的概念和知识,能较为全面地体现语言社群的社会生活,蕴含他们关于生产、生活、文化、历史、环境、技术等方面的传统知识和现代创新(包括借入)知识。
系统性和全面性是评估语保工程多媒体语料的必要条件,除此之外,还需满足充分条件,即语料样本量的充分性。例如,多媒体语料中虽有对话样本,但只有二三小段,效用就低。语料数量是否充分,决定了开发和利用的潜力空间。表1是对语保工程上交语料的效用分析。从中可知,样本质量表现好,系统性相对较好,但有个别空缺;内容全面性存在明显缺陷,充分性显得不足。
(二)语料数据模式的效度分析
除音视频样本外,语保工程的语料数据还有电子表和文档,主体数据是字、词、语法,数据模式是Excel电子表,而口传文化等话语数据是xml模式。语料数据模式关系到资源库平台构架、数据兼容和扩容、应用功能开发以及数据挖掘的可及度。由于未见到公开的资源库构架技术资料,也由于资源展示平台未开放,我们无法对资源库的使用作全面的用户体验,也无法了解资源库在多大程度和范围发挥效用,而只能基于语保工程的上交数据模板表,从数据模式角度对语料资源在资源库中的可能效用进行分析。
语保工程上交模板数据表有:方言音系表、方言字表、方言词表、方言语法(例句)表、民族语音系表、民族语词表、民族语语法(例句)表,这些都是Excel表。口头文化的数据模式是doc文件,标注软件采用ELAN标注模式(xml)。全部Excel表的字段组成如下:
1.音系表包括声母(或辅音)表、韵母(或元音)表和声调表
声母或辅音表有9个字段:编号、声母或辅音、例词1音标、例词1意译、例词2音标、例词2意译、例词3音标、例词3意译、备注。
韵母或元音表有9个字段:编号、韵母或元音、例词1音标、例词1意译、例词2音标、例词2意译、例词3音标、例词3意译、备注。
声调表有10个字段:编号、调值、调类、例词1音标、例词1意译、例词2音标、例词2意译、例词3音标、例词3意译、备注。
2.汉语方言数据表包括字音表、词汇表和语法表
汉语方言字表有15个字段:编号、调查条目、注例、音1声、音1韵、音1调、音1备注、音2声、音2韵、音2调、音2备注、音3声、音3韵、音3调、音3备注[注]将字音的音标注音分开成声母、韵母、声调3个字段,可能设计者认为这样便于声韵调的比较分析或制作声韵调分布图。实际上,计算机切分声韵调音标注音字符早已不是问题,而且已有简明算法。拙文《基于调查字表词表注音的汉藏语言音系处理系统》(语言文字应用,2012年第2期)提出了数字调值和元音字符匹配法切分声韵调的算法。笔者开发的Sonicfield v1.0 软件工具就是采用这种算法切分声韵调,在导入语保数据表时全部对原分开的声韵调字段作了合并。另外,美国(伯克利)加州大学的汉藏同源词数据库(2014年)则采用了有限状态机(Finite-state Machine,FSM)的数学模型切分声韵调字符。。
汉语方言词汇表有12个字段:编号、调查条目、注例、词1字、词1音、词1备注、词2字、词2音、词2备注、词3字、词3音、词3备注。
汉语方言语法数据表有12个字段:编号、调查条目全、注例、句1字、句1音、句1备注、句2字、句2音、句2备注、句3字、句3音、句3备注。
3.少数民族语言数据表包括词汇表和语法表
少数民族语言词汇表有9个字段:编号、调查条目、注例、词1音、词1备注、词2音、词2备注、词3音、词3备注。
少数民族语言语法表有15个字段:编号、调查条目全、注例、句1音、句1语素分析、句1直译、句1备注、句2音、句2语素分析、句2直译、句2备注、句3音、句3语素分析、句3直译、句3备注。
数据表体现了不同的数据类别,字段则描述和标识数据的属性。理论上讲,数据表越多则表明数据类别越丰富,字段越多则表明数据的属性描述越丰富,二者都利于数据挖掘。但这有个前提,数据表和字段应准确全面、避免冗余,如果数据表较多而数据类别相同或相近,字段数量多却数据性质相同,则不但不利于数据描述和数据挖掘,反而会降低数据操作效率。
语保工程的数据表(Excel表)有9种,共91个字段,其中不重名字段55个。用55个字段来描述数据的属性,对任何语料库来说都可以算得上丰富。但仔细检查字段却不难发现,许多名称不同的字段实际描述的是同一个语言学属性。
例如,音系表字段“例词1音标、例词2音标、例词3音标”,汉语方言字表字段“音1声、音1韵、音1调、音2声、音2韵、音2调、音3声、音3韵、音3调”,词汇表字段“词1音、词2音、词3音”,语法表字段“句1音、句2音、句3音”,都是描述和标识同一个语言学属性“音标注音”。又如,音系表字段“例词1意译、例词2意译、例词3意译”,词汇表字段“词1备注、词2备注、词3备注”,都描述和标识“中文意译”这个属性。再如,音系表“调值、调类、元音或韵母、辅音或声母”字段,字表、词汇表、语法表“调查条目、调查条目全”字段,都指“样本条目”这个属性。还有词表、句表字段“注例”,音系表字段“备注”,都属“补充说明”。可见,数据表有55个字段,但实际只描述了“编号、条目、音标注音、中文意译、中文直译(句)、语素分析、说明”等7个属性,存在大量冗余,这使得语料的属性描述和标识显得贫乏。例如,汉语方言字表缺少“音韵”属性,该属性对方言字音研究有重要的数据挖掘价值,数据库里如不补上该属性,将会减少一些重要的应用方向。再如,少数民族语言数据表缺少“民族文字”属性,同样会减少一些重要的语料开发和应用方向。如果搬用模板表来建构资源库的数据表,构架会十分臃肿,数据挖掘潜能和数据库应用功能将严重受限。这就是说,单纯从数据表模板来看,语料的效用度并不高。
Excel数据表虽然在数据库导入数据方面比较方便,但就原始数据兼容和安全存储而言,并不是最佳选择。国际标准化组织的语言资源管理标准(如ISO24610、24615、24617、24624等)都是基于xml的纯文本数据模式,由此看来建立一套必需的属性来描述和标识语料,是语保工程对语料保存、保护和利用考量中被忽略了的一项工作。
二、语保工程多媒体资源的应用方向
数字语料的品质、形态、种类、数量以及数据模式决定了它的效用,但要发挥语料的效用,还需要数据挖掘和二次开发。语保工程的言语样本是次生资源,但人们通常使用的是语言产品(成品),而不是资源本身。公众关心的资源利用实际上就是对这些多媒体语料进行再加工,对语料数据进行数据挖掘,开发和创新应用功能及终端产品。要实施这样的开发利用,需要语保工程资源管理者和服务方(主要是数据库开发者)与语言专家、语言社群及公众合作,开展需求调研,明确服务群体、服务项目和服务方向,这样才能使语保工程的语料数据真正成为有效用的社会公共资源。
(一)语保工程语料资源开发利用的原则
语保工程是一项具有保存言语样本和促进语言文化保护和发展性质的工程。保存是基本功能,这有点类似建在挪威斯瓦尔巴特群岛的全球植物种籽库,要保证国内有些语言或方言在不远的将来不可避免地灭绝以后,能够在工程保存的语料数据中找到较为系统的言语样本资料(可能用于语言学习或语言恢复)。当然,语言用进废退,采集言语语料的目的主要还是为了促进当下和以后的语言使用,保护是常规,而语料开发和利用就是常规的服务工作,因而应遵循精化和粗化结合、雅用和俗用并举、专用和通用兼顾的原则。
精化和粗化结合就是说,基础的、核心部分的语料采集、加工必须精炼、准确、严密,这不仅表现在上面所说的质量上,也表现在语言学的标注、描写方面,所有基础语料必须是完整的、系统的、完全标注且不留疑点的;而粗化则表现在持续扩充的语料方面以及面向非语言学或其他科学研究的语料呈现方面,不应作语言学标准或其他科学标准的苛求,这样才能促进资源的多样化和应用的多元化。
雅用和俗用、专用和通用,既涉及语料本身的内容及其呈现形式的难易特性,也涉及语料面向的领域行业的高低端属性,还涉及使用群体的专业性和大众性。雅用和专用,就是语料的开发利用要考虑语言学研究和高层次的正规教育教学和研发,考虑专业人员和某些专门领域的需求;俗用和通用,就是要考虑使资源内容和形式浅显化、知识化,面向大众或尽可能适应广大的用户群需求。如果有人说,实施语保工程本身就是为了雅用和专用,这无疑违背了工程的原旨和初心;而说语保工程完全是为了俗用和通用,那也不切实际,违背了语言学规律和语言使用及发展规律。
(二)语料的可能应用领域
语保工程的语料究竟有哪些当下应用和潜在用途?这些语料能向哪些社会群体、行业或领域提供什么服务项目?当下对语料资源有开发和利用需求的有以下这些领域。
1.高等院校语言学课程教学
大学《现代汉语》《语言学概论》《少数民族语言文字概论》《语音学》《方言学》《田野语言学》《词汇学》《语法学》等语言学课程的教学,需要汉语方言和民族语言的言语样本作为实证、例证。
2.语言学研究
汉语方言、民族语言、传统语言、语言理论和应用等学科领域的研究,需要利用语保工程多媒体语料。例如,绘制各种传统的中国语言地图(需开发地图软件程序);统计语言在字、词层面的形式相似度(需开发计算程序);语言同源词的比较和统计(需开发相关统计程序);语音和词汇(构词)的类型研究(需开发相关分析程序);汉语方言和民族语言的历史比较(需开发相关程序);汉语方言和民族语言文字的规范研究(如拼音方案、正字法);建立语音特征基本数据(尽管相对有限);等等。
3.语言学习或语言娱乐
汉语方言区或少数民族地区的中小学可能会使用多媒体语料样本,用于课外本土语言文化学习活动,或用于课堂双语教学,传播传统语言和文化知识。不过,这种情况对语料的使用不是刚性需求,使用量也比较有限。一些社会公众对语言知识有好奇心,也会有限地听或学某种民族语或汉语方言的一些单词作为知识和文化娱乐。语言群体可能有限地使用这些资源来宣传本族的语言和文化。可以明确的是,从语保工程现有的语料可用性来看,高等院校中文系、少数民族语言文学系、语言学及应用语言学系的语言学教师和学生,以及语言研究机构的工作人员,是语保工程资源的主要需求群体,其次才是语言族群和有限的社会公众群体。
(三)面向用户的资源库功能开发
从“语保工程采录展示平台”用户界面来看,资源库的多媒体展示是通过静态网页层级路径导航浏览页面,仅向用户提供这种单一的网页浏览,远不能发挥资源库的用途,不能满足公众用户的基本使用需求。要使语保工程的语料资源在上述领域的应用真正变成具体服务,则需要基于资源库进行系列工具研发和产品开发。
1.组合和聚合检索应用界面
多字段组合检索是根据数据表的属性标识,查找符合多种属性条件的多媒体言语样本资料。这类似于图书库或期刊库的多重条件检索,查找满足用户所需的语料资源件。语保工程语料样本的组合检索,至少应包含如下检索条件:语言名称(单语种/多语种)、语言地点(单点/多点)、样本单位(中文字/词/句、民族文字)、样本注音(国际音标/拼音文字)、音韵(对于汉语方言)等。
聚合检索是对同一字段属性中满足用户设定要素的记录进行查找。聚合检索可以是单一属性字段内检索,更重要的是组合检索条件下的多字段内的记录检索。例如,汉语方言的历史音韵比较,要查找中古“並”母字在湘、客、赣、土话中不读唇音(b/p/ph)的方言样本。再如,要查找包含前置成分“m/n/s”的藏缅语言及其分布地点等,这都是组合基础上的条件聚合检索。
无论是字段组合还是聚合检索,都必须跨语言、跨方言、跨地域、跨文字、跨样本单位层级。目前能见到的语保工程展示平台还不能提供这类检索,因而需要对数据库字段属性作增补、调整或整合开发,建立便利的多重搜索界面。
2.统计和计算的用户界面
面向用户需求的统计和计算,可能是语保工程网络资源库的功能空缺。对资源库数据表的文本数据进行统计和计算,是一项面向用户的重要应用服务。从理论上说,要使数据得到最大程度利用,就应当实现所有单个字段属性计算和跨字段属性的关系计算。由于语保工程数据表字段所表征的样本属性较少,计算对象可能会比较单一,主要是字段内的记录分布计算,而且计算的范围主要是音标注音、中文条目、语素分析等几个字段。例如,前面说的同源词统计、不同语言或方言语音相似度统计、类型学的统计,主要是基于词汇音标记音和中文词素进行计算。又如,对每个调查点字词句语音样本进行声学参数统计,建立基本语音特征模式,这是基于音频数据的计算。
我们也可利用语料进行音位、音节、超音段特征、语素的频次统计、组合分布统计、话语文本的词频和共现词组统计。语保工程的句子和话语样本很少,因而词表提取、词频和共现词组统计等应用功能基本上无用武之地。我们还可对调查点概况数据进行语言人口、分布等语言社情和区情的统计。要实现这些数据的计算分析,还需要开发相关应用软件工具或接口。
总之,语保工程资源开发利用不是一次性的,资源的管理、应用以及资源库平台的建设不会一劳永逸。近两年,有高校开始筹划建立语言博物馆,这可视为语保工程以及在其牵引下的语言资源保护和利用的一个实践选项。笔者曾指出,语保工程有结束之日,而语保永远在路上[2]。群众的语言生活在发展变化,基础语料也应当反映现实语言生活而持续增补,资源库也应该持续扩容并创新服务途径和服务形式。要想方设法挖掘数据的可用属性,尽最大努力开发适应用户的操作工具和应用界面,这样才能最大程度地实现资源的价值,最大程度地发挥它的社会效益。
