基于Hadoop平台的FCM算法并行化设计
2019-05-15陈阳
陈阳
基于Hadoop平台的FCM算法并行化设计
陈阳
(广东省科技基础条件平台中心)
基于云计算平台Hadoop的主要功能和MapReduce处理流程,设计FCM算法的并行化处理过程。
模糊C均值;MES;数据挖掘;并行化处理
0 引言
近年来,随着移动互联网、云计算、大数据等技术的快速发展及计算机计算能力的大幅提升,现代制造业逐渐走上了信息化、智能化转型和升级的道路[1]。其中,制造企业生产过程执行系统(manufacturing execution system,MES)智能化改造是企业信息化和智能化进程的关键内容之一。利用MES中的生产实时数据,结合大数据挖掘技术,跟踪产品质量管理和生产过程,是提高生产效率及智能化的关键。
然而,MES数据量较大,大数据挖掘处理速度亟待解决。目前提高大数据挖掘处理速度的技术主要包括云计算平台的分布式挖掘和智能算法2方面。
本文以Hadoop分布式框架为基础,研究基于模糊C均值聚类的数据挖掘算法并行处理技术,以提高大数据挖掘处理速度。
1 基于Hadoop的海量数据分布式处理平台
数据挖掘(data mining,DM)是指从大型数据库或者数据仓库中找出隐含的、当前未知的、非凡的以及有潜在应用价值的信息或者模式[2]。数据挖掘主要经历基于网格计算的分布式挖掘和基于云计算平台的分布式挖掘2个阶段。目前数据挖掘研究大多集中在云计算平台,其主要特点是使用多个计算节点对算法进行运算,分配规则是根据算法所需要的资源,在云端实现数据存储和运算。其中基于Hadoop分布式框架的云计算分布式挖掘是当前研究热点[3]。
Hadoop平台主要由MapReduce,Pig,HDFS,Hive和HBase等部分组成[4]。其中MapReduce(分布式计算)是算法处理核心,主要包括Map和Reduce 2个计算过程,处理流程图如图1所示[5]。此外,目前对于海量数据的处理,借助Combine函数对Map函数的输出进行合并,以减少传输到Reduce函数的数据量,从而提高数据处理效率。
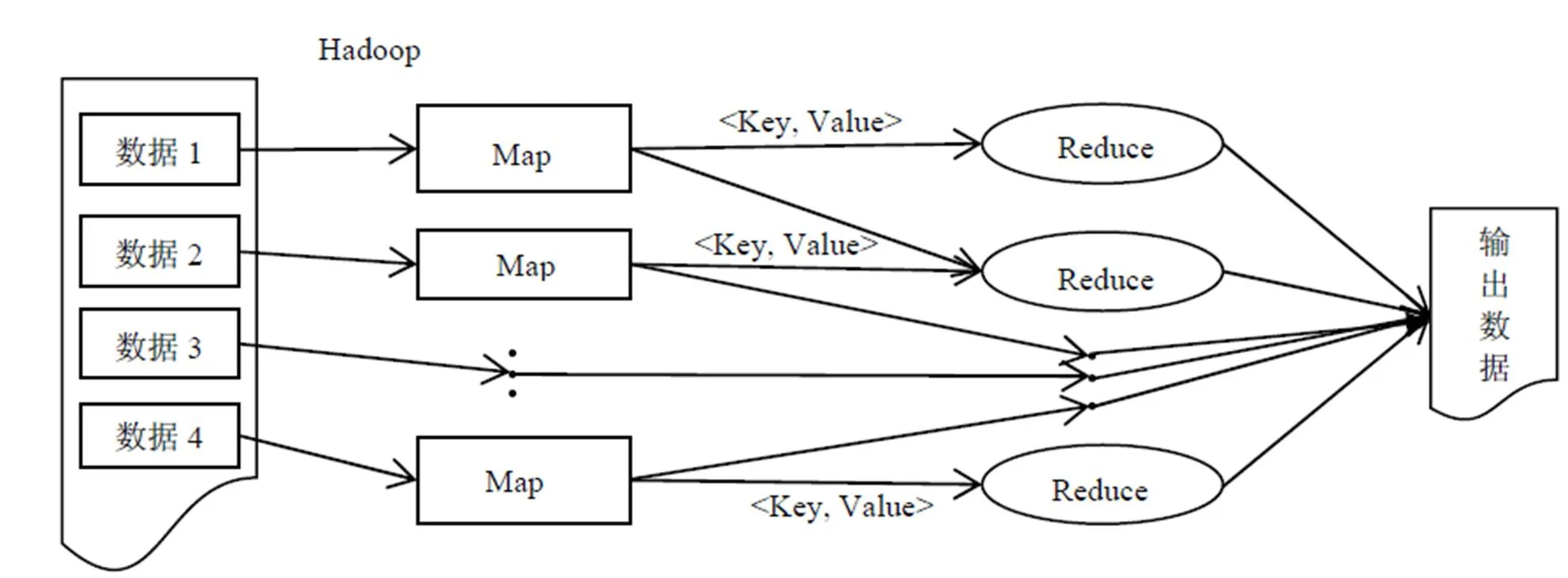
图1 MapReduce处理流程图
2 模糊C均值聚类算法
聚类算法是数据挖掘技术中的一类常用、高效的算法。模糊C均值聚类(Fuzzy C-Means,FCM)算法是以类内加权误差平方和作为目标函数的一类聚类方法[6],算法基本流程如图2所示。
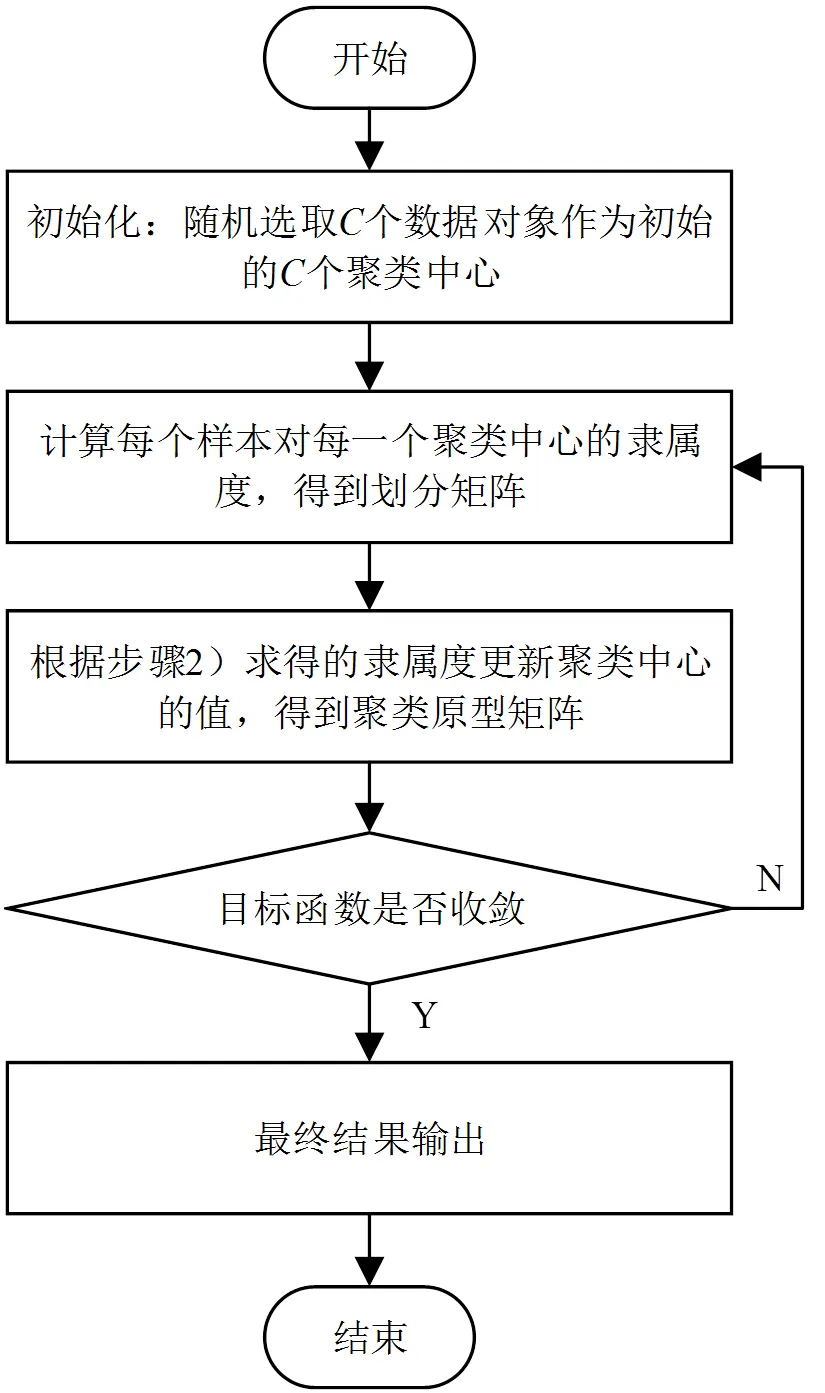
图2 FCM算法基本流程图
FCM算法的具体步骤描述如下:
1)初始化,对个样本={1,2,3,…,x}进行类划分,设置迭代定制阈值和最大迭代次数;初始化聚类原型矩阵,给定加权指数;初始化迭代起始数,即给置0;
2)利用式(1)计算或更新划分矩阵
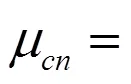
3)利用式(2)更新聚类原型矩阵

4)利用式(3)计算当前目标函数值,若目标函数值小于阈值或达到迭代次数,则输出划分矩阵和聚类原型矩阵的值;否则,令=+1,转步骤2)。
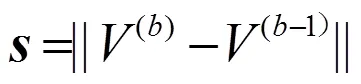
3 FCM算法并行化设计
根据FCM算法原理,每个数据对象到个聚类中心的隶属度计算是相互独立的,且比较耗费计算资源。因此,对这一过程进行并行化设计。
在Hadoop平台中,FCM算法的并行化设计和实现,实质就是将算法进行MapReduce化,即实现Map和Reduce过程,具体工作包括:1)输入和输出键值对设计;2)函数的具体实现逻辑。基于Hadoop平台的FCM算法并行化过程如图3所示。
4 FCM算法并行化实现
基于Hadoop平台的FCM算法并行化实现主要步骤:1) Map函数实现;2) Combine函数实现;3) Reduce函数实现。
1) Map函数实现
Map函数的作用是读取待分类数据和当前个聚类中心的值,并计算各个数据分别对个聚类中心的距离、隶属度、隶属度与数据的乘积和。Map函数形式为键值对,其中是当前数据的行偏移量;是当前对象各个维度坐标值的行记录。Map函数的实现过程就是从字符串中得到源数据/对象与个聚类中心的隶属度,最后输出形如<2,2>的返回值。
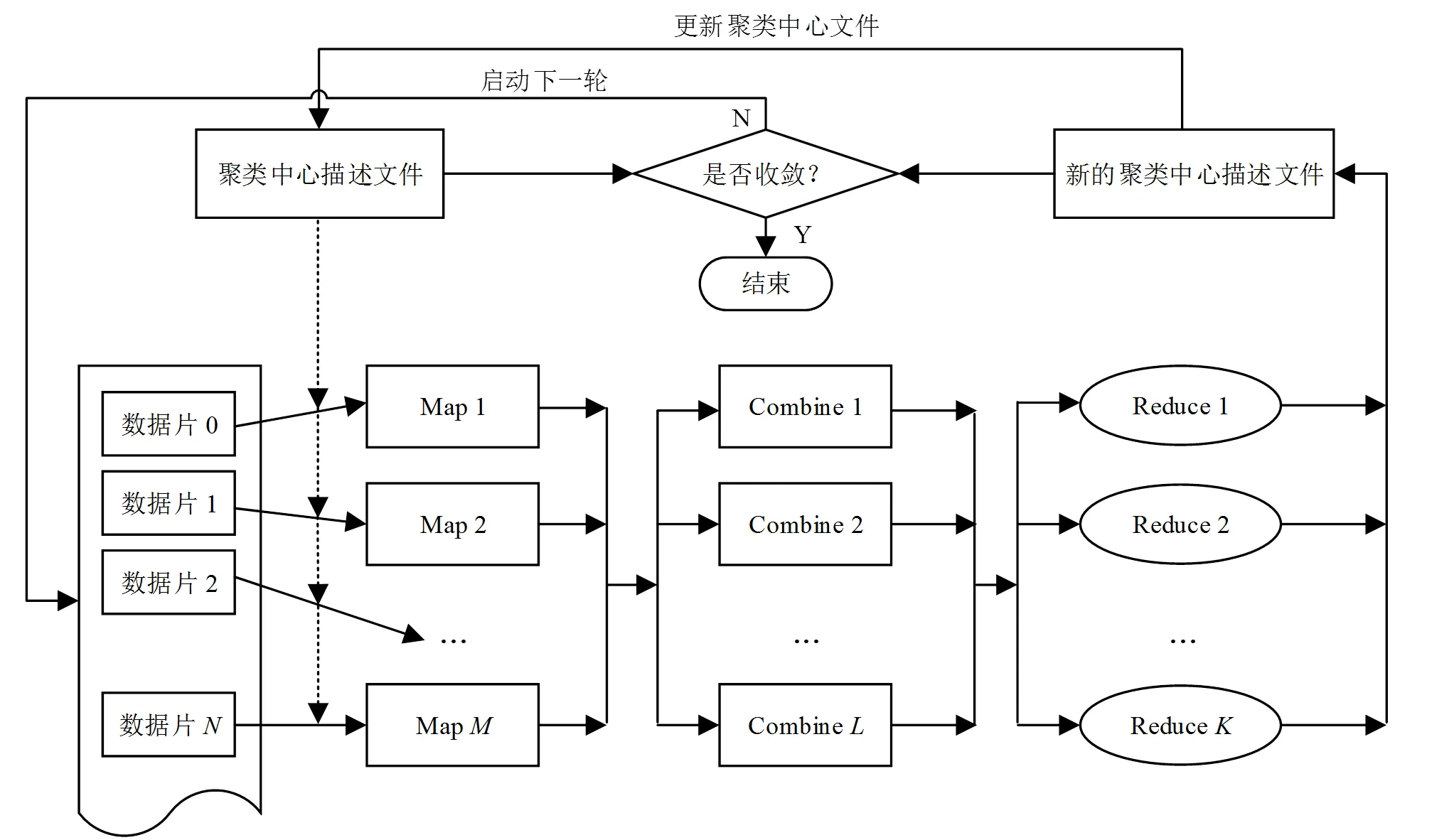
图3 基于Hadoop平台的FCM算法并行化过程图
Map函数设计与实现的伪代码为:
map(<,>,<2,2>){
从中解析出当前数据对象,记为Source={S|1,2,…,S};
得到个聚类中心={v|1,2,…,v};
初始化各数据点到个聚类中心的距离总和SUM_Distance=0
for(=1;≤;++){
_distance[]=Math.norm([]);
SUM_Distance=SUM_Distance+Math.pow(1/(_ distance[]*_distance[]),-1);
}
for(1){
_menbership[]= Math.pow(1/(_distance[]*_distance[]),-1)/SUM_Distance;
}
for(=1;++){
Temp_P[]= Math.pow(_menbership[], b)*[];
}
2个聚类中心的ID
2= (_menbership[], Temp_P[]);
函数返回<22>;
}
2)Combine函数实现
Combine函数的主要作用是对Map函数的输出结果(隶属度和隶属度与数据点的乘积和集)进行整理和排序,从而保证后续Reduce函数的输入参数能够按照值对Map阶段的输出结果进行分组。因此,Combine函数的输入参数为Map函数的输出22,其中,2代表当前C聚类中心的ID;2代表隶属度的值以及数据点的乘积和。
Combine函数设计与实现的伪代码为:
map(<2,2>,<3,3>){
创建一个存储空间,存储同一个聚类中心的相关数据;
for(=1;≤;++){
for(=1;≤;++);
While(value.hasNext()){
调用value.nex()得到属于第个聚类中心的数据;
将调出来的数据存入到对应的数组中;
}
}
3=2;
3=重新分配的数据组;
函数返回<3,3>;
}
3)Reduce函数实现
Map函数和Combine函数的处理结果经过Reduce函数的计算得到聚类更新后的聚类中心点,然后进行迭代,即进入新一轮的Map,Reduce过程。Reduce函数的输入参数格式为<33>键值对,其中3值表示聚类中心下标,3是Combine函数的计算结果。
Reduce函数设计与实现的伪代码为:
map(<3,3>,<4,4>){
初始化所有数据点与隶属度乘积和的总和为SUM1=0;
初始化所有数据点的隶属度总和为SUM2=0;
for(=1;≤;++){
SUM1[]=SUM1[]+Temp_P[];
SUM2=SUM2[]+_menbership[];
}
for(=1;≤;++){
New_C[]=SUM1[]/SUM2[];
}
4=3;
3=更新后的个聚类中心的ID;
函数返回<4,4>;
}
5 应用实例
本实验数据是某塑料制品加工企业MES中存储的手机前盖加工数据,包括生产设备信息、塑料原料信息、料筒温度信息、合模压力信息、锁模压力信息、螺杆位置信息、顶针位置信息、模具位置信息和制品检测信息等。通过对这些数据进行基于模糊C均值聚类的MapReduce并行化处理,实现手机前盖加工质量等级的分类。将该加工数据按样本大小逐级递增分为3组,如表1所示,要求生成3个聚类,分别是合格、次品和废品。

表1 实验数据集分组情况
加速比是算法在单节点与多节点上聚类给定数据集中数据对象执行时间的比值,是衡量并行系统性能或程序并行化效果和扩展性的重要指标[7]。本文利用加速比来验证算法的并行化效果。
分别设置1到10个节点进行运算,得到的实验结果如图4所示。

图4 基于模糊C均值聚类的MapReduce并行化处理实验结果
实验结果表明:该算法的加速比随着节点数的增加呈相对线性增长,即具有良好的加速比性能,且对于不同大小的数据集,加速比性能稳定。
6 结语
本文介绍了FCM在Hadoop平台的MapReduce并行化处理过程的设计与实现,为MES的数据挖掘算法并行处理技术提供借鉴和参考。
[1] 白艳玲,殷子焱.智能化制造业发展的战略思考[J].科技创新与生产力,2015(7):11-12.
[2] 张诚,郭毅.数据挖掘与云计算——专访中国科学院计算技术研究所何清博士[J].数字通信,2011,38(3):5-7.
[3] 贺瑶,王文庆,薛飞.基于云计算的海量数据挖掘研究[J].计算机技术与发展,2013,23(2):69-72.
[4] 林琳.揭秘Hadoop生态圈[J].科技视界,2016(26):247,231.
[5] 石慧芳,陈阳.基于大数据的制造业企业信息化数据分析及应用技术研究[J].现代计算机(专业版),2016(16):50-54
[6] 潘玉娜,陈进,李兴林.基于模糊c-均值的设备性能退化评估方法[J].上海交通大学学报,2009,43(11):1794-1797
[7] Susanne Englert, Jim Gray, Terrye Kocher, et al. A benchmark of NonStop SQL release 2 demonstrating near-linear speedup and scaleup on large database[J]. ACM SIGMETRICS Performance Evaluation Review, 1990,18(1): 245-246.
Parallel Design of FCM Algorithm Based on Hadoop Platform
Chen Yang
(Guangdong Science & Technology Infrastructure Center)
The parallel design and implementation of MES data mining algorithm based on fuzzy c-means clustering was deeply studied in this paper. Firstly, the main functions of Hadoop, the cloud computing platform supporting data mining technology, and the processing flow of MapReduce, which realizes algorithm operation, was introduced. Then, the fuzzy c-means clustering algorithm, which is different from k-means clustering algorithm, was introduced. Finally, the parallel processing of MapReduce based on fuzzy c-means clustering algorithm was designed and implemented.
Key Works: Fuzzy CMeans; MES; Data Mining; Parallelization
陈阳,男,1984年生,本科,高级工程师,主要研究方向:计算机、电子信息技术应用等。E-mail: gdcc_chenyang@foxmail.com
