基于EAST与CNN的钢材表面字符检测与识别方法
2019-05-17冯谦陶青川
冯谦,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
当前,国内各大钢材生产企业正逐步将一些生产环节从人工操作转变为自动化操作[1]。在钢板的表面有钢板的唯一编号,在测试试验的各个环节,需要把钢材编号与测试数据对应起来保存,以达到质量检测的要求。因此如何在实际生产环节中利用计算机视觉方法来进行自动化字符区域检测与识别,成为了一个亟需解决的问题。目前字符定位及识别的方式以人工目测法为主,效率不高且浪费人力。利用计算机视觉技术和神经网络技术,可以大大提高检测和识别的准确性和速度,并且可以减少对劳动力的依赖。本文旨在通过工业相机采集到钢材表面图片,再经过图像处理和预先训练的神经网络进行识别,实时精确且快速地得到当前钢材的编号。
近年来,在目标检测和字符识别取得了一些比较突破的成果。目标检测领域中,HOG结合SVM的方案是较为成熟的方案,提出时率先应用于自然场景中的人脸检测[2],之后在物体检测中也取得了很好的效果[3]。传统的OCR解决方案中,基于形态学的图像处理往往能在特定场景的目标检测取得很好的效果,例如发票票据信息检测[4],驾驶证证件信息区域检测[5]。字符识别领域中,基于ANN的神经网络对字符识别有着较高的识别率[6]。华中科技大学的白翔团队受到Mask R-CNN的启发提出了一种用于场景文本识别的可端到端训练的神经网络模型:Mask TextSpotter[7]。端到端训练的方式可以省去字符切割的步骤,字符分割效果不好的情况下会对下一步字符识别造成一定的影响。在实际的工业生产线上,计算机普遍配置不高且不具有高端显卡,对识别速度也要求较高。因此,需要一种网络结构简单,速度较快,能在较低配置计算机上正常运行的解决方案。
1 图像预处理
尽管工业相机成像质量较好,但由于现场环境复杂、钢材表面坑洼以及光照不均匀等多种原因,会造成图像噪声过多、过亮、过暗等情况,对后续检测和识别造成影响。

图1 图像预处理流程
高斯滤波处理噪声的同时较好地保留了字符的边缘,对后续算法影响最小。
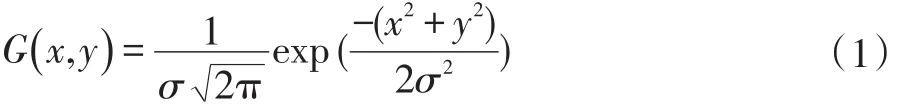
其中标准差σ是事先定好的常数,将求出的结果离散化为模板与原图做卷积即可。
使用直方图均衡化处理图像整体较暗或较亮有较好的效果[8]。本文针对文本检测的要求使用伽马变换,突出文本区域信息,弱化背景区域信息。

将γ值设置为3以拉伸具有更高灰度级的图像区域,即文本区域,同时,对灰度较低的区域进行压缩,增强了图像文本区域的对比度。

图2 图像预处理结果图
由于字符区域位于整个钢材的中央区域,因此在定位每一个字符的区域前先获取整体文本的位置是一种普遍的方法。传统的区域检测算法包括图像边缘分割和形态图像处理,以找到连接区域并获得目标区域。一个强大的基于神经网络的文本检测算法——EAST text detector在场景文本检测上具有优异的效果[9]。
EAST文本检测器是一种基于新颖架构和训练模式的深度学习模型。该方法使用单个神经网络直接预测整个图像中任意方向的四边形文本行,消除了不必要的中间步骤,例如候选区域聚合和字符分割。模型可以分解为三个部分:特征提取器、特征合并分支和输出层。最初可以使用卷积层和池化层交错的卷积神经网络进行预训练,以获得四级特征图像。大小分别是原图的1/32、1/16、1/8和1/4。合并分支的功能在特征合并部分中逐渐合并它们。要使图形的大小加倍,然后与当前特征图级联。接下来是一个3×3卷积层,它融合了信息并最终产生文本合并阶段的结果。输出层对应于RBOX,由轴向边界框和旋转角度表示。

图3 EAST网络结构图

图4 EAST识别成多段文本
EAST文本检测器有其缺点,一个文本区域有时会被检测到多个文本区域,这不利于长文本的检测。而最终需要整体的文本区域,因此需要将多个文本区域聚合。
基于长文本区域检测的要求,改进了EAST方法的输出层,使长文本预测更加准确。EAST是使用所有像素的预测顶点坐标的加权平均值计算最终的顶点坐标。而对于长文本的四边形来说从短边一侧的若干像素来预测另一侧的两个顶点难度较大。因此设计了一个有头尾方向的文本框边界输出层模式。头部像素只负责预测其一侧的两个顶点,尾部像素负责另一侧。

表1 改进后网络输出层
改进后网络输出层分别是第一位是否在文本框中,第二位和第三位是否属于文本框边界像素以及是头还是尾。最后四位是边界像素可以预测的两个顶点的坐标。
运行模型预测得到输出后,还需要根据输出计算得出最后的文本框坐标,这个过程如下。由预测矩阵根据配置阈值得到激活像素集合;按先左右后上下的顺序将相邻集合合并生成其头和尾边界像素集合;每个边界像素点预测值的加权平均值作为最后的预测坐标值。

图5 改进后EAST文本检测效果
2 字符区域矫正与分割
通过EAST检测到的文本区域有着一定的倾斜角度,倾斜角度过大会对下一步的分割造成干扰。因此,有必要矫正图片的文本部分以进行下一步。旋转角度根据字符区域的包围矩形的长边与水平轴的夹角确定,旋转中心根据字符区域的包围矩形的中心点确定,根据以上结果计算仿射变换矩阵。

图6 矫正效果图片
对图像倾斜矫正后需要将字符从背景中分割出来,一般采用Ostu算法或者Sobel算法。手动选择阈值的方法不利于多种场景下的分割,因此需要自适应阈值选择方法使用。选择基于Ostu算法(最大类间方差法)的二值化操作对图片进行处理。

对于阈值T,将图像分为了目标点和背景点,其中目标点的比例为w1,像素平均值为 p1,背景点的比例为w2,像素平均值为p2。当阈值T求得上式类间方差值为最大的时候,可以确认阈值。
二值化后,可以通过搜索连接区域并找到正外界矩形来确定多个字符区域。对外部矩形宽度异常的字符进行个别判断。运用列的线性扫描,在异常区域寻找上下轮廓的极小值,同时比照正常区域宽度进行分割得到切分正常的单个字符。将切分正常的单个字符顺序输入训练好的卷积神经网络得到最终的识别结果。

图7 二值化后效果图
3 卷积神经网络
CNN是卷积神经网络。LeNet5作为早期的卷积神经网络很快应用在了支票上手写数字的识别。21世纪后,随着深度学习理论的发展和计算机设备的不断完善,卷积神经网络得到了迅速发展,并被广泛应用于计算机视觉、自然语言处理等领域。
卷积神经网络的结构有三部分,分别是卷积层、池化层和全连接层。在普通神经网络的情况下,图像的每个像素作为连接到所有像素的神经元将导致过多的参数。卷积神经网络有两种方法可以减少参数的数量。第一种是局部感知,由于图像具有强相关性的特点,距离相近的像素相关性较强,距离较远的像素点相关性较差。因此,每个神经元仅需要局部感知,并且仅需要卷积核心的像素数量的参数。另一种是权重共享,即每个卷积内核是一种提取特征的方法。只要确认了提取某一种特征的卷积核,就能对整个图像学习到同样的学习特征。为了使特征提取充分,使用多个卷积核,可以学习多种特征。可以计算图像区域上的特定特征的平均值或最大值以表示该区域的特征。这些汇总统计特征不仅减少了特征的尺寸,而且使其难以过度拟合。此聚合操作称为池化,这简化了模型的复杂性和参数。在实际应用中,使用多层卷积,然后将完整连接层用于训练。层数越多,学习的特征就越全局化。本文对钢材表面图片字符先进行粗略切割然后保存,将其中字符图片分为数字0到9一共十类,分作训练集和测试集两个集合。运用LeNet5结构的卷积神经网络对字符进行训练,将训练后的权值保存作为后续检测的方法。
4 实验结果与分析
实验平台:
处理器:英特尔酷睿i5-7300HQ
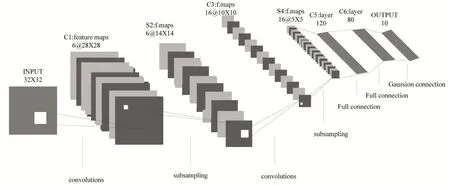
图8 卷积神经网络结构
显卡:GTX 1050M
操作系统:Windows 10
系统内存:8G
在定位文本时,将改进后EAST文本检测方法与传统的扫描线检测法以及单独的EAST方法进行了对比,测试样本共有1000个图像,结果如表2所示。

表2
传统的扫描线检测法与单独的EAST方法准确率相差不多,但单独的EAST方法可以得到文本的角度信息。改进的EAST方法大幅提升了定位准确度,很好地解决了定位的问题。
本文对已有的钢材表面图片字符先进行切割然后保存,将字符图片分为0到9一共10类,一共46889张训练图像以及4812张测试图像。将卷积神经方法与人工神经网络方法进行了比较,结果见表3。

表3
从表2-3看出,改进后的EAST在文本区域检测上是性能最优的。字符准确切割后的识别使用CNN是准确度最高的。两者结合能达到高准确度的结果。
5 结语
本文采用改进的EAST文本检测方法对文本进行检测,局部最小法对文本进行切分,并采用卷积神经网络方法进行字符识别。保证了在较低配置的计算机上时间的快速性和检测的准确性。经过测试,在测试集上获得了95%的综合识别率,能够在实际生产中应用。
