基于随机森林方法的证券市场内幕交易行为识别
2019-05-09邓尚昆王晨光曹成航樊雅婷
邓尚昆, 王晨光, 曹成航, 樊雅婷
(1. 三峡大学 经济与管理学院, 湖北 宜昌 443002; 2. 三峡大学 金融研究所, 湖北 宜昌 443002)
一、背景
现代意义上的证券交易起源于1792年美国纽约证券交易所的诞生,从此证券市场日益发展壮大。在证券市场逐步演变为重要的资本市场的同时,形形色色的证券欺诈行为也随之产生。而其中数量最大、对证券交易公平性影响最恶劣的犯罪行为莫过于内幕交易(Insider Trading)。
各国政府对于证券市场内幕交易的打击与监管从未停止。美国政府为此专门成立了“证券交易管理委员会”(SEC,Securities and Exchange Commission),英国政府也专门成立了“审慎监管局”(PRA, Prudential Regulation Authority)与“金融行为监管局”(FCA,Financial Conduct Authority);日本政府针对证券市场上内幕交易行为也投入了大量的资源用以应对,并于1948年5月颁布《证券交易法》。由于内幕交易形式的不断变化,日本在1997年和2013年对证券交易法进行了修改与完善。在我国,政府对于内幕交易行为采取零容忍的态度,通过不断完善相关法律等手段加强监管力度,并于2011年实行了内幕信息知情人登记管理制度。
截至2017年底,中国证券市场(不包括香港证券交易所)总市值约7万亿美元,居世界第二位,成为世界金融市场重要的组成部分。然而,每年发生的众多内幕交易行为给证券市场及市场交易者造成了巨大损失。随着中国证券市场的不断发展,内幕交易手段的日益策略化、内幕交易主体构成的多元化与内幕交易形式的多样化、隐蔽化等特点,如何对内幕交易进行及时有效的监管与防治在未来一段时间内仍将是亟需解决的问题。事实上,早期关于内幕交易的理论研究大部分都局限在法学领域,并没有引起经济学界的广泛关注。早期的法律学者讨论的焦点主要是关于内幕交易行为是否是一种公平的行为,以及其是否对外部投资者的利益有所损害,由于缺乏严谨的逻辑理论框架,不能给出对内幕交易有效的识别方法。随着机器学习方法的发展,利用机器学习算法从大量数据中提取有效信息,并建立内幕交易识别模型辅助以往的人工监督审查将会成为监管方法的新趋势。
二、文献综述
目前,国内外学者关于内幕交易的研究多数是从法律论证与制度讨论等理论层面进行,针对内幕交易行为,从数据挖掘角度进行内幕交易行为识别的研究较少。其中,在公司治理体系与财务状况方面,Scott和John通过内部交易变量和公司具体财务数据特征对内幕交易行为进行甄别,并获得了60%的内幕交易甄别准确率[1]。Maug[2]从公司治理层面分析了大股东与上市公司管理人员串谋的可能性并指出禁止内幕交易可以促使公司价值与中小股东利益的最大化[3];Wu在研究中发现,上市公司股东权利越大,发生内幕交易行为的概率越大[4];唐其鸣与张云从公司治理层面考虑,发现企业治理较好的公司,其内幕交易发生的概率较低,实证结果也表明内幕交易发生的根本原因之一为公司治理不善[5];在证券市场相关性指标方面,Kyle[6]认为内幕交易造成股票买卖价差的提高与交易成本的增加,从而使证券市场流动性降低;汪贵浦[7]运用内幕交易行为发生过程中的信息含量建立Logistic二元辨别模型,获得了70.59%的正确率;孙开连等以内幕信息中大户持股集中度为敏感信息,对内幕交易行为的识别进行了实证分析与检验[8]。王春峰等[9]对回报率、波动性与交易量之间的变化关系进行了实证检验,并得出了我国证券市场上存在普遍的、程度较为严重的内部知情人通过内幕消息来操纵股价与公共信息私有化现象的这一结论;史永东与蒋贤峰[10]同样运用了Logistic法,通过换手率与收益率两个指标建立甄别模型,在0.5的阈值下正确率达到75%;张宗新等[11]选用了收益率、波动率、流动性等作为辨别指标,分别建立了Logistic模型和决策树模型对内幕交易行为进行识别;王春峰等使用信息交易概率作为衡量证券市场信息非对称程度的指标,建立了关于波动性、流动性与信息交易概率之间关系的回归模型,其实证结果表明在中国证券市场中信息交易概率与市场流动性正相关,而与市场波动性负相关[12]。张宗新[13]在其之前研究的基础上又进一步采用神经网格建立辨别模型并与决策树模型和Logistic模型进行了比较分析;沈冰与赵小康通过超额换手率、累计超额收益率、股价波动持久性、股价信息含量与股权制衡度五个指标利用支持向量机(SVM,Support Vector Machine)建立内幕交易识别模型[14]对内幕交易行为进行识别,这对机器学习方法识别内幕交易的发展具有重要的指导意义。
综合来看,国内外学者在内幕交易识别指标的选取上各有异同,分别从不同角度运用不同方法建立了辨别模型来加以分析,但在识别指标的计算中关于指标时间区间(时间窗口期的长度)的划定缺乏严谨的依据,且在识别指标之间对于识别结果的贡献度也无明确的分析和比较。内幕交易始发于内幕信息的泄露,而内幕信息通常形成于公司内部,因此,在内幕交易的识别过程中,公司治理层面可以看做是内在因素,市场微观指标的变化可以看做是外在表现。本文拟利用机器学习中的随机森林算法,因其具有较高鲁棒性、不易过拟合与可快速准确处理大量数据等特点[15],从公司股权结构、财务数据、治理体系以及证券市场微观表现方面综合筛选特征指标来对证券市场内幕交易样本进行训练与识别。
三、内幕交易识别的试验设计
1.识别样本的选取与处理
本文选用2001至2017年证监会公布的内幕交易案件作为阳性样本,其中同一上市公司不同时间段内多次发生过内幕交易的案件按照多个样本分别处理,并按照1∶1的数量选取阴性样本。为了尽可能排除指标外因素的影响(政策、市场、总体行情等),阴性样本的选取原则为与阳性样本从属于同一行业,并且在同一年发生过同一类重大事件且至今从未被证监会处罚过的上市公司。由于证监会公布的内幕交易案件中部分样本指标的数据存在部分缺失、阳性样本不存在满足控制变量条件下相应的阴性样本、发生内幕交易但没有确切记载内幕消息公示时间的样本等原因,为了提高识别模型的准确度与实际应用推广力,本文经剔除不合规样本,共筛选出阳性样本171个,对应的阴性样本共164个,合计共335个样本。相关数据主要来源于中国证券监督管理委员会官网①与东方财富网②。
2.识别指标的选取与处理
在利用数据特征研究内幕交易识别的过程中,首先要选择识别指标。能否从证券市场海量的数据中利用可以作为有效识别内幕交易的指标将影响内幕交易识别模型的精度。本研究从我国证券市场上市公司股票微观表现、财务数据、股权结构以及治理体系四个方面搜集相应数据进行识别指标的计算。然后在控制变量的角度下尽可能找出相同数量的未发生内幕交易的股票样本,并收集和计算特征指标,对部分存在缺失的数据采用一定方式填补或删除,最后完成所有样本识别指标的收集。其中:
(1)在证券市场微观表现方面,分别从波动性、收益性、流动性与风险层面考虑指标的选取。其中波动性指标通过GARCH模型用股价波动持久性衡量:
(1)
收益性指标分别选取样本股票相对同规模超额回报率、相对本市场超额回报率、相对同风险超额回报率,采用事件窗口期内累加求和的计算方式,另外,选用Sigma系数来衡量收益的波动性。
流动性指标选取在不同事件窗口期内的总股数换手率与流通股换手率的均值。风险层面选用Beta系数来衡量。
(2)在上市公司财务数据方面,从每股指标的角度上选取市盈率、市净率与市销率,从资本结构及其偿债能力角度上选取资产负债率、流动比率与速动比率,从营运能力角度上选取总资产周转率,从成长力的角度上选取营业收入增长率与总资产增长率,从盈利与收益能力角度上选取净资产收益率、资产收益率与营业利润比率。

表1 指标变量的选取
(3)在上市公司股权结构与治理方面选择CR5指数、CR10指数、Z指数、H5指数、H10指数、年度股东大会会议出席率。其中对于上市公司财务数据与股权结构治理数据指标的选取时间段,考虑到财务报表公示数据的滞后性与不同行业公司运营的差异性,本文统一选取内幕交易发生时间点上一年度末的相应数据。关于指标变量的选取详见表1。
对于证券市场微观指标的选取时间段,学者袁理[16],以及沈冰和赵小康[14]等都采用信息公告日前30个交易日为研究时间段,但选取时间段内是否真正发生完整的内幕交易行为对模型的识别重要度较高,证监会公布的处罚决定虽然公示了内幕交易案件参与人的整个账户流水,但对于内幕交易的起始期,无论从法律推理上还是在实际案件调查中都无法准确判别。若选取事件窗口期过长,影响数据的因素也会越多,则可能使建立的模型识别效果较差;反之,若选取事件窗口期过短,则有可能没有包含内幕交易发生的全部时间段,从而可能在较大程度上降低辨别模型的准确性与实际操作应用性。因此,本文分别选取内幕消息公示日期前30、60和90个交易日并对其相应的七种时序属性指标(Sigma系数、Beta系数、换手率、波动率与三种超额累计回报率指标)进行计算,再与其他指标一起代入分别建模并进行对比检验,选出最佳对应模型。在实际案件辨别应用中,研究者也可以根据情况分别选择不同事件窗口期进行辨别。通过查找与统计,在公布的内幕交易股票样本中存在指标数据的缺失。舍弃含有缺失数据的样本造成样本数量的减少一般会降低辨别模型的解释度,但利用含有缺失数据的样本过程中对其缺失数据处理不当形成的噪声又会对模型精确度产生干扰。本文借鉴肖亚明等[17]关于处理分类变量缺失数据的思想,采用以下处理原则:对于同一个样本对应不同指标数值缺失较多时予以舍弃;对于同一样本个别指标数值的缺失,利用其他未缺失该项指标的样本指标均值予以代替。相关数据指标主要来源于CCER经济金融数据库③与RESSET锐思金融研究数据库④。
四、基于随机森林的识别模型
1.随机森林算法
本文利用机器学习算法中的随机森林算法建立内幕交易的识别模型。随机森林是一个包含多个决策树的分类器,其输出的类别是由个别树输出的类别的众数而定,因此不仅克服了大量参数的选择问题、拥有较高的鲁棒性,而且具有在决定类别时可评估变量的重要性、不易出现过拟合的情况与可快速准确处理大量数据的特点,最早是由Breiman和Cutler提出[15]。
2.内幕交易识别模型
Cutler等[18]认为随机森林算法包括了变量的交互作用并且可以对所有变量进行重要性评估,因此无需考虑一般回归问题如Logistic回归等面临的多元共线性的情况,本文将查找到的阳性样本和阴性样本与其对应的特征指标作为随机森林模型的输入集从而构成内幕交易识别模型,内幕交易识别模型的流程示意图见图1。
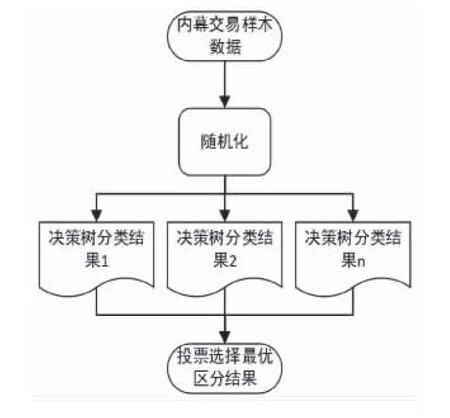
图1 基于随机森林的内幕交易识别流程

(2)
其中K表示有K个类别,pmk表示节点m中类别k所占的比例。特征Xj在节点m的重要性,即节点m分枝前后的GI变化量为:
(3)
其中,GIl与GIr分别表示分枝后两个新节点的GI。若特征Xj在决策树M中出现的节点在集合M中,则Xj在第i棵数的重要性为:
(4)
设随机森林共有n棵树,则:
(5)
所求重要性评分归一化:
(6)
五、实验结果与分析
本实验选定随机森林参数ntree为1000,mtry选取5进行计算。为了检测模型的分类识别效果,实验把所收集得到的样本随机分为训练集和预测集。其中预测集样本数量与训练集样本数量之比为3∶7。表2为分别以30、60和90个交易日作为不同事件窗口期建模之后测试数据的内幕交易判别准确度实验结果。

表2 事件窗口期的选择与其对应的识别准确度
由表2可知,以重大事件发生前的60个交易日内的证券市场微观指标为依据组合建立的模型识别准确度最高,达到79.17%,相比于选择为30日、90日时分别高出3.41%和5.13%。这意味着以重大事件发生前60个交易日左右的时间段内的相应数据指标对内幕交易的解释度最大,内幕交易在这段时期内的发生率也最高。
随机森林分类算法通常要在决策时对激进和保守的识别之间达到平衡。本文在内幕交易的识别过程中,可以构建一种非常激进的模型以即使误判非内幕交易样本为代价来确保尽量不误判任何一个内幕交易样本;另一方面,如果要保证尽量没有非内幕交易样本被错误地分类,可能要容许难以接受数目的内幕交易样本通过分类器成为非内幕交易样本。因此,无论哪一种偏激建模在实际识别运用中都难以提高模型整体的识别效率。为了更进一步分析模型的识别效果,对于训练集之外的预测集,本文引入召回率(Recall)与特异性(Specificity)指标来度量识别效果:
(7)
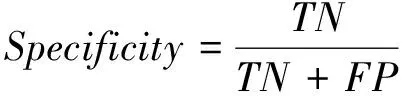
(8)
其中TP指真阳性样本数,FP指假阳性样本数,TN指真阴性样本数,FN指假阴性样本数。Recall为召回率,反映了内幕交易被正确判定的比例占总的正例的比重,Specificity为特异性,反映了非内幕交易被正确判定的比例占总的非内幕交易样本的比重,与Recall相对应。
由表3可知,在本文已构建的识别模型中,在事件窗口期为30个交易日时,模型的召回率为77.55%,特异性为74%,在事件窗口期为60个交易日时,模型的召回率为77.55%,特异性为80.85%;在事件窗口期定为90个交易日时,模型的召回率为82%,特异性为66.67%。

表3 事件窗口期的选择与其对应召回率与特异性结果
由于内幕交易行为对证券市场健康发展的巨大危害性,监管者在进行逐个排查前初步运用模型辨别样本时可能更希望不漏掉发生了内幕交易的样本。因此,本文识别模型对于内幕交易样本识别的召回率相比模型整体识别(包含内幕交易样本与非内幕交易样本)的正确率更加具有实际参考意义。从此角度来看,在事件窗口期为90个交易日时的辨别模型辨别最优,其模型的召回率为82%,这意味着对于内幕交易样本的识别率即召回率达到82%,相比模型整体识别的准确度高出7.96%,但模型特异性仅为66.67%。相比该模型的召回率与准确度均有一定差距。由于本文对阴性样本的选择是基于一定的假设(即不考虑发生了内幕交易而未被发现的情况),若考虑内幕交易隐蔽性高的特点,实际内幕交易发生量则可能远高于被查处的案件量,因此模型特异性的结果很可能受实际发生了内幕交易却没有被监管部门查处,从而被本文误作为阴性样本处理所影响。
图2为以重大事件发生前的60个交易日内的证券市场微观指标为依据组合建立的随机森林模型中以Gini指数度量的指标变量对识别模型的贡献度得分。
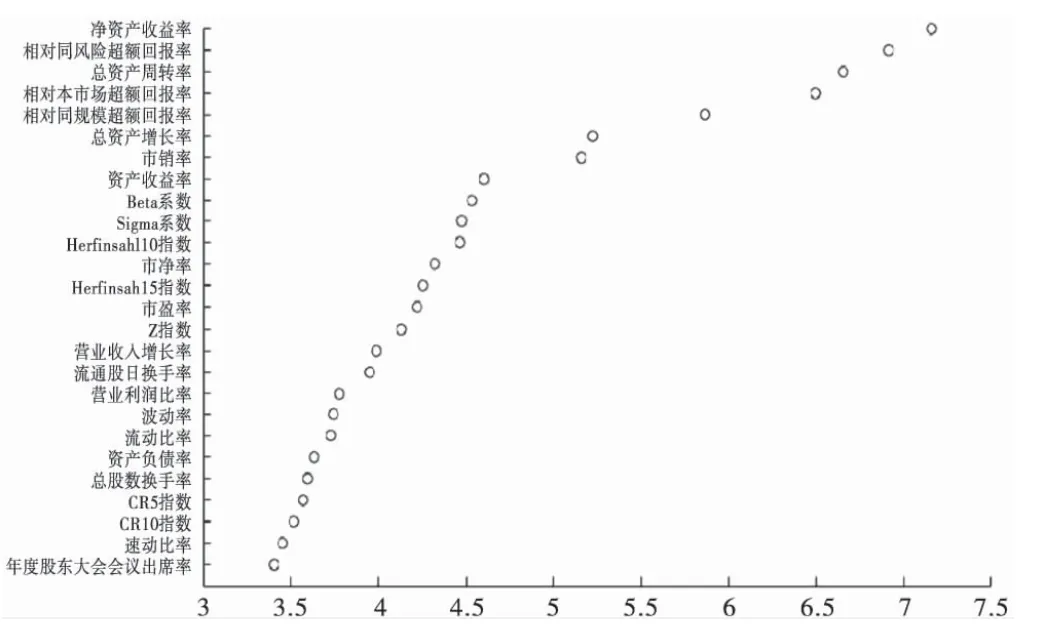
图2 指标变量重要性评分
由图2可以看出,在识别模型的Gini指数重要性评分中,净资产收益率指标得分最高,累计相对同风险超额回报率与总资产周转率指标的得分次之,年度股东大会会议的出席率得分最低。一般情况下,公司的自有资本获取收益的能力随其净资产收益率的增高而增高,公司的运营效益也随其净资产收益率的增高而更好。进一步分析发现,所选样本中阳性样本中净资产收益率的均值为1.33,阴性样本中净资产收益率的均值为9.67,其明显大于阳性样本的资产收益率。一般情况下,公司的周转速度随公司总资产周转率的升高而加快,公司的营运能力随公司总资产周转率的升高而增强。在本文所选取的数据集中,总资产周转率阴性样本均值为136.79,阳性样本均值为58.59。因此,相比而言未发生内幕交易样本的总资产周转率较高,这意味着发生内幕交易的上市公司其经营效益普遍弱于未发生内幕交易的上市公司。
图3为以重大事件发生前的60个交易日内的证券市场微观指标为例的包括阴性样本与阳性样本在内的所有样本对应的相对同规模超额累计回报率、相对本市场超额累计回报率与相对同风险超额累计回报率三者之间的相关性分析图。由图3可以看出,三者之间存在着高度正向线性相关性。
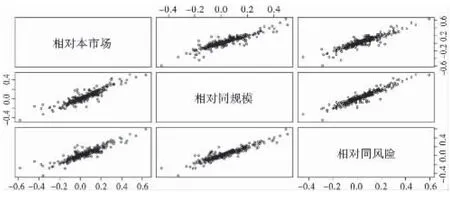
图3 指标相关性分析
进一步对不同类别样本的超额累计回报率指标数据分析发现,发生内幕交易案件的阳性样本其相对本市场超额累计回报率、相对同规模超额累计回报率与相对同风险超额累计回报率分别为13.51%、13.73%和13.91%,而未发生内幕交易案件的阴性样本其相对本市场超额累计回报率、相对同规模超额累计回报率与相对同风险超额累计回报率分别为0.95%、0.02%和-0.36%。针对三种累计超额回报率相比而言,发生内幕交易的股票样本在内幕消息公布前的60日内普遍比未发生内幕交易的股票获得更多的超额回报。在发生内幕交易的样本股票中,大多数内幕消息属于利好信息,因此在内幕信息被泄露后,可能是知晓内幕信息的知情人大量买入标的股票或是内幕信息的逐渐扩散化,这将导致标的股票的价格因为资金的入场而上升。随着重大信息公示日的逐渐来临,市场上部分敏感投资者也能够从标的股票股价的变化上得出信息从而买进,使得股票的价格又进一步攀升。那么实际上在利好消息未公示之前,市场就已经完全、甚至过度“消化”了利多因素,在消息公示之日,内幕信息的操纵者往往还会通过媒体等宣传手段大造声势,利用市场投资者对重大信息将带来的上涨预期在公告日后继续拉抬股价,而后在高位套现离场,获取更大的超额回报,从而损害广大投资者的切身利益。
六、结论
本研究选取了2001年1月1日至2017年5月31日中国证监会公开处罚的171个发生内幕交易的上市公司为阳性样本,采用1比1配对同样数量的阴性样本,并从公司股权结构、财务数据、治理体系以及证券市场微观表现方面选取了26个识别指标,对缺失数据进行相应处理后分别按照不同事件窗口期利用机器学习算法随机森林对内幕交易进行识别,分别以事件窗口期设定为30、60和90个交易日下计算的特征指标为依据建模。实验结果表明在内幕消息公布前的60个交易日内识别率最高,识别正确率达到79.17%,相较于选择为30日、90日时分别高出3.41%与5.13%。在辨别模型的Gini指数重要性评分中,净资产收益率指标得分最高,年度股东大会会议的出席率指标得分最低。陈国进等[19]通过实验发现上市公司业绩水平和上市公司内部人违规违法行为之间有密切负相关关系,原因可能是当一个上市公司健康发展时,出于信誉与未来阶段继续融资的顾虑,公司内部人员会自觉约束自身的违法违规行为。因此,提高上市公司的总体质量在保护广大中小投资者利益、减少上市公司内部人违法违规方面具有重要的作用。此外,累计相对同风险超额回报率指标的重要性得分仅次于净资产收益率,且与相对同规模超额累计回报率、相对本市场超额累计回报率呈高度正向相关性。其中,发生内幕交易的股票样本事件窗口期内的累计回报率明显高于未发生内幕交易的股票样本。综上,超额累计回报率与净资产收益率可以作为监督证券市场中上市公司内幕交易的两个重要预警指标,在实际内幕交易识别的运用中,有关监管部门可以灵活选择事件窗口期,有侧重地对重要性得分较高的指标如净资产收益率等指标进行监控,以作为预警提示。在本文提出的模型识别的基础之上针对性地调查取证,从而可提高监管效率和正确率。
注 释:
① 中国证券监督管理委员会(http://www.csrc.gov.cn/pub/newsite/)
② 东方财富网(http://www.eastmoney.com/)
③ CCER经济金融数据库(http://www.cerdata.cn/Home/Login.aspx)
④ RESSET锐思金融研究数据库(http://www.resset.cn/)
