基于改进的密度空间聚类算法的网络恶意数据流检测策略
2019-05-08李卫华
李卫华
(龙岩学院 信息工程学院,福建龙岩364012)
恶意网络流是由不同类型的恶意软件产生的,攻击者利用系统或软件安全漏洞[1]来部署恶意软件。近年来,网络异常流量的检测和攻击类型的识别一直是研究的热点[2-4]。现有的恶意流量检测主要集中在恶意软件的检测中,包括基于签名和基于异常的检测方法[5]。但由于这些检测方法都需要对数据包进行操作,从而产生巨大的计算开销,因此并不适用于动态的网络环境。研究者开始使用有监督的机器学习来检测恶意数据流(如C4.5决策树[6]、神经网络[7]、贝叶斯[2]),也有研究者将无监督学习算法用于恶意流量检测和分析[8],并用来识别恶意软件[9]。但随着攻击技术的发展,恶意数据流逐渐具有与正常数据流相似的统计特征。因此这些技术面临着产生高假阳性率的风险,即大量的正常网络数据流会被错误地归类为恶意数据流。聚类算法是常用的检测识别方法,然而,由于无法控制聚类过程中数据点的相似程度,现有的聚类算法不适用于恶意网络流的检测。鉴于此,本文设计一个有效的聚类算法,将恶意流的攻击过程分为多个阶段,利用基于参考点的策略来改进密度空间聚类算法。最后利用实验评估本文策略的有效性。
1 恶意数据流检测策略
本文将IP数据流[10]作为网络数据流的基本单元,并通过一个5元组来定义一个IP数据流。其中是源IP地址是源端口号是目的IP地址是目的端口号是协议类型。IP流由n维特征向量表示,其中n是特征的个数,xi是指从单个 IP流中提取的统计特征。研究人员发现了超过200个可用于数据流分类和聚类的复杂特征,但如果在进行数据流分类/聚类时使用了过多特征,就会产生很高的计算开销。因此本文仅使用几个简单的特征[11]来对网络恶意数据IP流(下文简称为“恶意流”)进行检测,具有足够的识别能力。我们使用网络数据流的网络层和传输层参数作为特征,如表1所示。
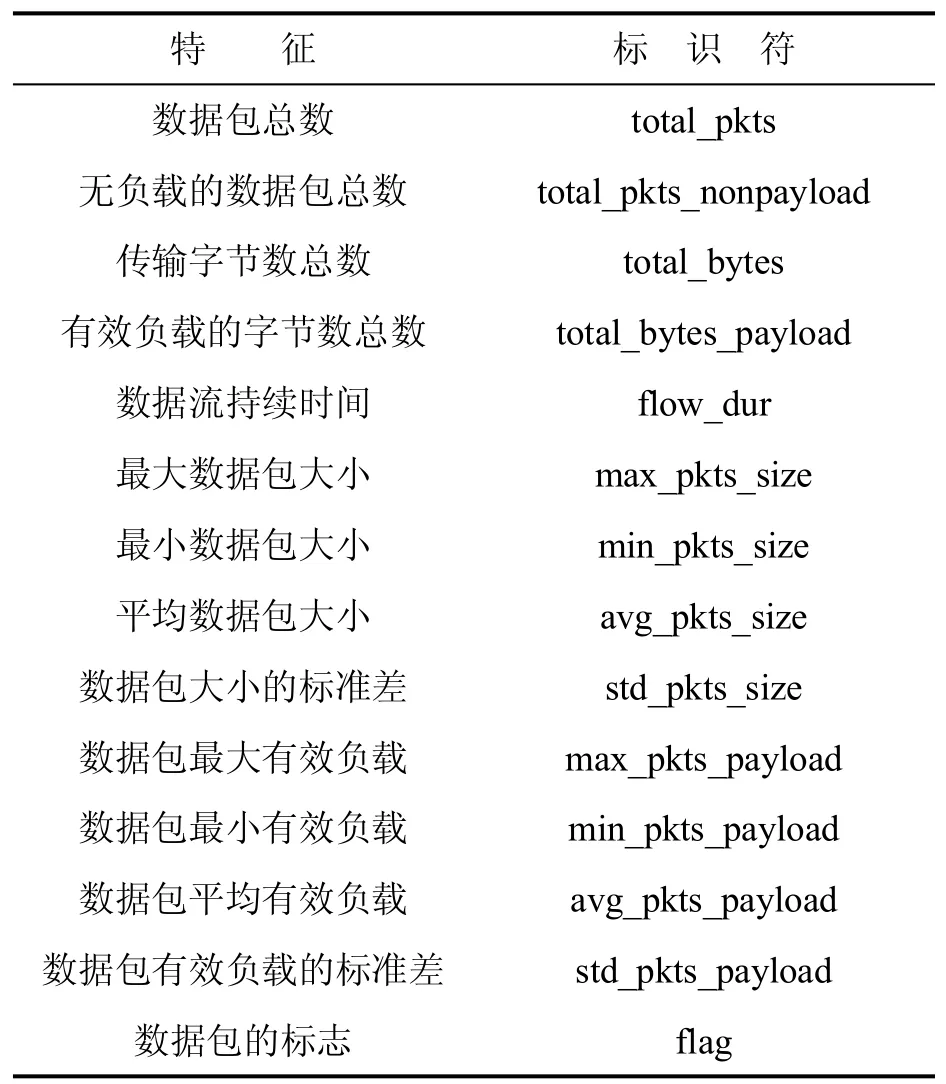
表1 网络数据流的特征
我们首先对数据集进行预处理。对于连续型的特征属性值,通过将其取值范围划分为多个区间,从而将一个连续属性值离散化。本文使用基于熵的离散化方法,假设阈值T将样本S分为子集S1和S2,并假设共有K个类是样本S中类的比例。子集S的类熵定义如下:

假设S1S,且 S2=S-S1,则样本S中关于特征F在阈值T下的类信息熵定义如下:
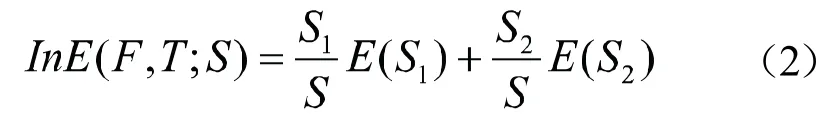
若满足公式(3)所示的条件,则认为对样本S以T作为阈值进行划分是可接受的。


其中,InG(F,T;S)是信息增益,N是样本个数,参数是常数。对于每个特征,我们根据可接受划分(即满足式(3)的划分)将特征属性值的取值范围划分为一系列区间,然后用不同的标称(nominal)表示各个区间,该过程就是连续值的离散化。
恶意流的聚类过程包括恶意流识别、特征提取、特征预处理、无监督学习和聚类,恶意流的最小粒度为IP数据包。首先,根据数据流的5元组标识将流量聚合成相应的数据流。然后,从聚合后的数据流中提取特征,利用离散化方法对特征进行预处理,将特征值转化为标称。接下来,使用非对称二进制对标称进行编码。最后,使用聚类算法来处理这些编码后的标称。某些恶意流具有与正常流相似甚至一样的特征,因此要从数据流中分离恶意流就显得尤为困难。像DDoS等这一类的恶意流具有不同的攻击阶段,因此有必要将恶意流分成不同的阶段,这能使分类的过程变得更加容易。
对于编码后的非对称二进制特征,其两种状态并不是同等重要的。给定两个非对称的二进制特征,那么两“1”(即正匹配)被认为比两个“0”(负匹配)更重要。本文用q表示个体i和个体j正匹配的数量,用r表示个体i的特征为“1”、个体j的特征为“0”的数量,用s表示个体i的特征为“0”、个体j的特征为“1”的数量。本文使用Jaccard系数来计算个体i和个体j之间的不对称二进制相似度sim(i,j)[12]。
(a)权重计算:对于数据流di,计算数据流di与集合D中所有数据流dj(除数据流di以外)之间的相似度sim(i,j),数据流di的权重wi计算方法如公式(4)所示。
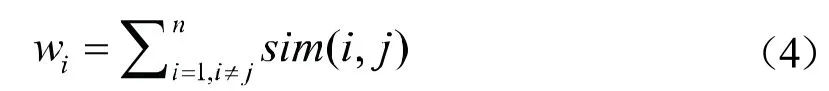
(b)参考点选择。按照数据流的权重对其进行降序排序,将结果存入候选队列中。从Q中选取两个数据流S1和S2作为参考点。我们需要尽可能确保这两个参考点分别属于不同的簇。由权重计算过程可知,属于同一簇的数据流具有相似的权重。因此,本文选择权重差异值最大的两个数据流作为参考点S1和S2。
(c)参考点聚类。对于数据流q,如果它与参考点s之间具有最大的相似度,则将q加入簇中,并将q从队列Q删除。当候选队列中的数据流与参考点之间的相似度小于阈值时,参考点的聚类过程停止。接下来,重复参考点选择、参考点聚类两个过程,直到队列Q为空。
(d)噪声消除。数据集中可能包含不属于恶意流的噪声,因此本文将簇大小小于3的视为噪声。

2 性能评估
我们使用入侵检测数据集中的DDoS数据集来评估本文的策略,DDoS攻击过程分为五个阶段:从远程站点进行IP-sweep、通过探测IP以查找sadmind进程、使用sadmind的漏洞进行破坏、安装DDoS木马软件以及进行DDoS攻击。
本文使用三个常用的指标来评价聚类结果,即纯度(purity)、兰德指数(Rand Index)以及F值(FMeasure)[13]。我们使用范围从0到1的阈值对测试数据集进行了一系列的聚类实验,结果如图1、图2和图3所示。随着阈值的增加,簇的纯度、兰德指数和F值也随之增加。尤其是当阈值大于0.5时,三种指标都能够得到更好的结果。然后,我们将本文策略与K-Means算法进行比较,其中我们将阈值设置为0.95,结果如图4所示。其中,图例中K-Means(C=2)是指K-Means算法的初始中心点数量为2。由图4可知,本文策略比K-Means具有更好的聚类性能。
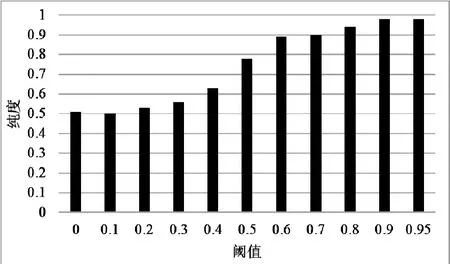
图1 聚类的纯度

图2 聚类的兰德指数

图3 聚类的F值
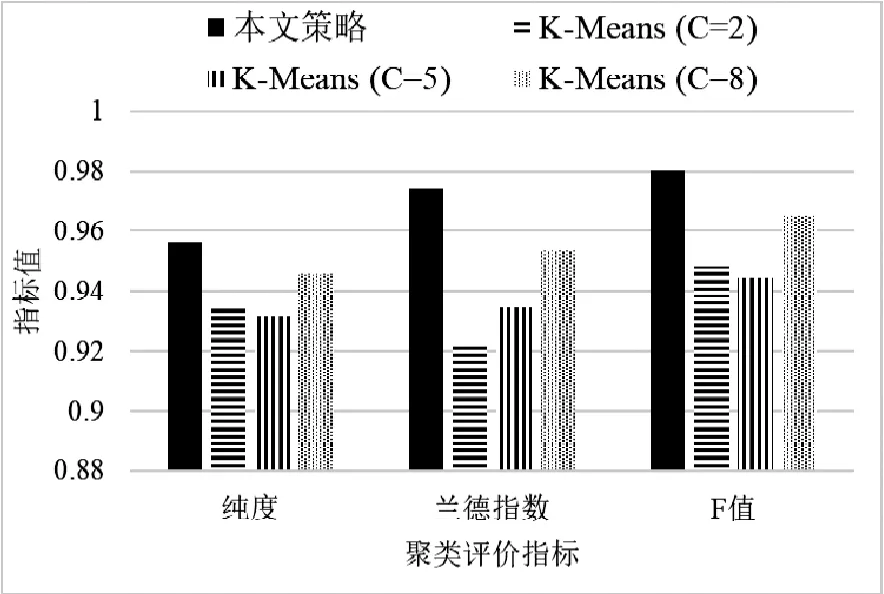
图4 本文策略与K-Means算法对比结果
3 结论
利用基于参考点展开的策略来改进密度空间聚类算法,并使用该聚类算法进行网络恶意数据流检测。实验结果表明,与K-Means算法相比,本文策略具有更好的聚类性能。在未来的研究工作中,我们将进一步研究如何根据聚类结果识别隐藏在正常数据流中的恶意攻击流。
