基于改进K均值聚类算法的星点聚类研究
2019-05-14夏永泉孙静茹WUXinwen谢希望
夏永泉,孙静茹,WU Xin-wen,支 俊,王 兵,谢希望
基于改进K均值聚类算法的星点聚类研究
夏永泉1,孙静茹1,WU Xin-wen2,支 俊1,王 兵1,谢希望1
(1. 郑州轻工业学院计算机与通信工程学院,河南 郑州 450000; 2.格里菲斯大学工程信息技术学院,昆士兰 布里斯班 4000)
针对高分辨率天文图像中的星点聚类研究中存在的2个问题:①天文图像的分辨率较高,且图像处理速度较慢;②选取何种聚类算法对天文图像中的星点进行聚类分析效果较好。在研究中,问题1采用图像分块的方法提高图像的处理速度;问题2提出了一种改进的K均值聚类算法,以解决传统的K均值聚类算法的聚类结果易受到值和初始聚类中心随机选择影响的问题。该算法首先在用K均值聚类算法对数据初步聚类的基础上确定合适的值,其次用层次聚类对数据聚类确定初始聚类中心,最后在此基础上再采用K均值聚类算法进行聚类。通过MATLAB仿真实验的结果表明,该算法的聚类结果与效率优于其他聚类算法。
k值;初始聚类中心;K均值聚类算法;层次聚类
对于天文图像中星点的提取识别,国内外众多专家学者都进行了研究,其中,王龙等[1]提出一种星敏感器星点聚类提取方法;全伟和房建成[2]提出一种基于蚁群聚类算法的快速星图识别方法;王春歆等[3]提出一种基于层次聚类的弱小目标检测算法。虽然这些文献通过聚类算法提取识别星点,但是很少对星点进行聚类分析的研究。
本文主要对天文图像中星点作聚类分析。星点聚类分析可采用的算法有很多,其中K均值聚类算法是最著名和最常用的方法之一。但是,由于传统的K均值聚类算法必须在聚类前设定值和随机选取聚类中心,最后得到的聚类结果会受到值和聚类中心的影响。若选取的值和聚类中心不合适,不仅会增加迭代的次数还会导致聚类结果不理想。张素洁和赵怀慈[4]提出一种算法,基于SSE (sum of the squared error)选取聚类个数,基于聚类中心点所在的周围区域相对比较密集、聚类中心点之间距离相对较远的选取原则来选取初始聚类中心;GUPTA等[5]提出一种混合PSO和K均值聚类的算法,用PSO算法优化K均值聚类的结果。魏建东等[6]提出基于DBI度量的层次初始的聚类个数自适应的聚类算法;陶莹等[7]通过全局化思想对K均值算法的改进,避免选取出初始聚类中心;CHAKRABARTY[8]提出一种质心初始化技术,用于K均值聚类算法;AKTHAR等[9]提出2种选取K均值聚类的初始聚类中心的方法,一种是从高密度区域选择最远距离的点作为初始聚类中心,另一种是从高密度区域选择最近距离的点作为初始聚类中心;CHOUHAN和PUROHIT[10]提出了基于PSO和K均值算法的文档聚类方法,通过在K均值聚类之前使用PSO方法进行寻找最优点并作为K均值聚类的初始聚类中心;丁明月和庄晓东[11]提出了自适应K均值算法,利用灰度直方图来确定初始聚类中心;于化龙和韩雪峰[12]提出改进K均值聚类算法的银行分类算法,根据类间最大相似度均值选择初始聚类中心;张红云和李萍萍[13]提出基于层次聚类的K均值算法研究,采用层次方法对文档进行初始聚类,得到的聚类总数作为K均值算法中的值,在此基础上,通过K均值聚类对聚类结果进行修订。
上述文献用到了各种方法来确定值和优化初始聚类中心,但本文提出一种新的方法来确定初始聚类中心,①通过K均值聚类算法的聚类准则函数值来确定合适的值;②使用经过层次聚类算法聚类后的结果计算出对应的聚类中心作为初始聚类中心;③在此基础上进行K均值聚类。
1 算法描述
由于天文图像的分辨率一般都比较大,所以直接对天文图像进行星点聚类效率很低甚至不能实现,因此本文进行聚类算法前先对天文图像进行分块,之后再对每一块子图像进行特征提取,确定合适的值和初始聚类中心,其次完成每一块子图像的星点聚类,最后以每一块子图像的聚类中心作为新的数据,采用本文聚类算法进行聚类得到整幅天文图像的聚类结果。
1.1 图像分块
一般图像分块是将1幅图像分为若干个图像块,如2×2,4×4,8×8。而本文采用的分块机制与之不同。本文采用的是按照一定大小的对图像依行列的方式直接进行分块,即将1幅高分辨率的天文图像按照分辨率的大小分成若干块。假定原始图像I经过灰度转换后分辨率大小为,设置子图像的宽高大小为,取值为2(=1,2,3,4,···),则天文图像被分成()×()块。
1.2 星点聚类特征的选取
本文选取颜色及纹理2类特征。其原因是从直观上观察每个星点的大小、明暗度、颜色以及光芒如何发散的不同,而颜色特征可以反映星点的明暗度和颜色,纹理特征可以反映星点的大小和光芒如何发散的。
1.2.1 颜色特征
大部分的彩色图像是基于RGB颜色3基色模型,但是RGB颜色空间体制并不适应人的视觉特点。所以本文采用更加符合人眼视觉特征的HIS颜色空间。HSI颜色空间模型是色调(ue)、饱和度(Saturation)和强度(Identity)首字母的简称。H表示颜色的种类,S表示颜色的纯度,I表示亮度信息。HSI颜色空间是由RGB颜色空间转换得来的,转换关系如下
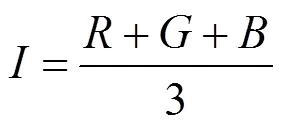
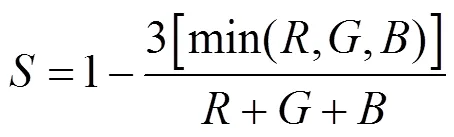
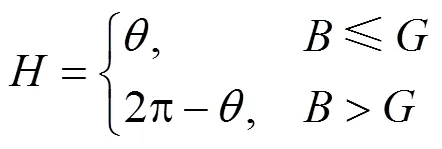
其中
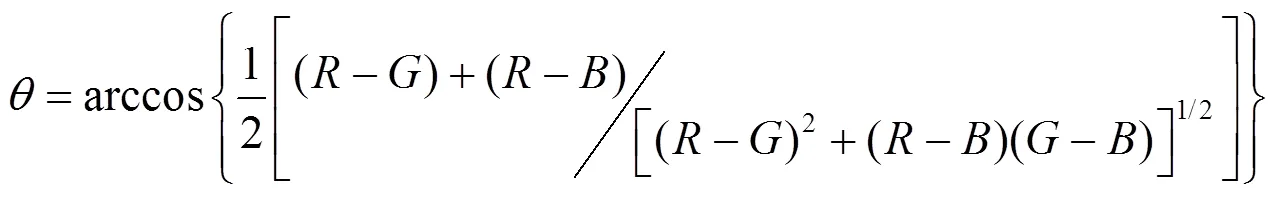
1.2.2 纹理特征
纹理特征提取有多种方法,如灰度差分统计、自相关函数、灰度共生矩阵等。本文使用灰度共生矩阵描述纹理。1幅图像的灰度共生矩阵能反映图像灰度方向,相邻间隔和变化幅的综合信息。为了能够更加直观地以共生矩阵描述纹理状况,选取以下5个标量来表征灰度共生矩阵的特征。
(1) 能量。是灰度共生矩阵元素值的平方和,反映了图像灰度分布均匀程度和纹理粗细度。
(2) 对比度。反映了图像的清晰度和纹理沟纹深浅的程度。返回整幅图像中像素和其相邻像素之间的亮度反差。
(3) 相关性。是度量灰度共生矩阵元素在行列方向上的相似程度,因此,相关性的值反映了图像中局部灰度相关性。返回整幅图像中像素与其相邻像素是如何相关的度量值。
(4) 熵。是图像所具有的信息量的度量。表示图像中纹理的非均匀程度或复杂程度。
(5) 平稳度。反映图像纹理的同质性,度量图像纹理局部变化的多少。返回度量灰度共生矩阵中元素的分布到对角线紧密程度。
综合以上2种特征,可以定义一个样本有8个特征值,则可以看作是一个8维的特征向量,即
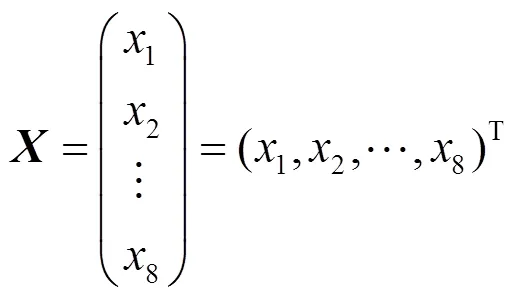
其中,1为对比度;2为相关性;3为熵;4为均匀度;5为能量;6为,7为,8为。
1.3 k值(聚类个数)的确定
传统的K均值聚类算法中的值必须是用户人为最先确定,即分成多少类。但是合适的值,用户是不可知的。因此本文通过对星点进行不同值下的K均值聚类算法,选取合适的值。选取适当的值的一个普遍方法是通过遍历得到某一范围聚类数的误差平方和。误差平方和准则是一种简单而又广泛应用的聚类准则,以评价聚类的优劣。
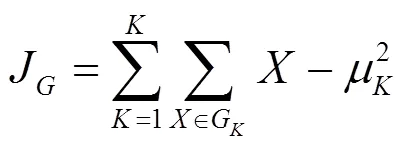
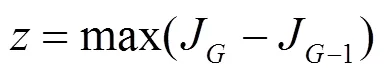
1.4 初始聚类中心的确定
传统的K均值聚类算法在聚类前随机选取聚类中心,并根据初始聚类中心进行循环迭代,直到聚类中心不在变化停止。因此,初始聚类中心的不同可能导致聚类结果的不稳定,会产生多个局部最优值。
本文算法通过以层次聚类作为前期处理,得到初步聚类结果,根据聚类结果选择相应的聚类中心的方法优化初始聚类中心。以此聚类中心作为K均值聚类的算法的初始聚类中心,进行K均值聚类算法。
前期处理中层次聚类是首先定义样本之间和类与类之间的距离,在各自成类的样本中,将距离最近的2类合并,重新计算新类与其他类间的距离,并按最小距离归类。重复此过程,每次减少一类,直到所有的样本称为一类为止。
根据式(4)定义包含个数据的特征值矩阵可用一个行8列的矩阵表示。那么第个样品和第个样品的特征值向量见式(7),2个样品的距离可根据欧式距离式(8)求得d,即
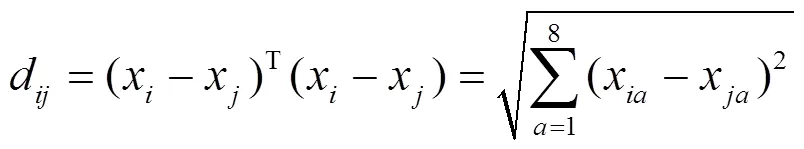
类与类之间的距离选取的是ward距离,用D表示第个类G到第个类G的距离。先计算1,2,···中各样本与类重心(即均值)的欧氏距离,然后将之取平方求和,得出结果称为离差平方和。若通过计算,把距离最近的2个类(G和G)合并,使之成一个新的类(G),那么这2个类(G和G)和合并后的新类G的离差平方和分别为[14]式(9)~(11),即
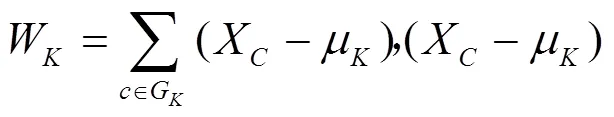
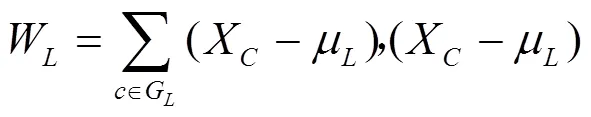
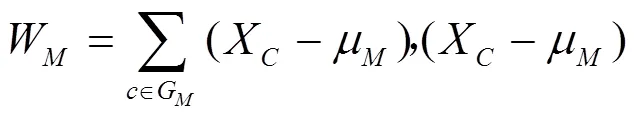
其中,

μ,μ,μ分别为类G,G,G的重心;W,W,W为各自类内样本分散程度的度量。G和G之间平方距离表示为
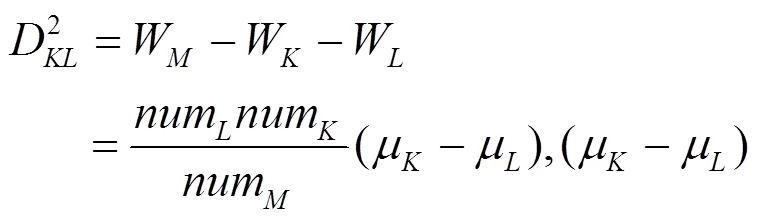
根据欧氏距离和ward距离完成层次聚类,并根据层次聚类的聚类结果计算出相应的聚类中心。聚类中心以某一类中的所有样本特征的平均值表示,根据式(13)可计算出其特征值,即
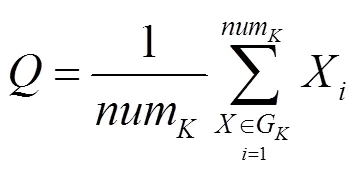
1.5 星点聚类
由于图像分辨率较大,所以在聚类分析时,需对每块子图像进行星点聚类分析,再对子图像之间进行聚类分析从而得到整幅天文图像的聚类分析。
1.5.1 子图像的星点聚类
首先通过腐蚀膨胀提取出每个图像块中的星点,并提取其纹理特征和颜色特征。其次对同1幅图像作3种方法的聚类分析,且分别记录聚类时间和误差平方和的值。
(1) 传统的K均值聚类算法。首先在整个数据集中任意选取个数据作为初始聚类中心,然后根据其他数据对象与个聚类中心的距离大小,将数据对象划分到距离最近的相似类中。所有数据划分后,重新计算个聚类中每个聚类的全部数据对象的平均值,该平均值所在的数据点作为新的聚类中心,经过多次迭代,直到连续2次的聚类中心相同,说明此时数据对象类别划分完毕,即得到个聚类。
(2) 文献[5]方法。一种混合PSO和K均值聚类的算法,用PSO算法优化K均值聚类的结果。先进行一次传统的K均值聚类算法,再对得到的聚类结果运用PSO算法优化。
(3) 本文方法也称改进的K均值聚类算法。通过算法确定值和初始聚类中心。将传统的K均值聚类算法改进成了一种自适应选取值的并优化了初始聚类中心的K均值聚类算法。
1.5.2 整幅图像的星点聚类
若对整幅图像直接进行聚类分析,时间过长甚至得不到结果,所以需要通过对子图像之间的聚类分析得到整幅图像的值,即可将整幅图像中的星点分成若干类。本文算法如下:
(1) 对每块子图像进行聚类分析。根据式(4),式(5)和式(11)得到每块图像的值和每一类的聚类中心的特征值。通过循环得到所有的子图像的聚类中心的特征值矩阵;
(2) 对聚类中心的特征值矩阵采用本文算法进行聚类分析,得到的聚类结果中的值就是整幅图像的值。
2 实验结果与分析
2.1 实验平台
实验平台选取matlabR2013b,4核CPU i5-3470,内存4 GB,操作系统Windows 8。
2.2 实验结果与分析
聚类实验中将分辨率为40000×30131的天文图像按照2048×2048大小的分块分辨率分成图像块,对每一个图像块中的星点进行3种方法的聚类分析,得到3种算法的聚类准则函数值和聚类时间,并根据所有的图像块的聚类中心的聚类结果得到天文图像的值。
(1)值的确定。根据不同的值,对同一幅图像进行多次传统的均值聚类,分别得到聚类准则函数值。以一张图像为例,值与聚类准则函数值的关系变化如图1所示。
从图1可看出,随着值的增加,聚类准则函数值越小。其中在=3之后,聚类准则函数值的减少速度越来越平缓,而=3之前,聚类准则函数值的急剧减少,即星点分成3类比较合适。
(2) 分析3种算法聚类结果的优劣。选取多幅图像实验,证明改进后的算法得到的结果的优越性。由于传统的K均值聚类的结果具有不稳定性,所以选用多次结果的平均值作为最终结果。图像的分辨率较大所以分成的块数较多,因此任意选取其中的16组进行实验结果显示(表1)。选取的原则是对角线选取。实验结果见。
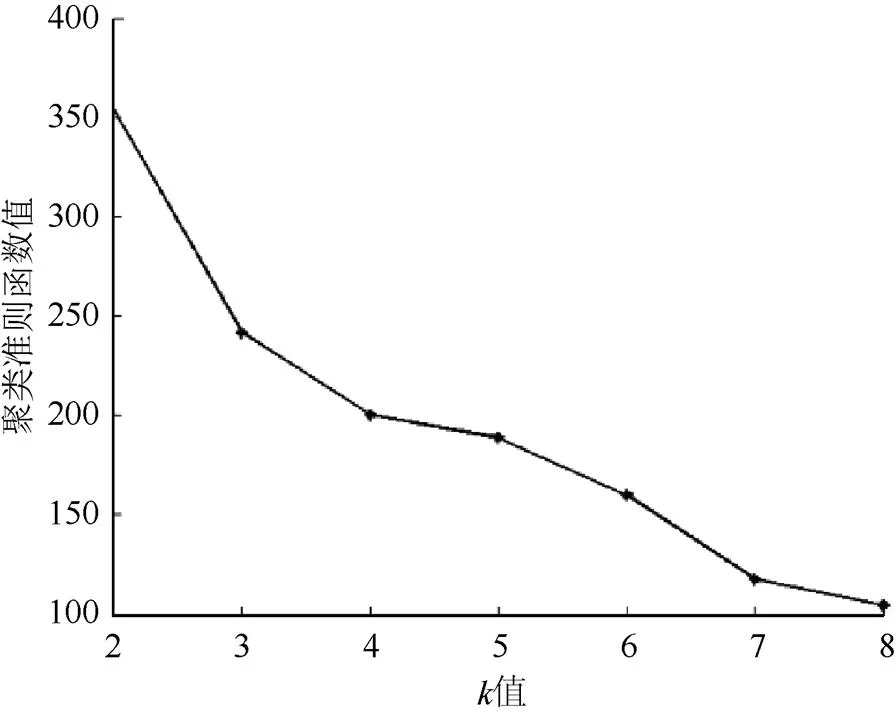
图1 k值与聚类准则函数值的关系变化图
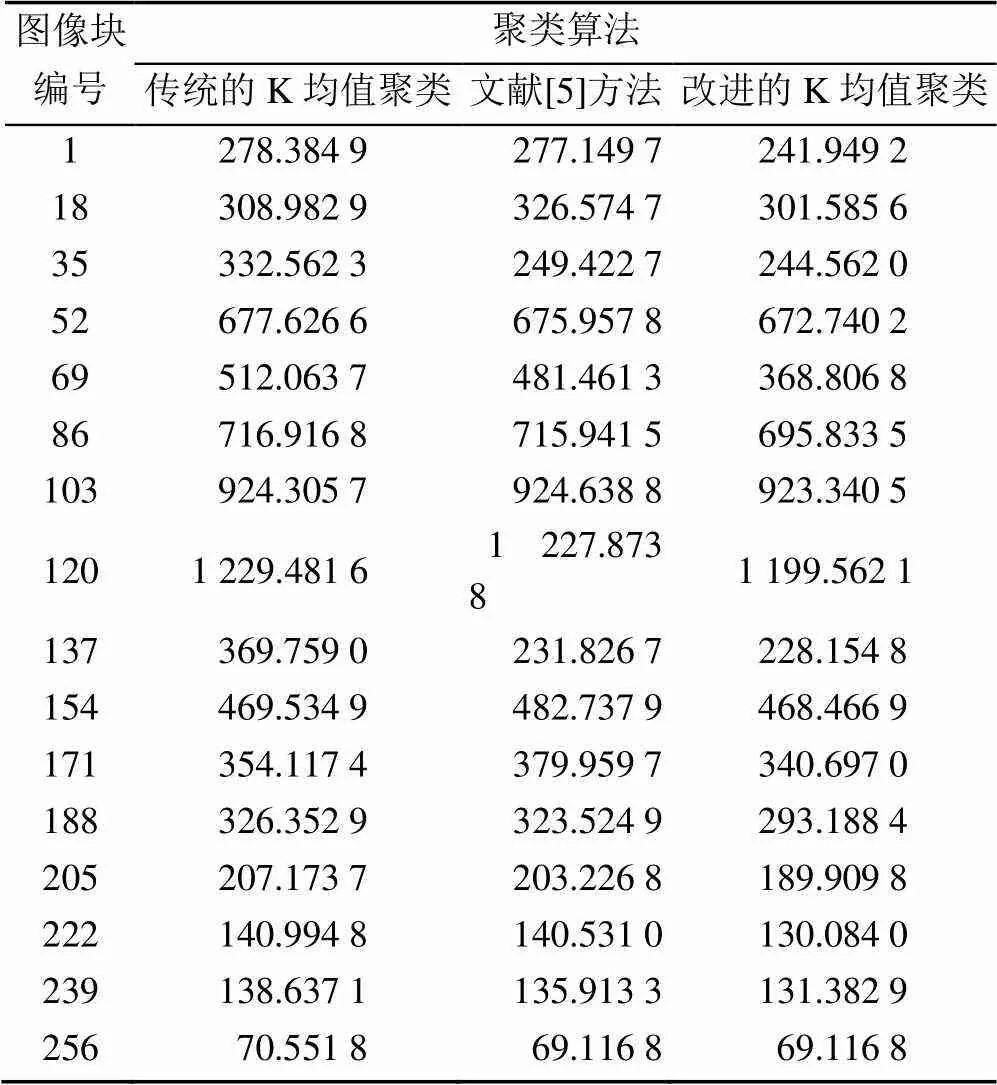
表1 聚类准则函数值表
聚类结果折线图如图2所示。
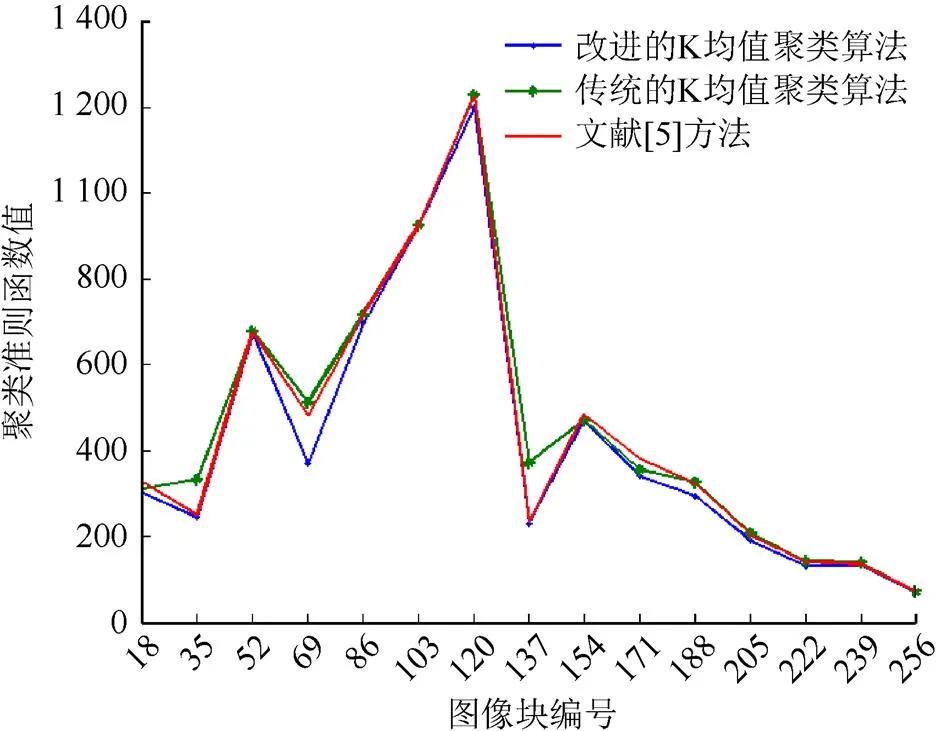
图2 聚类结果图
从表1可以看出,3种聚类算法的准则函数值相差的不大,只有几个数值相差较大,说明3种聚类算法在一些图像上进行聚类分析时差异性较大,但大部分图像的差异性较小。
从图2可以看出,改进的K均值聚类的每个结点的值都小于传统的K均值和文献[5]方法的聚类准则函数值,由于聚类准则函数值越小,代表聚类的效果越好,所以说明改进后的聚类结果优于传统的聚类结果和文献[5]的聚类结果。图3显示了部分聚类效果图。

(A1)(B1)(C1) (A2)(B2)(C2)
(3) 分析3种算法的速度。对同一幅图像分别采用3种算法聚类,分别记录其聚类时间。表2根据条件(2)中的图像所运行的聚类时间。
聚类时间折线图如图4所示。
从图4可以看出改进的K均值聚类时间和传统的K均值聚类时间均小于文献[5]方法的聚类时间,虽然文献[5]的聚类结果优于传统的K均值聚类算法,但是时间要高于传统的K均值聚类算法,因为文献[5]方法使用PSO算法优化K均值聚类结果,增加了时间消耗。改进的K均值聚类算法和传统的K均值聚类算法的聚类时间相差较小,但还是低于传统的K均值聚类算法,由于初始聚类中心的优化而减少了迭代次数,从而减少了聚类时间。故改进的K均值聚类算法优于其他两种方法。
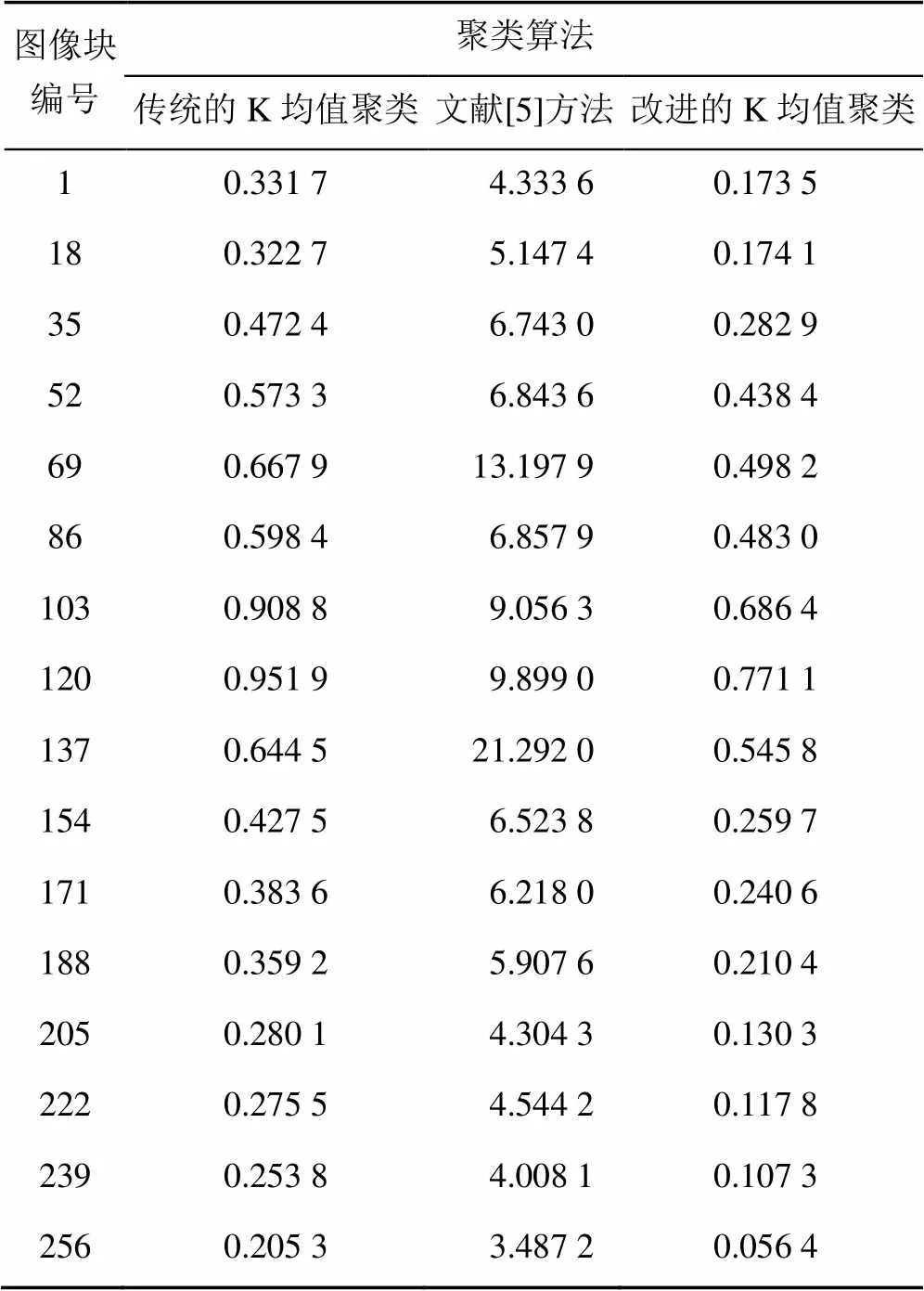
表2 聚类时间表
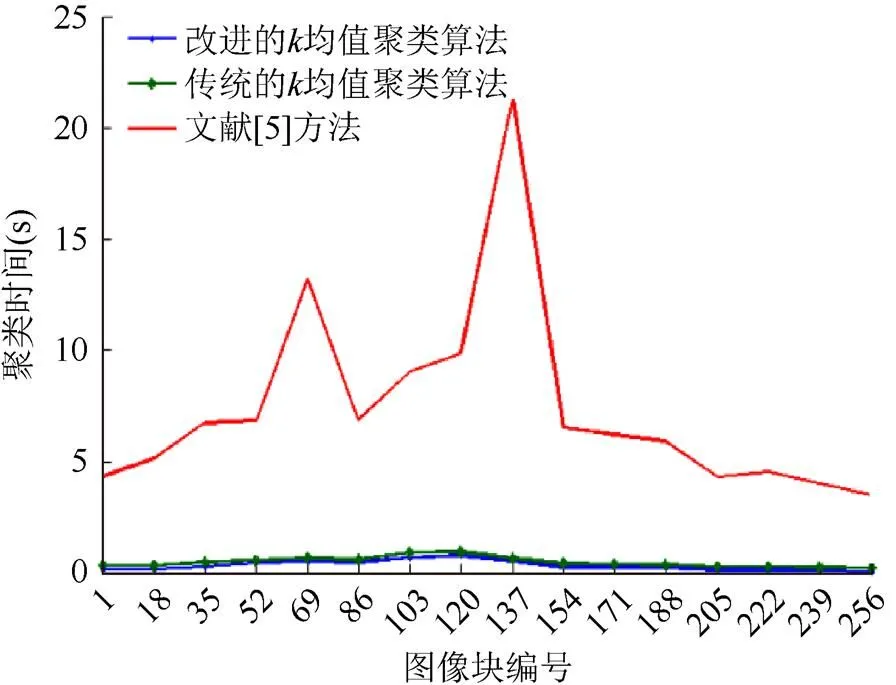
图4 聚类时间图
综上,改进的K均值聚类算法的聚类结果和效率优越于其他聚类算法。
3 结束语
本文针对高分辨率天文图像中星点聚类问题进行研究,利用改进的K均值聚类算法进行聚类分析。改进的K均值聚类算法通过不同值下的K均值聚类算法找到合适的值,采用层次聚类算法得到初步聚类结果,并计算出聚类中心,以此为K均值算法的初始聚类中心,在得到的值和初始聚类中心时进行K均值聚类算法。通过实验结果证明改进的K均值聚类算法的聚类结果和效率均比其他聚类算法优越,说明改进的K均值聚类算法更适用于星点聚类。
[1] 王龙, 杨孟飞, 钟红军, 等. 星敏感器星点聚类提取方法[J]. 中国科学: 技术科学, 2015(3): 257-262.
[2] 全伟, 房建成. 一种基于蚁群聚类算法的快速星图识别方法[J]. 宇航学报, 2008, 29(6): 1814-1818.
[3] 王春歆, 沈同圣, 张玉叶. 基于层次聚类的弱小目标检测算法[J]. 计算机工程与应用, 2006, 44(19): 24-27.
[4] 张素洁, 赵怀慈. 最优聚类个数和初始聚类中心点选取算法研究[J]. 计算机应用研究, 2017, 34(6): 1617-1620.
[5] GUPTA A, PATTANAIK V, SINGH M. Enhancing K means by unsupervised learning using PSO algorithm [C]//2017 International Conference on Computing, Communication and Automation. New York: IEEE Press, 2017: 228-233.
[6] 魏建东, 陆建峰, 彭甫镕. 一种层次初始的聚类个数自适应的聚类方法研究[J]. 电子设计工程, 2015(6): 5-8.
[7] 陶莹, 杨锋, 刘洋, 等. K均值聚类算法的研究与优化[J]. 计算机技术与发展, 2018, 28(6): 96-98.
[8] CHAKRABARTY A. An empirical seed initialization idea for K-Means algorithm inspired by CLIQUE algorithm [C]//2017 International Conference on Information Technology (ICIT). New York: IEEE Press, 2017: 21-23.
[9] AKTHAR N, AHAMAD M V, AHMAD S. MapReduce model of improved K-means clustering algorithm using Hadoop MapReduce [C]//Second International Conference on Computational Intelligence and Communication Technology. New York: IEEE Press, 2016: 192-198.
[10] CHOUHAN R, PUROHIT A. An approach for document clustering using PSO and K-means algorithm [C]//2018 2nd International Conference on Inventive Systems and Control (ICISC).New York: IEEE Press, 2018: 19-20.
[11] 丁明月, 庄晓东. 基于数据融合的K均值聚类彩色图像分割方法[J]. 青岛大学学报: 工程技术版, 2018, 33(2): 46-50, 62.
[12] 于化龙, 韩雪峰. 基于改进K均值聚类的银行客户分类算法[J]. 湘潭大学自然科学学报, 2018, 40(3): 129-132.
[13] 张红云, 李萍萍. 一种基于层次聚类的K均值算法研究[J]. 微计算机信息, 2010, 26(12): 228-229.
[14] 王学民. 应用多元分析[M]. 上海: 上海财经大学出版社, 2009.
Star Point Clustering Based on Improved K-Means Clustering Algorithm
XIA Yong-quan1, SUN Jing-ru1, WU Xin-wen2, ZHI Jun1, WANG Bing1, XIE Xi-wang1
(1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou Henan 450000, China; 2. Faculty of Engineering and Information Technology, Griffith University, Brisbane Queensland 4000, Australia)
Two problems in the study of star point clustering in high resolution astronomical images: ① The resolution of the astronomical image is higher, and the image processing speed is slower. ② Which clustering algorithm is selected to cluster the star points in the astronomical image is better. In the research, problem 1 uses image segmentation method to improve image processing speed. problem 2 proposes an improved K-means clustering algorithm to solve the traditional K-means clustering algorithm clustering results are susceptible to-value and The initial clustering center randomly selects the problem of impact. Firstly, the K-means clustering algorithm is used to determine the appropriate-value based on the preliminary clustering of data. Secondly, the clustering is used to determine the initial clustering center by data clustering. Finally, K-means clustering is used. The algorithm performs clustering. The simulation results of MATLAB show that the clustering results and efficiency of the algorithm are better than other clustering algorithms.
k-value; initial cluster center; K-means clustering algorithm; hierarchical clustering
TP 391.41
10.11996/JG.j.2095-302X.2019020358
A
2095-302X(2019)02-0358-06
2018-10-18;
2019-01-13
国家自然科学基金项目(81501547);河南省科技攻关项目(172102410080)
夏永泉(1972-),男,辽宁绥中人,副教授,博士。主要研究方向为图像处理、计算机视觉、模式识别与人工智能研究。 E-mail:694473762@qq.com
