基于随机博弈与改进WoLF-PHC的网络防御决策方法
2019-05-15杨峻楠张红旗张传富
杨峻楠 张红旗 张传富
(中国人民解放军战略支援部队信息工程大学 郑州 450001)
随着社会信息化程度的不断加强,网络攻击也日趋频繁,给防御者造成巨大损失[1].由于网络本身的复杂性及防御者能力的限制,导致网络无法达到绝对的安全,亟需一种能够对攻防行为进行分析和对网络风险与安全投入进行有效折中的技术,使得防御者能利用有限的资源做出合理的决策.博弈论与网络攻防所具有的目标对立性、关系非合作性和策略依存性高度契合[2].博弈论在网络安全中的研究和应用日渐兴起[3],其中基于随机博弈的攻防对抗分析更是成为一个热点.随机博弈是博弈论与Markov决策的结合,不仅将传统博弈的单状态扩展到多状态,还能对网络攻防的随机性进行刻画.目前基于随机博弈的网络安全分析已取得一定成果,但仍存在不足和挑战:现有攻防随机博弈以完全理性假设为前提,通过纳什均衡来进行攻击预测和防御指导.完全理性包括理性意识(追求最大收益)、分析推理能力、识别判断能力、记忆能力和准确行为能力等多方面的完美性要求,其中任何一方面不完美就属于有限理性[4].完全理性的高要求对于攻防双方过于苛刻,导致完全理性假设下得到的纳什均衡在实际中很难出现,降低了现有研究成果的准确性和指导价值.
针对上述问题,本文在有限理性约束下,研究基于随机博弈的防御决策方法.介绍了基于随机博弈的防御决策研究现状;分析有限理性下研究网络攻防随机博弈的难点及本文解决思想,在有限理性约束下构建攻防随机博弈模型并提出一种以主机为中心的攻防图用于提取博弈模型中的网络状态与攻防动作;基于资格迹改进WoLF-PHC[5],利用改进的WoLF-PHC对所构建的随机博弈模型进行博弈分析并设计防御决策算法;通过实验验证所提方法的有效性;最后总结全文并对未来研究进行展望.
本文的贡献主要有3个方面:
1) 网络状态及攻防动作提取是随机博弈模型构建的关键之一.现有随机博弈模型的网络状态包含网络中所有节点的安全要素,存在“状态爆炸”问题.针对此问题,提出了一种以主机为中心的攻防图模型并设计了攻防图生成算法,有效压缩了博弈状态空间.
2) 有限理性意味着攻防双方需要通过试错和学习来寻找最优策略,确定参与人的学习机制是一个关键点.本文将强化学习引入到随机博弈中,使随机博弈由完全理性拓展到有限理性领域,防御者利用WoLF-PHC在攻防博弈中进行博弈学习,从而针对当前攻击者做出最优选择.现有有限理性博弈大多采用生物进化机制进行学习,以群体为研究对象,与其相比,本文所提方法降低了博弈参与人之间的信息交换,更适用于指导个体防御决策.
3) 基于资格迹[6]对WoLF-PHC算法进行了改进,加快了防御者的学习速度,减少了算法对数据的依赖并通过实验证明了方法的有效性.
1 研究现状
国内外基于博弈论的网络安全研究已取得一定进展,但是目前研究大多以完全理性假设为前提[7].完全理性下依据攻防双方在博弈过程中的决策次数,可以分为单阶段博弈和多阶段博弈.单阶段网络攻防博弈的研究起步较早:中国科学院刘玉岭等人[8]采用静态博弈理论对蠕虫病毒攻击和防御策略的效能进行了分析.加拿大艾伯塔大学的Li等人[9]建立了攻击者与传感器信任节点间的非合作博弈模型,依据纳什均衡给出了最优攻击策略.在网络攻防中,虽然部分简单的攻防对抗属于单阶段博弈,但大多数场景中攻防过程往往持续多个阶段,所以多阶段网络攻防博弈成为一种趋势:信息工程大学张恒巍等人[10]将防御方看作信号发送源,攻击者为信号接收方,构建多阶段攻防信号博弈模型并给出均衡求解方法.密苏里科技大学的Afrand等人[11]建立了入侵检测系统和无线传感器节点间的重复博弈模型,分析了节点包的转发策略.上述成果虽然可以对多阶段攻防对抗进行分析,但是阶段之间的状态转移不仅受到攻防动作的影响,还受到系统运行环境以及其他外来因素的干扰,存在随机性,而上述成果忽略了这种随机性,削弱了其指导价值.
随机博弈是博弈论与Markov理论的结合,是一种多阶段博弈模型,采用Markov过程来描述状态的转移,能够准确分析随机性对攻防过程的影响.哈尔滨工程大学姜伟等人[12]将网络攻防抽象为随机博弈问题,给出了适用于攻防随机博弈模型的较为科学、准确的攻防收益量化方法.空军装备研究院王长春等人[13]使用随机博弈对网络对抗问题进行研究,运用凸分析理论证明均衡的存在性并将均衡求解转换为一个非线性规划问题.Lei等人[3]基于不完全信息随机博弈提出了一种网络移动目标防御决策方法.上述文献全部以完全理性假设为前提,这对攻防双方过于严苛,大多数情况攻防双方都只是有限理性水平,导致上述研究成果在攻防博弈分析时难免产生偏差.因此,探究有限理性的网络攻防博弈规律,具有重要的研究价值和现实意义.
有限理性意味着攻防双方不会在一开始就找到最优策略,会在攻防博弈中学习攻防博弈,合适的学习机制是在博弈中取胜的关键.目前有限理性攻防博弈的研究主要围绕演化博弈[14]展开.Hayel等人[15]建立了恶意软件和反病毒程序间的演化泊松博弈模型,借鉴复制动态方程分析反病毒程序策略.黄健明等人[16]通过引入激励系数,改进传统复制动态方程,完善复制动态速率计算方法,基于此构建演化博弈模型用于防御.演化博弈以群体为研究对象,采用生物进化机制,通过模仿其他成员的优势策略来完成学习.演化博弈中参与人之间信息交换过多且主要是对攻防群体策略的调整过程、趋势和稳定性进行研究,不利于指导个体成员的实时策略选择.
强化学习是一种经典的在线学习方法,其参与人通过环境的反馈进行独立学习,相比生物进化方法,强化学习更适于指导个体的决策.本文把强化学习机制引入到随机博弈中,将随机博弈由完全理性扩展到有限理性,并采用有限理性随机博弈对网络攻防进行分析.与现有攻防随机博弈相比,本文方法采用有限理性假设,更加符合实际;与演化博弈相比,本文方法采用强化学习机制,更适用于指导个体防御决策.
2 基于随机博弈的攻防对抗建模
2.1 网络攻防对抗问题描述与分析
网络攻防对抗是一个复杂问题,但从策略选取的层面,可以将其描述为一个随机博弈问题.将连续的时间轴划分为一个个时间片,每个时间片内包含且只包含一个网络状态.不同时间片内的网络状态可能相同.每个时间片都是一个攻防博弈问题,攻防双方检测当前网络状态,然后依据策略选取攻防动作并获得立即回报.攻防策略与网络状态相关联.网络系统在攻防双方的联合行为下由一个状态转移到另一个状态.网络状态之间的转移不仅受到攻防动作的影响,还受到系统运行环境以及外部环境等因素的影响,存在随机性.本文的目标是使得防御者在攻防随机博弈中获得较高的长期收益.
完全理性下攻防双方都能预测到纳什均衡的存在,所以纳什均衡就是双方的最优策略.由引言中对完全理性的描述可知,完全理性对于攻防双方的要求过于苛刻,实际中攻防双方会受到有限理性的约束.有限理性意味着攻防双方至少有一方不会在一开始就采取纳什均衡策略,意味着有限理性下攻防双方很难在博弈初期找到最优策略,需要针对对手的策略不断调整和改进,意味着博弈均衡不是一次选择的结果,是攻防双方在攻防对抗中不断学习达到的,而且由于不同学习机制的影响,即使达到了均衡也有可能再次偏离.
由上述分析可知,学习机制是有限理性随机博弈取胜的关键.针对防御决策问题,有限理性下的攻防随机博弈学习机制需满足2点需求:1)学习算法的收敛性.有限理性下攻击者策略具有动态变化特性,又因为攻防策略的相互依存性,使得防御者在面对不同攻击策略时都要学习到对应的最优策略才能保证自己立于不败之地.2)学习过程不需要过多攻击者信息.网络攻防双方具有目标对立性和非合作性,攻防双方会刻意隐藏自己的关键信息,学习过程如果需要过多对手信息会降低学习算法的实用性.
WoLF-PHC算法是一种典型的策略梯度强化学习方法,使防御者通过网络反馈进行学习,不需要与攻击者之间过多的信息交换.WoLF机制的引入保证了WoLF-PHC算法的收敛性[5]:在攻击者通过学习采用纳什均衡策略后,WoLF机制使得防御者能够收敛到对应的纳什均衡策略;在攻击者尚未学习到纳什均衡策略时,WoLF机制使得防御者能够收敛到对应的最优防御策略.综上可知WoLF-PHC算法能够满足有限理性下的攻防随机博弈需求.
2.2 攻防随机博弈模型
随机博弈由每个状态中的攻防博弈及状态之间的转移模型构成.
对每个状态下博弈所需的“信息”和“行动顺序”2个关键要素进行假定.1)“信息”.受有限理性的约束,将攻击者历史动作和攻击者的收益函数设定为攻击者的私有信息.网络状态为双方的共同知识.2)“行动顺序”.由于攻防双方的非合作性,双方只能通过检测网络来观察对方的行动,这会比动作的执行时间至少延迟一个时间片,所以在每个时间片攻防双方是同时行动,这里的“同时”是一个信息概念而非时间概念,即尽管从时间概念上攻防双方的选择可能不在同一时刻,但由于攻防双方在选择行动时不知道对方的选择则认为是同时行动.
构建网络状态转移模型:采用概率来表示网络状态转移的随机性.由于当前网络状态主要与前一个网络状态有关,所以采用一阶Markov来表示状态转移关系,故转移概率为P(st,at,dt,st+1),其中s为网络状态,(a,d)为攻防动作.由于攻防双方受有限理性的约束,为了增加模型的通用性将转移概率设定为攻防双方的未知信息.
在上述基础上,为解决防御决策问题,构建博弈模型.
定义1.攻防随机博弈模型(attack defense stochastic game model, AD-SGM)是一个六元组AD-SGM=(N,S,D,R,Q,π),其中:
①N=(attacker,defender)为参与博弈的2个局中人,分别代表网络攻击者和防御者;
②S=(s1,s2,…,sn)为随机博弈状态集合,由网络状态组成,具体含义及生成方法见2.3节;
③D=(D1,D2,…,Dn)为防御者动作集合,其中Dk={d1,d2,…,dm}为防御者在博弈状态Sk的动作集合;
④Rd(si,d,sj)为防御者在状态si执行防御动作d网络转移到状态sj后的立即回报;
⑤Qd(si,d)为防御者的状态-动作收益函数,表示在状态si下防御者采取动作d后的期望收益;
⑥πd(sk)为防御者在状态sk的防御策略.
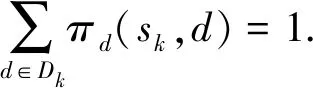
2.3 基于攻防图的网络状态与攻防动作提取方法
网络状态与攻防动作是随机博弈模型的重要组成部分,对网络状态和攻防动作的提取是构建攻防随机博弈模型的一个关键点[17].现有攻防随机博弈在进行网络状态描述时,每个网络状态包含当前网络所有节点的安全要素,网络状态的数量是安全要素的幂集,会产生“状态爆炸”[18].为此,提出以主机为中心的攻防图模型,每个状态节点仅描述主机状态,可以有效压缩状态节点规模[19].利用此攻防图提取的网络状态及攻防动作更有利于进行网络攻防对抗分析.
定义2.攻防图是一个二元组G=(S,E).其中,S={s1,s2,…,sn}是节点安全状态集合,si=host,privilege,其中host是节点的唯一标识,privilege={none,user,root}分别表示不具有任何权限、具有普通用户权限、具有管理员权限.E=(Ea,Ed)为有向边,表示攻击动作或防御动作的发生引起节点状态的转移,ek=(sr,vd,sd),k=a,d,其中sr为源结点,sd为目的结点.
攻防图的生成过程如图1所示.首先对目标网络扫描获取网络安全要素,然后与攻击模板结合进行攻击实例化,再与防御模板结合进行防御实例化,最后生成攻防图.攻防随机博弈模型的状态集合由攻防图节点提取,防御动作集合由攻防图的边提取.

Fig. 1 Attack-defense graph generation图1 攻防图生成
1) 网络安全要素
网络安全要素NSE由网络连接关系矩阵C、节点脆弱性信息V、节点服务信息F、节点访问权限P组成.其中,C=host×host×port描述节点之间的连接关系,矩阵的行表示源节点shost,矩阵的列表示目的节点dhost,矩阵元素表示shost到dhost的端口port访问关系,当port=∅时,表示shost与dhost之间不存在连接关系;V=host,service,cveid表示节点host上的服务service存在脆弱性cveid,包括系统软件、应用软件存在的安全漏洞和配置不当或配置错误引起的安全漏洞;F=host,service表示节点host上开启服务service;P=host,privilege表示攻击者在节点host上拥有privilege访问权限.
2) 攻击模板
攻击模板AM是对脆弱性利用的描述:AM=tid,prec,postc.其中,tid是攻击模式标识;prec=P,V,C,F描述攻击者利用一个脆弱性所需具备的前提条件集合,包括攻击者在源节点shost上具有的初始访问权限privilege、目标节点的脆弱性信息cveid、网络连接关系C、节点运行服务F,只有满足该条件集合,攻击者才能成功利用该脆弱性;postc=P,C,sd描述攻击者成功利用一个脆弱性而产生的后果,包括攻击者在目标节点上获得权限的提升、网络连接关系的变化以及服务破坏等.
3) 防御模板
防御模板DM是防御者在预测或者识别攻击后采取的响应措施:DM=tid,dset,tid是攻击标识,dset={d1,postd1,d2,postd2,…,dm,postdm}是应对特定攻击的防御策略集.其中,di是防御策略标识;postdi=F,V,P,C描述防御策略对网络安全要素的影响,包括对节点服务信息、节点漏洞信息、攻击者权限信息、节点连接关系等的影响.
攻防图生成过程中如果2个节点间具有连通关系,同时满足攻击发生所需的所有前提条件,则增加从源节点到目的节点的边,如果攻击改变了连通关系等安全要素,那么要及时对网络安全要素进行更新;如果防御策略实施改变了节点的连通关系或者攻击者的既有权限,则增加从目的节点到源节点的边,具体如算法1所示,其中行①是利用网络安全要素生成所有可能状态节点并初始化边;行②~是攻击实例化,生成所有攻击边;行~是防御实例化,生成所有防御边;行~是去除所有孤立节点;行是输出攻防图.
算法1.攻防图生成算法.
输入:网络安全要素NSE、攻击模板AM、防御模板DM;
输出:攻防图G=(S,E).
①S←NSE,E←∅;*生成所有节点*
② for eachSdo:
③ updateNSEins;
④ ifC.shost=s.hostandC.dhost.V≥AM.prec.VandC.dhost.F≥AM.prec.FandC.dhost.P.privilege≥AM.prec.P.privilege
⑤sr.host←C.shost;
⑥sd.host←C.dhost;
⑦sd.privilege←AM.postc.P.privilege;
⑧Ea←Ea∪{ea(sr,AM.tid,sd)};
⑨ end if
⑩ end for
假设目标网络的节点数为n,每个节点的脆弱性个数为m,则攻防图中的节点数目最多为3n.在攻击实例化阶段分析每两个节点之间连接关系的计算复杂度为O(n2-n),节点的脆弱性与连接关系进行匹配的计算复杂度为O(m(n2-n));在防御实例化与去除孤立节点阶段,遍历其所有节点的出、入节点的边的计算复杂度为O(9n2-3n).综上可知,该算法的计算复杂度为O(n2)数量级.攻防图G的节点可以提取网络状态,攻防图G的边可以提取攻防动作.
3 基于WoLF-PHC的博弈分析与策略选取
本节将强化学习机制引入到有限理性随机博弈中,采用WoLF-PHC算法在AD-SGM基础上进行防御策略选取.
3.1 WoLF-PHC算法原理
3.1.1 Q-learning算法
Q-learning[20]是WoLF-PHC算法的基础,是一种典型的免模型强化学习算法,其学习机制如图2所示.Q-learning中Agent通过与环境的交互获得回报和环境状态转移的知识,知识用收益Qd来表示,通过更新Qd来进行学习.其收益函数Qd为
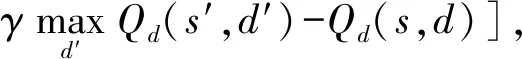
(1)
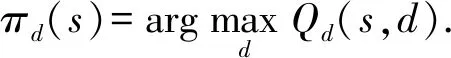

Fig. 2 Q-learning learning mechanism图2 Q-learning学习机制
3.1.2 PHC算法
爬山策略(policy hill-climbing)算法[5]是一种适用于混合策略的简单实用的梯度下降学习算法,是对Q-learning的改进.PHC的状态-动作收益函数Qd与Q-learning相同,但不再沿用Q-learning的策略更新方式,而是通过执行爬山算法对混合策略πd(sk)进行更新,δ为策略学习率.
πd(sk,di)←πd(sk,di)+Δskdi,
(2)
其中:
(3)
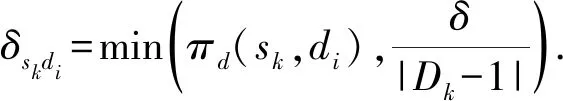
(4)
3.1.3 WoLF-PHC算法
WoLF-PHC(狼爬山策略)算法是对PHC算法的改进.通过引入WoLF机制,使防御者具有2种不同的策略学习率,当获胜时采用低策略学习率δw,当失败时采用高策略学习率δl,如式(5)所示.2个学习率使得防御者在比预期表现差时能快速适应攻击者的策略,比预期表现好时能谨慎学习.最重要的是WoLF机制的引入,保证了算法的收敛性[5].WoLF-PHC算法采用平均策略作为胜利和失败的判断标准:
(5)

(6)
C(s)=C(s)+1.
(7)
3.2 基于资格迹的改进WoLF-PHC及防御决策算法
为了提高WoLF-PHC算法的学习速度,减少算法对数据量的依赖程度,引入资格迹对WoLF-PHC进行改进.资格迹能跟踪最近访问的特定状态-动作轨迹,然后将当前回报分配给最近访问的状态-动作.WoLF-PHC算法是对Q-learning算法的扩展,目前有很多资格迹与Q-learning结合的算法,本文借鉴其中典型的Peng’sQ(λ)算法[21]对WoLF-PHC进行改进.定义每个状态-动作的资格迹为e(s,a),设当前网络状态为s*,资格迹更新:
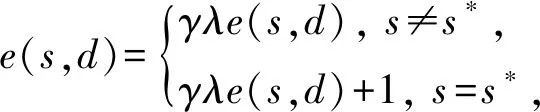
(8)
其中,λ为轨迹衰减因子.
WoLF-PHC算法由Q-learning算法扩展而来,属于off-policy算法,即在每个网络状态评估防御动作时使用greedy policy,而选择执行防御动作时为了学习偶尔会引入non-greedy policy.为了保持WoLF-PHC算法的off-policy特点,采用式(9)~(12)对状态-动作值进行更新,其中d*为在s*被选择执行的防御动作.由于只有最近被访问的状态-动作对的资格迹才会明显大于0,而其余绝大数状态-动作对的资格迹几乎为0.为了减少资格迹带来的内存和运算时的消耗,在实际应用时可以只保存和更新最近状态-动作对的资格迹.
Qd(s*,d*)=Qd(s*,d*)+αρ*,
(9)
Qd(s,d)=Qd(s,d)+αρge(s,d),
(10)

(11)
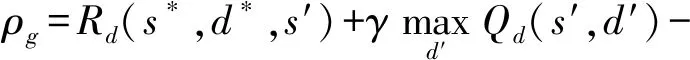
(12)

WoLF-PHC中的Agent对应攻防随机博弈模型AD-SGM中的防御者,Agent的状态对应AD-SGM中的博弈状态,Agent的行为对应AD-SGM中的防御动作,Agent的立即回报对应AD-SGM中的立即回报,Agent的策略对应AD-SGM中的防御策略.
在上述基础上给出具体的防御决策算法.算法2行①是对攻防随机博弈模型AD-SGM和相关参数的初始化,其中网络状态和攻防动作由算法1提取,行②是防御者检测当前网络状态,行③~是进行防御决策和在线学习,其中行④~⑤是依据当前策略选取防御动作,行⑥~是利用资格迹对收益Qd进行更新,行~是依据新的收益Qd利用爬山算法更新防御策略πd.
算法2.防御决策算法.
输入:AD-SGM;参数α,δ,λ和γ;
输出:防御动作d.
① initialize AD-SGM,C(s)=0,e(s,d)=0;
②s*=get(E);*从网络E中获取当前网络状态*
③ repeat:
④d*=πd(s*);*选取防御动作*
⑤ Outputd*;
⑥s′=get(E);

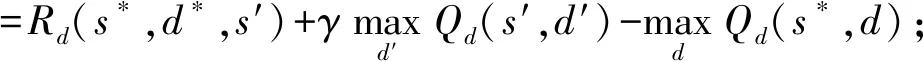
⑨ for each state-action pair (s,d) except (s*,d*) do
⑩e(s,d)=γλe(s,d);
∀d∈D(s*);
4 实验分析
4.1 实验场景描述
为验证本文方法的有效性,搭建如图3所示的典型企业网络进行实验.攻防事件发生在内网,攻击者来自外网.网络管理员作为防御者,负责内网的安全.由于防火墙1和防火墙2的设置,导致外网正常用户只能访问Web服务器,而Web服务器可以访问数据库服务器、FTP服务器和电子邮件服务器.利用Nessus工具对实验网络进行扫描,实验网络脆弱性信息如表1所示.
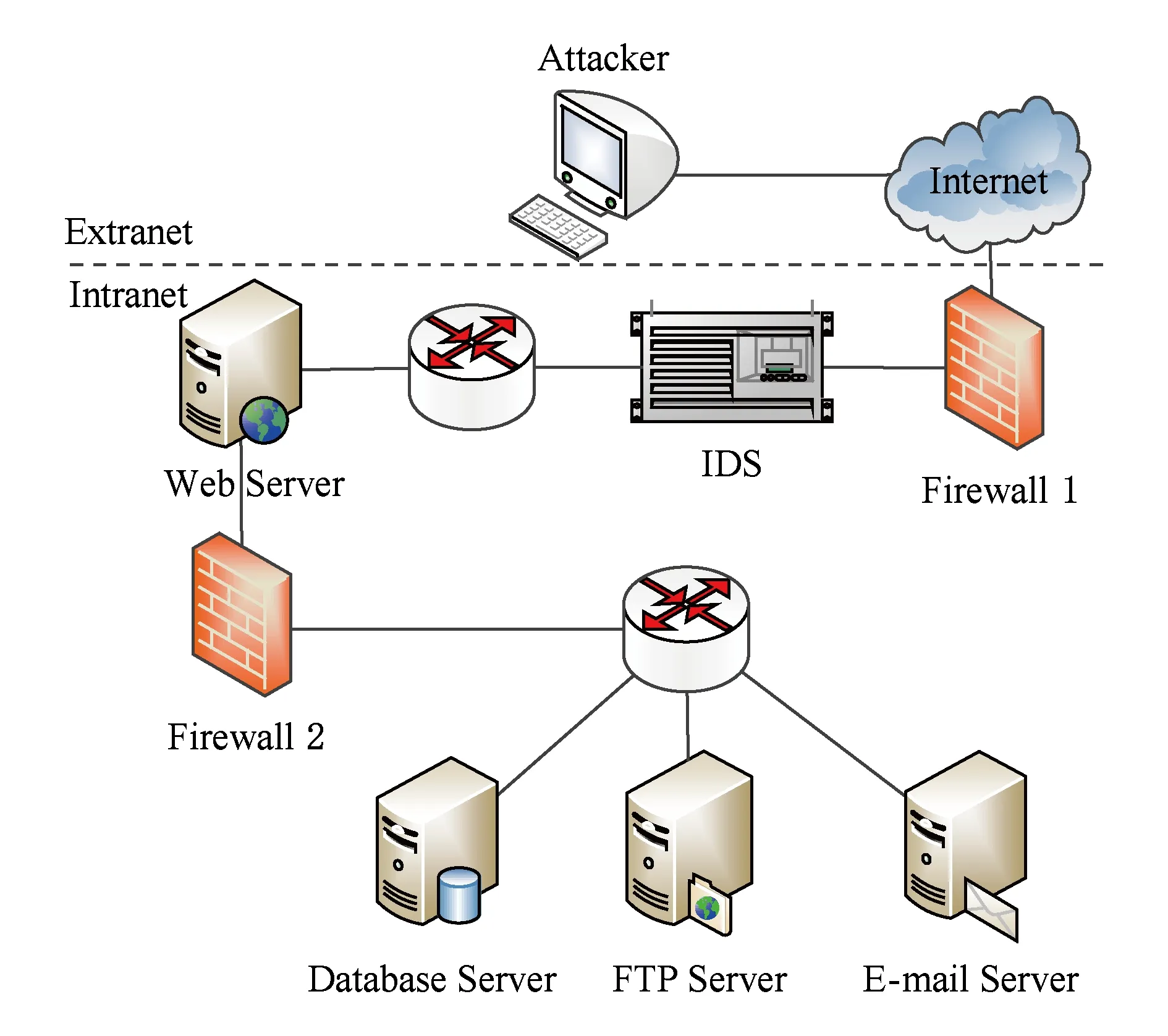
Fig. 3 Experimental network topology图3 实验网络结构
参考MIT林肯实验室攻防行为数据库构建攻击、防御模板,采用A标识攻击者主机、W标识Web服务器、D标识数据库服务器、F标识FTP服务器、E标识电子邮件服务器,利用算法1生成网络攻防图,为便于展示和描述,将攻防图分为攻击图和防御图,分别如图4和图5所示.防御图中防御动作含义如表2所示.

Table 1 Network Vulnerability Information表1 网络脆弱性信息
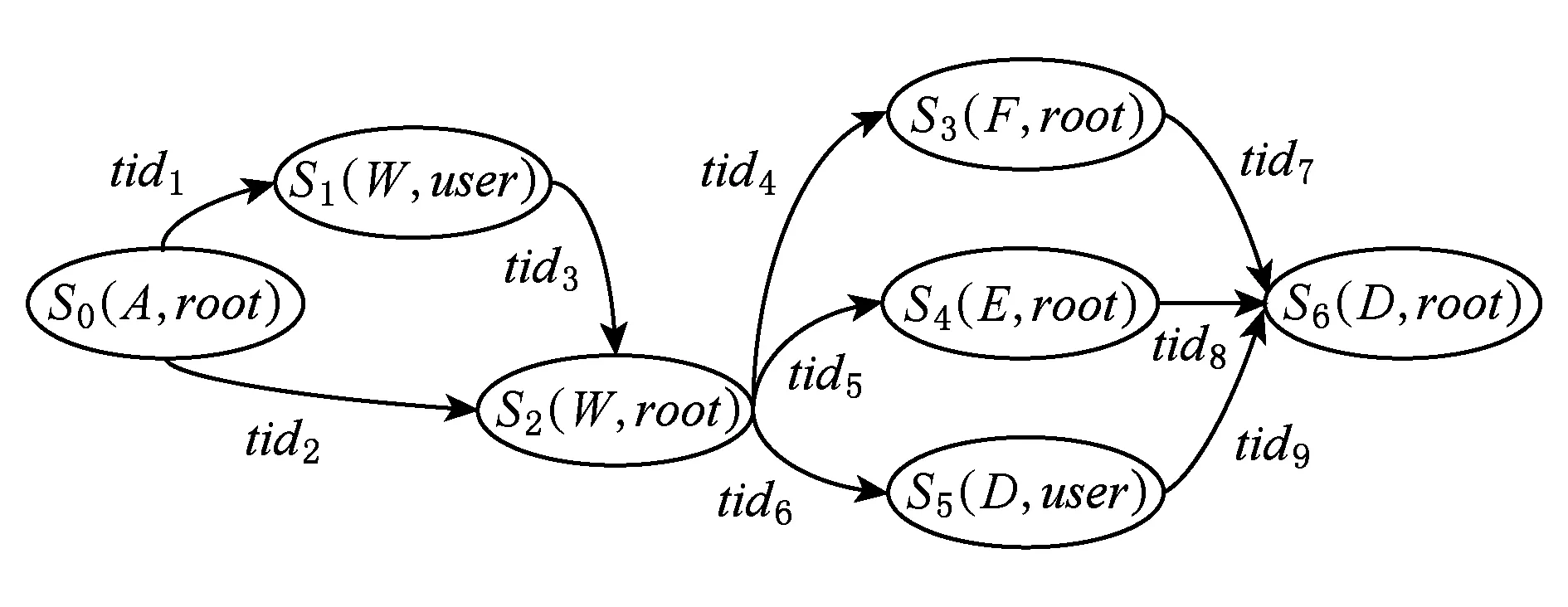
Fig. 4 Attack graph图4 攻击图

Fig. 5 Defense graph图5 防御图
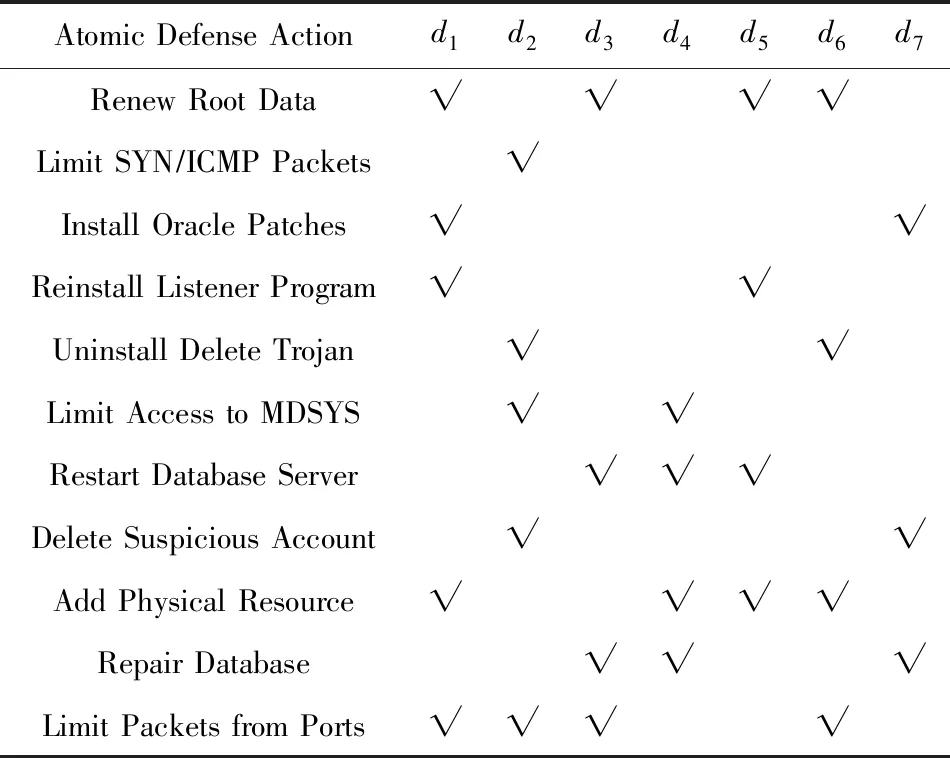
Atomic Defense Actiond1d2d3d4d5d6d7Renew Root Data√√√√Limit SYN∕ICMP Packets√Install Oracle Patches√√Reinstall Listener Program√√Uninstall Delete Trojan√√Limit Access to MDSYS√√Restart Database Server√√√Delete Suspicious Account√√Add Physical Resource√√√√Repair Database√√√Limit Packets from Ports√√√√
Note: “√” meansdicontain the atomic defense action.
4.2 构建实验场景的AD-SGM
①N=(attacker,defender)为参与博弈的局中人,分别代表网络攻击者和防御者.
② 随机博弈状态集合S=(s0,s1,s2,s3,s4,s5,s6),随机博弈状态由网络状态组成,由图4和图5中的节点提取.
③ 防御者动作集合为
D=(D0,D1,D2,D3,D4,D5,D6),
其中,D0={NULL},D1={d1,d2},D2={d3,d4},D3={d1,d5,d6},D4={d1,d5,d6},D5={d1,d2,d7},D6={d3,d4},由图5的边提取.
④ 防御者立即回报Rd(si,d,sj)的量化[12,22]结果为
(Rd(s0,NULL,s0),Rd(s0,NULL,s1),Rd(s0,NULL,s2))=(0,-40,-59);
(Rd(s1,d1,s0),Rd(s1,d1,s1),Rd(s1,d1,s2),Rd(s1,d2,s0),Rd(s1,d2,s1),Rd(s1,d2,s2))=(40,0,-29,5,-15,-32);
(Rd(s2,d3,s0),Rd(s2,d3,s1),Rd(s2,d3,s2),Rd(s2,d3,s3),Rd(s2,d3,s4),Rd(s2,d3,s5),Rd(s2,d4,s0),Rd(s2,d4,s1),Rd(s2,d4,s2),Rd(s2,d4,s3),Rd(s2,d4,s4),Rd(s2,d4,s5))=(24,9,-15,-55,-49,-65,19,5,-21,-61,-72,-68);
(Rd(s3,d1,s2),Rd(s3,d1,s3),Rd(s3,d1,s6),Rd(s3,d5,s2),Rd(s3,d5,s3),Rd(s3,d5,s6),Rd(s3,d6,s2),Rd(s3,d6,s3),Rd(s3,d6,s6))=(21,-16,-72,15,-23,-81,-21,-36,-81);
(Rd(s4,d1,s2),Rd(s4,d1,s4),Rd(s4,d1,s6),Rd(s4,d5,s2),Rd(s4,d5,s4),Rd(s4,d5,s6),Rd(s4,d6,s2),Rd(s4,d6,s4),Rd(s4,d6,s6))=(26,0,-62,11,-23,-75,9,-25,-87);
(Rd(s5,d1,s2),Rd(s5,d1,s5),Rd(s5,d1,s6),Rd(s5,d2,s2),Rd(s5,d2,s5),Rd(s5,d2,s6),Rd(s5,d7,s2),Rd(s5,d7,s5),Rd(s5,d7,s6))=(29,0,-63,11,-21,-76,2,-27,-88);
(Rd(s6,d3,s3),Rd(s6,d3,s4),Rd(s6,d3,s5),Rd(s6,d3,s6),Rd(s6,d4,s3),Rd(s6,d4,s4),Rd(s6,d4,s5),Rd(s6,d4,s6))=(-23,-21,-19,-42,-28,-31,-24,-49).
⑤ 为了更充分地检测算法的学习性能,防御者的状态-动作收益Qd(si,d)初始化时统一置0,不引入额外的先验知识.

4.3 测试与分析
本节的实验有3个目的:1)为了测试不同参数设置对算法的影响,从而找出适用于本场景的实验参数;2)将本文方法与现有典型方法进行对比,验证本文方法的先进性;3)测试基于资格迹对WoLF-PHC算法改进的有效性.

Fig. 6 Defense decision making under different parameter settings图6 不同参数设置下的防御决策
由图4和图5可知,状态s2的攻防策略选取情况最复杂、最具有代表性,故实验选取状态s2对算法的性能进行分析,其余网络状态分析方式相同不再赘述.
4.3.1 参数测试与分析
不同的参数取值会影响学习的速度和效果,目前并没有相关理论能够确定具体的参数设置.第4节中对相关参数做了初步分析,在此基础上,这里对不同的参数设置做进一步测试,寻找适用于本攻防场景的参数设置.实验对6种不同的参数设置进行了测试.具体的参数设置如表3所示.实验中攻击者初始策略为随机策略,学习机制与本文方法相同.

Table 3 Different Parameter Settings表3 不同参数设置
防御者在状态s2对防御动作d3和d4的选择概率结果如图6所示.从图6中可以观测不同参数设置下算法的学习速度和收敛性.图6中显示设置参数Set1,Set3,Set6的学习速度较快,3种设置下算法经过1 500次以内的学习即可得到最佳策略,但Set3和Set6的收敛性较差.虽然Set3和Set6能学习到最佳策略,但之后会出现震荡,没有设置Set1的稳定性好.防御收益可以代表算法对策略的优化程度,为了确保收益值不是只反应一次防御结果,取1 000次防御收益的平均值,其每1 000次的平均收益变化如图7所示.从图7中可以看到设置3的收益明显低于其他设置,但其他设置的优劣难以区分.为了更加直观地显示,对图7中不同设置下的25 000次防御收益计算平均值如图8所示.从图8中可以看到设置1和设置6的平均值较高,为了进一步对比,在平均值基础上进行一步计算标准差以反应收益的离散程度,如图9所示,设置1和设置2的标准差较小且设置1还要小于设置2.

Fig. 7 Defense return under different parameter settings图7 不同参数设置下的防御收益变化

Fig. 8 Average return under different parameter settings图8 不同参数设置下的平均收益
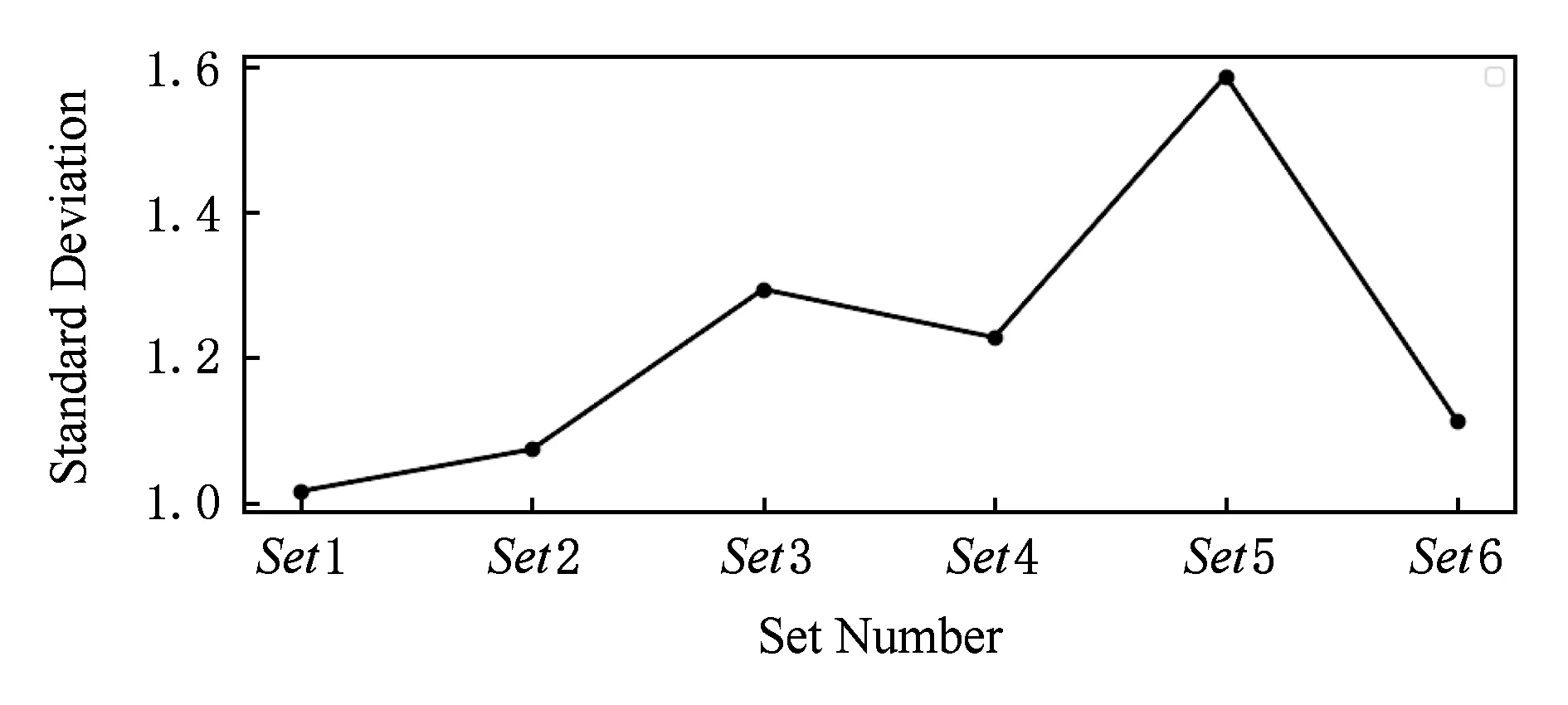
Fig. 9 Standard deviation of defense revenue under different parameter settings图9 不同参数设置下的防御收益标准差
综上可知:6组参数中设置1最适合于本场景.由于设置1已经取得了一个较理想的效果,能够满足实验需求,所以不再对参数做进一步的优化.
4.3.2 与典型博弈方法对比测试
本节选取随机博弈中文献[12]和演化博弈中文献[16]与本文方法进行对比实验.依据攻击者学习能力的差异,本节设计2组对比实验:第1组中攻击者学习能力较弱,不会针对攻防结果做出调整;第2组中攻击者学习能力较强,采取与本文方法相同的学习机制.2组实验中攻击者初始策略均为随机策略.
第1组实验中本文方法的防御策略如图6中的(a)所示.由文献[12]方法计算所得的防御策略为πd(s2,d3)=0.7,πd(s2,d4)=0.3,文献[16]的演化稳定均衡的防御策略为πd(s2,d3)=0.8,πd(s2,d4)=0.2.其每1 000次的平均收益变化如图10所示.由3种方法的策略和收益结果可知,本文方法能依据攻击者的策略进行学习从而调整到最优策略,因此本文方法能够获得最高收益.文献[12]的方法面对任何攻击者时都采取固定策略,当攻击者因受有限理性的约束而没有采取纳什均衡策略时,该方法所获收益较低.文献[16]方法虽然考虑了攻防双方的学习因素,但是模型所需参数很难准确量化,导致最终结果与实际存在偏差,因此该方法收益仍低于本文方法.

Fig. 10 Contrast of defense revenue change图10 防御收益变化对比
第2组实验中文献[12]和文献[16]计算结果仍为πd(s2,d3)=0.7,πd(s2,d4)=0.3和πd(s2,d3)=0.8,πd(s2,d4)=0.2,本文方法的决策如图11所示,本文方法在经过1 800次左右的学习后达到稳定,收敛到了与文献[12]相同的防御策略.从图12中可以看到,文献[16]的收益要低于其他2种方法,本文方法在前2 000次防御的平均收益要高于文献[12],随后与文献[12]的收益大体相同.结合图11和图12可知,具有学习能力的攻击者在初始阶段无法得到纳什均衡策略,此时本文方法要优于文献[12],当攻击者经过学习得到纳什均衡策略后,本文方法也能收敛到纳什均衡策略,此时本文方法与文献[12]性能相同.
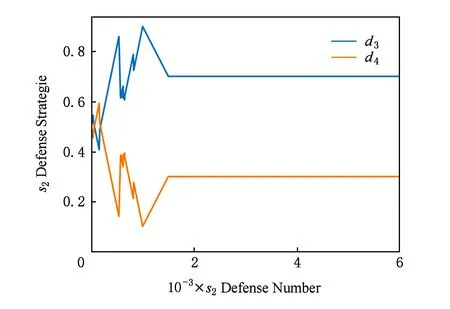
Fig. 11 Defense decision-making method in this paper图11 本文方法的防御决策
综上,可知当面对学习能力较弱的攻击者时,本文方法优于文献[12]和文献[16]的方法.当面对学习能力较强的攻击者时,如果攻击者尚未通过学习得到纳什均衡,此时本文方法仍然优于文献[12]和文献[16];如果攻击者通过学习得到纳什均衡,此时本文也能通过学习得到与文献[12]相同的纳什均衡策略,取得与其相同的效果,并优于文献[16].
4.3.3 有无资格迹的对比测试
本节关于资格迹对算法影响的实际效果进行测试.有无资格迹对策略选取的影响结果如图13所示.从图13中可以看到有资格迹时算法的学习速度较快,经过1 000次的学习后即可收敛到最优策略,而没有资格迹时,算法需要经过2 500次左右的学习才能够收敛.

Fig. 13 Comparison of defense decision making图13 防御决策对比
每1 000次的平均收益变化对比如图14所示.从图14中可以看到收敛以后有、无资格迹时算法的收益大体相同.从图14中可以看到收敛前的3 000次防御,有资格迹收益要比无资格迹的收益高,为了对其进一步验证,分别统计有、无资格迹下前3 000次防御收益的平均值,各统计10次,结果如图15所示.图15进一步证明在收敛前的防御阶段,有资格迹要比无资格迹的防御效果好.

Fig. 14 Contrast of defense revenue change图14 防御收益变化对比

Fig. 15 Contrast of average defense revenue图15 平均防御收益对比
资格迹的引入加快了学习速度,同时也会带来额外的内存和运算开销.实验中只保存最近被访问的10个状态-动作对,有效减少了内存消耗的增加.为了测试资格迹带来的运算开销,分别统计了20次有、无资格迹时算法进行10万次防御决策的时间,其20次的平均值为:有资格迹9.51 s,无资格迹3.74 s.虽然资格迹的引入会使得决策时间增加近2.5倍,但是引入资格迹后10万次的决策所需时间仍然只有9.51 s,仍可以满足实时性的需求.
综上,引入资格迹后,以牺牲少量内存和运算开销,可以有效增加算法的学习速度,提高防御收益.
4.4 方法综合比较
本文方法与一些典型研究成果综合对比,如表4所示:
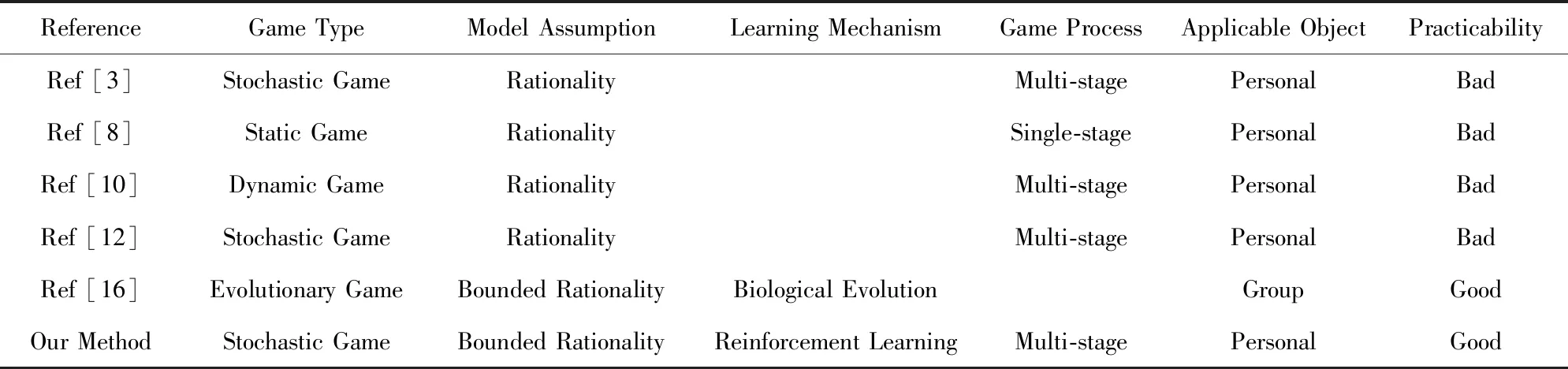
Table 4 Comprehensive Comparison of Typical Methods表4 典型方法综合比较
文献[3,8,10,12]以完全理性假设为前提,其所得的均衡策略在实际中很难出现,对实际的防御决策指导作用较低.文献[16]和本文以有限理性假设为前提,更具有实用性,但文献[16]基于生物进化理论,主要针对群体演化进行研究,其博弈分析的核心不是参与人的最优策略选择,而是有限理性参与人组成的群体成员的策略调整过程、趋势和稳定性,且此处的稳定性是指群体成员采用特定策略的比例不变,而不是某个参与人的策略不变,该方法不适用于指导个体实时决策.相比之下,本文方法的防御者采用强化学习机制,是在与攻击者对抗中依据系统的反馈进行学习,更适用于个体策略的研究.
5 结束语
本文针对防御决策问题,在有限理性的约束下将网络攻防对抗抽象为一个随机博弈问题.在模型构建时提出了一种以主机为中心的攻防图模型用于网络状态及攻防动作提取并设计了攻防图生成算法,有效压缩了博弈状态空间;在模型求解时提出了一种基于WoLF-PHC的防御决策方法,使得有限理性下的防御者在面对不同攻击者时都能做出最优选择;基于资格迹对WoLF-PHC算法进行了改进,加快了防御者的学习速度,减少了算法对数据的依赖.本文方法既满足了有限理性的约束,又不需要防御者获知过多攻击者信息,是一种实用防御决策方法.
下一步拟针对具体攻防场景对WoLF-PHC算法中的输赢标准做进一步优化,以加快防御者学习速度,增加防御收益.
